
半配对的多模态询问哈希方法
2024-03-15 09:22:06马江涛侯瑞霞
电子与信息学报 2024年2期
庾 骏 马江涛 咸 阳 侯瑞霞 孙 伟
①(郑州轻工业大学计算机与通信工程学院 郑州 450000)
②(中国林业科学研究院资源信息研究所 北京 100091)
③(中国农业科学院农业信息研究所 北京 100081)
1 引言
目前,社交网络中的多媒体数据持续以惊人的速度快速增长[1],使得信息搜索遇到前所未有的巨大挑战。哈希作为一种有效的特征表示技术,以其低存储、高效率的优点在信息检索、计算机视觉等领域发挥着重要作用[2]。哈希方法将高维数据映射成一串紧凑的二进制代码,然后通过快速异或运算来加速大规模数据中的最近邻(Approximate Nearest Neighbor, ANN) 搜索。先驱者们专注于单一模态搜索而提出了众多单模态哈希搜索方法[3–11],例如迭代量化(ITerative Quantization, ITQ)[3]通过学习零中心化后的数据的正交旋转矩阵,降低了从数据空间到二元超立方体空间过程的量化误差。离散局部线性嵌入哈希(Discrete Locality Linear embedding Hashing, DLLH)[6]将原始数据的局部流形结构保持到哈希码中,并且提供了一种基于锚点的加速方案,将其扩展到大规模数据搜索。基于哈达玛密码本的在线哈希(Hadamard codebook based online hashing, HCOH)[8]将共享相同标签的数据与哈达玛矩阵中的码字相关联,以在线方式训练哈希函数。单模哈希广泛应用于图像搜索并取得令人满意的性能。
然而,在实际搜索任务中,目标对象通常由来源不同的多种模态数据所描述,例如微信朋友圈发布的图片往往会附有相关的文字描述内容。一种直观的方式是扩展单模哈希,将多模态数据简单拼接为统一的高维特征来处理。然而,这种处理方式可能会造成了信息冗余和维数灾难,因此单模态哈希方法在多模态任务中表现不佳。为了克服这一问题,一些研究者们致力于研究多种模态特征的联合哈希编码问题并提出了众多多模态哈希方法[12–19],它们将异构多模态数据转换成一串联合的二进制编码。例如多特征哈希(Multiple Feature Hashing,MFH)[12],多视图潜在哈希(Multi-view Latent Hashing, MVLH)[13],多视图对齐哈希(Multiview Alignment Hashing, MAH)[14],深度多模哈希(Deep Multi-modal Hashing, SIDMH)[15],哈达玛矩阵引导的多模哈希(Hadmard matrix-Guided Multi-modal Hashing, HGMH)[16],基于松弛Hadamard矩阵的多模态融合哈希[17],具有动态查询自适应的在线多模态哈希(Online Multi-modal Hashing with Dynamic Query-adaption, OMHDQ)[18]和自适应多模态融合哈希(Adaptive Multimodal Fusion Hashing, AMFH)[19]等。多模态哈希方法旨在为完全配对的多模态样本生成联合的哈希编码,获得的联合哈希码融合了多个模态之间丰富的互补信息,相比单模态哈希方法而言,具有更好的表征能力。然而,由于习得的联合哈希函数考虑了所有的模态信息,因此这些方法对新的询问样本编码时需要确保样本中的模态信息完整。事实上,在询问阶段并不能保证所有的新样本数据都为完全配对的多模态数据,部分样本存在缺失某些模态信息的可能,本文将这种场景称之为半配对的多模态询问场景。针对这个上述问题,一些半配对的跨模态哈希方法,例如半配对哈希(Semi-Paired Hashing, SPH)[20],半配对半监督多模态哈希(Semi-paired and Semi-supervised Multi-modal Hashing,SSMH)[21],未配对的跨模态哈希(Unpaired Cross-Modal Hashing, UCMH)[22]和基于自训练的半监督和半配对哈希(Self- Training based Cross-modal Hashing, STCH)[23]被相继提出,它们为每个模态数据学习一个独立的哈希函数。但是,这些方法的多个独立哈希函数存在差异性,很难实现多模态的联合哈希编码。本文提出了一种半配对多模态询问哈希(Semi-Paired Query Hashing, SPQH),为半配对的多模态询问生成联合的哈希编码提供了有效的解决方案。图1展示了本文提出的SPQH的流程图。所提框架包括训练阶段和询问编码阶段。在训练阶段,联合执行投影学习、跨模态重构学习、多模态融合学习和语义保持哈希学习来学习联合的判别性哈希函数。在询问编码阶段,对于模态缺失的询问样本,提出的模型巧妙地利用学习到的交叉重构矩阵来补全缺失的模态特征,然后再融合多模态特征以获得询问实例的联合哈希码。本文提出的SPQH的主要贡献总结如下:

图1 SPQH框架的示意图
(1) 开发了一种多模态联合哈希学习框架,将子空间学习和哈希学习结合成一个统一的学习架构。提出的模型融合了多模态信息并保留标签空间中的语义结构信息以学习具有判别性的联合哈希函数。
(2) 设计的跨模态重构项增强了异质模态之间的语义一致性表示,能够利用学习到的重构矩阵有效地解决了询问数据中模态不完整的样本的联合哈希编码问题。
(3) 提出了一种有效的优化方法来求解带有离散约束的目标函数。在3个公开数据集上的评估结果表明了本文所提出的方法优于最新的多模态哈希方法。
在行文结构上,本文剩余部分安排如下。第2节详细描述提出的半配对的多模态询问哈希模型和优化方法。第3节展示并讨论了在3个数据集上的实验结果。第4部分得出论文的结论。
2 半配对的多模态询问哈希方法
2.1 模型阐述
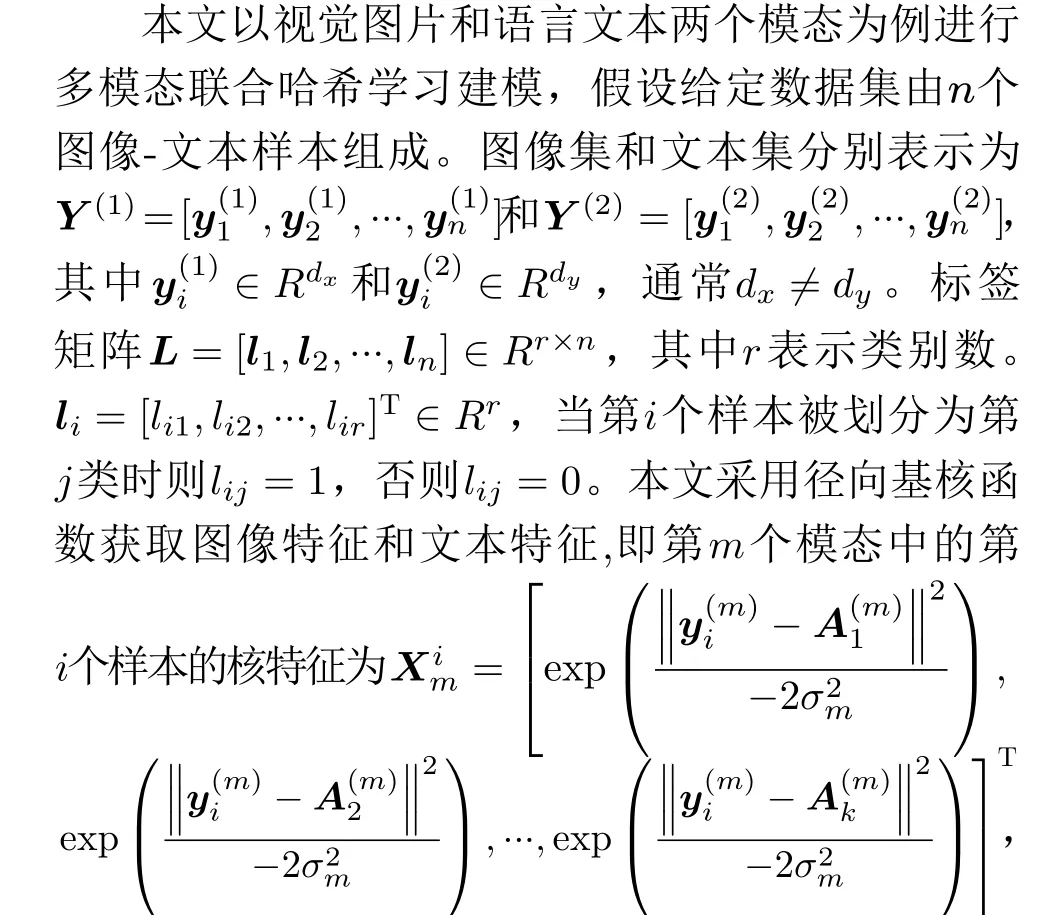
其中σm是第m个模态对应的核宽,(m=1,2);A(1)∈Rdx×k和A(2)∈Rdy×k分别是从图片模态和文本模态中随机选择的锚点样本集,其中k是锚点样本的数目。本文使用X1和X2分别表示经过核化计算后的图像模态特征矩阵和文本模态特征矩阵。
样本中的不同模态描述相同的语义内容,成对的不同模态之间的语义一致性可以作为跨越不同模态的桥梁。某个模态可以通过其他模态的子空间重建,以捕获模态之间的相关性。因此,通过找到一个潜在的子空间,其中任意模态数据通过其他模态的子空间特征来重构。上述想法转换为式(1)。
其中Pm ∈Rd×k和Um ∈Rk×d分别表示第m个模态的映射矩阵和基矩阵。Em ∈Rd×n表示第m个模态在子空间中的特征表示。异构模态之间的语义内容是一致的,且信息上存在互补性,因此,本文通过融合互补的多模态信息并且保留标签空间中的语义结构,有助于增强哈希模型的判别性。具体而言,问题表述为式(2)。

2.2 模型的优化方法
由于式(3)是一个多变量的非凸优化问题,直接求解比较困难。在本小节中,采用交替优化的方式来优化这些变量,通过固定其他变量,每次优化一个变量,更新规则总结为以下9个步骤。
步骤1 其他变量不变,关于P1的子目标函数为
令式(4)关于P1的导数为零,得到了P1的闭合解
步骤2 其他变量不变,关于P2的目标函数为
然后,令式(6)关于P2的导数为零,得到
步骤3 其他变量不变,关于E1的目标函数为
令式(8)关于E1的导数为零,可以得到

步骤8 其他变量不变,关于αm的目标函数为
其中Gm=//WmEm-B//2F,通过优化式(19)的拉格朗日函数得到最优αm
步骤9 其他变量不变,关于B的目标函数为
带离散约束的式(21)是一个NP-hard问题。通过引入辅助变量V,式(21)转化为它的等价形式
其中ρ是一个平衡参数。采用交替优化方法求解B和V。具体地,通过固定V,可以得到B的闭合解
保持B不变时,令目标函数(22)关于V的导数为零,可以得到
在联合学习过程中,所有变量将被迭代性地交替优化,直到总体目标函数收敛或迭代次数达到预设的最大值,整个优化过程被总结在算法1中。通过算法1可获得式(3)中最优的P1,P2,U1,U2,W1和W2值。这些求得的最优变量将被传递给后续询问编码阶段,用于为多模态询问样本生成联合的哈希编码。
2.3 非成对的询问扩展和联合哈希编码阶段


算法 1 半配对的多模态询问哈希模型

2.4 算法复杂性分析

3 实验
3.1 实验设置
为了验证提出的方法的性能,本节将在Pascal Sentence[24], NUS-WIDE[25]和IAPR TC-12[26]等3个基准数据集上与多种主流的哈希方法进行对比实验,即使用测试集数据从检索集中检索相关结果,文中采用平均查准率(mean Average Precision,mAP)指标衡量检索性能,越大的mAP值代表越好的检索性能。3个数据集的详细统计如表1所示,实验中的询问数据指的是除训练集以外的数据,包含了测试集和检索集。在对比实验中,将提出的SPQH与单模态哈希方法(包含ITQ[3], LSH[4],DLLH[6], HCOH[8]),多模态哈希方法(包含MFH[12],MVLH[13], OMH-DQ[18], SIDMH[15], AMFH[19]),半配对跨模态哈希模型(SPH[20], SSMH[21], UCMH[22],STCH[23])和深度学习方法(DMHOR[27], DMVH[28],FGCMH[29])进行性能比较。在实验中,完全配对的询问场景指的是在测试过程中提供了完全配对的询问集,而半配对的询问场景说明询问集中有一定比例的未配对的询问样本,其中完全未配对的询问场景表示询问集仅含有图片模态或者文本模态。由于SPQH方法在训练阶段是基于完全配对的图文样本来训练的,所以为了进行公平比较,单模态哈希方法(ITQ, LSH, DLLH和HCOH)将多个模态输入特征串联起来进行模型训练,半配对跨模态哈希模型(SPH, SSH, SSMH, UCMH, STCH)将配对样本的比例设置成100%来完成模型训练。基线方法中的超参数根据其原始论文中给出的设置建议进行设置。提出的SPQH通过固定其他参数,在较大范围内调整方法中的每个超参数以寻找其最优设置。在对比实验中,详细参数设置如下:在Pascal Sentence数 据 集 上,λ=0.5,β=1e5,γ=1e-3,ρ=1e3;在NUS-WIDE数据集上λ=0.1,β=1e1,γ=1e-3,ρ=1e3;在I A P R T C-1 2 数据集上,λ=0.9,β=1e3,γ=1e-5,ρ=1e-5。

表1 3个基准数据集的统计数据
3.2 检索精度比较
本节将呈现在3个数据集上所有方法在不同哈希码长度下的检索精度, 哈希编码长度分别被设置成16位、32位、64位和128位,以全面地评估所提方法的性能。在测试阶段,执行图像查询图像、文本查询文本、图像-文本实例查询图像-文本实例3种检索过程,分别简称为“I2I”, “T2T”和“O2O”。文中SPQH后接的后缀标识(如“all”, “img”,“txt”)是为了区分给定的询问数据中包含的模态类型。
(1) Pascal Sentence数据集上的对比实验:表2展现了所有对比方法在Pascal Sentence数据集上的mAP值。从对比的实验结果中可以观察到SPQH_all优于所有的单模态哈希方法。当码长为16 bit时,SPQH_all的性能劣于多模态哈希方法SIDMH和AMFH,而在码长大于32 bit时,比次优的多模态哈希方法AMFH平均提高了2 %。如图2(a)所示,通过改变汉明半径以返回落在不同半径内的点,绘制Pascal Sentence数据集上所有对比方法的PR 曲线,本文提出的SPQH性能优于所有基线方法。在表3中,可以观察到本文提出的SPQH在Pascal Sentence数据集上一致地超越所有半配对的跨模态哈希方法,并在平均性能上保持较大的差距。DMHOR, DMVH, SIDMH和FGCMH是基于深度学习的多模态哈希方法,尽管这些方法具有很强的特征提取能力,但是它们需要依赖大量的高质量数据去训练模型,在数据量较小的Pascal Sentence数据集上,其检索性能受到限制。如表4所示,与上述深度方法相比,SPQH取得了最佳的检索精度。此外,将本文提出的SPQH模型应用于仅含一种模态而其他模态缺失的单模态询问场景。'SPQH_img'表示询问编码阶段的样本仅提供图像模态,'SPQH_txt'表示询问样本仅提供文本模态。'SPQH_img'和'SPQH_txt'首先分别利用学习到的重构矩阵U1和U2生成伪文本模态特征和伪图像模态特征,然后通过习得的哈希函数获得其联合哈希码特征。图3(a)和图4(a)分别是完全未配对的图像询问场景和文本询问场景的PR曲线,可以看出SPQH在图像检索和文本检索任务中的性能都优于其他的对比方法。

表2 完全配对的询问场景下不同比特长度的多模态检索任务的mAP比较
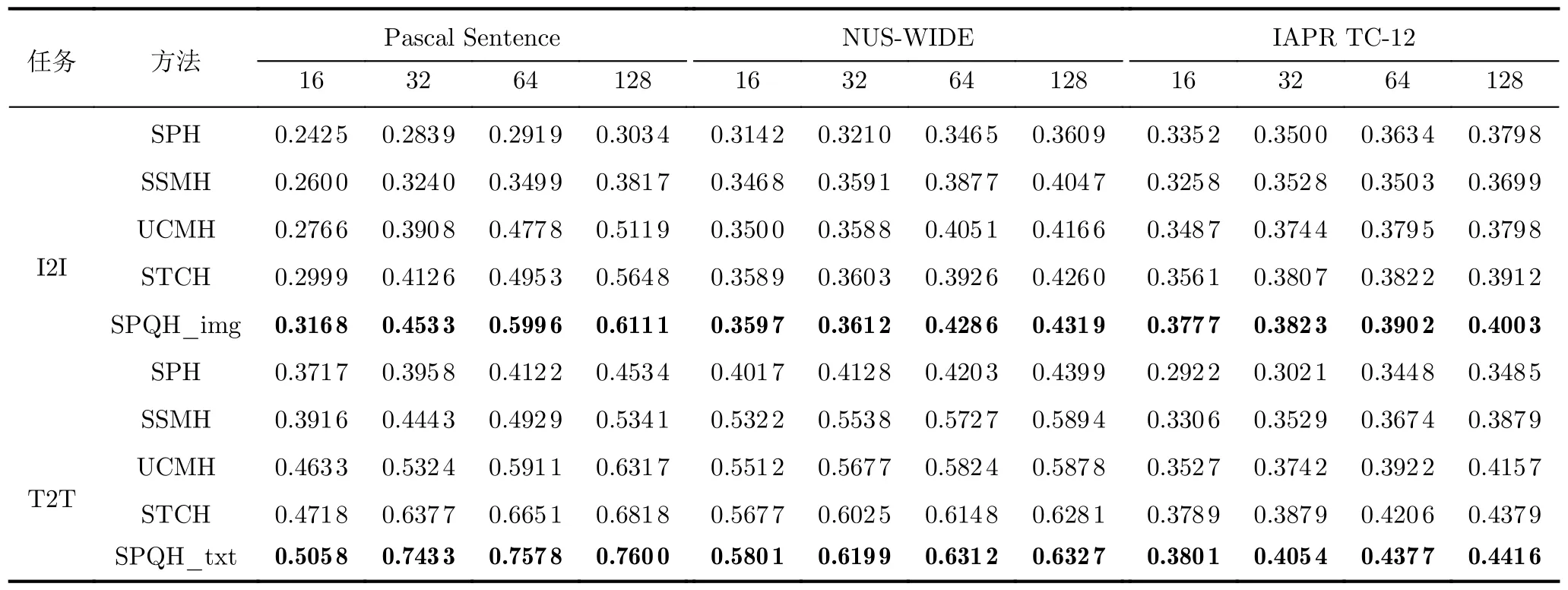
表3 完全未配对的询问场景下不同比特长度的多模态检索任务的mAP比较
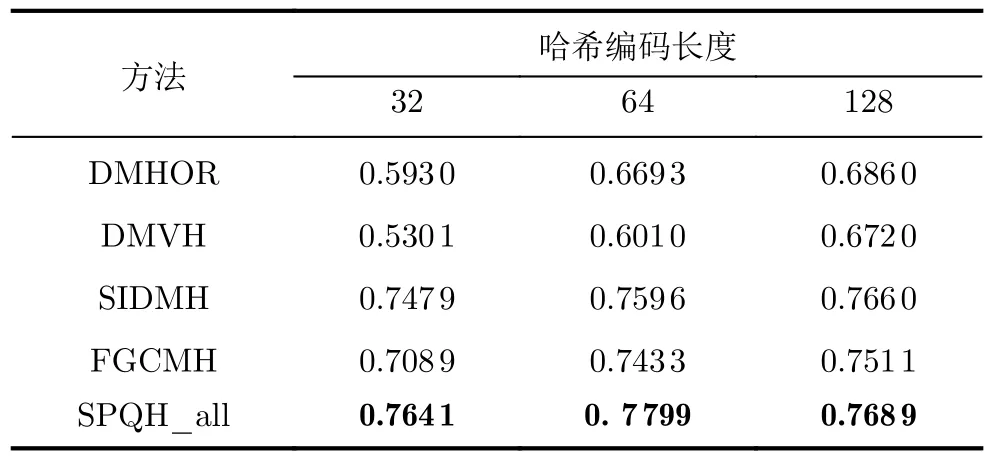
表4 Pascal Sentence数据集上SPQH与深度方法的mAP比较

图2 完全配对的询问场景下的PR曲线
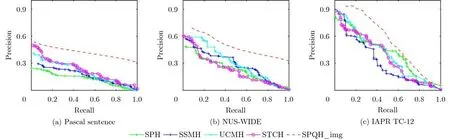
图3 完全未配对的图像询问场景下的PR曲线

图4 完全未配对的文本询问场景下的PR曲线
(2) NUS-WIDE数据集的对比实验:所有对比方法在NUS-WIDE数据集上的mAP值如表2所示,可以看出所提出的SPQH在不同码长设置下的“O2O”任务上都优于所有对比方法。图2(b)绘制所有方法的PR曲线,SPQH相比基准方法有显著的改进。表3记录了所有方法在I2I和T2T任务上的检索准确率,在平均检索准确率方面,本文提出的SPQH相比最佳基线方法STCH,在“I2I”任务上高出4.36 %,在“T2T”任务上获得了5.08%的性能提升。图3(b)和图4(b)分别描绘图像检索图像和文本检索文本的PR曲线,显然,SPQH的性能是最好的。上述实验结果表明本文提出的方法能够有效地完成图像搜索和文本搜索。通过观察表2、表3中SPQH_all, SPQH_img和SPQH_txt的mAP值,可以发现SPQH_txt比SPQH_img更接近SPQH_all。这种实验现象表明提出的模型在模态缺失的询问场景中通过已知文本模态生成图像模态特征的能力优于图像模态生成缺失的文本模态特征。
(3) IAPR TC-12数据集的对比实验:所有方法的比较结果及其在“O2O”任务上的PR曲线分别如表2和图2(c)所示。从实验结果中可以看到,本文提出的SPQH方法始终优于其他方法,并且随着哈希码长度的增加,获得了更高的准确率。具体来说,本文提出的方法在“O2O”任务上获得了2.86%的提升。同样,在IARP TC-12数据集上,SPQH_img和SPQH_txt比最好的基线方法分别高出4.03%和3.95 %。图3(c)和图4(c)分别描绘图像询问场景和文本询问场景下的PR曲线,实验结果表明所提出的SPQH方法在未成对的一种模态场景下的检索性能优于所有半配对的多模态哈希基线方法。
3.3 讨论
本节通过实验探究本文提出的方法在各特征空间的特征表征能力。以单标签的Pascal Sentence数据集为例开展直观的对比验证实验。首先随机选取600个图像-文本样本来训练本文提出的模型,保存中间过程的多种特征。然后,使用t-SNE工具分别绘制这些特征的分布图。图5给出了原始图像特征、原始文本特征、子空间特征和二值特征的可视化分布。如图5(a)和图5(b)所示,在原始模态空间中很难将各类数据分离。图5(c)中展示了文本模态的低维子空间的数据分布,可以观察到不同的聚类簇被呈现,不同类别的样本被聚集在不同的区域。图5(d)绘制的是学习到的联合哈希码特征的分布情况。在图5(d)中,可以清楚地看到具有相同类的样本更加紧凑,不同类别的区域更加分离。上述实验现象表明,本文提出的SPQH算法能够学习到具有判别性的联合哈希码特征。为了探索目标函数式(3)中的语义结构保持项对模型性能的影响,本文设计了如下的消融实验,其中SPQH-DSP表示SPQH模型丢弃语义结构保持项。在3个数据集上的对比实验结果如表5所示。相比SPQH-DSP,SPQH保持了较大的检索性能优势。由此可见,本文构建的语义保持项是非常有助于判别性的哈希函数学习。提出的SPQH模型通过训练阶段习得的重构基矩阵对缺失的模态特征进行补全,然后再利用训练阶段习得的联合哈希函数生成联合哈希码以实现哈希检索。本节通过设计以下实验来探索SPQH模型的跨模态特征重构能力。SPQH_all是利用联合哈希函数对完全配对的图文询问样本进行联合哈希编码。SPQH1指将习得的联合哈希函数中的视觉模态的权重总是设置为0,这意味着在编码阶段仅对多模态询问样本的文本特征进行编码。SPQH2表示文本模态的权重则被设置为0,即仅针对图像特征进行哈希编码。SPQH_img和SPQH_txt首先利用了跨模态重构矩阵对缺失的模态特征进行补全,构成全配对的伪数据,然后再生成联合的哈希码。值得注意的是SPQH_all, SPQH_img,SPQH_txt, SPQH1和SPQH2训练阶段没有区别,区别在于询问编码阶段。SPQH_all代表无缺失的询问集,而SPQH_img和SPQH2表示询问样本缺失文本,SPQH_txt和SPQH1表示询问样本缺失图像。如表6所示, SPQH_txt和SPQH_img的准确性分别高于SPQH1和SPQH2,检索结果表明本文提出的跨模态重构模块能够有效地生成缺失的模态特征。通过对比表3中记录的SPQH_img和SPQH_txt的mAP值,可以发现SPQH_txt优于SPQH_img。造成这种实验现象的可能原因在于文本模态蕴含更多的语义信息,而视觉图像体现更丰富的细节信息,高层的语义更容易转换为视觉表达。因此,相比图像模态重构缺失的文本特征,提出的SPQH模型更善于利用已知的文本模态信息去重构缺失的图像特征。此外,在测试阶段,通过对询问集中的成对的多模态样例的占比进行不同设置以观察模型的性能变化。将配对样本占比分别设置为0%, 20%, 40%, 60%, 80%和100%,假设未成对的多模态样本都只提供了文本模态信息,实验中缺失的图像模态特征信息将被重构。图6绘制了3个数据集上不同的配对样本占比的实验结果。从实验结果中可以发现在视觉模态完全缺失的情况下仍然保持较高的性能,随着配对样本占比的增大,SPQH的性能提升非常细微。由此可见,SPQH模型能够有效地利用文本模态对缺失的图片进行特征补全,并获得与完全成对的图文情景相接近的精度。通过上述讨论, SPQH模型能够学习到判别性的多模态联合哈希函数,且可以有效地对缺失地模态特征进行补全以实现半配对的询问场景下的联合哈希编码。

表5 语义结构保持项的消融实验

表6 SPQH在询问阶段基于不同模态特征编码的mAP比较

图5 不同特征空间的t-SNE可视化

图6 SPQH在询问编码阶段设置不同配对询问样本占比的mAP值
3.4 收敛性分析
在这一部分,从实验上来探究本文提出的模型的收敛性。当哈希码长度设置为128 bit时,图7给出了本文的方法在3个数据集上的收敛曲线。其他码长的收敛曲线形状与128 bit码长下的收敛曲线形状类似。在图7中,每个子图的横轴表示迭代次数,纵轴表示目标函数值。通过观察收敛曲线的变化趋势,可以看出本文提出的算法在3个数据集上都快速下降并收敛到稳定值。尽管无法从理论上去证明所提算法的收敛性,但是通过上述的实验分析,本文的算法具备较好的收敛能力。

图7 本文方法在3个数据集上的收敛曲线
4 结束语
本文提出了一种面向多模态检索的半配对的多模态询问哈希编码方法,该方法保留了标签空间中的语义近邻结构信息并且有效地融合了多模态之间的互补信息以学习联合的多模态哈希函数。基于成对的多模态数据之间的语义一致特性,设计了一种跨模态重建学习模块,为未成对的多模态询问样本生成联合的哈希编码提供有效的解决思路。另外,提出一种快速的优化方法来求解目标函数,并在3个公共数据集上执行了广泛的检索实验,实验结果表明所提出的方法在半配对的多模态询问场景中具有优越的检索性能。算法存在以下不足之处:在编码阶段,对询问数据进行融合时的加权系数是固定的,没有考虑到询问样本间模态信息的差异性。在未来的工作中,将在深度网络框架中开发自适应的多模态询问编码策略,以进一步提高哈希模型的泛化性能。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
数学物理学报(2017年5期)2017-11-23 07:51:31
专利代理(2016年1期)2016-05-17 06:14:36
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
新课程学习·中(2013年3期)2013-06-14 05:55:20
