
基于FFmpeg 多线程编码的智能交通监控系统设计
2024-03-25 06:34:26戚义盛张正华赵天林刘国澍
电子设计工程 2024年6期
戚义盛,张正华,吴 宇,苏 权,苏 波,赵天林,刘国澍
(1.扬州大学信息工程学院(人工智能学院),江苏扬州 225000;2.扬州国脉通信发展有限责任公司,江苏扬州 225000)
近年来,智能交通系统(ITS)飞速发展[1],诸如电子警察、诱导屏等众多交通管理设备得到广泛应用,而在安全监测方面,传统的人工巡查方式,工作量大且流于表象。因此,对交通管理设备实现高效准确地监控具有重要意义。
视频流监控因直观性高、信息量大等优点成为安全监测系统的研究热点[2]。用户体验QoE(Quality of Experience)通常被作为实时视频通信的优化目标[3],即更低的系统延迟和更高的视频质量。而传统的远程交通视频流传输系统,其传输数据量庞大,信息冗余多,常常会出现图像模糊、延迟高、稳定性差等问题。
针对以上问题,该文改进了FFmpeg 的编码流程[4],利用GPU 的专用硬件处理单元,实现宏块(Macroblock)行级[5]的并行编码加速处理,有效地降低了监控系统整体的延迟。该文引入率失真理论(Rate Distortion Theory)模型[6],通过率失真曲线特性来衡量和对比编码器的性能。
1 关键技术
1.1 率失真理论模型
如图1 所示,率失真曲线[7]的理论值是一条单调递减的凸函数,D为编码视频的失真,R为所消耗的码率,Rc为最大允许码率。对于同一压缩算法来说,虽然码率越高,图像质量越好,失真越小,但同时也会占用更多存储空间,增加了网络传输压力。因此,率失真曲线的理论值由码率与失真的最佳平衡点构成。
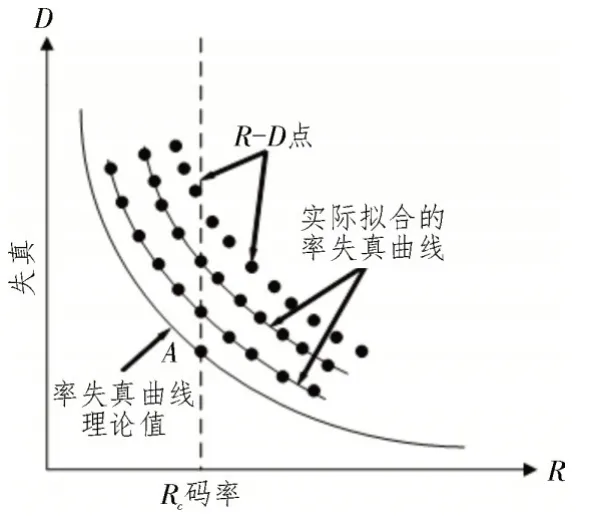
图1 率失真曲线示意图
该文从率失真优化(Rate Distortion Optimization)的角度[8]来衡量不同编码方案下的率失真特性。从图1 的虚线上看,当给定Rc时,失真D理论上最小的点落在曲线上的A点。因此,该文以特定的编码方案,在不同的Rc下,对视频进行编码,计算编码后的失真,就可以得到一个个实际可操作的R-D点,当这些离散的R-D点拟合而成的曲线越靠近理论值的曲线时,说明率失真特性越好,即编码的性能越高[9]。
该文采用峰值信噪比(PSNR)和结构相似性(SSIM)视频质量评价指标[10],对编码失真D进行量化。PSNR 值越大,表明图像质量越好,失真越小[11],计算PSNR 需要先计算均方误差(MSE),公式如下:
式中,I和K分别代表原始图像和目标图像,M和N分别表示图像的高度和宽度。则得到PSNR 的计算公式如下:
式中,MAXI是图像的最大可能像素值。考虑到人眼的视觉特性,SSIM 算法从图像亮度、对比度和结构的相似性三个维度来衡量图像质量。取值范围为[0,1],值越大图像失真越小[12]。SSIM 数学表达式如下:
式中,L(X,Y)、C(X,Y)、S(X,Y)分别为亮度、对比度和结构的相似性,α、β、γ分别为三者的权重值。
1.2 FFmpeg多线程编码加速
现在的显卡硬件编码是利用GPU 集成的专用硬件单元进行计算,其效率远高于通用计算,该文选用NVIDIA 的NVENC 进行多线程加速。如图2 所示,FFmpeg(Fast Forward Mpeg),一共有8 个常用库,h264_nvenc 作为FFmpeg 硬件加速处理的API,包含在编解码库AVCodec 中。
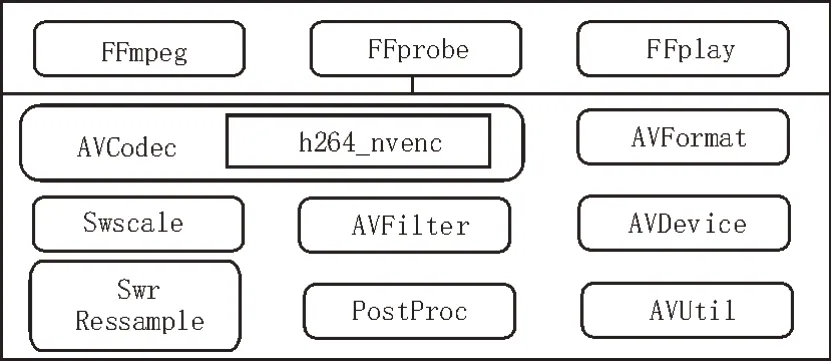
图2 FFmpeg模块结构图
GPU 硬件加速的关键在于多线程执行,不同于CPU,GPU 拥有众多的计算核[13],可以将执行相同指令的数据合理划分到不同的内核上,实现大规模并行处理。基于众核特性,得到多线程执行的FFmpeg编码流程图,如图3 所示。
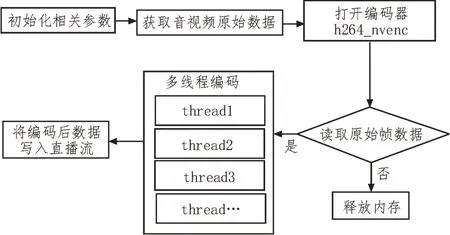
图3 FFmpeg编码流程图
FFmpeg 支持基于片(Slice)的并行算法,将每帧图像划分为多个Slice,同一帧的各个Slice 之间没有数据依赖,以此为基础可以实现并行编码。但由于每帧的Slice 数量较少,通常仅有1~4 个,因此,Slice并行编码的可扩展性会受到限制。该文专注于提高使用多线程编码器的效率,所以,将宏块行级并行化的方法应用到开源FFmpeg 的实现中,直接对宏块行实现并行编码,最大化编码的速率。宏块行级多线程编码流程如图4 所示。
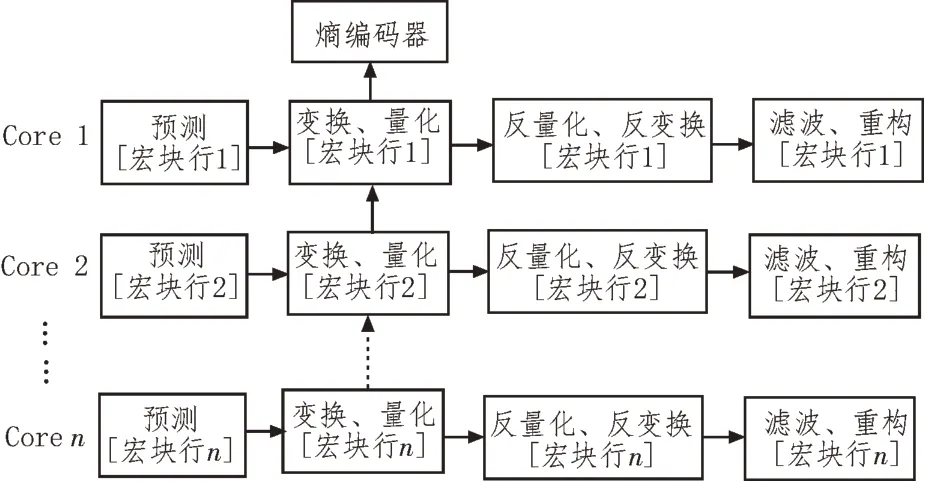
图4 宏块行级多线程编码流程
每个GPU 核心可单独处理同一行上所有宏块的预测、变换、量化、反量化、反变换、去块滤波和图像重构,其中预测包括帧内预测和帧间预测[14]。为了实现最大加速,最佳内核数应等于宏块行数。该方法将整帧图像的最终熵编码与预测、变换、量化、滤波等环节并行处理,同步运行,大幅度节省了CPU 计算最终熵编码所需的时间,从而显著提升FFmpeg 编码器整体的计算效率,降低交通视频流的传输延迟。
2 视频流传输方案设计
交通视频流监控系统主要包括原始音视频流数据采集、多线程编码、合并推流、流媒体服务器中继转发、以及客户端拉流播放等功能模块,系统的总体网络架构如图5 所示。
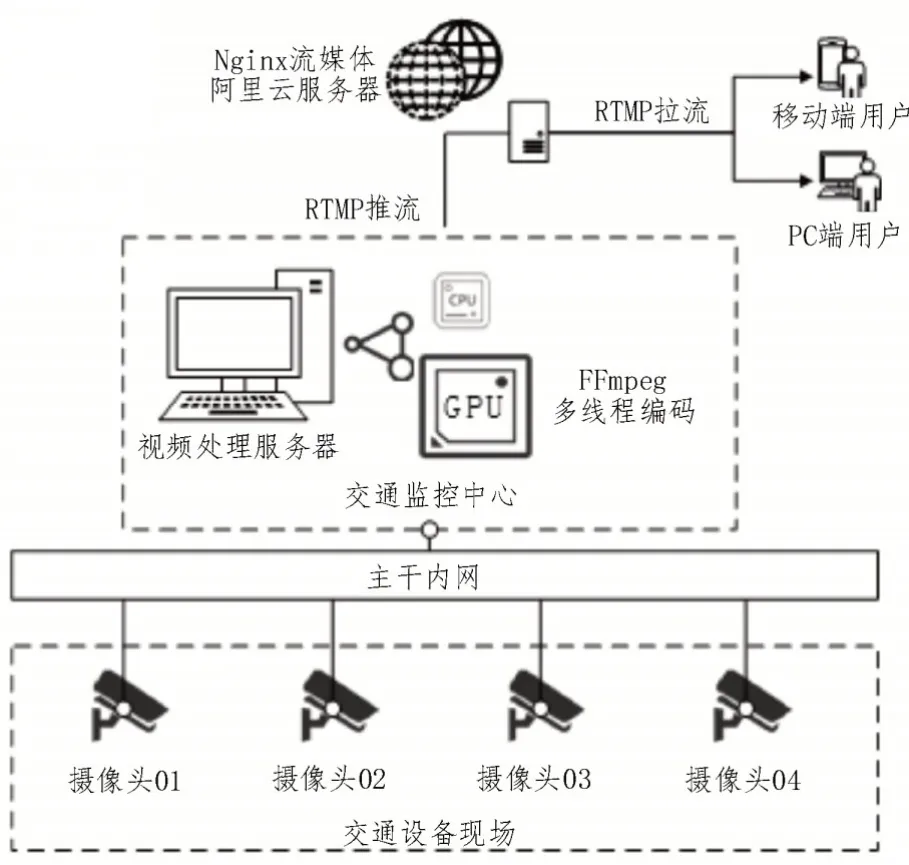
图5 视频流监控网络架构
Nginx 是一种高性能HTTP 反向代理服务器[15],该文采用基于RTMP(Real Time Messaging Protocol)的Nginx 服务器作为流媒体服务平台。并采用FFmpeg 封装音视频数据,通过RTMP 流媒体协议以直播流的形式将数据推送出去[16]。
具体传输方案如下:
1)交通管理设备现场的摄像头将采集的原始视频流数据通过光纤内网传输到交通监控中心的视频处理服务器上;
2)将nginx-rtmp-module 模块部署在阿里云服务器端,通过修改nginx.conf 文件,配置好RTMP 服务,实现RTMP 视频数据的中继转发功能;
3)将基于FFmpeg 自主开发的音视频处理软件部署在视频处理服务器上,通过FFmpeg 调用多线程编码模块,连接高性能GPU 进行并行运算[17]。最后对压缩后的多路视频流进行合并和封装,并通过单路推流至具有公网IP 的Nginx 云服务器端;
4)PC 端和移动端均可使用支持拉流和解码的软件,从Nginx 服务器获取视频流,实现对交通管理设备的实时监控。
3 系统集成测试
3.1 基本功能实现
基于FFmpeg 开源库编写的音视频处理软件,编译环境为Visual Studio 2019,使用QT15.5 搭建软件界面,以方便交通监控中心进行场景选择和推流设置。软件界面如图6 所示。

图6 软件界面
Nginx 流媒体服务搭建完成后,可在Windows 端打开并运行,输入推流地址,点击“开始推流”按钮,软件通过h264_nvenc 自动调用GPU 多线程编码,封装多路视频流并推送至Nginx 服务器。
监控系统的播放测试结果如图7 所示。系统支持PC 端和移动端两种用户播放方式,均可使用PotPlayer 拉流播放。输入拉流地址,链接到Nginx 服务器后,即可实现交通视频监控,经测试,系统满足设计之初的基本需求,完成了整个视频流数据的传输通道,监控无卡顿、画质清晰。

图7 PC端及移动端测试结果
3.2 系统性能测试
为了更好地对比GPU 宏块级多线程编码和传统CPU 软件编码的性能。该文重点对监控系统的画质、延迟、稳定性进行测试。
在编码质量方面,根据1.1 节中对率失真理论模型的分析,该文分别采用PSNR 和SSIM 作为视频质量指标来绘制“码率-质量”曲线,即R-D 曲线,用来比较编码性能和画质表现。
在编码效率方面,使用加速比作为性能指标,计算公式如下:
式中,Ts表示libx264(CPU)的运行时间,Tp表示h264_nvenc(GPU)的运行时间,SP 表示加速比。该文选用6 个不同的YUV 视频序列作为测试样本。测试序列信息如表1 所示。

表1 测试序列基本信息
实验运行在Windows 10操作系统上,CPU型号为AMD Ryzen 75800H,3.20 GHz,GPU 型号为NVIDIA RTX 3070,其中,GPU 一共包含2 944 个流处理器。
为得到不同视频压缩码率下的PSNR 值和SSIM值,该文通过FFmpeg 编码模式中的恒定量化器模式(Constant Quantizer)来实现压缩码率从低到高的控制,该模式通过设定qp 值(0~51 的数字)来量化画质,其中,51 代表最低画质,对应最低码率,0 代表最高画质,对应最高码率。根据式(2)和式(3)将不同qp 值下编码得到的有损文件,通过FFmpeg 命令与原始文件进行比对运算,即可得到PSNR 和SSIM。
该文选取帧数最多的life.yuv 测试序列,分别使用CPU(libx264)和GPU 多线程(h264_nvenc)进行编码,并选取12 个典型的qp 值进行测试,得到由低到高各自对应的12 组“码率-PSNR 值”和12 组“码率-SSIM 值”。根据率失真理论,这些“码率-质量”的数据组由实际的R-D点组成,再使用Matlab 获取所有R-D点构成的坐标,拟合出“码率-质量”的率失真曲线,如图8-9 所示。

图8 码率-质量(PSNR)曲线
分析图8 可以发现h264_nvenc 的率失真特性总体优于libx264,直到码率达到约18 000 kbps 时,libx264 的PSNR 值才追平h264_nvenc。分析图9 同样发现,当码率小于22 000 kbps 时,h264_nvenc 的SSIM 值更高,即失真会更小。而对于帧率为30 fps的1 080P 视频流,码率的需求一般在4 000~8 000 kbps 之间。因此,在相同码率输出的要求下,该文的加速编码方案编码质量并未降低,而且画质有小幅度的提升,失真更小。
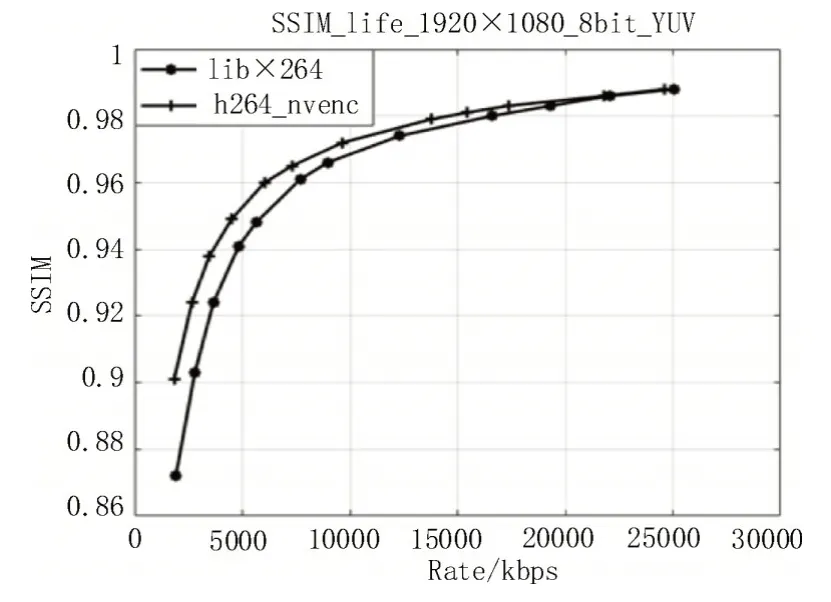
图9 码率-质量(SSIM)曲线
为得到编码消耗的时间,该文通过PowerShell 来分别调用FFmpeg 中的libx264 和h264_nvenc 编码器,对6 个帧率均为30 fps 的YUV 文件分别进行编码,通过“-b:v 8000k”命令,固定压缩码率为8 000 kbps,然后进行测试,记录编码时间,计算加速比SP,以此来对比开启GPU 多线程编码前后的编码效率,测试结果如表2 所示。
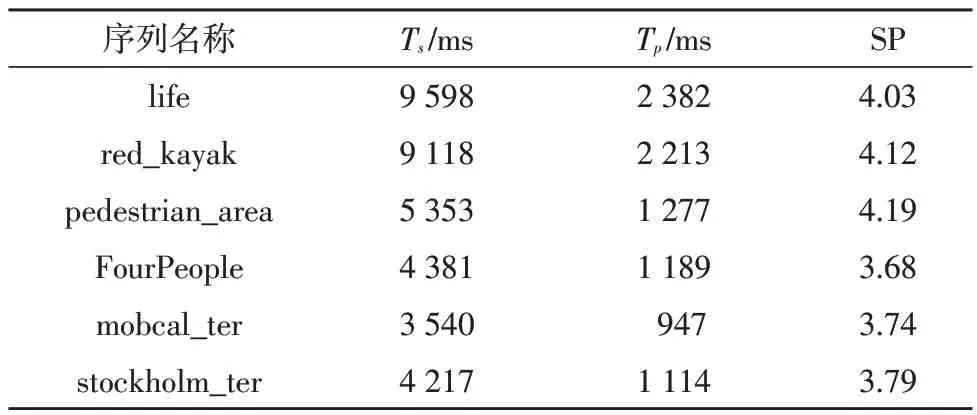
表2 编码效率和加速比
分析表2可知,Ts均明显高于Tp,说明h264_nvenc多线程编码的表现远好于libx264,视频分辨率1 080 P 和720 P 的平均加速比分别达到了4.11 和3.74。虽然分辨率越高,相同帧数的视频消耗时间也会越多,但是GPU 多线程编码的加速优势却更明显,例如601 帧720 P 的序列FourPeople 加速编码消耗时间为1 189 ms,而760 帧1 080 P 的序列red_kayak 消耗了2 213 ms,时间更长,但是加速比却从3.68 提高到了4.12。
然后测试整个监控系统的延迟,即推流端发送数据到收流端播放数据所需要的时间。该文对启用FFmpeg 多线程编码前后,分别进行100 次系统延迟测试。
传统CPU编码的测试结果如图10所示,系统延迟在2 500~2 580 ms之间波动,平均延迟为2 540.93 ms。
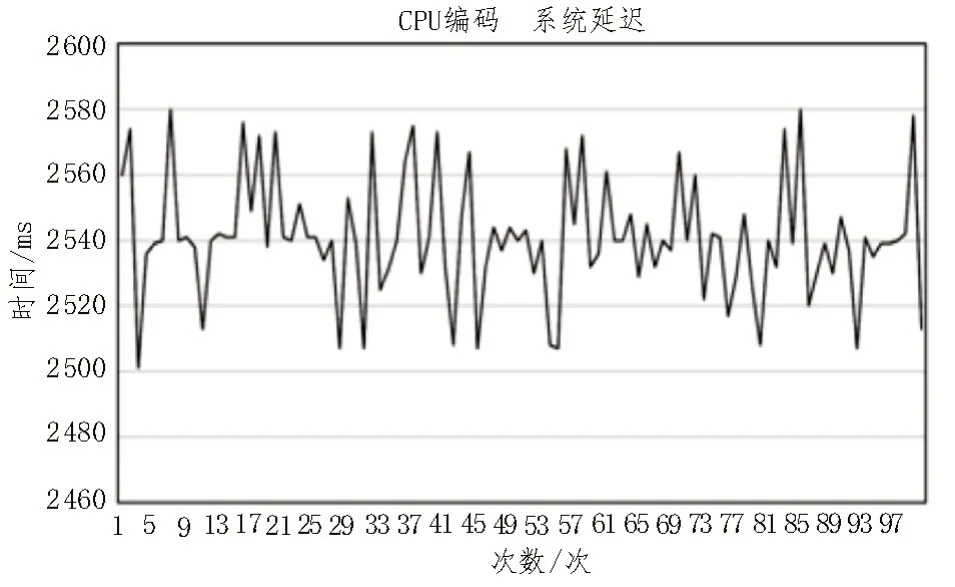
图10 CPU编码的测试结果
调用h264_nvenc 多线程加速编码后的测试结果如图11 所示,系统延迟明显降低,波动范围在801~892 ms 之间,且始终维持在1 s 以内,平均延迟为845.10 ms。

图11 GPU多线程加速后的测试结果
根据对图10 和图11 的分析,系统的平均延迟降低了近1.7 s,并最终控制在1 s 以内,监控的实时性得到了大幅度增强。
最后,测试系统的稳定性,记录交通监控系统在长期工作运行下的状态。该文的直播视频流输出设置分辨率为1 080 P,码率为8 000 kbps,帧率为30 fps。测试得到的系统平均延迟和丢包率如表3所示。
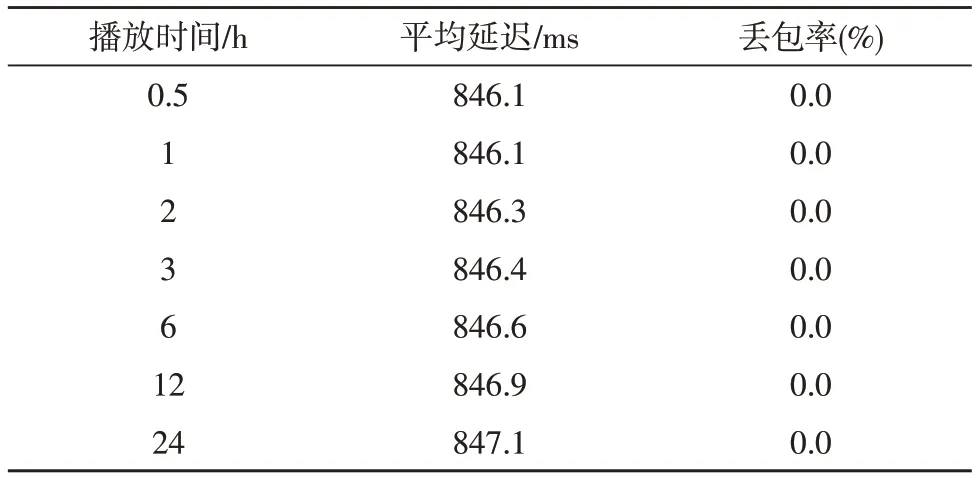
表3 系统稳定性测试结果
测试结果表明,监控系统可持续正常工作,且没有因延迟而出现帧丢失或跳过的情况,因为该文使用的RTMP 是基于底层可靠的TCP 协议建立的连接,不会存在丢包现象。24 h 连续测试后,系统的平均延迟依然稳定,可以满足智能交通背景下长期稳定的监控需求。
4 结束语
该文基于FFmpeg 设计的视频流传输系统,成功实现了对交通管理设备的实时监控。市场上的视频流传输方式,大多是以牺牲视频质量为代价换取较低延迟,或者以传输时延过大为前提,提高视频质量。
该系统采用多线程加速编码的方法,在提高编码速度,有效降低系统延迟的前提下,依然保持了优秀的率失真特性,保证了视频的高质量传输。经测试,系统整体传输延迟控制在1 s 以内,实时性高,且十分稳定。
下一步将继续研究Nginx 流媒体分发环节和解码播放环节的延迟优化,进一步降低系统的最终传输延迟。
猜你喜欢
无线互联科技(2022年11期)2022-08-18 01:56:42
数字通信世界(2020年11期)2020-12-04 05:24:22
计算机应用(2018年7期)2018-08-27 10:42:40
办公自动化(2016年13期)2016-08-24 01:47:29
江西理工大学学报(2015年3期)2015-12-22 05:26:24
电子设计工程(2015年24期)2015-08-26 06:39:42
计算机工程(2015年8期)2015-07-03 12:19:56
宇航学报(2014年2期)2014-12-15 02:49:06
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
杭州电子科技大学学报(自然科学版)(2011年5期)2011-09-04 06:09:24
