
基于GPU 直访存储架构的推荐模型预估系统
2024-03-23 08:04谢旻晖陆游游冯杨洋舒继武
计算机研究与发展 2024年3期
谢旻晖 陆游游 冯杨洋 舒继武
(清华大学计算机科学与技术系 北京 100084)
我们正身处一个信息过载的时代,全球内容生产呈指数型增长:新浪微博每天产生1.17 亿条微博[1],快手每天有千万条新发布的短视频[2].在如此庞大的规模下,用户很难从中找到自己可能感兴趣的内容.推荐系统负责从中筛选出可能感兴趣的内容个性化地推荐给每个用户,被认为是解决信息过载的有效手段.近年来,随着深度学习的快速发展,新型深度学习模型[3-6]已广泛应用至现代推荐系统之中,显著提升了个性化推荐的准确率.根据Meta 公司的统计[3],推荐模型预估(inference)耗时在其数据中心的人工智能服务总耗时的占比高达80%.因此,推荐模型预估系统设计已成为数据中心人工智能系统设计中的一个关键问题.
与计算机视觉、自然语言处理中的计算密集型深度学习模型不同,推荐模型包含一个巨大且访存密集的嵌入层(embedding layer).该嵌入层用于映射对应输入的特征ID 至低维嵌入参数(embedding vector),由于推荐模型接受的输入包含海量高维稀疏的特征ID(例如用户ID、近期观看过的视频ID),而深度神经网络无法直接从高维稀疏特征中学习.所有低维嵌入参数拼接后,一同输入深度神经网络拟合样本标签.由于特征交叉技术[5]的广泛使用与每个特征本身的海量ID 空间,嵌入层中包含的参数可多达千亿级,占模型总体参数的99.99%以上[7].受限于GPU 的内存大小,嵌入参数通常存储在内存(dynamic RAM,DRAM)与固态硬盘(solid state disk,SSD)等较为廉价的硬件资源上[8-10].
现有推荐模型预估系统[11]依赖于CPU 对存储资源上的嵌入参数进行访问(后文称为基于CPU 访问存储架构).具体地,由CPU 接收经GPU 去重后的特征ID,访问相应DRAM 或SSD 获得嵌入参数后,再将所需嵌入参数额外聚集(gather)到一块连续的内存空间,通过直接存储器访问(direct memory access,DMA)引擎传输至GPU.GPU 收到嵌入参数后,完成后续的神经网络计算任务.
然而,我们发现该架构存在2 个问题:一方面,GPU 所需的任何数据均需交由CPU 访问再传回GPU,CPU 和GPU 的频繁交互带来的通信开销增加了参数访问的时延;另一方面,聚集操作引入的额外内存拷贝消耗了CPU 资源与内存带宽,为访存密集的嵌入层带来了严重的性能损失.
针对上述问题,本文提出一种基于GPU 直访存储架构的推荐模型预估系统GDRec.GDRec 的核心思想是在嵌入参数的访问路径上移除CPU 参与,由GPU 通过零拷贝的方式直接访问DRAM,SSD 等存储资源,以减少主机端CPU 与DRAM 的开销.具体地,GDRec 包含2 个直访存储机制:内存直访机制(用于访问位于DRAM 上的参数)与外存直访机制(用于访问位于SSD 上的参数).
内存直访机制利用设备商提供的统一虚拟地址(unified virtual address,UVA)特性[12],将嵌入参数所在的DRAM 内存区域映射至GPU 内存虚拟地址空间.由此,GPU 核心函数(kernel)可以绕过主机端CPU,直接通过load/store 指令以字节粒度直接访问DRAM.由于跨PCIe 总线访问主机DRAM 内存有一定开销,GDRec 进一步地提出访问合并与访问对齐2 个优化,通过调度GPU 线程读取嵌入参数的方式,尽可能减少GPU 发出的PCIe 事务数量.
外存直访机制在GPU上实现了一个类似于存储性能开发套件(storage performance development kit, SPDK)[13]的用户态NVMe(non-volatile memory express)驱动程序,允许GPU 线程直接向SSD 提交读写请求,同时也允许SSD 通过DMA 引擎将读取到的硬盘数据直接写入GPU 内存.整个过程无需主机端的CPU 与内存参与.
在每次推荐模型的预估过程中,GDRec 首先利用GPU 高效地将特征ID 去重,然后根据对应的嵌入参数所在的位置将请求分流至内存直访机制与外存直访机制.待所有嵌入参数的读取请求完成后,类似于传统的预估系统,GDRec 进行后续的神经网络计算.
我们在3 个公开的点击率预估数据集上进行了测试,实验表明:与NVIDIA 公司深度优化的推荐模型预估系统HugeCTR[11](HugeCTR-Inference)相比,GDRec 可以提升超过1 个数量级的吞吐量;相比于使用SPDK 高度优化后的HugeCTR,GDRec 仍有多达1.9 倍的吞吐量提升.
综上所述,本文的主要贡献有3 个方面:
1) 分析了现有推荐模型预估系统(基于CPU 访问存储架构)的性能问题;
2) 提出了一种基于GPU 直访存储架构的推荐模型预估系统GDRec,其包含内存直访与外存直访2 个机制,分别使能GPU 直访DRAM 与SSD 上的参数;
3) 使用实验说明GDRec 设计的有效性,特别地,在3 个公开的点击率预估数据集上,GDRec 在性能上优于高度优化后的基于CPU 访问存储的同类系统,吞吐提升多达1.9 倍.
1 背景介绍与研究动机
本节主要介绍深度学习推荐模型的基本结构与现有预估系统的主要处理流程,同时分析现有系统使用CPU 访问存储架构导致的性能问题.
1.1 深度学习推荐模型结构
自微软公司的Deep Cross[6]与谷歌公司的Wide&Deep 模型[5]发布以来,推荐模型已全面步入深度学习时代.与传统机器学习模型相比,深度学习推荐模型的表达能力更强,可以挖掘出用户(user)与物品(item)之间更深层次的联系,从而更好地推测出用户的喜好.
深度学习推荐模型的输入特征主要包含2 种类型:稠密特征和稀疏特征.稠密特征亦称数值型特征、连续特征,指具有数值意义的特征,如用户的年龄、商品被访问的次数等;稀疏特征亦称类别型特征、ID 型特征,指如用户ID、视频ID 列表等以独热(onehot)或多热(multi-hot)形式存在的高维特征.稀疏特征一般被编码为ID 的列表,如某用户近期观看过的视频为[视频ID1, 视频ID4, 视频ID5].
图1 展示了典型的深度学习推荐模型结构,它由2 个部分组成:嵌入层(embedding)与多层感知机(multi-layer perceptrons,MLP).由于深度神经网络无法直接从高维稀疏特征中学习[14],嵌入层用于将稀疏特征映射至稠密的嵌入参数.具体地,嵌入层由多个嵌入表(embedding table)组成,如用户、视频嵌入表.每个表用于映射对应的输入特征ID 至低维嵌入参数,嵌入参数的维度称为嵌入维度(embedding dimension),映射的过程类似于哈希表查询.在嵌入层映射完稀疏特征后,所有嵌入参数会与样本中的稠密特征拼接,得到包含样本所有特征的特征向量.模型将特征向量输入MLP,MLP 对特征向量各个维度进行复杂的交叉组合,最后拟合样本的标签(例如某用户是否可能观看某视频).典型的工业级推荐模型神经网络包括:Wide&Deep[5],DeepFM[15],DCN[16],DIN[17],DIEN[18].各模型在具体模型结构上有所不同,但模型主体结构都符合embedding 和MLP 两个部分的结构.
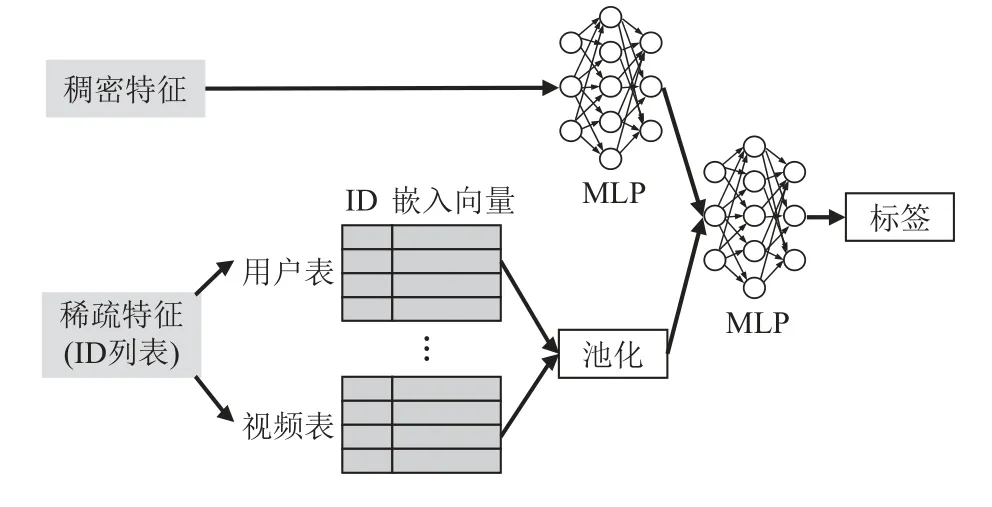
图1 深度学习推荐模型结构Fig.1 Structure of deep learning recommendation model
从图1 还可以看到,深度学习推荐模型的参数可分为2 类:稀疏参数(由嵌入层组成,用于处理稀疏特征)与稠密参数(由MLP 层组成,用于处理稠密特征与稀疏特征经嵌入表映射后的中间结果).这2 类参数在计算模式与存储特征上有着本质的区别.对于计算模式,只有样本包含的特征ID 涉及到的一部分稀疏参数会参与计算,而全部的稠密参数都会参与计算;对于存储特征,稠密参数通常只有百兆级,而稀疏参数可多达千亿级,这一方面是由于每个稀疏特征ID 空间巨大,另一方面也由于广泛使用的特征交叉技术[5]可以将多个特征做笛卡儿积(Cartesian product),从而形成ID 空间更大的新特征.
许多公司报告(如阿里巴巴[19]、Meta[3]),在它们生产环境的模型中,嵌入层通常占据模型端到端预估的时延60%以上.其原因在于嵌入层引入了大量对存储资源的随机访问.因此,针对嵌入层的系统设计与优化是提升推荐模型预估系统性能的关键所在.
1.2 传统架构及其问题分析
文献[2,7,20]表明,更大的参数量往往能带来更好的推荐质量,在过去几年中,推荐模型参数量级已从百亿级迅速膨胀至千亿级,海量参数使得纯内存存储方案成本过高.另一方面,随着Optane 等高速存储介质的发展,现代高性能SSD 的平均延迟不断降低.例如,Intel 公司在2018 年推出的905P SSD 的4 KB随机读延迟仅为10 μs.为了提高存储性价比,学术界与工业界的许多工作[7-8,10,21-23]都已迁移至内存外存混合存储方案.针对1.1 节所述的推荐模型结构与稠密、稀疏参数在计算、存储上的特点,现有推荐系统比较通用的做法是将稠密参数缓存在GPU 的内存中,而将稀疏参数存储在DRAM,SSD 等相对廉价存储介质中.
如图2 所示,现有系统采用基于CPU 访问存储架构.一次典型的预估处理流程为:
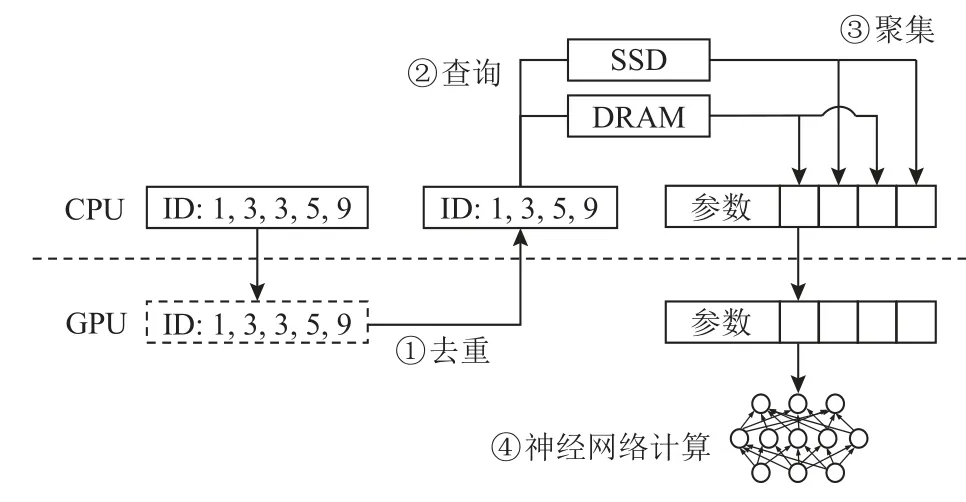
图2 典型预估流程Fig.2 Typical inference process
①去重.一次预估输入往往包含一批样本,其中样本包含大量重复的特征ID[11].CPU 会首先将所有特征ID 传输给GPU,由GPU 将特征ID 去重.得益于GPU 的高并行性,GPU 去重可以获得比CPU 去重更好的性能.
②查询.GPU 将去重后的特征ID 传输回CPU,CPU 根据去重后的特征ID,查取DRAM 以及SSD 上的嵌入表,得到特征ID 对应的嵌入参数.
③聚集.CPU 将上一步查询得到的嵌入参数聚集至DRAM 内存上一块连续的区域,再传输给GPU.
④神经网络计算.GPU 将嵌入参数与样本中的稠密特征拼接,输入MLP 计算,得到最后的预估结果.
然而,我们发现该架构存在2 个问题:
1) CPU 与GPU 之间的通信开销大.如图2 所示,GPU 需要将访问相关的元数据(即去重后的ID)传输至CPU,CPU 访问存储资源得到数据后,再传输回GPU.2 次通信交互均涉及到GPU 上DMA 引擎的启动、同步,以及包含数次用户态-内核态切换,这些开销增加了嵌入层参数访问的时延.
2) 聚集操作引入的额外拷贝,消耗了CPU 资源与内存带宽,同时增加了嵌入层的时延.为了便于GPU 上的DMA 引擎拷贝,CPU 需将访问得到的嵌入参数额外聚集至一块连续的内存空间,再由DMA 引擎传输给GPU.这一步额外的拷贝带来了3 方面弊端.首先,浪费宝贵的CPU 资源,除处理嵌入层外,CPU 还需服务于网络栈、模型预处理等过程.CPU 访问存储架构浪费了一部分CPU 资源用于访问存储、嵌入参数聚集.在面对包含复杂预处理的模型或单机多GPU 卡等场景下,CPU 可能成为瓶颈而影响全局性能[24].其次,消耗了内存带宽,给访存密集的嵌入层带来了严重的性能损失.最后,CPU 单线程逐参数拷贝性能低下,这增加了端到端预估时延.
2 GDRec 架构
本文提出一种基于GPU 直访存储架构的推荐模型预估系统GDRec.GDRec 同时使用GPU 显存、DRAM内存与SSD 外存 3 个层级的存储资源,参数存储方式与现有系统类似:GPU 显存中存储稠密参数,DRAM 与SSD 分层存储稀疏参数.具体地,在加载模型时,类似于现有工作[25],GDRec 根据参数访问热度对稀疏参数进行降序排序,并对参数ID 重编号.GDRec 将最热的一部分参数缓存于DRAM,剩余部分存储于SSD.
图3 描述了GDRec 的总体结构与一次预估过程.CPU 上的特征ID 会首先传输至GPU 进行去重;GPU根据去重后的特征ID,分别通过内存直访机制与外存直访机制,以零拷贝的方式直接访问主机端DRAM和SSD 上对应的嵌入参数;参数聚集操作直接在GPU 上完成;最后,模型正常进行神经网络计算.
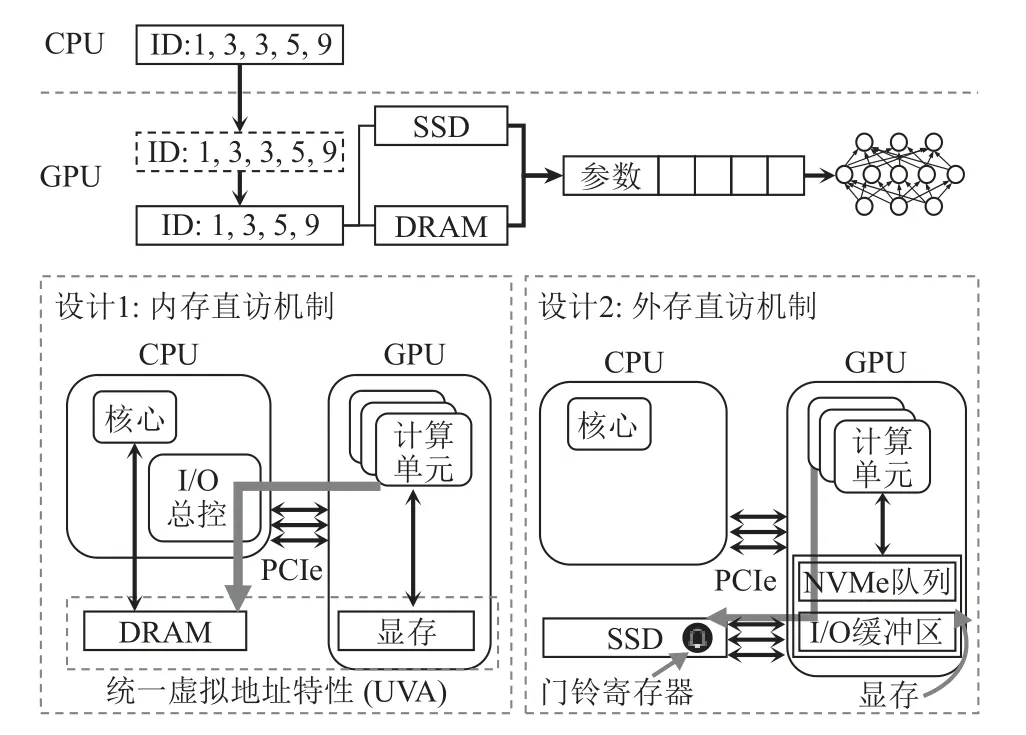
图3 GDRec 架构Fig.3 Architecture of GDRec
相比于传统CPU访存的架构,GDRec这种基于GPU直访存储的架构带来了3 点优势:1)GPU 访存可以享受GPU 高并行性带来的高性能,GPU 在并行访问DRAM、并行提交SSD 请求等方面可以获得比CPU更好的性能;2)在访存时仅涉及1 次CPU 与GPU 之间的通信,即去重前的ID 从CPU 传入GPU,之后所有过程均由GPU 单独完成;3)GPU 直访机制节省了聚集过程中的额外拷贝,参数可直接被读取到位于GPU 内存的目的地址,无需经由DRAM 缓存,这节省了CPU 资源、DRAM 内存带宽,同时降低了端到端延迟.
需要说明的是,GDRec 的实现基于NVIDIA 公司推出的GPU,同时本文主要关注于CUDA(compute unified device architecture)编程模型;对其他厂商的GPU 以及编程模型(如AMD 与ROCm)的支持将是我们的未来工作.
3 关键技术设计与实现
本节将逐一介绍GDRec 的2 个关键技术,包括内存直访机制与外存直访机制.
3.1 内存直访机制
根据1.2 节的问题分析,GDRec 内存直访机制的核心思想是让GPU 以零拷贝的方式从DRAM 中读取数据,避免已有系统中CPU 额外的聚集操作与DMA 引擎启动的开销.为了达到这个目标,GDRec的内存直访机制利用了CUDA 提供的UVA 特性[12].该特性可以将一块DRAM 内存地址空间映射至GPU内存虚拟地址空间,GPU kernel 以读写指令(load/store)直接对DRAM 进行访问.整个过程无需主机端CPU的参与.
GDRec 精心挑选了内存直访机制的实现方式.CUDA 提供了下面2 种方式使一段内存可供GPU 直访.1)如果内存尚未分配,可以通过cudaMallocHost函数同时实现内存的分配与地址空间的映射,该函数返回的指针可同时被CPU 与GPU 两种处理器读写;2)如果内存已经分配,使用函数cudaHostRegister首先将该段内存区域锁页,再使用函数cudaGet-DevicePointer 获得该区域在GPU 虚拟地址空间的指针.GDRec 使用方式2,原因是我们发现其可以使用大页(huge page)分配内存,而方式1 不可以.大页的使用可以减少转换检测缓冲区(translation lookaside buffer,TLB)缺失,从而提升嵌入层访存时的性能.在系统初始化分配DRAM 上的嵌入表后,GDRec 将对应的UVA 虚拟地址指针传入GPU.
内存直访机制使得GPU 细粒度地访问DRAM上的稀疏参数成为可能,但细粒度的访问同时也可能带来PCIe 开销大的问题.一般来说,对于传输同样大小的数据,越多的PCIe 事务意味着传输所需的元数据也越多,相应地访存的有效吞吐量也会降低.例如,对于PCIe 4.0 标准,每个事务层数据包(transaction layer packet,TLP)包含12 B 或16 B 的包头,如果数据包仅携带32 B 有效数据,直访内存机制将遭受27%~36%的PCIe 开销.由于PCIe 带宽是有限的,这导致GPU 直访内存的有效带宽受限.为了解决该问题,GDRec 通过调整GPU 线程读取嵌入参数的方式,尽可能地减少GPU 发出的PCIe 数据包数量,调整方式具体包括2 个部分:访问合并与访问对齐.对于访问合并,现代GPU 支持以最大128 B 的内存事务访问主机端的内存.GDRec 令GPU 线程束(warp,32 个线程为1 束)读取连续的内存区域,每个线程读取4 B.这样,当该内存区域首地址是128 B 对齐时,这个线程束的内存访问将被硬件合并为1 个PCIe 事务.对于访问对齐,其处理的情况是当访问的参数首地址非128 B 对齐时,例如参数尺寸非128 B 的整数倍.一种简单的方法是位移参数,将每个嵌入参数的首地址对齐至128 B 的倍数,但这会引入额外的内存空间开销.相对地,GDRec 没有改变参数在内存中的布局,而是调整了GPU 线程读取嵌入参数的方式.具体而言,如图4 所示,当访问的内存区域非128 B 对齐时,GDRec 所有线程束向高地址方向读取对齐的1 个128 B,并额外分配1 个线程束读取头部剩余的字节.这样,假设要访问的内存区域大小为X(单位为B),我们只需发出「X/(128B)■个PCIe 事务,就可达到最优情况.

图4 访问对齐Fig.4 Aligned access
3.2 外存直访机制
现有推荐模型预估系统在访问外存时并不高效,它们将嵌入参数视为键值,并依赖于已有的SSD 键值存储系统.例如NVIDIA 公司的HugeCTR 使用RocksDB系统[26]读写SSD.这种做法不仅面临着大量内核存储I/O 栈的开销,其以CPU 为中心的访存架构同样存在着如1.2 节中所述的CPU-GPU 通信开销大、额外拷贝引起的内存带宽消耗与CPU 资源浪费这2 个问题.
对此,GDRec 提供了GPU 上的NVMe 驱动以实现GPU 外存直访机制,进而优化推荐模型预估系统的外存访问路径.GDRec 的外存直访机制具有3 个特点:1)纯用户态.类似于SPDK 绕过Linux 内核I/O 栈,允许在用户态直接访问SSD.2)GPU 直访.GDRec 使得GPU kernel 可以直接向SSD 发起读取请求,读取到的数据直接写入GPU 内存,控制路径与数据路径皆无需途经CPU,这减少了CPU-GPU 通信开销、主机端CPU 和DRAM 的使用;3)GPU 并行快速提交I/O 请求,GDRec 充分利用GPU 并行性,允许大量线程并行提交一次预估过程中所需参数对应的I/O 请求至NVMe 提交队列(submission queue, SQ),以进一步缩短控制路径上的时延.
我们在GPU 内存上分配NVMe SSD 的提交队列、完成队列等空间,并将这些队列注册给SSD,同时分配可供SSD DMA 传输参数的数据缓存区,基于GPUDirect RDMA 机制,这些空间可以被暴露给SSD 读写访问;然后将SSD 的门铃寄存器(doorbell register),包括提交门铃寄存器与完成门铃寄存器,映射至GPU 内存虚拟地址空间,此操作需要2 步:首先使用函数mmap 将SSD 的门铃寄存器所在地址映射至用户进程地址空间,再使用函数cudaHostRegister 将其进一步注册至GPU 内存虚拟地址空间.
GDRec 的每次预估过程涉及一批位于SSD 上的嵌入参数的查询(假设有N个),直访外存的具体流程如下.首先,GPU 接收到一批已经去过重后的特征ID,计算出对应的嵌入参数所在的逻辑块号;其次,GDRec 为每个计算单元SM 分配了单独的SSD,请求提交队列与完成队列,并充分利用GPU 并行性将I/O 命令批量写入提交队列;同一批次的读请求中如果有多个参数在同一个逻辑块中,GDRec 会将对应的I/O 命令合并以减少SSD 读取的数据量.然后,GDRec 单独分配1 个线程用于更新提交门铃寄存器以通知SSD,利用门铃批处理(doorbell batching)机制,提交读请求时GPU 产生的跨PCIe 总线写次数可以从N次降低至1 次;SSD 在收到提交门铃寄存器的更新后,拉取位于GPU 内存上的提交队列,处理其中的NVMe 命令;SSD 在完成I/O 命令后,会向位于GPU内存上的完成队列写入完成项,并更新完成门铃寄存器.GPU 通过轮询完成队列得知SSD 读取的完成情况.
GDRec 还采用2 个优化进一步提升外存直访性能:
1)由于嵌入参数的尺寸通常在128~512 B,GDRec通过NVMe format 命令调整SSD 的逻辑块大小,其优势在于对于大小恰为逻辑块的嵌入参数,GDRec可以将目的地址直接填入NVMe 读命令,并加入提交队列,以减少1 次从I/O 缓存区到目的地址的拷贝,并实现零拷贝.
2)GDRec 尽可能地将所有嵌入参数均匀地分布在SSD 整个空间上,如图5(b)所示.相比于简单的连续存放,如图5(a)所示,这种方式可以更充分地综合利用SSD 内部不同存储芯片资源.当多个模型需要共享1 块SSD 的存储空间时,GDRec 将各个模型的参数交错存储,如图5(c)所示.
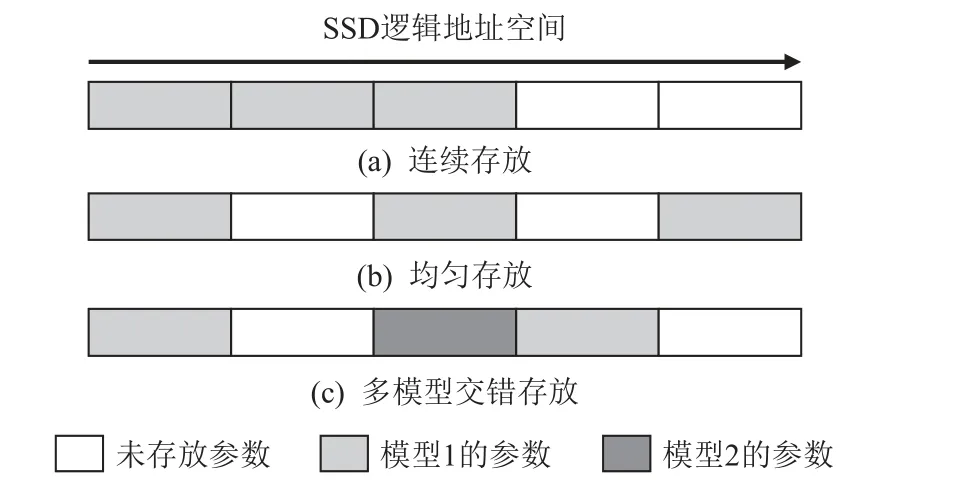
图5 SSD 嵌入参数放置策略Fig.5 Embedding placement strategy in SSD
3.3 局限性
GDRec 目前的实现有2 方面的局限性:
1)GDRec 仅支持静态模型的预估,无法支持增量更新[2]的动态模型.其原因是GDRec 的直访机制要求在GPU 内完成每个嵌入参数地址的定位,动态模型需要额外维护从特征ID 到嵌入参数地址的索引,而这通常会超过GPU 显存容量.也因为同样的原因,GDRec 目前不支持冷热数据在SSD 和DRAM间的迁移.
2)GDRec 仅支持部分型号的GPU.由于GDRec外存直访机制需要GPU 支持GPUDirect RDMA 机制.因此,对于NVIDIA 公司推出的GPU,GDRec 的外存直访机制可以在NVIDIA Tesla 与Quadro 系列的GPU上运行,但无法在NVIDIA GeForce 系列GPU 上运行.
4 实 验
本节将通过实验对比和分析GDRec 与现有系统的性能差异.首先,使用微观基准测试说明GDRec的GPU 直访架构相比于传统CPU 访存架构在性能上的优越性;其次,使用真实世界的推荐模型与数据集对比测试所有系统的端到端吞吐量、延迟-吞吐曲线;最后,对比测试纯内存场景下,小型推荐模型预估时所有系统的性能.
4.1 实验平台与测试数据集
1)实验平台.本文实验使用的实验平台配置信息如表1 所示.本文实验使用的GPU 为NVIDIA Tesla A30,其包含24 GB 显存,使用的SSD 为Intel Optane P5800X,其4 KB 随机读延迟为5 μs.实验机器拥有2 个非统一内存访问(non uniform memory access, NUMA)架构节点,为避免跨NUMA 访问带来的性能下降,本文实验只使用同一NUMA 下的CPU,GPU,DRAM,SSD.

Table 1 Configuration Information of Experiment Platform表1 实验平台配置信息
2)数据集.本文实验共选用3 个数据集,具体信息如表2 所示.数据集来自Avazu 与Criteo 这2 家公司对真实世界点击率(click-through rate, CTR)负载的采样.在所有数据集上,我们训练一个深度交叉网络(deep cross network,DCN)作为推荐模型负载,该模型包含6 个交叉层与形状为(1 024, 1 024)的MLP 层.对于Avazu 与Criteo-Kaggle 数据集,嵌入参数的维度被设为32;对于Criteo-TB 数据集,维度被设为128.
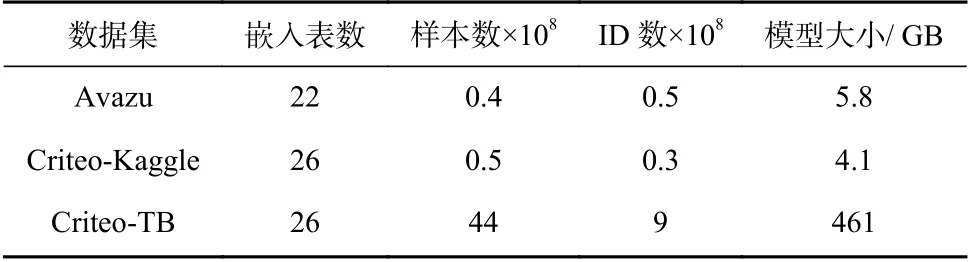
Table 2 Datasets for Test表2 测试用数据集
3)对比系统.本文实验将GDRec 与HugeCTR 进行性能对比.HugeCTR 是NVIDIA 公司推出的针对推荐模型负载特别优化的预估系统.HugeCTR 使用RocksDB系统存储SSD 上的参数,其会导致严重的内核I/O 栈开销,同时其采用的LSM-Tree(log-structured merge-tree)数据结构对推荐模型点查询的负载并不友好.为了公平对比与充分展现基于GPU 直访架构的优势,我们基于SPDK 重新实现了SSD 参数存储模块,并替换RocksDB,后文简称该系统为HugeCTR-OPT.HugeCTROPT 可被视为极致优化的基于CPU 访存架构的系统,其与GDRec 仅在I/O 提交方式上有区别.
在系统配置方面,如不作特殊说明,我们默认设置DRAM 大小为5%的模型,模型剩余部分存储于SSD中.对于HugeCTR,我们使用NVIDIA 提供的原生配置(RocksDB 开启10 b 布隆过滤器, 8 MB 块缓存大小).HugeCTR 与GDRec 均使用单个CPU 线程处理预估请求.
所有代码使用GCC 9.3 与NVCC 11.3 编译,优化选项为-O2.对于GPU,我们使用的CUDA 版本为11.3,cuDNN 版本为8.2.
4.2 微观基准测试
本节测试对比基于CPU 访存与GPU 直访的2 种架构在访问DRAM 与SSD 时的基准性能.测试过程为:在GPU 中以均匀分布随机生成一定数量的特征ID,由2 种架构分别访问DRAM 和SSD 得到对应参数,并将参数拷贝至GPU 中.该测试过程对应于推荐模型访问嵌入参数时的过程,我们分别选择HugeCTROPT 与GDRec 系统的对应功能实现用作本节的测试.
图6 展示了当参数完全位于DRAM 上时2 种架构的性能.对于同样数量的特征ID,GDRec 的完成时延要比HugeCTR-OPT 低1.5~3.6 倍.这一方面由于GDRec 无需CPU-GPU 之间多次通信,另一方面得益于GDRec 避免了聚集时CPU 额外拷贝造成的时延.
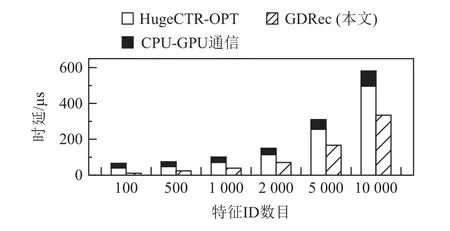
图6 内存嵌入参数访问性能Fig.6 Performance of accessing in-memory embeddings
此外,当查询的特征数目较少时,例如100,Huge-CTR-OPT 单就CPU-GPU 通信时延(包括将ID 从GPU传至CPU、将参数从CPU 传至GPU),已与GDRec 完成的总体时延相近,这充分说明了GDRec 内存直访机制设计的优越性.
图7 则展示了当参数完全位于SSD 上时2 种架构的性能.GDRec 相比于HugeCTR-OPT 性能有1.2~2.0 倍的提升.其原因一方面类似于内存直访机制,外存直访机制同样节省了CPU-GPU 通信开销与聚集步骤的额外拷贝;另一方面,外存直访机制在提交SSD 的I/O 请求时可以充分利用GPU 的高并行性并行提交,减少了参数读取时延.
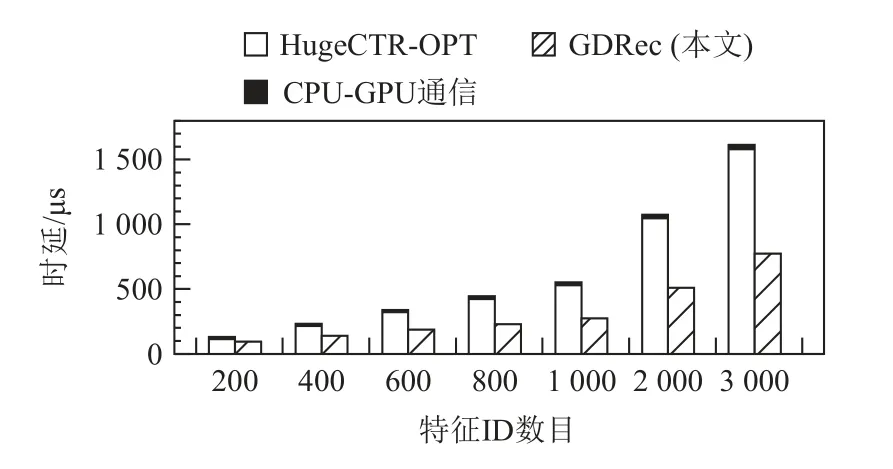
图7 外存嵌入参数访问性能Fig.7 Performance of accessing in-SSD embeddings
对比图6 和图7,我们发现相比于在DRAM 上,GDRec 在SSD 上获得的性能提升更少.其原因是SSD有着比DRAM 更高的硬件读取延迟,这导致GDRec可优化的软件部分时延占端到端的比例减少,进而在SSD 上性能提升更少.
4.3 端到端吞吐量对比测试
图8(a)展示了在不同批处理大小下,GDRec 与对比系统的预估样本吞吐量情况.从图8(a)中可知:
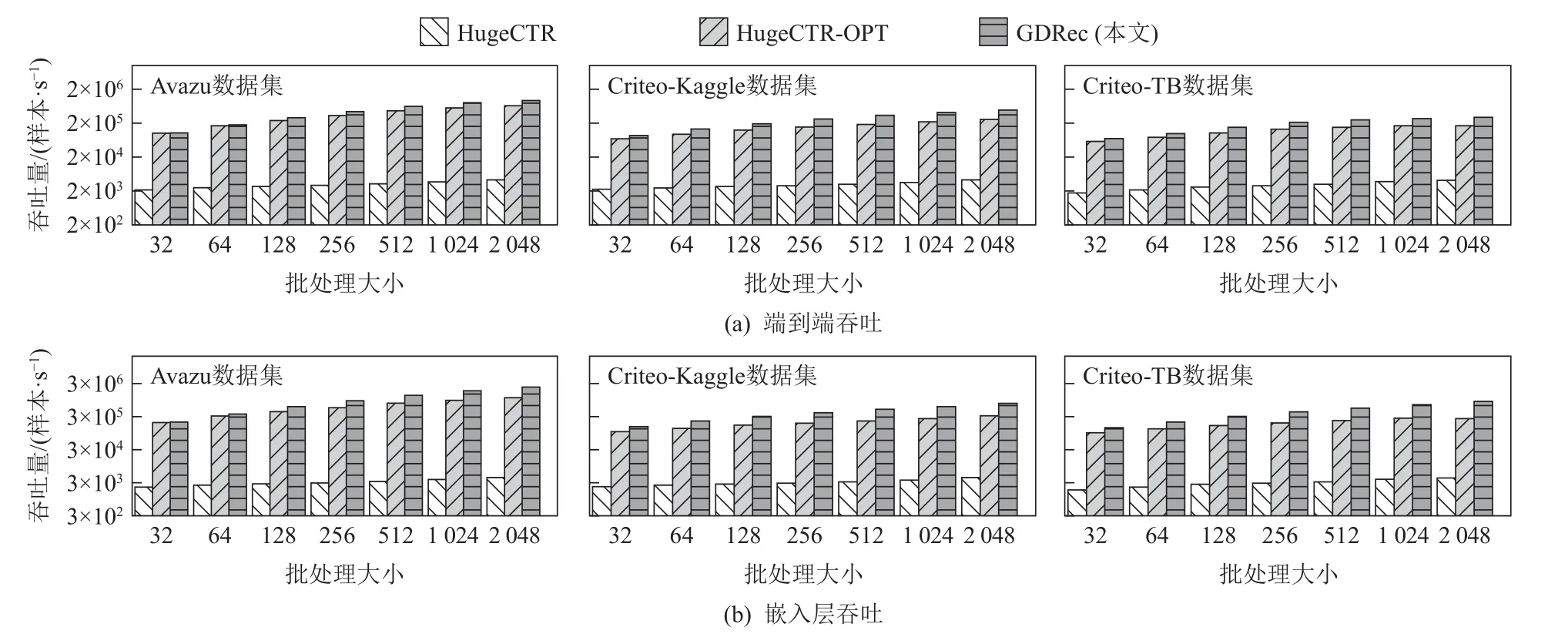
图8 系统吞吐量对比Fig.8 System throughput comparison
1) 当批处理变大时,所有系统的吞吐量都随之上升,这是由于大的批处理可以更充分地利用GPU的并行性;
2) HugeCTR 系统吞吐最低,且与另外2 个系统有着数量级上的差距,其原因是RocksDB 适合范围查询、写密集场景,并未针对推荐模型的点查询、读密集场景做定制优化;
3) HugeCTR-OPT 使用SPDK 定制了点查询友好的SSD 参数存储模块,相比于HugeCTR 获得了性能提升,但其CPU 访存的架构仍然面临1.2 节所述的2个问题;
4) 相比于HugeCTR-OPT,GDRec 在Avazu,Criteo-Kaggle,Criteo-TB 这3 个数据集上分别获得1.1~1.4 倍、1.1~1.9 倍与1.3~1.9 倍的性能提升,性能提升来自于GDRec 的GPU 直访存储设计,内存直访机制与外存直访机制将CPU 与GPU 的通信次数均降低为1,同时零拷贝的设计消除了额外的拷贝开销,而GPU 并行提交I/O 命令缩短了读取SSD 时控制路径的时间;
5)随着批处理变大,GDRec 相对于HugeCTROPT 提升的性能更多,这是由于大批次样本情况下查询SSD 的时间占比更多,此时GDRec 的GPU 外存直访机制的优势更得以充分体现.
进一步地,由于GDRec 的所有设计仅针对于嵌入层,我们在图8(b)单独展示不同系统在模型嵌入层的吞吐量.可以看到,在Avazu,Criteo-Kaggle,Criteo-TB 这3 个数据集上,相比于HugeCTR-OPT,GDRec分别可以获得1.1~2.1 倍、1.4~2.4 倍与1.4~2.7 倍的性能提升.此测试排除了GDRec 未优化的模型MLP 层,因此,相比于端到端预估,GDRec 可以获得更多的性能提升.
4.4 延迟-吞吐量曲线测试
图9 展示了HugeCTR-OPT 与GDRec 在3 个数据集上的端到端预估中位数延迟-样本吞吐曲线.由于HugeCTR 的性能与它们有数量级的差异,因此省去其测试结果.
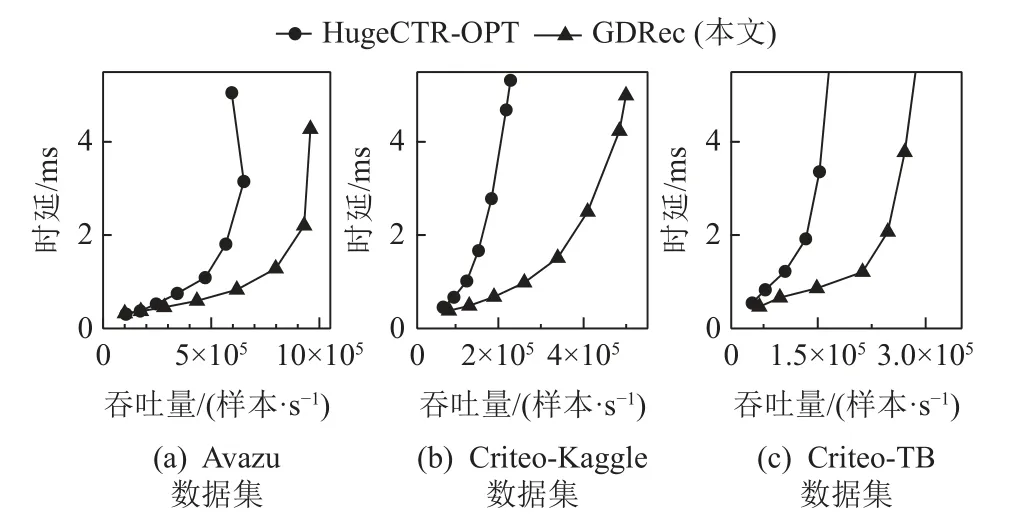
图9 端到端中位数延迟-吞吐量曲线Fig.9 Curves of throughput vs.end-to-end median latency
从图9 发现,相比于HugeCTR-OPT,GDRec 可以达到更高的样本吞吐量与更低的预估时延.在Criteo-TB 数据集上,给定中位数延迟为2 ms 的情况下,GDRec提升样本吞吐量1.9 倍,这主要是由于GDRec 充分利用GPU 并行性对内存与外存进行直访,可以达到更高的嵌入层吞吐量,同时避免CPU 访存架构在嵌入层的瓶颈现象;给定样本吞吐量为15 万样本/s,GDRec 可以降低74%的中位数延迟,这一方面由于在数据路径上GPU 直访省去了CPU 聚集时在内存上的额外拷贝与大部分CPU-GPU 通信开销,另一方面,GPU 可以并行提交DRAM 的访存指令和SSD 的I/O 命令,在控制路径上具有更低的时延.
4.5 小模型性能对比测试
本节实验考虑小模型预估场景,即当模型可以完全存储在DRAM 中时的情况.
图10 展示了GDRec 和HugeCTR-OPT 在不同批处理大小下的样本吞吐量.因为Criteo-TB 数据集对应的模型容量已远超过CPU 的DRAM 内存大小,本节测试用的数据集选择了Avazu 与Criteo-Kaggle.从图10 可知:
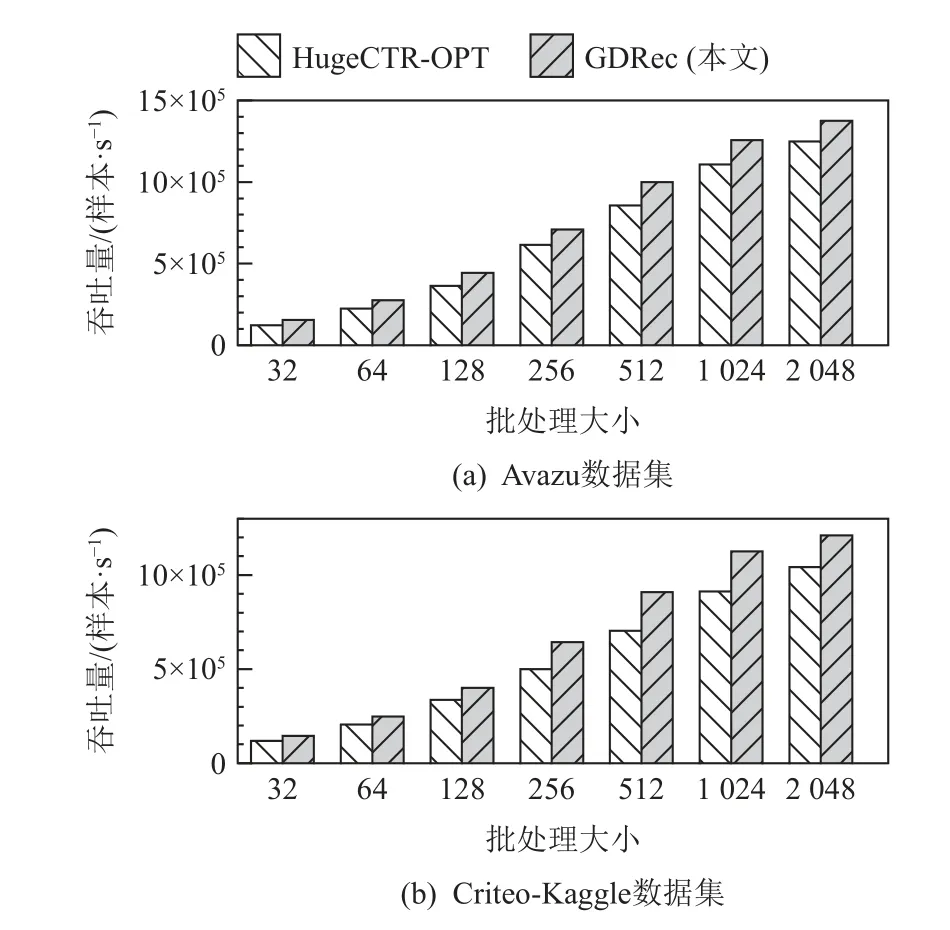
图10 小模型端到端吞吐量Fig.10 End-to-end throughput when models fit in DRAM
1) GDRec 可以在纯内存场景下在Avazu 与Criteo-Kaggle 上分别获得1.1~1.3 倍、1.2~1.3 倍的吞吐性能提升,这完全得益于GDRec 的内存直访机制;
2) GDRec 的相对性能提升在较大的批处理大小情况下更少,其原因是此时GPU 去重、CPU-GPU 通信等操作的时延增加,导致访问内存时延占比变少,因此内存直访机制可以提升的部分有限.
5 相关工作
本节从推荐模型预估系统与基于GPU 直访存储架构的系统2 方面介绍相关工作.
1)推荐模型预估系统.由于推荐模型独特的访存特性,大量工作对此设计定制化的预估系统.我们根据使用的硬件将它们分为两类.
一类工作仅使用CPU,GPU 等通用硬件.HugeCTRInference[11]是NVIDIA 公司推出的高度优化的预估系统,其构建GPU 显存、DRAM、SSD 多层级参数服务器存储模型参数.Fleche[27]在HugeCTR-Inference 的基础上优化了嵌入参数显存缓存的组织形式与查询方式,以减少缓存缺失率并提升预估性能.MERCI[25]基于物化视图的思想缓存同时出现的嵌入参数经池化后的结果,以减少内存访问量,提升性能.Bandana[10]系统利用NVMe SSD 存储模型以降低DRAM 成本,其使用超图划分算法将可能同时出现的参数放置于同一个数据块中,以减少块设备的读写放大现象.EVSTORE[8]为SSD 参数存储设计了混合型DRAM缓存,混合使用了组缓存、混合精度缓存和近似缓存,可以在几乎不影响模型准确率的情况下充分降低DRAM 的使用量.文献[11, 27]工作虽然在不同场景下缓解了嵌入层访存瓶颈问题,但它们在本质上仍属于传统CPU 访存架构,并未解决CPU-GPU 通信开销高、内存上的额外拷贝等问题.
另一类工作使用FPGA、近内存计算(near memory processing, NMP)等定制硬件加速嵌入层的处理.MicroRec[28]与FleetRec[19]利用带有高带宽内存的FPGA 加速嵌入层的访存操作.RecNMP[29],Tensor-DIMM[30],FAFNIR[31]使用近内存计算的方式,将池化操作卸载至内存; 类似地,FlashEmbedding[22]与RecSSD[23]将嵌入层的访存与计算操作卸载至SSD控制器.在数据中心中部署这些工作需要付出额外的硬件开销,而GDRec 则可以完全使用现有服务器硬件部署.
2) 基于GPU 直访存储架构的系统.图计算、图神经网络、推荐系统等新兴应用催生了GPU 对存储资源进行大量随机、细粒度的访问需求.传统架构依赖CPU 对存储资源进行访问,但造成CPU-GPU 通信开销大、CPU 处理时延高等问题,严重影响GPU 计算效率.在此背景下,一些工作绕开CPU,使GPU 直访存储并加速各类应用.EMOGI[32]针对GPU 上的图遍历负载,利用细粒度主机内存直访加速图数据结构的访问.伊利诺伊大学厄巴纳-香槟分校、IBM、NVIDIA 等单位合作于2021 年提出的图卷积神经网络训练系统[33],使用少量GPU 线程以零拷贝的方式从主机内存预取图节点特征至GPU 内存,重叠计算与访存,获得了多达92%的训练吞吐量提升.BaM[34]将SSD 抽象成可供GPU 直访的大数组,并在其之上运行图分析与数据分析应用.文献[32–34]的工作仅面向单一的内存或外存GPU 直访,且尚无现有工作针对推荐模型预估的独特访存流程与混合存储场景做定制设计.
6 结 论
推荐模型的参数访存已成为模型预估的性能瓶颈.现有基于CPU 访存架构的预估系统存在着CPUGPU 同步开销大和额外内存拷贝2 个问题,其性能已无法满足模型高速增长的访存需求.本文提出一种基于GPU 直访存储架构的推荐模型预估系统GDRec,通过在参数访存路径上移除CPU 参与,由GPU 以零拷贝的方式高效直访内存、外存资源.实验显示,相比于现有预估系统,GDRec 可以大幅度提升模型预估的吞吐量,同时降低预估延迟.
作者贡献声明:谢旻晖参与论文设计、代码实现测试,撰写论文;陆游游参与研究思路讨论,修改论文;冯杨洋参与前期实验方案的讨论设计与论文修改;舒继武参与研究思路讨论.
猜你喜欢
矿山安全信息(2022年22期)2022-11-24
成都信息工程大学学报(2022年4期)2022-11-18
高技术通讯(2021年5期)2021-07-16
汽车工程(2021年12期)2021-03-08
当代陕西(2019年13期)2019-08-20
电信科学(2017年6期)2017-07-01
当代化工研究(2016年2期)2016-03-20
电测与仪表(2015年22期)2015-04-09
测绘科学与工程(2014年5期)2014-02-27
电脑爱好者(2009年13期)2009-07-07
