
基于特征变量扩展的含气饱和度随机森林预测方法
2024-03-16 03:24桂金咏李胜军高建虎刘炳杨
岩性油气藏 2024年2期
桂金咏,李胜军,高建虎,刘炳杨,郭 欣
(中国石油勘探开发研究院西北分院,兰州 730020)
0 引言
含气饱和度是天然气藏商业价值评估、储量提交、井位优选、剩余气描述等定量化分析工作的重要物性参数,可以直接通过试气数据或使用测井曲线解释得到。目前,在地球物理勘探领域已经提出了大量含气饱和度测井解释方法,但有关含气饱和度的地震解释方法却较少[1-3]。利用地震数据预测天然气藏的含气饱和度是一种复杂的、多解性的以及高度非线性的地震反演问题,现有的试图从地震信息中解译出含气饱和度信息的方法,大多都是借助叠前地震反演技术先从叠前地震数据中反演出弹性参数数据,继而重点研究如何更高精度地将弹性参数数据进一步反演为含气饱和度等物性参数,而物性参数与弹性参数间的岩石物理模型则起到一种正、反演基本准则的作用。Bachrach[4]以经典的Gassmann 方程为基础,建立了纵波阻抗、横波阻抗及密度与孔隙度、饱和度等物性参数间的统计岩石物理模型,实现了孔隙度和饱和度的联合反演。胡华锋[5]结合统计岩石物理模型与贝叶斯分类器,对储层物性参数进行了反演。De Figueiredo 等[6]利用混合高斯模型获取物性参数的先验分布概率密度函数,提出了贝叶斯线性解析化物性参数反演方法。刘兴业等[7]针对统计岩石物理反演中似然函数难以表征的问题,采用核估计的方法得到了条件概率密度函数,基于核贝叶斯判别法预测物性参数。李红兵等[8]提出了一种基于弹性阻抗的、适用于复杂孔隙储层孔隙结构的饱和度反演方法。另外,为了避免地震数据到弹性参数数据,再到物性参数数据这种“两步”反演方法误差传递的问题,也有学者尝试将岩石物理模型与Zoeppritze 地震反射方程或其简化方程相融合,提出了物性参数地震直接反演方法,直接将叠前地震数据反演为含气饱和度、孔隙度等物性参数数据。桂金咏等[9]结合包裹体岩石物理模型将双相介质地震反射系数推导成含气饱和度、孔隙度和泥质含量的函数,并对其应用差分进化算法求解。Lang 等[10]在Gassmann 方程的基础上,结合临界孔隙度模型,推导了流体体积模量、剪切模量及密度随岩石基质、流体参数的偏导数,发展了基于贝叶斯线性反演的叠前地震AVO 物性预测。Liu 等[11]基于Kuster-Toksöz 岩石物理模型推导了饱和岩石模量的线性近似式,采用基于柯西约束的贝叶斯最大后验概率解,开展了叠前地震确定性物性参数反演。李坤等[12]推导了利用KT 岩石物理模型高阶近似和Gray 地震反射模型表征的叠前地震AVO 反射系数方程,假设在待反演物性参数服从混合概率先验模型的前提下,直接反演出孔隙度、饱和度及泥质含量。Fjeldstad 等[13]利用高斯混合模型表示含气饱和度等物性参数的先验分布特征,结合地质统计学空间模拟技术,提出了含气饱和度的“一步法”地质统计学反演。
实际上,无论是“两步法”还是“一步法”都离不开岩石物理建模过程。对于地质条件日趋复杂的天然气探区,弹性参数与物性参数间的岩石物理关系往往具备极强的非线性,极易受到实际研究区岩性、孔隙结构、压力、温度等多种因素的影响,导致在大多数情况下难以建立起精确的岩石物理模型[14-17]。机器学习方法的出现为这类非线性建模问题提供了一种新的途径。机器学习方法可以通过机器自主学习得到一种非线性映射关系,实现高度复杂的非线性函数逼近,具有强大的学习数据集本质和高度抽象化特征的能力。通常根据训练是无监督的还是有监督的进行分类。无监督学习无须训练数据集,直接基于输入数据的分布或结构来对信息相似的数据进行分组和映射;监督学习则需要训练数据集,包括输入数据和标签,标签是输入的响应值。监督学习的主要目标是从标记的训练数据中学习出一个最优的映射模型,将已知领域知识与数据本身进行结合,能够有效减少预测的多解性。在众多的监督机器学习算法中,随机森林(Random Forests,简称RF)近年来在地球物理学领域取得了较好的应用效果[18]。Breiman[19]提出的RF 是一种集合学习算法,结合了bagging 集合和随机特征选择的思想,预测结果由多个决策树分类器投票决定。多个决策树的作用相当于组合很多非线性关系形成更复杂的非线性关系,具有预测精度高、对异常值和噪声数据容忍度高等优点,已广泛应用于金融、生物、遗传、图像识别、医学等领域。在地球物理领域,Harris 等[20]将随机森林算法应用于地球物理和地球化学数据联合岩性分类。宋建国等[21]针对储层预测的复杂非线性及稳定性问题,将随机森林回归算法引入到地震储层预测中,建立地震属性与自然伽马之间的非线性关系。王光宇等[22]考虑了不平衡样本对随机森林岩性分类问题的影响。Kuhn 等[23]利用地球物理和遥感数据对金矿附近未开采区域的岩性进行了分类研究。Cracknell 等[24]将RF 与SVM、朴素贝叶斯、K 近邻和人工神经网络进行了岩性预测效果比较,认为RF 优于其他机器学习算法,并且证明了RF 能够以更简单的输入参数和更少的计算成本产生准确的结果。
以往研究结果表明,对于岩性和流体识别等离散数据的分类问题,利用若干个对目标敏感的地震衍生属性,如振幅、频率以及弹性参数等作为输入特征变量,即可获得较好的分类结果[25-27],而对于含气饱和度这类连续数值的回归问题,特征变量的数量对预测结果的影响尚未明确。离散分类问题和连续值回归问题在算法本质上差别不大,但对参与训练的特征变量的数量依赖程度不同。连续值回归问题可以看作是将连续值按极小的间隔离散化的分类问题,只是所分类别较多,对参与训练的特征变量的数量要求也更大。通常情况下,训练中涉及的特征变量越多,所携带的信息越丰富,训练结果可能更准确、泛化性能更好[27],但如果无限制地增加特征变量数量,会导致工作量巨大。另外,含气饱和度训练样本的取值分布往往具有“非平衡”特征,尤其是复杂天然气探区,含气层往往薄薄地发育在大套背景岩性中,当高含气层样本过少,而低含气层样本过多时,会使训练结果向低含气层偏倚,导致含气饱和度的预测准确率较低。
基于随机森林(RF)预测含气饱和度,引入合成少数类过采样技术以消除样本不平衡对RF 训练的影响,采用自动特征变量扩展策略解决含气饱和度回归对特征变量数量的依赖,利用随机森林对特征变量进行含气饱和度预测重要性排名,优选重要性较高的特征变量进行最终随机森林训练,并将该方法在实际工区中进行应用,以期提高地震信息对天然气藏含气饱和度的定量预测能力。
1 方法原理
1.1 特征变量扩展
RF 算法用于含气饱和度预测的一个关键步骤是要准备足够的特征变量作为训练集。Alvarez等[28]对纵波阻抗、横波阻抗、纵横波速度比、拉梅参数×密度、剪切模量×密度、拉梅参数/剪切模量、(拉梅参数-剪切模量)×密度、泊松比、杨氏模量×密度、体积模量×密度、泊松阻抗等11 种常用的地震弹性参数进行数学变换,得到了大量的地震衍生属性作为孔隙度、含水饱和度与泥质含量等物性参数线性回归的基础属性集,在常规碎屑岩物性参数预测中取得较好的应用效果。然而,且不论该方法采用线性回归的合理性,实际上常用的弹性参数的数量就远远超过11 种,该方法可能会遗漏对目标敏感的弹性参数。另外,每个弹性参数的获取都需要基于叠前地震反演或利用不同的变换公式转换得到,自动化程度较低,且变换过程中也存在误差积累和放大的风险。尤其是对于各向异性比较明显的致密砂岩或页岩气藏,叠前地震反演本身就存在极大的不确定性。为克服人工准备大量特征变量的问题,利用扩展弹性阻抗(EEI)自动生成一系列弹性属性作为特征变量。Whitcombe 等[29]在Connolly弹性阻抗方程的基础上提出了EEI方程的定义:
式中:χ为角度,(°),取值-90°~90°;vp,vs,vp0和vs0分别为纵波速度、横波速度、目的层平均纵波速度和平均横波速度,m/s;ρ和ρ0分别为密度和目的层平均密度,kg/m3;k=vs2/vp2。
由式(1)可知,EEI可以由vp,vs和ρ这3 个基本的弹性参数计算得出,通过调整χ的大小可以对EEI进行调整,当其与一些弹性参数近似成正比,可以用于岩性或流体识别[29]。此外,EEI还可以对常见的测井属性(如电阻率、伽马)进行较好的拟合[30]。通过叠前地震反演技术易获得vp,vs和ρ这3个基本的弹性参数体,使用不同值的EEI作为特征变量替代常规弹性参数。
首先,针对从叠前地震反演获得的弹性参数存在一定误差这一问题,直接从叠前地震反演得到的弹性参数数据体中提取井旁道的纵波速度、横波速度和密度伪井曲线作为与含气饱和度测井解释标签对应的弹性参数样本,采用机器学习算法进行处理。即使训练样本带有一定的误差,机器学习也能在无意识下学习得到包含噪声的映射模型,直接将带有误差的特征变量映射为含气饱和度。需要注意的是,特征变量的误差也不能过大,会削弱有效信息。其次,设定角度χ 的变化步长,将纵波速度、横波速度和密度伪井曲线带入式(1),自动生成一系列不同角度的EEI曲线。然后,根据Alvarez等[28]的数学变换思想,采用对数、指数、倒数、平方、开方运算对扩展弹性阻抗进一步扩充,以设定χ为5°为例(表1),每个数字代表一个特征变量,可得到222 个弹性属性作为特征变量数据集。最后,将生成的井旁道特征变量和对应的含气饱和度测井解释标签作为监督学习的原始训练集。

表1 扩展特征变量Table 1 Extended feature variables
在实际操作中,还可以针对具体条件来设定需要扩展的特征变量的数量。为了尽量不遗漏潜在的目标敏感弹性属性,χ 的变化步长可以设定得更小,以获得更多的特征变量。另外,也可以使用或增加其他的数学运算方法来进行自动转换,进一步扩充特征变量的种类来增加特征变量数据集中有敏感性属性的可能性。
1.2 样本平衡化处理
RF 算法的核心是采用Bootstrap 抽样法对原始样本集进行重新抽样,随机生成k个子训练集S1,S2,...,Sk。通过Bootstrap 抽样,每个训练子集平均包含约63.2%的样本,而剩余37.8%的“袋外”样本则用于验证[19]。每个子训练集所包含的元素不尽相同,这可以保证决策树的多样性,使得训练模型具备泛化性,但在Bootstrap 抽样过程中,所有样本每次抽样的概率都是相同的,这就意味着在不同类别样本数量差别很大的样本集上训练时,往往会出现分类面向多数类样本偏倚的现象,少数类样本无法获得理想的分类效果。近几年来,机器学习中不平衡数据的分类问题受到了越来越多的关注[31],这里的“不平衡数据”是指分类问题中对应于每个类别的样本数量是不同的,而且数量差异较大。这种不平衡数据往往会恶化机器学习算法的性能[32],如在进行岩性识别时,当样本集中目标岩性(如含气砂岩)的样本数量过少,而非目标岩性(如泥岩)的样本数量过多时,会使预测结果向非目标岩性偏倚,导致目标岩性的预测准确率较低。同样,对于含气饱和度回归也有这样的问题。在中国西部地区,有利气藏通常厚度较小,发育在大套地层中,若含气饱和度较高的有利储层训练样本数较少,而含气饱和度较低的非有利储层的训练样本数较多,RF回归器的训练可能会偏向于非有利储层,影响有利储层的含气饱和度回归精度。
对于不平衡数据的处理一般有过采样和欠采样2 种方法。过采样是通过复制少数类样本来增加其规模,欠采样则是随机删除一些多数类样本的数量。考虑到机器学习含气饱和度回归主要以测井数据作为训练样本,而测井成本较高,往往数量也不多,因此不删除多数类样本,而是采用过采样方法来处理少数类样本。在机器学习领域,应用较多的过采样方法是合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE),该技术通过分析少数类样本的特征,人工合成新的样本,并将新的样本加入到数据集中,直到各类样本的数量趋于平衡,形成一个大的平衡训练集,其实施步骤如下[33]:
(1)对于少数类中的每个样本,利用欧式距离计算其与少数类中所有样本的距离,并获得m个最近的邻点。
(2)根据不平衡类比例设定抽样比例,确定少数类样本的抽样放大最终数量为N。对于少数类中的样本x,从m个最近的邻点中随机选择几个样本y,构建新的样本z:
式中:rand(0,1)为随机数,取值0~1。
(3)重复步骤(1)—(2),直到少数类样本数量增加到预先设定的数值N。
然而,该方法并没有考虑样本的边界问题,可能会造成样本取值的大量重叠,在离群点附近也会产生一些不能提供有效信息的样本,降低学习性能。边界合成少数过采样技术(BSMOTE)是在SMOTE 基础上改进的过采样算法[34],如图1 所示,该算法在采样过程中将少数类样本分为“安全”“危险”和“噪声”3 类,“安全”类别是指邻域超过一半的样本是少数类样本(如图1 中点A 所示);“危险”类别是指邻域超过一半的样本为多数类样本,视为边界上的样本(如图1 中点B 所示);“噪声”类别是指样本被多数类样本包围(如图1 中的点C 所示),只对被标记为“危险”的样本进行过采样合成新样本,可以改善样本的类别分布。

图1 BSMOTE 原理示意图Fig.1 Schematic diagram of BSMOTE
1.3 随机森林回归器构建
作为一种数据驱动算法,RF 对每个Bootstrap抽样得到的子训练集S1,S2,...,Sk分别进行决策树建模,从而显著提高了模型的准确性和鲁棒性,在处理各种复杂的预测和分类问题时表现出了出色的性能。在RF 中,每棵决策树都独立地为给定的数据样本提供一个预测值,然后将全部k棵决策树的预测值取平均作为最终的输出值。这种集成方法在处理高维数据和大规模数据时,可以有效地应对过拟合和欠拟合的问题。决策树构建算法采用Breiman 提出的CART 算法[23],其基本步骤为
(1)特征选择。CART 算法对于每一个节点都需要选择最佳的特征进行分裂,通常基于基尼系数来进行特征选择,以实现节点的最佳分裂。
(2)节点分裂。根据选定的特征,对节点进行分裂,使得各个子节点中的样本尽可能属于同一类别(分类树)或者具有相似的回归值(回归树)。
(3)递归构建。重复对子节点进行上述分裂操作,直到满足停止条件。如在分类树中,可以设定树的最大深度或者节点中样本数量的最小阈值;在回归树中,也可以设置类似的停止条件。
(4)剪枝。构建完整的决策树后,可以对树进行剪枝,通过降低树的复杂度来提高模型的泛化能力,防止过拟合。
根据本文提出的特征变量扩展方法,可以将叠前地震反演得到的纵波速度、横波速度和密度数据体生成222 个特征变量作为RF 回归器的输入数据。然而,扩展弹性阻抗变量之间本身也具有一定的相关性,大量信息重复的特征变量可能带来过多的冗余信息和计算消耗。有些特征变量可能是极为敏感的指标参数,而有的特征变量可能包含的有效信息很少,选择对目标回归贡献较大的特征变量可以加快过程并提高预测的准确性。
RF 的另一个优点是可以提供变量重要性(Variable important,VI)的衡量标准,根据特征变量的预测能力进行排序[35]。用随机森林进行特征重要性评估的思想就是衡量每个特征在随机森林中的每棵树上所做的贡献,取所有树的平均贡献来比较特征变量的贡献大小。在RF 中,有Gini 重要性和互换精度重要性2 种得分评价标准,对于含气饱和度预测这类回归问题宜采用互换精度重要性来计算VI 得分。根据Bootstrap 采样思想,每棵决策树都有子样本集37.8%的“袋外”样本在构建过程中并没有使用,可以被用来计算特征变量的重要性。
第i棵树,第j个特征变量Xj的VI 得分[35]为
取所有树的平均VI 得分作为变量的最终VI得分,根据VI 得分的排名,选择排名靠前的特征变量作为RF 回归器构建的最终使用特征变量。
2 实施流程
基于特征变量扩展的含气饱和度随机森林预测方法在实际生产中的实施流程如图2 所示,主要有4 个步骤:

图2 随机森林含气饱和度预测流程Fig.2 Workflow of gas saturationprediction by random forests
(1)训练样本平衡化处理。抽取井旁道纵波速度、横波速度和密度3 个弹性参数的叠前地震反演结果作为基本特征变量样本,根据测井有利储层分类解释结果,采用BSMOTE 方法对基本特征变量和对应的含气饱和度样本进行平衡化处理。
(2)特征变量样本扩展。对平衡化后的弹性参数样本应用表1 所列扩展方式进行自动扩展并编号,得到扩展的特征变量样本。
(3)随机森林回归器训练。分为预训练和正式训练,先开展RF 预训练,根据式(3)对各特征变量进行重要性排名,优选排名靠前的特征变量,输入优选的特征变量样本和目标物性参数标签,进行RF 正式训练,得到最优的回归器。
(4)含气饱和度预测。根据步骤(3)中优选的特征变量的编号,依据表1 中对应的扩展方式,将弹性参数叠前地震反演成果数据体整体转换为特征变量数据体,输入到训练好的随机森林回归器中,输出预测的含气饱和度数据体。
3 应用实例
以中国西部某天然气藏研究区为例验证新方法的有效性。该研究区气藏埋藏较深、分布广泛、有效储层厚度大。早期部署的探井获得高产工业气流,显示出该区域气藏巨大的资源潜力,但随着探井部署的增多,发现产能横向差异较大,钻井风险大,需要精细刻画有利气藏的分布。然而,该区域气藏经过多期矿物转化,岩石矿物的组成和孔隙结构相比浅层气藏更加复杂,弹性参数不仅与含气饱和度有关,还受岩相、孔隙度和孔隙结构的影响,岩石物理模型难以准确建立,导致常规基于岩石物理模型的含气饱和度反演方法的精度较低,难以有效指导勘探井位的部署。因此,有必要尝试基于数据驱动的方式获取高精度含气饱和度信息来减少勘探风险。
3.1 单井分析
图3 为研究区某重点井的含气饱和度测井解释曲线及从纵波速度、横波速度和密度叠前地震反演数据体中提取的对应井旁道伪井曲线。可以看到含气饱和度解释曲线与纵波速度、横波速度和密度伪井曲线间并没有直观的线性关系,利用简单的数学公式难以将弹性参数进一步转换为含气饱和度。

图3 中国西部某天然气藏含气饱和度测井解释曲线及井旁道弹性参数反演曲线Fig.3 Log interpretation curve of gas saturation and inversion curves of elastic parameters from the uphole trace in a natural gas reservoir in western China
图4 为不同角度的EEI曲线和利用图3 中纵波速度、横波速度和密度曲线计算得到的拉梅阻抗(拉梅参数×密度)λρ曲线。λρ通常被用作反映岩石刚度变化的岩性和流体识别指标[36]。可以观察到,不同角度的EEI曲线具有不同的变化形态,突出的特征也不同,当角度为20°时,EEI(20°)与λρ曲线非常相似,相关系数达到0.97,表明EEI随着角度的变化确实可以逼近一些常见的弹性参数。因此,本文提出的利用EEI随角度变化的这种特性开展特征变量的扩展具有一定现实依据。

图4 中国西部某天然气藏3 个不同角度的EEI 曲线与拉梅阻抗曲线Fig.4 Well curves of EEI withthree different angles andLame impedance curve in a natural gas reservoir in western China
根据表1 的生成方式,得到222 个扩展变量进行VI 排序。如图5 所示,并非每个变量对含气饱和度预测都很重要,许多变量的重要性非常低,这表明存在信息冗余。最高、最低VI 变量分别为EEI(20°)-2和EEI(50°)2,将这2 个变量对应的特征变量曲线与测井解释的含气饱和度曲线进行对比(图6)可知,最高VI 特征变量曲线大致上可以反映含气饱和度曲线的变化,而最低VI 特征变量曲线与含气饱和度曲线差异大,证明了VI 的可靠性。

图5 中国西部某天然气藏含气饱和度随机森林预测时222 个扩展特征变量的重要性得分情况Fig.5 Importance scores of 222 extended feature variables in random forests prediction of gas saturation in a natural gas reservoir in western China

图6 中国西部某天然气藏含气饱和度随机森林预测时最高(a)、最低(b)重要性特征变量曲线与含气饱和度(c)形态对比Fig.6 Curve shape comparison of the highest(a)and lowest(b)importancefeature variable curves predicted by random forestsand logging interpretation curves gas saturation(c)in a natural gas reservoir in western China
综上所述,与λρ相关性最高的特征变量曲线(参见图4)、重要性最高的特征变量曲线(图6)的整体形态均与密度曲线相似(整体方向上有所不同),这也说明了利用扩展特征属性能够代替常规需要人工一一提取或转换计算的弹性参数。本文中提取的扩展策略能够得到222 种扩展属性供优选作为含气性敏感的特征变量,但并不能只用一个扩展特征变量就预测含气饱和度,即使是重要性最高的特征变量曲线与含气饱和度曲线在细节上仍有一定的差异,还需要其他特征变量来参与修正。
按照变量重要性从高到低的排序,依次加入到RF 训练中,如图7 所示,仅以重要性最高的特征变量进行单个训练,预测的含气饱和度曲线与真实含气饱和度曲线的相关系数为0.47,随着特征变量数量的增加,相关系数先上升,当数量达到约20 个时(如图7 中红点所示),相关系数趋于平缓,约为0.90。因此,可以认为在本例中只需前20 个特征变量即可满足训练要求。
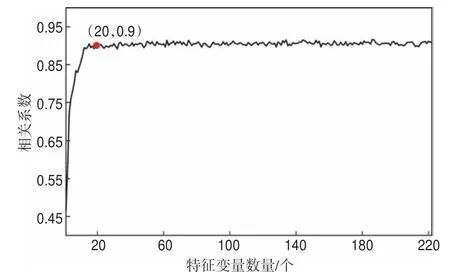
图7 中国西部某天然气藏基于特征变量扩展的含气饱和度随机森林预测结果和含气饱和度测井解释的相关系数-特征变量数量曲线Fig.7 Variations in the corresponding correlation coefficient between the gas saturation predicted by random forestsand the the real gas saturation curve in relation to the number of variables in a natural gas reservoir in western China
将未平衡化的全部222 个变量、VI 前20 个变量和11 个常用弹性参数分别作为随机森林回归器训练的特征变量,预测得到的含气饱和度曲线如图8 所示。全部222 个变量的预测曲线与VI 前20个特征变量的预测曲线几乎重合,且与真实含气饱和度曲线的吻合程度较高,明显优于利用11 个常用弹性参数参与训练的预测结果,但在高含气饱和度区间(如图8 中黑色箭头所示)有明显的偏差。分析认为处于高含气饱和度区间段的样本占比较小,导致RF 回归器的训练偏向低含气饱和度样本。因此,需要对参与训练的样本进行平衡化处理。

图8 中国西部某天然气藏3 种不同的特征变量的含气饱和度随机森林预测结果与含气饱和度测井解释曲线对比Fig.8 Comparison among the gas saturation curvespredicted by random forestswith three different feature variables and the real gas saturationcurve in a natural gas reservoir in western China
利用BSMOTE 方法对预测的含气饱和度曲线及其对应的特征变量进行平衡化处理后,原始样本中低含气饱和度的样本数量未发生改变,而高含气饱和度的样本数量明显增加,且取值更加丰富,高、低含气饱和度样本数量大致达到平衡(图9)。

图9 中国西部某天然气藏含气饱和度样本平衡化前(a)、后(b)直方统计Fig.9 Histogram ofgas saturation before(a)and after sample balancing(b)in a natural gas reservoir in western China
对经过BSMOTE 处理后的样本进行训练,采用VI 排名前20 的特征变量参与训练,高含气饱和度区间的预测结果有明显的改善(图10),相关系数由平衡前的0.903 2 上升到平衡后的0.985 5。这也说明了对于含气饱和度这类不平衡数据的预测,样本平衡问题是不可忽视的。
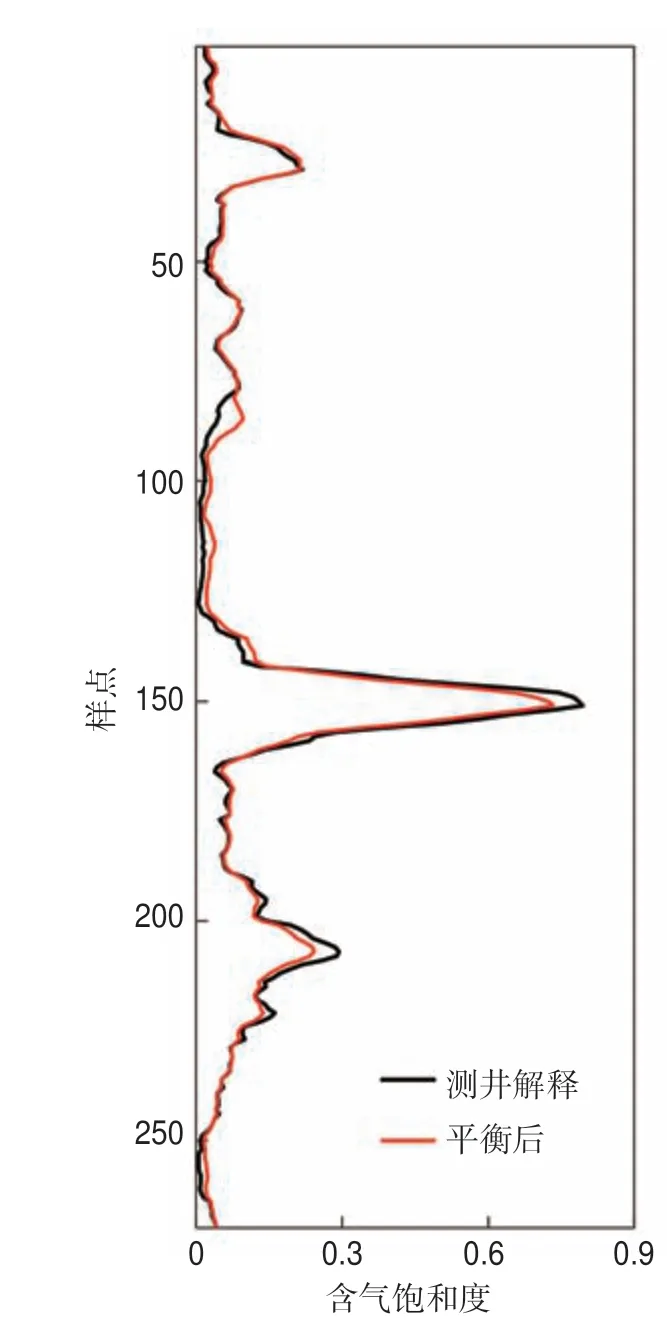
图10 中国西部某天然气藏样本平衡化后含气饱和度随机森林预测结果与含气饱和度测井解释曲线对比Fig.10 Comparison between the gassaturation curves predicted by random forestsafter sample balancing and the real gas saturation curve in a natural gas reservoir in western China
3.2 二维资料应用分析
研究区前期勘探经验和综合分析表明,含气饱和度与其他物性参数具有较好的线性关系,找到高含气饱和度区域通常就意味着能找到有利气藏。因而,生产上需要利用地震储层预测方法优选含气饱和度较高的目标区域为钻井的轨迹设计提供依据。
研究区含气饱和度测井解释结果(图11 中黑色曲线)显示目的层上部发育1 套含气饱和度较低的差气层(图11 中蓝色箭头所示),下部发育1 套含气饱和度较高的高产气层(图11 中红色箭头所示)。将区内A 井和C 井作为训练参与井,B 井作为验证井,分别采用本文方法和常规方法(基于常规未平衡化的11 个弹性参数作为RF 的输入)预测含气饱和度并绘制连井剖面(图11)。结果显示,采用常规方法解释该区发育上、下2 套含气饱和度较高且值相近的储层(图11a 中虚线框所示),很容易被解释为具备同一品质的储层,而本文方法解释的这2 套储层含气饱和度差异较大,下部的储层(图11b 中虚线框所示)含气饱和度明显更高,这一结果与测井解释结果一致。

图11 常规方法(a)与基于特征变量扩展的随机森林法(b)预测的含气饱和度剖面Fig.11 Gas saturation profiles predicted by conventional method(a)and random forestswith feature variable extension(b)
为了进一步验证本文方法的正确性,抽取验证井B 井的井旁道反演结果(图12)可知,本文方法预测结果整体上与含气饱和度测井解释曲线吻合较好,而常规方法在高含气饱和度部位出现了较大的偏差,很可能会被错误地解释为差气层。

图12 采用常规方法和基于特征变量扩展的随机森林法预测的验证井含气饱和度对比Fig.12 Comparison of gas saturation of validation well predicted by conventional methods and random forestswith with feature variable extension
4 结论
(1)对于含气饱和度这类连续型数值回归问题,基于数据驱动的机器学习方法为取得最佳性能,需要大量的特征变量作为训练集,利用扩展弹性阻抗自动生成222 个扩展弹性属性作为机器学习的训练集,能够大幅减少特征变量提取和优选的人工工作量。
(2)大量信息重复的特征变量会带来过多的冗余信息和计算消耗,利用随机森林预训练对特征变量进行重要性排名,优选对含气饱和度预测重要性较高的特征变量参与正式训练,能够有效减少信息的冗余。
(3)“不平衡数据”特征会恶化机器学习算法的性能,而复杂气藏的含气饱和度的取值分布往往也具有“不平衡”特征,引入边界合成少数类过采样技术能有效解决储层和非储层的含气饱和度样本取值分布不平衡导致的随机森林回归器训练偏倚的问题。
(4)基于特征变量扩展的含气饱和度随机森林预测方法在实际资料应用中能有效增强随机森林算法在含气饱和度地震预测方面的能力,且特征变量扩展策略对于孔隙度、有机质含量等其他气藏物性参数的机器学习预测同样有借鉴意义。
猜你喜欢
中等数学(2022年5期)2022-08-29
小资CHIC!ELEGANCE(2021年25期)2021-07-29
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年2期)2017-11-23
录井工程(2017年4期)2017-03-16
少儿科学周刊·儿童版(2015年7期)2015-11-24
中国煤层气(2015年5期)2015-08-22
理科考试研究·高中(2014年11期)2014-11-26
优雅(2014年4期)2014-04-18
