
基于虚拟目标制导的自适应Q学习路径规划算法
2024-03-13 05:45李子怡胡祥涛张勇乐许建军
计算机集成制造系统 2024年2期
李子怡,胡祥涛,张勇乐,许建军
(安徽大学 电气工程与自动化学院,安徽 合肥 230601)
0 引言
作为智能移动机器人关键技术之一,路径规划长期以来一直是十分活跃的研究领域,被国内外学者广泛关注[1-4]。路径规划问题描述为:在路径长度、连续性以及实时性等约束条件下,找到一条从当前位置移动到目标位置的最优无碰撞路径[5-6]。根据移动机器人已知工作环境信息的程度,路径规划问题分为[7-8]全局路径规划和局部路径规划。全局路径规划也称为离线规划,指根据完全已知的环境先验信息建立静态全局地图,再基于全局地图从起始位置到目标位置规划出最优路径[9]。常见的全局路径规划方法可以分为4类[10],即基于图搜索的规划方法(以A*及D*[11]和可视图方法[12]为代表)、基于随机采样的规划方法(以快速搜索随机树(Rapidly-Exploring Random Trees,RRT)及其改进方法[13-15]为代表)、智能搜索方法(以遗传算法[16]、蚁群算法[17-18]为代表)、人工势场法[19-20]。全局规划方法对环境先验信息的依赖性较强,在实际任务中,机器人更多面对的是未知环境,常规全局路径规划方法不适用,因此越来越多的学者关注局部路径规划方法。
局部路径规划描述为移动机器人在探索未知环境过程中,通过传感器获取周围环境信息,进行增量计算后得出下一节点,从而逐步获得一条无碰撞最优路径[7]。局部路径规划不受环境先验信息影响,对未知环境具有更强的适应性和实时性,在智能移动机器人路径规划中更被青睐[21-22]。局部路径规划算法主要分为避障规划类算法(动态窗口法[23]、BUG类方法[24])和强化学习方法[25-27]。不同于避障规划类算法,强化学习算法通过对环境进行交互式试错学习,得到一个从初始状态到目标状态最优的行动策略[28-30]。因此,面对复杂未知环境,强化学习算法的适应性最好,在移动机器人路径规划中表现优异[7,31]。
在移动机器人路径规划算法中常采用的强化学习方法是Q学习(Q-learning)算法[8,21]。宋勇等[20]提出将人工势场引入经典Q学习,根据先验信息构造势能场初始化Q表,提高了Q学习的收敛速度,但对初始化Q-Table需要环境先验信息,不适用于未知环境;LOW等[1]将花授粉算法(Flower Pollination Algorithm, FPA)引入Q学习,由FPA取得先验知识初始化Q表,加快了Q学习算法收敛,但不适用于未知环境;田晓航等[32]将蚁群算法引入Q学习,提出一种寻优范围优化方法,减少了智能体的无效探索次数,然而算法中信息素机制对Q表的编码方案需要环境先验信息,不适用于未知环境;CHEN等[33]针对凹形地形问题提出融入障碍区扩展思想的改进算法,避免智能体因进入凹形障碍物区域而产生无效迭代,然而算法仍需对凹形障碍区进行大量探索,以分辨障碍物和智能体的位置关系;GUO等[34]提出将模拟退火(Simulated Annealing,SA)算法引入Q学习平衡探索和利用的关系,加快了算法的收敛速度,虽然SA算法不完全拒绝恶化解的特性能够避免移动机器人陷入局部最优区域,但是其自身存在超参数设置问题,增加了计算的负担;LI等[10]在Boltzmann Q学习的基础上引入启发搜索策略,避免了局部最优的情况,提高了算法收敛速度,然而玻尔兹曼策略在每一次选择动作后都需要进行大量计算,当状态集较大时会带来更多计算量,影响收敛速度;LI等[35]在Q学习基础上引入自适应探索策略,提出AE Q-learning算法,在一定程度上缓解了探索和利用的冲突,加快了算法收敛速度,然而该方法有较多超参数,不利于方法迁移,具有较强的主观性;WANG等[36]在Boltzmann Q学习的基础上引入经验重载,提出Backward Q-learning算法,该方法在每次成功达到终点后重新计算成功路径的Q值,每次重载路径并计算的代价较大,算法在极大提高收敛性和算法稳定性的同时牺牲了效率,而且算法受状态—动作空间维度的影响极大。
综上所述,在经典强化学习领域内,学者们主要从融合智能算法、探索策略改进[37-39]两方面对Q learning进行改进。融合智能算法类表现在对状态集进行编码及对Q表初始化的改进上,使算法尽量掌握环境的完备信息,缩小了Q学习的适用范围,该改进方法不适用于环境信息不完备的未知环境;探索策略改进类主要表现在引导策略方法对奖励值设置的改进和对智能体动作选择策略上的改进,这类改进加快了算法收敛效率且未增加对先验信息的要求。这些改进虽然成功应用于路径规划并表现优异,但是仍然存在3个局限性:①收敛速度慢,且随着地图规模的增大,状态变量增多,计算效率下降;②算法鲁棒性有待进一步提升;③面临特殊环境时,机器人容易陷入地形陷阱。针对上述问题,本文在经典Q学习算法基础上,设计了双重记忆机制、虚拟目标引导方法、自适应贪婪因子,提出基于虚拟目标制导的自适应Q学习算法(Adaptive Q-learning algorithm based on Virtual Target Guidance,VTGA-Q-Learning),并通过对比实验验证了算法的有效性,实现了移动机器人在未知环境下的路径规划。
1 虚拟目标制导的路径规划问题与描述
1.1 学习算法
Q学习算法是一种基于值函数的强化学习算法,其核心是Q表的设计与更新。Q表建立了“状态动作对”(s,a)与Q(s,a)的映射。按照Q学习算法,智能体基于当前状态st从Q表中选择动作at,然后环境反馈相应回报Rt+1,利用式(1)计算该状态动作对的价值Q(st,at),并更新Q表中的Q(st,at)值,以此作为下一状态选择最优动作的依据。
Q(st,at)←Q(st,at)+
(1)
式中:st为t时刻智能体的状态,st∈S,S为智能体有限状态集合;at为t时刻智能体的动作,at∈A,A为智能体有限动作集合;Rt+1为智能体在状态s下选择动作a所获的即时奖励;α为学习率,α∈(0,1);γ为折扣率,γ∈(0,1)。
1.2 路径规划模型
将Q学习算法用于移动机器人路径规划问题,需要分别对机器人所处的环境、状态集、动作集、价值函数进行定义和建模。
1.2.1 环境建模
本文采用格栅法建立移动机器人环境模型。格栅法用网格等分整个环境,将自由区域标记为0,障碍物标记为1,格栅图中的障碍物(obstacle)、智能体起点位置(start)、智能体终点位置(goal)、自由空间(freedom)如图1所示。

1.2.2 状态集和动作集
本文将移动机器人的状态描述为格栅中心坐标(x,y),每个栅格为一个状态。由于为未知环境,状态集的大小依赖机器人探索得到。随着地图规模的增大,状态集的规模随之增大,导致Q表的维护成本增加。
动作集的设置方式一般有四邻域和八邻域两种,如图2所示。四领域只有上、下、左、右4个动作,移动机器人在每个状态下选择其中一个动作执行;八领域有8个动作,规划出的路径相对平滑,但会降低算法收敛速度。本文所有Q学习算法都采用四邻域状态集,不影响本文的算法性能验证和对比分析。

1.2.3 奖励函数
奖励函数会影响智能体的收敛和探索周期,在常规Q学习算法中,设置奖励函数
(2)
式中将智能体所处的状态分为Sgoal,Sobstacle,Sfreedom3类,分别对应目标点、障碍物、自由空间,Q学习算法根据状态分类给予相应奖励。
2 算法改进设计
常规Q学习算法在处理未知环境下移动机器人路径规划问题时,存在收敛速度慢、鲁棒性差、盲目性和地图陷阱等问题,本文设计了3种机制以改善Q学习算法性能。
2.1 双重记忆机制
2.1.1 障碍物记忆机制
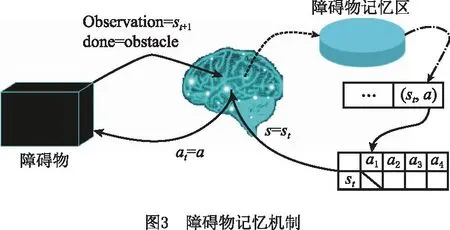
在Q学习中,智能体需要不断同环境进行交互学习,经过一段时间学习后,Q表中指向障碍物的动作的奖励值会小于其他动作的奖励值,因此智能体可以根据Q表选择最佳动作避开障碍物。然而在学习过程中,智能体需要平衡探索和利用的关系,即智能体的动作选择不完全依赖Q表,而是以一定概率随机选择一个动作,以加强对未知地图的探索开发。因此在探索期间,智能体仍会高频选择指向障碍物的动作,从而产生无效迭代,降低了探索效率。为此,本文设计了障碍记忆机制对障碍物进行一次学习,克服了Classic-Q-Learning对障碍物迭代学习过程中因随机策略而产生无效迭代的问题。
如图3所示,障碍记忆机制设计可描述为:智能体在状态st采取动作at时,如果观测到下一位置为障碍物,则将动作状态对(st,at)存储到障碍物记忆区中,并将障碍物记忆区内的动作状态对被选择的概率置0,以杜绝智能体随机探索时的无效迭代,提高探索的有效性;另外,因为本文算法面对的是未知环境,所以将Q表设置为动态创建而不是初始化为固定大小的Q表。
2.1.2 短时记忆机制


为了解决地图陷阱问题,本文提出短时记忆机制。该机制首先定义短时记忆区间T-M(如图5),用于存储智能体连续的5个状态行为对,然后通过查询T-M内是否存在{st,st+1}∈{st-3,st-2,st-1}来判断智能体是否陷入地图陷阱。当陷入地图陷阱时,禁止选择链接st,st+1的动作,智能体随机选择其他动作,从而跳出地图陷阱。

2.2 虚拟目标引导方法
不同于蒙特卡洛方法利用一次实验的经验平均来估计当前值函数,Q学习利用策略采样获得后继状态的值函数来估计当前状态的值函数。对采样数据的利用效率深刻影响着值函数迭代,而且Q学习存在探索效率低下的问题。虚拟目标引导方法从经验区M中筛选出不同重要程度的状态集,再从该状态集中获取状态作为阶段性虚拟目标,并设置虚拟奖励,通过虚拟奖励使智能体学习到虚拟目标作为辅助节点的价值,引导机器人更高效地到达真实目标。
通过虚拟目标引导方法从经验区M中筛选出3级重要数据表层经验(Surface Experience,SE)、深层经验(Deep Experience,DE)、贪婪经验(Greedy Experience,GE),如图6所示。表层经验指在历史实验数据中,根据式(3)筛选出比序列整体优秀的状态—动作对;深层经验指在表层经验中,根据式(4),通过加权平均的方法求出截止当前实验序列确定的状态价值,反映了过往经验中该状态的相对价值随实验数据的增加而趋近于真实状态价值;贪婪经验指在深层经验中,根据式(5)贪婪选取深层经验中状态价值最大的状态,从而筛选出历史数据中较为重要的序列节点。

(3)
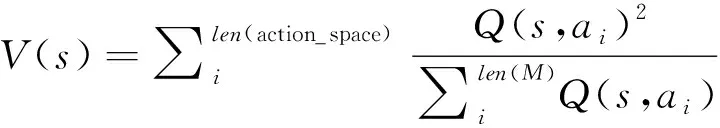
(4)
(5)
式(2)给出了常规Q学习算法的价值函数计算方法,这种设置方法在地图规模不大时相对适用。当地图规模较大时存在稀疏奖励问题,导致智能体盲目探索,算法难以收敛。同时,为了改善强化学习存在的稀疏奖励问题,在完成虚拟目标选择后,分别赋予不同分区中的状态不同的动态价值,该思路可描述为:对贪婪经验中的状态给予高激励,深层经验中的状态给予中激励,浅层经验中的状态给予较低激励。本文的动态奖励函数设置如下:
(6)
Dy_R(st)=
J(st)·F(st)+w·E(st)+R1;
(7)
(8)
(9)
式中:Dy_R(st)为动态奖励函数;J(st)为一个二值函数,用于限制在{表层经验;深层经验;贪婪经验}中的状态只能被动态奖励额外奖励一次,以防过度奖励造成收敛弥散;count[st]为标志数组,用于存储被动态奖励附加奖励的状态;w∈(0,0.1)为常权重参数;E(st)为历次实验中,状态st到{表层经验;深层经验;贪婪经验}中的次数。
2.3 自适应贪婪因子
常规Q学习算法采用贪婪策略虽然在一定程度上平衡了探索和利用,但是贪婪因子ε为固定值,ε值的设计极大影响了对未知地图的探索利用能力,固定的贪婪因子使智能体的探索性始终保持不变,这不利于算法收敛,使算法存在较大波动,且使超参数设计存在主观性;调整贪婪因子应随探索程度的提高而衰减,合理的贪婪因子应随智能体的探索经验动态调整。针对以上问题,本文提出自适应贪婪因子。
自适应贪婪因子根据智能体同环境的交互程度以及由探索经验估计的环境复杂程度进行自行调整,并将学习阶段分为探索阶段、随机探索利用阶段、利用阶段3个阶段,从而提高算法的收敛速度和稳定性,更好地平衡探索和利用的矛盾,同时摆脱了超参数设计的困扰。本文定义自适应贪婪因子
ε=tanh((|xstart-xgoal|+|ystart-ygoal|)·
(10)

自适应贪婪因子根据智能体与环境的交互程度主动调整贪婪因子,对学习阶段进行划分,逐步增加智能体对已有知识的利用,从而提高算法的收敛性和稳定性,更好地平衡探索和利用的矛盾。
3 基于双重记忆机制的自适应Q学习算法流程
基于上述改进,将双重记忆机制、虚拟目标引导方法、自适应贪婪因子融入常规Q学习算法,提出VTGA-Q-Learning,其流程如图7所示,具体步骤如下:

步骤1初始化学习率α、衰减系数γ、贪婪因子ε;设置最大幕数episode、常权重参数w、障碍物记忆区、短时记忆区、虚拟奖励学习步长C、经验池容量M,以及起点和终点。
步骤2设置初始化参数后,智能体同环境进行交互(超过最大幕数则终止),用自适应贪婪因子(式(10))对ε调整后,根据动作选择机制获得下一时刻的状态观测值(observation)、奖励值(reward)和结束标志位(done)。
步骤3判断是否陷入地图陷阱,是则返回步骤2,否则执行步骤4。
步骤4每隔C步从经验区M中抽取虚拟目标,并由式(7)设置虚拟目标奖励。
步骤5根据式(1)更新Q表,将[st,at,r,observation]加入M中。
步骤6更新幕数并对done进行判断。如果done=goal,则更新到达目标点的次数,转步骤2;如果done=obstacle,则将状态observation加入障碍物记忆区间,转步骤2;如果done=free,则执行步骤7。
步骤7更新状态s=observation,转步骤2。
因为VTGA-Q-Learning面对未知环境,所以状态集未知。因此在Q表的创建上,动态创建Q表而非创建固定维度的Q表(智能体同环境交互获得观测数据后查询Q表,判断当前状态是否为新状态,是则扩展Q表)。图7中的动作选择机制的步骤描述如下:
步骤1输入st,at-1,ε。
步骤2判断当前状态是否存在Q表中,是则执行步骤3,否则在Q表中创建新行后执行步骤3。
步骤3判断当前状态是否在障碍物记忆中,是则根据式(11)选择动作,否则根据式(12)选择动作。
(11)
(12)

4 算法性能测试与分析
4.1 测试环境
为验证所提VTGA-Q-Learning算法的可行性和有效性,本文在Python 3.8+Open AI Gym和Pybullet中搭建环境地图,操作系统为Windows10 x64,硬件信息为Intel i5-11400F,DDR4 8 GB。
本文针对未知环境下的路径规划问题设置了4种环境格栅地图(如图8)用于测试验证算法。其中红色方格表示智能体起点位置,黄色圆圈表示终点位置。图8a为16×16维地图,用于对比测试算法性能;图8b~图8d为25×25维复杂地图,其中设计了大量地图陷阱,用于测试本文算法的泛化性能以及规避地图陷阱的能力。算法的参数设置如表1所示。


表1 参数设置
表中,C的取值对算法优化影响较大,现在图8a环境地图中对参数C进行研究,令C∈[0,600],按间隔50离散取值,每个C分别进行10次实验,计算其奖励值,C=0时表示不使用虚拟奖励。按式(13)对实验数据进行处理,给出10次实验的平均奖励步长比。如图9所示,横坐标为实验幕数,共1 000幕;纵坐标为10次实验每幕奖励值与步长比值的平均值,可见C=200时虚拟奖励最大。因此,后文均取C=200。


(13)
式中:j为实验次数,j=1,…,10;rewardepisode,num_stepepisode分别为每一幕的总奖励与总步长;episode为当前幕数,episode∈[0,max_episode]。
4.2 实验结果分析
4.2.1 算法对比测试结果
图10所示分别为Classic-Q-Learning,Dynamic-Q-Learning[40],AE-Q-learning[35],SA-Q-learning[34],Backward-Q-learning[36]和本文VTGA-Q-Learning在图8a上的实验数据,包括episode-reward图(左列)和episode-stepnum图(右列)两类数据。图10中左右两列的横坐标均为强化学习幕数(episode),左图(episode-reward图)纵坐标为智能体每一幕的总奖励值,右图(episode-stepnum图)纵坐标为智能体在该幕下的累计步长。表2所示为各算法在图8a上进行10次实验的平均数据。从图10和表2可以发现:



表2 各算法在图8a上的实验数据
(1)在10 000幕内,Classic-Q-Learning中智能体到达目标点的总幕数为5 833幕;Dynamic-Q-Learning中智能体到达目标点的总幕数为8 530幕;同时从图10a和图10c可见,两种算法都不能稳定收敛,奖励值存在较大波动,收敛性较差;从图10b和图10d可见,智能体每幕的步长存在较大波动,表明智能体存在受ε影响而导致的随机收敛问题,Classic-Q-Learning和Dynamic-Q-Learning在收敛阶段仍存在因障碍物而提前终止的情况,降低了算法的效率。
(2)从图10e和图10f观察到,AE-Q-learning在1 000幕内,智能体到达目标点的总幕数为618幕;在197幕以后,智能体就能稳定到达目标点。表明该算法的收敛速度和稳定性都有很大改进。但对比Dynamic-Q-Learning可见,AE-Q-learning虽然提升了算法的收敛性,但是不能稳定收敛,仍为随机收敛。
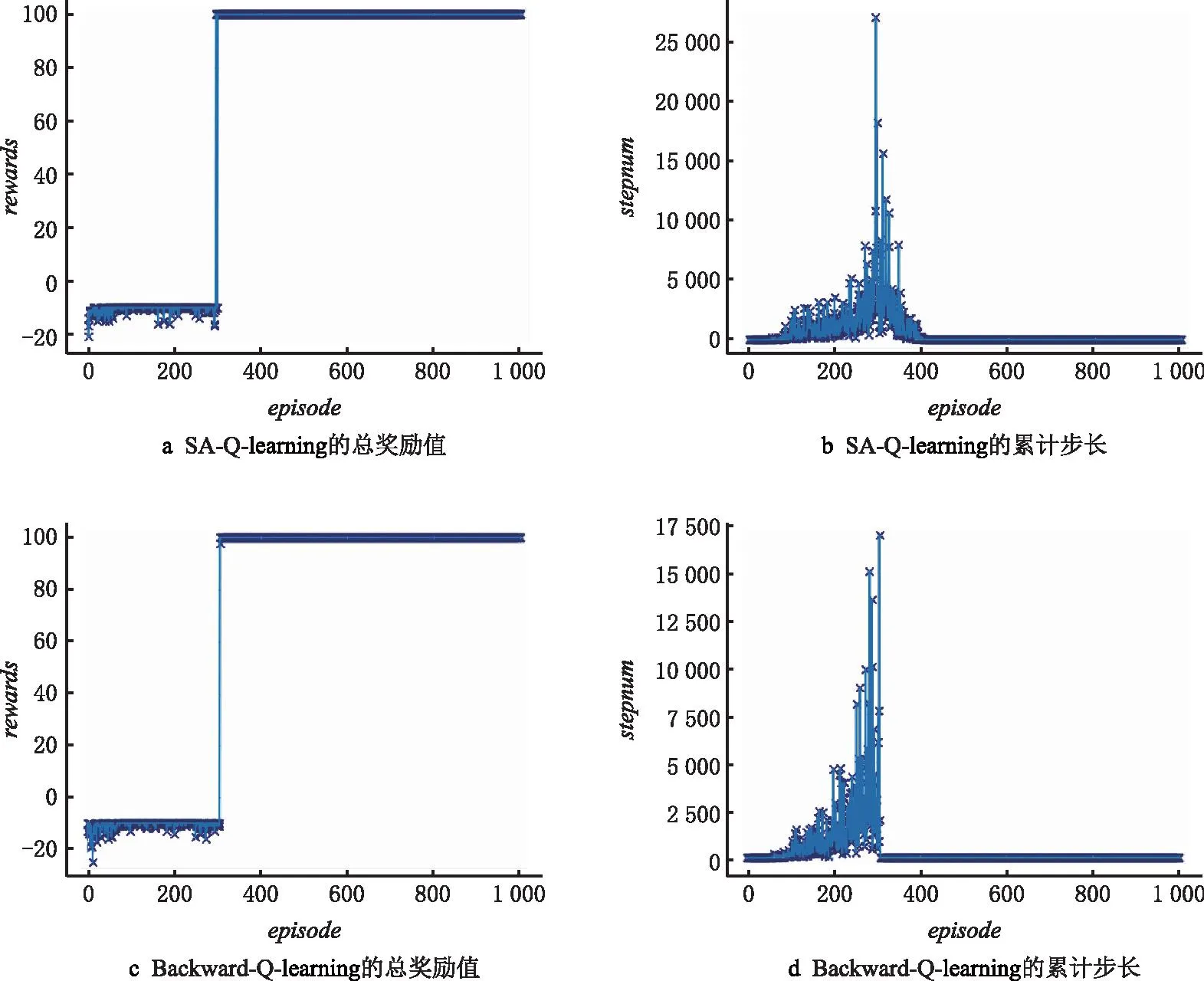
(3)从图10g和图10h观察到,SA-Q-learning在1 000幕内,智能体到达目标点的总幕数为872幕;在188幕以后,智能体就能稳定收敛到达目标点。表明该算法的收敛速度和稳定性都有很大改进,但从实验数据可见其步长峰值较高,平均用时为155.631 s,对比Dynamic-Q-Learning法10 000幕的用时,可见SA-Q-learning在提升算法收敛性的同时降低了收敛速度。
(4)从图10i和图10j观察到,Backward-Q-learning在1 000幕内,智能体到达目标点的总幕数为892幕;在124幕以后,智能体稳定收敛到达目标点。从表2的实验数据可见其平均用时为201.423 s,对比Dynamic-Q-Learning和SA-Q-learning可知,Backward-Q-learning在提升收敛性的同时,也因Backward模块降低了算法效率。
(5)从图10k和图10l观察到,VTGA-Q-Learning在1 000幕内,智能体到达目标点的总幕数为935幕;智能体在57幕就已准确到达最终目标点,并在82幕后稳定到达目标点,平均用时比AE-Q-learning降低42.322%,比SA-Q-learning降低63.471%,比Backward-Q-learning降低71.776%。表明所提改进方法能有效提高算法的收敛速度和稳定性,其次对比图10的a,c,e,g,1 5张图可见,VTGA-Q-Learning的奖励值更为丰富。
4.2.2 鲁棒性测试
鲁棒性测试实验用图8b~图8d进行测试,实验数据分别如表3~表5(10次实验的平均数据)、图11~图13所示,对比算法采用SA-Q-learning和Backward-Q-learning(Classic-Q-Learning,Dynamic-Q-Learning,AE-Q-learning算法在1 000幕内不能收敛)。

表3 各算法在图8b环境地图上的实验数据

表4 各算法在图8c环境地图上的实验数据

表5 各算法在图8d环境地图上的实验数据



从表3可见,在环境图8b上,相比SA-Q-learning在286幕、Backward-Q-learning在307幕初次到达目标点,VTGA-Q-Learning在253幕首次探寻到目标点且收敛速度和成功率均较好,3种算法规划的路径长度相同;同时由图11f对比可见,VTGA-Q-Learning在步长峰值和稀疏奖励问题上都得到很大改善,缓解了盲目探索问题。
从表4可见,在图8c上,VTGA-Q-Learning的收敛速度比对比算法有较大改善;从初次到达目标点的幕数来看,VTGA-Q-Learning针对包含陷阱的地图仍有较好的适应性;从图12f可见,VTGA-Q-Learning的步长峰值远低于对比算法,且成功率相对较高。
从表5可见,在面对包含较多凹型陷阱的复杂环境(如图8d)时,VTGA-Q-Learning在263幕收敛时,对比算法还未找到目标点;从收敛用时和成功率上看,VTGA-Q-Learning在提高收敛速度的同时,并未降低探索的有效性;从图13可见,VTGA-Q-Learning步长得到明显改善,且奖励值更加密集。
4.2.3ε曲线分析
为体现自适应贪婪因子中ε的变化,图14给出了VTGA-Q-Learning在图8a~图8d中的自适应贪婪因子的变化曲线。从图14a~图14d可见,起始阶段智能体有一段完全探索时期(ε=1),期间智能体对环境进行充分探索;在对环境信息有所掌握后,由探索经验估计地图的复杂程度和交互程度来ε调整的变化速率;当交互程度较高时,ε变化速率减缓,逐渐稳定在较小值,使策略比较保守,更倾向于利用已有知识。对比图14a和图14b~图14d可见,面对比较简单的环境,ε的变化比较平滑;反观图14b~图14d,面对复杂环境,ε随交互程度和环境复杂程度主动调节变换速率,所提自适应贪婪因子对环境具有较好的自适应能力。
5 虚拟仿真实验
在第4章算法性能对比实验的基础上,本文进一步开展虚拟仿真实验,通过模拟真实环境,验证机器人的自主路径规划能力和工程实用性。虚拟仿真实验用四驱麦克纳姆轮小车作为测试对象,在Pybullet软件中模拟创建室内环境地图,如图15所示,图中黑色为障碍物,红色为目标点,紫色为四驱麦克纳姆轮小车。四驱麦克纳姆轮小车具有前后左右行走能力,搭载有高性能控制器、4个超声波传感器、里程计等;超声波传感器安装在小车的4个边(对应小车4个动作的方向),每边的感知范围为±20°,距离为2 cm~450 cm;里程计定位精度≤0.15 m,能够根据上位机发出的目标位置自主探索路径;小车模型与实物图如图16所示。根据小车尺寸、感知范围和行走定位误差,定义每个正方形栅格边长为1 m,小车位于栅格中心。



在相同室内环境下,本项目开展了两组实验,实验1如图15a所示,实验2如图15b所示,图中红色为目标点,紫色为小车当前起始位置,实验1和实验2的起点和终点相反,以表现算法的泛化性。为了验证算法的稳定性,每组实验各做10次。按照算法设计,小车接到目的地位置指令后开始进行探索,小车移动方向对应的超声波传感器检测到0.02 m内有障碍物即视为碰撞,然后根据算法设置返回起点再次探索;当小车定位在距目标≤0.02 m,且小车移动方向所对应的超声波传感器检测到0.02 m内有障碍物时,视为成功并输出起点到终点的轨迹列表。
在本文强化学习算法驱动下,小车每次实验都能准确找到最优路径,其中两组虚拟仿真实验第10次路径规划结果如图17所示,表明所提算法具有良好的泛化性。因为强化学习的特性,每组中10次实验得到的最优路径并不完全相同,路径探索时间和路径长度的统计数据如表6所示。从表中可见,实验1路径长度均值为18.598 m,标准差为0.287 m,实验2路径长度均值为18.903 m,标准差为0.225 m,而且两组实验各自探索时间也非常接近,表明算法稳定性较好。


表6 规划路径长度与探索时间统计分析
综上所述,小车在两组实验中都能稳定到达目标点,而且每次实验数据无较大波动,表明本文算法具有较好的稳定性、泛化性和工程适用性。
6 结束语
本文针对环境信息未知的移动机器人路径规划问题,提出一种VTGA-Q-Learning,相对常规Q学习算法,其改进如下:
(1)双重记忆机制 在一定程度上减少了地图维度带来的维度灾难问题,而且引入障碍物记忆机制,避免探索时重复选择无效动作,增强了对复杂地图的适应性,加快了收敛速度。
(2)虚拟目标引导方法 通过从历史经验中提取中间态信息,并将中间态反映在动态奖励函数设置上,使智能体学习到比较重要的中间状态,从而改善稀疏奖励,提高智能体的目标趋向性。
(3)自适应贪婪因子 自适应动作选择策略自适应地平衡了探索和利用的关系,并根据机器人同环境的交互程度确定主要参数;同时根据交互经验设置动作概率,避免了非贪婪时均匀动作选择的弊端。
通过4种地图进行仿真测试表明,相对其他Q学习算法,本文VTGA-Q-Learning提高了Q学习的收敛性和收敛速度,具有很好的泛化性和障碍陷阱规避能力,并通过虚拟仿真实验证明了本文算法的工程适用性。
猜你喜欢
小学生作文(低年级适用)(2019年5期)2019-07-26
小学生作文(低年级适用)(2018年3期)2018-04-17
读友·少年文学(清雅版)(2018年12期)2018-04-04
领导决策信息(2018年50期)2018-02-22
商周刊(2017年5期)2017-08-22
少年博览·小学低年级(2017年4期)2017-06-09
中国卫生(2016年2期)2016-11-12
家庭百事通(2016年3期)2016-03-14
山东青年(2016年3期)2016-02-28
中国工程咨询(2016年4期)2016-02-14
