
基于预训练模型的药物不良事件抽取方法研究*
2024-03-15 08:01李计巧王正瑶王怀玉
医学信息学杂志 2024年2期
袁 驰 李计巧 王正瑶 王怀玉
(1河海大学计算机与软件学院 南京 211100 2北京中医药大学国家中医体质与治未病研究院 北京 100029)
1 引言
药物不良事件(adverse drug event,ADE)是指患者在应用药物时出现的不良临床事件,可能会导致住院、残疾甚至死亡[1]。尽管在临床试验阶段,药物研发者试图发现和减少药物使用过程中可能出现的各类不良反应,但在药物上市后仍难免有新的不良反应事件发生[2]。统计数据显示,ADE每年导致超过350万次内科就诊以及100万次急诊就诊[3]。
ADE抽取作为医学信息抽取的重要任务,一直以来受到广泛关注。从最早的ADE数据集[4]到2018年n2c2的ADE评测任务[5],丰富的ADE数据集为抽取方法的研究提供了有效支撑。在众多数据集上,不少研究者积极探索各类方法[6-9]。如 Li F等[6]提出一种基于卷积神经网络的联合抽取模型,在ADE数据集上实验表明其优于流水线方法。实体关系联合抽取在于充分利用两个子任务的特性联合训练,避免了流水线方法中的错误累积,受到不少研究者的关注[10-14]。近年来预训练模型的引入为此研究提供了新的解决思路[15]。Giorgi J等[16]基于预训练模型和联合抽取模型在多个公开数据集上取得了不错的效果。
2 研究方法
2.1 总体框架
本文设计一种基于预训练模型的实体关系联合抽取方法,见图1。第1步:输入序列首先经过预训练语言模型,得到最终隐藏层的向量表示。第2步:经过命名实体识别任务模块对每个词(token)分类,输出对应的token实体标签,完成实体识别任务。第3步:根据实体识别结果确定句子中实体的边界位置,通过预训练语言模型获得对应token的向量表示,经过关系抽取任务模块,获取实体间的关系类别。
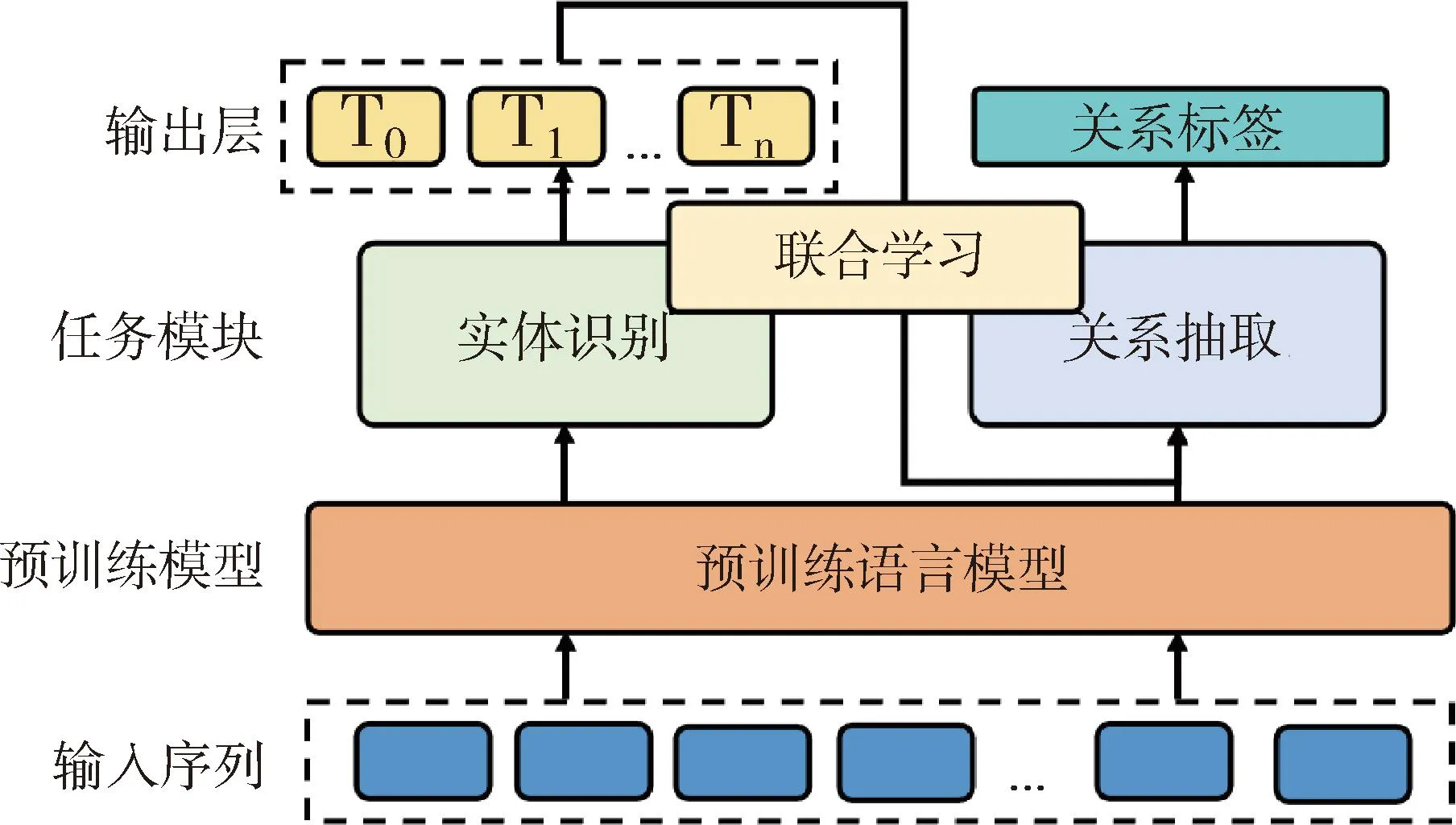
图1 基于预训练模型的实体关系联合抽取框架
2.2 实体识别模块
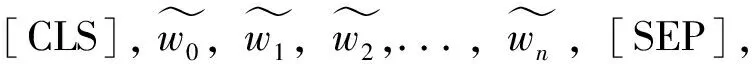
(1)
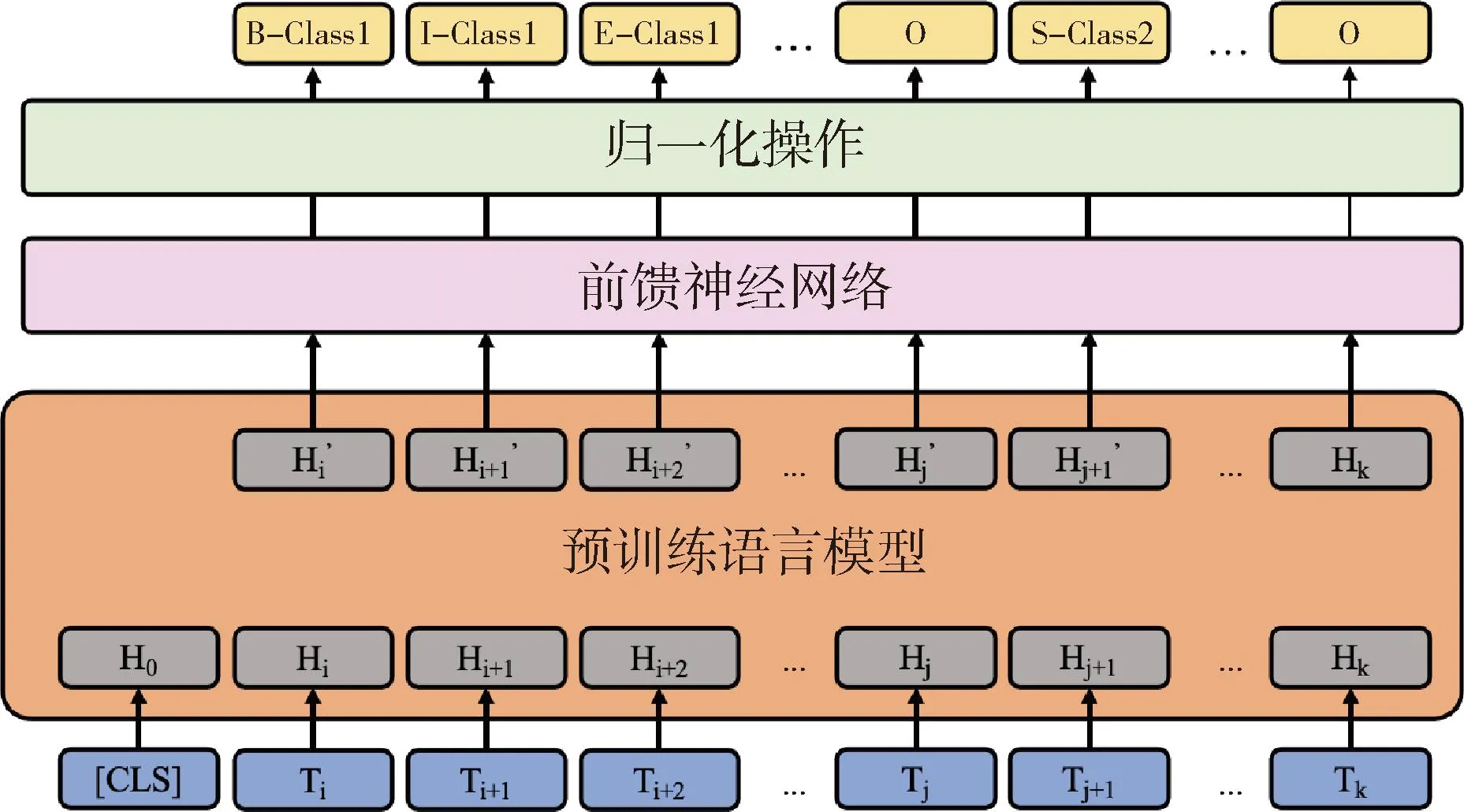
图2 实体识别模块
实体识别模块本质上是对输入序列S的每个token分类,从而得到待识别实体和非实体之间的边界。为了充分利用实体间的上下文关系,通过将编码后token的上下文表示hi输入一个前馈神经网络,经过一个归一化操作softmax层,得到每个token的所属标签,计算方式如下:
Pi=softmax(FFNN(hi))
(2)
本文采用预训练BERT模型,在编码过程中使用了基于WordPiece字典的切分化方法,可能出现输入序列中的单个单词被切分成多个token的情况。针对该问题,取首个token的实体标签代指整个单词的标签,避免出现同一个单词中部分属于某一实体,而剩余部分属于另一个实体的情况。在实体识别模块的训练中,采用基于交叉熵的损失函数,计算方式如下:
(3)
2.3 关系抽取模块
2.3.1 实体关系的编码 在关系抽取模块中,受R-BERT方法的启发,以原数据句子序列作为输入的同时,将命名实体识别结果同时传入,作为判定实体边界的依据,见图3。对每个输入的句子s,为了提取其中每个实体的表示,在实体识别结果中,选取实体 1 和实体 2 中的末尾 token 作为对应实体的向量表示,再通过激活函数激活,得到实体1和实体2的编码结果,计算方式如下:

图3 关系抽取模块
H′e1=W1(tanh(Hk))+b1
(4)
H′e2=W2(tanh(Hv))+b2
(5)
为了获得输入序列的整体表示,与BERT预训练模型相对应,获取每个句子序列中的首个token,即[CLS]token在最后一个隐藏层的结果,作为整个序列特征的表示,即图3中的H0,经过公式(6)中的激活函数激活后得到H′0,用作后续处理中代表整个序列的特征表示。本文采用的序列表示方法,不依赖人工设置特征表示,既不需要通过句法分析或者词法分析的结果设计特征或者核函数,也不需要设计具体复杂的深度神经网络,而word embedding[17]、Character Embedding[18]则要通过深度学习方法进行特征表示。
H′0=W0(tanh(H0))+b0
(6)
关系抽取可以转换为机器学习方法中的分类任务。在获得成对实体的表示、序列的表示后,通过对3个向量集联操作,获得最终用于关系分类的特征表示,计算方式如下:
Hrel=W3(concat(H′0,H′e1,H′e2))+b3
(7)
2.3.2 实体间关系的分类 在获得关系的上下文表示Hrel后,通过一个多层感知机分类模型和 softmax输出层得到关系的分类概率,计算方式如下:
Prel=softmax(MLP(Hrel))
(8)
采用基于交叉熵的损失函数作为关系抽取模块的损失函数,计算方式如下:
(9)
2.4 联合学习方法
联合学习过程中,实体识别模块和关系抽取模块共享参数,能够充分利用两个子任务的关联性对预训练模型 BERT 进行调优。整个联合抽取模型的损失函数Ljoint由两个子任务的损失函数(公式 (3)和(9))共同决定,最终联合学习的损失函数定义如下,其中λ为一个用于平衡实体识别模块损失和关系分类模块的超参数。
Ljoint=λLner+(1-λ)Lrel
(10)
3 实验与结果分析
3.1 数据集和评价指标
实验部分主要采用ADE公开数据集[2],达到与此前研究可对比的效果。该数据集主要由5位独立的领域专家通过共同讨论制定标注指南文件,再由3位专家实际进行数据标注得到,具体统计信息,见表1。评价指标主要由实体识别的评价指标、关系抽取的评价指标和实体关系联合抽取评价指标3部分组成。采用机器学习领域常用的精准率、召回率和F1指数。为了便于与此前研究方法进行性能对比,通过与此前方法类似的10折交叉验证来验证模型效果。

表1 训练集数据统计信息
3.2 实验参数设置
为了比较不同预训练模型在本文设计提出的实体关系联合抽取框架中的实际效果,测试BERT、BioBERT和ClinicalBERT共3种预训练模型的表现。实验中联合抽取模型使用的具体参数,见表2。

表2 本文实验中的参数设置
3.3 实验结果
3.3.1 预训练模型对比 实验结果,见表3、表4。基于生物医学文献训练得到的BioBERT模型在面向生物医学文献中的ADE实体和关系抽取时F1表现(0.904,0.868)明显优于基于书籍语料和维基百科语料训练得到的BERT,以及基于临床文本训练得到的ClinicalBERT。但是在端到端任务的验证结果方面,本文方法结合3种不同模型时F1表现则较为接近,见表5。
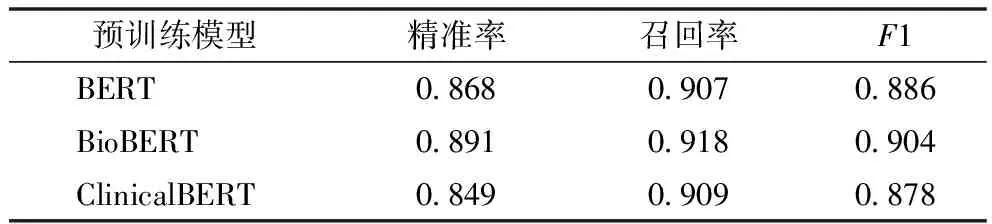
表3 本文方法结合不同预训练模型在实体抽取任务中的实验结果
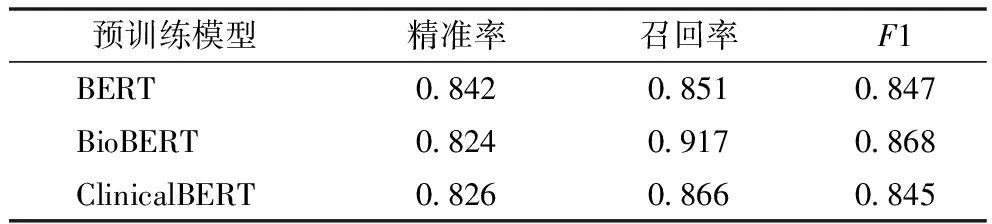
表4 本文方法结合不同预训练模型在关系抽取任务中的实验结果

表5 本文方法结合不同预训练模型在端到端抽取任务中的实验结果
3.3.2 与现有方法对比 本文所设计的基于预训练模型的实体关系联合抽取方法在 ADE 数据集上的实体抽取表现和关系抽取表现(0.904,0.868)均优于此前的研究[6-9,16],见表6、表7。实验数据均来自原作者发表论文。同是基于预训练模型的方法,本文方法在实体识别和关系抽取上的表现均优于Giorgi J等[16]提出的方法。端到端任务实验结果,见表8,本文方法(0.878)与Giorgi J等[16]的方法(0.877)表现接近,优于其他现有方法。

表6 本文方法和现有方法在实体识别任务中的实验结果
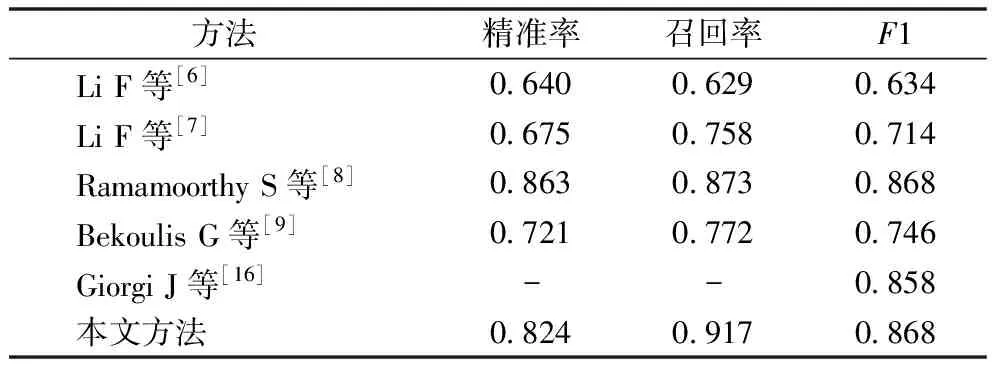
表7 本文方法和现有方法在关系抽取任务中的实验结果
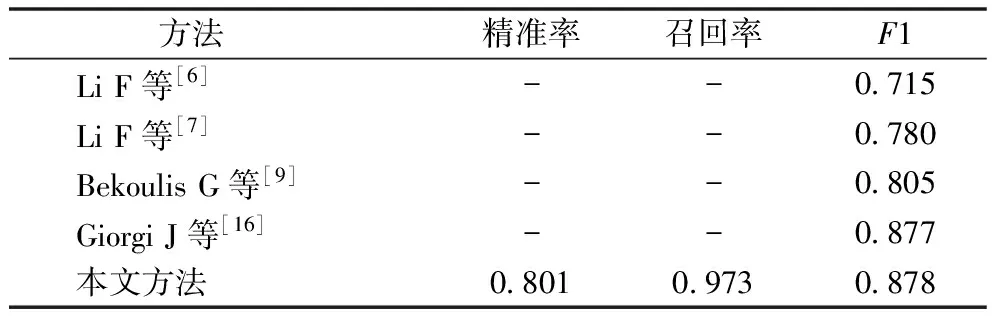
表8 本文方法和现有方法的端到端实验结果
4 讨论
通过实验分析发现,本文提出的基于预训练模型的实体关系联合抽取方法仍存在一定的改进空间,其中包括实体和关系抽取模块的优化设计、联合学习的方法等。
4.1 模块设计
本文在实体识别模块中采用一种基于预训练模型和前向神经网络的结构,虽然也取得不错的效果,但是对预训练模型的利用仍存在改进空间。后期可以采用已经在某些数据集上验证的更优化的神经网络结构,如Si Y等[19]使用BiLSTM+BERT的方法进行改进。随着研究者对预训练模型研究的深入,将提出更多的实体抽取或关系抽取方法,本文提出的联合抽取框架具有一定的扩展性,即实体抽取和关系抽取模块能够被更优化的基于预训练模型的方法替换。
4.2 预训练方式
对于预训练模型本身,本文方法并没有处理其预训练过程,而是采用通用方法得到预训练模型。对于预训练过程,可以考虑融合多种新的任务或者方法扩展原有基于掩码的语言模型(masked language model,MLM)和基于下一句预测(next sentence prediction,NSP)的方法,使训练得到的预训练模型在端到端实体关系任务上获得更优表现。现有的预训练模型对于序列分类任务和序列标注任务都设计了有针对性的训练方法,从而得到在多项测试集上的优异结果,但尚无针对关系抽取的特定优化或针对端到端方法对预训练模型本身进行的优化,导致在部分实例上效果不佳。
4.3 联合学习方法
除了利用联合抽取框架平衡两个模块的方法外,Zheng S等[20]于2017年提出标注方法解决实体关系联合抽取问题,即将实体关系联合抽取转换为与实体识别类似的序列标注任务,以“BIEO-Relation-Entity”的形式,将实体信息和关系信息都包含在每个token标签中。上述方法虽然存在无法处理实体重叠的问题,但是仍然为研究者打开了一种新的研究思路,多重标注或者多次识别可能弥补上述短板从而衍生出新的实体关系抽取方法。Zheng S等[20]也在 NYT数据集上验证了其方法的有效性。
5 结语
本文结合医学自然语言处理领域的最新发展趋势,面向ADE抽取任务提出了一种基于预训练模型的实体关系联合抽取方法。充分利用预训练模型在特征表示上的优势,无须人工加入对于实体或者序列的表示特征。实验结果表明,该方法优于已有联合抽取方法,能够应用于ADE的抽取中。
利益声明:所有作者均声明不存在利益冲突。
猜你喜欢
小猕猴智力画刊(2022年9期)2022-11-04
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
中国外汇(2019年18期)2019-11-25
小哥白尼(趣味科学)(2019年6期)2019-10-10
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
发明与创新(2016年38期)2016-08-22
太空探索(2016年5期)2016-07-12
