
多层次时空特征自适应集成与特有-共享特征融合的双模态情感识别
2024-03-15 09:22:12孙强陈远
电子与信息学报 2024年2期
孙 强 陈 远
①(西安理工大学自动化与信息工程学院通信工程系 西安 710048)
②(西安市无线光通信与网络研究重点实验室 西安 710048)
1 引言
近年来,结合以脑电图 (ElectroEncephalo-Gram, EEG)为代表的生理信号[1]和以人脸图像为代表的物理信号实现情感计算的做法已成为情感识别领域的研究热点[2,3]。这类方法在安全驾驶、远程教育、医疗健康等多个领域得到了广泛应用[4]。
在结合EEG信号和人脸图像的情感识别研究工作中,由于EEG信号具有非平稳性、低信噪比的特点,基于EEG的情感语义特征学习比基于人脸图像的特征学习更具挑战性,如何提取更具泛化性的EEG情感语义特征用于情感识别已成为该领域的研究重点[5,6]。现有的EEG特征提取主要包括手工特征提取[7,8]、脑电地形图[9,10]、深度学习[11,12]3种方法。手工特征提取方法忽略了EEG信号通道间的相关性,使得模型性能受限;脑电地形图方法的性能很大程度上依赖于手工特征的质量;深度学习方法往往通过简单的卷积操作从EEG信号中学习情感语义特征,忽视了EEG信号本质上是一种复杂的多通道时间序列数据,导致现有模型难以充分建模EEG信号内部复杂的时空关系。
另一方面,如何充分有效地利用多模态信息,捕捉多模态特征在情感语义上的一致性与互补性同样是情感识别领域的研究重点。一致性侧重于描述各模态特征之间的共享语义信息,而互补性强调各模态特征中特有语义信息的差异性[13]。为此,特征级融合、决策级融合是最为常见的融合策略。在特征级融合方法中,Zhang等人[14]通过控制各模态的特征序列长度建模模态间的关系,Rayatdoost等人[15]通过余弦相似度促使各模态特征表示对齐。然而,特征级融合方法无法克服模态间的语义鸿沟问题,难以充分挖掘模态间的语义一致性。在决策级融合方法中,Fang等人[16]采用贝叶斯融合模型结合EEG信号和人脸图像两种模态的预测结果完成最终预测,Choi等人[17]利用多模态特征生成各模态特征权重。然而,这类融合方法仅侧重于提取各模态的特有语义信息,而无法提取模态间的共享语义信息,导致模型性能受限。为此,后来的研究者做出了许多尝试。例如,Zhao等人[18]通过联合损失优化的方式使得模型同时具备决策级融合和特征级融合的优点;He等人[19]通过多模态特征增强各模态特征的表征能力,实现各模态的信息交互以及自适应的模态间平衡。然而,这些工作忽视了各模态特征所包含的情感语义信息不一致的问题,导致生成的多模态特征的表征能力欠佳,使得模型在特征融合过程中无法充分捕捉模态间的共享语义信息。
由上可知,在结合EEG信号和人脸图像的双模态情感识别研究领域,主要存在两大挑战:(1)如何从EEG信号这种非线性多通道时间序列中学习更具显著性的情感语义特征;(2)如何充分捕捉EEG信号和人脸图像中情感语义的一致性与互补性,从而有效提升情感识别模型的性能。
针对以上两大挑战,本文提出了多层次时空特征自适应集成与特有-共享特征融合的双模态情感识别模型。具体来说,针对第1个挑战,设计了多层次时空特征自适应集成模块,用于自适应集成EEG信号的多层次时空特征,生成更具显著性的情感语义特征;针对第2个挑战,受领域自适应工作的启发[20,21],提出了特有-共享特征融合模块,通过特有特征学习和共享特征学习两种方式并结合相关的损失函数学习各模态特征,完成对EEG信号和人脸图像中情感语义一致性与互补性的捕捉。本文工作主要贡献如下:
(1) 为从EEG信号中学习更具显著性的情感语义特征,设计了多层次时空特征自适应集成 (Adaptive Integration of Multi-level Spatial-Temporal Features, AIMSTF)模块,先采用双流结构学习EEG信号的时空特征,再基于多层次EEG特征之间的相似度生成各层次特征的权重,最后采用门控机制处理集成后的多层次时空特征,实现对相对重要特征的自适应保留。通过这种方式,模型的特征学习部分可以为后续特征融合部分产生更具显著性的情感语义特征奠定基础,进而提升模型的性能。
(2) 为捕捉两模态的情感语义的一致性与互补性,设计了特有-共享特征融合(Specific-Shared Feature Fusion, SSFF)模块,将各模态特征学习分为特有特征学习和共享特征学习两种方式,并采用损失函数约束各特征之间的相似性或差异性。通过这种方式,模型可以提取到各模态内部的特有语义信息以及模态间的共享语义信息,即保证模型对各模态特有情感语义信息与模态间共享情感语义信息的捕捉能力。
(3) 在DEAP数据集和MAHNOB-HCI数据集上开展了大量实验,采用跨实验验证以及5折交叉验证两种实验方法展示了所提出方法的可行性和有效性。
2 相关工作
在本节中,针对前文提到的两大挑战,对基于EEG信号和人脸图像的情感识别研究工作进一步概述。
针对第1个挑战,前人提出了手工特征提取、脑电地形图、深度学习3种方法。对于手工特征提取方法,通常采用小波变换、傅里叶变换等方法提取EEG信号中的时域、频域或时频域特征。例如,李幼军等人[22]通过Hilbert-Huang 变换从EEG信号的5个频段中提取功率谱密度 (Power Spectral Density, PSD)参数作为脑电特征;Yang等人[23]采用滑动窗口法分割数据,从每段EEG数据中提取微分熵特征。然而,这些方法依赖于领域知识,过于耗费时间和精力,难以有效表达EEG各通道之间的关系。其次,手工特征往往代表EEG信号在一个时间段内的平均状态,导致部分关键特征容易丢失。
为此,有的研究者提出了脑电地形图法[24–26],将手工特征映射至地形图,利用卷积神经网络(Convolutional Neural Network, CNN)强大的空间特征建模能力间接捕捉EEG通道之间的关系。例如,王斐等人[24]先采用快速傅里叶变换提取PSD特征,再将其转换为电极-频率分布图,利用CNN完成疲劳检测;Li等人[25]将5个频段对应的微分熵特征映射至脑电地形图,通过一种改进的ResNet34网络实现情绪分类;Siddharth等人[26]基于PSD特征生成脑电地形图,通过预训练的VGG-16网络建模EEG的通道间关系。然而,该方法没有克服手工特征的缺点,模型性能依赖于手工特征的质量,没有充分利用深度学习模型的端到端特征学习能力。
为简单有效地从EEG信号中捕捉具有较强泛化能力的特征,部分研究者采用深度网络从EEG信号中直接学习情感语义特征[27–29]。例如,杨俊等人[27]将EEG信号作为输入,采用2维卷积学习脑电信号的时间、空间特征,结合自编码器完成特征映射;An等人[28]将多通道EEG时间序列转换为2维网状矩阵序列,通过CNN与卷积长短期记忆 (Convol u t i o n a l L o n g S h o r t-T e r m M e m o r y,ConvLSTM)网络的结合学习EEG信号的时空特征;类似地,陈景霞等人[29]将EEG信号转换为2维图像帧序列,并提出了级联卷积-循环神经网络和级联卷积-卷积神经网络分别用于建模EEG信号在空间与时间上的依赖关系。然而,这些方法往往忽略了特征学习过程中部分情感语义特征的丢失,导致模型性能欠佳。
针对第2个挑战,研究者们探索了数据级融合、特征级融合、决策级融合以及混合融合等多种策略。例如,Salama等人[12]首先将EEG信号与人脸图像在数据级融合,再结合迁移学习方法训练深度学习模型。然而,数据级融合带来了参数量过大的问题,导致模型容易出现过拟合。Comas等人[30]采用自编码器重建生理信号,利用中间表示作为特征,通过特征拼接完成特征融合;Zhang等人[14]通过控制两模态的特征向量长度简单建模模态间的相关性;Kumar等人[31]采用迁移学习方法,采用预训练模型学习各模态特征,并通过带有加权机制的决策级融合预测情感类别。
需要指出的是,特征级融合方式虽然在一定程度上能够建模模态间的相关性,但也同时带来模态内语义信息的表征能力不足和模态间语义信息不一致所导致的性能欠佳等问题。决策级融合虽然可以充分学习模态内的特有语义信息,但是无法捕捉模态间的共享语义信息,导致模型性能受限。为此,He等人[19]通过多模态特征表示增强各模态特征的表征能力,实现各模态的信息交互和自适应的模态间平衡。类似地,Li等人[32]采用多模态多头注意力模块和时间多头注意力模块,实现模态内和模态间的特征学习。这些方法的共同特点是,通过各模态特征直接产生多模态特征,而忽略了各模态特征包含的语义信息不一致的问题。
3 本文方法
本节详细介绍了提出模型架构,包括EEG信号特征学习、人脸图像特征学习、特有-共享特征融合模块3个部分。首先,多尺度卷积和AIMSTF模块用于学习EEG模态的特征,而CNN和ConvLSTM用于学习人脸图像特征;其次,SSFF模块用于学习各模态的特有特征以及模态间的共享特征,而权重生成网络用于生成各特征相应的权重,以强调不同特征对于最终预测的贡献度;最后,全连接层用于实现情感预测。如图1所示,即为提出模型的架构。
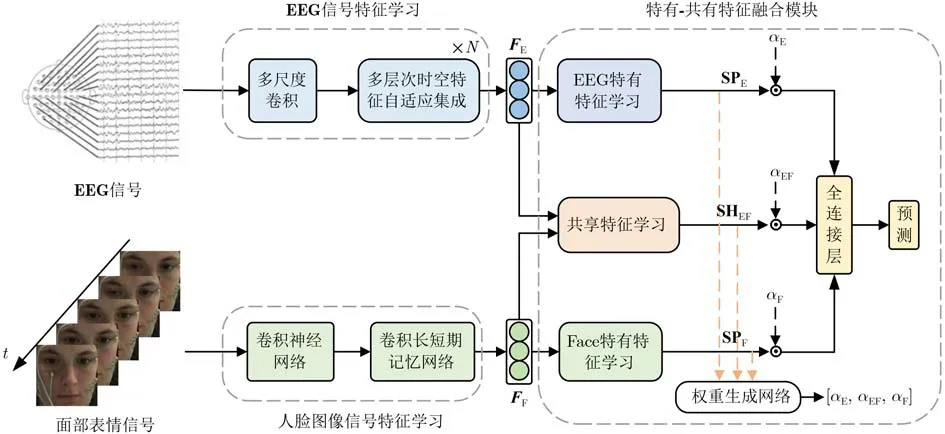
图1 提出模型架构示意图
3.1 EEG多层次时空特征学习
首先,由于与人类情感密切相关的脑电波段为Alpha (8~12 Hz)、Beta (12~30 Hz)和Gamma(>30 Hz)波段,采用多尺度卷积,通过将卷积核长度设定为与EEG采样率f相关的比例α来减少无关频段信息的干扰,实现对EEG信号的时间和频率特征的捕捉[33]。多尺度卷积模块可以用式(1),式(2)表示:
其中,x ∈R32×128表示输入的EEG信号,α·f表示1维卷积核大小,且α ∈[0.5, 0.25, 0.125] ,而ei表示1 维卷积的输出, Concat(·)代表拼接操作,MSConv(·) 代表多尺度卷积模块,P0为多尺度卷积模块的输出。
然而,虽然多尺度卷积在一定程度上能够捕捉EEG信号的时间和频率特征,但考虑到EEG信号是一种具有非平稳、非线性、多通道等特性的信号,仅通过多尺度卷积难以有效捕捉EEG情感特征中的高级语义信息。同时,考虑到EEG信号与人脸图像之间存在的语义鸿沟问题,直接融合EEG情感特征与人脸图像情感特征得到多模态情感特征并用于分类,会导致模型的泛化性欠佳。因此,设计了AIMSTF模块,旨在自适应地集成EEG信号的多层次情感特征,使EEG情感特征能在语义上更充分地包含与人脸图像情感特征相一致的信息,从而提升模型的性能。图2展示了AIMSTF模块结构,由时空特征联合学习 (Spatial-Temporal Feature Joint Learning, STFJL)模块和多层次特征自适应集成 (Adaptive Integration of Multi-level Features, AIMF)模块组成。
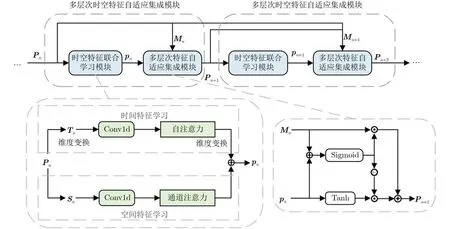
图2 AIMSTF模块结构示意图
在AIMSTF模块中,多层次卷积的输出特征P0作为输入特征。首先,通过基于双流结构的STFJL模块同时捕捉EEG信号的时间特征和空间特征,然后通过AIMF模块集成EEG特征的多层次情感语义信息,增强模型的特征学习能力。具体而言,假设输入特征为Pn ∈Rc×l,经过维度变换,得到时间特征学习分支的输入Tn ∈Rl×c和空间特征的学习分支输入Sn ∈Rc×l。该过程可用式(3),式(4)表示:
其中, Reshape(·)代表维度变换操作。
在时间特征学习分支中,首先在时间尺度上采用1维卷积操作完成EEG模态的特征学习,再采用自注意力机制,基于输入特征生成查询向量Q、键向量K以及值向量V,在时间尺度上实现EEG模态相对重要特征的选择。该过程可用式(5),式(6)表示:
其中, SA(·) 代表自注意力操作,Wq,Wk,Wv分别代表用于生成Q,K以及V的参数矩阵,dk代表缩放点积因子, Softmax(·)代表Softmax激活函数,用于对每列数据进行归一化。在空间特征学习分支中,首先在空间尺度上采用1维卷积完成对EEG模态的特征学习,再采用通道注意力机制赋予相对重要的特征通道更大的权重,捕捉EEG模态的空间特征。其中,为实现通道注意力机制,首先通过全局平均池化完成EEG模态各通道特征图的信息压缩;其次,基于权重矩阵W′完成特征的降维与非线性激活,建模各个特征图之间的相关性;然后,通过W′′完成特征的升维,并通过权重表征每个通道的相对重要性;最后,采用Sigmoid激活函数生成各通道相应的注意力分数,并应用于输入特征图,从而实现通道加权。通过权重矩阵W′与W′′分别实现特征降维和升维操作,通道注意力引入了非线性表示能力,使模型可以更有效地利用输入数据中的信息。该过程可用式(7),式(8)表示

AIMF模块将STFJL模块的输出特征pn、多层次集成特征Mn作为输入特征。为生成多层次集成特征Mn,采用余弦相似度评估先前各层次特征P=[P0,...,Pi,...,Pn] 与当前层次特征pn的相似度αi,并对其归一化,从而获得不同层次特征相应的权重系数 1-αi。这一步骤使得模型能够在特征学习过程中更关注可能丢失的、相对重要的特征。随后,对各层次特征加权求和,得到多层次集成特征Mn,即
其中, cos_simi,n表示计算Pi与pn的余弦相似度的操作。
然而,由于对先前各层次特征的集成,Mn也会不可避免地包含部分的冗余特征。因此,该模块通过门控机制自适应地学习Mn,pn中相对重要的特征,使得生成的Pn+1包含更为显著的情感语义信息。同时,将Pn+1作为下一层AIMSTF模块的输入。通过AIMSTF模块的堆叠,每个AIMSTF模块的输入特征融合了先前层次的更多特征,从而生成更具显著性的情感语义特征。该过程可用式(13),式(14)表示
其中,⊕代表拼接操作,⊙代表点乘操作。
3.2 基于预训练CNN的人脸图像特征学习
考虑到所使用数据集中人脸图像样本数量的限制,本文通过预训练模型完成人脸图像的特征学习。具体而言,我们采用了Zhang等人[14]的方法,将在AFEW-VA数据集上预训练的CNN用于每帧人脸图像的特征学习,并将得到的特征依次送入ConvLSTM中,建模各人脸图像帧之间的时间特征关系,最后将ConvLSTM的输出特征送入全连接层,得到人脸图像模态的特征FF。其中,Zhang等人[14]提出的结构如图3所示,所使用的预训练CNN的详细参数如表1所示。
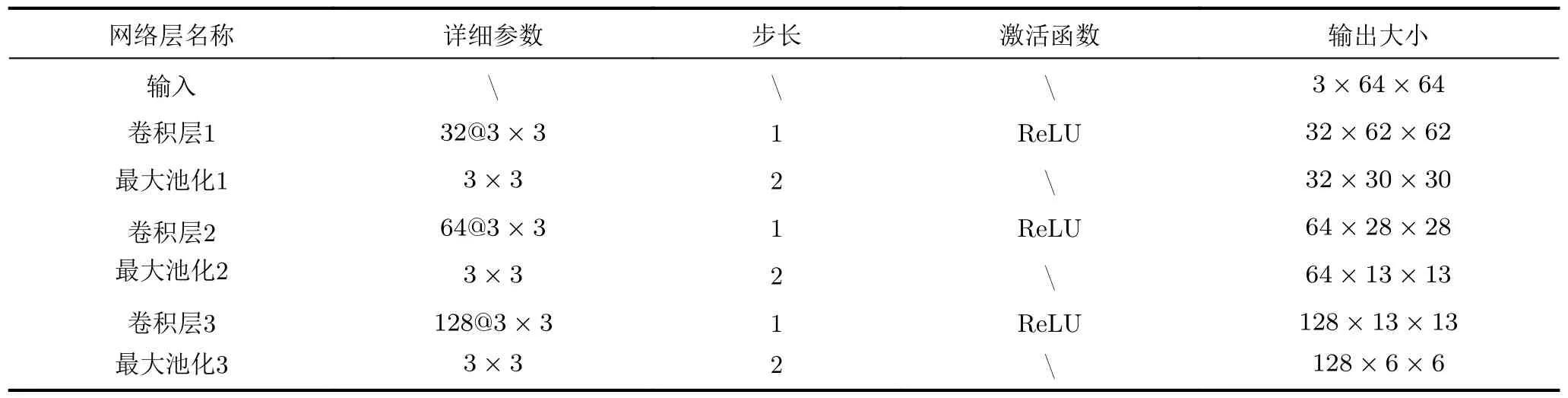
表1 Zhang等人[14]所使用的预训练CNN的详细结构参数

图3 Zhang等人[14]方法结构示意图
3.3 特有-共享特征融合
图4是SSFF模块结构示意图,其中EEG模态的特征FE、人脸图像模态的特征FF为输入特征。首先,通过特有特征学习分支、共享特征学习分支完成对两模态特征的学习,再通过损失函数建模各特征之间的关系,然后通过权重生成网络自适应地给予各特征相应的权重,最后采用全连接层完成最终预测。其中,特有特征学习分支用于学习特有特征SPE,SPF,而共享特征学习分支采用参数共享的方式学习共享特征SHE,SHF。

图4 SSFF模块结构示意图
同时,为了使模型能够有效地学习到各个模态内的特有语义信息和模态间的共享语义信息,在EEG特有特征SPE与人脸图像特有特征SPF之间、EEG特有特征SPE与共享特征SHE之间、人脸图像特有特征SPF与共享特征SHF之间引入软子空间正交性约束,通过最小化损失来最大化各分支输出特征包含的语义信息的差异,以有效捕捉到EEG信号与人脸图像信号内的特有特征。该差异性损失Ld可表示为

在领域自适应及相关领域中, Kullback-Leibler(KL) 散度[34]、最大均值差异 (Maximum Mean Discrepancy, MMD)[35]、中心矩差异 (Central Moment Discrepancy, CMD)[21,36]等方法一般被用于度量不同数据之间的分布差异。其中,KL散度用于度量两个分布之间的信息损失,是一种基于1阶中心矩的度量方法;MMD基于核函数将两个分布映射到再生希尔伯特空间,再计算两者距离,可视为一种基于所有阶中心矩加权和的度量方法;CMD基于两个分布的一阶矩和高阶矩信息完成度量,而无需如MMD方法一样使用核函数。综合来看,CMD相比于KL散度包含了高阶矩信息,相比于MMD具有更低的计算量。因此,综合考虑后采用CMD用于度量EEG共享特征SHE与人脸图像共享特征SHF之间的分布差异,并通过最小化损失使得两模态的共享特征的分布尽可能一致。具体而言,假设M、N为在区间 [a,b] 上 的随机样本,K表示中心矩的最大阶数,该相似性损失Ls可表示为
其中,//·//2表示L2范数, E(·) 表示期望, C2(·)表示方差。
然后,考虑到EEG信号和人脸图像的特有特征和共享特征中所包含的情感语义信息不同,不同特征对于最终预测的贡献度并不一致,我们设计了权重生成网络。具体来说,先将SHE,SHF拼接融合,得到融合特征SHEF,再为SPE,SPF,SHEF3个特征分别设置3个不同的可学习参数矩阵WE,WF,WEF,并拼接SPE,SPF,SHEF3个特征,最后基于拼接后的特征自适应地生成各特征相应的权重,赋予相对重要的特征以更高的权重。该过程可用式(18)—式(20)表示
其中,αE,αF和αEF分别表示EEG特有特征、人脸图像特有特征和两个模态间的共享特征所对应的权重,而 Concat(·)表示拼接操作。
最后,拼接加权后的各类特征,再采用全连接层实现最终预测,即
其中, L inear(·)用于表示全连接层。
表2详细展示了提出模型内部各模块的输入和输出特征的维度大小。
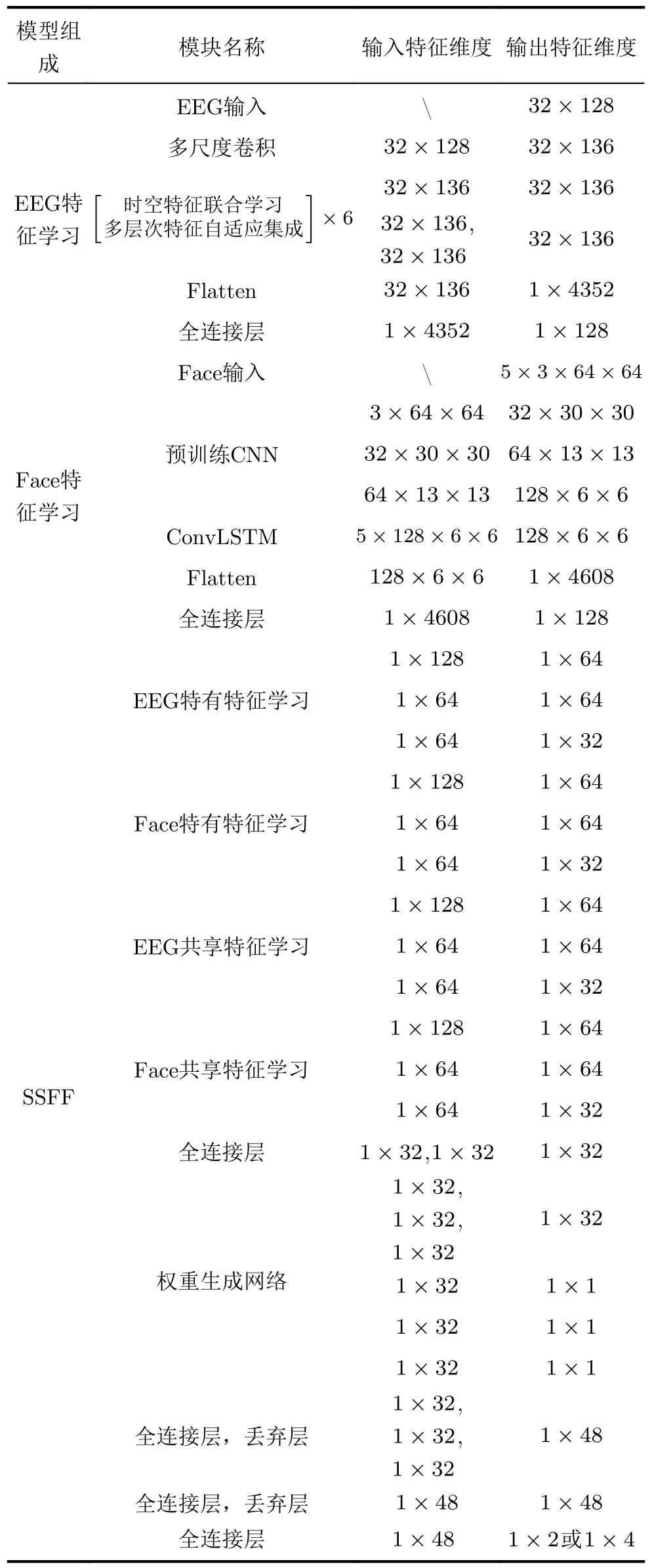
表2 提出模型的详细结构参数
4 实验与结果分析
4.1 数据集及预处理
本研究基于DEAP数据集[37]和MAHNOB-HCI数据集[38]展开实验,下面简要介绍这两个数据集。
DEAP数据集:包含来自32名受试者在观看40个持续时间为63 s的视频时产生的多模态信号。所有受试者被要求在观看视频后以1到9的连续值标记所观看视频的效价值 (Valence)、激活度 (Arousal)、支配度(Dominance)、喜好度(Liking)和熟悉度(Familiarity)等5个维度的数值大小。其中,共有22名受试者的脑电信号、外周生理信号和人脸图像被记录。
MAHNOB-HCI数据集:包含30名受试者在观看20个持续时间为35 s~117 s不等的视频时采集到的脑电信号、外周生理信号以及人脸图像信号。观看每个视频后,受试者使用自我评估量表以1到9的离散值对他们感知的Valence, Arousal,情感标签(Emotional label/tag), Dominance和可预测性(Predictability)等5个维度的数值打分。
对于DEAP数据集,使用其中22名受试者的数据用于实验;对于MAHNOB-HCI数据集,使用其中27名受试者的数据用于实验。许多研究表明[10–12],在处理脑电相关任务时,使用较短的实验数据相较于使用完整实验数据更具实际应用的意义。同时,考虑到DEAP和MAHNOB-HCI数据集中实验数据的限制,与其他工作一致[14,37],将每个实验样本分割为不重叠的1秒的数据片段,用于模型训练。其次,两数据集的EEG信号都采用Python完成预处理,包括平均参考、4~45Hz滤波、降采样和伪影去除等操作,并使用前3s数据的平均值作为基线信号,用于每个EEG信号样本的基线去除,即
其中, EEGi用于表示原始EEG信号, EEGn用于表示第n秒的EEG基线信号, EEGo表示经过基线去除的EEG信号。
对于人脸视频信号,为与EEG信号对齐并避免过多冗余信息,每秒提取5张人脸图像,并对每张图像采用人脸检测、裁剪、对齐等预处理方式,最后统一调整为 64×64分辨率。
4.2 实验设置
提出模型基于深度学习框架PyTorch架构完成搭建,所有的实验都是在配置为Intel(R) Core (TM)i9-10900K CPU @ 3.70GHz, GeForce RTX 3 080 GPU的服务器中实现。在训练过程中,采用Adam算法作为优化器,并以0.000 1的学习率训练模型。与先前工作一致[10–12,14],以5为阈值,将Arousal和Valence划分为高、低两种状态,用于2分类。其次,还采用情绪环形模型得到Emotion类别,包含高激活值-高效价值(HA-HV),高激活值-低效价值(HA-LV),低激活值-高效价值(LA-HV),低激活值-4类。对于2分类,采用二元交叉熵损失作为损失函数;对于4分类,采用交叉熵损失作为损失函数。因此,最终用于训练的损失函数为
其中,α,β分别为各损失函数的权重系数,Lt为二元交叉熵损失函数或交叉熵损失函数。
4.3 实验结果及分析
为了全面地展现提出模型的性能,在DEAP和MAHNOB-HCI数据集上采用了跨实验验证、5折交叉验证两种验证方法。对于跨实验验证,将每个受试者的实验数据划分为训练集、测试集两种。在DEAP数据集中,每个受试者样本包含40次实验,将20次实验对应的实验数据作为训练集,其余实验对应的数据用于测试集;对于5折交叉验证,将所有受试者的实验数据用于实验,并划分为5份。每次训练时使用其中的1份数据用于测试,其余数据用于训练。
为了展现提出模型的有效性,表3展示了提出模型在DEAP和MAHNOB-HCI数据集上与其他方法的对比结果。其中,标有*的数值是复现的结果,标有λ代表该工作采用10折交叉验证方法。对于跨实验验证方法,提出模型在DEAP数据集中的Valence, Arousal以及Emotion 3个类别上分别实现了82.60%, 83.09%和67.50%的准确率,而在MAHNOB-HCI数据集中的Valence, Arousal以及Emotion 3个类别上分别实现了79.99%, 78.60%和62.42%的准确率,相较于对比的工作实现了最优的结果。
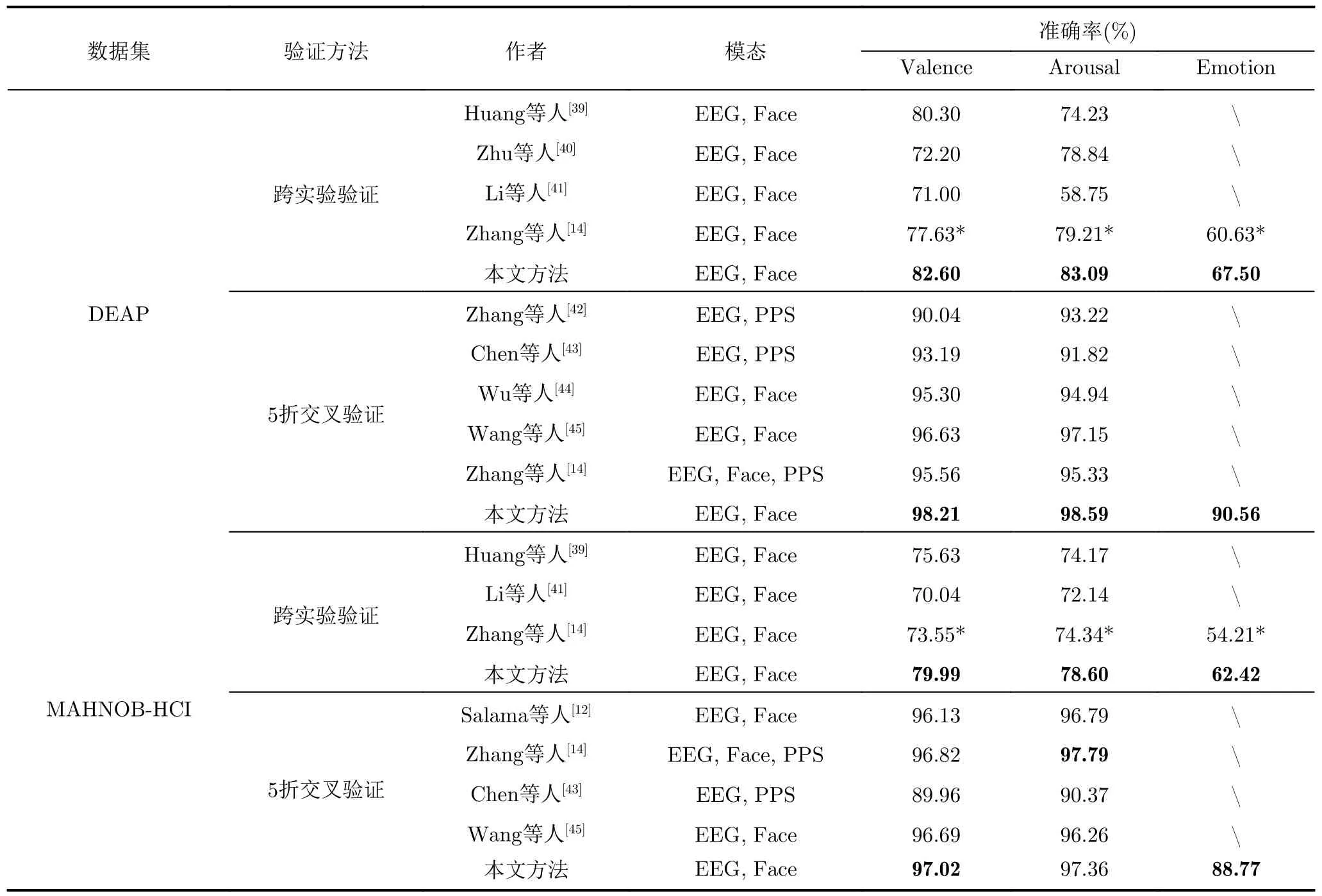
表3 提出模型与其他方法的性能对比
对于交叉验证方法,提出模型在DEAP数据集中的Valence, Arousal以及Emotion 3个类别上分别实现了98.21%, 98.59%以及90.56%的准确率,而在MAHNOB-HCI数据集中的Valence, Arousal以及Emotion3个类别上分别实现了97.02%, 97.36%和88.77%的准确率,仅在MAHNOB-HCI数据集的Arousal类上性能略低于Zhang等人[14]的工作。这是由于Zhang等人[14]的工作加入了外周生理信号,具备更为丰富的多模态信息。同时,提出模型在MAHNOBHCI数据集中的Valence类别上性能优于Zhang等人[14]的工作,这可以看出提出模型相较于其他方法仍然具有显著的竞争力。
同时,为了更清晰地展示提出模型的性能,还给出了提出模型在DEAP和MAHNOB-HCI数据集上各个受试者的准确率,如图5所示。在DEAP数据集上,提出模型在各个受试者上的Valence,Arousal以及Emotion 3个类别上的最低准确率分别为64.83%, 73.42%, 53.67%,最高准确率分别为93.58%, 94.50%, 85.17%。在MAHNOB-HCI数据集上,提出模型在各个受试者上的最低准确率分别为59.02%, 41.76%, 38.37%,最高准确率分别为95.53%, 92.77%, 78.95%。
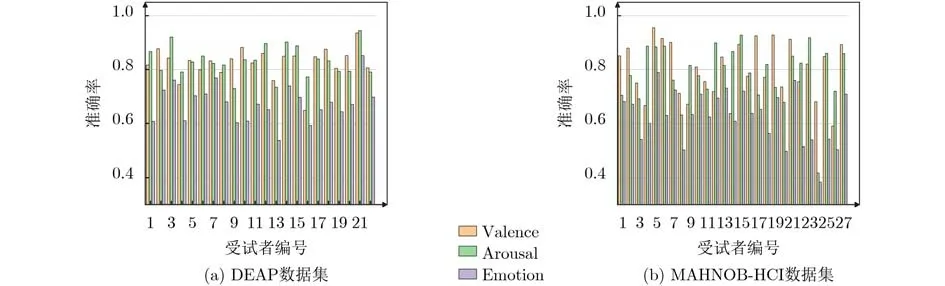
图5 所用数据集中各个受试者的准确率
此外,还计算了提出模型在DEAP和MAHNOBHCI数据集上Valence, Arousal以及Emotion 3个类别的实验数据方差。其中,在DEAP数据集上的方差分别为0.003 3, 0.003 10, 0.004 9,在MAHNOBHCI数据集上的方差分别为0.010 4, 0.012 0, 0.009 5。综合比较两数据集的实验结果,可以看出,提出模型在DEAP数据集上各个受试者的性能相较于MAHNOBHCI数据集表现得更为稳定,这可能是因为DEAP数据集中每个受试者包含的实验样本更为丰富,有助于模型充分学习更具显著性的情感语义特征。同时,DEAP数据集中每个实验对应的数据样本相对均匀,减小了模型在训练过程中受到类别不均衡问题的影响,进而提高了性能的稳定性。
4.4 消融实验
为了进一步分析提出模型各个模块对于模型性能的影响,基于DEAP数据集采用跨实验验证方法开展了全面的消融实验。
4.4.1 各模态对模型性能的影响
为了研究各模态对模型性能的影响,表4展示了仅使用EEG信号或人脸图像信号作为输入时的模型性能。值得注意的是,并没有直接去除SSFF模块,而是采用双分支结构完成各模态信号的特有特征和共享特征的学习。可以发现,仅使用EEG信号的模型性能优于仅使用人脸图像信号的模型性能,而这两种单模态方法的模型性能均低于双模态方法的模型性能。这说明了EEG信号与人脸图像信号的结合包含更为丰富的语义信息,使得双模态模型相较于单模态模型能具有更好的性能表现。
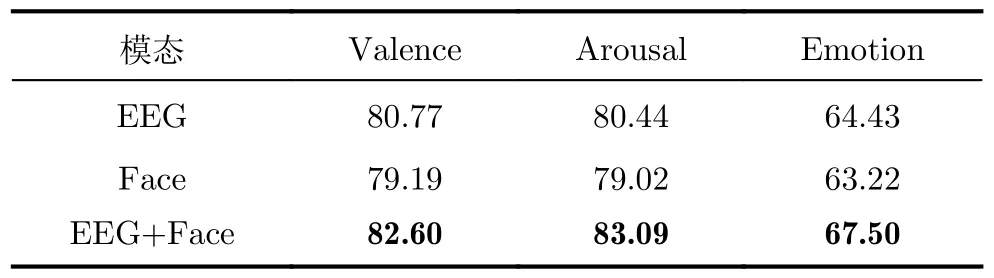
表4 DEAP数据集上不同模态配置对模型准确率的统计结果(%)
4.4.2 AIMSTF模块对模型性能的影响
为说明AIMSTF模块的有效性,还消融了AIMSTF模块中的各个组件,并设计两组实验分别用于说明AIMSTF层数、AIMSTF各组件对模型性能的影响。
如图6(a)所示,随着AIMSTF模块的层数的上升,提出模型的性能随之变化,并在层数为6时取得最佳效果。当AIMSTF的层数为0时,模型性能欠佳,这是由于AIMSTF模块的缺失,模型不能充分学习到EEG信号的时空特征,导致EEG特征的表征能力不足。而AIMSTF层数为4~6时,模型性能表现较佳。这是由于在提出模型中,每一层的AIMSTF模块都集成了先前层次的所有特征,自适应地捕捉EEG模态在特征学习过程中各层次中相对重要的特征,生成更具显著性的情感语义特征,从而提高模型的性能。对于Arousal类别,层数为6时,模型性能尽管略低于层数为5时的结果,但是在Valence和Emotion类别上表现得更出色。因此,本文最终将模型中AIMSTF模块的层数设置为6。
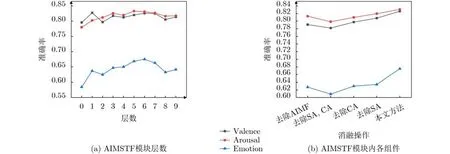
图6 在DEAP数据集上AIMSTF模块对模型性能的影响
此外,对AIMSTF各个组件的消融均导致了模型性能的下降,如图6(b)所示。AIMF模块的去除,使得模型无法捕捉先前层次中相对重要的特征;自注意力的去除,使得模型对EEG信号内部时间关系的建模能力降低;通道注意力的去除,使得模型对EEG信号的通道间关系捕捉能力下降。
4.4.3 SSFF模块对模型性能的影响
我们开展了一系列消融实验,用于研究SSFF模块的各组件对模型性能的影响(表5)。值得注意的是,在去除SSFF模块的实验中,将两模态特征向量直接拼接完成特征级融合。实验结果表明,去除SSFF模块的模型性能最差。同时,仅包含共享特征学习分支的模型性能略微优于仅包含特有特征学习分支的模型。这是因为相较于仅包含特有特征学习分支的模型,仅包含共享特征学习分支的模型引入了CMD,这一做法有助于约束EEG模态和人脸图像模态之间的特征分布差异,从而带来更优的性能。其次,权重生成网络的去除导致了模型性能的下降,这是由于不同特征对于最终预测结果的贡献度不同,而权重生成网络可以完成各模态特征之间的信息交互,并基于可学习参数矩阵自适应地生成各特征对应的权重,给予相对重要的特征以更高的权重,促使模型性能得到提高。
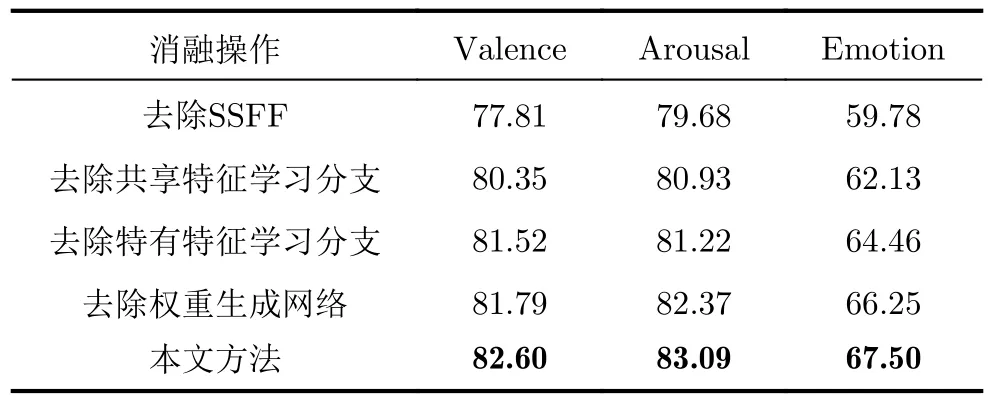
表5 DEAP数据集上SSFF模块消融实验结果(%)
除此之外,无论是SSFF模块的去除还是SSFF模块中特有特征学习分支、共享特征学习分支的去除,都导致了模型性能的下降。这说明了SSFF模块也有助于提升模型的性能,通过特有特征学习分支和共享特征学习分支的结合使得模型可以有效学习到各模态的特有特征以及模态间的共享特征,实现对EEG特征与人脸图像特征之间的语义一致性和互补性的捕捉,使得模型最终在Valence, Arousal以及Emotion 3种分类任务上均带来良好的性能表现。
4.4.4 损失函数对模型性能的影响
如表6所示,通过消融实验评估了模型训练过程中使用的不同损失函数对最终分类结果的影响。结果表明,Ld或Ls的去除都对模型在Valence, Arousal以及Emotion 3种分类任务上的性能产生了不同程度的影响,这表明了Ld与Ls在模型训练过程中的关键作用。具体而言,Ld的最小化降低了各分支生成特征之间的语义相似度,增大了特征之间的语义信息差异,从而有助于有效捕获 EEG 信号与人脸图像中的特有特征;另一方面,Ls的最小化使得两种模态的共享语义信息的分布更为相似,促使模型有效地学习到EEG信号与人脸图像之间的情感语义共享特征。
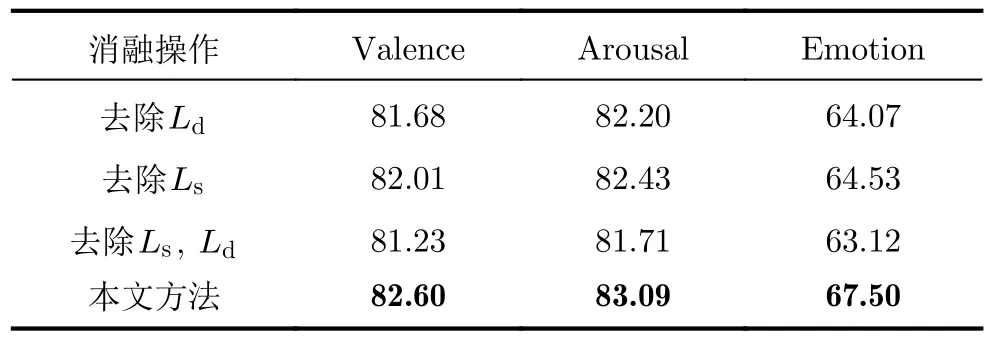
表6 DEAP数据集上模型训练所用损失函数消融实验结果(%)
4.5 可视化分析
为了更直观地展现提出模型的有效性,图7展示了模型在DEAP数据集和MAHNOB-HCI数据集上采用5折交叉验证时得到的t-SNE可视化图。
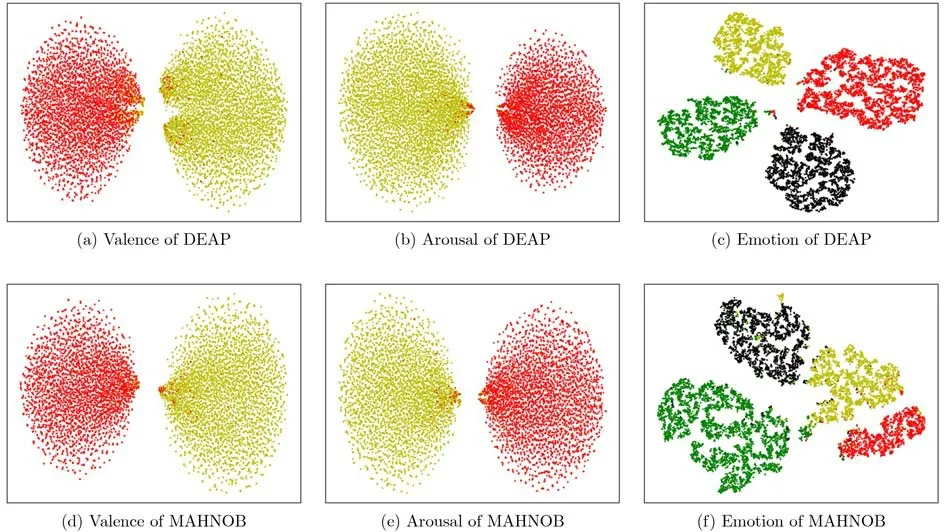
图7 在DEAP和MAHNOB-HCI数据集上利用5折交叉验证时提出模型产生的t-SNE可视化图
具体来说,采用t-SNE方法可视化提出模型最后1层或倒数第2层的特征。可以看出,提出模型有效地完成了Valence, Arousal以及Emotion 3种分类任务。对于Valence, Arousal分类任务,t-SNE方法将特征有效地分为了两个类别;对于Emotion分类任务,特征被清晰地为4类。由于数据集质量的影响,DEAP数据集相较于MAHNOB-HCI数据集包含更多的样本数,同时样本分布更为均匀。因此,提出模型在DEAP数据集上的分类效果要优于MAHNOBHCI数据集。
5 结束语
本文提出了多层次时空特征自适应集成与特有-共享特征融合的模型,用于脑电和人脸图像的双模态情感识别。在该模型中,首先提出了多层次时空特征自适应集成模块,通过双流结构学习EEG信号的时空特征,然后利用多层次特征之间的相似度计算各层次特征权重,并采用门控机制对集成的多层次特征与当前层次特征进一步处理,使得模型可以自适应地捕捉EEG特征中相对重要的特征,获得更具显著性的情感语义特征。此外,还提出了特有-共享特征融合模块,结合损失函数与特有特征学习、共享特征学习两种方式来联合学习情感语义特征,旨在实现EEG特征和人脸图像特征所含情感语义的一致性和互补性,缓解了特征学习过程中由于EEG特征和人脸图像特征之间的语义鸿沟问题所导致的多模态表征能力欠佳的问题。在DEAP数据集与MAHNOB-HCI数据集上的大量实验及其分析可以看出,提出模型能够有效地实现EEG信号和人脸图像的双模态情感识别。在未来的研究工作中,可以对EEG信号的特征学习采用预训练的方式,并考虑加入外周生理信号以进一步增强情感识别的性能;其次,还可以考虑如何实现基于EEG信号与人脸图像的实时情感识别模型。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
开放教育研究(2020年2期)2020-03-31 01:54:14
动漫星空(2018年9期)2018-10-26 01:17:14
现代语文(2016年21期)2016-05-25 13:13:44
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
发明与创新(2015年33期)2015-02-27 10:40:09
大连民族大学学报(2015年2期)2015-02-27 08:28:11
奇闻怪事(2014年5期)2014-05-13 21:43:01
计算物理(2014年2期)2014-03-11 17:01:39
