
河网地区洪水预报模型开发及在长江下游地区的应用
2024-03-22 05:20赵艳红王晓书陈秋实王船海
中国防汛抗旱 2024年3期
陈 钢 赵艳红 王晓书 陈秋实 王船海
(1.河海大学水文水资源学院,南京 210098;2.沂沭泗水利管理局水文局(信息中心),常州 221018)
0 引 言
长江下游各地区人类活动频繁,下垫面与水网条件复杂[1],防洪除涝工程面广、量大,蓄滞洪区、圩区、泵站、调水等工程措施和防洪非工程措施相结合,运行状态多变[2]。此外,洪涝过程还受本地暴雨、长江过境洪水与沿海风暴潮影响[3],诸多因素导致产汇流过程和洪涝灾情复杂,工程群与地区间防洪除涝联合调度难度大。以往研究中,该区域模拟主要采用水动力模型,涉及控制方程组简化、方程组离散和求解、初边条件确定等一系列问题[4-5]。此类方法需要详细的河道地形资料及特征参数,且计算收敛稳定性受输入边界影响较大,规模庞大、时间长。传统建模及求解方式难以同时满足精准度与时效性的要求,实时预报调度难度极大[6-7]。
全球各地的水文学家开发了许多分布式或半分布式流域水文模型,Freeze和Harlan[8]首先提出了分布式水文模型设想,最具有代表性的是SHE(Système Hydrologique Européen)模型[9]。这类模型从水文循环过程的物理机制入手,将蒸发、下渗、地表水运动、土壤水运动、地下水运动、产汇流等过程联系在一起研究考虑水文变量的空间变异性,通常也称为“白箱”模型。英国Wallingford 水力研究所研发的InfoWorks[10]和丹麦水力学研究所(DHI)研发的MIKE 系列软件[11]可以模拟流域产流、河流水力过程。中国水利水电科学研究院自主研发的城市洪水分析系统IFMS URBAN 耦合集成了一维河网、管网模型和二维水动力学模型[12],具备模拟城市排水和地表洪水演进的能力。但以上模型缺少耦合流域水文、水动力、工程调度的一体化模型,无法实现人类活动影响下的全流域水循环实时预报调度。
基于河海大学太湖流域模型理论及应用实践[13],本文提出了一个通用的河网地区洪水预报模型框架,并进行了实例应用。该模型能够根据需要反映平原水网地区复杂的机理变化,对分布式水文模型与实时预报的发展提供了有价值的探索。
1 模型架构设计
1.1 分布式架构
水循环在不同的阶段和时间表现出不同的形式,其迁移和转化规律不同。即使在同一地区,不同阶段的水循环规律也不同。水循环可以分为垂直与水平循环2个过程。在垂直水循环中,水在不同介质中以不同状态进行循环迁移,主要包括2 个阶段(图1):①水在空气中迁移和转化的阶段,主要由气象学家研究;②陆地水循环,已得到水文学家的深入研究。
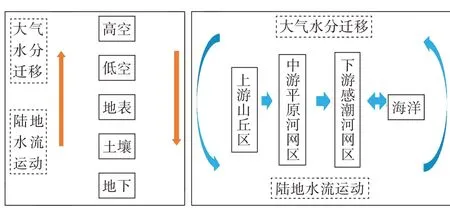
图1 垂直水循环示意图
在空中,水分的迁移规律相对简单,介质一致;而在陆地上,受地形、地貌和下垫面等影响,水循环可分为产流和汇流2个阶段。水汽从海洋和陆地蒸发升至天空,经大气层迁移后以降水形式分布在不同地区。在陆地上,水流遵循由高到低的原则,从山区到平原,最终流入海洋。不同地形地貌影响水流规律:山区流速快,河系单一;平原地区河道纵横交错,流向不定,湖泊和人工建筑物多,洪水运动复杂[14];河口感潮区受潮汐和海水影响,水流更为复杂。
这种区域性差异导致了陆地水分迁移转化规律的多样性,无法用统一理论描述。因此本文设计了分布式架构模型来解决复杂下垫面的水循环精细模拟,其具备以下特点:①模型中具有吸收多种结构(集总式、分布式)、多种类型(黑箱、概念、物理基础、地形因素)已有模型的能力;②模型可以根据需要采用多种类型求解方法;③模型具有可以采用多种离散尺度的能力;④模型参数要求能够尽量系数化,能够直接从下垫面信息提取;⑤具有能够充分模拟全球水循环过程中垂向与横向循环的能力;⑥模型还具有强大的可扩展能力,能够吸收其他优秀模型的能力,以及能够扩展研究区域的能力,如扩展到大气迁移转化与陆气耦合模型等。
1.2 水文特征单元
由于流域下垫面的复杂性,不同地形、地貌、植被等会影响产汇流规律,因此在分布式架构模型中引入水文特征单元的概念,即具有相同产汇流机理的水文地理区域。水文特征单元可分为产流型、汇流型和混合型,与传统水文单元不同,水文特征单元用于反映产汇流机制的不同。在进行水文单元划分时,需考虑最佳模型离散尺度的影响。
根据水文特征单元的概念,结合分布式架构,可以构建描述流域水循环模拟的分布式架构水文模型(图2)。流域被分解为不同类型的水文特征单元,图3 展示了流域主要水文特征单元组成。

图2 分布式架构水文模型结构示意图

图3 水文特征单元逻辑结构
通过引入水文特征单元,将流域水循环分解为不同阶段、不同区域的耦合体,并针对每种水文特征单元采用最适合的模拟模型算法进行求解。在求解每个水文特征单元时,可选择最适合的模型离散时空尺度,进一步将水文特征单元划分为水文计算单元进行模型计算。
这种分布式架构模型解决了由水文特征单元组成的流域水循环模型的问题。例如,在山丘区可以采用新安江模型,将整个山丘区作为一个水文特征单元,对其进行子流域划分,各子流域即为水文计算单元;在平原区,可有河道一维特征单元、河道二维特征单元、湖泊零维特征单元、湖泊二维特征单元、堰闸特征单元和坡面特征单元等。在水文特征单元内部可进一步细分区域,这些区域即为水文计算单元,如河道一维特征单元中的断面、河道二维特征单元中的网格等。水文特征单元的分类不是唯一的,随着研究的深入和对流域水循环机理的认识不断深化,可进一步细分。各种水文特征单元的详细模拟原理详见参考文献[15]至[18]。
1.3 水网地区多要素多过程耦合
1.3.1 产流与汇流特征单元的耦合
长江下游地区地势平坦,水系发达,河流纵横交错,多呈网状分布。其汇流过程不同于山丘区,没有统一的汇流出口。为了研究平原区产水量的分配过程,将产水汇流到周边河道里,本文提出河网多边形的概念,实现了产流过程与汇流过程的耦合。
河网多边形是指由概化河网、各类分界线所围成的封闭区域(图4)。图4(a)为概化河道围成的多边形,图4(b)为概化河道与分界线围成的多边形,图4(c)为山丘区分水线与概化湖泊边界线围成的多边形。图4(a)多边形面积上的产水量或需水量必须经周边的概化河道排泄或补给;图4(b)多边形产水量或需水量只可能通过概化河道周边排出或补给,其他性质的边,如沿江、沿海、湖泊岸边、山丘分水线或平原区的分界线等,是不能排泄多边形水量的;图4(c)是一些特殊的多边形,其周边无概化河道,如滨湖的山丘、滨湖一侧的山丘区降雨产流只可能汇入湖泊。

图4 河网多边形
为满足数值模拟的需要,将计算区域划分为网格(如1 km×1 km)。图5 是由概化河道构成的多边形,包括概化河道1、2、3、4、5,多边形面积为A,多边形的面积及各类下垫面面积,可以用其覆盖的网格计算得到。多边形所包含面积上的数值只能分配到多边形周围概化河道1、2、3、4、5。多边形中任一网格,需要明确它的产流流向哪一条河道,其灌溉需水量又是取自于哪一条河道。在没有详细地形的情况下,假定该网格与其距离最近的河道相联系,即取图中距离s最小的概化河道作为与该网格相联系的概化河道,如图5 中黑色网格的产水量流入与其相联系的概化河道5,该网格的灌溉需水量亦只能从概化河道5 引取,该网格与概化河道1、2、3、4无关。

图5 河网多边形栅格化处理
仅把距离远近作为网格与周围概化河道相联系的唯一依据,有时会产生不合理的结果,往往会出现一条小河与很多网格相联系的情况。如在洪水时,有太多的雨洪汇集到该条小河,来不及排泄而形成高水位,或需要太多的灌溉水量导致河道干涸。从模型计算的稳定性方面考虑,在分配中考虑河道过水能力,取综合系数:
式中:θ为综合系数;A为过水面积,m2;R为水力半径,m;s为计算网格到概化河道的最小距离,m。
将网格分配到多边形周边综合系数最小的概化河道,网格所属的下垫面亦随着网格的分配而归属于相应的概化河道。
1.3.2 汇流特征单元间耦合
水流运动模拟可由零维、一维或二维(准三维)模拟所组成,各部分模拟必须耦合联立才能求解。对模拟区域中控制水流运动的堰、闸、泵等进行耦合,控制建筑物的过流产流量可以用水力学方法来模拟,对于不同的控制建筑物采用相应的水力学公式,采用局部线性化离散出产流量与上下游水位的线性关系。
在河网水流模拟计算中河道的交汇点称为节点,对于河网节点,按节点处的蓄水面积可分为2类:①节点处有较大的蓄水面积,节点水位变化导致的蓄水量变化不可忽略,这类节点称之为有调蓄节点;②节点处的水量调蓄面积较小,水位变化导致的节点蓄水量变化可以忽略不计,这类节点称之为无调蓄节点。在河网一维水流计算中,节点实际上有1 个基本假定:与河节点相通的河道断面水位相等,即节点水面是平的,不考虑其中的水头差。河网节点水量平衡式为:
式中:A(z)为节点调蓄面积,m2;∑Q为包括降雨产汇流、河道出入流在内的所有出入节点的产流量,m3/s。
在河网模拟计算中,节点水位的求解是整个河网水流模型计算的关键,节点水位获得后可以计算得到河道任一断面的水位产流量。节点水位也是全流域耦合的关键。对于每一个节点,根据节点类型分别建立相应的水量平衡方程,结合边界节点的边界条件,可构建关于节点水位的完备线性方程组,从而实现水动力过程之间的耦合求解。
2 预报调度功能
模型的规划模拟功能不同于实时决策功能,不是简单地改变边界,需要融合多源数据,如风暴潮、台风、数值天气预报、下垫面信息等数据,并通过技术手段进行实时水雨情、工情校正。
2.1 数据库耦合技术
数据库管理系统主要解决模型与外部数据库的接口问题,包括数值天气预报、风暴潮、水文测站站网、水利工程工情信息的实时引入,同时负责处理模型计算成果的入库。通过设计通用数据库接口,可解决系统与数据库的接口问题,系统所有与数据相关的操作(读、写数据库)均由此接口负责完成。同时该接口在设计时考虑到数据库的开放性、数据库库表结构的可扩充性要求,即当数据库表结构发生变化时,系统只需对数据接口部分做相应调整,系统就能正常运行,而无需修改系统源代码。
模型中采用ODBC 标准接口与数据库相连接,可以连接任意网络数据库,如Ms SQL Server 2000、Oracle 8 等。ODBC 定义了系统与SQL 数据库之间的程序设计接口,通过设置ODBC 数据源,即可实现系统用户对外部数据库的读写。
2.2 实时校正技术
对预报模型进行实时校正,是提高复杂水网地区预报精度的有效途径之一。卡尔曼滤波理论能够同时对多维的时变状态量进行校正,因此比较适合应用到河道洪水预报实时校正中,并且卡尔曼滤波的计算特点(如在线估计时间短、存储量小等)适合实时处理和计算机运算。本研究采用卡尔曼滤波方法作为河网地区预报模型实时校正功能开发的核心算法,实现步骤为:①根据河网模型各河段有无实测站点及与实测站点所在河段间的拓扑关系,将所有河段自动分级;②依据基于单一河道的滤波方程求解结果,将单一河道各断面实时校正结果简化为校正单位线,在此基础上构建河道多模式单位线生成及管理模块;③通过有实测站点的水位预报误差(又称为新息),对实测站点所在河道进行校正,并根据河段分级逐级传播至整个河网。实时校正流程见图6。

图6 实时校正流程图
水量预报模型根据潮位预报模型的预报潮位结果及气象部门的预报降雨资料进行预报模拟后,从实时数据库自动读取实测站点水位、报汛水位等资料,与模型相应位置计算值对比获得新息源,按照河段分级顺序,根据各河段校正单位线,从各实测站点逐级沿河段将新息传播到全河网,对所有节点、断面水位预报水位进行校正。
2.3 水利工程调度技术
调度模型设计了不同触发规则,支持水量条件、水质条件、时间条件等,运行情况模拟支撑闸泵工程的分孔控制、逐步启闭、不同开启高度等。水利工程的具体控制调度方法在模型中是以控制条件的形式实现,创建联系控制条件即实现联系的具体控制调度,相同调度规则的闸泵工程可设置在同一个控制条件中。联系控制有2 种方法,GATE格式控制和具体控制。以GATE格式控制为例,控制条件设置步骤如下。
(1)设置水位产流量统计。设置统计河道或湖泊的水位产流量状态量,明确控制代表站的断面或节点位置、间隔时段等,设定状态量名称,作为控制条件的判别依据。若判别条件不涉及水位产流量,可不建立水位产流量统计。
(2)设定水位相关线和调度线。通常与代表站点调度线有关的闸泵调度需设置此项,若其他闸泵涉及代表站以外的水位相关线,也可再进行分级设置。
(3)编写控制条件。闸门运行的规则调度标准,闸门依据控制条件列表中的1 条或多条的任意组合调度,返回值为闸门的启闭。
(4)确定控制步长。闸门开启后,对开启的方式进行具体控制,以满足实际运行中的特殊要求。
(5)在GATE格式控制步长标签下,按照调度规则编写工程具体控制逻辑,并在联系要素列表中选定按此调度规则进行调度的闸泵工程,增加到具体控制信息中。
3 太湖流域应用
3.1 研究区域
太湖流域地处我国东部长江河口段南侧及钱塘江与杭州湾之间,三面滨江临海,一面环山,其北滨长江,南濒钱塘江,东临东海,西以天目山、茅山等山区为界。太湖流域行政区划分属江苏省、浙江省、上海市和安徽省[19]。流域总面积36 895 km2,其中江苏省19 399 km2,占比为52.6%;浙江省12 095 km2,占比为32.8%;上海市5 176 km2,占比为14.0%;安徽省225 km2,占比为0.6%。
3.2 模型概化
根据上述分布式架构水文模型提出的水文特征单元概念,结合太湖流域的具体情况,太湖流域可以概化为由下面几类特征单元组合构成(表1)。

表1 太湖流域主要概化基本信息
根据太湖流域平原水网的特点,将流域内影响水流运动的因素分别概化为零维模型(湖、荡、圩等零维调蓄节点)、一维模型(一维河道)和联系要素3 类。联系要素包括水闸、船闸、涵洞(立交)及泵站等工程,联系要素的上下游都设有节点,节点之间的水位差与产流量之间的关系取决于堰流公式选取及运行方式。太湖流域河网、湖泊概化情况见图7。共包括概化河道(段)1 483条;计算断面4 274个;节点116个,其中边界节点105个,调蓄节点76个;控制建筑物(闸、泵等)168个。

图7 太湖流域概化
3.3 模型率定
选取2016年实况数据对模型参数进行率定,率定水位站选取太湖和均匀分布于湖西区、武澄锡虞区、阳澄淀泖区域内的代表站点,率定结果见图8 和表2。率定结果显示,计算与实测水位过程拟合程度非常高,太湖计算日均最高水位与实测水位基本一致。地区代表站日均最高水位误差基本在0.1 m以内。研究范围内所有站点Nash系数fNSE均值为0.97,确定性系数R2均值为0.96,其中太湖fNSE均值为0.97,R2均值为0.99,湖西区fNSE均值为0.99,R2均值为0.99,武澄锡虞区fNSE均值为0.95,R2均值为0.98,阳澄淀泖区fNSE均值为0.97,R2均值为0.91。各站水位预报合格率均高于85%,预报项目精度达到甲级等级。其中6个代表站的预报精度在90%以上,太湖水位预报精度最高,达98.9%。

表2 2016年水位率定成果表
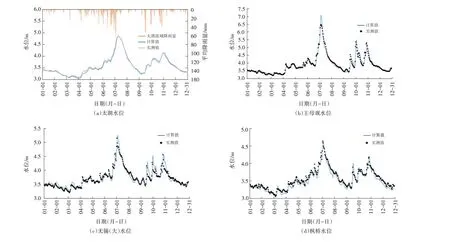
图8 2016年太湖水位及部分代表站率定成果表
3.4 实时预报
为评估实时校正在实时预报中的效果,同步对比设置校正点和不设置校正点的预报成果,在太湖流域模型中对太湖代表站水位设置实时校正点、计算时段选取2016 年5—8月,预报期降雨、边界条件选用实测资料,降低外部输入误差,预报期工程调度选用规则调度,以计算时段内每日8:00 作为预报依据时间,预报未来3 d 太湖及各区域代表站水位,分别选取1 d、2 d、3 d 预报成果与实测水位对比,计算确定性系数、最大误差、洪峰峰值误差等。如2016年5 月1 日8:00 作为预报依据时间,预报2016 年5 月2 日8:00、2016年5月3日8:00、2016年5月4日8:00这3个时刻的水位成果,分别作为1 d、2 d、3 d 预见期成果,与对应时刻实测水位做对比。
对不同预报期的预报成果使用确定性系数R2和合格率QR来进行评估,其中合格率QR的计算公式为:
式中:m为预报总次数;n为合格预报次数。对合格预报次数的判定标准为:实测值减去计算值的绝对值小于0.1。
太湖作为太湖流域主要调蓄水体,其水位预报精度对太湖流域防洪等至关重要,太湖水位不同预见期成果误差分析如表3 所示。当不设置实时校正点时,太湖水位1 d、2 d、3 d预见期预报成果与对应时刻太湖实测水位相比,确定性系数只能达到0.607、0.570、0.524,当设置校正点之后,确定性系数提高到0.996、0.988、0.974;最大误差由0.52 m、0.56 m、0.59 m 降低到0.08 m、0.12 m、0.17 m;峰值误差由0.08 m、0.09 m、0.10 m降低到0.03 m、0.06 m、0.04 m,预报合格率由35.5%、35.5%、35.5%升至99.2%、95.2%、80.6%。

表3 太湖水位不同预见期预报成果误差分析表
从太湖水位1 d、2 d、3 d 预见期预报成果与实测数据对比图(图9)可以看出,不管是水位变化趋势和峰值水位,在设置校正点之后,预报精度都有明显改善。在没有设置实时校正点的情况下,太湖水位随着预报时间的推进,预报误差逐步增大,而从设置了实时校正点的预报成果来看,预报误差得到了有效控制。同时在设置校正点和不设置校正点2种计算工况下,预报期条件一致,因此误差来源主要是预报依据时间所在时刻模型状态和流域实际状态的不同,由此可见,该实时校正方法可以大幅提升太湖水位预报精度。
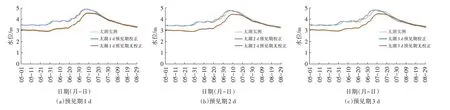
图9 太湖水位1 d、2 d、3 d预见期预报成果与实测数据对比
4 结 论
综合考虑平原河网区的汇流特征和汇流影响因素,本文提出了基于水文特征单元的分布式架构模型。以太湖流域为原型,构建了一个完整的多要素、多尺度、多过程的水循环精细模拟模型。
(1)提出了分布式架构水文模型,能够反映某一区域机理变化的耦合模型。该模型模拟的对象是考虑人类活动影响的流域水循环系统,结构具有分布式特点,考虑了降雨和下垫面条件空间分布不均匀对流域降雨径流的影响。
(2)引入水文特征单元,使得模型在计算时可以根据流域特征和实际需要采用最合适的模块组合,如集总式、概念性或分布式模型。
(3)实时预报调度功能,可耦合数值天气预报、风暴潮、水文测站站网、水利工程工情信息,并进行数据同化。
这些改进提高了模型的精度和适用性,为平原水网地区流域水资源管理和防洪减灾提供了有力支撑。
猜你喜欢
水资源开发与管理(2023年8期)2023-09-08
国学(2020年1期)2020-06-29
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
数学物理学报(2017年6期)2018-01-22
摄影之友(影像视觉)(2017年1期)2017-07-18
河南水利年鉴(2017年0期)2017-05-19
水利科技与经济(2017年2期)2017-04-22
心理学探新(2015年4期)2015-12-10
科技创新与应用(2015年32期)2015-05-30
