
摩尔纹图案自动去除技术综述
2024-03-23 08:04亓文法刘宇鑫郭宗明
计算机研究与发展 2024年3期
亓文法 刘宇鑫 郭宗明
(北京大学王选计算机研究所 北京 100080)
在21 世纪这个网络信息爆炸的时代,数字图像作为人类认知世界的视觉基础,已经成为信息记录、表达、储存及传播的重要手段.同时,随着数码相机、平板电脑以及智能手机等移动设备的迅速普及,人们可以轻松地获取各种有意义或有趣的宝贵瞬间作为数字图像的内容.但是当利用光学镜头设备拍摄电子屏幕(如LED 屏、LCD 屏等)或者高频重复纹理图案(例如布料、瓷砖等)时,若相机的彩色滤光片阵列(colour filter array, CFA)与拍摄对象条纹之间的空间频率接近,则拍摄图像中会出现不规则的点状、条纹、曲线或者涟漪等形状的干扰图案,即所谓的摩尔纹,如图1 所示.因为从数学上讲,2 个具有相近频率的等幅正弦波被叠加,合成信号的振幅将会根据2个频率之间的差异而发生随机变化[1].摩尔纹图案的出现严重降低了拍摄图像的视觉质量和美感价值,并且会影响后续的传统图像处理效果,比如图像超分[2]、图像分割[3]、人脸识别[4-5]等.依据拍摄硬件设备、方向角度以及距离远近的差异,摩尔纹图案存在着形状各异、频谱广泛、纹理随机以及颜色复杂等动态特性.因此,拍照图像中的摩尔纹图案自动去除面临着巨大的挑战.

图1 不同尺度、频率和颜色的摩尔纹Fig.1 Moiré pattern of different scales, frequencies, and colors
理论上讲,摩尔纹去除可以视为传统的图像修复处理,其目的是消除拍照图像中的摩尔纹图案噪声,重建图像的高频细节以及恢复颜色空间信息[6].摩尔纹图案去除算法的输入为一幅包含摩尔纹图案的污染图像,输出则为一幅去除摩尔纹图案并进行了颜色空间信息恢复的干净图像.由于摩尔纹图案和原始图像信号在空域和频域的混合范围都很广,传统的图像去噪[7-8]、去网纹[9-10]和去模糊[11]等图像修复算法不能有效地直接应用于摩尔纹图案去除任务.比如,图像去噪任务通常假定噪声仅存在高频带中,但摩尔纹的分量不规则地分布于从低频到高频的各个子带中,即表现为在不同图像之间甚至同一图像中的不同区域,摩尔纹图案都会随机占据不同能量的频域子带;图像去网纹技术消除的图像纹理通常是均匀分布的,但是摩尔纹图案的分布疏密不均匀;图像去模糊技术则要求图像噪声的颜色或者强度变化幅度相对一致,而在实际场景中CFA 的颜色分布不均衡,使得摩尔纹图案在RGB 颜色通道中分别显示不同的强度.为了抑制摩尔纹图案的产生,最常用的方法是在成像之前添加一些预处理,例如,在相机镜头前面放置一个抗混叠滤波器[12-13],并对CFA 的输出图像应用相对复杂的插值算法[14-15].由于光学滤波器会导致高频信息丢失,并导致图像过度平滑,这些预处理方法在实践中发挥的能力很有限.因此,大部分的工作聚焦于图像去摩尔纹的后处理方法研究,尤其是针对拍摄后的屏幕图像.
早期的摩尔纹图案去除研究工作主要是基于摩尔纹生成模型展开的,其中利用了摩尔纹图案的特定先验知识和前提假设.考虑到常用的Bayer 型CFA通常会对采集的颜色通道分量进行插值处理后才能得到拍照后的全彩色图像,因此通过改进图像插值算法可以有效抑制摩尔纹干扰现象的发生[16-17].为了充分考虑颜色通道的相关性,更高性能的图像插值算法被提出,如梯度插值方法[18]、自适应插值方法[19]、加权系数插值方法[20]等.该类方法得到的修复图像能够较好地保留图像的细部边缘特征,但算法实现过于复杂,难以在实际场景中得到广泛应用.通过对摩尔纹图案的空间结构统计特征和频域能量分布特性进行分析,经过摩尔纹污染的拍摄图像可以被视为摩尔纹图案和背景自然图像的非线性叠加[21-22].Liu 等人[23]和Yang 等人[24]分别基于加性模型提出了用于纹理图像摩尔纹和屏摄图像摩尔纹的消除方法,通过图像分解模型实现摩尔纹图案和背景自然图像的区分,并同时保留图像细节以及保证图像锐度.Fang 等人[25]将污染屏摄图像描述为潜在层和摩尔纹图案层,结合潜在层的分段常数特性,提出了一种凸模型来解决摩尔纹消除问题.Sasada 等人[26]和Sidorov 等人[27]基于摩尔纹图案具有特定形状(如条纹、点状或单色)的假设来进行检测,并将摩尔纹图案与背景层相分离,实现摩尔纹图案的去除和背景颜色通道信息的恢复.另外,由于摩尔纹图案可以视为一种高频噪声,很多学者通过对图像频域能量信号进行分析,并应用相应滤波器将摩尔纹图案作为特定频率信号去除.常见的滤波器包括中值滤波器[28-29]、高斯陷波滤波器[28]、DoG(difference of Gaussians)[30]、非线性滤波器[31-32]、自适应滤波器[33]等.但是该类方法使用到的滤波器通常是经过人工设计的,去除摩尔纹图案后的图像会出现局部过平滑现象,部分图像细节缺失.另外,当背景自然图像中的感兴趣区域(region of interest, ROI)跟摩尔纹图案具有同样的高频特性时,基于滤波的摩尔纹图案消除方法就会失效.总之,基于传统信号处理的方法通常依赖于摩尔纹图案生成的先验知识,计算复杂度高,而真实世界中的摩尔纹图案往往具有不同的形状和频域特征,此时该类方法的处理效率较低.
近年来,基于卷积神经网络(convolutional neural network, CNN)的学习方法得到了长足发展,成为计算机视觉和图像处理领域的一场革命.CNN 在图像分类和图像识别方面取得成功后,同样在低水平视觉和图像处理任务中也被证明是非常有效的,包括图像超分辨率[34-35]、去马赛克[36]、图像去噪[37]和图像重建[38]等.Abraham[39]将CNN 方法引入摩尔纹图案处理领域,提出了一种利用小波分解和多输入深度卷积神经网络模型来检测计算机屏幕拍摄图像(屏摄图像)中的高频摩尔纹噪声图案.由于摩尔纹图案跨越很宽的频域范围,Sun 等人[40]利用一种多分辨率全卷积神经网络(deep multiresolution fully convolutional neural network, DMCNN)自动去除屏摄图像中的摩尔纹图案,该网络在计算如何消除每个频带内的摩尔纹伪影之前,对输入图像进行非线性多分辨率分析.之后,更多基于空域的多尺度CNN 模型[1,41-46]被相继提出,屏摄图像中的摩尔纹图案去除性能得到显著提高.除了考虑摩尔纹图案的空间特征外,Zheng 等人[47]提出了可学习的多尺度带通滤波器,以处理频域中摩尔纹图案的多样性.此外,空间域和频域变换也被用来探究摩尔纹图案的互补特性,高效地实现自然图像和纹理的恢复.然而,文献[1,41-47]的方法基于监督学习需要大量的可以成对的干净图像-摩尔纹图像进行训练,其模型性能在很大程度上取决于训练对的特性.为了解决这一限制,最近研究了使用生成性对抗网络(generative adversarial network,GAN)的无监督学习算法[48-50],由摩尔纹图案生成网络和摩尔纹图案去除网络组成.生成网络负责生成摩尔纹图案以构造摩尔纹和干净图像的伪配对集,然后使用生成的伪配对数据集以有监督的方式对摩尔纹图案去除网络进行训练,以有效地去除摩尔纹图案.
综上所述,摩尔纹图案去除算法主要包括基于传统信号处理方法和基于深度学习方法.鉴于摩尔纹图案的频率分布复杂、颜色通道幅度的不平衡以及外观属性不同等特点,深度学习方法在摩尔纹图案去除方面的性能更加出众.除了如何构造有效的摩尔纹图案去除网络结构外,大规模图像对的基准数据库构建对于摩尔纹去除算法的研究和评估也具有重要意义.
本文的主要贡献包括3 个方面:
1)系统梳理了摩尔纹图案去除方法的研究脉络,并进行合理的分类归纳总结;
2)基于相同的公开基准数据库,选择主流的基于深度学习方法进行算法实现和性能对比分析,并总结了相应方法的优缺点;
3)对目前的摩尔纹图案去除算法的研究现状进行总结,并对未来的研究方向进行展望.
1 基于先验知识的方法
1.1 图像滤波
当使用智能手机或数码相机等设备拍摄屏幕图像时,由于显示设备像素和摄像头传感器网格之间的混叠,导致传感器对场景图像产生欠采样,因而产生频率干涉的摩尔纹图案.为此,数码相机开发商提出了一种光学低通滤波器(optical low pass filter, OLPF)方案[12],主要是使用2 个透镜将光信号折射至2 个方向,从而降低信号源的频率以避免混叠.在此基础上,Schoberl 等人[13]计算求得了一组可以达到最小信号频率混叠和最好图像分辨率的滤波器参数.除了OLPF 这种前置滤波方法以外,“后处理”的滤波方法也在专业领域得到了应用.
Wei 等人[28]提出了一种从扫描透射X 射线显微镜图像中滤除摩尔纹图案噪声的后处理方法.该方法包括使用局部中值滤波器半自动检测傅里叶振幅谱中的谱峰,以及使用高斯陷波滤波器消除谱噪声峰值.文献[30]通过使用DoG 对傅里叶图像进行滤波,分析图像中的摩尔纹图案来识别人脸欺骗.尽管高频滤波器可以检测摩尔纹图案,但它无法将其与其他感兴趣的高频对象区分开,这可能会导致误报.Sidorov 等人[31]通过研究摩尔纹变形模型,基于图像傅里叶频谱幅值的阈值化设计了非线性滤波器,解决通过硬件设备在电影到视频的数字转换过程中出现的摩尔纹干扰问题,以减少由于摩尔纹图案的非平稳性而可能出现的振铃伪影的影响.基于扫描半色调图像模型,Sun 等人[33]提出了一种基于自适应滤波的去网纹方法,从扫描图像中恢复出高质量的连续色调图像.首先,采用基于图像冗余的去噪算法来降低打印噪声和衰减失真;然后,使用扫描图像的屏幕频率和局部梯度特征进行自适应滤波;最后,使用边缘保留滤波器进一步增强边缘的清晰度,以恢复高质量的连续色调图像.文献[28-33]的方法均将摩尔纹当成了一种高频噪声,通过去除噪声的方式达到摩尔纹去除的目的.然而,与噪声不同的是,摩尔纹图案广泛分布在图像的各个频带,传统的基于图像滤波的方法并不能完全解决摩尔纹去除的问题.
1.2 图像插值
拍照设备传感器表面覆盖了CFA,传感器则具有感知光线不同色彩强度的能力,其中每个滤光片仅允许RGB 3 原色中的其中一种颜色通过,即CFA仅仅采集到了原始图像1/3 的信息量.为了重建原始图像,需要利用插值的方法恢复另外2 个颜色,这种方法也称为去马赛克.通过利用颜色通道之间的相关性,邱菊[16]提出了一种基于图像色差的插值算法进行图像摩尔纹的去除,并通过将向量的概念引入到插值算法中实现了RGB 通道的3 维插值,恢复后的图像更加平滑、更接近实际值.在文献[16]的基础上,邱香香[17]则利用自适应方法选择关联度高的颜色分量来协助判断通道插值方向,图像插值结果更为合理.Hamilton[19]通过计算图像亮度及色度的相近程度确定针对图像的插值方法;Kimmel[20]提出了以不同权值为基础的插值方法,权值与邻域内边缘的信息密切相关,每个像素缺失的颜色分量由邻域内像素的颜色分量按照不同的权值计算得到.此外,Hibbard[18]利用图像在水平和竖直方向上的亮度和色度差计算梯度,然后将得到的梯度值与事先设定的阈值进行比较来确定针对亮度和色度进行插值的方向,最后根据方向做插值运算.这类方法得到的恢复图像能够较好地保留图像前景部分的边缘细节特征,但算法实现过于复杂,尤其难以在移动设备中实现.
1.3 图像分解
另外一类常用的“后处理”即为基于图像分解实现摩尔纹图案的消除.Liu 等人[23]提出了一种低秩稀疏矩阵分解模型,实现织物图像摩尔纹的消除.通过对纹理分量和摩尔纹分量分别进行空域和频域分析,发现摩尔纹分量分布集中,几乎不与纹理分量的能量混合,于是对纹理分量添加低秩先验约束,对摩尔纹分量添加稀疏先验约束以及在其频域分布内添加位置约束,从而区分摩尔纹分量和纹理分量.后来,Yang 等人[51]改进文献[23]所提算法,从数码相机拍摄织物图像出现摩尔纹的成像原理入手,发现伪彩色波纹状的摩尔纹主要存在于R,B 这2 个通道,G通道的摩尔纹分量较少,于是将文献[23]中的方法应用于G 通道的图像信息,再通过RGB 三通道间的相关性,借助已经恢复的G 通道图像,并应用导向滤波算法恢复R,B 通道图像.Ok 等人[52]提出了一种纸质支票上的摩尔纹消除方法,通过前景提取、摩尔纹检测和摩尔纹消除等操作提高图像质量.Yang 等人[24]以摩尔纹和背景图像是加性关系为前提,并结合屏摄摩尔纹的3 通道成像差异和结构相似性,提出了联合小波域导向滤波和基于高斯混合模型(Gaussian mixed model, GMM)的多相图层分解模型以消除屏摄摩尔纹图案.
屏摄图像I可以看作是背景图层B、摩尔纹图层M以及方差为 σ2的高斯噪声n的叠加,假设有加性模型[17]为:
该模型引入了2 个基于 GMM 的图像先验,分别对背景图层和摩尔纹图层进行规则化.于是该问题转化为最小化问题:
在实际情况下,摩尔纹分量与纹理分量在频域存在能量混叠,因此基于图像分解方法容易将纹理信息误判为摩尔纹成分,纹理恢复图像中存在轻微的振铃效应.另外,由于导向滤波算法本身固有的缺陷,容易导致恢复图像的局部出现光晕现象.
基于传统信号处理的方法探究了摩尔纹图案的成因以及相关特性的先验知识,可以用于特定场景下的摩尔纹图案自动去除,各类方法的具体对比分析如表1 所示.然而鉴于摩尔纹图像本身具有分布不规则的特性,传统方法很难将分布在不同频段的摩尔纹分量去除干净,因此该类方法的摩尔纹图案自动去除性能还需要进一步提升.
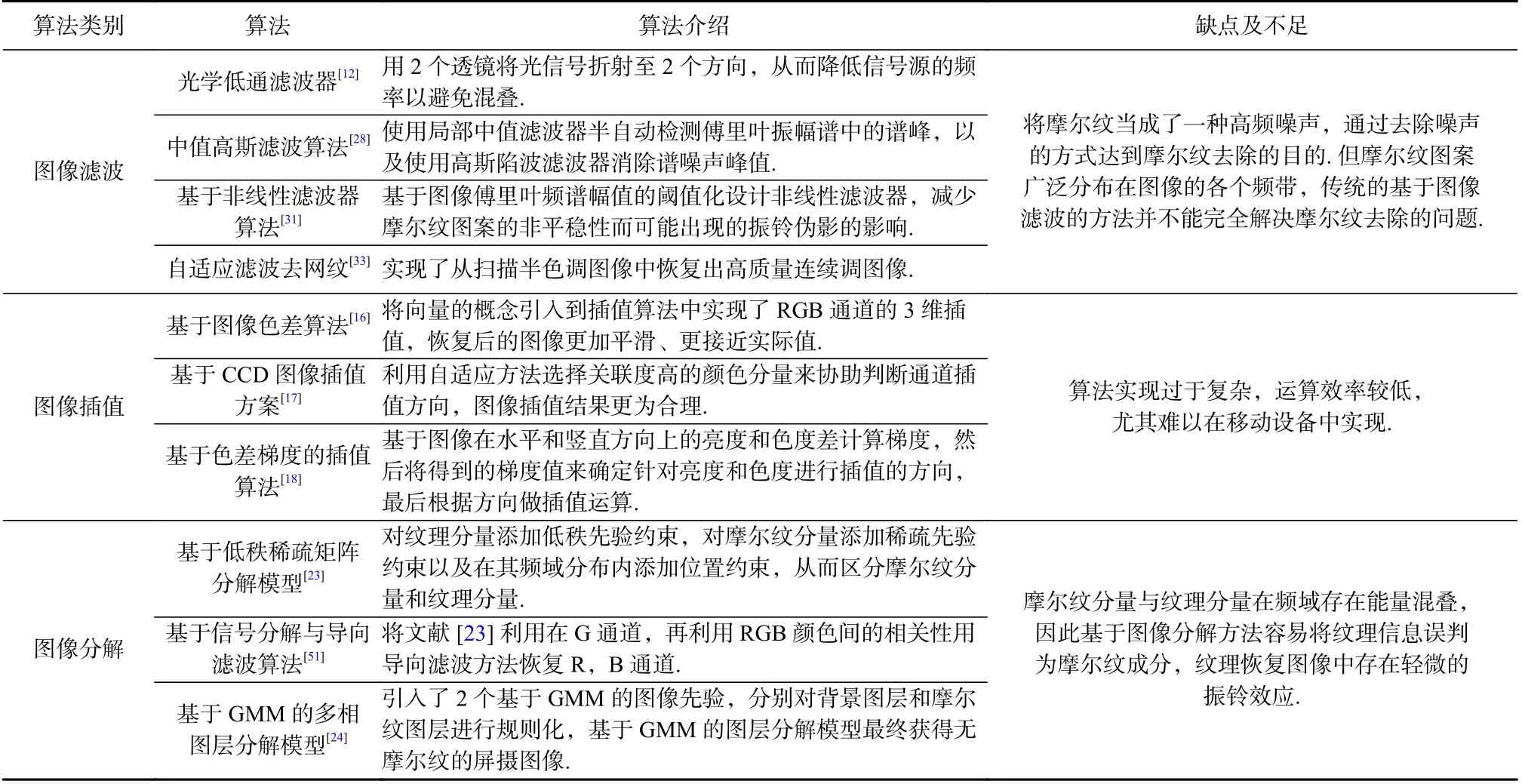
Table 1 Comparative Analysis of the Morié Removal Algorithms Based on Prior Knowledge表1 基于先验知识的摩尔纹去除算法对比分析
2 基于深度学习的方法
2.1 基于卷积神经网络(CNN)方法
基于CNN 的摩尔纹去除方法主要包括基于图像空间域的分析模型和基于图像频域的分析模型,以下分别选取具有代表性的网络结构模型进行介绍.
2.1.1 基于图像空间域的CNN 模型
由于摩尔纹图案跨越很宽的频域范围,Sun 等人[40]最先尝试利用CNN 去除摩尔纹图案,提出了一种基于DMCNN 的摩尔纹去除方法,其网络结构如图2 所示.该网络共有5 个平行的分支,最顶层的分支是在输入图像原始的分辨率下处理,下层的分支通过由上层分支做下采样得到.每个分支分别做各自的卷积操作,最后进行反卷积运算将各个分支的结果上采样到原始图像的分辨率后相加,从而得到输出的恢复图像.Liu 等人[41]提出了由1 个粗尺度网络和1 个细尺度网络组成的2 段式摩尔纹去除方法DCNN(deep CNN),在粗尺度网络上对输入图像做降采样,利用堆叠的残差块去除摩尔纹,然后利用细尺度网络上采样至原始的分辨率.
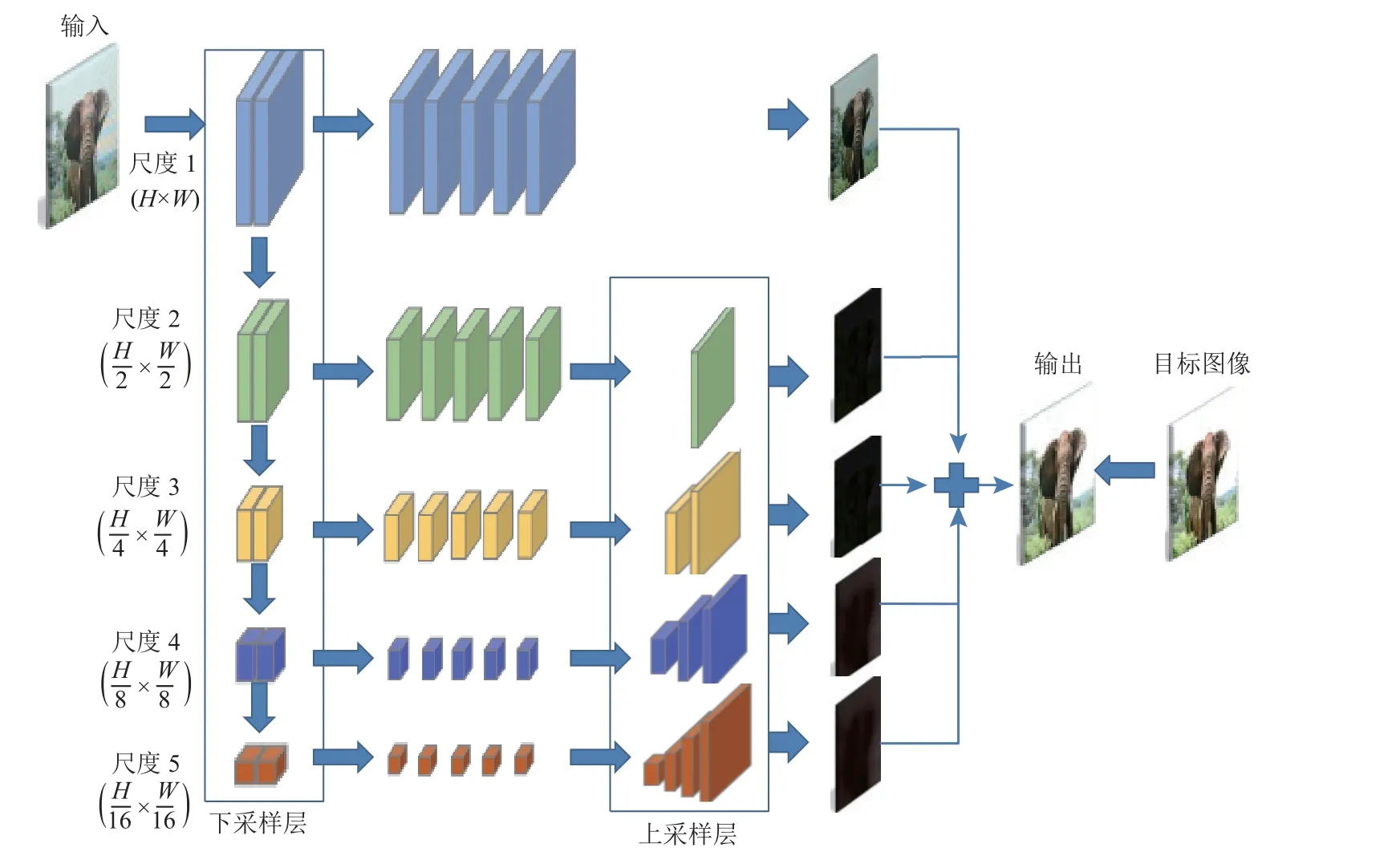
图2 DMCNN[40]模型架构Fig.2 The architecture of DMCNN[40] model
以DMCNN 为基础,为了利用不同尺度特征映射之间的关系,Gao 等人[42]提出了一种基于深度学习的多尺度特征增强(multi-scale feature enhancing, MSFE)摩尔纹去除网络模型,并利用多尺度的结构从多个分辨率上提取与摩尔纹无关的上下文.该方法以U-net网络模型[53]为基础,首先利用残差网络模块,将输入图像下采样到4 个不同的尺度中,每个分支在特征增强处理过程中,实现将所在分支的特征与所有低于所在分支分辨率的特征相融合,最后将每个分支利用残差模块做上采样处理,不同分支的采样结果融合后得到最终的输出图像.
针对摩尔纹图案的频率分布复杂、颜色通道幅度的不平衡以及外观属性不同等特点,He 等人[43]提出了MopNet(Moiré pattern removal neural network)神经网络模型用于摩尔纹图案去除,具体包括:
1) 多尺度特征聚合.首先提取图像的多尺度特征,然后通过级联[54]和SE (squeeze-and-excitation) 块[55]进行特征融合.SE 块通过计算每个通道的归一化权重来重新加权特征图,所产生的聚合特征可以用于如下数学方法表示:
其中S E为SE 块操作,Cat表示串联,Fi表示从多尺度提取器gm获得的不同频带的特征图,NUi是用于将特征图转换为相同空间大小的非线性上采样.
2) 信道方向目标边缘预测器.利用网络来预测无摩尔纹目标图像的通道方向边缘映射Ep,并使用Sobel 算子将每个颜色通道的Esr,Esg,Esb的单独边缘映射用于增强源图像Is,边缘预测器为
其中ge为信道边缘预测器,Epr,Epg,Epb表示R,G,B信道的预测边缘图.
3) 基于属性的摩尔纹模式分类器.摩尔纹图案的精确描述可以更好地指导学习过程,因此,使用多标签分类器C来描述摩尔纹图案的频域C0、颜色C1和形状C2这3 个外观属性,并通过连接3 个上采样标签映射获取属性信息:
然后将这种模式属性的预测输入到目标输出的推理中,为摩尔纹图案的外观提供辅助指导.
MopNet 的所有核心组件都是专为摩尔纹图案的独特特性而设计的,包括使用多尺度特征聚合以解决复杂频率问题、使用通道方向的目标边缘预测器以检测颜色通道之间的不平衡幅度,以及使用属性感知分类器以表征不同外观,并更好地建模摩尔纹图案.
为了克服MopNet 以及MSFE 模型存在的多尺度信息交换和融合的不足,Yang 等人[44]提出了一种基于高分辨率的摩尔纹去除网络(high-resolution deMoiré network,HRDN),以充分探索不同分辨率特征映射之间的关系.HRDN 由3 个主要部分组成:并行高分辨率网络、连续信息交换模块和最终特征融合层,其结构如图3 所示.HRDN 网络是一种带有残差块的并行多尺度架构,它可以在处理较低分辨率的同时保持全分辨率,并处理不同尺度的不同频率.为了充分利用不同特征图之间的关系,HRDN 使用信息交换模块和最终特征融合层在整个网络中不断地交换信息,以充分融合从低层到高层的特征,反之亦然.通常情况下像素损失函数会导致过度平滑,从而减少细节和边缘纹理.为此,HRDN 通过定义边缘增强损失函数来保留边缘细节,L可以表示为
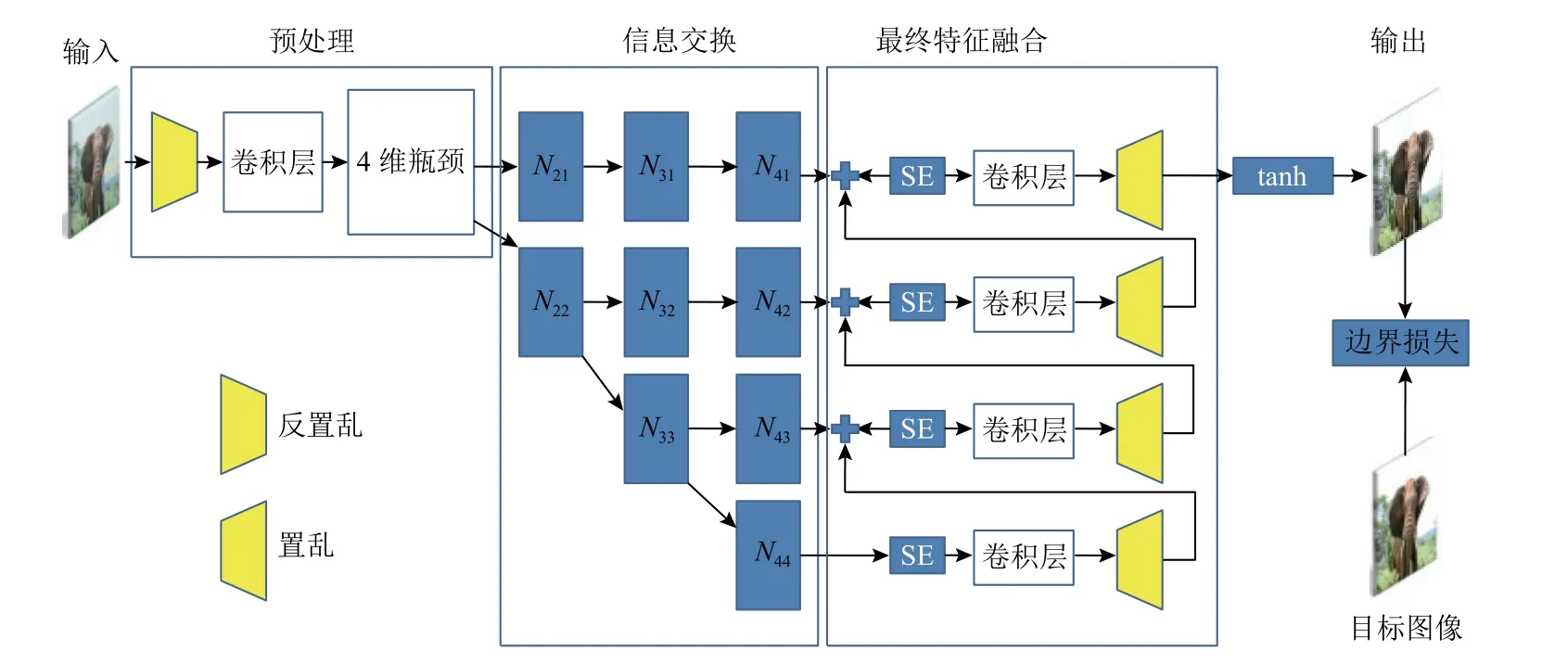
图3 HRDN[44]模型架构Fig.3 The architecture of HRDN[44] model
其中CLoss表示L1 Charbonnier 损失,S Loss表示L1 Sobel 损失,分别定义为:
其中N代表批量大小,和Y分别表示HRDN 的输出去摩尔纹图像和原始背景干净图像.
HRDN 模型在图像分解和图像融合中都保留了摩尔纹分量在不同尺度下的综合特征,摩尔纹去除效果有了明显改进.但是在每一个尺度中,仅通过一系列卷积操作,无法提取完整的特征信息.为此,Cheng等人[45]提出了一种基于多尺度动态特征编码的摩尔纹去除网络(multi-scale convolutional network with dynamic feature encoding for image deMoiréing, MDDM).该算法首先利用降采样的方式将输入图像分成6 层尺度,分辨率最高的一层仅做卷积运算,将基于通道的动态特征编码的残差模块作用于从第2 层到第6 层尺度的分支,以实现在复杂的纹理背景下区分干净图像与被摩尔纹污染的图像数据.MDDM 通过动态特征编码来增强模型处理动态复杂纹理的能力,并将全局残差学习方法应用于网络中每个分辨率的分支;它使用残差块在每个特征级别和频带上模拟干净图像和摩尔纹图像之间的差异,即每个分支上的摩尔纹图案.在动态特征编码的过程中,利用自适应实例归一化(adaptive instance normalization,AdaIN)方法[56]将额外的旁路分支引入至每个主干尺度分支中,以对不同空间分辨率的图像特征进行编码.具体地,在AdaIN 中,首先计算特征图的均值和方差:
其中H和W分别表示特征图的高度和宽度,和是动态特征编码分支中第i个编码层的特征xenc的均值和方差.在计算摩尔纹图案的统计值后,MDDM 使用这些值通过AdaIN 动态调整主干分辨率分支的参数:
其中 μi和表示来自主干分支的统计信息,xi表示来自主干分支中第i个残差块的特征图.
在MDDM 的基础上, Cheng 等人[46]又进一步提出了改进的MDDM+模型.整个网络由原来的6 个分支减少为3 个分支,每个分支中基于通道的动态特征编码的残差模块的数目保持一致,这样可以大幅度减少存储模型所需的参数数目,同时也改进了模型在不同分辨率的尺度间参数不平衡的现象.另外,考虑到摩尔纹的频域分布特征,引入了基于小波分解的特殊损失函数,即分别对网络的输出图像和ground truth 图像I做小波变换,小波损失表示为
其中N表示一个批量大小, ε为一个常数, ε=E-6,W即小波分解操作.
综上,除了将单幅图像作为输入外,Liu 等人[1]提出了一种基于多帧及多尺度的摩尔纹图案去除(multiframe and multi-scale for image deMoiréing, MMDM)网络.MMDM 使用多幅图像作为输入,多尺度特征编码模块用于低频信息增强.MMDM 有3 个关键模块:新设计的多帧空间变换网络(multiframe spatial transformer network, M-STN)、多尺度特征编码模块(multiscalefeature encoding module, MSFE)和增强非对称卷积块(enhanced asymmetric convolution block, EACB).其中M-STN 自动对齐相同场景下的多帧输入图像,MSFE用于多频率信息的提取,最终EACB 用于图像的重建.在NTIRE2020(New Trends in Image Restoration and Enhancement 2020)挑战赛中,本方法在摩尔纹去除赛道上获得第2 名.
2.1.2 基于图像频域的CNN 模型
除了针对摩尔纹分量在空域上的分布特征展开研究外,一些学者还尝试提取摩尔纹分量在图像频域内的特征并进行摩尔纹去除[47,57-61].Zheng 等人[47]认为摩尔纹去除的过程可通过式(12)表示
其中Imoire与Iclean分别为包含摩尔纹的污染图像和去除摩尔纹后的干净图像,Nmoire为污染图像中的摩尔纹分量,ψ-1是ψ的反函数,即将污染图像中的颜色色调恢复为原始干净图像色调.基于此理论提出的基于多尺度带通CNN(multi-scale bandpass CNN, MBCNN)网络分别解决了2 个子问题:1)纹理恢复问题.在摩尔纹纹理去除模块(Moiré texture removal block,MTRB)中集成了一种可以学习的带通滤波器,以学习去除摩尔纹前后的频率特征.2)颜色恢复问题.首先利用全局色调映射模块(global tone mapping block,GTMB)校正图像的全局色彩,然后利用局部色调映射模块(local tone mapping block, LTMB)对局部色调逐个进行像素级别的微调.模型首先将输入图像分成4 个大小相等的子图像,网络结构由3 个分支构成,每个分支依次执行特定比例的摩尔纹去除和色调映射,最终输出上采样后的图像,并与上层分支融合.在前2 个分支中,将当前分支的特征与下一层分支的输出结果相融合,然后再进行一系列的色调处理和摩尔纹去除,以消除因缩放操作引起的纹理和颜色错误.
摩尔纹分量Nmoire表示为
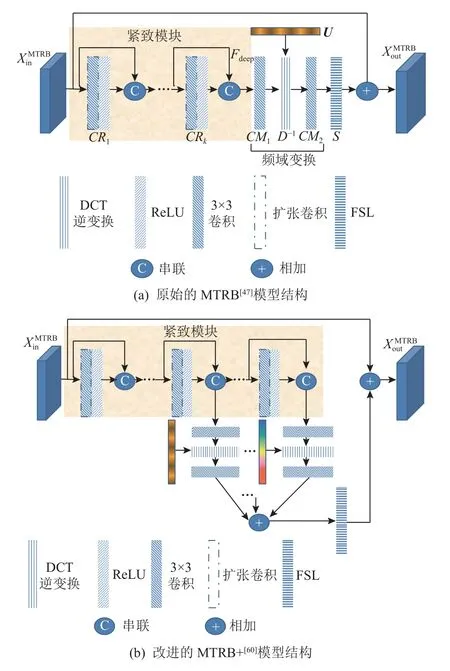
图4 原始的及改进的MTRB 模型架构Fig.4 Architecture of original and of improved MTRB models
在损失函数中引入了改进的Sobel算子损失(advanced sobel loss, ASL),定义为
在提取摩尔纹分量特征时,MBCNN 中的每个摩尔纹去除模块都用一组相同的权值作用于经过一系列卷积运算得到的频谱中.鉴于摩尔纹的多尺度频域分布特征,Zheng 等人[60]在原有的MBCNN 基础上做了2 方面改进,这里称为MBCNN+:
1) 将摩尔纹去除模块MTRB 中带通滤波器LBF 变为基于不同块大小的带通滤波器(multi-blocksize LBFs),即由原来经过k个扩张卷积运算后的结果进行最终的一次频域反变换,转变为每一次扩张卷积操作后都进行一次频域反变换,以达到学习摩尔纹分量不同尺度、不同频域特征的目的,最后将k个不同尺度结果累加后送入FSL,改进后的MTRB+结构如图4(b)所示.
2) 在计算损失函数时,由原来的ASL运算变为基于不同扩张尺度的ASL,即DASL:
Liu 等人[61]设计了一种基于小波域的双分支网络(wavelet-based dual-branch network,WDNet).Liu 等人认为在频域中更容易去除摩尔纹图案,首先使用小波变换将包含摩尔纹的输入图像分解为不同的频带;经过小波变换后,摩尔纹在某些小波子带中更加明显,在这些子带中,摩尔纹更容易去除.该模型具有密集分支和扩张分支的双分支网络,分别负责恢复近距离和恢复远距离信息.同时,WDNet 还设计了一种空间注意力机制,称为密集分支中的方向感知模块,以突出具有摩尔纹图案的区域.
2.2 基于生成式对抗网络(GAN)方法
流行的基于监督学习的方法需要大量的成对训练图像,这在实际应用中难以获取和对齐.为此,基于GAN 的非监督学习方法被应用于摩尔纹去除[48-50].Yue 等人[49]提出了一种无监督的生成式对抗性摩尔纹去除网络(unsupervised generative adversarial network for Moiré removal,MR-GAN),这是基于无监督学习的摩尔纹去除的首次尝试,为使用未配对的训练数据进行无监督摩尔纹去除开辟了一条途径.
具体地,在进入网络训练之前,首先根据图像不对称的径向梯度分布[64]去除摩尔纹图像中存在的晕角,校正后的图像亮度比原始屏幕拍摄图像更加均匀.在MR-GAN 网络中存在2 个生成器,即摩尔纹去除生成器和摩尔纹重构生成器.摩尔纹去除生成器Gm→c是将一幅摩尔纹图像Im转化成相应的干净图像;摩尔纹重构生成器Gc→m是将一幅干净的图像转化为摩尔纹图像.Gm→c和Gc→m形成一个循环,并受到循环一致损失的约束,以在没有训练对的情况下同时训练生成器Gm→c和Gc→m.这2 个生成器具有相同的网络结构,核心结构均是9 个残差模块的堆叠.同时,网络同样存在2 个结构相同的鉴别器:在大尺度上鉴别摩尔纹图像与干净图像,在小尺度上鉴别摩尔纹图像与干净图像,核心结构是数个卷积层+ NL(non-local)层[65]+Leaky ReLUs 的堆叠,最后再加1 层卷积.为了训练MR-GAN,集成了许多损失函数来学习真实的无摩尔纹图像生成器和有效的鉴别器,具体包括:
1) 生成器的损失函数.为了在没有真实监督的情况下学习有效的生成器,该方法首先提出了一组自我监督的损失函数ϑself,包括在像素级别 ϑpcyc和特征级别 ϑfcyc的循环一致损失、身份损失 ϑidt、余弦相似度损失ϑcos以及内容泄漏损失 ϑcl.因此,自监督损失表示为
其中 λ1, λ2, λ3, λ4, λ5分别为加权参数.另外,与传统的对抗性损失不同,该方法提出了一种双尺度对抗性损失分别对应于MR-GAN 中的2 个鉴别器组.为了确保网络在训练中稳定,利用 LSGAN 损失函数[66]定义大尺度特征的对抗损失:
其中ϑself确保生成的结果包含足够的原始信息,和指导生成器得到预期结果.
Park 等人[50]提出了一种基于端到端的非对称循环网络(an end-to-end unpaired cyclic network,EEUCN),该方法使用未配对的摩尔纹图像和干净的图像数据集.令 χ和 γ分别表示摩尔纹图像集和干净图像集,X∈χ和Y∈γ分别表示摩尔纹图像和干净图像,未配对图像去摩尔纹的目标就是学习从摩尔纹图像到干净图像之间的映射.如图5 所示,EEUCN 网络由2 种类型的GAN 组成:图5(a)所示的摩尔纹生成网络和图5(b)所示的摩尔纹去除网络.摩尔纹生成网络主要学习映射GM:γ →χ,通过添加摩尔纹伪影来降低干净图像质量;摩尔纹去除网络则是学习映射GD:χ →γ,以从摩尔纹图像中去除摩尔纹伪影干扰.摩尔纹生成问题可以分为像素强度退化和摩尔纹图案生成2 个子问题,相应地,屏摄摩尔纹图像生成器模型GM可以表示为
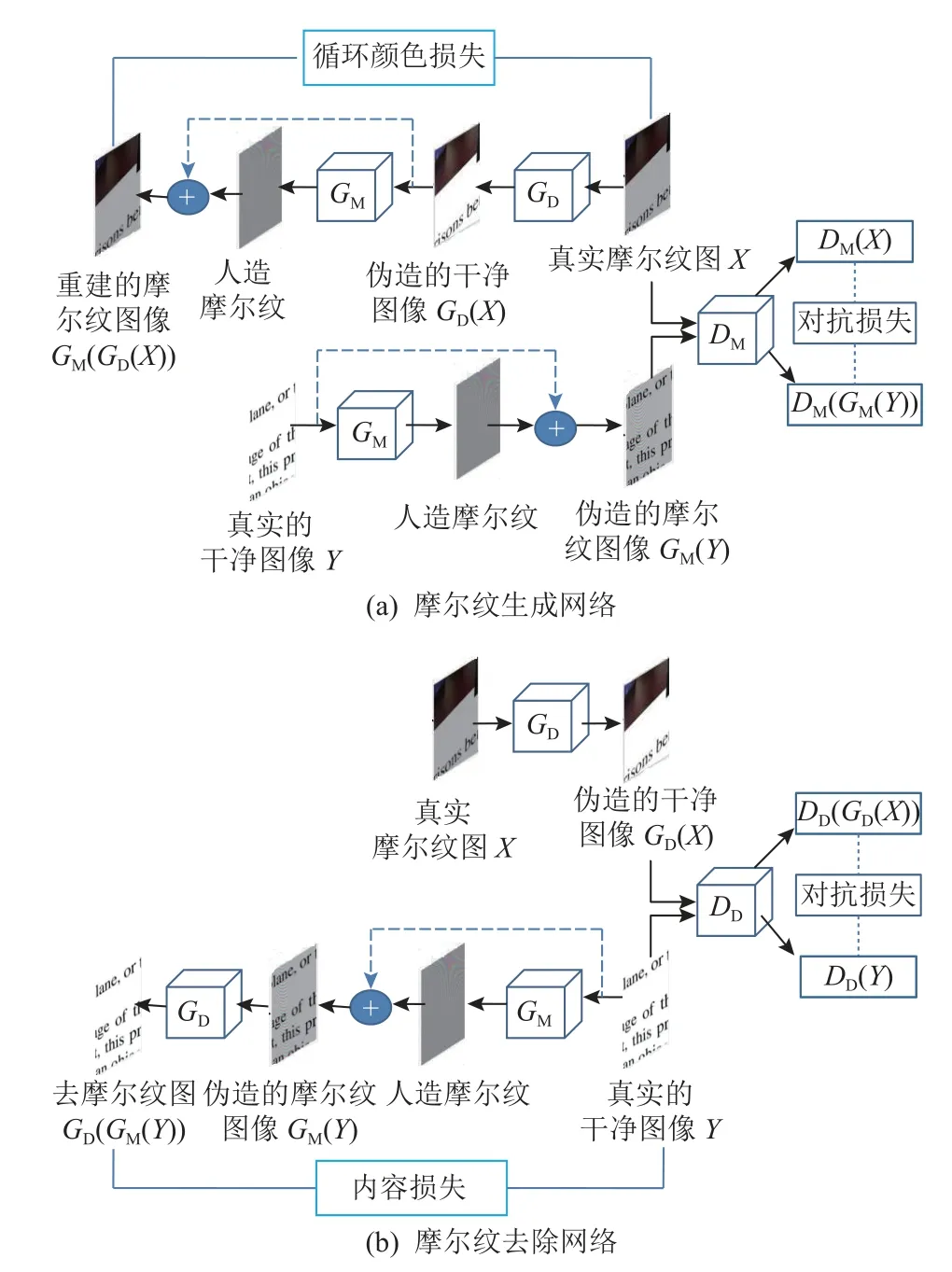
图5 EEUCN[50]结构Fig.5 The architecture of EEUCN[50]
其中m表示摩尔纹图案, α用于控制图像对比度降低的幅度,α ∈(0,1].给定一张干净的图像Y,强度退化模块估计全局强度退化参数α,而摩尔纹生成模块生成摩尔纹图案m.
摩尔纹生成网络构造完伪配对集{γ,GM(γ)}后,EEUCN 利用学习的生成器GM以有监督方式训练摩尔纹去除网络,并进行摩尔纹图案去除,如图5(b)所示.相应地,摩尔纹去除模型GD可以表示为
因此,类似于上述摩尔纹生成网络,摩尔纹去除问题也可以分为2 个子问题:摩尔纹伪影去除和全局强度恢复.给定摩尔纹图像αY+m,摩尔纹去除模块去除摩尔纹图案m,强度恢复模块估计全局强度恢复参数 α.
在EEUCN 中,摩尔纹生成网络是在已知GD的情况下训练GM,网络中的鉴别器DM用于区分真实的摩尔纹图像与网络生成的摩尔纹图像;反之,摩尔纹去除网络是在已知GM的情况下训练GD,网络中的鉴别器DD用于区分真实的干净图像与网络去除摩尔纹后的图像.2 个网络的整体结构比较类似,主要区别在于循环颜色一致性是在Y和GD(GM(Y))之间计算的,即所谓的内容损失.具体地,在摩尔纹生成网络中,循环颜色损失ℓcycle被定义为重建的摩尔纹图像和原始摩尔纹图像之间的 ℓ1范数,由式(22)给出:
不同于生成网络,额外的循环损失ASL运算被用于训练摩尔纹去除网络,由式(23)给出:
其中Si(·)表示水平、垂直和2 个对角滤波器中Sobel滤波中第i个滤波器得到的边缘图.因此,式(23)中的ℓAS L量化了重建图像和原始干净图像的边缘图之间的循环颜色一致性.由于自然图像包含有意义的边缘信息,ASL运算用于去除已被检测为虚假边缘的摩尔纹伪影.由于摩尔纹图像的边缘图包含大量噪声,对应于摩尔纹伪影,很难区分真实的和生成的摩尔纹图像的边缘图.因此,EEUCN 只使用ASL运算来训练摩尔纹去除网络.
3 训练数据集构建
摩尔纹去除网络模型的训练数据集质量在很大程度上影响了深度学习方法的处理性能,因此训练数据的收集和对齐工作也至关重要.现实生活中人们通常会通过屏幕拍照和屏幕录像的方式获取屏摄图像,而将视频文件一般转化为带有摩尔纹图案的图像帧序列,因此本文主要聚焦于屏摄图像中的摩尔纹图案去除研究.目前摩尔纹图像训练数据集的构建主要从正向和反向2 个角度展开.所谓正向构建是指通过手机设备拍摄电子屏幕得到包含摩尔纹的屏摄图像,然后利用图像处理方法将屏摄图像进行矫正预处理,并将预处理后的摩尔纹图像与原始的干净图像对齐形成图像对,例如TIP2018 数据集[40]与MRBI 数据集[67].反向构建方式是指利用马赛克采样、重上色等操作处理原始的干净图像得到被污染的图像,用于模拟摩尔纹图案生成,从而形成干净图像和摩尔纹图像的图像对,例如在多个国际大型的摩尔纹图像去除竞赛中用到的LCD Moiré数据集[68]及CFA Moiré数据集[69].表2 为4 种数据集间的对比和总结,下面分别对这4 种训练数据集的构造过程进行简要介绍.
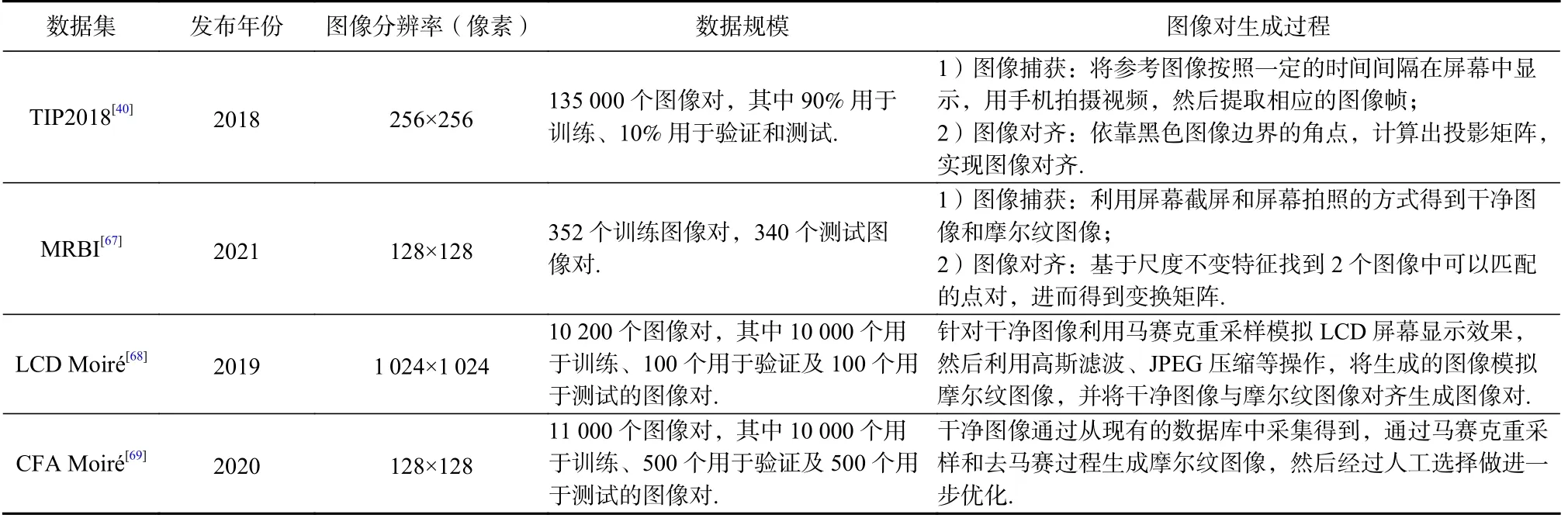
Table 2 Summary and Comparison of Different Training Datasets表2 不同训练数据集的总结对比
TIP2018 数据集主要包含135 000 个图像对,每个图像对包含1 幅被摩尔纹污染的图像及其对应的未污染参考图像,其中未受污染的参考图像来自ImageNet ISVRC 2012 数据集的100 000 幅验证图像和50 000 幅测试图像.在所有图像中,90%用作训练集,10%用于验证和测试.收集这些数据的流程如图6所示,主要包括2 个步骤:图像捕获和图像对齐.1)图像捕获.如图6(a)所示,每个参考图像T用黑色边框增强并显示在计算机屏幕的中心位置,以最大程度减小受摩尔纹效应的影响.为了增加图像对齐过程中可以使用的角点数量,该方法进一步从黑色边框的每条边挤出一个黑色块,并用纯白色填充黑色边框(和块)之外的屏幕其余部分,这使拍摄者能够轻松地检测捕获图像中的黑色边框.在图像采集过程中,拍摄者使用不同型号的智能手机和显示器屏幕设备,并随机改变手机和计算机屏幕之间的距离和角度,确保在不同的光学传感器上捕捉到的摩尔纹图案S具有多样性.为了提高图像捕获效率,将参考图像T按照一定的时间间隔在屏幕上连续显示,并使用手机记录连续显示图像的视频,然后将拍摄视频中的帧提取为摩尔纹图像.2)图像对齐.实际上,该方法依靠沿着黑色图像边界的角点来完成图像对齐,捕获图像S和参考图像T中的对应点通过单应性关联,并用具有 8 个自由度的 3×3 投影矩阵表示.为了提高配准精度,附加到图像边界的4 个黑色块将非共线对应点的数量从4 个增加到20 个,利用这些角点来计算投影矩阵,并进一步对齐每对图像.为了检测角点,屏摄图像首先进行二值化处理,利用传统Harris 角点检测方法沿黑色图像边界的最外边界搜索角点.然而,由于摩尔纹伪影的存在,图6(b)所示的20 个角点有时无法可靠地被检测到,其中某些边缘像素可能被错误地检测为角点.经过额外的假角点和重复角点消除处理后,所有的20 个角点都可以被成功检测到,如图6(c)所示.最后,通过计算出的投影矩阵,该方法可以对齐每个图像对,配准结果如图6(c)(f)所示.TIP2018 数据集是第一个被大规模用于摩尔纹去除网络的训练数据集,后续很多工作都是基于该数据集进行算法优化和对比评测.

图6 图像采集[40]Fig.6 Image acquisition[40]
文献[67] 指出TIP2018 数据集在视频模式下录制往往会使重新捕获的帧变亮,这使得图像对之间的亮度差异很小,这与实际的屏幕拍摄图像效果不符.此外,为了应用图像对齐算法,TIP2018 数据集中的参考图像被要求显示在平板显示器的屏幕中心位置(以能够拍摄全部的黑色边区域),这也限制了摩尔纹图像的种类.为了克服上述缺陷,文献[67]通过5 种不同型号的智能手机拍摄3 种不同类型的显示器屏幕如笔记本电脑、台式电脑的LED 显示屏以及电视的LCD 屏来构建MRBI 数据集,其训练集包含352 幅重新捕获的带有摩尔纹伪影的屏幕图像和相应的原始图像(通过屏幕截图获得).测试集包含由24 种屏幕和相机组合捕获的 340 幅图像,它们代表了各种各样的摩尔纹图像.具体地,在创建训练图像对时,首先对相同内容的屏幕分别通过屏幕截屏和屏幕拍照得到干净图像Io和包含摩尔纹的图像Im;接着对Im缩放使Io和Im这2 幅图像大小相似;然后利用基于尺度不变的特征变换(scale-invariant feature transform, SIFT)[70]找到2 幅图像中可以匹配的一系列点构成点对的集合 Ω;然后,随机从 Ω中选出4 个点对,用RANSAC 算法[71]估计Io和Im之间的变换矩阵H, Ω中的其他点对用于验证H的准确性.验证方式是点与的距离是否小于预先设置的阈值 ε,若是,则点对与被称之为内点.重复上述过程直到所求的变换矩阵H满足使 Ω中内点的数目最多.最后对Io做矩阵为H的变换得到一个训练图像对.通过上述方法构造的MRBI 数据集为图像去摩尔纹和亮度改善提供了基准,并将会激发更多关于这一主题的工作.
LCD Moiré数据集[68]包含10 200 个合成生成的图像对(由摩尔纹退化的图像和干净的原始图像组成,10 000 对用于网络训练、100 对用于验证及100对用于测试),是专门为举办首次图像去摩尔纹挑战赛而创建的.该挑战赛是与ICCV 2019 联合举办的图像处理进展(Advances in Image Manipulation,AIM)研讨会的一部分.LCD Moiré数据集中的干净图像是从ICCV(IEEE International Conference on Computer Vision),ECCV(European Conference on Computer Vision),CVPR(IEEE Conference on Computer Vision and Pattern Recognition)等计算机视觉会议论文中收集,由文本、图形或等比例组合的文本/图形组成.摩尔纹图像的生成相当于模拟使用智能手机在显示干净图像的LCD 屏幕上拍照的过程.具体的思路为:经过RGB图像的马赛克重采样处理,以模拟LCD 屏幕显示图像;对图像应用随机投影变换以模拟显示器和相机的不同相对位置和方向,并应用3×3 高斯滤波器;使用Bayer CFA 对图像重新采样以模拟原始数据,并添加高斯噪声以模拟传感器噪声;应用简单的ISP 处理,包括去马赛克(双线性插值)和去噪;使用JPEG 压缩来压缩图像以模拟压缩噪声,将干净图像与摩尔纹图像对齐,并裁剪出图像对.为了确保训练、验证和测试图像集中的内容和摩尔纹图案分布相同,该方法附加了图像内容平衡和摩尔纹分量平衡等后处理操作.
2020 年,CVPR 的图像恢复增强竞赛(NTIRE)提供了一个新的摩尔纹图像训练数据集CFA Moiré Dataset[69],该数据集由10 000 个训练图像对、500 个验证图像对和500 个测试图像对组成.其中干净的图像从现有的图像数据库中采集或者裁剪后得到,图像质量较高,内容涵盖了服装、建筑等高频重复图案.相应的摩尔纹图像通过马赛克重采样和去马赛克过程生成,其中摩尔纹伪影图案出现在图像高频区域.数据集构建分为2 步:首先,通过傅里叶频域中摩尔纹伪影的量化自动选择符合条件的图像对,即测量清洁图像和去马赛克图像之间的频率变化;然后,通过人工选择进一步优化选择的图像对,将已经被污染的干净图像从数据集中删除.
4 实验对比分析
随着不同拍摄设备和显示设备的广泛普及,摩尔纹图像的呈现也趋于多样化.由于摩尔纹图案不规则,且不均匀地分布在图像中的不同空域及不同频域段中,其分布特征无法通过先验知识准确获取.另外,当摩尔纹分量与图像中的纹理分量出现混叠时,基于先验知识的图像处理方法无法将其准确区分,因此基于特定先验知识的传统图像处理方法在摩尔纹去除方面愈加受限.而在训练数据集构建逐渐完善的情况下,深度学习方法的处理性能更加显著,并逐渐成为主流方法.目前的神经网络模型主要利用CNN 卷积神经网络模型和GAN 对抗网络,通过提取空域或频域中的特征信息达到摩尔纹去除的目的.本节主要将基于深度学习的摩尔纹图案去除方法进行简单回顾总结,并分别对各种方法的优缺点进行定性的对比分析.另外基于相同的公开数据集,我们选取了部分代表性工作进行了算法实现,并给出了定量的性能对比结果.
4.1 深度学习方法对比分析
首先,在基于CNN 空域算法中,DMCNN[40]模型和DCNN[41]较早地将深度学习方法应用于摩尔纹图像去除,并实现了不同分辨率分支下的特征提取.由于摩尔纹不规则地分布在图像的多个频段中,因此,提取图像的多尺度特征信息成了学者们的共识.但是此类方法在每一个尺度上提取的特征过于简单,且忽略了不同尺度特征之间的联系,因此具有一定的局限性.例如:当图像中出现大面积彩色条纹分布的摩尔纹时,摩尔纹去除的效果不理想.MSFE[42]模型是基于DMCNN 提出的,其明显的缺陷是仅仅将低分辨率的特征嵌入到了高分辨率特征中,而高分辨率的特征没有融合进低分辨率的特征中,因此对比DMCNN 模型优势不明显.相对于DMCNN 而言,MopNet[43]考虑了更多的摩尔纹图案的不同属性特征,但是没有综合分析这些特征在多个不同尺度间的联系,而且针对边界的提取无法获得复杂的纹理特征.因此,MopNet 无法准确区分出污染图像中的纹理区域和摩尔纹区域.HRDN[44]在上采样和下采样的过程中针对不同的尺度做了较为充分的信息交换,但每个尺度中提取的特征信息不够充分.MDDM[45]模型的分层数目过多,各个尺度之间仍然缺乏信息的交互,同样存在低分辨率分支中没有融合进高分辨率信息的现象.并且高分辨率的分层卷积数目少,低分辨率的分层卷积数目多,理论上应该反过来,因为高分辨率的分支拥有更多的特征.相较于MDDM,改进后的模型MDDM+[46]不仅视觉效果得到明显的改善,而且存储的参数数量由8.01 MB 变为3.57 MB,实用性进一步提高.但相较于HRDN 模型,MDDM+仍存在各分支间缺少信息交互的特点.
在基于CNN 频域算法中, MBCNN[47]在提取摩尔纹分量DCT 频域特征时,每个摩尔纹去除模块可以根据多尺度频域特征采用不同的权值.相对于MBCNN,MBCNN+[60]在网络结构设计和损失函数中改进了不同尺度特征提取和融合的方式,因此取得更好的输出图像视觉效果.WDNet[64]则是基于小波域实现,与傅里叶变换和离散余弦变换相比,小波变换既考虑了空间域信息,又考虑了频域信息.在小波合成中,不同的小波带代表如此广泛的频率范围,这是几个卷积层即使是大核也无法实现的.
基于GAN 的摩尔纹图案去除方法是最近2 年提出的,较好地解决了CNN 方法依赖大量对齐的训练对的问题.该类方法的处理性能跟CNN 方法相比还有一定的差距,但为摩尔纹图案去除方法研究提供了一种新的思路.
综上所述,不同的网络模型架构具有各自的优势和劣势,具体的对比分析如表3 所示.
4.2 实验结果讨论
在本节中,我们基于相同的公开的数据集,分别选择不同类别中有代表性的方法进行了算法实现和性能对比实验.CNN 空域算法模型选择:首次使用的DMCNN[40]训练模型;融合多尺度特征聚合、信道方向目标边缘预测器和模式分类器的MopNet[43]训练模型;不同尺度间特征能够较充分融合的HRDN[44]训练模型.在CNN 频域算法模型方面,我们选取了基于DCT 频域特征信息提取的MBCNN[47]训练模型.相应地,在GAN 网络模型中,我们选取了目前性能最好的EEUCN[50]模型.测试环境为torch1.8.0,GPU3090,数据集选用TIP2018 数据集.在摩尔纹图案去除算法性能的评估方面,我们采取了类似ICCV 2019 AIM[69]和2020 CVPR NTIRE[70]竞赛的评判规则,分别计算了在TIP2018 数据集上取得平均的PSNR值和SSIM 值.
首先,在模型预处理阶段,我们在Sun 等人[40]预处理方法的基础上,对TIP2018 数据集中的摩尔纹图像进行了重采样和归一化处理.为了保证每个模型训练数据的一致性和公平性,我们加载了MopNet[43]的预训练模型对上述数据再次进行预处理操作,预处理后的图像样本尺寸统一为256×256 像素.据此,我们分别针对不同的网络模型采取不同的训练方式.
1) DMCNN 方法.使用Adam 优化器,学习率设置为0.000 1,当损失不下降时缩减学习率为原来的90%,共计训练50 个epoch.
2) MopNet 方法.训练模式分为2 个阶段: 第1阶段,训练边缘提取模型和分类模型直到模型收敛,2 个模型分别训练50 个epoch 和20 个epoch;第2 阶段,使用Adam 优化器,学习率最初设置为0.000 2,并随着训练线性衰减,共计训练150 个epoch.
3) HRDN 方法.使用Adam 优化器,学习率设置为0.000 1,当损失不下降或每训练10 个epoch 时下降为原来的50%,共计训练50 个epoch.
4) MBCNN 方法.使用Adam 优化器,学习率设置为0.000 1,共计训练100 个epoch.
5) EEUCN 方法.使用AdamW 优化器,学习率设置为0.000 1,在训练100 个epoch 后,学习率缩减为原来的10%,共计训练150 个epoch.由于EEUCN 是使用unpair 数据集的方法,我们基于文献[50] 提供的LCD Moire 上非成对的数据集进行训练,并使用TIP2018 数据集进行测试.
不同的训练模型在TIP2018 数据集上取得平均的PSNR 值和SSIM 值如表4 所示,其中部分图像在不同模型上得到的去除摩尔纹图像效果如图7 所示.
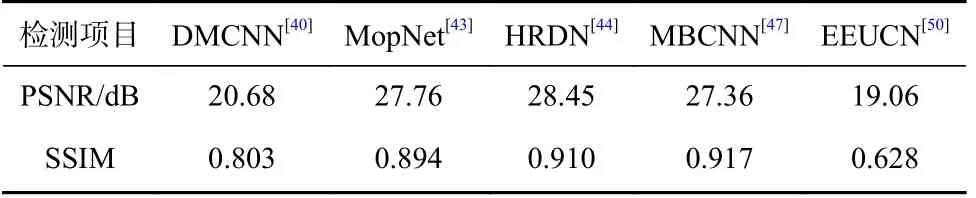
Table 4 Quantitative Comparison of Different Network Models表4 不同网络模型的容量对比

图7 在TIP2018 验证数据集上的对比结果Fig.7 Comparison of results for the validation set in TIP2018
如表4 和图7 所示,DMCNN[40]是利用多尺度卷积神经网络去除摩尔纹图案的初步尝试,在摩尔纹分量的去除和图像色调恢复方面,相比其他模型而
言,该模型输出结果不太理想.EEUCN[50]是利用GAN 网络去除摩尔纹图案的尝试,其思想是先利用摩尔纹生成网络在干净的图像中添加摩尔纹图案,然后利用监督学习方法去除摩尔纹图案.由于模拟生成的摩尔纹图案与真实的摩尔纹图案之间存在一定的差异,当训练数据集和测试数据集不同时,该模型输出的去摩尔纹图像存在较大的颜色失真,例如图7(g)所示的第8 幅图像中的多个颜色分量被误删除.诸如MopNet[43],HRDN[44],MBCNN[47]等有监督的多尺度卷积神经网络则可以得到较理想的图像质量.但由于MopNet 仅通过边界提取区分摩尔纹分量与图像分量,导致如图7(d)中第4 幅图像的前景区域、第5 幅图像的人脸区域、第6 幅图像的翅膀区域、第9 幅图像的瓢虫区域等局部摩尔纹图案去除不干净,另外第8 图像中的复杂区域则产生严重的色调失真.HRDN 在特征提取和融合阶段具有相对充分的信息交换过程,在TIP2018 数据集中取得较高的PSNR 值和SSIM 值.但由于该模型中各尺度特征提取不够充分,当处理包含特殊的复杂摩尔纹图案时,HRDN 方法处理的图像视觉效果不很理想,如图7(e)中的第2 幅、第6 幅中出现了形状复杂的彩色摩尔纹图案,HRDN 未能准确提取出摩尔纹分量.MBCNN 通过提取摩尔纹图像的频域特征,并进行频域中摩尔纹分量去除,同时融入了色调恢复过程,则在有监督学习的卷积神经网络模型中取得了较为理想的视觉效果.其中SSIM 值明显高于其他模型,则说明该模型输出去除摩尔纹图像在亮度、对比度、结构上与原始干净图像保持较好的一致性,如图7(f)所示,MBCNN能够较好地处理各种复杂特殊的摩尔纹图案.
5 总结与展望
图像去摩尔纹是一项重要的图像修复任务,其目的是从污染图像中去除摩尔纹干扰图案并恢复底层干净的图像.传统的基于先验知识的方法具有算法效率高、不需要大规模训练等优点,能够较好地处理频域或空域分布特征相对简单的摩尔纹图案.比如当利用智能手机或者数码相机拍摄布料、织物、瓷砖等高频重复纹理静态图案时,在频域中摩尔纹的能量是集中的,与图像的纹理能量有一定的差距.因此,基于图像分解的方法则可以更好地分离2 种不同能量,进而有效去除摩尔纹图案.对于扫描的半色调图像而言,摩尔纹图案可能会呈现周期性的网纹干扰性质,利用传统图像滤波的方法性能可能会更好;基于图像差值的方法在去除摩尔纹图案的同时,可以更好地恢复图像亮度信息和色彩空间信息.
然而,与图像去噪任务中均匀分布的噪声和超分辨率任务中缺失的高频细节不同,屏幕拍摄的摩尔纹图案具有广泛分布的频谱和复杂纹理的动态特性,这使得图像去摩尔纹任务面临着巨大挑战.传统的基于信号处理的摩尔纹去除方法需要基于特定的先验知识和模型,因此图像修复效果存在较大的提升空间.基于深度学习的摩尔纹去除方法则通过在不同尺度上探究摩尔纹图案和背景图像之间的内在相关性,并考虑不同尺度之间的特征融合,在图像质量改善方面取得较好的性能.但是基于CNN 的网络模型需要大规模的摩尔纹污染图像和原始干净图像的训练集对的支撑,数据集构造的质量也会严重影响算法性能,而相关数据集对的构造难度较大,在很多情况下无法完成.综上,针对目前摩尔纹图案去除方法存在的问题,为了进一步提高网络模型的实用性,以下3 个技术方向值得进一步关注.
1) 摩尔纹成因描述模型构建
在早期阶段,人们对于摩尔纹的研究大多基于数学模型,从摩尔纹的成因出发,研究摩尔纹的频域和空域特征.不同的成像模式也会造成摩尔纹特性表现的差异,通过对摩尔纹成因的深入研究,我们可以构建更为准确的摩尔纹消除模型.一方面,摩尔纹成因分析有利于特定场景下的摩尔纹图案去除.刘芳蕾[21]通过对纹理图像中摩尔纹分量的频域稀疏特性和纹理分量的空余低秩特性的分析,构建图像分解模型实现了纹理层与摩尔纹的分离.张雪[22]针对屏摄图像中摩尔纹能量分布非常分散、高频信息难以区分等特点,并结合屏摄摩尔纹和图像背景的结构性差异,提出了基于GMM 的多相图像分解方法,在保留背景图像结构的同时扰乱摩尔纹结构,从而避免块效应并降低算法的时间复杂度.另一方面,精确的摩尔纹成因描述模型也可以辅助深度学习模型的训练,促进网络结构优化,提升摩尔纹图案消除算法性能.鉴于摩尔纹图案的复杂特性和成因差异,现有描述摩尔纹成因的数学模型缺乏通用性,需要未来进一步的深入研究.
2) 真实场景下的通用摩尔纹去除网络研究
目前基于深度学习的摩尔纹图案去除网络大都是采用实验室环境下采集和模拟生成的数据集进行训练和评估的,在某些情况不能完全适用于现实场景中具有复杂特征的污染图像,模型泛化性能较低.由表2 可知,规模最大的TIP2018 数据集最接近于真实场景下的摩尔纹图案效果,但其图像采集过程也存在图像分辨率低、摩尔纹场景简单、拍摄角度单一等问题.而实际需要处理的摩尔纹图案往往具有分辨率高,且摩尔纹颜色、形状、边界、密度等复杂多变的特点.为此,我们需要从以下方面展开深入研究,以探索真实场景下的摩尔纹图案去除方案:①利用人工智能和计算机视觉技术,在真实场景下构建更大规模的摩尔纹图案数据集,包含不同分辨率、不同场景、不同摩尔纹强度等多种特征;②充分探索不同分辨率特征映射之间的关系,将不同尺度下的摩尔纹颜色、形状、边界、密度等多种特征信息进行融合和交换,然后通过学习和解耦得到更加通用的摩尔纹图案相关语义特征,而忽略无关特征,从而构建高效和高鲁棒的通用摩尔纹去除网络模型结构;③基于对抗神经网络GAN 的训练模型,在网络生成器和鉴别器中引入基于多尺度特征融合的CNN 卷积神经网络,将会成为摩尔纹去除技术的一个重要研究方向.
3) 基于移动终端的泛化应用拓展
随着移动互联网技术的飞速发展和智能移动终端设备的全面普及,利用智能移动终端进行信息捕获、处理、存储和共享等成为主流应用方式,比如图像美化[72]、OCR 识别[73]和水印提取[74]等.由于屏摄图像中通常会受到摩尔纹干扰图案的严重干扰,基于移动终端的摩尔纹去除应用存在诸多不足之处:①硬件设备的多样性和不同设备之间的差异性导致了摩尔纹图案的频域特征分布更加不规则,深度学习网络模型的泛化性能普遍较低;②现有的基于深度学习的摩尔纹去除网络模型大多都是部署在服务器端,其网络结构复杂、训练数据庞大、计算资源配置高,较难直接部署于计算能力有限的移动终端设备;③深度学习算法与移动终端应用结合的研究有待深入,鲜有直接应用于移动终端的轻量级深度学习模型被提出,基于移动终端的摩尔纹去除方法实时性较差.为此,需要在2 个方面进行基于移动终端的摩尔纹去除网络模型的优化和构建:①利用低秩近似分解、网络剪枝和网络量化对已有的深度学习网络进行模型压缩和加速优化;直接设计轻量化的网络结构,并将训练完成的深层网络模型完全运行于移动终端设备.②结合边缘计算技术,通过神经网络前向推理框架[75]将优化后的深度学习模型部署至移动端的应用系统.
总之,基于深度学习的摩尔纹图案去除模型的部署轻量化、计算低配化、性能普适化以及操作实时化将成为移动终端泛化应用的重要研究目标.
作者贡献声明:亓文法提出了文章框架结构和研究思路,并撰写论文;刘宇鑫负责完成实验并撰写论文;郭宗明提出指导意见并修改论文.
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
河北画报(2020年10期)2020-11-26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
英美文学研究论丛(2018年2期)2018-08-27
雷达学报(2018年3期)2018-07-18
太空探索(2016年5期)2016-07-12
火控雷达技术(2016年1期)2016-02-06
电测与仪表(2015年3期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年4期)2000-06-24
