
基于Transformer 的文物图像修复方法
2024-03-23 08:04王真言蒋胜丞宋奇鸿毕秀丽
计算机研究与发展 2024年3期
王真言 蒋胜丞 宋奇鸿 刘 波 毕秀丽 肖 斌
(图像认知重庆市重点实验室(重庆邮电大学) 重庆 400065)
文物是国家的瑰宝,其蕴含着一个民族独有的精神价值、思维方式和想象力,具有极高的历史、艺术与科学研究价值.由于材质的特殊性,文物极易受到潮湿发霉、虫蛀鼠咬、人为破坏等威胁.纸张的自然老化也会产生破洞、碎裂、褪色等问题.如果不及时修复,文物的价值就会下降.传统破损文物修复技术经过数代人继承和发展已经逐渐成熟,但现有修复技术都会对文物本身造成一定的损害.此外,传统文物修复行业还面临供需不平衡、人才紧缺、技能门槛高等一系列问题.因此,国内外博物馆都倾向使用数字图像修复技术对文物进行虚拟化修复,该技术已成为当前的研究热点[1-4].
目前主要的文物图像修复技术都是基于传统的图像处理算法.例如:陈永等人[5]针对敦煌壁画裂纹修复问题提出了一种改进曲率驱动扩散的修复算法;Criminisi 等人[6]提出的基于块匹配的方法,以及Barnes等人[7]提出的基于随机采样的块匹配方法PatchMatch,在文物修复领域也有很广泛的应用[8-9].这类方法的主要思想是通过迭代地执行待修复样本块相似度计算、最佳匹配样本块搜索、待修复样本块填充3 个步骤来完成修复任务.但是这类方法把图像的局部特征作为修复的主要依据,忽视了上下文的特征信息.
深度学习技术通过对大规模数据进行自监督训练,并使用学习到的高维特征映射修复缺失区域,能结合语义信息来恢复图像,具有较强的生成泛化能力.目前,使用深度学习技术进行文物图像修复成为一种趋势.例如,2022 年Yu 等人[10]使用现代计算机视觉和机器学习技术对敦煌文化遗产进行修复.但是,大多数方法都使用自然图像修复中常见的卷积神经网络(convolutional neural network, CNN).同时,网络框架也大多采用编解码器的结构.这类方法能够结合上下文语义信息进行修复.但是,由于卷积操作的局部相关性和平移不变性,网络难以利用图像的全局结构.因此,重复的纹理和伪影经常出现在被修复的区域中.近年来, Transformer[11]在计算机视觉领域取得了极其优异的成绩.与CNN 相比,它克服了卷积的局部相关性,通过自注意力模块来获取图像的全局信息,其应用在文物图像修复任务中可更好地恢复出图像的完整结构.同时,使用多头注意力机制可以实现修复结果的多元化输出.但是,Transformer也存在着计算量过大的问题.
值得注意的是,自然图像修复与文物图像修复存在一定的区别,如图1 所示.从破损结构而言,自然图像的破损大多具有固定的结构,而文物图像的破损多是不规则且连续的.虽然有针对不规则破损图像补全的方法,并已实现了良好的补全效果,但并没有运用到图像修复领域中;从破损面积而言,自然图像破损面积更大且破损区域往往并不连续,而文物图像的破损面积都较小;从纹理复杂程度而言,文物图像的纹理比自然图像更加复杂.同时,基于深度学习的方法大多以数据驱动,但目前国内外并没有高质量的大型文物数据集,导致网络模型无法学习到足够的文物图像特征.因此,从自然图像修复领域直接迁移的模型并不能很好地实现对文物图像的修复.

图1 破损图像对比Fig.1 Comparison of damaged images
综上所述,针对文物图像修复任务,本文结合文物图像的特点和艺术家工作时“先结构后细节”的工作流程提出了一种基于Transformer 的文物图像修复方法,将文物图像修复工作分为2 个步骤:第1 步使用Transformer 进行多元化结构修复;第2 步使用卷积神经网络进行上采样并恢复缺失区域的纹理,方法流程图如图2 所示.实验结果表明,在符合现实场景的破损文物修复实验和文物大面积破损修复实验中,本文方法的修复结果视觉效果更好,客观指标也高于代表性方法.同时,支持多元化输出,为修复人员提供了多样化的参考,在文物修复领域具有较高的价值.

图2 基于Transformer 的文物图像修复方法Fig.2 Transformer-based image restoration method for cultural relics
1 相关工作
本节主要介绍图像修复领域的相关工作及其在文物修复领域的应用,并讨论这些方法的优缺点.图像修复方法可以分为传统方法和基于深度学习的方法.
1.1 传统的图像修复方法
传统的图像修复方法主要包括基于扩散的修复方法和基于样本块匹配的修复方法.目前主要的文物图像修复都是基于这2 类修复技术.
基于扩散的修复方法通过设计的扩散函数将相邻区域的像素块传递到缺失区域内[12-14].陈永等人[5]针对壁画裂纹修复问题提出了改进曲率驱动扩散的敦煌壁画修复算法,使曲率扩散的扩散项更合理.
基于样本块匹配的修复方法是从同一幅图像的相似区域选择关联度高的样本块并填充到缺失区域[6,15-16].其中,2004 年提出的PatchMatch[6]通过使用快速最近邻算法可以很好地完成图像修复任务.然而实现这种方法的前提是能够在图像的已知区域找到缺失区域的相似纹理,但并不是所有待修复图像都能满足这样的条件.在文物图像修复领域,2019 年Yao[9]在修复唐卡图像的过程中,在Criminisi 算法的基础上引入结构信息对匹配策略进行优化,尽可能避免了错误匹配的问题.2019 年Wang 等人[17]针对敦煌壁画修复问题提出了结合多个候选区的稀疏模型来保证纹理的相似性和结构的连续性.
基于扩散的修复方法和基于样本块匹配的修复方法主要依赖单张图像的局部特征,很难恢复出符合上下文特性的缺失区域.
1.2 基于深度学习的修复方法
深度学习技术通过对大规模数据进行自监督训练,并使用学习到的高维特征映射修复缺失区域,相较于传统方法其能够学习到更高维度的特征[18],并且能够在缺失的区域生成连贯的结构.基于CNN 的方法占主导地位,可以分为基于编解码结构的单阶段修复模型和提供先验信息的修复模型.
最先使用基于编解码结构的单阶段修复模型是2016 年提出的Context Encoder[19],编码器映射图像缺失区域到低维特征空间,解码器用来构造输出图像.然而,输出图像的恢复区域通常包含视觉伪影且模糊.2018 年Liu 等人[20]为解决普通卷积特征提取不足的问题创造了“部分卷积”,把传统卷积层替换为部分卷积层,将编码器层的深层和浅层特征作为CNN的输入,使得修复后的图像纹理更加一致.2021 年,Zeng 等人[21]提出一种使用可学习的损失函数替代注意力机制的2 阶段模型.基于上下文重建损失,无注意力机制的生成器也能学习到从已知区域匹配特征进行修复的能力.在文物图像修复领域,2021 年Zhang等人[22]针对古代石刻碑文保护的问题提出了一种基于多尺度特征融合的石刻图像去噪与修复方法.
提供先验信息的修复方法[23-24]在单阶段方法的基础上加入了先验信息,因此效果更好.2018 年Contextual Attention[25]采用的策略为:第1 阶段使用简单的膨胀卷积网络粗略地恢复缺失内容;第2 阶段的细化网络使用上下文注意力机制来优化结果.2018 年Shift-Net[26]受样本块匹配思想的启发,在UNet 模型的基础上增加了Shift 连接层,可以计算每个缺失区域样本块与已知区域的相似度系数,并在编码器特征上引入了引导损失,提升了修复的精度.2020年Zeng 等人[27]利用深度卷积神经网络对破损图像进行粗略修复,然后利用最近邻像素匹配进行可控制的再次修复,使得修复的图像更具真实感.2021 年Qin 等人[28]提出了基于多尺度注意力网络的修复模型,通过引入多尺度注意力组来提高修复后图像的真实性.在文物图像修复领域,2019 年曹建芳等人[29]针对古代壁画起甲、脱落等问题提出一种基于增强一致性生成对抗网络的图像修复算法,提高了壁画修补区域与全局的一致性.
将文献[23-29]所述的方法直接应用到文物图像修复领域虽然能够修复大面积破损的图像,但由于文物的破损往往存在细节丢失、特征不足等问题[5,30],难以恢复连贯结构[28-29].同时卷积的局部连接和平移不变性导致其对图像的全局结构很难把握,也容易产生重复的纹理.随着深度学习理论的发展,Transformer 在计算机视觉领域内的广泛应用,一些初步的工作[31-33]也证明了它在自然图像合成方面有非常强的能力.如2021 年ICT(image completion transformer)[33]采用Transformer 的输出作为结构先验以实现高保真度的图像补全.此外,Transformer 中的多头注意力机制可以实现结果的多样化输出.但是,由于自注意力机制每次都要计算所有块之间的注意力,计算复杂度为输入长度的平方,因此处理高分辨率图像较为困难[34].
2 文物图像修复方法
本文受到提供先验信息的深度学习方法的启发,为避免卷积操作难以恢复全局结构的缺点,先采用Transformer 模型来恢复整体的结构信息,再通过一个具有上采样功能的修复网络进行纹理修复,使得修复后的文物图像整体结构连贯,同时避免出现伪影、模糊等现象,并且使修复结果更加逼近原始图像.文物图像修复的目的是将有缺失像素的输入图像ID=I⊙(1-M)通过预测转化成完整图像IC.因此,本文方法将文物图像修复任务分成多元化结构修复和上采样纹理修复2 个阶段,网络结构分别如图3、图4 所示.第1 阶段中,Transformer 模型将输入图像ID变换为具有连贯结构的中间修复结果IR,此过程可表示为p(IR|ID).第2 阶段中,IR通过CNN 模型学习到IC的特征映射,将IR进行上采样的同时修复精细纹理,并在特征层次进行融合得到输出图像IC,实现对文物图像的修复,此过程可表示为p(IC|IR,ID).综上,整个修复过程可表述为
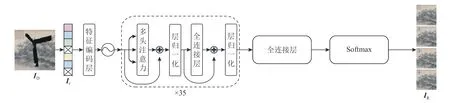
图3 多元化结构修复网络结构图Fig.3 Diversified structure repair network structure diagram
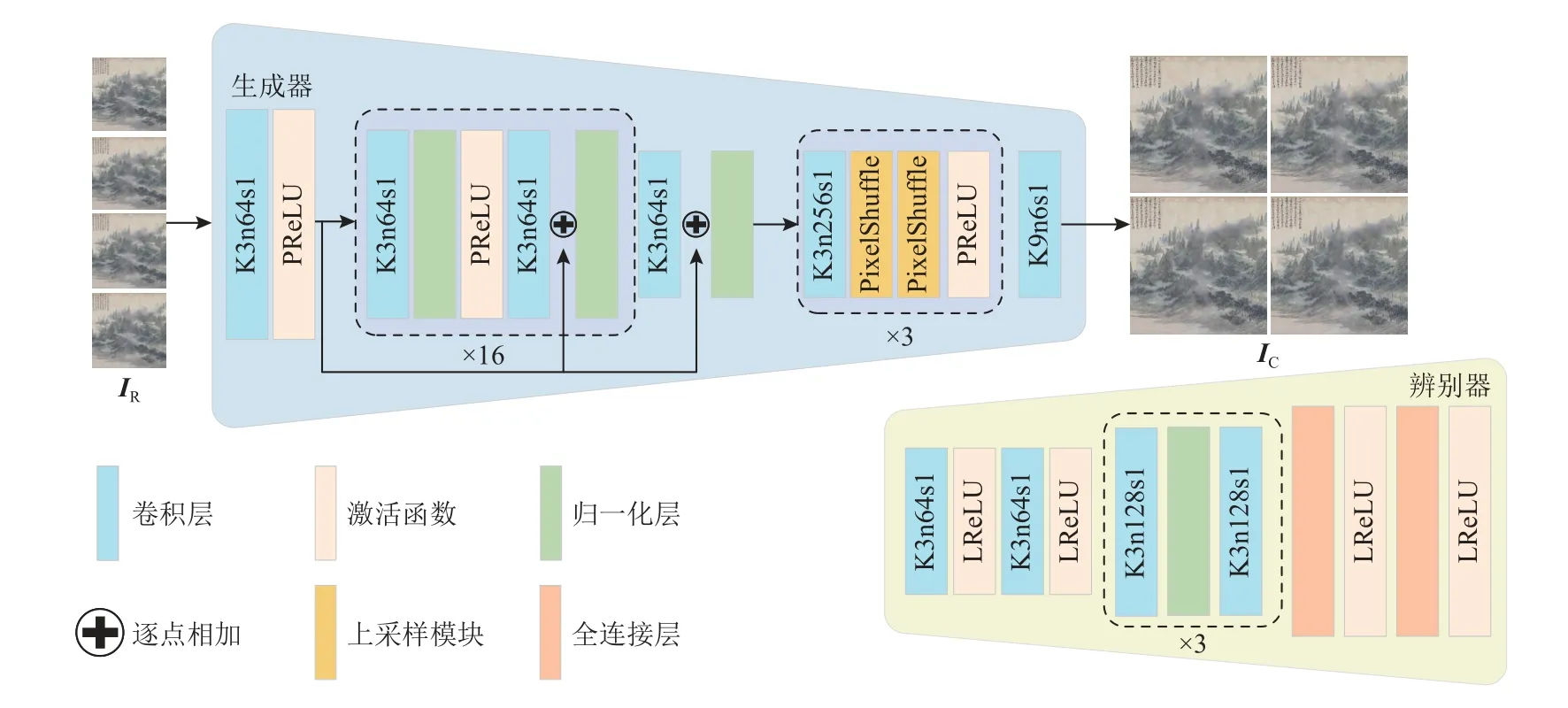
图4 上采样纹理修复网络结构图Fig.4 Upsamping texture repair network structure diagram
2.1 多元化结构修复网络
Transformer 摒弃了CNN 的局部相关性和平移不变性,通过多个自注意力模块来获取图像的全局信息[11],其应用在文物图像修复任务中可更好地恢复出图像的完整结构.
本文使用的Transformer 模块结构如图3 所示,与GPT-2 模型[35]的做法相同,仅使用Transformer 的解码器,其计算过程可表述为
其中LN,MSA,MLP分别代表层归一化、多头自注意力模块、全连接层.其中,MSA可表示为
其中n代表注意力头的个数;Q,K,V代表3 个可学习的映射矩阵;dK为K的特征维度;MLPO是一个连接不同自注意力模块的全连接层.
由于GPT 模型是通过单向注意力预测缺失区域的元素,仅能关注到前序序列的信息.为了使每个样本块都能关注到所有位置的信息,本文采用与BERT[36]类似的遮蔽语言模型(mask language model, MLM)来优化Transformer 模型,确保生成像素可以捕获所有可用的上下文信息,从而使生成内容与已知区域相一致.具体来说,让Π =(π1,π2,...,πm)表示离散化输入中标记为掩膜的索引,其中m是被屏蔽的标记数量.MLM 的目标是使所有观察区域条件下XΠ的负对数似然最小,用公式表示为
其中 θ代表Transformer 模型所学习到的参数.MLM和双向注意力机制相结合,确保了网络可以利用所有位置的信息来预测缺失区域的内容.
在输入到Transformer 之前,图像首先被编码成为一个离散化的序列,表示为Ir=(i1,i2,…,ilen),其中len代表Ir的长度.为了对图像的空间信息进行编码,将一个可学习位置的特征选择器添加到每个位置的标记特征中,然后再将这个离散化序列通过预学习编码映射到一个高维的特征向量中,最后再组成Transformer 模型的输入.考虑到Transformer 的计算复杂度与输入长度的平方成正比,且多头注意力机制[11]的计算复杂度与输入长度的4 次方成正比,如果采用正常的RGB 像素表达矩阵,那么计算量将过于巨大.为了降低计算成本,采用与ICT 相似的做法,使用原始文物图像对应的低分辨率版本来表示其连贯结构的先验,即使用大小为32×32 的块来表示原始图像的结构信息和粗略的纹理.为了进一步降低维度,本文还使用K-Means 聚类算法在文物图像数据集上构造大小为512×3 的RGB 像素词表.可以通过搜索这个词表来重建每个连贯结构的先验信息.
2.2 上采样纹理修复网络
由于Transformer 中多头注意力机制的存在使IR可以很容易地输出多种合理的结果,针对每一种结果,在重建低维结构先验信息之后,本文方法还学习了一个确定的映射将低维图像IR放大为输入图像的大小,并且没有改变空洞区域和非掩码区域的边缘结构信息.为了尽可能恢复图像的纹理细节和高频信息,本文使用了传统CNN 卷积及残差结构,并使用联合感知损失函数对细节修复的结果进行约束,在上采样的过程中尽可能恢复高频细节.
在上采样纹理修复网络中,双层残差结构在保证输入先验结构信息不被篡改的同时,使修复结果更加符合上下文语义信息.然后利用PixelShuffle 像素重组技术对图像进行上采样,在不损失清晰度与真实细节信息的前提下对图像进行超分辨.
为达到这个目的,本文方法的第2 阶段训练了前馈式CNN 的生成网络Gθ,网络结构如图4 所示.其中生成器网络的训练过程可以表示为
其中联合损失函数lSP是若干损失函数的加权组合以模拟恢复图像的不同特征.θG={W1:L;b1:L}代表第N层网络通过联合损失函数lSP优化后的权重和偏置.为恢复更加逼真的纹理细节,在网络训练阶段将生成器参数和辨别器参数进行交替优化,优化表达式为:
其中IH为高分辨率图像,IL为低分辨率图像.
2.3 联合感知损失函数
为了更好地完成基于结构先验的修复任务,本文在Ledig 等人[37]的基础上设计改进了更适用于文物图像修复任务的联合感知损失函数,其表达式为
联合感知损失函数由3 部分组成:内容感知损失lcontext、生成对抗损失ladv、全变分损失lTV.无论是在像素层面还是感知层面都能很好地提升修复图像的质量.
2.3.1 内容损失函数
内容损失lcontext主要分为2 部分,即像素层面的均方差损失和特征层面上提出VGG 损失.像素层面的均方差损失的表达式为:
其中R,W,H分别表示图像缩放系数、图像宽度、图像高度.这是图像修复领域运用最广泛的损失函数.然而实验结果表明虽然修复结果具有较高的峰值信噪比(peak signal noise rating, PSNR)指标,但使用其进行优化往往会导致修复结果缺乏高频细节,丧失图像原本的真实性.因此前人在特征层面提出VGG损失为:
其中VGG/i,j中的i,j代表本文所选用的卷积层,φi,j为第i个池化层前的第j个卷积层,Wi,j和Hi,j表示VGG 网络中特征图的宽度与高度.这种方法得到的PSNR 较高,纹理也相对真实.
2.3.2 对抗损失函数
本文方法在训练阶段还额外添加了一个对抗损失来产生更加真实的纹理:
其中D是参数为 ω的辨别器.交替共同训练生成器网络F和辨别器D来求解优化问题:
其中lℓ1为L1损失函数, α1=1.0, α2=0.1.
2.3.3 全变分损失函数
使用2.3.2 节的损失函数能够产生较好的修复结果,但在文物图像破损区域仍然存在部分失真与不平滑的区域.因此,本文引入了全变分损失函数lTV[38],使修复图像和掩膜的边缘更加平滑.其表达式为:
其中u为支持域, β=2.0.
3 实验结果与分析
为了讨论和验证本文提出的修复方法,并将其与已有的修复方法进行对比和分析,本节将从5 个角度进行实验.首先,对比各方法在现实场景下的破损修复效果;然后对比各方法对大面积破损的修复效果、验证本文方法在不同数据集上的修复效果、验证本文方法在自然图像上的修复效果;最后讨论多元化文物图像修复的优点.
3.1 实验数据库
目前文物图像修复领域并没有高质量的大型公开数据集,而大多数基于深度学习的方法均以数据为驱动,如果训练集过小则会导致网络性能不佳、修复效果不理想等问题.为解决文物图像数据库过小的问题,本文对中国台北故宫博物馆官网提供的5 000张分辨率为3 000×4 000 的文物图像进行处理,最终得到的88 000 张分辨率为256×256 的文物图像作为本次实验的基础数据集.具体处理过程为:首先将5 000张分辨率为3 000×4 000 的图像进行人工筛选,剔除颜色过于单一、无关内容太多的图像;然后通过随机剪裁分成分辨率为256×256 的图像;再进行一次人工筛选,最终构成包含山水画、人物画像、壁画、花鸟画4 类共计80 000 张的大型文物图像数据集.此外,为了降低数据集原始样本的影响,本文在训练样本中随机抽取8 000 张图像进行数据增广,详细的数据集划分与增广操作如表1 所示.
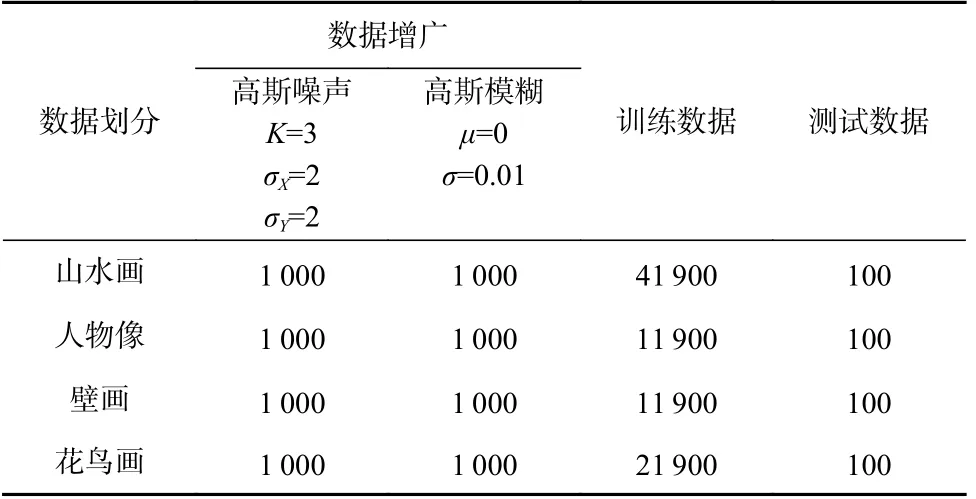
Table 1 Statistics for Using Datasets表1 使用数据集的统计信息
3.2 评价指标
在图像修复领域,目前最常用的评估指标有峰值信噪比和结构相似性(structural similarity index measure,SSIM).近年来,为更深层次地评价修复图像的质量,常使用学习感知图像块相似性[39](learned perceptual image patch similarity, LPIPS)来作为评估指标.
3.3 实验细节
本文实验的硬件环境为Intel®Xeon®Platinum 8255C 和2 块Tesla V100.实验平台的软件环境为Pytorch 1.8.0,CUDA 11.1.1.训练过程中采用Adam 优化器对参数进行优化,学习率为1×10-4,1 阶动量为0.5,2 阶动量为0.1.
3.4 实验对比与分析
本节在符合现实场景破损和大面积破损2 种情况下,与基于块匹配的传统方法代表PM[6]、结合先验信息的深度学习方法代表Shift-Net[26]、双阶段修复模型CRF[21]和EC[23]、使用不同类型卷积的单阶段深度学习方法代表PC[20]、基于Transformer 和CNN 的双阶段修复方法代表ICT[33]和EC[33]进行对比,以验证本文方法的有效性.
3.4.1 符合现实场景破损的修复实验
本节将对比各种方法在符合现实场景的皲裂山水画的修复效果.结合现实中文物破损面积小、破损不规则、破损区域连续等特点,本文专门设计了大小在10%~15%且破损区域连续、大小依次递增的5 张掩膜,表示为Ms-1~5.本节实验均采用这5 张特定的掩膜.同时,由于山水画更加强调结构的连贯性与纹理的细腻性,修复难度更高,因此实验在本节与3.4.2节均在山水画中进行对比.
图5 展示了各方法的修复结果.由图5(c)可见,PM 整体表现优异,但修复区域缺乏上下文的语义信息.在已知区域无法提供足够多的先验信息时尤为明显.由图5(d)(e)所示,PC 和Shift-Net 的修复结果在连贯结构的恢复上并不合理,存在重复的纹理和伪影.由图5(f)(g)所示,EC,CRF 的修复结果较为优秀,但在某些特定掩膜下会出现严重的伪影.相对这些方法,本文的2 阶段修复模型的图像处理效果均比较理想,阶段性的修复过程更加适用于文物图像修复任务.图5(h)的ICT 与本文方法的修复质量相对较高,由此可见,基于Transformer 的修复方法可以给模型提供更好的先验信息.但ICT 未将上采样和修复过程结合,导致其在上采样过程中丢失的关键像素无法被修复,部分区域仍存在颜色失调的现象.而本文方法先使用Transformer 进行结构先验,再结合图像超分辨的思想,把上采样和修复的过程结合起来,增强了网络上采样的能力,使网络在上采样的过程中能保留更多的关键信息.同时在联合损失函数的约束下,文物图像修复的质量得到极大提升,修复结果语义连贯、伪影和重复的纹理较少,取得了较好的指标和视觉效果.

图5 不同算法对现实破损场景的修复结果对比Fig.5 Comparison of repair results of different algorithms for realistic damaged scenes
各种方法的修复指标如表2 所示,本文方法在PSNR,SSIM 上表现均为最优.相较于PM,PC,Shift-Net,EC,CRF,ICT 这6 种方法,SSIM 指标分别提升了13.2 个百分点、11.7 个百分点、11.9 个百分点、1.3个百分点、2.7 个百分点、0.8 个百分点;PSNR 指标分别提升了14.4 个百分点、14.5 个百分点、22.3 个百分点、9.7 个百分点、6.0 个百分点、11.5 个百分点.随着掩膜逐渐增大,PSNR,SSIM 这2 项指标均有所下降,但本文方法相较于其他方法下降趋势更加平稳.
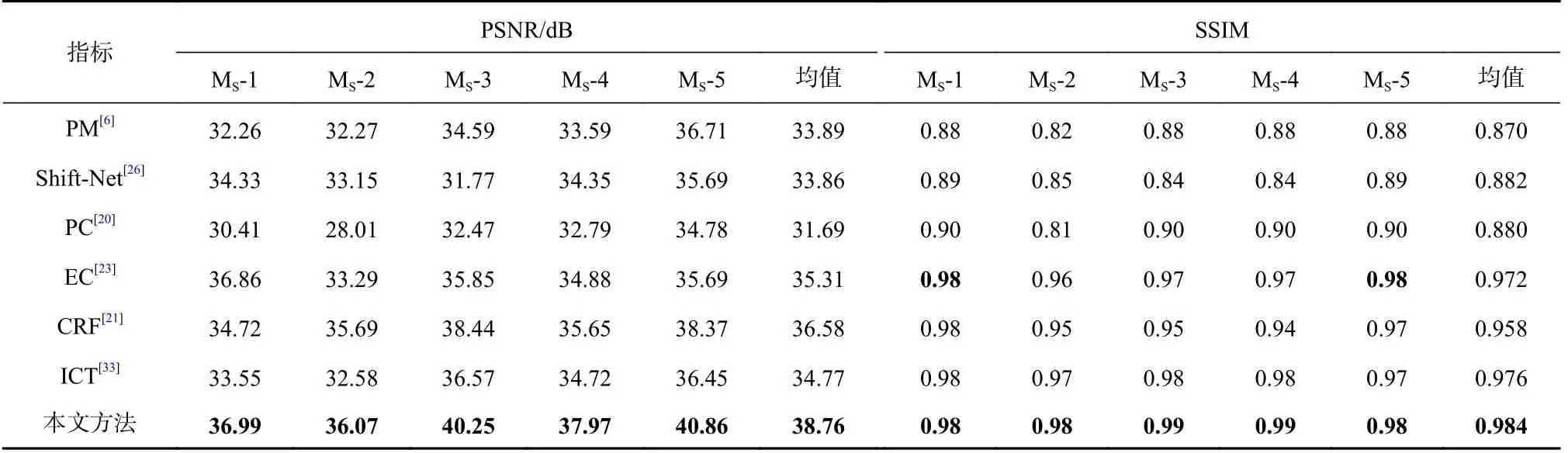
Table 2 Results of Our Method and Other Methods for Repairing Real-Life Damaged Scenes表2 本文方法与其他方法针对现实破损场景修复的结果
3.4.2 针对大面积破损的修复实验
3.4.1 节实验中使用的是特定的掩膜.为进一步验证本文方法对大面积破损文物修复的有效性,本节使用3 张20%~25%的随机掩膜进行测试,表示为ML-1~3.
各种方法的修复结果如表3 所示.可以看出,PM,PC,Shift-Net 这三者的指标相较于3.4.1 节实验中的值出现了比较明显的下降,而基于Transformer 的2种修复方法在面对大小不同的掩膜时,指标下降的趋势相对平稳,由此可以验证基于Transformer 的模型的泛化性、鲁棒性更好.本文方法相较于PM,PC,Shift-Net,EC,CRF,ICT 这6 种方法,SSIM 指标分别提升了27.8 个百分点、30.9 个百分点、30.9 个百分点、3.2 个百分点、2.0 个百分点、1.0 个百分点;PSNR 指标分别提升了21.1 个百分点、20.7 个百分点、32.6 个百分点、17.8 个百分点、15 个百分点、11.6 个百分点.由表4 左侧可以看出,在破损区域较为集中时,得益于Transformer 模型提供的先验信息和上采样修复模型的约束,本文方法可以很好地恢复文物图像的底色和山的轮廓,局部纹理也清晰可见,伪影较少.由表4 右侧中可以看出,在破损区域较为随机时,本文方法恢复的结构很好地把握了全局的信息,局部纹理也非常逼真.

Table 3 Results of Our Method and Other Methods for Repairing Large Areas of Damage表3 本文方法与其他方法针对大面积破损修复的结果
表3 和表4 表明本文方法对大面积破损文物的结构恢复能力突出,纹理、颜色的恢复也较为合理,具有很好的修复效果.
在实验过程中发现,少部分指标较高的图片却存在修复区域模糊的现象,而符合人类视觉感知的修复结果其指标反而更低,如图6 所示.

图6 异常指标对比图Fig.6 Comparison chart of abnormal indicators
本文认为利用单一损失函数约束的回归模型在PSNR,SSIM 两个指标上能得到提升,但其修复结果并不是人类视觉感知上最好的结果.并且损失函数的部分约束计算和PSNR,SSIM 这2 个指标计算类似,因此会影响网络的训练环节,导致部分文物图像修复结果出现轻微模糊、但其图像指标颇高的现象.为进一步验证本文方法的有效性,本文引入更深层次衡量修复图像质量的指标LPIPS[39].初步实验结果证明,LPIPS 指标更符合人类的视觉感知,其值越低表示2 张图像越相似,结果如图7 所示.本文方法相较于基于深度学习的Shift-Net,PC,EC,CRF,ICT 这5 种方法,LPIPS 指标分别下降了41.1 个百分点、70.7 个百分点、27.1 个百分点、1.8 个百分点、17.2 个百分点.

图7 不同掩膜的LPIPS 值对比Fig.7 Comparison of LPIPS values of different masks
综上所述,本文方法在PSNR,SSIM,LPIPS 这3种指标上表现均优于其他具有代表性的方法.
3.4.3 数据库中其他类型图片的修复实验
本节将验证本文方法在人物画像、壁画、花鸟画中的修复效果.人物画像、壁画、花鸟画绘画技法都以线为主勾勒表现绘画对象,对整体结构的连贯性要求比较小,颜色的层次更少,纹理相较于山水画更简单.因此本节实验中分别使用数据集中的人物画像、壁画、花鸟画进行训练,实验细节与3.4.1 节、3.4.2 节完全一致.表5 中,对于花卉修复结果,无论掩膜区域相对集中还是随机,本文方法都能恢复出连贯的结构和合理的颜色;人物画像修复结果主要结构相对集中,在主体结构缺失的情况下,本文方法恢复的结果语义相对连贯,轮廓、细节都能得到很好的恢复;壁画的结构相对简单,颜色相对单一,本文方法恢复的结果伪迹较少,具有良好的视觉效果;但由于根据类别划分的数据集样本较少,以及Transformer 多元化输出的特点,本文方法在修复大面积破损图像时会出现轻微失真的情况.对于此现象带来的优缺点,本文将在3.6 节中对多元化修复作进一步阐述.
以上结果表明在对不同类别文物图像的修复中,本文方法在主观和客观指标上都具有较好的修复效果.
3.5 常规图像修复
由于目前大多数基于深度学习的图像修复方法针对的都是常规图像,因此本文也验证了所提方法对自然图像的修复效果.由表6 可见,针对缺失面积较大的图像,本文方法恢复的图像结构连贯,与原图相对一致,轮廓清晰,局部纹理逼真.针对缺失面积较小的图像,本文方法恢复的图像结构连贯且符合上下文语义信息.

Table 6 Conventional Image Restoration Renderings表6 常规图像修复效果图
3.6 多元化修复
文物修复往往需要将修复人员的主观认知和原始参照物结合起来.但在实际的文物修复任务中,存在无对照样本的情况,导致修复结果无法验证合理性.针对此问题,本文方法通过多头注意力机制实现多样化输出.多元化的修复结果如表7、表8 所示.值得注意的是,本文方法虽然在进行大面积修复时偶尔会出现轻微失真、模糊的情况,但可以为专家提供多种修复参考,为后序修复提供决策依据,在降低文物修复的主观性、随机性的同时加强修复的准确性,极大地提升了文物修复效率.
3.7 阶段性子网络分析实验
本节通过讨论2 阶段网络的修复结果,分析论证各阶段子网在文物修复任务中的不同作用.在实际修复任务中,文物图像常常会因老化而产生破洞、裂痕等问题,使图像整体结构受到破坏,如图8 所示.第1 阶段利用Transformer 对破损文物图像进行整体结构先验信息修复的结果如图8(b)所示;第2 阶段利用多重残差卷积网络对第1 阶段输出图像进行纹理修复的结果如图8(d)所示.

图8 各阶段文物修复效果Fig.8 Effect of the various stages of cultural relics restoration
本文方法从文物图像的特性出发,在修复过程中充分考虑了图像的整体结构与局部纹理.如果在文物图像修复任务中仅仅使用第1 阶段的子网络,虽然可以生成连贯且符合语义的整体结构,但为减少计算量的降维操作往往会导致修复结果较为模糊、缺乏相应的细节语义信息,如图8(b)所示;如果在文物图像修复任务中仅仅使用第2 阶段的子网络,虽然可以生成有效的局部纹理,但修复的图像会缺乏正确的上下文语义信息,如图8(d)所示.
综合上述对阶段性子网络的分析表明,本文方法只有在2 阶段网络共同作用下才能实现最优修复效果.
4 总 结
在文物图像补全领域,长期存在着既要实现足够的多样性又要求修复效果逼真的困境.本文针对文物图像修复任务提出了一种基于Transformer 的修复方法,该方法将Transformer 和CNN 的优点结合;利用Transformer 的全局结构理解能力和多元化输出以及CNN 较强的局部感知能力,本文方法实现了对文物图像的高质量修复.同时,本文提出了一个新的高质量文物数据库,解决了国内外缺乏相关数据库的问题.大量实验表明,本文方法在主客观效果上均优于现有方法,并实现了多元化输出,提升了文物修复效率.本文方法仍有需要深入研究与改进的方面,如图8 的修复结果在原始缺损区域附近产生模糊等问题.此外,本文设计的2 阶段网络能够生成多元化的结果,最大程度地为文物修复提供指导与参考,但在修复大面积破损图像时也会产生与原始图像不一致的结果.最后,由于评估指标的缺陷,实验中会出现高指标、低主观感知质量和低指标、高主观感知质量的修复结果,对网络训练的非线性回归产生影响.后续工作考虑在第2 阶段子网络设计方面对图像进行多尺度特征融合与去噪[25];探索更能反映文物图像修复质量的评价指标,加强对网络的约束并提升文物图像修复质量.也可借助门控卷积[40]网络的设计思想对第2 阶段进行改进,使其更能适应缺损面积较大的文物图像修复任务.还可以进一步提高文物图像数据集的数量与质量,将各类文物图像进行更加细致地划分,以适应更加复杂的修复场景;更新专项训练策略,提高修复结果的分辨率和观赏价值.
作者贡献声明:王真言负责部分实验开发任务、数据整理分析并提供论文修改意见;蒋胜丞完成部分实验开发任务、数据集的创建并撰写论文;宋齐鸿提供论文修改意见;刘波、毕秀丽和肖斌提供实验开发思路,给予工作支持和指导意见.
猜你喜欢
金桥(2022年6期)2022-06-20
数学小灵通·3-4年级(2021年5期)2021-07-16
软件(2020年3期)2020-04-20
东方考古(2019年0期)2019-11-16
少儿美术(快乐历史地理)(2019年5期)2019-09-10
摄影之友(影像视觉)(2018年12期)2019-01-28
今日农业(2019年15期)2019-01-03
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
