
基于词汇增强和表格填充的中文命名实体识别
2024-03-20 04:31褚天舒唐球梁军学徐睿王明阳刘涛
电子技术应用 2024年2期
褚天舒,唐球,梁军学,徐睿,王明阳,刘涛
(1.华北计算机系统工程研究所,北京 100083;2.中国人民解放军93216 部队,北京 100085)
0 引言
在大数据时代,每天都产生海量的文本数据,如何从这些存在大量冗余的数据中获取真正有价值的知识信息显得愈发重要。使用知识抽取方法能够自动识别并提取所需知识要素信息,为后续的知识融合、知识加工、知识应用提供数据支撑,其中命名实体识别是知识抽取的重要任务,也是知识图谱、数据挖掘、智能检索、问答系统等下游任务的基础,命名实体识别技术的研究具有重要的理论需求与现实意义。
中文命名实体识别根据粒度划分可分为基于词的命名实体识别、基于字符的命名实体识别和基于字词混合的命名实体识别。与英文命名实体识别相比,中文没有明确的单词分隔符号,因此,中文命名实体识别存在分词困难的问题。
基于词的中文命名实体识别方法需要对中文文本进行分词操作,错误的分词经常导致模型对实体边界识别效果不佳。基于字符的中文命名实体识别方法虽然能够避免分词错误带来的影响,但忽略了词汇本身包含的边界信息。为了解决以上问题,基于字词混合的方法成为了主流的中文命名实体识别方法,其中基于词汇增强的方法是在字符编码的基础上引入词典,将输入文本与词典进行匹配,获取最相近的词汇信息,再将词汇信息融入到模型中,实现字词融合。Zhang 和Yang[1]在长短时记忆网络(Long Short Term Memory Network,LSTM)模型上做出改进,提出了Lattice-LSTM 模型,通过引入大型词汇库,将句子与词汇库进行匹配,获取最相关的字符和单词,避免了单词分割错误产生的影响,然后将潜在的词汇信息集成到基于字符的模型中。Li等人[2]使用基于跨度的平面结构代替晶格结构(Lattice),解决了Lattice-LSTM 模型无法并行计算的问题,并提出了一种新颖的字与词相对位置编码。Liu 等人[3]受 到BERT(Bidirectional Encoder Representation from Transformers)适配器的启发,构造了词典适配器(Lexicon Adapter),并利用词典适配器将词汇信息融合到BERT 预训练模型中。
现有的中文命名实体识别研究多集中于平面实体识别,而在实际生活中,存在大量的嵌套实体。嵌套实体识别和平面实体识别的区别如图1 所示,在“农行河南省分行”这个例子中,嵌套实体识别任务需要确定“河南省”和“农行河南省分行”两个实体的边界,并正确预测对应的类别,而在平面实体识别任务中将忽略更短的实体“河南省”,只需要判别出长实体“农行河南省分行”的实体边界和实体类别,与平面实体相比,识别嵌套实体的实体边界更加困难,同时也更具有挑战。通常会根据实际需求选择不同的实体识别任务,因此需要一个统一的中文命名实体识别模型同时满足这两个任务的要求。

图1 嵌套实体识别和平面实体识别示意图
目前,基于词汇增强的中文命名实体识别[1-4]多使用基于序列标注的方法,在解码阶段采用条件随机场(Conditional Random Field,CRF)解码,对嵌套实体的识别效果不佳,有些研究对CRF 进行了创新,通过采用分层CRF 或者设置复杂标签的方法实现对嵌套实体的识别,但存在标签稀疏的问题。
针对上述问题,本文提出TLEXNER 模型,在编码阶段通过在BERT 模型中Transformer 层之间添加词典适配器[3],将词汇信息集成到预训练模型中,为了充分利用字符与词汇的相对位置信息,在BERT 的嵌入层仿照原有的3 种嵌入方式加入字符与词汇组的相对位置信息嵌入。在解码阶段,不同于传统的中文命名实体识别使用CRF 进行解码,本文使用表格填充(Table Filling)的方法,通过条件层归一化(Conditional Layer Normalization,CLN)和双仿射模型(Biaffine Model)构造字符对表格,将命名实体识别任务转化成多分类任务,能够有效地识别平面实体和嵌套实体。
基于词汇增强和表格填充,本文提出TLEXNER 模型实现中文命名实体的识别,本文的主要贡献如下:
(1)将中文的平面实体识别任务中常用的词汇增强方法用于嵌套实体识别任务中,并证明了有效性。
(2)提出将字符与词汇组的相对位置信息集成到BERT 的嵌入层中。
(3)使用条件层归一化和双仿射模型构造字符对表格,使用表格填充的方法代替中文命名实体中常用的CRF 解码方式。
(4)实验证明了TLEXNER 模型能够有效识别中文的平面命名实体和中文的嵌套命名实体,并且优于其他基于词汇增强的方法。
1 相关工作
对命名实体识别的研究早期主要集中在对于平面实体的识别,后来随着技术的进步,逐渐将重心转移到对嵌套实体的识别,与平面实体识别相比,嵌套实体识别对实体边界的要求更加严格,同时也更具挑战。现在主流的命名实体识别主要分为基于序列标注的方法和基于跨度的方法。
基于序列标注的方法[5-8]通常采用BIO 或者BMES的标注方式,在平面命名实体识别中取得了不错的效果,并广泛应用在中文命名实体识别任务中,但由于模型自身的特点,导致对嵌套实体识别效果不理想,为此,研究人员对CRF 进行了一定的变体,采用了更加复杂的标签[9-10],或者重复使用序列标注模型,将实体识别转换成多标签分类任务[11-13]。
基于跨度(Span)的方法是以词的跨度作为基本单位,为每个跨度分配标签,因此能够对嵌套实体进行识别,但由于预测的实体头尾之间是相互独立的,缺少信息交互,存在错误识别实体边界的问题。Yu 等人[13]在2020 年提出使用双仿射模型进行命名实体识别,通过双仿射模型对实体的开始和结束标记进行评分,通过这些标记表示所有的跨度,实现嵌套实体识别。Li 等人[14]在2021 年提出模块化交互网络模型,同时关注单词级别及跨度级别的信息,使用交互机制实现两个子任务的信息共享,有效解决长距离嵌套实体识别的问题。为了更好地识别实体边界,Shen 等人[15]通过对种子跨度使用过滤和边界回归的方法生成跨度建议,然后识别边界调整后的跨度的类别。Li 等人[16]在Yu 等人[13]的基础上,利用多粒度空洞卷积层(Multi Granularity Dilated Convolution)来捕捉不同距离的单词间关系,然后将多粒度空洞卷积与双仿射模型的结果拼接,构造并预测二维词对网格,实现嵌套实体识别。
2 模型结构
本文的模型整体结构如图2 所示,主要分为编码阶段、表格填充阶段和解码阶段3 个模块。在编码阶段,首先通过词典适配器将词汇信息集成到BERT 预训练模型中,然后通过双向LSTM 获取词向量表示;在表格填充阶段,使用条件层归一化和双仿射注意力模型构造并预测字符对表格;在解码阶段通过softmax 分类器得到实体头部和实体尾部,并预测潜在实体的类别。

图2 TLEXNER 模型整体结构
2.1 编码阶段
2.1.1 BERT 模型
Liu 等人[3]的研究表明,使用词典适配器将词汇特征集成到BERT 预训练模型中能够提升中文命名实体识别的效果。因此,本文在BERT 模型中的第一个Transformer 层加入词典适配器,将词汇信息融入到底层模型中,实现字符特征与词汇特征的融合。整体结构如图3所示。

图3 BERT 模型结构图
首先,输入的句子C由多个中文文本字符{c1,c2,…,cn}组成,使用词典D 获取每个字符ci所匹配的一组词汇信息wi={wi1,wi2,…,wij}。其中wij代表第i个字符匹配的第j个词汇。
Li 等人[2]设计了一种巧妙的位置编码,通过一个标记(token)分配头部位置和尾部位置的方式,确定标记的位置信息。受到这种思想的启发,本文将字符与词汇的相对位置信息集成到BERT 的底层中。
因为多个字符可能会匹配到同一个词汇,为了更好识别出字符与词汇的潜在关系,本文仿照BERT 嵌入层(Embedding)中原有的3 种嵌入方式,加入了字符与词汇的相对位置信息嵌入(Boundary Embedding),将字符特征和字符与词汇组的相对位置特征一同输入到BERT模型的嵌入层中,并在嵌入层实现字符与词汇组的相对位置嵌入。其中字符与词汇的相对位置包含了字符位于词汇的头部(B)、位于词汇的中间(M)、位于词汇的尾部(E)以及单一字符(S)4 种情况。字符匹配词汇及相对位置信息如表1 所示。

表1 字符匹配词汇及相对位置信息
然后,通过词典适配器,将字符特征向量与词汇特征向量相结合,适配器包含了两个输入,字符特征向量和一组单词向量
其中,ec表示BERT 的嵌入层,表示通过BERT 的嵌入层得到的第i个字符的向量表示,ew为预先训练好的单词嵌入层表示第i个字符所匹配的第j个词汇的向量表示。
由于每个字符可能匹配多个词汇,但每个词汇特征对于实体边界识别的作用并不相同,因此引入双线性注意力(Bilinear Attention)机制,将字符向量表示与对应的词汇组向量表示输入到双线性注意力模型中,根据相关性对词汇组中的每一个词汇特征赋予不同的权重,接着将这些词汇特征加权为一个向量,然后将该向量添加到字符向量中,得到的输出
其中,LA 为词典适配器的计算过程。
为了与其他研究进行对比,本文使用的预训练模型是基础的BERT 模型。
2.1.2 双向LSTM
为了进一步加强词向量的上下文表示,本文将BERT 预训练模型的输出输入到双向LSTM 中,获取到最终的词向量表示。
2.2 表格填充阶段
表格填充用于实体关系联合抽取任务中[17-18],使用表格中的每一项表示两个单词之间的关系。受此启发,本文将表格填充用于中文命名实体识别任务中,使用字符对分别表示实体的头部位置和实体的尾部位置,将字符对组成的实体的类别视为字符对之间的“关系”。
由于表格具有表示一个句子中多个字符对之间关系的特点,因此嵌套实体和平面实体都可以通过表格结构进行表示。在表格的构造过程中,句子中的任意两个字符都会进行信息交互,并计算它们之间的关系,因此能够避免基于跨度的命名实体识别方法中存在的头尾实体无法交互的问题。
Li 等人[16]已经在命名实体识别任务中使用了构造二维词对表格的方法,并通过设计复杂的标签和解码方式,实现对非连续实体的识别。与上述研究相比,本文的研究目标是对嵌套实体和平面实体进行识别,根据研究目标的不同选择更加简洁的表格标签,在解码阶段只需要预测表格的上三角区域,而非整个表格,这样能够提升解码效率并且减少标签稀疏带来的影响。具体的字符对表格如图4 所示。
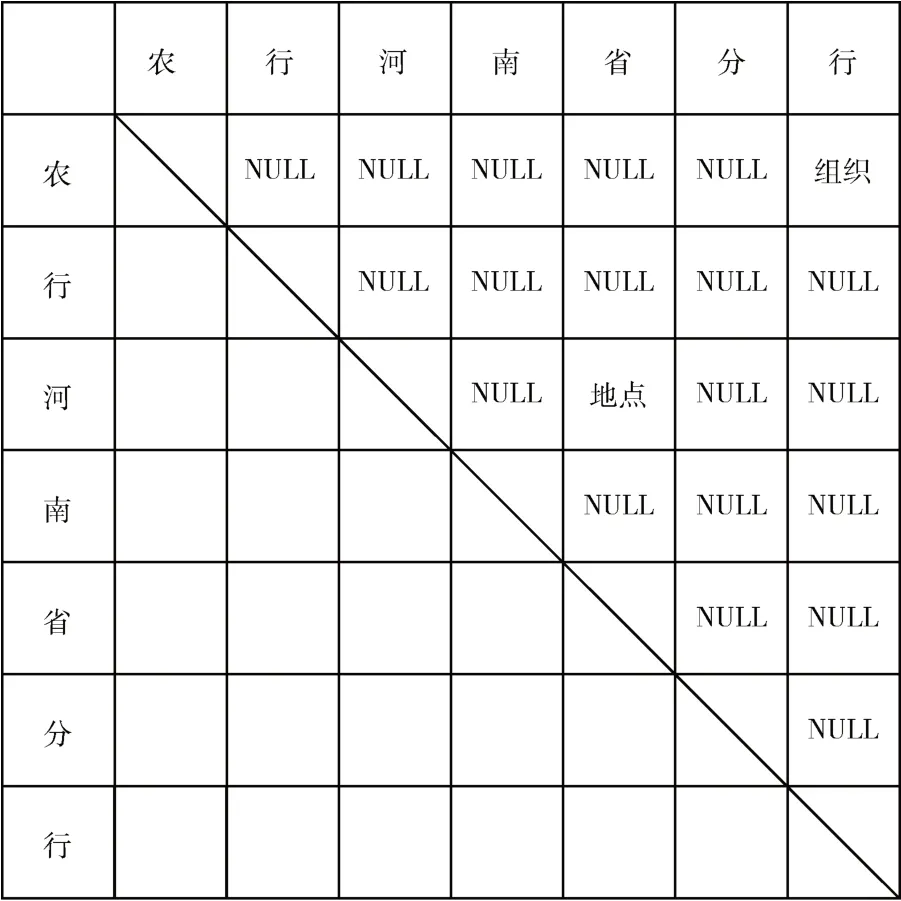
图4 字符对表格
图4 中的对角线表示潜在实体的头部,上三角区域中的每一项都代表一个字符对之间的关系,即实体的类别,纵坐标表示实体可能的尾部位置,即可能的实体边界。如果字符对之间不存在实体关系,则用NULL 进行表示。图中的“河南省”和“农行河南省分行”是需要识别的两个实体,因此将实体的类别填充到表格中的对应位置,而表格中的其他项标注为NULL。
本模块的目的是通过条件层归一化和双仿射模型构造高质量的表格,用来表示字符对之间的关系,然后预测表格上三角区域的每一项的值,最后通过解码器识别出潜在实体和实体的类别。
2.2.1 条件层归一化
使用条件层归一化构建字符对表格T,条件层归一化在层归一化的基础上,根据条件信息动态生成增益γ和偏置λ,并将这些信息集成到上下文表示。
其中,CLN 是条件层归一化的计算过程,tij是字符对表格T 中坐标为(i,j)的得分,表示字符对(ci,cj)的关系分别是字符ci和cj对应的词向量表示,⊙表示点乘运算,γi和λi表示与相关的 增益参 数跟偏置项,γi=+bα,λi=+bβ,μ和σ分别表 示平均值 和标准差,dh′表示词向量的维度,μ′表示元素值为μ的与同维的常 数矩阵。
然后将结果tij和距离嵌入Ed和区域嵌入Er进行拼接,最后通过多层感知机将这些信息进行融合,生成高质量的 表格表 示
2.2.2 双仿射模型
将词向量H′输入到两个多层感知机中,分别表示实体头部和实体尾部,然后与双仿射矩阵相乘,构造字符对表格T′′。
其中,U,U′和b是可以训练的参数,U代表双仿射矩阵,b是偏置项,⊕表示矩阵拼接操作表示字符对表格T′′中坐标为(i,j)的得分,用来判断从i个字符到第j个字符是否为一个实体。
2.3 解码阶段
在解码阶段,本文使用softmax 分类器对字符对表格中的上三角区域中的每一项进行多分类,然后根据任务的不同选择不同的解码方式。
在平面命名实体识别任务中,选取表格的每一行中得分最高的一项作为实体的边界,并将该项中可能性的最大的类别作为当前实体的类别。在嵌套实体中,表格上三角区域的每一项都对应一个潜在的实体,判断其所有满足得分0 的字符片段C[i:j]都被视为实体输出,与采用CRF 和CRF 的改进版本相比,采用这种解码方式的速度更快。
3 实验与结果分析
3.1 实验数据
在平面实体识别任务中,本文使用的是Resume[1]和MSAR 数据集。其中,Resume 数据集来自新浪财经网关于1 027 位高级经理人的简历摘要数据,标注了人名、国籍、籍贯、种族等8 种实体类别。由于中文嵌套实体领域的数据集相对匮乏,因此本文构造了军事领域的中文嵌套实体数据集(Military)。从人民网、新华网、环球网爬取近一年的军事领域新闻,然后进行分句、筛选等数据清洗工作,接着对已经爬取的8 000 多条数据进行实体标注,预定义了部队、人物、战备工程、国家/地区、机构/组织、职务、时间、地点、政党、合同/协议等15 个实体类别,标注7 万多实体,最后按照7:2:1 比例划分训练集、验证集和测试集,数据集具体分布情况如表2 所示。

表2 数据集分布情况
3.2 实验评价指标
本文采用准确率P、召回率R和F1作为最后的评价指标,对于实体评价的标准使用精确实体匹配方式,即要求实体边界与实体类别均识别正确。
3.3 模型参数设置
本文的实验所使用的深度学习框架为PyTorch,版本为3.7.1,内存为32 GB,预训练模型使用BERT 模型,实验主要参数设置如表3 所示。

表3 实验参数设置
3.4 实验结果分析
本文在公开的平面实体数据集Resume 和军事领域的嵌套实体数据集Military 上进行对比实验和消融实验。
3.4.1 对比实验
(1)中文平面命名实体识别
为验证文本提出模型TLEXNER 识别中文平面命名实体的效果,在Resume 数据集与其他先进模型进行对比,其中,FLAT[2]、SoftLexicon[4]、LEBERT[3]是主流的基于词汇增强的模型。本文使用的方法与实验目标与LEBERT 模型[3]相近,因此将其作为基线方法,实验结果如表4 所示。本文提出的模型与基线方法相比,F1的值由96.08%提升为97.35%,比基线方法增加1.27%,这主要是因为本文使用表格填充的方法代替基线方法中使用的CRF 方法,使用表格填充的方法能够得到字符对之间的关系,而这种关系有利于中文平面实体识别任务。与效果最好的模型W2NER[16]相比,准确率、召回率和F1都有提升,分别为0.81%、0.58%和0.7%。这可能是因为TLEXNER 模型中引入了外部词典所导致。

表4 各模型在Resume 数据集实验结果(%)
(2)中文嵌套命名实体识别
在Military 数据集上,本文提出的模型准确率达到90.28%,召回率达到93.70%,F1值达到91.96%。与先进的模型W2NER[16]相比,准确率与F1的值略有提升,分别为1.04%和0.08%,表明本文提出的模型能够有效完成军事领域的中文嵌套实体识别任务,召回率的值降低了0.98%。召回率降低的原因可能是TLEXNER 模型在解码阶段使用了简单的解码方式,即将表格上三角区域中的每一个大于0 的字符对均视为实体,因此导致了一部分字符对被错误识别成实体。相关实验结果如表5所示。

表5 Military 数据集实验结果(%)
3.4.2 消融实验
为验证本文提出模型的有效性,分别在Resume 数据集和Military 数据集上基于原有模型进行消融实验。实验结果如表6、表7 所示。
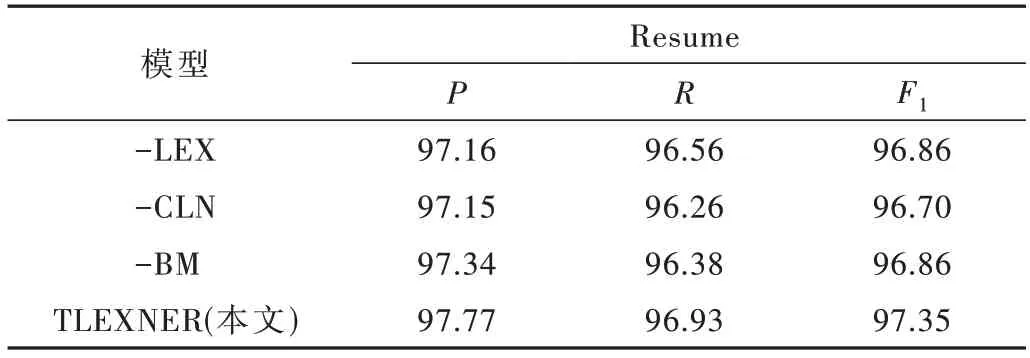
表6 Resume 数据集消融实验结果(%)

表7 Military 数据集消融实验结果(%)
(1)-LEX 表示不在BERT 中引入词典信息。在Resume 和Military 两个数据集上与原模型相比F1值分别降低0.49%和0.48%。消融实验结果表明通过引入外部词典,将词汇信息集成到底层模型中,有利于中文命名实体识别任务。
(2)-CLN 表示删除条件层归一化。在Resume 数据集上与原模型相比,准确率降低0.62%,召回率降低0.67%,F1降低0.65%;在Military 数据集上,准确率降低1.16%,召回率降低0.74%,F1降低0.96%。消融实验结果表明,在中文实体识别的两个任务中使用条件层归一化均有利于构造高质量的字符对表格。相比之下,在Military 数据集中准确率和F1值下降幅度更大,这表明相较于平面实体识别,嵌套实体识别对字符对表格的质量要求更高。
(3)-BM 表示删除双仿射模型。删除了双仿射模型后在Resume 和Military 两个数据集上准确率、召回率和F1值都有一定程度的降低,证明了双仿射模型对中文命名实体识别任务的有效性。而在Military 数据上F1值仅降低0.08%,与其他模块相比降低的数值较少,表明了双仿射模型对嵌套实体识别任务带来的提升有限。
4 结论
本文基于词汇增强和表格填充提出了一个中文命名实体识别的统一模型,能够实现对平面实体和嵌套实体识别。该模型在BERT 中通过词典适配器融合词汇信息,并将字符与词汇的相对位置信息集成到BERT 的嵌入层中,然后通过条件层归一化和双仿射模型构造并预测字符对表格,最后根据字符对表格判别实体的类别。实验在Resume 数据集上,与当今前沿的模型相比,在准确率,召回率和F1的值均有一定提升,F1提升至97.35%,在自行标注的军事领域数据集上,与经典的模型对比,证明了本文模型的有效性。在未来工作中,将探究能否使用空洞卷积获取更多实体边界信息,改善现有模型对嵌套实体的边界识别不够精准的问题。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
电脑爱好者(2022年15期)2022-05-30
系统工程学报(2021年4期)2021-12-21
小学生学习指导(低年级)(2019年12期)2019-12-04
中国外汇(2019年19期)2019-11-26
电子制作(2019年19期)2019-11-23
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
少儿美术(快乐历史地理)(2018年7期)2018-11-16
计算机工程(2014年6期)2014-02-28
