
面向淋巴水肿疾病的电子病历命名实体识别应用研究*
2024-03-15 08:01:36汤昊宬苏万春冀秀元信建峰孙宇光沈文彬
医学信息学杂志 2024年2期
汤昊宬 苏万春 冀秀元 信建峰 夏 松 孙宇光 徐 毅 沈文彬
(1中国科学院自动化研究所 北京100190 2首都医科大学附属北京世纪坛医院 北京100038)
1 引言
淋巴水肿主要表现为局部体液滞留和组织肿胀,是全球致残率最高的疾病之一,严重危害人体健康,及时准确的诊断是阻断疾病恶化、提升术后康复痊愈率的关键。伴随着人工智能技术的飞速发展,疾病相关数据驱动的精准医学研究为此提供了行之有效的解决方案。研究者基于文本数据[1]、图像数据[2]在临床疾病辅助诊断领域已取得显著效果。患者电子病历[3]是医务人员借助医疗信息系统对临床治疗经过的记录,包括患者检查、诊断和治疗过程等重要医疗信息,通常以半结构化或非结构化形式存储,是构建智能化诊疗分析系统的数据基础。但是电子病历记录具有明显的子语言特性[3],例如包含大量专业术语和行业习惯用语、表达模式化、数字和单位混合(如6.0~8.0 mmol/L)、句子语法结构不完整等,数据噪声显著,呈异质性分布,尤其是针对同种疾病,不同医生遵循不同标准或习惯书写病历,存在一词多义和多词一义等不规范的现象,并且相较于英文语料缺乏明显的边界分隔符,词频分布呈现厚尾效应,严重影响双向编码器表征(bidirectional encoder representations from transformer,BERT)[4]等序列化语义分析技术的使用。因此,电子病历文本数据挖掘往往需要人工提取关键信息,依赖于高年资临床医生的精细标注,标注过程耗时费力,电子病历标注语料稀缺,尤其体现在亚专业学科。由此可见,针对淋巴水肿电子病历文本数据的智能化预处理或信息提取尤为重要。
命名实体识别(named entity recognition,NER)技术可以从文本中检测关键实体的范围和语义类别,是目前从非结构化文本数据中进行信息抽取的关键技术之一[5]。在电子病历数据中,实体重叠是相当普遍的现象,见图1。“左下肢”与“淋巴水肿”首尾不相交,为非嵌套实体,而“手术后淋巴水肿”包含更细粒度的“淋巴水肿”实体,为嵌套实体。如果忽略嵌套实体,则无法捕获底层文本中更细粒度的语义信息。针对该问题,基于超图[6]、序列标注[7-8]和区域设置[9]的方法存在计算复杂度高、错误级联、准确率低等问题。而GlobalPointer模型[10]无需复杂的特征工程,采用全局指针在中文嵌套实体识别任务中取得了最优效果。因此,本研究利用GlobalPointer模型和模型微调方法实现少量标注样本背景下的淋巴水肿电子病历命名实体识别模型训练,并选取基准模型进行比较,建立高质量电子病历标注文本语料库,构建人工智能技术辅助淋巴水肿疾病精准诊断、分期研究和应用的关键数据基础。
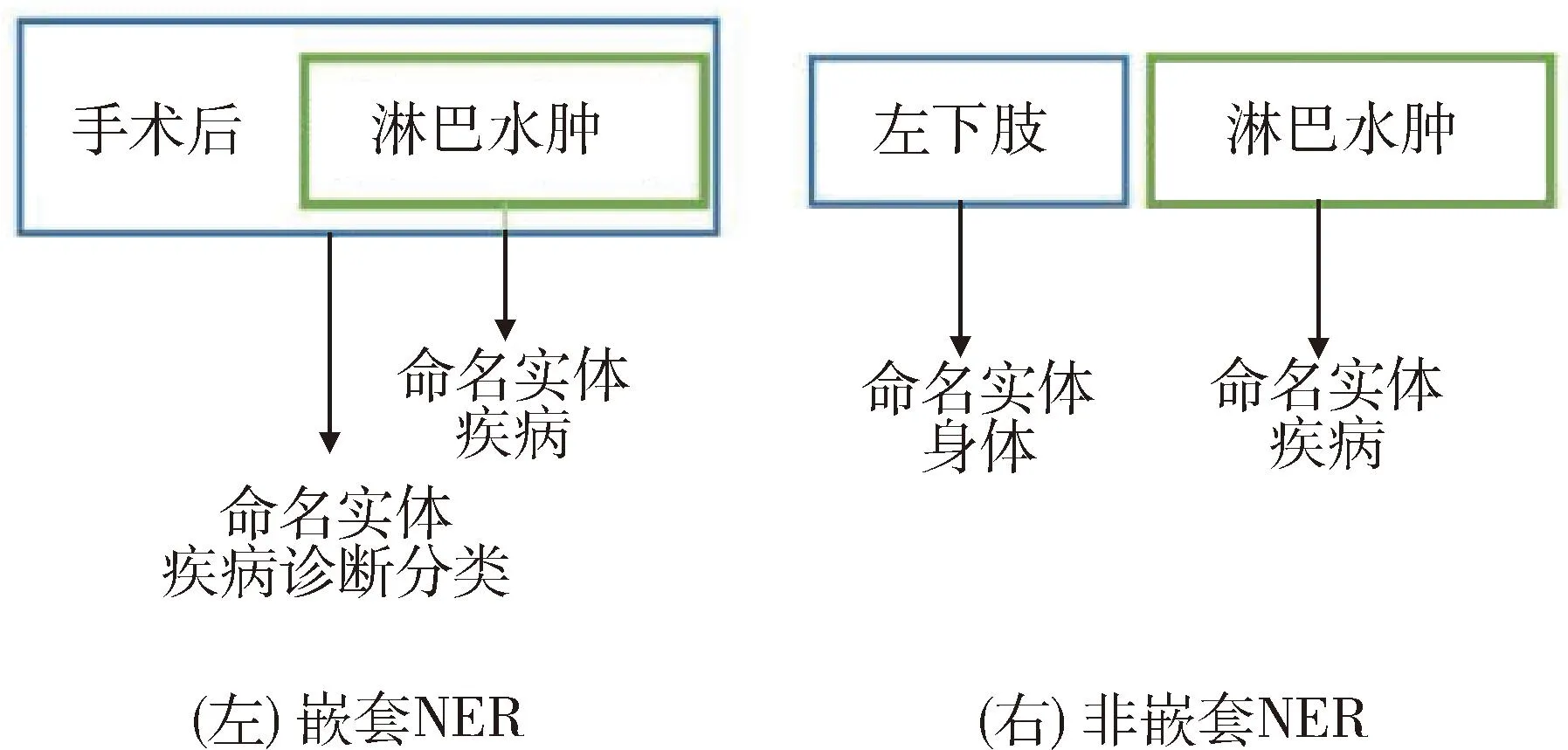
图1 命名实体识别任务分类
2 模型介绍
2.1 预训练语言模型
GlobalPointer模型以预训练语言模型为编码器提取文本特征。BERT是预训练语言模型之一,由多层编码器堆叠而成,采用完全自注意力机制,计算每个词与其他所有词的关联,在自然语言处理领域取得了显著效果,但其时间和空间复杂度与序列长度为二次方关系O(n2),可以处理的最大序列长度为512字符,长文本处理能力受限。BigBird模型[11]是另一种预训练语言模型,同样由多层编码器堆叠构成,但区别于BERT普通的多头注意力机制,其采用稀疏的多头注意力机制,将时间和空间复杂度降低为线性O(n),运行效率更高,可以处理的最大序列长度为4 096字符,是BERT的8 倍,适用于本研究中的长文本电子病历。因此,采用BigBird模型作为GlobalPointer模型的编码器。注意力值计算方式如下:
ATTND(X)i=

(1)
其中,Qh和Kh分别是查询函数和键函数,Vh是值函数,σ是评分函数,H表示头数(Head),N(i)表示所有需要计算的词。
2.2 GlobalPointer模型
传统嵌套实体识别方法设计两个模块分别识别实体的头、尾位置,未考虑实体片段的内在关系,GlobalPointer模型构造文本长度的方形矩阵,同时考虑首、尾位置,通过行和列索引位置来判断文本片段是否为一个实体,更具全局性,见图2。第1行第3列属于病程类型的实体“5年前”,赋予标签1,其余部分为0。此外,方形矩阵的数量与实体类别数量相同,每一个方形矩阵用来判别一种实体类别。命名实体识别任务方向为从前向后,如要判别“5年前”是否为实体,无需考虑“前年5”是否为实体的情况。基于此特性,矩阵左下三角为空白,无需赋予标签,训练时亦无需计算损失。图中每个小方框代表1个待识别的实体,对于长度为n的文本,若仅需要识别一种实体,则有n(n+1)/2个不同的连续片段(待识别实体),因此,研究任务可转化为从中选择a个实体的多标签分类问题。

表1 淋巴水肿电子病历文本数据统计

图2 GlobalPointer模型示例
GlobalPointer模型由学习层和预测层两部分组成,学习层由BigBird编码器构成,输入文本X=[x1,x2,…,xn]经过预训练语言模型BigBird编码得到语义表示H=[h1,h2,…,hn],其中:
h1,h2,…,hn=PLM(x1,x2,…,xn)
(2)
令s[i:j]表示文本的片段序列,i表示开始位置索引,j表示结束位置索引,H经过前馈层变换后得到用于识别α类型实体的向量表示qi,α(开始位置,矩阵中的行)和kj,α(结束位置,矩阵中的列):
qi,α=Wq,αhi+bq,α
(3)
kj,α=Wk,αhj+bk,α
(4)
(5)
(6)
由于电子病历文本长度n较长,n(n+1)/2个待识别实体中包含的真正实体(标签为1)数量往往占比较小,会带来极其严重的类别不均衡问题。采用多标签分类的损失函数解决此问题:
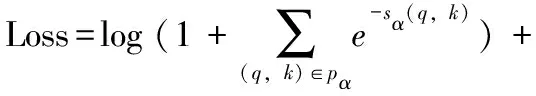
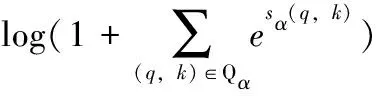
(7)
其中,Pα表示α类型实体的首、尾集合,Qα表示非实体或者非α类型实体的首、尾集合,因此,损失函数的优化方向为属于α实体的sα(q,k)得分增大,非α实体的sα(q,k)得分减小。
3 实验设置
3.1 数据介绍
实验数据来自医院脱敏数据,见表1。利用Doccano工具进行数据标注,临床医生确定的实体类别以及统计的实体数量,见表2。实体数量分布不均衡,例如“临床症状”实体类别包含29 342个实体,而“微生物”实体类别只包含2个实体。共有19名淋巴外科专业的医生参与数据标注任务,其中主任医师1人,副主任医师3人,主治医师5人,住院医师10人。学历学位分布方面,12人为博士学位,5人为硕士学位,2人为本科学位。数据标注流程为:先由高年资医生制定数据标注标准和质量控制规范,并标注300例示例数据;然后经过培训的低年资医生以“双人标注,双人核查”的方式标注剩余数据。对标注不一致的数据,由高年资医生进行最终决策,保证数据标注的准确性和规范性。
3.2 实验参数设置
实验中模型的超参数包括训练批次(epoch)、学习率(learning rate)、文本最大长度(max_len)、批量大小(batch_size)。由于显存限制,文本最大长度设置为2 800字符,超出部分将截断,本研究数据截断占比为1%。批量大小设置为2,学习率一般为e-5级别,对常用的2e-5、3e-5和5e-5利用网格搜索法进行实验,结果表明学习率设定为5e-5、训练批次设定为25时模型效果最优。
3.3 模型微调过程
借助预训练语言模型,GlobalPointer模型已经在普通带嵌套命名实体识别任务中取得了最优效果,因此,本研究主要进行垂直领域微调学习,根据少量医生标注样本数据实现最终模型的快速学习。微调训练过程如下。输入:模型初始化参数θ,学习率λ。输出:更新后的参数。初始化模型的参数θ,学习率为λ。数据预处理:电子病历文本经过BigBird编码器后,得到语义向量H=[h1,h2,…,hn],作为新的输入X。计算损失函数LE(θ)=-ylogp(y|x;θ),p(y|x)表示预测标签为y的概率。则θ=θ-λ▽LE(θ)。
3.4 基准模型选取
为验证本研究方法的适用性,选取BERT-MRC模型[12]进行比较。BERT-MRC是一种基于机器阅读理解(machine reading comprehension,MRC)的命名实体识别模型,通过构建问句的方式引入实体类别相关先验信息,再与文本内容共同作为模型输入。随后,模型通过两个多分类任务从文本内容中抽取问句答案,分别预测答案的开始和结束位置,即实体在文本中的起止位置,从而完成命名实体识别任务。这种方法在多个中英文数据集的命名实体识别任务中表现优异,可作为基准模型与GlobalPointer模型进行预测效果的比较。
3.5 模型评估指标
采用5折交叉验证方法,将数据集分成5个子集,每次使用其中4个子集作为训练集,剩余的1个子集作为测试集,评价模型的预测能力。评估指标包括精准率(precision)、召回率(recall)和Macro_F1分数,并计算均值和方差:
(8)
(9)
(10)
(11)
其中,TP表示实际为正样本且预测为正样本的个数,FP表示实际为负样本但预测为正样本的个数,TN表示实际为负样本且预测为负样本的个数,FN表示实际为正样本但预测为负样本的个数,精准率表示全部正样本的预测结果中正确预测所占比例,召回率表示全部正样本中正确预测所占比例,Macro_F1分数是精准率和召回率的调和平均值。此外,采用箱线图四分位数反映数据分布特征,并判断是否存在异常值。下限表示为Q1-1.5 (Q3-Q1),下四分位数表示为Q1,中四分位数表示为Q2,上四分位数表示为Q3,上限表示为Q3+1.5(Q3-Q1),异常值为低于下限或超过上限的值。
4 实验结果分析
4.1 准确性分析
数据集共15种实体类别,其中“微生物”“当前的”包含实体数量极少(分别为2个、11个),予以剔除。因此,本研究评估含有13种实体类别的命名实体识别GlobalPointer模型效果,并与基准模型BERT-MRC进行对比。总体实验结果,见表3,GlobalPointer模型方差较小,并且没有异常值(“-”表示没有异常值),与BERT-MRC模型相比,在Macro_F1分数方面可以提升约8个百分点,展现了实体识别总体结果最佳。

表3 总体实验结果
GlobalPointer模型针对每个实体类别的分类效果,见表4。“医疗设备”实体数量相较于其他实体类别过少,仅包含99个实体,虽然精准率高,但召回率过低,待样本数量增加后,Macro_F1分数会有所提升。此外,“临床症状”“医疗程序”等实体类别包含不同名称的实体数量较多,对实验结果造成一定干扰,待数据标注规范更新统一后,命名实体识别模型效果可得到进一步提升。
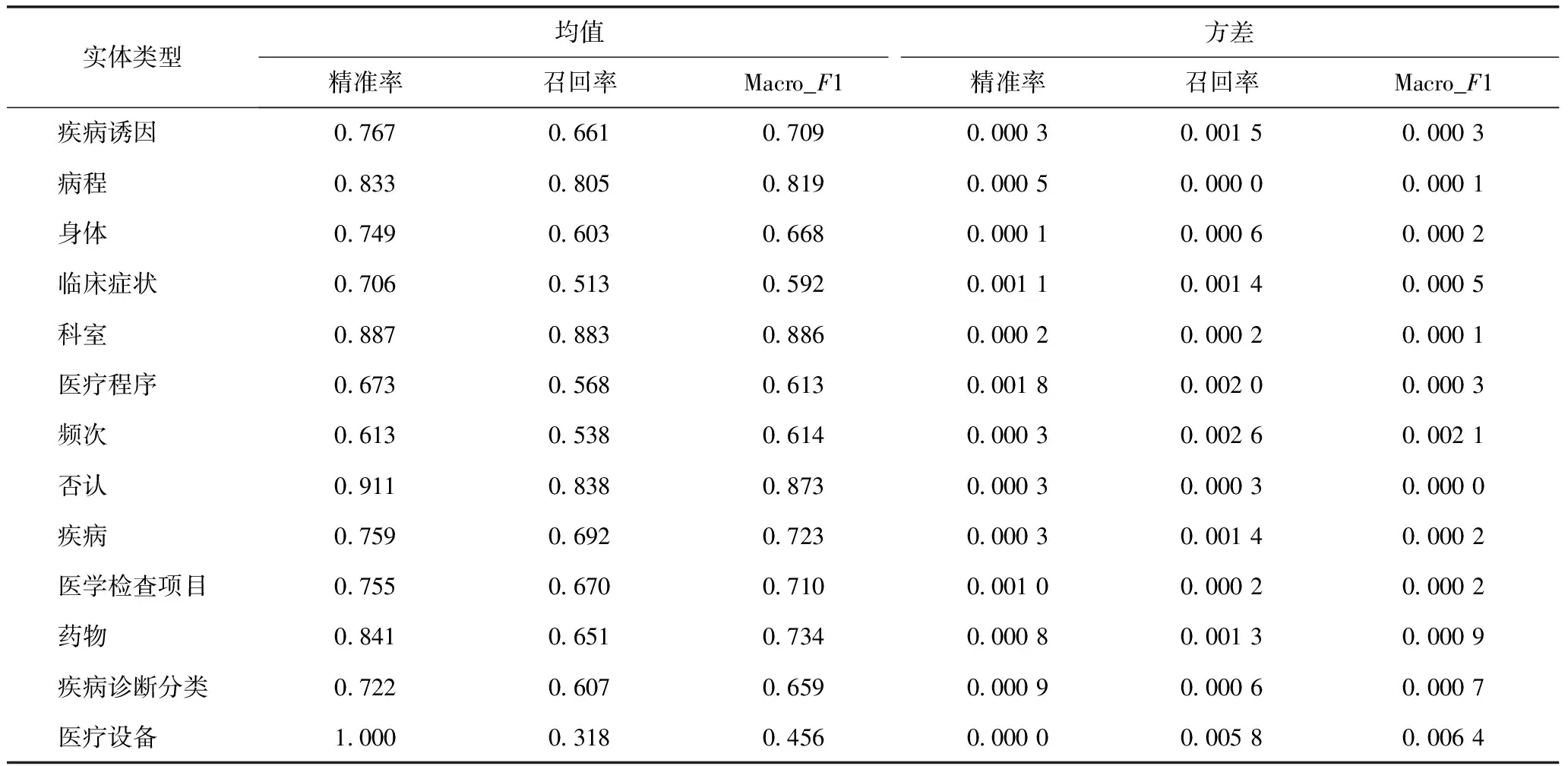
表4 GlobalPointer模型13种实体类别实验结果
4.2 案例分析
以某份淋巴水肿电子病历的命名实体识别结果为例进行分析,展示现病史、既往史、体格检查和出院诊断的标注情况,见图3。左图为模型标注结果,右图为真实标签情况。针对“出院诊断”标注部分,模型不仅能够识别出“手术后淋巴水肿”这一“疾病诊断分类”类型的实体,同时可以识别出更细粒度的“疾病”类型实体“淋巴水肿”,模型具备识别出“XX 淋巴水肿”的能力,可以较好地解决实体嵌套问题,提升命名实体识别效果。但标注模型仍存在一定缺陷。例如,虽然将“宫颈癌根治术”正确识别为“疾病诱因”实体类别,却又赋予该实体“医疗程序”的错误标签,一定程度上说明针对某些实体,模型区分实体类型之间的差别能力较差。此外,模型存在一定的漏标(如未能识别“放疗”这一疾病诱因实体)问题,有待进一步提升。
5 结语
本研究主要开展淋巴水肿疾病患者电子病历文本命名实体识别应用研究。利用医生专业领域知识确定了13种常见实体类别,涵盖疾病病史、症状、诊断、治疗、评估等方面。基于少量医生标注的电子病历数据,针对电子病历文本数据实体嵌套特性,采用GlobalPointer模型,以及以自然语言理解大模型为基础的预训练-微调模型学习范式,实现领域快速自适应学习。实验结果表明GlobalPointer模型对淋巴水肿患者电子病历命名实体识别任务有效,这为真实临床病历数据构建和预处理奠定基础;数据和算法均填补了智能化方法在淋巴疾病领域的应用空白。本研究采用的数据来自电子病历中的非结构化文本内容,医学专业名词表达不统一、数据记录习惯不一致,产生了一词多义和多词一义的问题。因此,如果能经预处理实现命名实体归一化,排除噪声干扰,则可以进一步提升模型表现。
个性化精准医疗是疾病诊疗的必然需求,应在模型研发时融入更多领域知识,识别多种类型文档蕴含的重要实体。与此同时,实体之间的关系也影响关键实体识别,应结合知识图谱相关技术,深入挖掘实体和实体之间的多种关系,识别其与细分领域疾病的关联关系,共同构建数据基础。此外,从淋巴外科智能化诊疗技术发展远景来看,引入数据规范和模型应用验证的标准是推动技术研发和临床应用转化协同发展的必经之路。
利益声明:所有作者均声明不存在利益冲突。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18 05:52:42
世界最新医学信息文摘(2021年12期)2021-06-09 08:35:26
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:16
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
中国卫生(2016年10期)2016-11-13 01:07:44
听力学及言语疾病杂志(2015年5期)2015-12-24 01:47:05
中国卫生(2015年10期)2015-11-10 03:14:32
现代医药卫生(2014年18期)2014-03-11 19:33:24
