
基于改进K-means 算法的物流配送中心选址研究
2024-03-16 08:37:56吴秀荣谢贝贝王诗璇梁益铭
物流科技 2024年5期
姚 佼,吴秀荣,李 皓,谢贝贝,王诗璇,梁益铭
(1.上海理工大学 管理学院,上海 200093;2.中国铁路济南局集团有限公司,山东 济南 250000)
0 引言
近年来,伴随着全球经济的快速发展,电子商务领域空前繁荣,物流业更是被称为“第三利润源泉”,2010 年至2020 年间我国快递行业业务量总量逐年增长,预计2021 年至2025 年,快递业务量年均增长15.4%,为满足快递业务的发展需求,合理的物流配送中心位置显得尤为重要。
目前国内外对物流配送中心的选址研究主要有:在应急物流选址方面,Özdamar 等提出了自然灾难发生后的应急物流和应急物资配置问题,以物资送达时间最短和救治伤患延误最小建立一种多目标物流选址模型[1]。Mohri 运用ArcGIS 软件研究了应急物资的配送问题[2]。我国的欧忠文等最先提出应急物流的概念,提出设立应急处理设施和技术平台的观念[3];丁雪枫等构建了考虑总成本、公平性和效率性的多目标应急设施选址模型[4]。在生鲜物流选址方面,HE X D 通过阐述生鲜农产品物流的系统节点成员微观行为与系统宏观结构演化关系,揭示生鲜农产品物流生态系统演化的复杂性,以此进一步促进生鲜农产品物流生态系统网络的全面协调和优化,最终提高生鲜农产品物流的整体性能[5]。李晶晶根据生鲜农产品易腐败的特性,分析了新鲜度降低和打折销售对顾客的影响,引入新鲜度函数建立满足需求为前提、总成本最小为目的的冷链配送中心选址模型[6]。在逆向物流选址方面,Tadaros 针对锂离子电池上市时间短但丢弃数量严重的现象,以最低的收集成本、运输成本、处理成本以及建设设施成本之和最小为约束来恰当安排锂离子电池的选址位置和数量,最终成功解决了废旧锂电池的归属问题[7]。Guo 分析了政府补贴对消费者、电商企业、电商平台的作用机制,这在促进快递包裹回收以及明确不同主体战略选择层面的意义非凡[8]。
在物流配送中心选址的方法方面,主要包括定性研究法和定量研究法。其中定性研究法通常采用专家判断或者多指标评价法来选择最优方案,如张春玲运用模糊综合评价法和层次分析法解决了多个备选点最优的问题[9]。定量研究法主要通过数据统计和分析,并使用数学模型对各种选址方案进行模拟分析,常见的方法有多目标规划方法、聚类算法和遗传算法。其中聚类算法具有能够识别数据中的潜在模式和结构,以发现不同地点的相似性和差异性这一特点广泛应用于选址问题中,Francisco 运用多项式Logit 模型研究了中国大陆跨国企业在德国投资时不同聚集网络类型的优缺点及选址问题[10]。朱晨阳分析了海南省生鲜农产品物流配送中心和配送中心网络结构现状,结合实际引入配送时间满意度函数,建立了考虑多种因素的多目标模型[11]。徐昊源等基于K-means 聚类方法,以新鲜度损耗成本最小为目标对生鲜自提柜进行选址,并结合建设与运营成本给出最佳的自提柜设置数量[12]。薛德琴等采用模糊综合评价法和层次分析法针对已经划分完毕的协同配送区域具体选址确定两种方案[13]。然而在运用K-means 算法进行聚类选址时,通常需要预先指定聚类数量K,而这个值的选择通常是基于经验或试错来进行的,这会导致算法结果的不确定性和不稳定性,且由于实际的数据大多数是数值型和类别型变量混合,该算法无法对类别型变量进行聚类。
基于上述研究问题,本文主要从K 值确定及数据类型的聚类对K-means 算法进行优化。本文将综合运用肘部法及轮廓系数确定K-means 算法中的合理K 值;针对无法处理类别型变量的问题,采用变量编码的方法,将类别型变量转化为数值型变量,然后再进行聚类。最后基于实际数据,对研究区域的最优物流配送中心位置进行进一步的分析探讨。
1 物流配送中心选址影响因素分析与指标体系构建
1.1 影响因素初步获取
配送中心选址过程中需考虑多种影响因素,本文对2022 年以来的文献进行梳理总结,将影响因素分为经济因素、经营环境因素、基础设施因素、自然因素、运输物品特点因素和其他因素六大类。对影响因素统计分类后结果如图1 所示,根据ABC 分类法,对物流配送中心选址的各项影响因素进行分类,具体可分为关键因素、一般因素和次要因素三类。通过ABC 分类法,对选址文献进行综合考虑,本文选取以下划分标准对物流配送中心选址影响因素进行分类:累计频率为0%~80%为关键影响因素,80%~90%为一般影响因素,90%~100%为次要因素。

图1 文献指标统计图
由图1 可知,运输成本、运营成本、固定成本、需求量、服务满意度水平、运输方式、道路可达性和交通设施这8 项因素为关键影响因素,经营环境和地形条件为一般影响因素,其余为次要影响因素。本文将以关键影响因素为基础探究选址问题。
1.2 影响指标体系构建
结合数据的可获得性及影响因素特点,本文将建立物流配送中心选址影响因素指标体系如表1 所示:
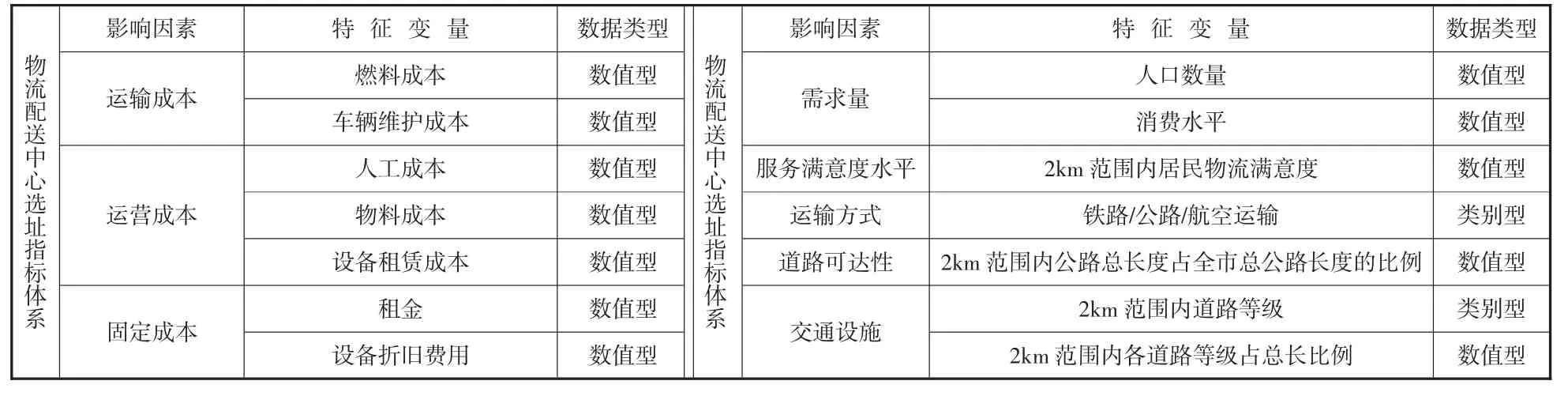
表1 物流配送中心选址指标体系表
2 基于改进K-means 算法的物流配送中心选址模型
2.1 K 值确定
K-means 算法中,K 值决定在该聚类算法中所要分配聚类的簇的多少,簇的多少影响着算法的聚类效果。而通常情况下,想确定最佳K 值比较困难,目前常用的确定K 值的方法有肘部法及轮廓系数法。肘部法聚类时使用的评价指标为数据集中所有样本点到其中心簇的距离之和的平方(SSE),肘部法选择的并不是误差平方和最小的K 值,而是误差平方和突然变小时对应的K 值,因此对于降低速率较为均匀的数据无法确定合适K 值。在此种情况下,轮廓系数法能够很好地解决该问题。轮廓系数值是常用的聚类效果评价指标,该指标结合内聚度和分离度两个因素,具体计算过程如下:
(1)假设已经通过聚类算法将数据进行了聚类,并最终得到k 个簇,对于簇中的每个样本点i,分别计算其轮廓系数,其中需要对每个样本点i 计算下面两个指标:
①a(i)为样本点i 到与其同属同一个簇的其他样本点的距离平均值,该值越小,说明该样本属于该类的可能性越大。
②b(i)为样本点i 到其他簇中所有样本的平均距离的最小值。
(2)该样本点的轮廓系数为:
对于所有样本点的轮廓系数的平均值为该聚类结果的总轮廓系数。S(i)∈[-1,1],越接近1 聚类效果越好。
2.2 不同类别变量的处理
本文数值型数据均采取归一化处理,在影响选址的指标体系中除数值型数据外,还有类似运输方式等类别型数据,对于该种类型数据的处理本文采取独热编码(One-Hot Encoding)将每个类别值表示为一个二进制向量,转换为可以处理的连续型数据。该种方法保留了类别信息,不引入任意的数值关系,同时可以避免数值的大小对模型产生不正确的影响。适用于大多数机器学习算法,尤其是那些基于距离度量的算法,如本文的K-means 算法。
独热编码的过程如下:首先,确定类别型特征中的所有不同类别值。然后,对于每个类别值,创建一个维度与类别数量相等的二进制向量。最后,将每个二进制向量的对应维度上的值设置为1,其他维度上的值设置为0。如表1 中运输类型指标,有铁路/公路/航空三种运输方式,通过独热编码的方式可转化为:铁路:[1,0,0];公路:[0,1,0];航空:[0,0,1]。原来的类别型特征被转换为了三个维度的连续型数据,继而能够在后续聚类算法中应用。
2.3 物流配送中心选址模型构建
Mac Queen 首次提出了K 均值聚类算法,它是一种非监督学习的硬聚类算法,通过迭代的方式寻找最优的聚类结果。假设已获取的物流配送中心营业点样本点有I=(1,2,…,i)个,需要考虑的影响因素具有N=(1,2,…,n)个,对于第i 个样本点其特征向量可以表示为;聚类中心有K=(1,2,…,k)个,对于第k 个聚类中心其特征向量可以表示样本在聚类过程中,一个关键问题是如何定义样本之间的相似性度量函数。常见的方法是使用欧氏距离作为度量样本间距离的方式,欧氏距离是一种常见的距离度量方法,用于计算样本之间的差异程度。每个簇下样本点到聚类中心的聚类使用欧式距离表示,欧氏距离的计算公式如下:
依据上述公式,逐个计算每个特征的差值的平方,并对它们进行求和并进行平方根运算,然后计算每对样本之间的欧氏距离,得到每个元素表示相应样本之间的欧氏距离。根据欧氏距离结果将数据点分配到最近的聚类中心,然后计算聚类后的各簇内样本点到聚类中心的欧氏距离和,设定总误差平方和SSE 为:
对于所有样本点的总误差的平方和为该聚类结果的总误差平方,SSE越小聚类效果越好。除考虑样本点到该簇聚类中心点距离外,在聚类过程中还需考虑样本点至其他簇中样本点的距离,即轮廓系数,具体计算公式如式(1)所示。计算后选取最佳K 值,确定最优聚类方案,运用Matlab 编程后输出聚类结果。
3 案例分析与验证
3.1 案例区域选择
上海市作为中国经济发展迅速的城市之一,拥有众多的物流配送中心,选取物流服务业中的顺丰速运为代表研究其在上海市的物流配送中心选址问题。基于百度开放平台与Python 平台获取上海市大虹桥商区顺丰速运末端营业点目前布局,如图2 所示。这些物流配送中心分布在城市的不同区域,有的地理位置优越,有的则位于偏远的郊区。为了更好地管理和优化这些物流配送中心,需要对它们进行聚类分析,并选取合适的聚类中心作为物流配送中心。
图2 百度地图上海市大虹桥商区“顺丰速运营业点”可视化散点图
3.2 数据获取
根据本文研究所需从不同渠道获得不同类型的数据,本文所需数据如道路等级等来源于百度开放平台;人口、劳动力成本等数据来自上海市统计局颁布的上海统计年鉴及顺丰官网2021 年度报告,基于各末端营业点中的人口数量占总人口的比例计算各营业点人口成本。
3.3 聚类结果与分析
本文使用肘部法和轮廓系数法度量聚类结果如图3 所示,运用肘部法对该样本数据进行聚类时,随着K 值的增大,SSE 值会逐渐降低,但K 值下降速率平缓,无明显突然下降趋势,该种方法下无法确定最佳K 值;而轮廓系数法K 值为3 时轮廓系数最大,较为合适。
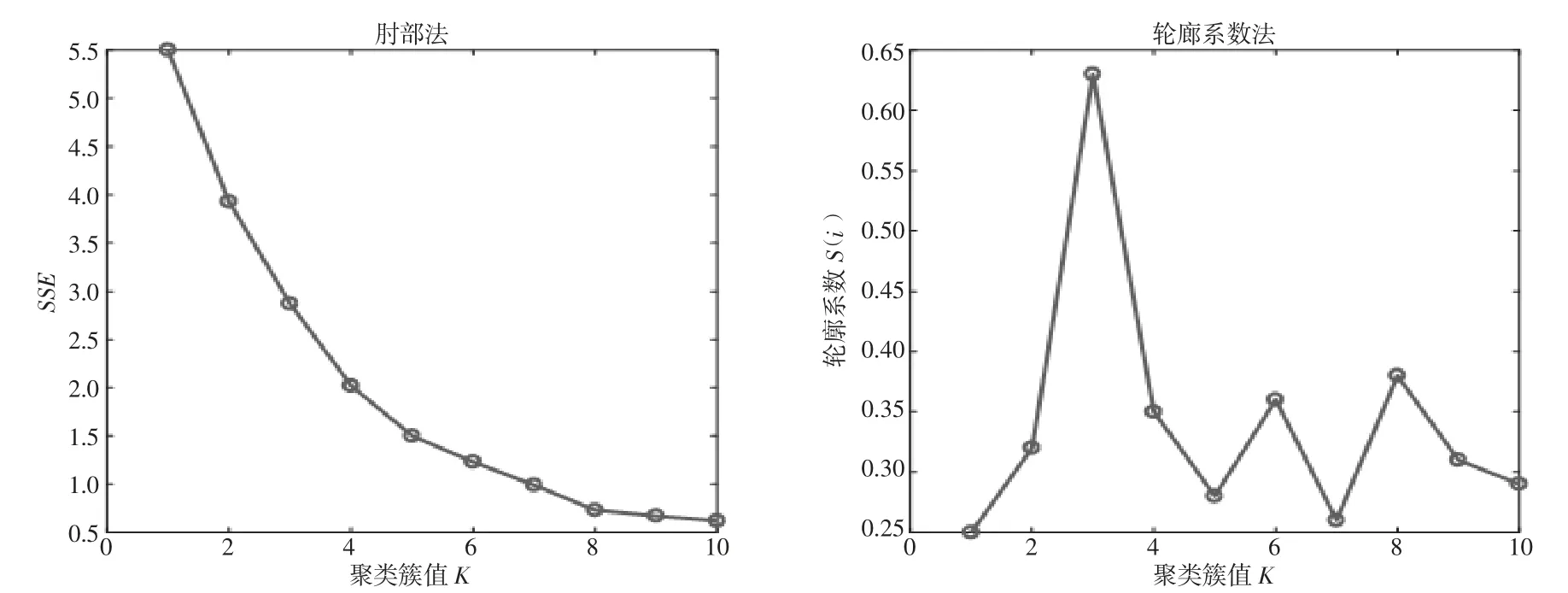
图3 聚类结果K 值图
选取K 为3,对大虹桥商区顺丰现有物流配送中心营业点进行聚类,聚类结果如图4 所示。
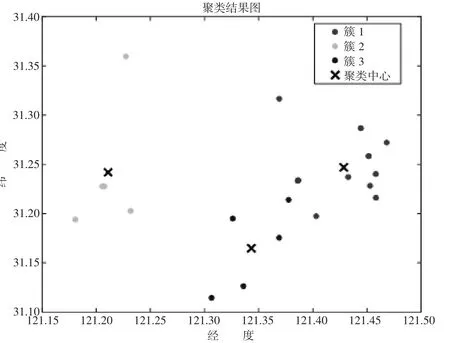
图4 聚类结果图
上述聚类结果以运输成本、固定成本以及类别型影响因素为依据,为更好地衡量该方案聚类效果,对比传统K-means 聚类算法的物流总成本,物流总成本包含运输成本、运营成本和固定成本。传统K-means 聚类方法无法对类别型影响因素做出计算,因此在数据输入时,传统K-means 算法仅能输入数值型影响因素特征值,改进K-means 算法能够同时输入数值型影响因素与类别型影响因素特征值,结果如表2 所示。

表2 成本对比表 万元
从中可以看出,传统K-means 算法聚类结果K 值为4 时,对比改进后考虑类别型因素K 值为3 时物流总成本为34.153 2 万元,降低8.76%,运营成本降低14.85%,固定成本降低8.09%。由此可知,该方案能够有效降低物流总成本。
4 结束语
本文在梳理出物流配送中心选址影响因素体系的基础上,综合运用肘部法及轮廓系数确定K-means 算法中的合理K 值;针对无法处理类别型变量的问题,采用变量编码的方法,将类别型变量转化为数值型变量,然后再进行聚类,确定物流中心的选址。最后基于实际的案例数据,对最优物流配送中心位置进行聚类分析,确定最佳选址。结论如下:
(1)相比较于传统K-means 算法,本文提出的算法能够采用热编码的方法有效处理类别型数据,获得更准确的聚类效果。
(2)采用本文算法进行聚类分析的结果显示,相比较于传统K-means 算法,本文计算的聚类结果能够有效降低物流总成本,整体方法可行。
(3)本文在考虑聚类选址时主要考虑了经济和交通影响因素,对于综合考虑更多其他要素时,可在本文模型的基础上进行丰富,其拓展性还可以进行更深入的研究。
猜你喜欢
今日农业(2021年19期)2022-01-12 06:16:28
装备制造技术(2020年9期)2021-01-26 00:15:18
太原科技大学学报(2019年3期)2019-08-05 01:18:22
知识经济·中国直销(2018年5期)2018-05-26 09:25:58
电子测试(2017年15期)2017-12-18 07:19:27
新校长(2016年8期)2016-01-10 06:43:59
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
