
利用自适应光照初始化的弱光图像增强方法
2024-03-15 09:22田广粮马建峰毕秀丽
电子与信息学报 2024年2期
刘 波 田广粮 肖 斌 马建峰 毕秀丽*
①(重庆邮电大学图像认知重庆市重点实验室 重庆 400065)
②(西安电子科技大学网络与信息安全学院 西安 710071)
1 引言
随着计算机视觉技术的广泛应用与发展,越来越多的数字图像出现在人们的日常生活、工作和学习等方方面面。但由于受到外界环境或硬件的限制,如拍摄环境照明不足、相机曝光时间较短等因素,都会导致拍摄得到的图像视觉质量较差,存在低亮度、低对比度以及内容信息丢失等问题。而这类弱光图像不仅严重影响人们的主观视觉感受,同时也限制了其他计算机视觉任务的性能提升,如图像分类、目标检测、图像分割[1]等。
为了解决弱光图像存在的问题,在过去的几十年,许多优秀的增强方法被提出。而作为图像增强的有效工具,Retinex模型最早由Land[2]和McCann等人[3]提出,在图像恢复[4]、弱光图像增强[5]等任务中都有着广泛的应用。如图1所示,该理论将观察到的图像分解为光照分量和反射分量两部分,其中光照分量表示场景中光照的分布情况,包含图像的结构信息;反射分量则代表物体的基本固有属性,主要由图像的纹理细节和颜色信息表示。

图1 Retinex模型示例
观察图1可以看到,单独的反射分量是非常不真实的,需要加入准确的明暗对比光照信息来使得图像更加自然。由于图像分解估计是一个高度不确定的问题,对于弱光图像来说,需要通过各种假设条件和先验知识来约束光照分量的优化估计。在早期的研究尝试中,光照分量被假设为是平滑的,他们利用高斯滤波来估计光照分量,并将反射分量作为增强结果[6,7]。Kimmel等人[8]则将图像的光照平滑问题建模为一个变分问题来加以解决。Fu等人[9]提出了一种在线性域中同时对光照分量和反射分量进行约束估计的概率算法,避免了对数变换带来的副作用。Xu等人[10]通过利用指数局部导数来提取图像的结构和纹理信息,并基于此对光照分量和反射分量进行正则化。Cai等人[11]考虑到物体的3D特性,设计了一种联合内外先验的改进Retinex分解模型。Guo等人[12]仅考虑对图像的光照分量进行结构感知平滑,提出基于加权L1范数正则化的优化方法,在增强图像的同时进一步缩小解空间,但由于其忽略了局部区域的光照边缘信息,从而容易错误地估计图像的光照分量,导致结果存在过度增强以及边缘伪影的问题。Li等人[13]将图像的噪声考虑进来,首次提出加入噪声估计映射的鲁棒Retinex模型。Cao等人[14]提出了一种改进的自适应伽马矫正,通过新的图像反转策略以及截断灰度累积分布函数,解决了伽马矫正对全局明亮图像和局部不均匀曝光图像处理不佳的问题。Wang等人[15]不同于以往神经网络方法学习图像到图像的映射,而是学习图像到照明的映射,并将输入与预期的增强结果相关联,让网络学习到更多样的图像调节信息。以往的方法大都专注于讨论如何更准确地约束光照分量的优化估计,却很少考虑光照分量的初始化问题,然而初始光照分量不仅直接决定后续优化估计操作的准确性,同时也关系到最终增强结果的好坏。由此,本文提出一种准确估计图像初始光照分量的方法,进一步实现更好的弱光图像增强。
本文剩余部分由如下构成,第2节首先介绍了本文所提弱光图像增强方法的整体流程,分析如何实现自适应光照分量初始化,并讨论光照分量的平滑优化;第3节实验部分分别从方法参数设置、方法的消融实验、方法图像分解估计的能力、方法对弱光图像的增强效果以及算法运行时间5个方面来验证本文方法的有效性;最后,第4节对全文进行总结。
2 基于自适应光照初始化的弱光图像增强方法
本文提出的弱光图像增强方法的大致流程如图2所示,具体步骤如下:
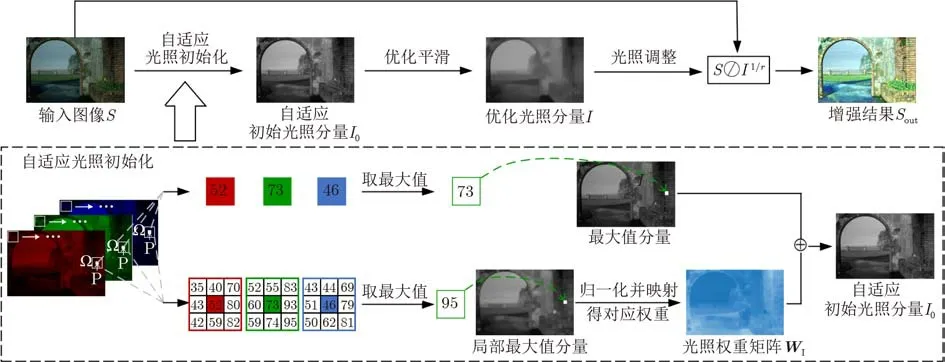
图2 基于自适应光照初始化的弱光图像增强方法流程
(1)通过提出的光照初始化模块,自适应地估计出输入图像的初始光照分量;
(2)在结构光照先验的约束下,对初始光照分量进行优化估计;
(3)对得到的优化光照分量执行伽马校正,以进一步对图像的亮度实现非线性调整;
(4)结合Retinex模型实现弱光图像的增强。
2.1 Retinex理论模型
Retinex理论基于自然场景中人类的视觉感知以及颜色恒常性进行建模,其基本思想是将观察到的图像分解为光照分量和反射分量两个部分的乘积。具体公式为
其中,S(x) 代表输入的原始弱光图像,I(x)表示光照分量,R(x) 为反射分量,x表示具体像素,运算符⊗则表示按元素的乘法操作。本文假设彩色图像3个颜色通道中的光照分量是相同的。
2.2 自适应光照初始化
本文首先对以往常用的几种光照初始化方法进行简单的说明。如式(2),Max-RGB[2]为最早提出的颜色恒定方法,通过计算输入彩色图像3个颜色通道(R,G和B)的最大值来得到初始光照分量I0(x);也有研究人员尝试用3个颜色通道的平均值来初始化光照分量,如式(3);之后,人们又提出将彩色图像从RGB色彩模式(RGB color mode, RGB)颜色空间转至HSV颜色模型(HSV color model,HSV)颜色空间,并取亮度通道V作为初始光照分量,具体为式(4)所示
其中,I0(x) 表示初始光照分量,c包含不同的颜色通道,SV则表示图像在HSV颜色空间中的V分量。以往基于Retinex模型的弱光图像增强方法都采用上述方式来初始化光照分量,但这些方法均没有考虑光照的局部一致特性,导致图像局部区域的结构信息不能得到很好的保护,式(3)取3颜色通道平均值的方法忽略了光照分量的范围先验,即光照分量的亮度应不小于原始图像。由式(1)可知,光照分量的估计和反射分量有着直接联系,从而影响到最终的增强结果。所以准确分解估计出图像的光照分量对基于Retinex模型的弱光图像增强来说至关重要,而作为第1步的光照分量初始化,则显得尤为关键。
在Retinex理论中,根据光照分量的空间平滑[12]先验,图像在局部区域所接收的光照强度相一致,即局部光照一致性,并能够在结构边缘处感知光照的明暗过渡情况。简单来说,理想的光照分量估计要在尽可能保留图像结构边缘的同时,平滑图像的局部纹理细节。基于此,本文引入局部块来弥补以往初始化方法对图像内容感知的缺失,并通过比较局部块在3个颜色通道中相邻像素间的关联性得到图像对应的光照权重矩阵,旨在突出图像的边缘结构信息,此外也考虑到光照分量的范围先验,将反射分量的值限制到[0,1],避免反射分量出现颜色失真的问题。具体公式为
其中,WI=maxy∈Ω(x)(maxc∈{R,G,B}(Sc(y)))/£为光照权重矩阵,Ω表示以x为中心的局部块,在本文中块大小取 3×3,£为光照调整参数。
为了验证光照权重矩阵WI的有效性,本文分别提取了引入光照权重矩阵前后图像初始光照分量的边缘图。如图3所示,可以看到,相较于引入光照权重矩阵之前,图3(b)中初始光照分量有着更明显的边缘结构(房屋、高塔等);此外,从图中的红色框区域可以观察到,光照权重矩阵除了指导图像结构信息的感知之外,还很好地抑制了塔墙面上的纹理细节。

图3 光照权重矩阵 WI的影响
为了验证光照权重矩阵WI的有效性,本文分别提取了引入光照权重矩阵前后图像初始光照分量的边缘图。如图3所示,可以看到,相较于引入光照权重矩阵之前,图3(b)中初始光照分量有着更明显的边缘结构(房屋、高塔等);此外,从红色框区域可以观察到,光照权重矩阵除了指导图像结构信息的感知之外,还很好地抑制了塔墙面上的纹理细节。
为了进一步的证明本文所提方法在实现光照分量的准确初始化以及后续图像分解估计中所起到的作用,对比了本文方法与前面提到的几种常用光照初始化方法在图像分解上的表现。这里仍然使用加权最小二乘滤波对不同方法得到的初始光照分量执行优化平滑,以保证实验的一致性。如图4所示,其中第1行为优化光照分量,第2行为对应的反射分量。可以看到,与其他几种光照初始化方法相比,本文自适应光照初始化的方法能够更好地感知估计图像的结构纹理信息,图4(d)底部红色框放大图中,窗户区域以及上方墙面格子的结构信息都得到了更好的保留,而这在反射分量中表现得则更加明显,即在图4(d)蓝色框区域中,窗户和墙面包含有更清晰的细节纹理。

图4 不同光照初始化估计方法结构纹理的感知
此外,与其他几种初始化方法相比,本文方法也很好地避免了反射分量颜色失真的困扰,而这正是得益于本文自适应光照初始化方法对图像光照分量结构信息的准确感知估计。
2.3 光照优化
根据上文的分析可以知道,理想的光照分量优化算法是在保持边缘结构的同时,尽可能平滑空间纹理,而这类图像的细节信息则应体现在反射分量中。又根据Retinex理论模型可知,光照分量的准确估计将直接影响到反射分量,因此在本文仅考虑光照分量的优化问题以进一步简化算法。由此有如式(6)的目标函数
其中,I0表示初始光照分量,I表示优化光照分量,W是结构权重矩阵,∇I为1阶导数滤波器,其具体又分为∇hI(水平方向)和∇vI(垂直方向)两部分, ||·||1和 ||·||F则分别为1范数和标准范数。式(6)目标函数中,第1项//I0-I//2F为数据保真项,用来约束I0和I之间的差异,正则项//W ◦∇I//1的作用则是来限制解空间的大小,系数α用来平衡保真项和正则项,实现光照分量的结构感知平滑。
权重矩阵W旨在感知图像的结构边缘信息,具体又包括如式(7)和式(8)的水平方向Wh(x)和垂直方向Wv(x)两部分
其中,Gσ(x,y) 表示标准差为σ的高斯核函数,有Gσ(x,y)←exp(-dist(x,y)/2σ2) , dist(x,y)表示像素x和y的空间欧氏距离, ε为一个很小的常数,以避免分母为0的情况, |·|则代表取绝对值操作。
由式(7)、式(8)可以看到,结构权重矩阵W是基于前文得到的初始光照分量I0所构建的,而非优化光照分量I,即表明在本文中结构权重矩阵W只需要计算1次,从而可以有效缩短算法的执行时间,另一方面,也再次强调了初始光照分量的重要性。
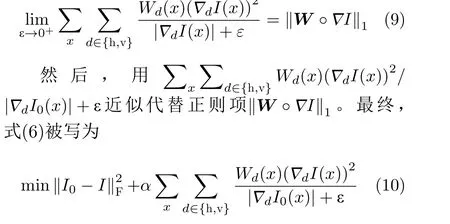
为了进一步提升算法的计算效率,本文对目标函数式(6)行近似简化操作。首先我们把目标函数中的正则项展开有具体来说,当//∇dI0(x)//值 很小的时候,//∇dI(x)//的值同样较小,而 (∇dI(x))2/|∇dI0(x)|+ε的取值也会被抑制。即最终优化估计得到得光照分量I避免在初始光照分量梯度较小的位置产生梯度变化,反之亦反。从而说明了式(10)中正则项对光照分量结构边缘的约束与原始目标函数是保持一致的。最终本文直接计算只涉及2次项的等价目标函数式(10),其中只有待求的优化光照分量是未知的,因此不需要进行迭代。
2.4 光照调整
对弱光图像增强任务来说,图像亮度的提升是要解决的核心问题之一,所以在输出增强结果之前,本文还要对得到的优化光照分量执行伽马校正,实现图像亮度的非线性调整,进一步改善增强结果。具体公式为
其中,γ取值为0.8。由输入图像S(x)以及光照调整之后的优化光照分量Ig,结合Retinex模型得到最终的增强结果Sout
这里, ε为一个很小的常数,避免分母为0。
3 实验结果与分析
实验部分将从以下几个方面来对本文提出的自适应光照初始化增强方法进行讨论和验证。首先讨论了光照权重矩阵中常数 C的取值问题,然后通过消融实验来证明光照权重矩阵WI的有效性,接着分析了本文方法在基于Retinex模型的图像分解中对结构纹理的感知能力,并在多个数据集上与现有最好的弱光图像增强方法从主观视觉效果和客观评价指标两个方面进行比较,最后也对本文方法的运行效率进行了分析。本文的所有实验是在Intel(R)Core(TM) i5-7 500 CPU @ 3.40GHz的PC平台下进行的(Matlab R2016a, Windows10操作系统)。
3.1 弱光图像数据集
为了确保实验结果的客观公正,在本文中所使用的图像均为弱光图像增强领域常用的公开数据集,具体包括有LIME[12], NASA[17], VV[18],DICM[19]4个自然低光数据集,以及Wei等人[20]提供的合成低光数据集LOL,共计628张彩色夜间图像和曝光不足的弱光图像。值得一提的是,这些数据集中包含有室内外环境中的自然风光、人物日常以及建筑等丰富的内容场景,从而能够充分地验证本文方法的有效性和普遍适用性。
3.2 实验评价指标
考虑到大部分的弱光图像数据集都是没有参考图像的,所以本文在实验部分选取了弱光图像增强领域中常用的两个无参考图像质量评估指标来对增强的结果进行客观评价,分别包括离散熵[21](Discrete Entropy, DE) 和自然图像质量评估器[22](Natural Image Quality Evaluator, NIQE)。其中DE关注的是图像内容信息的丰富程度,越高的值代表着最终得到的增强结果其细节越丰富、可见性越好。而NIQE则是用来衡量图像的自然程度,其数值越低,则表示增强的结果越自然,图像质量越高。
3.3 本文方法的参数设置
在与其他弱光图像增强方法对比分析之前,首先来讨论一下本文方法提出的光照权重矩阵WI=maxy∈Ω(x)(maxc∈{R,G,B}(Sc(y)))/£中,£的取值问题以及局部块Ω尺寸对增强结果的影响。
如图5所示,本文分别尝试了£∈{1,3,5,7}的情况,其中第1行为最终的增强结果,第2行则为对应的优化光照分量。可以看到,随着£取值的增大,优化估计得到的光照分量逐渐地平滑掉了图像中的更多细节信息,而最终增强结果的亮度则相对应地变大。为了达到理想的增强效果,根据观察,本文取£=5的情况,此参数设置在后续实验中均保持一致。

图5 常数值 £的取值
而对于局部块Ω的尺寸大小,本文分别尝试了3×3 , 5×5 , 7×7 以及 9×9这4种情况,随着局部块尺寸的增大,其需要考虑的局部结构信息也越多,从而导致容易出现错误估计图像结构的情况,正如图6所示,除去图6(a)之外,其他几种情况均出现不同程度的结构伪影,而这正是对图像结构错误估计的结果。本文将局部块Ω的大小设为 3×3。

图6 局部块尺寸大小的选择
3.4 本文方法的消融实验
本节通过设计消融实验来进一步证明本文提出的自适应光照初始化方法的有效性。为保证实验部分的一致性,这里分别在上述提供的4个弱光图像数据集上使用离散熵DE[21]、自然图像质量评估器NIQE[22]这两个评价指标来进行实验评估,并取各数据集的平均值来作比较。如图7、图8所示,其中基准方法是在光照初始化时仅采用逐像素取最大值的估计策略。可以看到,与基准方法相比,本文提出的自适应光照初始化方法的两个客观评价指标在4个不同数据集上都有明显的提升,从而在客观指标上也证明了本文方法的有效性。

图7 不同数据集中DE的平均值

图8 不同数据集中NIQE的平均值
3.5 本文方法与其他方法的图像分解对比
Retinex模型的核心思想即是将图像分解为光照分量和反射分量两个部分,但是对于光照分布不均的弱光图像来说,高度的不确定性使得很难实现准确的图像分解估计。此外,在2.2节提到,理想的光照分量应该在保持图像边缘结构的同时尽可能地平滑空间纹理,另一方面,更多的纹理细节则应包含在图像的反射分量中。为了验证本文提出的方法在图像分解问题上的有效性,本文对比了现有最好的基于Retinex模型的弱光图像增强方法,包括MSR[7], SRIE[9], RRM[13], STAR[10]以及LR3M[16]。如图9、图10所示,其中第1行是图像优化光照分量的热力图,第2行则为对应的反射分量。通过观察可以得出,在MSR[7]和SRIE的方法中,优化光照分量被过度地平滑,使得图像的结构信息没有得到很好的保留,进而也导致对应的反射分量在边缘区域存在光晕伪影问题。此外,方法RRM,STAR以及LR3M分解得到的反射分量还存在不同程度的颜色失真问题。相比之下,本文方法能够准确地估计出图像光照分量的结构边缘,并且在反射分量中保留更多的纹理细节,同时还有效地避免了颜色失真的问题。

图9 不同基于Retinex方法的图像分解对比
3.6 本文方法与其他弱光图像增强方法的对比
本节与现有最好的弱光图像增强方法进行比较,旨在验证本文提出的方法在弱光图像上的增强效果,其中对比方法包括CLAHE[23], GC[24], Dehaze[25], SRIE[9], STAR[10], JIEP[11]以及Zero-DCE[26]。下面分别通过主观视觉效果和客观评价指标两个方面来进行分析讨论。
3.6.1 主观评价的对比
如图11所示,本文对比了在5个弱光图像数据集中不同方法的增强效果。由于只关注像素大小的调整,而缺乏对图像结构信息的考虑,CLAHE[23]和GC[24]方法的增强结果都存在严重的颜色失真和过度曝光问题。Dehaze的方法没有很好地恢复图像的暗区域信息,而且同样也存在颜色失真问题的困扰。SRIE, STAR以及JIEP方法的增强结果在亮度提升上有限,而且由于没能准确地保留估计出光照分量的边缘结构,导致其在图像边缘区域容易产生伪影光晕。此外,基于神经网络的方法Zero-DCE,其增强结果很大程度上依赖于训练数据集,而弱光图像数据集大多是人工合成的,而非真实的图像对,从而导致增强结果的不自然。相比之下,本文方法不仅能够适当地增强亮度不均的弱光图像,有效地提升图像的对比度,同时得益于本文对图像准确的分解估计,本文方法的增强结果也避免了颜色失真以及边缘伪影的问题。

图11 不同弱光图像增强方法的主观效果
3.6.2 客观评价的对比
考虑到弱光图像的增强效果受个人主观视觉偏差的影响较大,为了更加客观有效地对比不同方法的增强结果,本节通过离散熵DE[21]和自然图像质量评估器NIQE[22]这两个常用的无参考图像评价指标来做进一步的评估。具体的评估结果如表1、表2所示,↑(↓)表示值越大(小),增强效果越好。最好的情况用加粗字体突出表示,次好的则用下划线来加以区分。可以看到,与其他方法相比,在离散熵DE评价指标中,本文方法在4个数据集上均有着最好的表现,表明了本文方法得到的增强结果包含有更多的图像信息,也即能够显现出弱光图像中更多的纹理细节。在NIQE评价指标中,本文在NASA和VV这两个数据集上取得了最好的结果,而在LIME[12]和DICM数据集中则表现为次好的,略低于神经网络的方法Zero-DCE[26]。

表1 不同方法在各数据集上DE↑的平均值

表2 不同方法在各数据集上NIQE↓的平均值
为此,本文对比了本文方法与Zero-DCE方法在数据集LIME和DICM上的弱光图像增强结果。正如图12所示,虽然Zero-DCE方法在两个客观评价指标上有着最好的结果,但是在主观效果的比较中发现,Zero-DCE方法的增强结果在图像的边缘结构区域存在明显的光晕伪影问题,如图12(a)中的灯罩边缘、铁塔轮廓以及远处的山峰,而且受神经网络训练数据集的影响,该方法增强的结果同时还存在色彩偏差的问题,如图12(a)中的天空区域。相比之下,本文方法则很好地避免了上述存在的问题,展现出更好的视觉效果。

图12 Zero-DCE方法的局限
3.7 本文方法与其他方法计算时间的对比
本节进一步分析了上述弱光图像增强方法的运行效率。为了保证实验结果的客观公正性,所有的对比方法均在作者推荐的环境下运行。对于神经网络的方法Zero-DCE,本文也根据官网建议将部署其在GPU环境下运行。表3分别记录了各方法在上述提供的数据集中执行弱光图像增强任务所用时间的均值。可以看到,本文提出的方法要比SRIE,STAR以及JIEP方法更快,而CLAHE, GC, Dehaze以及Zero-DCE方法虽然有着不错的计算效率,但这些方法的增强结果并不理想。相较之下,本文方法在更好完成低光图像增强任务的同时,也保证了较好的运行效率。
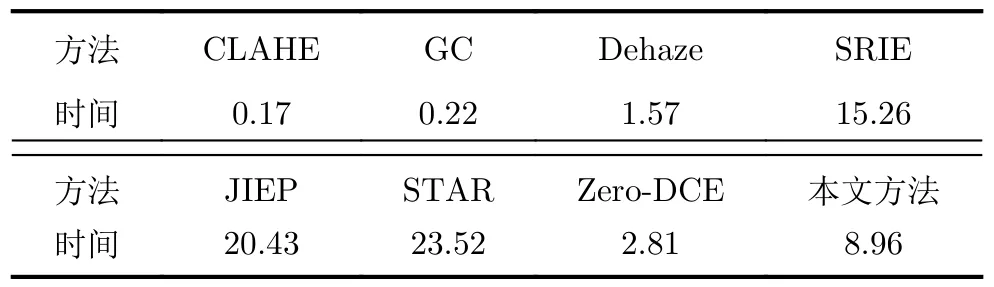
表3 不同方法增强图像的运行时间平均值(s)
4 结论
本文针对现有弱光图像增强方法在光照分量估计上存在的问题,提出一种自适应光照初始化的增强方法,来准确初始化图像的光照分量,实现更好的弱光图像增强。首先,根据输入图像得到其对应的光照权重矩阵,旨在指导光照分量的自适应初始化,随后在结构光照的约束下,通过提出的等价目标函数对初始光照分量执行优化平滑,并进一步对其执行非线性光照调整,最终结合Retinex理论实现弱光图像的增强。实验证明,本文的方法不仅能够准确地初始化光照分量,实现更好的图像分解估计,而且从主观视觉效果和客观评价指标与现有的弱光图像增强方法进行比较可得,本文方法在多个公共数据集上也都有更好、更稳定的表现。
猜你喜欢
中国机械工程(2022年8期)2022-05-09
燃气涡轮试验与研究(2021年6期)2021-08-01
中国机械工程(2021年8期)2021-05-07
海洋信息技术与应用(2020年4期)2021-01-18
中国生物医学工程学报(2019年5期)2019-07-16
音乐教育与创作(2019年8期)2019-05-16
现代园艺(2017年23期)2018-01-18
北京航空航天大学学报(2017年3期)2017-11-23
动物营养学报(2015年10期)2015-12-01
苏州科技大学学报(工程技术版)(2015年3期)2015-02-28
