
一种可解释的云平台任务终止状态预测方法
2024-03-23 08:04刘春红李为丽王敬雄张俊娜
计算机研究与发展 2024年3期
刘春红 李为丽 焦 洁 王敬雄 张俊娜
1 (河南师范大学计算机与信息工程学院 河南新乡 453007)
2 (智慧商务与物联网技术河南省工程实验室(河南师范大学) 河南新乡 453007)
近年来,机器学习模型在众多领域中都得到了广泛的应用,并且表现出很好的性能.然而模型的黑盒特性,使其缺乏透明度、可解释性和可信赖性,如果不能从人类的角度对模型决策进行理解,寻找更好的模型最终将沦为试错法.例如在云平台中,对任务的终止状态进行预测时,需要很高的透明度和可信度,这意味着我们需要能够解释模型的决定、预测和证明它们的可靠性.这需要更好的可解释性,意味着我们需要理解算法背后的机制[1].
在分布式云平台的调度管理中,用户的应用请求以作业的形式提交到数据中心,每个作业由调度器分配计算和存储资源,作业的一次调度运行称为任务.作业包含1 个或多个任务.其中,任务终止状态包含驱逐、失败、完成和被杀[2].Jassas 等人[3]提出了一种能够在早期发现失败作业的失败预测框架,该框架的优势是减少资源浪费,提高云应用的性能.Gao 等人[4]提出了一种基于多层双向长短期记忆(Bi-LSTM)的失败预测算法来识别云中的任务和作业失败,提高以往基于机器学习和深度学习方法的失败预测精度.现有任务终止状态预测模型在预测精度上有很大的提高,但是模型缺乏可解释性,人们无法确定模型产生的输出是否符合常理,所以即使模型产生较好的结果,人们依然无法完全信任模型.
为了克服模型缺乏可解释性的限制,必须考虑用于建模的输入变量的可解释性,即特征选择的可解释性,以及模型预测的可解释性.由于模型内部复杂的结构,会导致输入特征和预测结果之间的因果关系难以理解,所以模型是不可解释的.基于此,可以通过对特征进行统计分析,以建立特征和输出之间的因果关系,从而实现模型内部的透明化[5-10].特征统计分析方法是指对模型的特征进行汇总分析或者显著性可视化,对混乱的特征进行统计分析,计算不同特征对模型输出的贡献,并对显著特征进行可视化.该方法是基于特征对模型进行解释,特征作为可解释性和模型之间的桥梁[11].鉴于特征选择对模型可解释性的作用,故研究基于树模型探讨其在任务终止状态预测研究中的实用性.
基于树的机器学习模型是当今最流行的非线性模型.随机森林、梯度增强树、决策树等树模型被用于金融、医学、生物学、客户保留、广告、供应链管理、制造、公共卫生和许多其他领域.基于输入特征集做出预测,为每个输入特征分配信用数字来度量局部解释.如图1 所示,在任务终止状态预测中,将一组相同的特征变量分别输入到黑盒模型和白盒模型,“白盒”局部解释可以通过为每个特征分配一个特征重要性系数来表示特征对于模型产生某种预测结果的影响程度.在保证模型预测性能的同时,提高模型的可解释性,其中的可解释性意味着我们可以理解模型如何使用输入特征来表示预测[12].

图1 局部解释示意图Fig.1 Illustration of local explanation
然而,尽管树的全局解释方法有丰富的历史,总结了输入特征对整个模型的影响,但是人们对解释输入特征对个体预测影响的局部解释的关注较少.
目前有3 种比较常用的方法用来解释树模型的个体预测,即局部解释方法:1)报告决策路径;2)一个未发表的启发式方法,为每个输入特性分配积分;3)各种与模型无关的方法,需要为每种解释多次执行模型[12].这3 种方法有3 个局限性:1)简单地报告预测的决策路径对大多数模型都是没有帮助的,特别是对那些基于多棵树的模型;2)行为启发式信用分配方法还没有被仔细分析,对基于树的深度改变特征的影响有强烈的偏差;3)由于模型不可知的方法依赖于任意函数的事后建模,它们可能速度很慢,并存在抽样可变性.
树解释器,是一种新的用于树的局部解释方法,它使得最优局部解释的易处理计算成为可能,由博弈论的理想性质定义[13].研究借助任务终止状态预测模型,选择出最佳特征子集,并对进一步的模型可解释性进行研究.为了解决当前树集成方法存在的不一致问题,即当一个特征的真正影响实际增加时,它们会降低该特征的重要性,我们使用博弈论的最新应用,将树集成特征属性方法与SHAP 方法相结合,使用SHAP 值来衡量特征的重要性[14],将各特征对输出的影响可视化.通过结合许多局部解释,可以表示任务终止预测全局结构,同时保持对原始模型的局部忠实性,任务终止状态预测可解释性全局结构图如图2 所示.
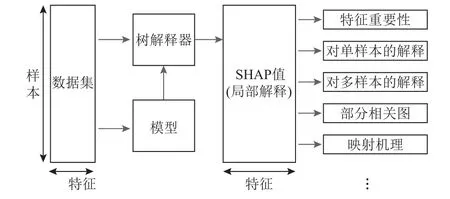
图2 任务终止状态预测可解释性架构Fig.2 Architecture of the task termination state prediction interpretability
云平台中,对任务的终止状态进行预测,对预测结果采取相应的调度措施,将失败的作业/任务提前终止,以确保良好的时间性能,并大量降低系统的资源浪费,提高资源利用率.通过解释作业/任务的系统属性、动态负载变化情况等因素与任务终止状态之间的关系,可视化负载特征对预测结果的贡献度,选择重要特征,进而提高任务终止状态预测模型的可解释性,可以更好地调度任务.
本文的贡献包括2 个方面:
1) 提出了一种可解释性强的云平台任务终止状态预测模型,研究负载特征与任务不同终止状态之间的关系.
2) 通过一系列直观的可视化结果,分析负载特征如何影响模型对任务不同终止状态的预测,探索特征与任务终止状态之间的映射机理.
本文使用谷歌数据集进行实验,在保证任务终止状态预测模型性能的同时,打破模型的黑盒特性,提高可解释性.在下文中,我们将讨论为什么树形模型在许多情况下都是最合适的模型,因为它们的准确性及其可解释性(1.2节),将计算精确SHAP 值的复杂度从降至,分析全局特征重要性(2.2 节),讨论对基于树的模型进行更好的局部解释的必要性(2.3 节和2.4 节),扩展了局部解释来捕获交互效应(2.5 节),并找出特征与任务终止状态之间的映射机理(2.6 节).
1 可解释的任务终止状态预测方法
1.1 特征获取
Google 日志中包含任务各种资源的实际使用情况,其能基本准确反映出任务在实际运行过程中消耗的资源,但在早期运行过程中,任务的数据所含信息量很少,所以需要对数据进行额外的信息补偿,以弥补模型预测中动态信息的不足,动态信息主要与任务的动态属性有关.在早期阶段,任务的运行状态数据较少,例如样本CPU 使用率、分配的内存使用率、未映射的页面高速缓存内存使用率、平均磁盘I/O 时间以及每个周期指令(CPI) 等动态属性.只利用单个 任务数据构建预测模型,限制了预测性能的提高.同时,部分作业之间具有相似资源消耗周期性变化的特点,引入更多的作业之间的相似信息以增加预测模型的动态信息[15].
加入任务的动态信息,最终选择用于任务终止状态预测的 59 个特征[16],其包含有 5 个静态特征和54 个动态特征.特征描述如表1 所示,其中静态特征指不随着时间戳的变化而改变的特征,动态特征指随着时间戳的变化而改变的特征.

Table 1 Static and Dynamic Characteristics of Tasks表1 任务的静态和动态特征
为了描述方便,本文使用英文特征名简写表示表1 中的中文特征名称:任务采样CPU 使用率最大值max_cpu,任务规范内存使用的最大值max_dsik,任务分配内存使用的最大值max_fendsik,任务分映射页面缓存的内存使用的最大值max_chachdsik,任务平均disk 的I/O 时间的最大值max_dsikOI,任务平均使用的本地磁盘空间的最大值max_localdsik,任务每个指令存储器访问的最大值max_instructiondsik,任务每个指令周期的最大值max_perInstructiondsik,任务平均CPU 的使用率的最大值max_Mcpu.对于均值(mean)、峰值(pv)、标准差(sd)、均方根(msr)、方根幅值(rpv)的命名同理.
1.2 基于SHAP 的特征分析
树解释器可以通过平均许多局部解释作为一种全局方法[13].如果对数据集中的所有样本都采用树解释器,那么就可以得到一个特征重要性的全局度量,它不会受到经典增益方法不一致性的影响,与排列方法不同,它不会错过高阶交互效应.基于树解释器的全局特征归因,与目前最先进的方法相比,在存在交互作用时具有更高的检测重要特征的能力,这对于基于树集合的特征选择任务具有重要意义.
为了更好地理解模型的输出,可以从特征的角度出发对模型进行解释,采用SHAP 可视化特征对终止状态的重要性,利用变量重要性结合SHAP 值来解释XGBoost 模型,对任务终止状态预测模型建模后的结果进行解释.SHAP 值用于特征的重要性,被定义为观察每个输入特征的值对模型输出顺序的影响,并在所有可能的特征排序上取平均值[2].对于所有可能的排序,我们在模型输出的条件期望中每次引入一个特征,然后将期望中的变化归因于所引入的特性.
SHAP 交互值由一个特征属性矩阵(对对角线的主要影响和对非对角线的交互影响)组成,并具有类似于SHAP 值的唯一性保证.通过单独考虑单个模型预测的主要影响和交互效应,树解释可以发现可能被遗漏的重要模式.
集成树模型做分类任务时,模型输出的是一个概率值.SHAP 实际是将输出值归因到每一个特征的SHAP 值上,依此来衡量特征对最终输出值的影响.SHAP 属于加性特征归因方法,其表示如式(1)所示:
其中g是解释模型;M是输入特征的数量;表示在所有的M个特征中,有多少特征是该样本所在的决策路径中包含的特征,对于某个样本,如果特征k不在其决策路径中,那么对应特征的SHAP 值为0,即φk=0,表示该特征不会对样本产生归因,对于最终预测值没有贡献.
在树模型中,对于某个特征j,需要针对所有可能的特征组合(包括不同顺序)计算SHAP 值,然后进行加权求和,如式(2)所示:
其中N为训练集中所有特征的集合;M为特征数量;S是模型中使用的特征的子集;fx(S)表达的是只利用特征集合S,根据树的结构、叶子节点的取值、内部节点的Cover 值等,计算出样本的平均值;fx(S∪{i})表达的是在特征集合的基础上,加上特征i,然后再根据树的结构、叶子节点的取值、内部节点的Cover值等,计算出样本的平均值;是对应特征子集S下,对于上述包含特征i和不包含特征i的情况下,样本取值之差的权重.
正如Lundberg 等人[12]所提到的,这类附加特征属性方法的一个重要属性是,该类方法中存在一个唯一的解,且该解具有3 个期望的属性:局部精确性、一致性和缺失性.局部精确性表示特征归因的总和等于我们要解释的模型的输出;一致性表明,更改模型以使某个特性对模型产生更大的影响,永远不会减少分配给该特征的属性的总和等于我们试图解释的函数的输出;缺失性表示已经缺失的特征(例如不具有重要性.
如果忽略计算复杂度,那么可以通过估计E[f(x)|xS]计算树的SHAP 值,然后使用式(2),其中fx(S)=E[f(x)|xS].E[f(x)|xS]是输入特征的子集S的条件期望值,图3 解释了如何从E[f(x)]得到预测值,SHAP 值将每个特征的归因值赋值为在调整该特征时模型预测的预期变化,将模型f对于样本x1=a1,x2=a2,x3=a3,x4=a4的预测解释为引入条件期望的每个特征的影响 φj的总和.
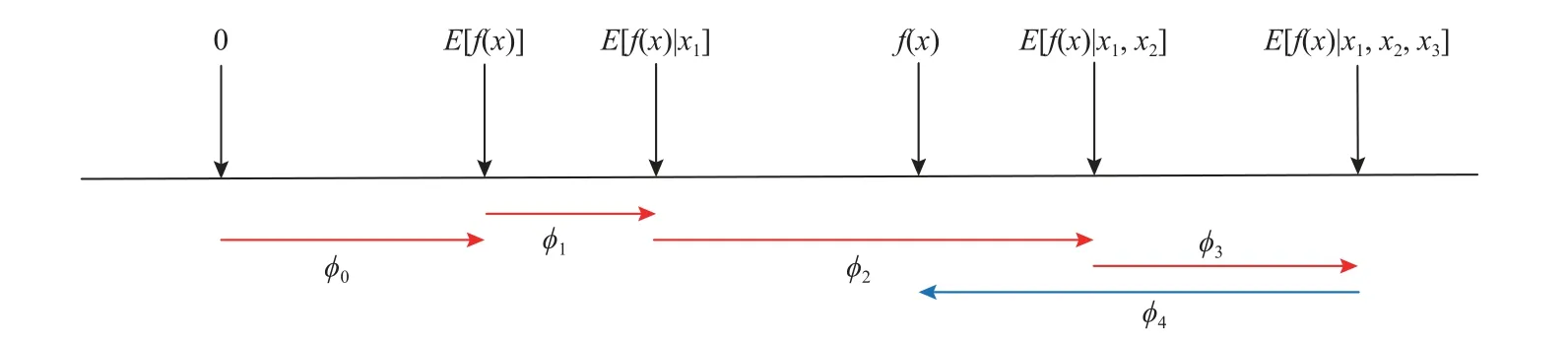
图3 SHAP 加和解释原理Fig.3 Principle of SHAP addition explanation
1.3 融合SHAP 的可解释任务终止状态预测算法
树解释器用于任务终止状态可解释性研究中,其背后的主要算法可以精确地计算SHAP 值,从而保证一致的解释.在低阶多项式时间内精确计算式(2),其中条件期望函数fx是使用树遍历(算法1)来定义的.通过直接计算SHAP 值,我们能够保证解释总是一致的和局部精确的.
算法1.估计E[f(x)|xS].
算法2.Tree SHAP.
传统的特征重要性方法可以直观地反映出特征的重要性,但是依然无法得出特征与模型预测结果之间的关系,SHAP 属于加性特征归因方法,将每个特征都视为贡献者,计算每个特征的贡献值,可以反映出每个特征对于最终预测结果的影响,增加任务终止状态预测模型的可解释性.使用XGBoost 模型对任务终止状态进行预测,从特征的角度出发,以SHAP 值来衡量模型预测中特征的重要性,并对其结果进行直观的可视化.使用SHAP 总结图可视化特征的变化如何影响任务的不同终止状态,进而找出特征与任务终止状态之间的映射机理.
2 实验及结果分析
2.1 数据集和评价指标
本文以 Google 云平台的计算调度系统 Borg[17]为研究对象,利用 Google 公开的工作负载监控日志数据集①https://github.com/google/cluster-data进行验证,该日志有1 个月的监控数据.验证实验筛选了Google 集群日志前3 天的数据进行实验.该样本数据集中共有10 473 个job,包含1 665 280个任务.为了更准确地对云平台任务不同终止状态的影响因素进行更直观的可视化,需要进一步对任务的终止状态进行细分,即不仅预测任务是成功(finish)还是失败,还需要进一步细分失败是驱逐(evict)、失败(fail)或被杀(kill)的状态,从而采取提前终止或继续运行等不同的调度策略.
由于Google 云平台数据集是从真实环境中采集获取,同时数据集存在含有部分噪声和缺失值等问题,所以需要对数据进行清洗预处理.实验筛选了Google 集群日志前3 天的数据,处理清洗过程参考文献[17].
多分类评价指标分为宏平均(macro-average)和微平均(micro-average),以召回率(recall)为例,Macro-R表示宏平均的召回率,Micro-R表示微平均的召回率.针对极度不均衡的多分类来说,Macro-R受样本数量少的类别影响较大,比Micro-R更合理[15].所以本文在测试数据集上,选择宏平均来度量分类器性能,更侧重对小类判别的有效性,本文使用的评价指标均使用宏平均的方法进行计算.
Kappa 评价指标k可以用来进行多分类模型准确度的评估,k的取值范围是[-1,1],实际应用中一般k∈[0,1],与ROC曲线中一般不会出现下凸形曲线的原理类似.k的值越高,则代表模型实现的分类准确度越高.
海明距离用来衡量预测标签与真实标签之间的距离,取值在0~1 之间.海明距离为0 说明预测结果与真实结果完全相同,海明距离为1 说明模型与我们想要的结果完全背道而驰.
各个多分类各评价指标的计算如式(3)~(6)所示.其中Macro-R表示召回率的宏平均;召回率表示任务样本中有多少运行成功的样本被正确预测;Macro-P表示准确率的宏平均;Macro-F1 表示F1 的宏平均;k表示Kappa 系数,式(6)中po是总体精度,pe是偶然一致性误差.
实验设计为2 组: 1)特征重要性的可视化,使用特征重要性图表示4 种不同的任务终止状态的特征重要性; 2)特征对模型输出影响的可视化,使用个体样本力图、多个样本力图、部分相关图、SHAP 总结图可视化特征如何影响任务的不同终止状态.
2.2 特征重要性分析
绘制树集合模型中特征的影响通常是用条形图来表示全局特征重要性,或用部分相关性图来表示单个特征的影响.然而,由于SHAP 值是个性化的特征属性,对于每个预测都是唯一的,因此它能够实现新的、更丰富的视觉表示.
取每个特征的SHAP 值绝对值的平均值作为该特征的重要性,并进行降序排序,由于任务有多种终止状态,得到的结果是堆叠的条形图,基于XGBoost模型的20 个重要变量的排序结果如图4 所示.
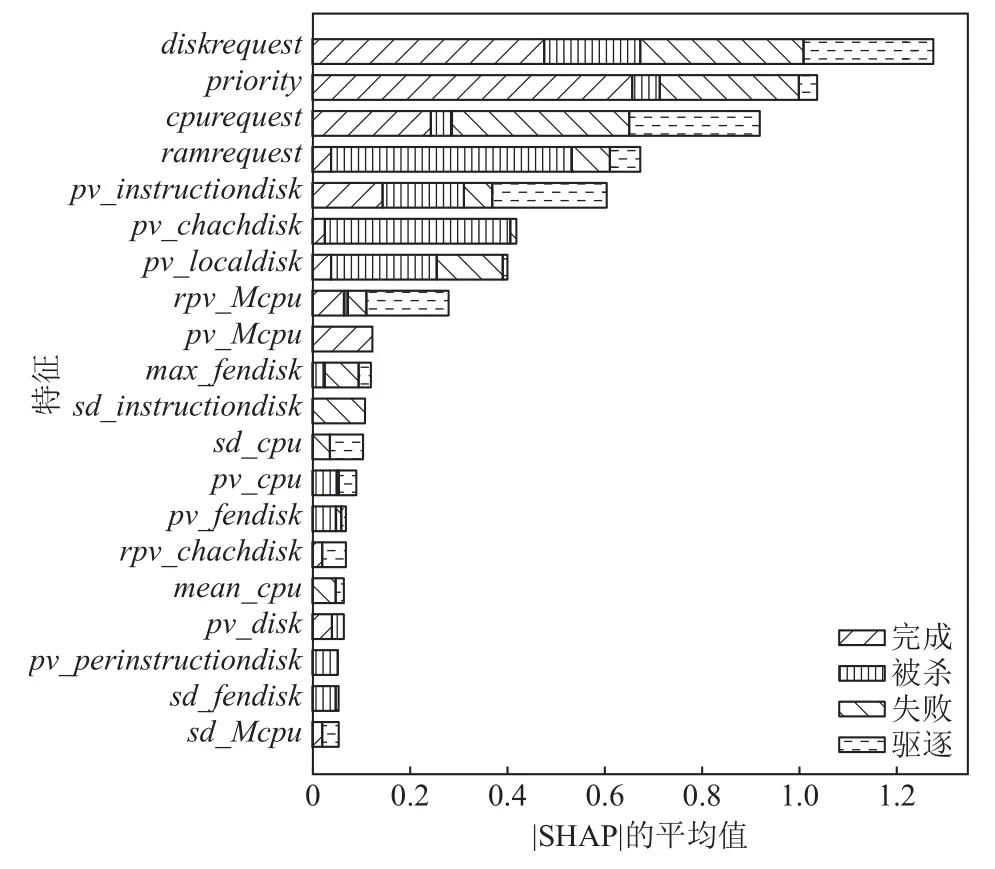
图4 特征重要性图Fig.4 Feature importance map
从图4 可以看到,在选出的20 个重要特征中,finish 类不使用sd_instructiondisk,pv_cpu,sd_cpu,max_fendisk等特征;kill 类不使用pv_Mcpu,sd_cpu,sd_Mcpu,rpv_chachdisk,mean_cpu这些特征;fail 类不使用pv_Mcpu,rpv_chachdisk,rpv_chachdisk,pv_disk这些特征;evict 类不使用pv_disk,pv_Mcpu,sd_instructiondisk,pv_chachdisk等特征.
2.3 对单个样本的解释
对于正确分类的样本,通过单个样本的力图,可以得知模型预测值的高低是如何造成的、由哪些特征造成的.如图5 所示,模型predict_proba值为0.91,代表当前样本的SHAP 值的输出值,基值为0.429 8,即全体样本的平均值,模型作出这样的结果,主要是受到任务平均CPU 使用率的方根幅值、 任务采样CPU 使用率的方根幅值、任务平均CPU 使用率的均方差、任务采样CPU 使用率的最大值的影响,这些特征对模型产生正向作用.任务分映射页面缓存的内存使用的最大值、任务分映射页面缓存的内存使用的峰值是对模型产生反向作用的特征.

图5 预测正确的样本力图Fig.5 Force plot of prediction correct sample
根据模型的预测结果找出被模型分错的样本,对其进行可解释性分析,查看哪些因素导致样本被错误分类.在测试集中,样本ID 为2610 的样本是成功完成的,但是模型将其终止状态预测为失败,导致模型这种错误预测的原因如图6 所示,主要受到任务平均CPU 的使用率峰值、任务磁盘空间资源请求、任务每个指令存储器的访问峰值、任务分映射页面缓存的内存使用峰值的影响.

图6 预测错误的样本力图Fig.6 Force plot of prediction wrong sample
2.4 对多个样本的解释
对多个样本的预测结果进行可视化,可以将单个样本的力图旋转90°,然后横向堆叠,得到力图的变体,这样我们可以得到对整个数据集的解释.对于多个样本的解释,在生成的力图中,可以选择不同的横纵坐标,实现对模型预测的直观可视化.从图7 可以看出,在基于样本的解释中,对输出贡献正向影响的特征和对输出贡献负向影响的特征;x轴是样本数量,y轴是SHAP 值加总(每个特征的SHAP 值);左边红色扎堆是正向SHAP 增益区, 任务的局部磁盘空间资源请求、优先级对一些样本是正向增益的.整体来说,图7 是一个宏观的了解,将诸多样本中不同特征对预测结果产生的影响进行可视化.
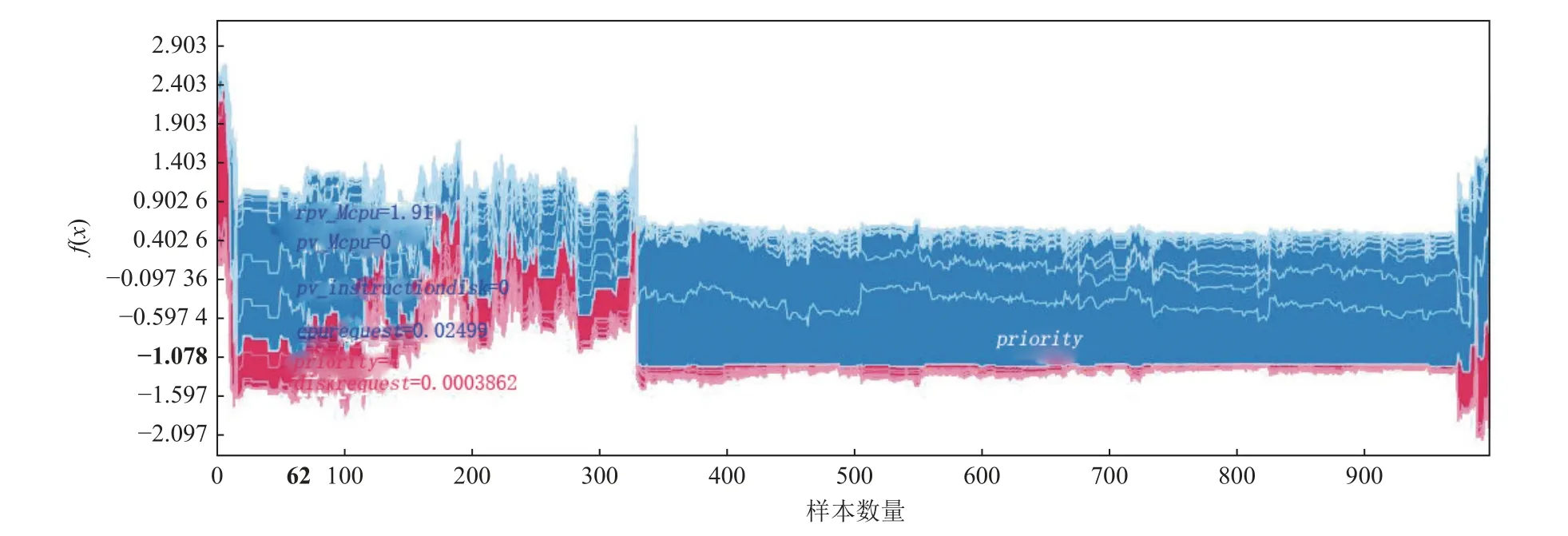
图7 预测多个样本的力图Fig.7 Force plot of prediction multiple samples
2.5 特征相关图
特征相关图表示特定变量或变量组的值固定时模型的预期输出.固定变量的值是变化的,并绘制出最终的预期模型输出.绘制一个函数的预期输出如何随着我们改变的一个特征而改变,有助于解释模型如何依赖于该特征.
特征相关图如图8 所示,可以更清楚地显示出特征对于模型输出的影响,x轴表示特征的取值,y轴表示该特征的SHAP 值,也就是说特征的取值会给模型的输出带来变化量.通过绘制数据集中许多任务的这些值,我们可以看到特征的属性重要性如何随其值的变化而变化.标准的相关图仅产生直线,而特征相关图由于模型中的相互作用而捕捉垂直离差.这些效果可以通过用交互特征的值给每个点着色来可视化.
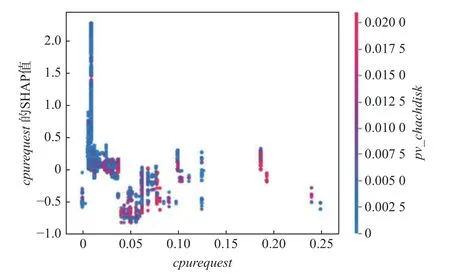
图8 特征相关图Fig.8 Feature dependence plot
对于相关图中的同一个x值,也就是特征取值相同的样本,它们的SHAP 值不同.其原因是,该特征和其他特征有着交互效应,相关图可以自动地选择与该特征相关的另外一个特征,来表现特征之间的这种交互效应.图8 右边是对比的特征,红色代表相关特征的高分部分,蓝色代表相关特征的低分部分.任务分映射页面缓存的内存使用的峰值的高分部分,对于低任务的CPU 资源请求来说,SHAP 值一般小于0,所以是负面影响.
2.6 特征与终止状态之间的映射机理
使用SHAP 特征归因方法实现对特征与任务终止状态之间关系的解释,对不同终止状态预测的特征重要性进行直观的可视化,根据可视化的结果,分别找出任务终止状态为完成、被杀、失败、驱逐的影响因素,并对特征如何影响模型的预测结果进行分析,找出特征与终止状态之间的映射机理.
特征重要性条形图给出了训练数据集中相对重要性的概念,但并不表示特征对模型输出的影响范围和分布,也不表示特征的值与其影响的关系.SHAP摘要图利用个性化的特征属性来传达特征重要性的所有方面, 同时保持视觉简洁.
SHAP 值类似回归系数,有正负之分,也有大小之分,SHAP 值越高,表示在任务终止状态预测模型中预测为该类的对数的几率越高,数据集中的每个样本都在模型中运行,并且为每个特征属性值创建一个点,因此每个任务在特征的线上获得一个点,该点由该任务的特征值着色,并垂直堆积以显示密度.每个点都是一个特征和实例的SHAP 值.
SHAP 概要图如图9 所示,其中y轴上的位置由特征决定,x轴上的位置由对应特征的SHAP 值决定.图9 的右侧有一条表示特征值大小的线,颜色从蓝色变为红色,代表特征的值从低到高.如果特征对模型输出的影响随着其值的变化而平滑变化,则该颜色也将具有平滑的渐变.重叠点在y轴方向上抖动,因此我们得到每个特征的SHAP 值的分布,这些特征是根据它们的重要性排序的.
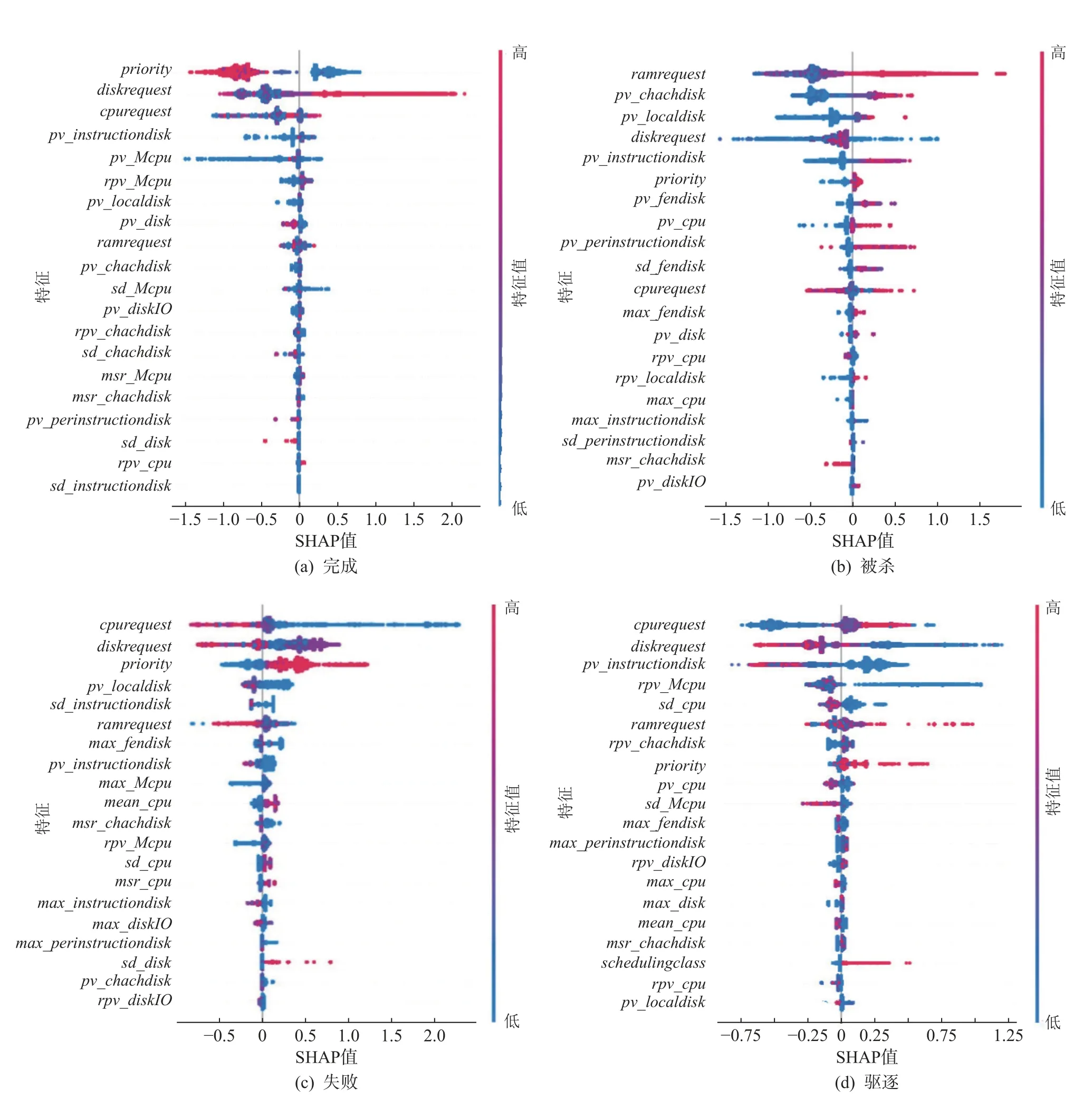
图9 不同任务终止状态的SHAP 概要图Fig.9 SHAP summary chart of different task termination states
由图9(a) 可知,对于终止状态为finish 的任务,priority这一特征对模型非常重要,而且priority值较大时,SHAP 值小于0,对模型产生负向影响,会降低输出为finish 的概率.横向来看,diskrequest这个特征,样本分布较为分散,具有长长的右尾,对该类的预测产生正向影响.不难理解,在云平台中,过高优先级的任务需要被优先调度,但在机器资源过度分配时,其资源请求得不到满足,容易失败.
由图9(b) 可知,对于终止状态为kill 的任务,ramrequest对模型输出的影响最大,较大的ramrequest,使得SHAP 值大于0,对模型产生正向影响,增加模型产生这种输出的概率.资源请求值表示在任务运行过程中,各请求被允许使用的最大值,当任务的资源请求超过资源请求值时,该任务可能会被终止或者受到限制.当调度程序在计算机上过度提交资源时,即使任务请求小于限制值,也会出现没有足够的资源满足任务运行时请求的情况,这种情况下,云平台会杀死1 个或多个低优先级任务.
由图9(c) 可知,对于终止状态为fail 的任务,cpurequest,diskrequest对模型输出的影响较大,对于较小的cpurequest,SHAP 值大于0,增加模型产生这种输出的概率.在资源请求较少时,任务在运行过程中有很大概率会超过资源请求的界限,导致任务失败.同时,priority对类fail 的影响也很大,对于较高的priority,SHAP 值大于0,增加模型产生这种输出的概率,即过高优先级的任务更容易失败.
由图9(d) 可知,对于终止状态为evict 的任务,cpurequest,diskrequest,pv_instructiondisk,rpv_Mcpu,ramrequest对模型输出的影响较大.当任务的实际需求超过计算机的处理能力时,任务的资源请求得不到满足,或磁盘所保存的任务数据丢失,都可能会导致任务被驱逐.
通过SHAP 摘要图,可以直观清晰地看出任务不同终止状态的影响因素,以及各个特征是如何影响任务的不同终止状态的,通过对可视化的结果进行分析,找出特征与终止状态时间的映射机理.
2.7 任务终止状态预测模型的选择
本节分别构建XGBoost、随机森林、GBDT、朴素贝叶斯、决策树、k近邻算法、Adaboost 这7 种任务终止预测模型.由表2 的模型性能评价结果可得,除了朴素贝叶斯模型,其余6 个模型均具有较好的分类性能,其中,XGBoost 模型具有较高的Kappa 值(0.686)、ACC值(0.959 7) 、Macro-P值(0.956 4)、Macro-R值(0.957 2)、Macro-F1 值(0.953 1),并且其具有较低的海明距离值(0.057).综合考虑各个指标的最优值,最终选择XGBoost 模型作为任务终止状态预测模型,该模型计算简单且易于理解,并且具有较强的可解释性.
研究结果表明,与已有工作相比,在进行特征选择和处理的基础上,本文所提的融合XGBoost 与SHAP 模型的可解释性方法可以更好地对云平台中任务的终止状态进行预测.
3 结束语
大型异构云计算平台上,使用特征选择结合模型可解释性方法,构建易于理解的任务终止状态预测模型.XGBoost 模型结合SHAP 方法,在保证模型预测性能较好的同时,提高模型的可解释性.从特征的角度出发,对任务的不同终止状态进行可解释性研究,可视化特征与终止状态之间的关系,对于实验结果进行了深入分析,找出特征是如何影响不同任务终止状态的,进而探索出特征与任务终止状态之间的映射机理,实现对云平台系统调度决策的优化,提升云平台的运算性能.未来将继续研究云边融合中任务终止状态可解释性方面的工作,探索更好的可解释性方法,并对负载特征与任务终止状态之间的映射机理进行更加深入的探索,增加本文所提方法的应用范围.
作者贡献声明:刘春红提出方法思路和实验方案;李为丽负责完成实验并撰写论文;焦洁提出特征选择意见;王敬雄协助完成实验;张俊娜提出论文整体的修改意见.
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
法律方法(2021年4期)2021-03-16
海洋信息技术与应用(2020年1期)2020-06-11
广州文博(2020年0期)2020-06-09
传媒评论(2019年4期)2019-07-13
文教资料(2018年30期)2018-01-15
传播力研究(2017年5期)2017-03-28
中国宪法年刊(2016年0期)2016-05-20
兽医导刊(2016年6期)2016-05-17
