
基于胶囊网络的异常多分类模型*
2024-03-19 11:13:22阳予晋陈志刚
计算机工程与科学 2024年3期
阳予晋,王 堃,陈志刚,徐 悦,李 斌
(1.中南大学计算机学院,湖南 长沙 410083;2.国网宁夏电力有限公司信息通信公司,宁夏 银川 753000)
1 引言
随着传统电网业务乘上IT技术快速发展的东风被搬上云端,电力企业业务以及相关应用数量逐年增长,应用系统的复杂度和规模都在不断增长和变化,数据量也呈现快速增长的趋势,智能电网信息运维工作面临着越来越多的挑战。一个突出的挑战是及时处理各类电网信息设备的异常行为,因此异常数据检测在电网中起着非常重要的作用。在配电网中,使用异常检测技术可以及时发现影响电能的各种异常状态,防止故障扩散[2]。对于运维监控数据,异常检测可以检查设备运行状态,避免故障检测不及时导致的机器损坏[3]。识别电网的异常行为需要开发高效的异常检测方法,这对电网的稳定、实时和安全运行至关重要[4]。电网中的大多数异常可以通过分析时间序列数据来检测,一些传统的异常检测方法能检测的异常种类少且精度低,会导致告警不准确、漏告警、误告警数量多等问题[5]。如果不能及时检测异常,电网的稳定将会面临严重的威胁。因此,准确快速地分析时间序列,挖掘出电网中存在的不同类型的异常是亟待解决的问题。
近年来,许多研究人员一直在研究时间序列建模,特别是使用经典的统计学方法如LOP(Local Outlier Factor)[6]、GMM(Gaussian Mixture Module)[7]、HMM(Hidden Markov Model)[8]、ARIMA(AutoRegressive Integrated Moving Average model)[9]。然而基于统计学的方法需要对大量的样本数据进行统计,难以对高维数据进行异常值检测。除此之外,机器学习的方法也被广泛应用在时间序列异常检测中,如随机森林[10]和SVM(Support Vector Machine)[11]等。与其他机器学习问题场景一样,数据是否被标记是选择使用哪种方法的关键因素。用于异常检测的数据挖掘技术一般可以分为3大类:监督异常检测、半监督异常检测和无监督异常检测。
时间序列数据的无监督异常检测是一项具有挑战的任务。传统的方法通常是基于距离的方法[12],如K-最近邻KNN(K-Nearest Neighbor)算法[13]通过每个数据样本与其K个最近邻的平均距离来计算异常分数。除此之外,聚类模型[14]通过对时间序列进行聚类,并使用预定义好的分数来发现异常值。在基于分类的方法中,如One-Class SVM[15],通过对训练数据的密度分布进行建模,将多元时间序列数据分为正常的和异常的2类。无监督异常检测算法仅根据数据实例的内在属性检测异常值,不需要有标签的数据,这类算法比较灵活,但是其检测精度没有有监督异常检测的高。无监督异常检测可以用于未标记数据样本的自动标记,因此本文利用无监督算法挖掘电网运维监控数据中的潜在异常并自动对其进行标记。
基于有监督的异常检测算法需要对数据集中的每个数据点进行标记,算法使用标签信息来学习正常实例和异常实例之间的差异。由于有监督异常检测算法能准确识别正常实例和异常实例,因此其异常检测准确度更高。有监督异常检测的步骤为:首先对数据集进行标记;其次分类器在标记好的训练数据集上学习正常实例和异常实例,再使用标记好的测试数据集去优化分类器;最后使用训练好的分类器对目标数据集中的异常进行分类。典型的有监督异常检测算法有决策树CART(Classification And Regression Trees)[16]、支持向量机SVM[17]和神经网络模型(如循环神经网络RNN(Recurrent Neural Network)[18,19]、长短期记忆网络LSTM(Long Short Term Memory networks)[20]、多层感知机MLP(MultiLayer Perceptron)[21]等)。基于有监督的异常检测算法的缺点是数据不平衡,在异常检测领域,正常样本比异常样本多得多。为了弥补这一缺点,本文提出了一种基于胶囊网络的多维时间序列异常多分类模型NNCapsNet(Neural Network-Capsule Network)。该方法根据电网实际运维场景以及专家知识,定义异常模式并在数据集中注入故障数据和异常数据,同时利用无监督算法挖掘数据集中的疑似异常并对其进行标记。针对数据集不平衡问题,使用过采样[22]和欠采样[23]技术平衡正常数据和异常数据。与此同时,深度学习的方法被广泛应用在基于分类的算法中,比如胶囊网络[24]。本文提出的模型在原有的胶囊网络基础上增加了2层CNN(Convolutional Neural Network),以充分提取时间序列的特征,用于捕获时间序列的时间依赖性和相关性,处理多维时间序列数据并提取复杂的内在特征,从而实现异常分类。
本文实验数据集采集于国网宁夏电力有限公司营销业务应用服务器生产的监控数据。为了解决训练数据集缺少标签的问题,本文定义了异常模式并在数据集中注入异常数据,结合无监督算法挖掘数据集中的异常并进行标记。最后,将标记好的数据集送入胶囊网络中进行异常分类。
本文的主要工作如下所示:
(1)根据电网实际运维场景,定义了训练数据集的异常模式,结合专家知识在现有数据集上注入异常数据和故障数据,保障异常种类的多样性。此外,结合上采样和过采样的方法解决正负样本不平衡问题。
(2)基于无监督算法标签化电力监控大数据,采用统计判别(3sigma)和无监督算法(k-Means、随机森林和one-class SVM)进行判决,过滤大量正样本并输出疑似异常,结合专家知识对未标记的数据集进行标注。
(3)提出了一种基于胶囊网络的异常多分类模型NNCapsNet,用于处理PC服务器监控数据的异常检测问题。该模型将卷积结构与胶囊网络叠加起来以分层提取运维监控时间序列的特征,并结合标量和矢量计算来处理时间序列数据。
2 电力监控大数据的清洗及其标签化
2.1 数据集介绍
本文实验数据集采集于国网宁夏电力有限公司营销业务应用服务器生产的监控数据的监控时序数据,数据集的属性如表1所示。该数据集提供了2020年3月1日到2020年5月31日的服务器监控数据,采样间隔为每5 min一次。数据集属性的种类包括:主机进程个数、SysCpu使用率、NiceCpu使用率、UserCpu使用率、内存负载、健康运行时长、主机CPU平均负载、IdleCpu使用率、虚拟内存使用率和状态(如表1所示)。
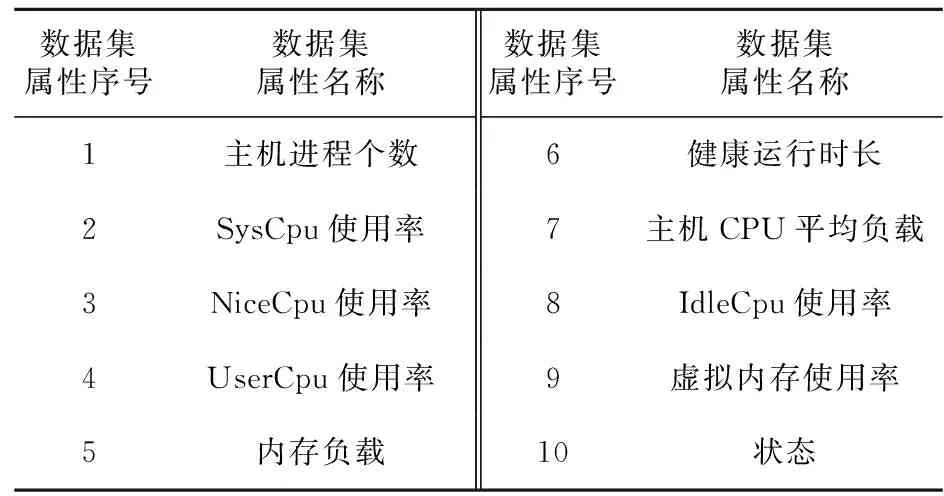
Table 1 Information of dataset attributein State Grid Ningxia Electric Power Co.,Ltd.表1 国网宁夏电力有限公司数据集属性信息
通过对数据集属性进行分析,最终选择UserCpu使用率、内存负载和主机CPU平均负载这3个属性作为异常检测的衡量指标(如图1、图2和图3所示)。内存负载可以反映服务器内存变化的状态,主机CPU平均负载和UserCpu使用率可以从全局和局部体现CPU的健康状况。这3个属性可以全面体现服务器运行状况。
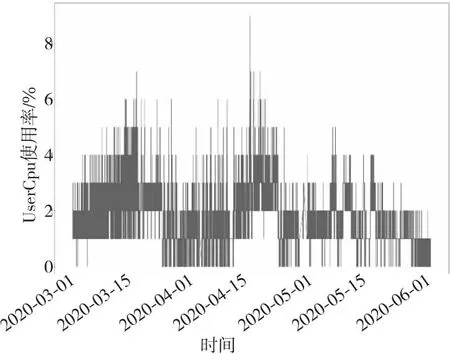
Figure 1 Trend of UserCpu usage rate changing over time图1 UserCpu使用率随时间变化的趋势
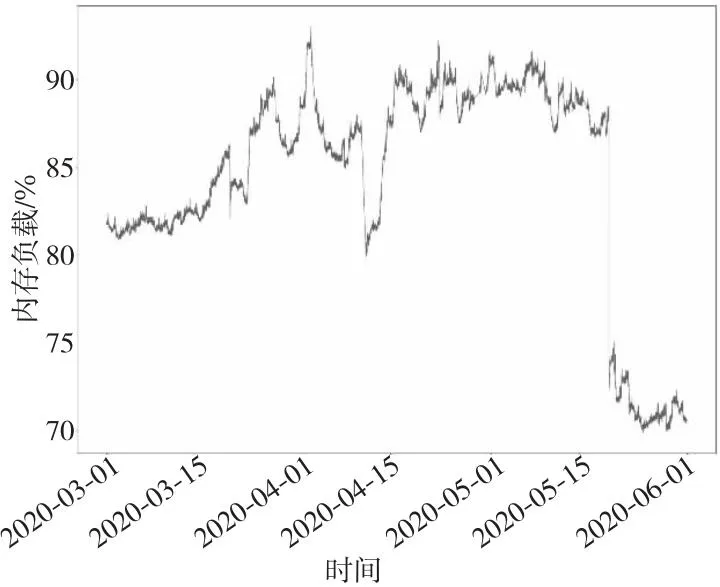
Figure 2 Trend of memory load changing over time图2 内存负载随时间变化的趋势
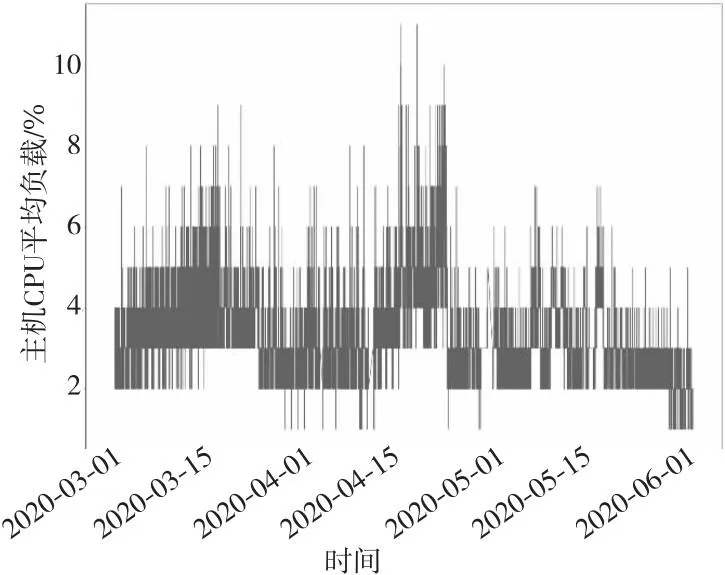
Figure 3 Trend of host CPU average load changing over time图3 主机CPU平均负载随时间变化的趋势
由于训练数据集缺乏标签,而且正常数据远多于异常数据,因此本文需要对数据集进行预处理,注入异常数据,使用无监督算法挖掘疑似异常并对其进行标注。本文构造数据集的方法包括3个步骤:定义异常模式、注入异常数据和使用无监督算法挖掘疑似异常。
2.2 定义异常模式及注入异常数据
根据电网实际运维场景及专家知识,一共定义了10种类型的故障数据。故障数据类型及其对应标签如表2和图4所示。

Table 2 Fault data description表2 故障数据描述
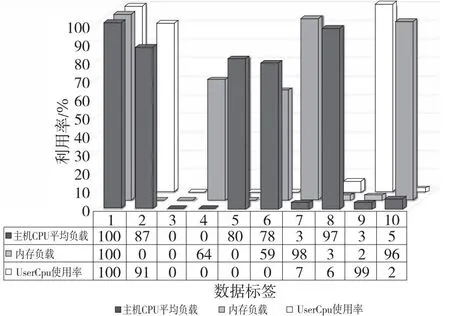
Figure 4 Fault data types and their corresponding labels图4 故障数据类型及其对应标签
当UserCpu使用率、内存负载及主机CPU平均负载这三者的使用率都达到100%时,服务器卡死,标注为1。当内存负载的使用率为0时,无法访问内存,标注为2。当三者的使用率都为0时,服务器死机,标注为3。当UserCpu使用率和主机CPU平均负载使用率都为0时,无法访问CPU,标注为4。当UserCpu使用率及内存负载为0时,CPU和内存同时故障,标注为5。当UserCpu使用率为0时,应用服务器中断,标注为6。当内存负载和主机CPU平均负载并未协调变化时,服务器性能紊乱,服务器业务运行状态与实际监控阈值设计逻辑不符。其中,内存负载处于高峰状态而主机CPU平均负载处于低峰状态,标注为7;主机CPU平均负载处于高峰状态而内存负载处于低峰状态,标注为8。当内存负载和UserCpu使用率并未协调变化时,服务器性能紊乱,服务器业务运行状态与实际监控阈值设计逻辑不符。其中,UserCpu使用率处于高峰状态而内存负载处于低峰状态,标注为9;内存负载处于高峰状态而UserCpu使用率处于低峰状态,标注为10。
根据定义好的异常的模式,挖掘数据集中异常的同时注入故障数据,并采用过采样及上采样技术解决数据集不平衡问题,使得每种异常类型的数据都为400个。
2.3 基于无监督算法标签化电力监控大数据
除了已经定义好的异常类型,本文拟采用无监督算法挖掘出数据集中的疑似异常。利用统计判别和无监督算法过滤掉大量的正样本,人工标注正负样本。本文利用集成学习的思想,采用了统计学上的异常检测方法3-sigma,以及无监督异常检测算法孤立森林、k-Means聚类以及one class SVM。 3-sigma算法及各种无监督算法的原理如下所示:
(1)3-sigma[25]:数据需要服从正态分布。在3sigma原则下,异常值如果超过3倍标准差,那么可以将其视为异常值。如果数据不服从正态分布,也可以用远离平均值的3倍标准差来描述。
(2)孤立森林[10]:异常值是少量且不同的观测值,因此更易于识别。孤立森林集成了孤立树,在给定的数据点中隔离异常值。和其他正常的数据点相比,异常数据点的树路径更短。
(3)k-means聚类[26]:通过计算样本对象到各聚类中心的距离,在不断的迭代循环中,将数据分配到k个类簇中,并通过预定义好的分数来发现异常值。
(4)one class SVM[15]:对训练数据的密度分布进行建模,将时间序列数据分为正常的和异常的2类。
多种算法的组合加强了对正常样本的过滤能力,提高了分类准确率。无监督算法检测疑似异常如图5所示。
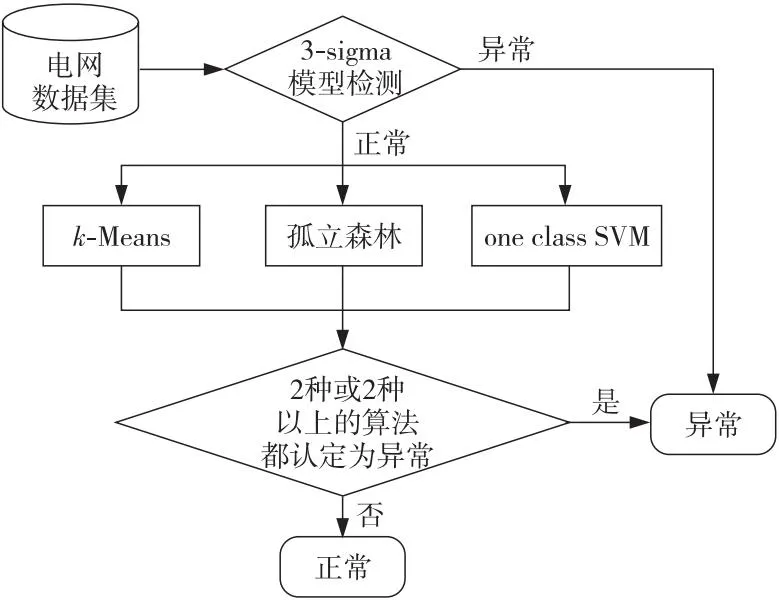
Figure 5 Unsupervised algorithm detects suspected anomalies图5 无监督算法检测疑似异常
如图5所示,本文将多变量时间序列拆分为单变量时间序列,分别对UserCpu使用率、内存负载及主机CPU平均负载进行异常检测。首先基于3-sigma算法检测异常,在3-sigma原则下,如果样本数据超过3倍标准差,那么可以将其视为异常值,直接标注为疑似异常。若3-sigma算法检测为正常,则使用无监督算法进行检测并输出疑似异常。k-Means算法首先对时间序列实施聚类,然后通过子序列到聚类中心的距离来确定异常分数,当异常分数大于某一阈值的时候,将其判定为疑似异常。基于孤立森林的异常检测算法规定了接近二叉树根节点的数据为异常数据,而正常数据远离二叉树根节点。one class SVM算法对数据进行建模,将异常数据划分出来。若3-sigma算法检测为正常时,使用这3种无监督算法进行联合检测,利用集成学习的思想,将2种或2种以上的算法认定为异常的时间点标记为疑似异常。
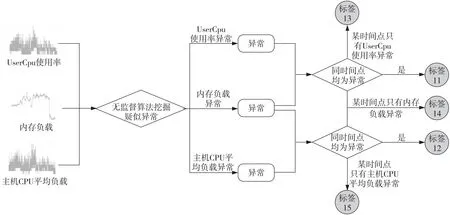
Figure 6 Label suspected anomalies mined based on statistical discrimination and unsupervised algorithms图6 标注基于统计判别和无监督算法挖掘出的疑似异常
图6显示了如何标注基于统计判别和无监督算法挖掘出的疑似异常。首先分别使用无监督算法对UserCpu使用率、内存负载及主机CPU平均负载进行异常检测。如果在同一时间点UserCpu使用率和内存负载都被检测为异常,则标注为11。与此同时,当在同一时间点内存负载和主机CPU平均负载同时被检测为异常,则标注为12。当在某个时间点只有UserCpu使用率异常时,标注为13。当在某个时间点只有内存负载异常时,标注为14。类似地,当在某个时间点只有主机CPU平均负载异常时,标注为15。由于正常数据远多于检测出的疑似异常,因此本文采用过采样技术解决数据集中正负样本不平衡的问题。
标注好的实验数据集如表3所示,正样本和负样本的比例为1∶1,正负样本数据条目都为7 000。其中负样本包含15类异常数据,标签1到标签10的数据条目均为400,标签11到标签15的数据条目都为600。

Table 3 Information of the constructed dataset表3 构造的数据集信息
3 本文模型
3.1 卷积操作获取底层特征
卷积神经网络(CNN)在提取低级空间特征方面性能卓越,已经被广泛应用于图像识别[27]。传统的CNN由3种类型的层组成,即用于特征提取的卷积层、用于压缩特征图的池化层和用于整合局部特征的线性层[28]。其中,池化层可以对数据进行降维,但是在采样过程中可能会丢失重要的特征。因此,为了更准确地提取运维监控时间序列的特征,只保留了卷积层。
输入的时间序列首先与过滤器进行一维卷积,通过滑动窗口实现卷积操作,从而学习局部特征,最后进行线性激活,如式(1)所示:
xtk=f(xt⊗αtk+bk)
(1)
其中,xt表示对应于时间t的运维监控时间序列的输入,xtk表示第k个特征,⊗表示卷积操作,αtk表示连接输入的共享权重,bk表示偏差,f(·)表示激活函数,本文选用ReLU函数。
3.2 动态路由机制提取时间序列特征
3.2.1 胶囊
胶囊是多维向量神经元,封装了有关对象特征的重要信息[24]。总的来说,输出向量的长度代表某个类别实例存在的概率,而方向代表了特征的位置、大小和方向等姿态信息。胶囊网络作为一种新型的深度神经网络,其特点在于胶囊之间是使用向量计算,而不是使用传统的标量计算。胶囊之间的向量计算可以检测特定实例的存在,以运维监控时间序列的特征为例,其计算如图7所示。
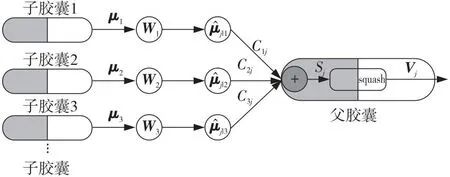
Figure 7 Capsule calculation in time series feature detection of operation and maintenance monitoring图7 运维监控时间序列特征检测中的胶囊计算
每一个时间序列胶囊是一个多维向量,表示为μi。每一个时间序列子胶囊对在一段时间内提取的特征进行编码。然后,对父胶囊Vj进行预测,其表征时间序列的特征。其中,权重矩阵Wj表示第i个子胶囊与第j个父胶囊之间的部分-整体关系,其关系如式(2)所示:
(2)
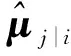
3.2.2 动态路由机制
运维监控时序特征提取的关键在于动态路由。动态路由是一种迭代路由机制,可以用于信息的选择,确保从时序子胶囊中提取的特征可以发送到与预测最一致的时序父胶囊中。时间序列特征提取的动态路由机制如图8所示。在图8中,小三角和小圆点都表示时序胶囊的预测向量,即运维监控时序特征。图中的小圆点聚集在一起代表预测相似,而小三角点分散则代表预测差异大。从图8可以看出,子胶囊层的时序胶囊通过耦合系数Cij连接到父胶囊层的时序胶囊,耦合系数Cij决定了时序胶囊的输出,即需要提取的时间序列特征。
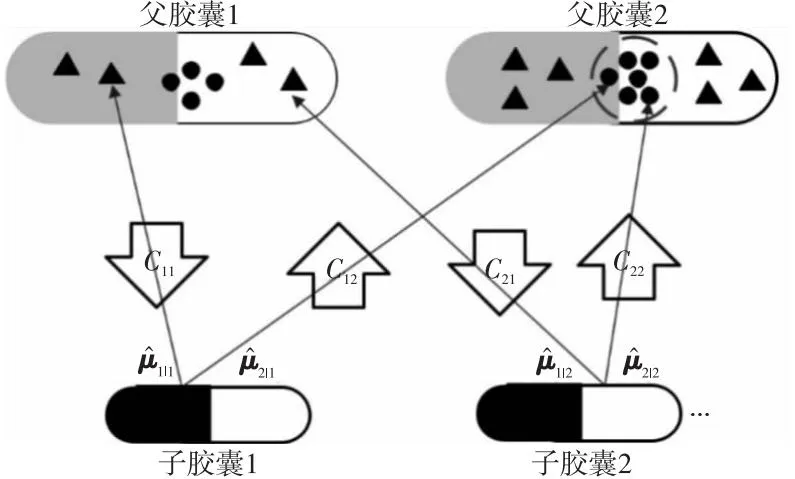
Figure 8 Dynamic routing mechanism for time series feature extraction图8 用于时间序列特征提取的动态路由机制
时序胶囊的预测需要大部分都指向同一个父胶囊的小圆质心。时序子胶囊通过调整耦合系数Cij来决定路由到哪个时序父胶囊,耦合系数Cij由softmax函数计算,如式(3)所示:
Cij=exp(bij)/∑mexp(bmk)
(3)
(4)
其中,使用squash函数让输出向量的长度不超过1,从而表示一个时序特征的检测概率,如式(5)所示:
(5)
其中,下标j代表第j个输出向量。
式(3)中的临时变量bij根据式(6)更新:
(6)
3.3 损失函数
胶囊网络损失函数由2部分组成,即间隔损失 (Margin Loss)和重构损失(Reconstruction Loss)。其中间隔损失函数如式(7)所示:
Lk=Tkmax(0,m+-‖vk‖)2+
λ(1-Tk)max(0,‖vk‖-m-)2
(7)
其中,当k存在时,Tk=1,否则Tk=0;m+表示惩罚假阳性上界;m-表示惩罚假阴性下界;λ表示比例系数。
3.4 基于胶囊网络的异常多分类模型框架
电网信息设备监控数据是按时间顺序排列的数据,而影响时间序列分类的重要特征可以由卷积层获得。因此,为了充分获取时间序列的局部特征,本文采用了3层1D-CNN进行特征提取。本文模型将卷积结构和胶囊子网络叠加起来,分层捕获时序特征。基于胶囊网络的异常多分类模型如图9所示。
Figure 9 Anomaly multi-classification model based on capsule network图9 基于胶囊网络的异常多分类模型
基于胶囊网络的异常多分类模型主要分为4个部分:第1部分是特征提取层,使用了3层1D-CNN进行特征提取,通过多个不同的卷积核在时间序列的不同位置提取特征;第2部分是子胶囊层,该层将原始局部时序数据特征封装成含有低层特征的时序子胶囊,并使用squash函数进行压缩;第3部分是父胶囊层,在这一层中,时序胶囊通过与权重矩阵相乘来计算时序子胶囊与时序父胶囊的关系,然后根据动态路由协议来更新上层时序胶囊的权重;第4部分是全连接胶囊层,该层将时序数据的标签转换成一个概率分布,取概率值最大的作为最终的分类结果。最后,再使用重构网络对最终生成的时序胶囊进行重构,将重构网络生成的重构误差作为异常多分类模型损失函数的一部分。
3.5 基于胶囊网络的电网多维时间序列数据异常检测流程
由于训练数据集缺乏标签,而且正常数据多于异常数据,因此本文结合电网实际运维场景及专家知识定义了电力信息系统典型业务服务器中的10种异常类型,并在数据集中注入各种类型的异常数据和故障数据,保障异常种类的多样性。本文在数据集中一共标注了15种异常,正常数据标注为0。采用上采样和过采样技术解决数据集正负样本不平衡问题,使得正常数据和异常数据的比例为1∶1。最后使用NNCapsNet对标注好的数据集进行异常分类。对应的检测流程如图10所示。
基于胶囊网络的电网多维时间序列数据异常检测方法主要包括3个步骤:第1步是收集电网实际运维场景的原始数据集,包括UserCpu使用率和内存负载等;第2步是对收集好的数据集进行标记,根据定义好的异常模式,并基于无监督异常检测算法及统计学上的异常检测方法挖掘数据集中的异常,同时注入故障数据,并采用过采样及上采样技术解决数据集不平衡问题,最终获得的数据集如表3所示;第3步是将处理好的训练数据输入2.4节描述的基于胶囊网络的异常多分类模型中,进行异常数据多分类实验。
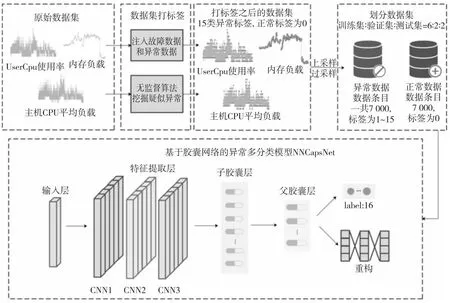
Figure 10 Anomaly detection process of power grid multi-dimensional time series data based on capsule network图10 基于胶囊网络的电网多维时间序列数据异常检测流程
4 实验及结果分析
4.1 实验设置
本文数据集采集于国网宁夏电力有限公司营销业务应用服务器生产的监控数据的UserCpu使用率、内存负载及主机CPU平均负载数据,关于每个监控数据指标的统计数据如表4所示。本文的所有算法均采用Python 3.8实现,实验环境采用Window 10,AMD RyzenTM5 3550H with RadeonVega Mobile Gfx2.10 GHz,16 GB内存。神经网络使用PyTorch 1.4.0+cu92实现。
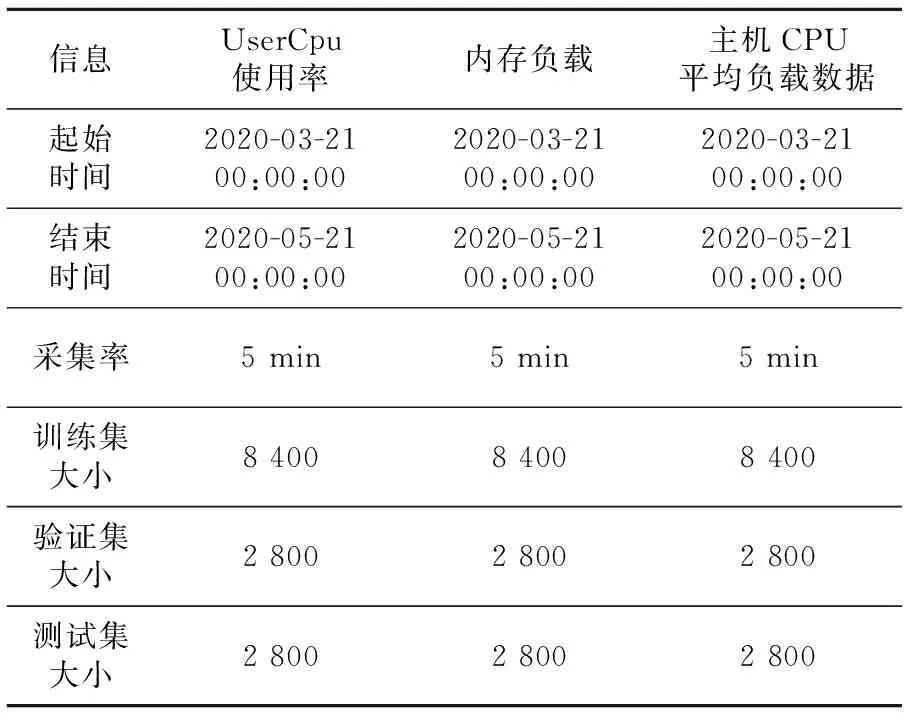
Table 4 Information of modeling data 表4 建模数据信息
本文为了使输入数据保留时间纬度,从时间戳中提取了年、月、日、分这4个纬度,再加上UserCpu使用率、内存负载及主机CPU平均负载,最后输入层的大小为71。本文实验的batchsize为100,训练次数为200,学习率为1e-3。特征提取层由3层1D-CNN(内核大小为3,步幅为1,padding为2)组成。子胶囊层的胶囊为四维(4D),胶囊个数为16。父胶囊层则由16个八维(8D)胶囊组成,分别对应于异常类别的出现概率。更详细的实验超参数如表5所示。

Table 5 Experimental parameters of NNCapsNet 表5 NNCapsNet实验参数
4.2 评估指标
异常检测模型有效性可以通过不同指标进行评价。本文使用ROC曲线画出假阳性率和真阳性率的关系,通过计算ROC曲线下的面积AUC(Area Under the Curve)来评价模型的性能。AUC可以直观反映分类器的效果,值越大分类效果越好。除此之外,本文还使用了准确率Acc(Accuracy)、P(Precision)、R(Recall)和F1(F1-Score)来进一步衡量模型的性能。它们的定义分别如式(8)~式(11)所示:
(8)
(9)
(10)
(11)
其中,P表示正确预测的正样本数占所有预测为正样本的数量的比值,R表示正确预测的正样本数占真实正样本总数的比值,F1为模型准确率和召回率的调和平均值。
通过确定正确的标签是否在前k个预测标签中来计算 Topk准确度。本文用Top1Acc来表示在前1个预测标签中计算准确度,采用Top2Acc来表示在前 2个预测标签中计算准确度。此外,AUC曲线的假阳性率FPR及真阳性率TPR的定义分别如式(12)和式(13)所示:
(12)
(13)
其中,TP表示真阳性结果的数量,FP表示假阳性结果的数量,TN表示真阴性结果的数量,FN表示假阴性结果的数量。
4.3 异常多分类效果
4.3.1 使用测试集评估各标签的分类情况
本文将数据集按6∶2∶2划分为训练集、测试集和验证集,以评估NNCapsNet的性能,图11和图12给出了测试集各标签的分类情况。其中,图11使用柱状图直观地反映各标签的分类性能,图12绘制了各标签的ROC曲线图,依次是从标签0到标签15,实线为各个类的ROC曲线,点虚线为micro-average曲线图,-虚线为macro-average曲线图。从图11和图12中可以看出,各标签均取得了较好的分类效果,其中标签1的分类效果最好,Accuracy、AUC、P、R和F1均达到了1。这是因为标签1的异常变化趋势最明显,模型可以很好地区分此类异常。标签2、标签3、标签4、标签6、标签8和标签9均取得了较好的分类效果,Accuracy、P、R和F1均达到0.95以上。其中除了标签2的AUC值为0.988以外,其余标签的AUC值均为1。这些标签的分类效果没有标签1的分类效果好,这是因为这些标签的异常变化趋势不如标签1那么明显。除此之外,标签10、标签11、标签12及标签14的Accuracy、R和F1均达到了0.85以上,AUC值达到了0.98以上。无监督异常检测算法仅根据数据实例的内在属性检测异常,因此检测的异常数据的变化趋势没有人工标注的异常数据那么明显,标签2~标签9的分类效果没有标签1的分类效果好。以上实验结果表明,NNCapsNet可以有效地识别多种异常模式并且检测精度高,可以更高效、更精确地检测故障,避免了因为检测不及时导致的机器损坏和业务损失,从而提高电网及其系统的稳定性。
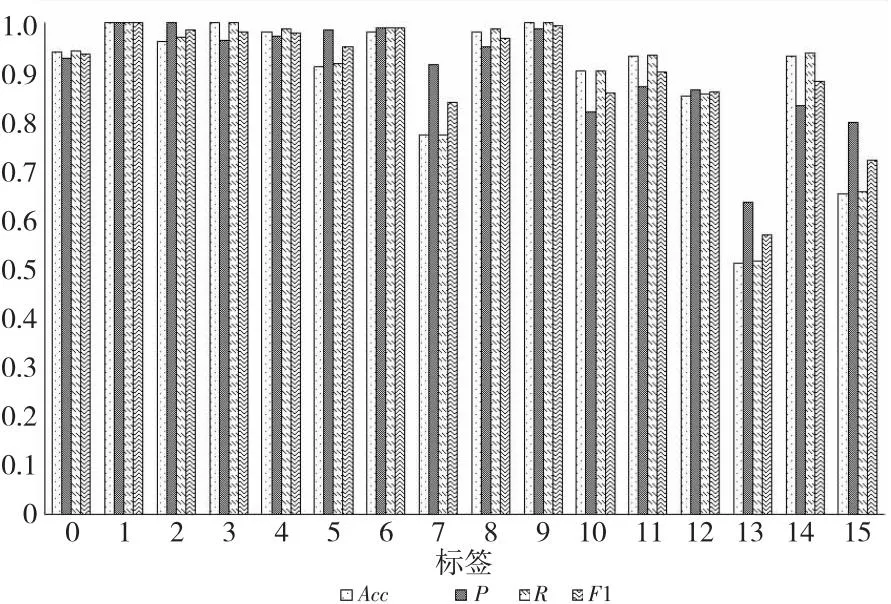
Figure 11 Classification results of various labels on the test set using NNCapsNet图11 NNCapsNet在测试集上各标签的分类结果
4.3.2 五折交叉验证
本文采用五折交叉验证法评估NNCapsNet的性能,表6和图13总结了五折交叉验证的实验结果。如表6所示,5次验证的Top1Acc和Top2Acc的均值分别为0.9061 6和0.970 7,说明NNCapsNet的异常分类准确率较高;在AUC方面,5次验证的AUC分别为0.982 1,0.982 1, 0.985 4,0.979 0和0.981 7,也反映了本文模型具有良好的分类效果;5次验证的F1、P和R的均值分别为0.898 1,0.921 7和0.898 2,综合反映了本文的NNCapsNet在异常分类方面具有良好的性能。
4.3.3 特征提取层
表7和图14总结了使用不同的CNN层作为特征提取层在五折交叉验证框架下的性能比较。其中,1层CNN代表原有的胶囊网络,2层~5层CNN代表本文在原有胶囊网络的基础上,增加了1层~4层的CNN作为特征提取层。实验结果表明,模型的性能随着层数的增加而提高。峰值点在CNN层数为3时,在那之后模型的性能开始下降。当使用3层CNN作为特征提取层时,模型的性能最佳,其Top1Acc、Top2Acc、P、R和F1均高于其他多层CNN的,分别达到了0.906 2,0.970 7,0.921 7,0.898 2和0.898 1。此外,AUC值和其他多层CNN的相差无几。这表明在原有胶囊网络的基础上增加CNN层作为特征提取层可以充分提取多维时间序列的局部特征,保留了时间序列的时间依赖性和相关性,从而提高异常分类的准确率。但是,当CNN的层数不断增加时,特征提取层提取到的特征变得越来越相似,导致过度平滑,模型性能开始下降。
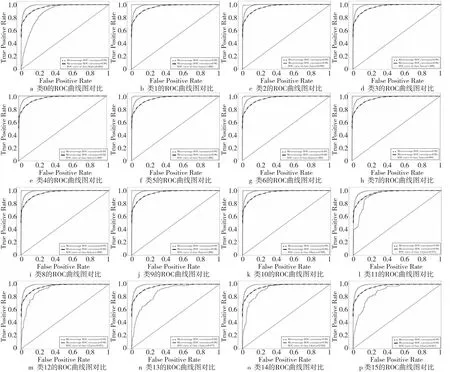
Figure 12 ROC curve of each label on the test set using NNCapsNet图12 NNCapsNet在测试集上各标签的ROC曲线

Table 6 Five-fold cross-validation results of NNCapsNet
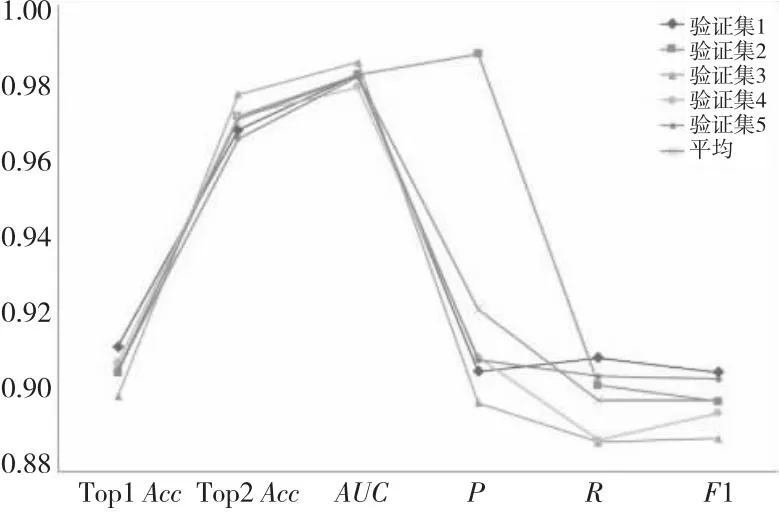
Figure 13 Five-fold cross-validation charts of NNCapsNet图13 NNCapsNet的五折交叉验证折线图
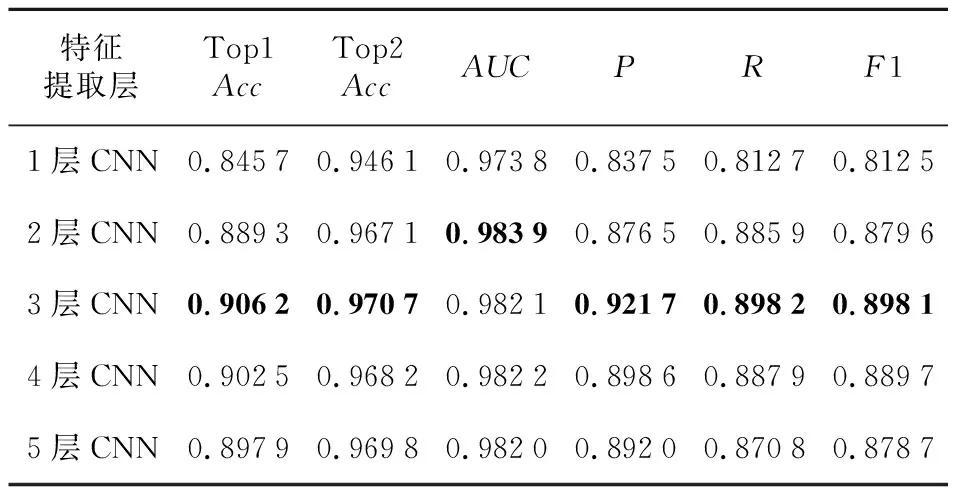
Table 7 Performance comparison of different feature extraction layers under five-fold cross-validation framework表7 不同特征提取层在五折交叉验证框架下的性能比较
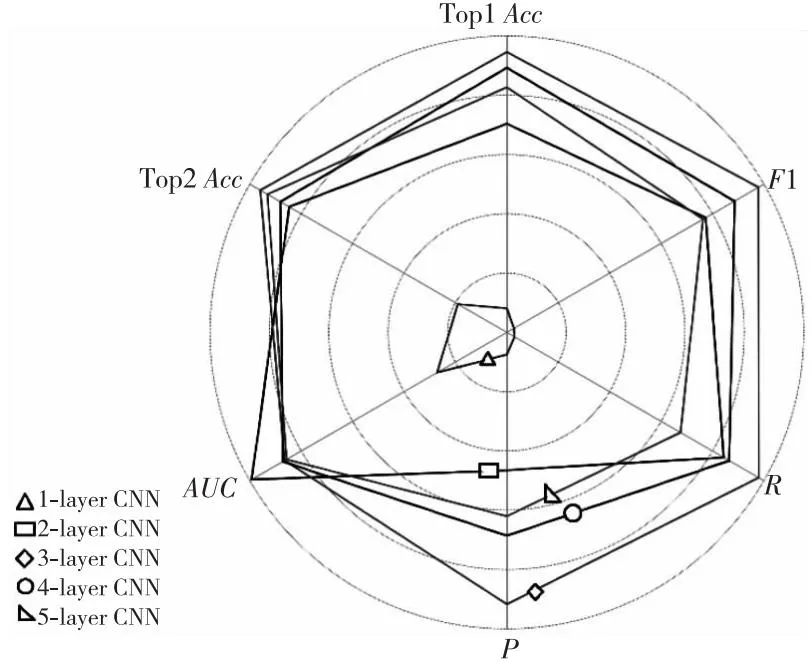
Figure 14 Performance comparison of different feature extraction layers图14 不同特征提取层的性能比较
4.4 动态路由迭代次数
表8和图15总结了胶囊网络中动态路由迭代次数对模型性能的影响。实验结果表明,模型的性能随着迭代次数的增加而提高。当迭代次数为3时,模型的性能最佳,其Top1Acc、Top2Acc、AUC、P、R和F1分别达到了0.906 2,0.970 7, 0.982 1,0.921 7,0.898 2和0.898 1。当迭代次数不断增加时,模型性能开始下降。
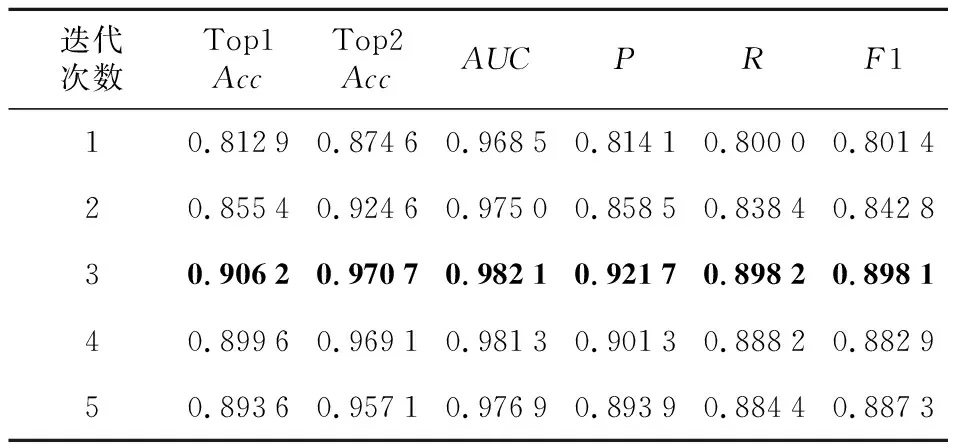
Table 8 Impact of numbers of dynamic routing iteration on model performance表8 动态路由迭代次数对模型性能的影响

Figure 15 Line charts of impact of numbers of dynamic routing iteration on model performance图15 动态路由迭代次数对模型性能影响折线图
4.5 与基准模型的比较
为了进一步验证基于胶囊网络的异常多分类模型NNCapsNet的有效性,在国网宁夏电力有限公司营销业务应用服务器生产的监控数据上将NNCapsNet与4个基准模型进行了比较。4个基准模型的具体描述如下所示:
(1)CNN:本文采用了4层一维卷积层对时间序列数据进行特征提取,全连接层用于对异常进行分类,此外softmax层用于输出样本数据的标签。
(2)LightCNN[25]:在 CNN 的每个卷积层中引入了 maxout 激活的一种变体MFM(Max- Feature-Map)。MFM是通过竞争关系来实现的,其不仅可以分离噪声和信息信号,还可以在2个特征图之间起到特征选择的作用。此外,还提出了一种语义引导方法,使网络的预测与噪声标签更加一致。
(3)AlexNet[30]:该架构由8层组成,包括5个一维卷积层和3个全连接层。在该框架中,使用ReLU激活函数加速收敛,引入了池化层防止过拟合。
(4)CNN+RNN[31]:以不同方式结合了CNN和RNN。其中,CNN负责从数据集中提取有用的特征;RNN负责从提取的特征中找到隐藏的时间模式,它充当了异常分类器的角色。
表9和图16显示了NNCapsNet与其它4个模型的性能比较。很明显,NNCapsNet在大多数关键指标上都优于其它4个模型的。NNCapsNet的AUC、Top1Acc值和Top2Acc分别达到了0.982 1,0.906 2和0.970 7,明显高于其它4个模型的。除此之外,NNCapsNet的P、R和F1都取得了较高的值,分别达到了0.921 7,0.898 2和0.898 1。CNN在池化过程中会丢失部分特征,因此NNCapsNet的分类效果高于CNN的。 AlexNet的网络比CNN更大更深,使用了最大池化代替平均池化,AlexNet的分类效果比CNN的要好,比NNCapsNet的差。CNN+RNN模型使用CNN提取特征,使用RNN充当异常分类器,然而一层CNN无法充分提取时序特征,因此CNN+RNN的分类效果不如NNCapsNet的。总之,实验结果充分表明,NNCapsNet在时间序列异常多分类方面具有较好的性能,可以有效提高运维监控数据的异常检测准确性。
5 结束语
本文提出了一种基于胶囊网络的多维时间序列数据异常多分类模型,并对该模型进行了综合测试,还将其与其它异常多分类模型进行了比较。采用来自国网宁夏电力有限公司营销业务应用服务器生产的监控数据验证了本文模型的可行性和有效性。实验结果表明,NNCapsNet可以检测电力信息系统典型业务服务器的不同类型的异常,并且检测精度高,避免了故障检测不及时导致的物理硬件损坏和线上业务中断带来的经营性损失,维持了电力信息设备及系统的稳定和安全运行。
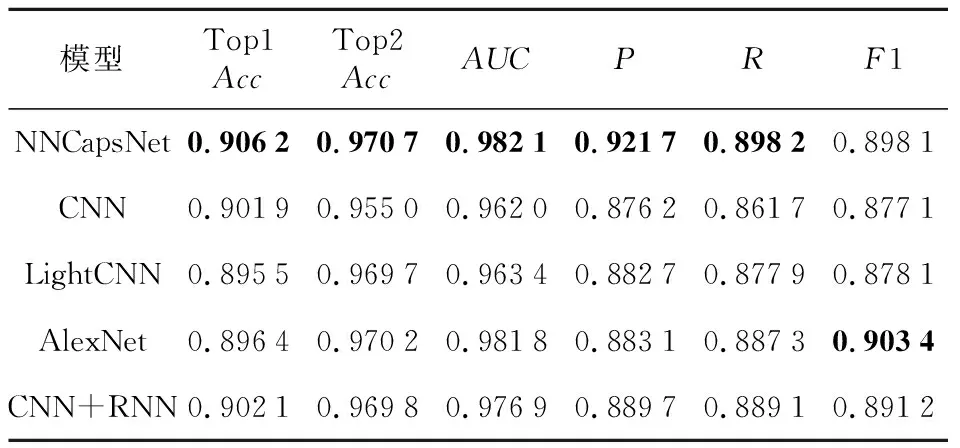
Table 9 Performance comparison between NNCapsNet and other four models表9 NNCapsNet与其它4个模型的性能比较

Figure 16 Performance comparison between NNCapsNet and the other four models图16 NNCapsNet与其它4个模型的性能比较
猜你喜欢
当代陕西(2019年13期)2019-08-20 03:54:22
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
中国社区医师(2015年10期)2015-01-27 06:41:56
测绘科学与工程(2014年5期)2014-02-27 07:06:14
初中生学习·低(2012年4期)2012-04-29 04:29:50
初中生学习·低(2012年7期)2012-04-29 00:44:03
中国建设信息化(2011年2期)2011-09-22 01:09:22
