
基于可分离扩张卷积和通道剪枝的番茄病害分类方法
2024-03-25 13:56姜晟久钟国韵
江苏农业科学 2024年2期
姜晟久 钟国韵

摘要: 为了实现番茄病害的快速检测,针对传统卷积神经网络病害分类方法参数量大、对算力要求高的问题,提出了一种基于可分离扩张卷积和通道剪枝的番茄病害分类方法。基于MobileNet v2,提出了一种可分离扩张卷积块,在不增加网络参数的情况下,扩大网络的感受野,提升网络提取番茄叶部病害特征的能力。然后替换PReLU激活函数,避免产生梯度弥散问题。同时能够更好地处理图像,提高网络对番茄叶部病害负值特征信息的提取能力,具有更好的鲁棒性。最后,使用通道剪枝技术,引入缩放因子联合权重损失函数,分辨相对不重要的通道,并对其进行裁剪,再对剪枝后的网络进行微调并重复以上步骤,在大幅减少网络参数量的同时,不影响网络的性能。在数据集上的结果表明,研究方法在网络参数量仅为0.7 M的情况下,准确率达到了96.44%,精确率达到了96.36%。与目前主流轻量化网络MobileNet v3、GhostNet、ShuffleNet v2相比,模型准确率分别提高了0.45、0.77、0.24百分點,同时模型参数量分别仅为以上模型的12.96%、13.46%、30.43%,模型更轻量且准确率更高。
关键词: 番茄病害;可分离扩张卷积;通道剪枝;MobileNet v2
中图分类号:TP391.41 文献标志码:A
文章编号:1002-1302(2024)02-0182-08
农作物病虫害是制约我国农业生产的主要灾害之一,严重影响农作物的产量和质量,其中灾难性农作物病虫害的发生加剧了粮食供应的短缺[1]。番茄作为重要的蔬菜,被广泛种植于世界各地,我国便是番茄种植大国之一[2]。在栽培或收获后的贮藏期间,番茄容易感染由一系列致病真菌、线虫、细菌或病毒引起的200多种疾病[3]。因此,及时诊断和防治番茄病害,对于保证番茄的高产有着重要意义。
近年来,图像处理和计算机视觉方法被应用到番茄叶片图像获取中[4-5],可进一步用于番茄病害的检测等。这些方法使用传统方法或深度学习方法提取叶片图像特征。李超等针对叶片病斑与织物疵点相似的特点,提出了基于窗阈值中心对称局部二值模式的方法对作物病斑进行检测[6]。师韵等针对叶片图像的非线性,提出了一种基于二维子空间学习维数约简的方法对苹果叶部病害进行识别[7]。马浚诚等使用机器学习方法,针对黄瓜霜霉病提出了一种基于条件随机场的图像分割方法来对其进行诊断,以期满足设施蔬菜叶部病害诊断的需求[8]。赵建敏等结合最大类间方差法(OSTU)与支持向量机 (SVM)算法来识别马铃薯病害,首先使用小波变换对图像进行去噪,然后使用OSTU阈值算法分割图像,最后利用SVM分类器进行识别[9]。不过,传统方法要求对数据进行符合传统方法的预处理,同时也要花费大量人力对数据集进行标注,因此依靠传统方法得到的网络鲁棒性不强,其应用有一定局限性。
随着深度学习的发展,卷积神经网络(CNN)已经成为植物病害识别的主要方法,叶中华等采用单次多边框(SSD)目标检测模型,实现了对复杂背景农作物图像病害区域的预测[10]。王林柏等提出了一种基于ResNet50为主干的特征提取网络,加入了空间金字塔池化(SPP)模块,通过提高特征提取能力来识别马铃薯的叶片病害[11]。顾兴健等设计了一种多尺度网络,使用多尺度特征提取模块、分类与桥接模块和反卷积模块,从多尺度实现对叶片病斑的分割与识别[12]。黄英来等提出一种基于ResNet-50的改进模型,对玉米叶片病害图像进行分类,取得了较好效果[13]。
综上所述,为了实现对番茄病害的高准确率、快速识别,本研究提出一种可分离扩张卷积块,以MobileNet v2模型为主体框架,使用可分离扩张卷积块替换一部分卷积块,以扩大感受野,同时保持计算量不变来提高精确度,并替换激活函数来提取负值特征。此外,使用通道剪枝技术使模型变得更轻量化,为防治番茄病害提供技术支持。
1 材料与方法
1.1 试验数据集
本研究所用试验数据取自Kaggle平台的公开数据集,由QASIM KHAN整理公开数据集 Plant Village和中国台湾的番茄叶片数据集得到。本研究所使用的数据集包含超过2万张番茄叶片图像,其中包括感染细菌性斑点病、早疫病、晚疫病、叶霉病、白粉病、斑枯病、二斑叶螨病、轮斑病、花叶病、黄化曲叶病的番茄及健康番茄叶片共11种番茄叶片类型,详见图1。
1.2 数据预处理
由于计算机处理图像的算力有瓶颈,无法只通过盲目输入大量训练图像来对深度卷积模型进行训练,因此先要对图像进行预处理来减少后续训练所需的算力。首先需要对病斑叶片图像进行增强、降噪、归一化等预处理[14-17]。大部分图片的原始尺寸是256×256 像素,但是还有部分图像大于或小于该规格,同时考虑到图像大小应与网络的输入大小匹配,因此将图像尺寸统一先进行放大后再随机裁剪为224×224 像素,最后对部分不均衡样本进行随机翻转、随机角度旋转等数据增强操作。
1.3 试验环境
本研究使用的是Windows 10 22H2计算机,中央处理器(CPU)为AMD Ryzen 5600,图形处理器(GPU)为GeForce RTX 3060(12 GB),内存为 32 GB。以Python 3.8+CUDA 11.0+Pytorch 1.8.1作为环境设置。每个模型的训练轮次为50次,以Adam作为优化器对整个网络进行评估并对参数进行优化[18]。初始学习速率为0.01,每经过10轮,学习率下降为原来的50%。
1.4 评价指标
本研究采用准确率、精确率来评价模型分类的性能指标,同时使用模型参数量、浮点计算量来评价模型的复杂度和模型的轻量化程度。
准确率的计算方法见公式(1),即所有预测正确的样本(TP+FN)占总样本(TP+FP+TN+FN)的比例。虽然准确率可以作为样本总体分类正确率的标准,但是当样本的类别不平衡时,就无法作为有效的评价指标。因此在样本类别不够均衡的情况下,高准确率的结果没有任何意义,此时准确率就会失效。
Acc= TP+FN TP+FP+TN+FN 。 (1)
精確率的计算方法见公式(2),即正确预测为正(TP)占全部预测为正(TP+FP)的比例。精确率是一个在正样本分类结果中的正确率指标,准确率则是一个在所有样本分类结果中的正确率指标。
prec= TP TP+FP 。 (2)
模型参数量是指模型所占存储空间和每次训练所占用的存储空间,如果模型太大,设备内存小,也无法在小内存设备使用大模型。
1.5 相关模型及其结构
1.5.1 MobileNet v2模型[19] MobileNet v2是谷歌团队在2018年提出的轻量级CNN,是专门为移动终端和资源受限环境量身定制的网络结构。在保持相同精度的同时,它能显著减少操作次数和内存需求。MobileNet v2在MobileNet v1的基础上提出了一些改进,在提升准确率的同时也提升了速度。该模型的最大特点就是深度可分离卷积和倒残差结构,相比之前的MobileNet v1版本,引入了深度可分离卷积,对于算力的要求大幅减少,同时网络也更加简单,可以很好地应用在移动设备上,或者任何自身算力不高的设备上。同时在MobileNet v2中引入了一个更好的模块——倒残差结构。对层之间的线性瓶颈进行试验验证,结果表明,使用线性层是至关重要的,因为它可以防止非线性破坏太多信息。
1.5.2 深度可分离卷积 MobileNet v2相较于其他轻量化网络的特点就是深度可分离卷积。深度可分离卷积的工作原理是利用拆分思想,把普通的卷积拆分成2种独立的卷积——深度卷积和点卷积。深度卷积区别于普通卷积,在进行深度卷积时通道为单通道。深度卷积能够保证图像特征深度不变,同时让卷积操作在各个通道都发生,使得最后得到特征图的通道和最初输入的一样。不过这样的操作会带来一个不好的后果,即通道数一直不变,从特征图获得的信息也不够多,获得的信息也不够有效。点卷积的设计就是为了解决这一问题。之所以取名为点卷积,是因为它是一个1×1的卷积,其作用是用来改变特征图的维度。通过深度可分离卷积来拆分普通卷积能够显著减少整个网络结构的计算深度和整体尺寸。
假定标准卷积的大小为DK×DK×M,总数有N个,因此进行1次标准卷积计算的参数量是DK×DK×M×N,如果要进行DW×DH次运算,那么就可以得到标准卷积的计算量为
DK×DK×M×N×DW×DH。 (3)
1次深度卷积加上1次点卷积构成了1次深度可分离卷积。假设深度卷积的大小是DK×DK×M,点卷积的大小是1×1×M,总数是N个,那么进行1次深度可分离卷积计算的参数量为DK×DK×M+M×N。进行1次深度可分离卷积的计算量就是进行1次深度卷积计算加上1次点卷积计算。因此,如果进行DW×DH次运算,就可以得到深度可分离卷积的计算量,详见公式(4):
DK×DK×M×DW×DH+M×N×DW×DH。 (4)
参数量下降为公式(5):
DK×DK×M+M×N DK×DK×M×N = 1 N + 1 D2K 。 (5)
计算量下降为公式(6):
DK×DK×M×DW×DH+M×N×DW×DH DK×DK×M×N×DW×DH = 1 N + 1 D2K 。 (6)
而在大部分使用过程中,采取的卷积核大小为3×3,那么带入公式(5)、公式(6)可知,进行1次深度可分离卷积的参数量和计算量约为标准卷积的1/9。
1.5.3 倒残差结构 倒残差结构就是在线性瓶颈层中加入了ResNet的残差连接,能够更好地回传梯度和特征重用。倒残差结构与传统的残差结构相反,传统的残差结构先使用1×1的卷积层进行降维,再进行3×3的卷积操作,最后使用1×1的卷积层恢复到原来的维度;倒残差结构先使用点卷积提升维度,然后通过深度卷积减小计算量,最后再利用点卷积下降至初始维度,如此一来,倒残差结构可以提高内存使用效率。深度卷积的设计无法改变通道维度,如果上一层通道维度过低,就会导致效果不佳,为了改善这个问题,在每个深度卷积之前都使用点卷积来提升维度,以增强特征的表达能力。这种结构的另一个优点是允许使用更小的输入和输出维度,可以减少相关参数量和网络运算复杂程度,从而减少运行时间,实现模型的轻量化。倒残差结构如图2所示。
1.6 基于可分离扩张卷积和通道剪枝的模型设计
1.6.1 可分离扩张卷积 尽管深度可分离卷积解决了普通卷积计算量过大的问题,但与普通卷积类似,同样具有会丢失部分信息的缺点。Lei等将扩张卷积引入到分类任务,并取得了很好的效果[20]。扩张卷积最初被应用在图像分割领域,为了解决多尺度的问题。扩张卷积的作用是在捕捉到更多全局信息的同时,不增大特征图的大小。扩张卷积就是通过在矩阵2个元素中增加0元素来扩大卷积核,它和普通卷积的不同点就是存在0元素,因为0元素不参与运算,因此可以获得更大的特征图而不增加计算量。图3表示由扩张卷积得到的感受野。图3-a为1个经过3×3的标准卷积后得到的感受野;图3-b为1个经过大小为3×3,但扩张值为1的扩张卷积后得到的感受野;图3-c为1个经过大小3×3,但扩张值为2的扩张卷积后得到的感受野。可以看出,扩张卷积能够在参数量不变的情况下,获得比普通卷积更大的感受野。
使用扩张卷积核代替普通卷积核的等效卷积核大小计算方法见公式(7):
k′=k+(k-1)×(r-1)。 (7)
式中:k′是等效卷积核大小;k是卷积核大小;r是扩张率。
RFi+1=RFi+(k′-1)×Si。 (8)
式中:RFi+1是当前层的感受野;RFi是上一层的感受野;Si是之前所有层的步长的乘积。
受Lei等的研究结果[20]的启发,本研究提出一种可分离扩张卷积块来有效捕获特征图并保留更多信息,其结构如图4所示。本研究使用扩张卷积核替代深度可分离卷积中的普通卷积核,以扩大感受野,在不增加计算量的情况下获得更大的感受野,保留更多信息。扩张卷积虽然能够在不增加计算量的情况下扩大感受野,但Wang等研究发现,过多使用相同扩张率的扩张卷积将导致信息不连续,反而丢失一部分细节信息[21]。因此,本研究应用HDC规则,使用不同的扩张率,从而在获得更广阔的信息时,防止获得的信息不相关和产生部分信息无故损失等问题。同时为了保证获取的信息足够有效,本研究将可分离扩张卷积块应用在模型的前几层,因为此时特征图的信息相对多且有效。
在进行1次标准卷积计算时,假定初始高、宽、通道数大小为h×w×c1的特征图I,I和大小是k×k×c1×c2的卷积核K采用标准卷积计算,计算得到大小是(h-k+1)×(w-k+1)×c2的特征图O,O=K×I,相关公式如下:
O(y,x,j)=∑ m i=1 ∑ s u,v=1 K(u,v,i,j)I(y+u-1,x+v-1,i)。 (9)
式中:O(y,x,j)为第j个特征图中点(y,x)的值;K(u,v,i,j) 为第j个卷积核为第i个通道上点(u,v)的值;I(y,x,i)为第i个输入通道上点(y,x)的值。
通过公式(9)可得,要进行k×k×c1次运算才能得到1个结果,要进行计算的公式为k×k×c1×(h-k+1)×(w-k+1)×c2,所有参数大小为k×k×c1×c2。
可分离扩张卷积使用扩张卷积替换标准卷积,给定与标准卷积一致的特征图I。使用扩张率为r,与标准卷积一致的卷积核K采用标准卷积计算时,得到大小为(h-k′+1)×(w-k′+1)×c2的特征图O′。
O′(y,x,j)=∑ m i=1 ∑ s u,v=1 K(u,v,i,j)I[y+u+(u-1)(r-1)-1,x+v+(v-1)(r-1)-1,i]。 (10)
由公式(10)可知,扩张卷积层的总计算量为 k×k×c1×(h-k′+1)×(w-k′+1)×c2,总参数量为k×k×c1×c2。在不进行填充的情況下,扩张率r≥2的扩张卷积与标准卷积相比,能够在参数量相同的情况下,使计算量更小,且感受野更大。进行填充时,输出的特征图大小均为h×w×c1时,扩张卷积与标准卷积的计算量和参数量相同。
1.6.2 通道剪枝 网络剪枝是神经网络模型压缩最常用的方法之一,通过删减不重要的部分,能够有效缓解过拟合问题来减少计算量、缩小网络模型[22]。网络剪枝有2种,一种是结构化剪枝,一种是非结构化剪枝,其中非结构化剪枝直接修剪参数,完全不受任何约束限制,是压缩网络大小的最佳方式之一,非常方便快捷,能够在不影响性能的同时大量修剪网络大小。而结构化剪枝是对网络的中间层进行修改,这样不仅参数量更少,更易储存,同时计算量更少,运算所需内存更少。Zhuang等提出了一种基于网络原有BN层的剪枝[23],通过裁剪每一层的通道数,达到模型压缩的目的,详见图5。
针对BN层重新训练来进行剪枝。首先对整个网络进行稀疏化训练,对于BN层进行L1正则化,就能够起到稀疏训练的作用。通过使BN层的指标接近0来进行剪枝。然后增加新指标γ,将指标对应 每个通道,然后与每个通道的输出相乘。综合得
到权重和设定的指标后,再进行稀疏正则化。最后,对于指标相对小的通道进行裁剪。公式(11)为稀疏训练中的Loss函数:
L=∑ (x,y) l[f(x,W),y]+λ∑ γ∈Γ g(γ)。 (11)
式中:(x,y)代表一组训练数据,x代表输入图像,y代表输入图像对应的类别标签;f代表训练网络中的前向传播函数;W代表网络中的可训练权重值;l代表单个样本的损失函数;λ代表用于控制稀疏正则化项的权重;γ代表通道的缩放因子;Γ代表所有通道缩放因子的集合;g代表稀疏惩罚函数,用于推动缩放因子向零靠近。
BN层的计算过程见公式(12):
= zin-μB σ2B+ε ;zout=γ+β。 (12)
式中:代表批量归一化层对zin进行归一化后输出的结果;zin批量归一化层的输入;B代表当前一组数据;μ代表均值;σ代表标准差;ε代表一个常数,防止除零错误;zout代表批量归一化层的输出,也是下一个卷积层的输入;β代表可训练的偏移因子,对应于每个卷积通道。在归一化后对输出进行线性平移。
1.6.3 激活函数 激活函数是使用更简单的数学运算来预测决定神经元对网络的输入是否重要。ReLU激活函数由于只有一定数量的神经元被激活,因此与sigmoid、tanh函数相比,ReLU函数的计算效率要高得多。同时它是线性变化的,且直接不处理负值,这样就使得梯度下降更精准地收敛到最小值。相应的副作用是会导致部分神经元保持不变,就会产生不更新和变化的死亡神经元。因此PReLU激活函数诞生了,其旨在解决轴左半部分梯度变为零的问题[24],数学形式如下:
f(yi)=max(0,yi)+aimin(0,yi)。 (13)
式中:yi为非线性函数f在第i个通道的输入;ai负责控制负半轴的斜率,当ai=0时,PReLU就变成了ReLU。
函数图像如图6所示,因此本研究在深度扩张分离卷积块中使用PReLU激活函数替换ReLU函数来提升网络对于负值特征信息的提取能力。
2 结果与分析
因为大部分文献使用的番茄病害数据集或多或少有差异,因而在本试验中,为了保持统一,各个模型都使用本研究中的数据集。本 研究展示的结果
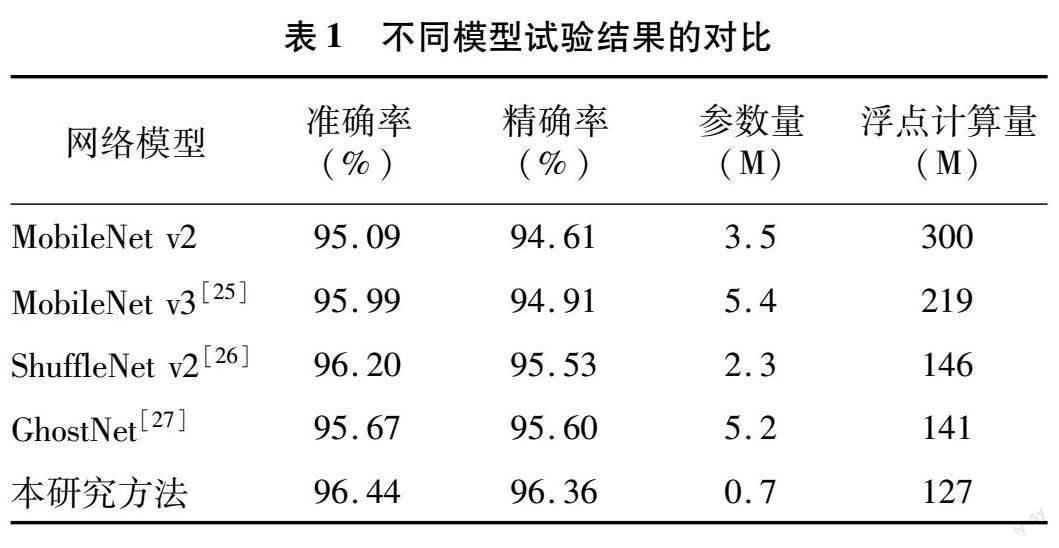
都是基于本研究数据集训练的模型产生的。表1展示了测试集上各模型的整体性能,可以看出,本研究使用的基于可分离扩张卷积和通道剪枝的模型获得了比原始MobileNet v2更高的准确率和精确率。本研究提出的改进模型准确率、精确率分别达到了96.44%、96.36%,相比原模型分别提高了1.35、1.75百分点。
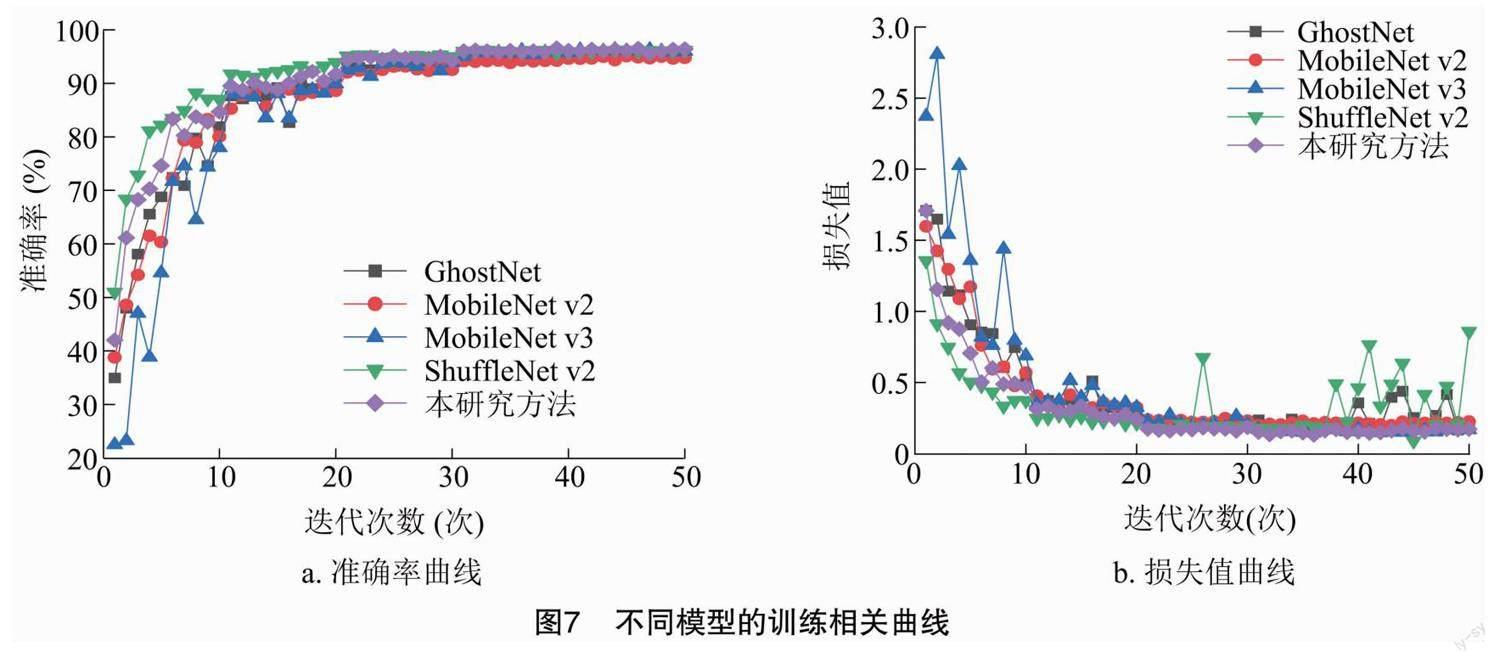
为了证明本研究改进算法的可行性和优越性,将其与目前的轻量级模型进行对比,使用番茄病害数据集进行训练。在训练过程中,在每个训练轮次之后记录训练数据集、验证数据集上的识别准确率和损失值,这样可以观察训练情况,保证每个模型在收敛条件下完成训练。将每个模型在验证数据集上的训练结果绘制为曲线(图7)。由于生成的曲线图有噪声,因此需要对曲线进行平滑处理,以减少噪声的干扰,这样能够使每个模型的识别效果更直观。
用本研究提出的可分离扩张卷积块替换模型原有的卷积,由表2可知,在不影响模型大小的情况下,准确率提升了1.15百分点,将激活函数替换为PReLU后,准确率提升了1.04百分点,这是因为植物病害往往表现为颜色、纹理、形状等复合特征,可分离扩张卷积块提取到了更多信息,进而提取了多种病害特征,增强了网络病害识别能力。
根据本研究模型的分类结果计算出的混淆矩 阵进行误差分析,结果如图8所示。其中混淆矩阵的横坐标代表真实值,纵坐标代表预测值,细菌性斑点病的实际测试样本有731个,正确分类样本有704个,其余样本被错误分类为早疫病、健康、晚疫病、叶霉病、二斑叶螨病、轮斑病和黄化曲叶病。细菌性斑点病的分类准确率为96.40%,同理可知,其他类型病害的分类准确率分别为95.01%、96.28%、97.12%、94.32%、98.62%、98.89%、99.59%、98.78%、98.02%、89.66%。可以注意到,由于细菌性斑点病、叶霉病的病理特征较类似,因此分类错误率相对较高。本研究方法对于识别番茄病害的准确率较高,能够在现实中很好地应用于快速病害检测。
3 结论
针对番茄病害泛滥、受灾损失大的问题,本研究提出了基于可分离扩张卷积和通道剪枝的番茄病害分类模型,在卷积结构和激活函数上对原模型进行了改进,同时使用剪枝技术对模型进行压缩。通过对比试验可知,在同等条件下,本研究方法比原模型在准确率上提升了1.75百分点,且模型参数量减少了80%,浮点计算量减少了58%。在更轻量的情况下,对番茄病害的分类效果更好。
参考文献:
[1] 翟肇裕,曹益飛,徐焕良,等. 农作物病虫害识别关键技术研究综述[J]. 农业机械学报,2021,52(7):1-18.
[2]谭海文,吴永琼,秦 莉,等. 我国番茄侵染性病害种类变迁及其发生概况[J]. 中国蔬菜,2019(1):80-84.
[3]Singh V K,Singh A K,Kumar A. Disease management of tomato through PGPB:current trends and future perspective[J]. 3 Biotech,2017,7(7):1-10.
[4]Luna R,Dadios E P, Bandala A A . Automated image capturing system for deep learning-based tomato plant leaf disease detection and recognition[C]//TENCON 2018-2018 IEEE Region 10 Conference. Jeju,South Korea. IEEE,2018:1414-1419.
[5]Zhang Y,Song C L,Zhang D W. Deep learning-based object detection improvement for tomato disease[J]. IEEE Access,2020,8:56607-56614.
[6]李 超,彭进业,孔韦韦,等. 基于局部二值模式的作物叶部病斑检测[J]. 计算机工程与应用,2017,53(24):233-237.
[7]师 韵,黄文准,张善文. 基于二维子空间的苹果病害识别方法[J]. 计算机工程与应用,2017,53(22):180-184.
[8]马浚诚,温皓杰,李鑫星,等. 基于图像处理的温室黄瓜霜霉病诊断系统[J]. 农业机械学报,2017,48(2):195-202.
[9]赵建敏,薛晓波,李 琦. 基于机器视觉的马铃薯病害识别系统[J]. 江苏农业科学,2017,45(2):198-202.
[10] 叶中华,赵明霞,贾 璐. 复杂背景农作物病害图像识别研究[J]. 农业机械学报,2021,52(增刊1):118-124,147.
[11] 王林柏,张 博,姚竟发,等. 基于卷积神经网络马铃薯叶片病害识别和病斑检测[J]. 中国农机化学报,2021,42(11):122-129.
[12]顾兴健,朱剑峰,任守纲,等. 多尺度U网络实现番茄叶部病斑分割与识别[J]. 计算机科学,2021,48(增刊2):360-366,381.
[13]黄英来,艾 昕. 改进残差网络在玉米叶片病害图像的分类研究[J]. 计算机工程与应用,2021,57(23):178-184.
[14]Saleem M H,Potgieter J,Arif K M. Plant disease detection and classification by deep learning[J]. Plants,2019,8(11):468.
[15]Dhiman P,Kukreja V,Manoharan P,et al. A novel deep learning model for detection of severity level of the disease incitrus fruits[J]. Electronics,2022,11(3):495.
[16]Guan X. A novel method of plant leaf disease detection based on deep learning and convolutional neural network[C]//2021 6th international conference on intelligent computing and signal processing. Xian,China:IEEE,2021:816-819.
[17]Loti N N A,Noor M R M,Chang S W. Integrated analysis of machine learning and deep learning in chili pest and disease identification[J]. Journal of the Science of Food and Agriculture,2020,101(9):3582-3594.
[18]Zhang Z. Improved Adam optimizer for deep neural networks[C]//2018 IEEE/ACM 26th international symposium on quality of service. Canada:ACM,2018:1-2.
[19]Sandler M,Howard A,Zhu M,et al. Mobilenet v2:inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF conference on computer vision and pattern recognition. Salt Lake City,USA:IEEE,2018:4510-4520.
[20]Lei X Y,Pan H G,Huang X D. A dilated CNN model for image classification[J]. IEEE Access,2019,7:124087-124095.
[21]Wang P,Chen P,Yuan Y,et al. Understanding convolution for semantic segmentation[C]//2018 IEEE winter conference on applications of computer vision. Nevada,USA:IEEE,2018:1451-1460.
[22]姜曉勇,李忠义,黄朗月,等. 神经网络剪枝技术研究综述[J]. 应用科学学报,2022,40(5):838-849.
[23]Zhuang L,Li J G,Shen Z Q,et al. Learning efficient convolutional networks through network slimming[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice,Italy,2017:2736-2744.
[24]He K M,Zhang X Y,Ren S Q,et al. Delving deep into rectifiers:surpassing human-level performance on imagenet classification[J]. IEEE Computer Society,2015:1026-1034.
[25]Howard A,Sandler M,Chen B,et al. Searching for Mobilenet v3[C]//2019 IEEE/CVF International conference on computer vision. South Korea:IEEE,2020:1314-1324.
[26]Ma N,Zhang X,Zheng H T,et al. Shufflenet v2:practical guidelines for efficient cnn architecture design[C]//Proceedings of the European conference on computer vision. Munich,Germany:IEEE,2018:116-131.
[27]Han K,Wang Y,Tian Q,et al. Ghostnet:more features from cheap operations[C]//2020 IEEE/CVF conference on computer vision and pattern recognition. Seattle,USA:IEEE,2020:1580-1589.
收 稿日期:2023-03-06
基金项目:国家自然科学基金(编号:62162002);江西省主要学科学术和技术带头人领军人才项目(编号:20225BCJ22004)。
作者简介:姜晟久(2000—),男,湖南新化人,硕士研究生,研究方向为计算机视觉及其应用。E-mail:2021110251@ecut.edu.cn。
通信作者:钟国韵,博士,教授,硕士生导师,研究方向为计算机视觉、图像音视频处理。E-mail:gyzhong@ecut.edu.cn。
