
虚拟试穿能量法空间注意力编码算法
2024-03-25 01:58:18孟义智杨大伟
大连民族大学学报 2024年1期
孟义智,杨大伟,毛 琳
(大连民族大学 机电工程学院,辽宁 大连 116650)
虚拟试穿包含服饰试穿和人物姿态合成两个方面的功能。主要工作是在模特人物更换试穿衣服的过程中,将待更换的服饰和人体部件从图片中分割出来经编码,融合到目标模特的指定姿态上,形成试穿效果。
在虚拟试穿研究中,引入注意力的目的是提高服装的分割精度和服饰迁移后的呈现效果,进一步提高虚拟试穿的可视化主观评价感受。
现有基于深度学习的注意力网络,对于通道注意力来说典型模型为SENet(Squeeze-and-Excitation Networks)[1],通过压缩-激励过程,对通道角度下的特征进行权重赋值,实现去除通道中冗余信息的目的;空间注意力代表为STN(Spatial Transformer Networks)[2],将源域图像特征经过随机变换映射到另一个中间域,而后返回到当前域空间,在转换过程中,实现空间特征的仿射不变性获取;还有一种注意力网络就是混合注意力网络,其代表模型是CBAM(Convolutional Block Attention Module)[3],融合了通道和空间两种注意力机制,来进一步提高特征的有效利用。
虚拟试穿研究与这些注意力网络结合来提高服饰生成和迁移的可视化效果。王琴[4]等人,以苗族服装数据集为研究对象,将CBAM混合注意力网络,嵌入到全卷积神经网络(Fully Convolutional Networks,FCN)中,实现了局部特征和全局特征的交互共享;覃琴[5]等人在密集连接网络上对服装数据集进行了空间多尺度特征的融合,能够实现自动地分割苗族衣服上的服装信息;赵海英[6]等为了解决传统服装上的细小花纹边缘提取不清晰的问题,在特征提取阶段引入卷积注意力特征(Convolution Attention Feature,CAF)网络,提高系统对花纹样式等纹理的关注程度。以传统非机器学习方法,利用空间上的能量法来对视觉目标的显著能量进行快速有效地获取,有效地解决目标的预分割处理问题[7]。
本文针对服饰试穿领域中,将分割作为生成器编码的需求,为深度学习的分割网络提供更好的预处理空间注意力。提出一种适用于虚拟试穿应用场景的能量法空间注意力网络(Spatial Attention Feature extraction algorithm based on Energy approach for visual try-on,SAFE),利用空间各轴向上的像素位置统计信息,实现分割掩模模板的位置精准匹配问题,从而提高分割输出的编码质量。
1 问题分析
在虚拟试穿分割特征编码部分,以文献[8]中提及的Dior(Dressing in order network)网络为例。Dior网络采用轻量级分割特征编码结构,采用一个精减的2层VGG卷积网络作为主干,对服装输入S经重采样变换,分别得到特征纹理T和分割M两路输出,为后续模特试穿生成提供编码基础。Dior网络中,分割编码模块的具体结构示意图如图1。其中,分割支路与纹理支路内容特征的输入,均来自于重采样后的输出结果,且分割处理模块为3个3×3卷积。
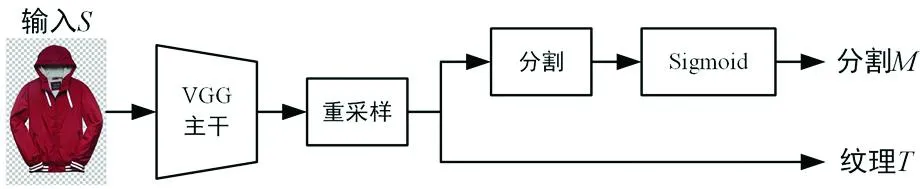
图1 Dior分割编码结构示意图
在这种轻量级分割特征编码网络里,属于浅层信息处理范畴。特别是在分割M支路中,分割模块原本是对全部输入特征进行分割处理,如果能够加入注意力机制,则可以有针对性地对特定区域着重分割,从而提高分割输出的精度。
2 SAFE算法设计
2.1 算法设计
为提高分割编码质量,SAFE采用预分割处理方式来提高空间位置上的特征表达能力,以传统非机器学习的能量法显著目标区域检测思路[7]。
获取显著目标区域位置信息的原理如图2。假设给定一幅图片,其高度和宽度尺寸为(m,n)像素,则X轴和Y轴的能量就是按列或行的方向,对像素值大小的累加和结果。X=[x1,x2,……,xn]∈R,Y=[y1,y2,……,yn]∈R,且满足如下条件:

图2 能量法显著目标区域检测原理示意图(各轴上能量区域重叠的部分,即为显著区域)
(1)
(2)
其中,P(xi,yj)为图片像素幅值大小,在计算任意轴某元素能量时,图像应经归一化处理,使像素幅值大小的范围在[0,1]之间。
从图2中可得,显著区域实际是由轴和轴的能量重叠区域所构成。该显著区域[9][(visual saliency)将可作为后续分割的预处理过程,提高分割的位置敏感性需求。为配合深度学习网络的设计,本文借鉴位置注意力深度学习网络CA(Coordinate Attention)[10]的设计思想,为虚拟试穿的分割模块,提供显著目标的位置注意力机制。能量法显著目标注意力结构如图3。
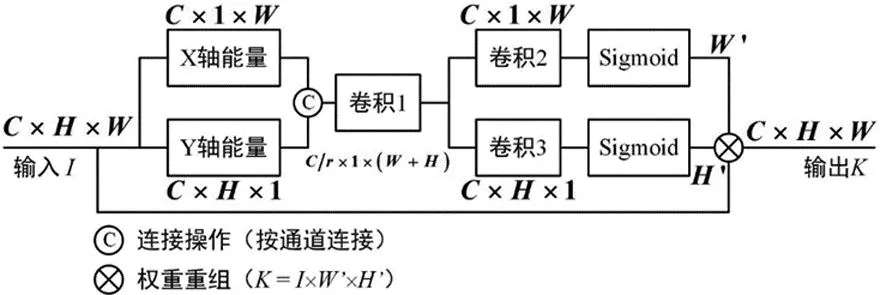
图3 能量法显著目标注意力结构(r = 16)

图4 整体网络结构
图3中,输入I为输入图像或输入特征图,其中,C为通道,H为特征图高度,对应于能量法显著目标区域检测的Y轴方向能量计算,W为特征图宽度,对应于X轴方向能量。遵循能量法显著目标区域检测思路,设定如下步骤来构建深度学习网络,从而实现一个神经网络下的能量法显著目标空间注意力机制。
步骤1:能量计算。各轴上的能量,为输入特征图I的归一化后单个像素点(或特征空间点)的幅值大小累加和,为保证深度学习后续的梯度等计算要求,对累加和做求平均操作。即,能量计算从公式(1)和公式(2)变为求平均操作。
(3)
(4)
步骤2:通道缩减。通道缩减是去除多个通道中的冗余信息,而通道缩减操作在注意力机制中,相当于要解决给定深度学习网络要关注何种特征信息。设定通道缩减的衰减系数为常数值r。该操作由图3中的卷积1操作完成。
步骤3:通道恢复。经图3中的卷积2和卷积3来实现通道恢复,并完成各个轴方向上的能量计算。
步骤4:权重重组。图3中的权重重组操作,是对输入特征图I的注意力操作。
K=I×(W′×H′) 。
(5)
式中:I为特征图;W'为X轴的能量计算结果;H'为Y轴的能量计算结果。K为能量法显著目标区域对输入特征图I的注意力结果。
2.2 整体网络结构
将本文所提的SAFE算法植入Dior网络[8],置于特征图分割支路,输入来自于VGG主干网络[11]经重采样的输出结果,输出送至分割、Sigmoid激活网络,形成分割结果M。
3 仿真分析
3.1 仿真参数
SAFE算法网络采用流行的服饰数据集DeepFashion[12],训练集与测试集分开。其中,图片尺寸均为,这里256为图片高度,176为图片宽度。训练集有48 674张照片,大约占用9 GB存储容量。测试集有4 038张照片,大约占用700 MB存储容量。
整个网络迭代30万次,优化器采用Adam梯度下降算法,初始的学习率为,一般来说,学习率最终会下降到。
仿真环境,采用Ubuntu 18.04操作系统,单张NVIDIA 1070Ti显卡(8G显存),BatchSize=2。
3.2 评价指标
依照虚拟试穿网络魔性的主流评测手段,本文SAFE算法从结构相似度SSIM[13]、分布相似度FID[14]以及感知相似度LPIPS[15]等三个角度去衡量生成结果与真实参考图片之间的关联性。
SSIM评价公式为
(6)
式中:x和y分别表示真实图片和生成图片;μ为图片像素值的平均值;σ为图片像素值的标准差;C1、C2为常数。
FID评价指标公式为
(7)
式中:x和y分别表示真实图片和生成图片;Tr为矩阵的迹;μ表示均值;σ表示方差。
LPIPS评价公式为
(8)
式中:x和x0分别为真实图片和生成图片的局部分块;l是当前卷积层的序号;y和y0对应于x和x0经过l层卷积后的结果;H和W是当前第l层特征图的高度和宽度;ωl是通道激活系数;⊙表示按通道方向的相乘。
3.3 消融实验
SAFE算法的设计是基于能量法的空间注意力,对分割处理关注空间信息的深度学习处理模块来说,具有良好的处理作用。为检验空间注意力对系统各模块的影响,设计4组消融实验来提供佐证见表1。表1中的序号表示SAFE要加入网络的位置,这里规定,每次只有1个位置插入SAFE算法模块,保证对比实验的结果具有可分析性。其中,位置1对应于分割支路,位置2对应于分割和纹理支路同时应用SAFE算法,位置3是仅对纹理支路进行空间注意力计算,位置4则是在主干网络VGG之后。SAFE消融实验设计示意图如图5。4个不同位置加入SAFE算法的消融实验对比图如图6。

表1 SAFE消融实验设计一览表

图5 SAFE消融实验设计示意图

图6 4个不同位置加入SAFE算法的消融实验对比
图6中,输入为模特图片,根据由OpenPose[8, 12]生成的18点姿态参考骨架点为参考,合成出新的人物姿态试穿效果图片。根据消融实验对比发现,从图片1和图片3可以看出,在图2的位置1加入SAFE算法,相比于其他三个位置来说,模特姿态及服饰变形的还原程度最好。从图片4和图片2中可以看出,位置1的模特人物面部表情相对较好,与原始输入图片的外观样貌更加相近。
四个位置的消融实验对结果的影响见表2。显而易见,SAFE-1的位置1上的效果相对更好。也同时跟原有算法比较得到了一定的提高,其中SSIM提高1.08%,FID提高0.5%,LPIPS提高0.2%。

表2 不同位置的消融实验对比结果
SAFE算法虚拟试穿的效果图如图7。从图中看出来两组实验仿真结果,任务模特的变换效果虽然整体迁移较为成功,但是,人物脸部和衣服局部细节仍旧存在变形问题。这也是后续科研课题中要解决的主要问题之一。

图7 SAFE算法虚拟试穿效果
4 结 语
采用深度学习的方式,还原了一种非学习的能量法空间位置注意力机制—SAFE算法网络。将其应用在主流虚拟试穿网络的分割编码前端,为分割模块提供有效的空间注意力信息。其结果不仅从参数的数值精度上有所提高,更从可视化角度上明显感受到空间注意力对分割编码的影响。这样的尝试,更为今后在服饰生成网络的应用中,提供研究基础。分割编码需要更加精细的空间注意力,补偿模特人物前后姿态变化和服饰变化的空间变形缺损,进一步加强分割的实现效果,提高整体的虚拟试穿指标精度。
猜你喜欢
轻音乐(2022年9期)2022-09-21 01:54:44
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
少儿美术(快乐历史地理)(2019年1期)2019-05-09 03:09:34
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
腹腔镜外科杂志(2016年9期)2016-06-01 12:10:07
中华老年多器官疾病杂志(2016年7期)2016-04-28 08:42:47
