
基于改进Transformer 的锂电池剩余寿命预测
2024-03-15 12:17:24朴博晖彭俊荣杨一鹏王晓海
船电技术 2024年2期
朴博晖,彭俊荣,杨一鹏,别 瑜,王晓海
(武汉船用电力推进装置研究所,武汉 430064)
0 引言
随着电力电子和新能源技术的快速发展,锂离子电池在工程上得到了广泛的应用。然而,随着充放电周期的增加,容量通常会降低,如果无法准确预测电池剩余寿命,便无法保证产品的安全性等其他方面。因此,锂电池寿命的准确预测至关重要。
在预测RUL 时,RVM[1]等机器学习模型和MLP 等深度学习模型被广泛应用。然而针对锂电池数据呈现序列结构且具有强时间关联性的特点,基于循环神经网络(RNN)的多种模型都表现出了良好的性能,包括GRU[2]和LSTM[3]等,针对长序列Transformer[4]更具竞争力。但目前仍然存在以下两个问题:基于RNN 的网络以循环的方式对序列数据进行建模,由于长期依赖会导致性能下降;上述方法将原始数据直接输入网络模型,但原始数据大多带有较强的噪声,导致预测结果不准确。
本文基于Transformer 设计了一种全新的网络结构,在两个数据集下针对本文模型和其他基准模型进行了实验,并验证了模型的可行性和准确性。本文提出的方法对于锂电池RUL 预测具有一定的指导意义。
1 p-Transformer
本文主要对锂离子电池剩余使用寿命的预测方法进行研究,提出了一种全新的模型p-Transformer,在Transformer 的前面添加了前置编码器,其架构如图 1 所示。首先简要介绍Transformer 模型原理,而后介绍改进部分的前置编码器。

图1 p-Transformer 网络结构示意图
1.1 Transformer
Transformer 由具有多层结构的编码器和解码器组成,且每层都包括一个多头自注意力(Multi-Head Self-Attention)和一个前馈神经网络(Feedforward Neural Network, FNN)子层。编码器将输入序列映射到高维,而后将其馈送到解码器生成输出序列。由此,可以从电池历史数据中学习容量退化的长期依赖关系。
多头自注意力机制将单个自注意力机制拆分为多个子空间,并在每个子空间上执行自注意力机制,从而更好地捕捉不同层次的特征。具体来说,将输入序列和上下文向量分别转换为h组查询(Query)、键(Key)和值(Value)[5],得到h组注意力矩阵A1,A2,...,Ah,经拼接得到增广矩阵AεRn×hd,然后通过线性变换转换为最终加权和向量CεRn×d。
其中,Selfattention表示单个自注意力机制,Concat表示拼接操作,分别表示第i组查询、键和值的权重矩阵,0W表示线性变换的权重矩阵。令(Hi) =(Q,K,V)。
前馈神经网络子层由两个线性变换和一个激活函数组成,其中第一个线性变换将输入向量转换为一个中间表示向量,第二个线性变换将中间表示向量转换为最终表示向量。具体来说,将输入向量x在FNN 子层中表示为:
则可由Hi当前得到下一个预测结果Hi1+:
1.2 前置编码器
锂电池原始输入数据具有一定程度的噪声,且在进行充放电时更为明显。在大多数方法中,原始数据不做任何处理直接输入网络,其中的噪声数据会严重影响预测精度。为了保持稳定性和鲁棒性,输入数据在进入网络前需经过去噪处理。预处理前置编码器将高维特征编码为低维特征,进行数据压缩降维并提取深层非线性特征,而后经过解码器去除噪声并对原始数据进行重构。模块结构如图2 所示。

图2 前置编码器简易结构图
为了减少输入数据的分布变化对网络的影响,需要对数据进行归一化处理。设C0为额定容量,x={x1,x2,...,xn}表示长度为n的输入序列,将其映射到(0,1],即:
其中,W、b、f和y分别表示前置编码器输出层的权重、偏置、激活函数和输出。
其中:W'、b'、f'和分别表示前置解码器输出层的权重、偏置、映射函数和输出。
在该前置编码器网络中,ReLU 和Sigmoid函数分别作为编码器和解码器的激活函数。目标函数定义如下:
结合前述过程,通过数据输入归一化、去噪降维并经过Transformer 层,得到最终目标函数(11),通过训练使损失函数误差最小,得到模型结果。
给定h个注意力机制层,将最后一个单元(cell)学习到的结果映射为Transformer 的预测:
其中,Wpre、bpre、f和Hh分别表示预测层的权重、偏置、映射函数和输入。
2 评价指标
为了从多角度对模型性能进行评估,本文基于Park 等人[6]的研究,选择了相对误差(Relative Error, RE)、均方根误差(Root Mean Squared Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)三种评价指标,定义如下所示:
3 实验及结果
3.1 实验环境
本文使用锂电池领域认可度较高的两个公共数据集NASA[7]和CALCE[8]。其中,NASA 包含四种不同锂离子电池的数据,每个电池重复充电、放电和阻抗测量三种操作。
实验环境为:Python3.7、Pytorch1.8.0 和Windows 下i7 处理器。模型可变参数包括:学习率lr、自注意力层数L、隐藏层大小h和任务比重a。通过反复实验确定在该实验环境下,最优参数为:
3.2 实验结果
在同样的数据集、实验环境和模型参数的情况下,实现了以下基准方法的锂电池RUL 预测,并与本文的模型进行了比较,结果如表1 和表2所示。下表列出了所有方法的三重指标数值,并标注了最优结果,其中RE、RMSE 和MAE 分别代表相对误差、均方根误差和平均绝对误差。

表1 NASA 数据集下多种模型的评价结果

表2 CALCE 数据集下多种模型的评价结果
此外,为了探究前置编码器的去噪效果,在相同实验环境下,将无前置编码器的模型与p-Transformer 进行对比,结果如图3 和图4 所示:

图3 NASA 数据集下,无前置编码器与p-Transformer的对比结果
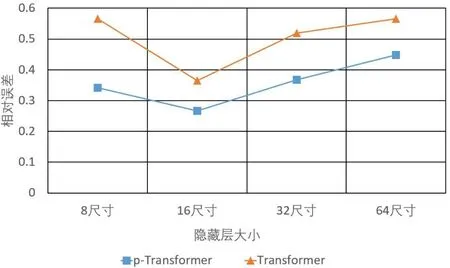
图4 CALCE 数据集下,无前置编码器与p-Transformer的对比结果
3.3 结果分析
从表1和表2可以看出,本文的模型实验效果相对最好。该模型能够从锂电池序列中提取有价值的信息,且该模型具有稳定性和鲁棒性。
与GRU相比,本文模型在NASA数据集下的均方根误差较大,最可能的原因是两个数据集的序列长度不同。GRU比Transformer比更擅长从短序列中学习特征,这也是Transformer的不足。此外,由图5和图6可以看出,在Transformer网络基础上加入前置编码器进行去噪,可以得到更好的性能,这是由于前置编码器去除了大部分原始数据的噪声信号,使得预测结果与真实数据更为接近,误差更小,从而更准确地预测锂电池的RUL。
4 结论
本文提出了一种基于Transformer 的优化模型预测锂电池RUL,模型通过前置编码器对输入数据进行去噪并降维压缩,而后利用Transformer网络学习容量衰落的特征。与其他基准方法相比,本文提出的模型可以较低的相对误差、均方根误差和平均绝对误差得分较为准确地预测锂电池RUL,性能更加优秀。本文所做研究对于锂电池RUL 预测具有一定的参考意义。在后续研究中,可以针对去噪问题设计性能更好的模型结构。此外,针对电池数据序列长短不一的问题,可以设计算法黑盒来适应不同长度序列的锂电池数据。
猜你喜欢
中国生殖健康(2020年5期)2021-01-18 02:59:52
教书育人(2020年11期)2020-11-26 06:00:32
当代陕西(2020年13期)2020-08-24 08:22:02
中国生殖健康(2018年5期)2018-11-06 07:15:42
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电源技术(2016年2期)2016-02-27 09:04:52
电子器件(2015年5期)2015-12-29 08:42:24
电源技术(2015年7期)2015-08-22 08:48:22
电测与仪表(2014年13期)2014-04-04 12:04:18
