
基于多序列MRI 影像组学与深度迁移学习特征的脑胶质瘤分级预测研究
2024-03-13 04:46刘志鹏降建新吴琪炜卞雪峰朱银杏
南京医科大学学报(自然科学版) 2024年3期
刘志鹏,降建新,吴琪炜,周 炎,卞雪峰,朱银杏
1南京医科大学附属泰州人民医院信息处,2神经外科,3影像科,江苏 泰州 225300;4南京医科大学泰州临床医学院,江苏泰州 225300
脑胶质瘤是一类脑部常见的恶性肿瘤,年发病率为6/10 万~10/10 万[1],约占成人中枢神经系统(central nervous system,CNS)恶性肿瘤的75%[2],严重危害人类的身体健康。根据脑胶质瘤组织学检查的增殖程度、有丝分裂指数和坏死水平,可将其分为Ⅰ~Ⅳ级,其中Ⅰ、Ⅱ级为低级别胶质瘤(lowgrade glioma,LGG),手术易切除,Ⅲ、Ⅳ级为高级别胶质瘤(high-grade glioma,HGG),多预后不良[3-4]。LGG 占成人CNS 原发恶性肿瘤的6%,总生存期约7 年,但Ⅱ级LGG经常复发并最终发展为HGG[5]。因此,术前无创准确地预测胶质瘤分级,对脑胶质瘤患者手术方案的制定和后续治疗计划的实施具有重要意义。目前用于诊断胶质瘤的成像技术主要为磁共振成像(magnetic resonance imaging,MRI),常见的MRI 序列包括T1、T2、T1c 和Flair,这些序列分别从不同维度检测脑部肿瘤和其他神经系统疾病。然而单一序列图像无法全面展现脑胶质瘤的全部区域,可能会导致脑胶质瘤信息的丢失。因此,临床医生通常需要结合不同序列图像来综合分析脑胶质瘤的位置和形状,以更好地诊断和治疗。
目前脑胶质瘤的术前分级主要依赖影像科医生的主观判断,缺乏客观性。此外,在常规影像检查中,有些细节人工难以识别,因此寻找一种客观、稳定、可靠的分类方法至关重要[6]。在此形势下,影像组学应运而生。影像组学可以深入分析影像图片中肉眼无法识别的肿瘤特征以获取更多信息,结合临床信息通过统计学或机器学习(machine learning,ML)的方法进行分析,可以揭露更多关于肿瘤的组织学特征、进展、甚至总生存率等方面的信息。传统的影像组学需要人工提取图像特征,深度学习(deep learning,DL)可以通过卷积神经网络(convolutional neural network,CNN)进行特征提取,但这需要许多数据集来理解数据之间的潜在关系[7]。深度迁移学习(deep transfer learning,DTL)是一种采用预训练的DL 网络,并对其进行微调以学习新任务的过程,便于深度学习影像组学(deep learning radiomics,DLR)在小型数据集中应用[8],这一策略近年来已成为研究热点[9-10]。目前,胶质瘤术前分级预测方面应用手工影像组学(hand-crafted radiomic,HCR)技术的研究较多,但这类研究多集中在单独或两个序列的MRI 图像[11],且基于多序列MRI 的DLR 模型预测脑胶质瘤分级的研究少有报道。因此,本研究旨在结合DTL 和影像组学技术,提出一种基于多序列MRI的DLR特征的辅助诊断策略,实现脑胶质瘤的术前分级预测。
1 资料和方法
1.1 资料
本研究的影像数据均来自MICCAI 网站上BraTS2019数据集[12],本研究使用了其中332例患者的影像数据,包括有258 例HGG 数据,74 例LGG 数据。随机抽取30 例HGG 和8 例LGG 作为测试集使用,其余294 例数据作为训练集和验证集使用。构建及验证分级预测模型的流程图见图1。每位患者均接受了4 种MRI 序列扫描,即T1、T2、T1c 和Flair 序列。4 个序列的原始图像和感兴趣区域(region of interest,ROI)的图像显示如图2所示。
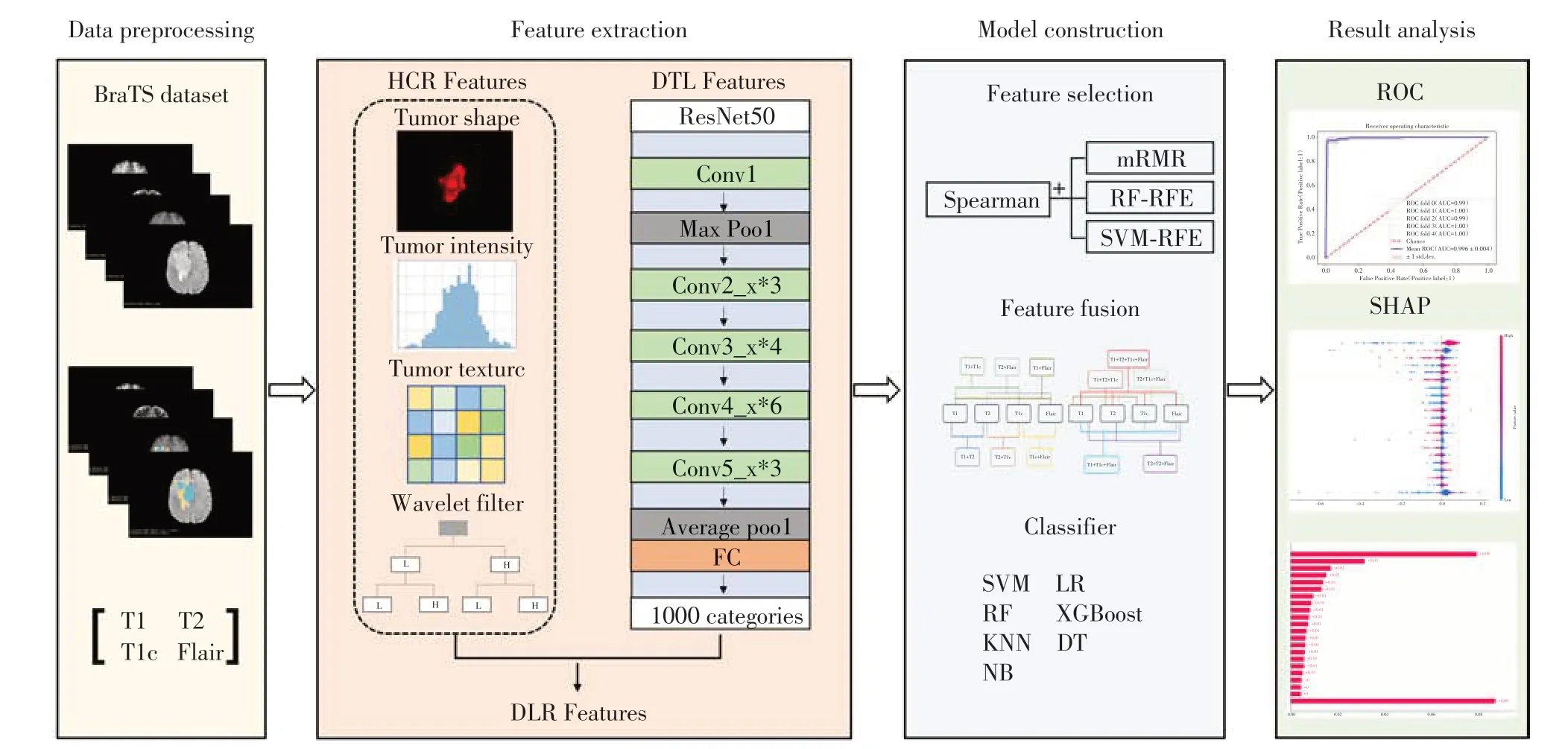
图1 构建及验证分级预测模型的流程图Figure 1 A flow chart of the building and validating the hierarchical prediction model
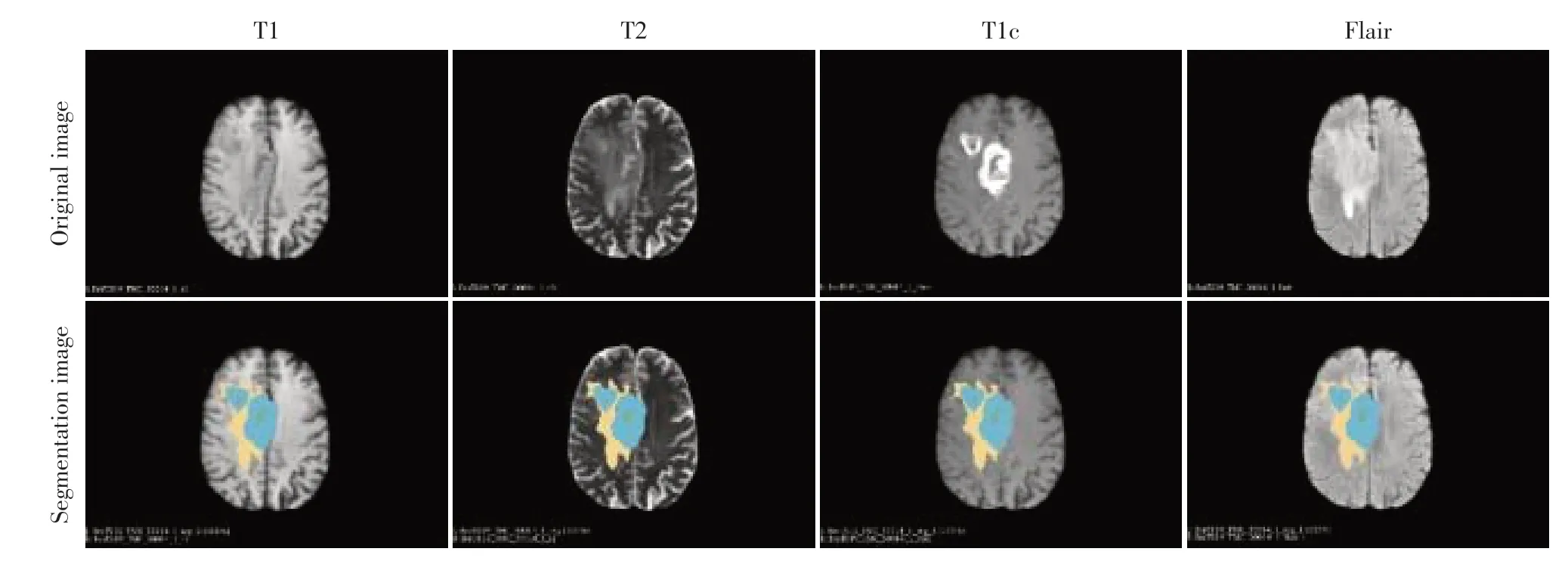
图2 多序列MRI影像图片Figure 2 Multi-sequence MRI images
将所有数据集内的胶质瘤图像去除颅骨,由经验丰富的神经影像科医生手工分割勾画ROI,ROI包括坏死区域、增强肿瘤区域、非增强肿瘤区域和水肿区域。在手动分割后,使用SimpleITK 软件包(www.simpleitk.org)对所有MRI 进行N4 偏置场校正,对图像进行预处理以减少数据采集的影响。
1.2 方法
1.2.1 特征提取
HCR 特征提取:使用Pyradiomics 软件包(https://pypi.org/project/pyradiomics)从T1、T2、T1c和Flair 4个序列的感兴趣区域体积(volume of interest,VOI)中分别提取HCR特征。HCR特征包括一阶特征、形态特征、灰度共生矩阵(gray level co-occurrence matrix,GLCM)、灰度游程矩阵(gray level run length matrix,GLRLM)、灰度尺寸区域矩阵(gray level size zone matrix,GLSZM)、灰度相依矩阵(gray level dependence matrix,GLDM)和灰度区域大小矩阵(neighborhood gray-tone difference matrix,NGTDM)特征。
DTL特征提取:在提取DTL特征之前,选择上述4 个序列中各自具有最大矢状面积的ROI 进行裁剪,将输入图像重采样为224×224 单位大小。选择在ImageNet(http://www.image-net.org)上预训练的ResNet50 作为本研究迁移学习模型的基本模型,它集成了残差学习,以避免深度网络中的梯度分散和准确性降低,提高网络效率、准确性和执行速度。最终在最后一层全连接层提取DTL特征。以上过程均在Python 3.7平台上使用Tensorflow深度学习库完成。
1.2.2 特征选择
将得到的所有特征进行Z-score 归一化处理。为防止过拟合,本研究采用多步特征选择方法选择最佳特征。第一步,采用Spearman相关系数法对所有影像组学特征进行排序分析。采用Spearman相关检验考察个体特征之间的内在线性相关。相关系数绝对值越大,相关性越强,对于线性相关系数≥0.95的特征只保留一个。第二步,分别采用最大相关最小冗余(max-relevance and min-redundancy,mRMR)、基于支持向量机的递归特征消除(support vector machine-recursive feature elimination,SVM-RFE)、基于随机森林的递归特征消除(random forest recursive feature elimination,RF-RFE)3 种方法筛选出影响力排名前10的特征子集。
1.2.3 特征融合
特征融合技术是使用多个给定的特征集生成一个新的组合特征集,不同特征子集之间优点互补,有利于后续的分类任务。首先,对每个序列的HCR 和DTL 特征进行融合,生成DLR 特征集,故后续每个序列的研究为HCR、DTL 和DLR 3 种特征集。其次,由于不同序列的影像数据捕获的重点信息不同,将上述4种序列的特征子集进行融合,融合方式分别为:随机2种序列融合、随机3种序列融合以及4 种序列全部融合。特征融合过程如图3 所示,最终有15种影像序列融合方式。
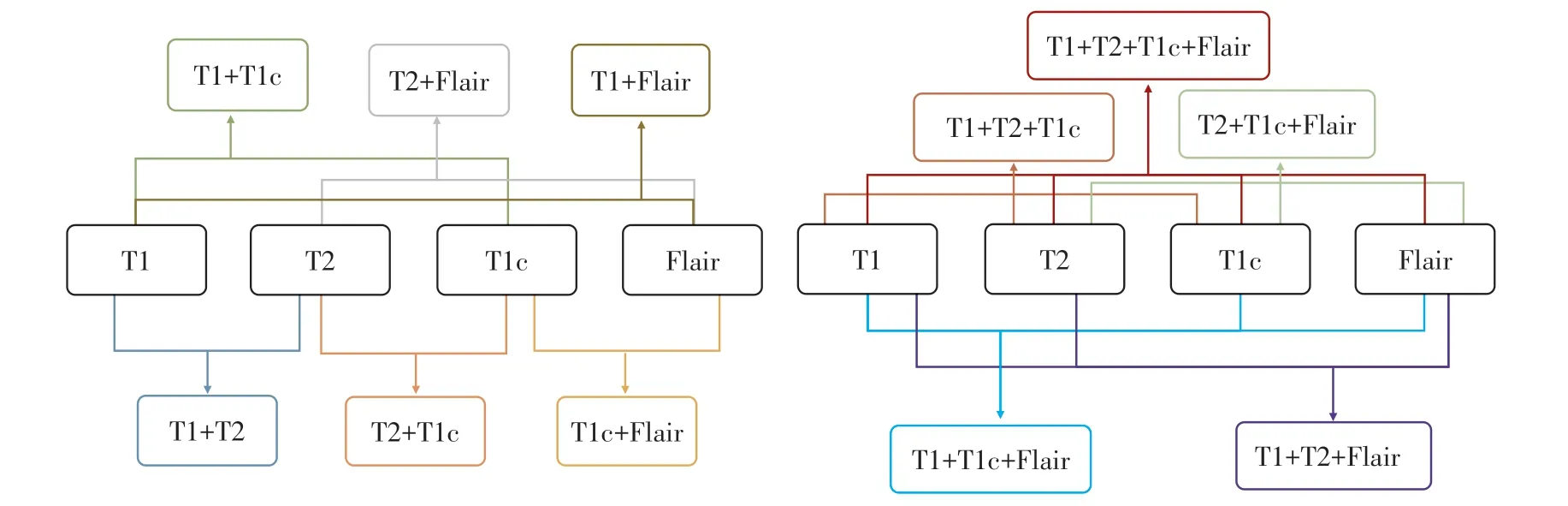
图3 特征融合过程Figure 3 The fusion process of features
1.2.4 分类模型构建
在特征选择和融合后,分别使用每个特征子集构建ML 分类模型,本研究使用了支持向量机(support vector machine,SVM)、逻辑回归(logistic regression,LR)、随机森林(random forest,RF)、XGBoost、决策树(decision tree,DT)、K 近邻(K-nearest neighbors,KNN)、朴素贝叶斯(naive bayes,NB)这7 种常见的ML 模型,模型由Python Scikit-learn 实现,并对其在脑胶质瘤分级预测中的性能进行比较。为了防止过拟合,采用五折交叉验证来评估模型的分类性能和泛化能力,将其中4 份作为训练集,1 份作为验证集。在进行模型训练过程中,采用网格搜索法选取最佳的超参数值。
1.3 统计学方法
本研究均在Python 3.7(https://www.python.org)上实现。采用Spearman 相关系数法对所有影像组学特征进行排序及相关性分析。分别采用mRMR、SVM-RFE、RF-RFE 方法筛选出影响力排名前10 的特征子集。使用受试者工作特征曲线下面积(area under curve,AUC)评分用于测试预测模型的性能。在模型构建过程中计算约登指数(Youden index,YI)评价诊断精度,并将其整合到准确度(accuracy,ACC)、灵敏度(sensitivity,SEN)和特异度(specificity,SPE)的计算中来进一步评估模型功效。使用Python 中的SHAP 包来显示每个特征重要性之间的关系。对最佳模型特征重要性进行量化以及个体特征影响进行归因分析。
2 结果
2.1 特征选择和特征融合
从T1、T2、T1c、Flair序列分别提取1 321个HCR特征和1 000个DTL特征。经过Spearman相关系数法筛选出的HCR 和DTL 特征数量如表1 所示。随后,分别采用mRMR、SVM-RFE、RF-RFE 3种筛选方法对上述筛选出的特征进一步选出排名前10 的特征(表1)。15种影像序列融合方式中,每种序列融合方式均包含3 种筛选方法下的3 种特征组合方式,即9 个特征子集,最终生成135种特征融合子集。

表1 特征筛选结果Table 1 Results of the selected features(n)
2.2 脑胶质瘤分级模型的构建和比较
2.2.1 单序列分析
本研究主要包括4 个序列(15 种序列融合方式)、3 种特征和3 种特征筛选方法,因此对上述这135 个特征融合子集分别通过7 种ML 分类器进行建模。此外还对HCR、DTL 和DLR 这3 种特征提取方法进行比较,4 个单序列数据集的性能分析结果显示,在4个序列中,与HCR和DTL相比,DLR作为输入特征建模时,实验结果更具有竞争力(表2)。
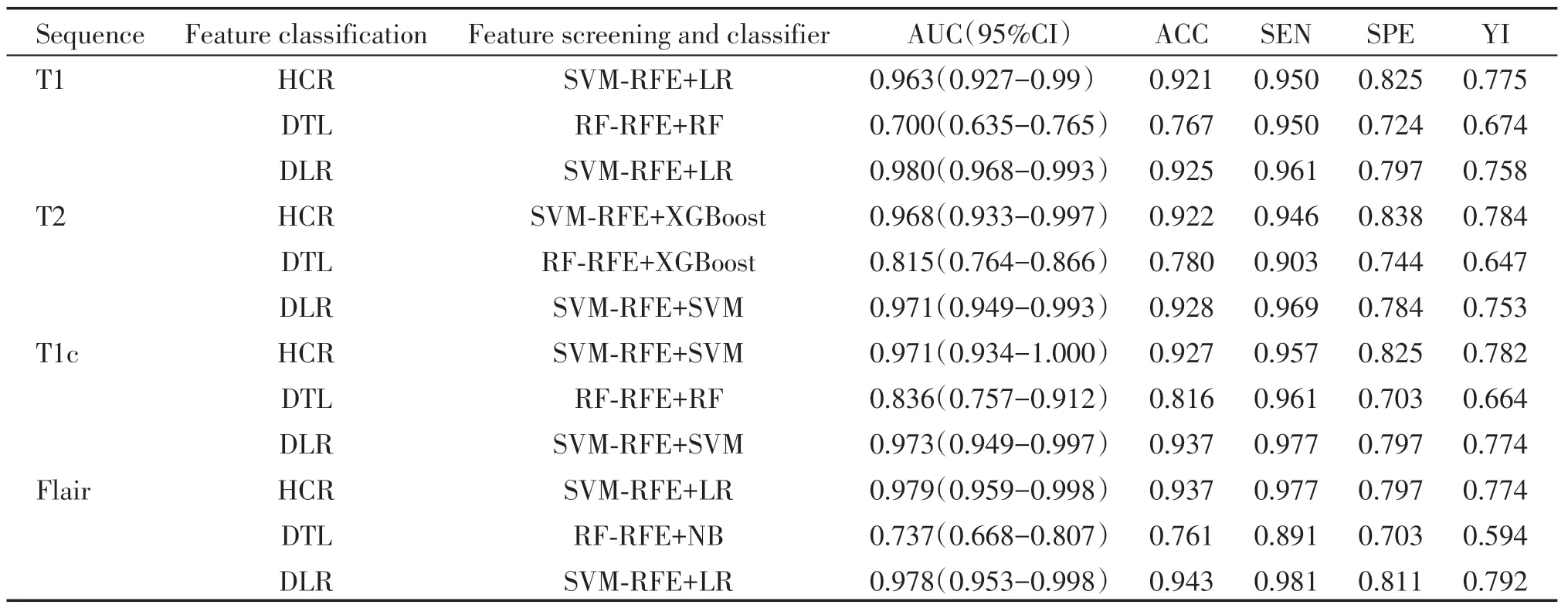
表2 单序列验证集实验结果汇总Table 2 The summary of single sequence in verification sets
2.2.2 多序列分析
单序列分析结果显示,基于DLR 特征构建的ML 模型具有较高的分级预测效能,因此在多序列建模中使用DLR 特征集进行后续实验分析。对各模型特征筛选方法和分类器的预测性能进行比较,并对11种多序列的最优实验结果进行整理,结果显示,使用T2+T1c+Flair 序列组合,且基于SVM-RFE的特征筛选方法和SVM 分类器的模型获得最好的预测效果(图4A、B):在验证集上,AUC 达到0.996(95%CI:0.991~1.000),YI、ACC、SEN、SPE 分别为0.920、0.976、0.988 和0.932。五折交叉验证结果显示该模型具有较高的稳定性(图4C)。
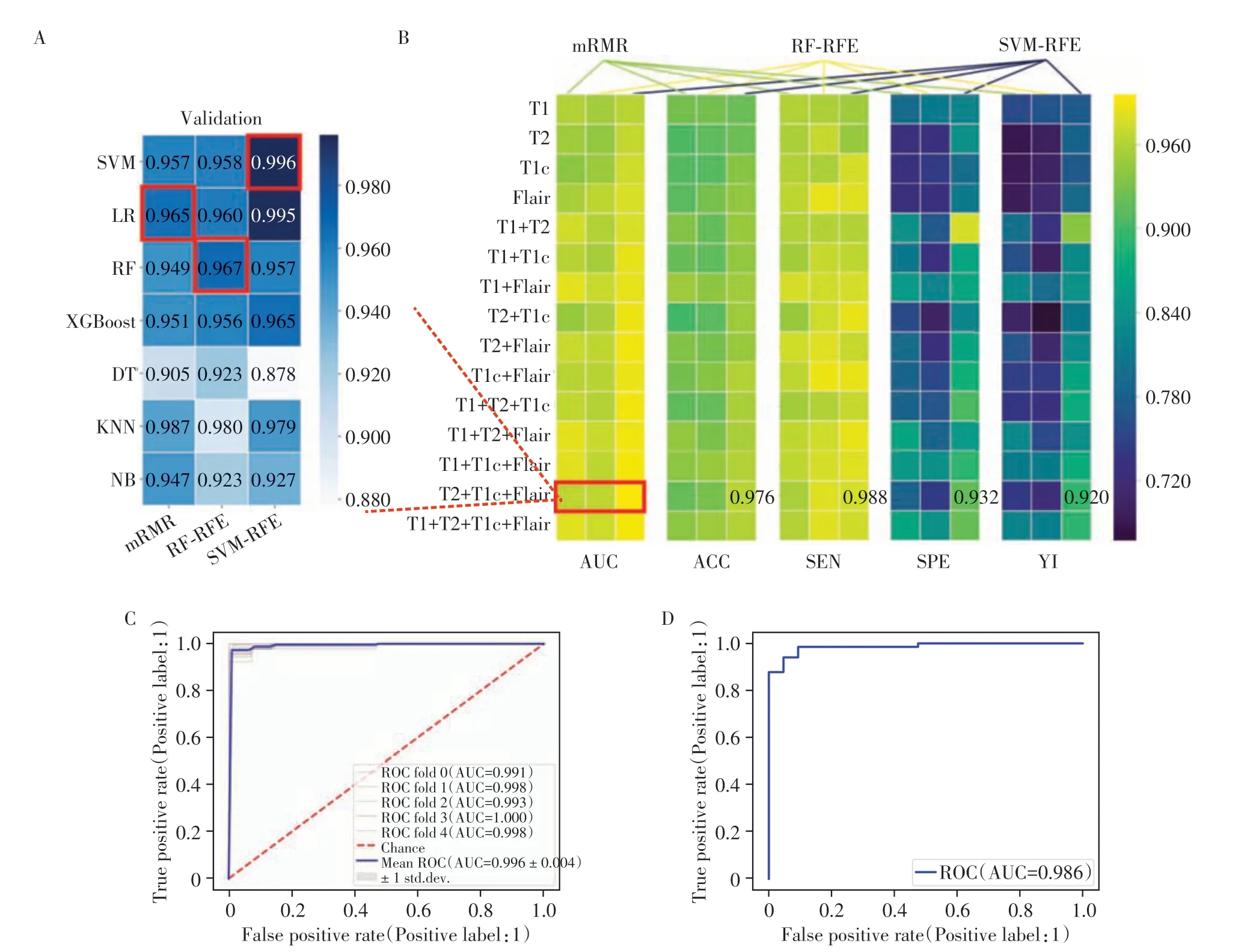
图4 DLR特征实验结果Figure 4 The results of DLR features
2.2.3 模型验证
使用30 例未参与训练的测试数据集进行最终模型分类效能的验证。在测试集上,AUC值为0.986(图4D)、ACC为0.921、SEN为0.933、SPE为0.875。
2.3 模型临床获益和可解释性
使用SHAP算法获得各序列的每个DLR预测特征的权重,并按重要性排序列出前20 的特征。SHAP 值表示每个特征对最终预测的贡献,Flair 序列的特征贡献较大,其次为T2及T1c序列(图5);同时,排名前20的特征中,HCR和DTL特征均有贡献。
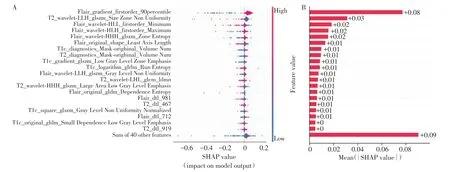
图5 SHAP特征权重分布蜂图(A)及权重均值直方图(B)Figure 5 SHAP feature weight distribution swarm plot(A)and weight mean histogram(B)
3 讨论
由于侵袭性和浸润性不同,脑胶质瘤的分级直接影响治疗方案及患者预后[13]。因此,术前无创准确地预测胶质瘤分级,对制定手术方案和实施后续治疗计划具有重要意义。本研究建立基于多序列MRI 的HCR 和DTL 特征的ML 模型,其中最优的模型在训练集和验证集均能有效预测脑胶质瘤的高低分级,通过决策曲线筛选出获益率最高的特征,并对模型进行了归因分析,表明该模型在脑胶质瘤分级预测中具有巨大应用潜能。
MRI成像技术具有分辨率高、软组织结构清晰、无辐射等优点,根据不同的成像条件,不同的MRI序列反映不同的肿瘤组织特征并互相补充,是诊断脑胶质瘤可信度极高的成像技术[14]。T1 序列可以显示组织的形态和大小,T1c 序列是T1 序列的一种增强版本,通过注射对比剂来增强肿瘤和血管等组织的成像效果,在检测脑部肿瘤和血管病变等方面更具优势。T2 序列更适合显示组织的水含量和炎症程度,Flair 序列是一种增强的T2 序列,可以显示炎症和肿瘤周围的水肿区域,对于检测脑部肿瘤具有很高的诊断价值。因此本研究对多序列(T1、T2、T1c和Flair)的MRI进行了研究。通过随机2种序列融合、随机3 种序列融合以及4 种序列全部融合的方法,最终产生15种影像序列融合方式。
影像组学通常指以高通量方式从成像图像中提取大量图像信息,以实现肿瘤分割、特征提取和模型构建[15]。然而,影像组学分析需要手动描绘ROI以实现肿瘤分割,这可能影响特征值的提取[16]。DL已经广泛应用于医学影像领域,因此本研究首先比较了HCR 特征、DTL 特征和两者组合的DLR 特征,结果表明DLR 作为输入特征建模时,表现出具有竞争力的分类效能。同样,在多数研究中,基于DLR特征构建的ML模型均表现出最优效能[17-18]。
为了探索适合脑胶质瘤分级预测的最佳ML模型,本研究采用3 种特征筛选方法和7 种ML 算法,最终每种特征均各自构建了15 个序列共135 种ML模型,并对每种模型的性能进行评估,以选出最优的模型组合。RFE通过迭代训练ML模型,每轮训练后,将权重(或系数)最小的特征进行剔除,直到得到最优特征子集[19],本研究显示,采用SVM-RFE法筛选特征后,T2+T1c+Flair 序列组合的SVM 分类器模型效能最优。SVM 是一种常用的ML 二元分类算法,Siakallis等[20]在HGG监测中提出了一种结合MRI特征的SVM 分类器,可以提高分类性能,优于放射科医生的分类。既往采用SVM 分类器预测脑胶质瘤分级的研究,均取得了较好的效能。Chen 等[21]回顾性分析了220 例HGG 患者和54 例LGG 患者的MRI图像,SVM构建的胶质瘤分级预测模型准确率为91.27%。Tian 等[15]收集了153 例胶质瘤患者(42 例LGG 和111 例HGG)的术前MRI 图像。他们从多个序列(T1、T2、ADC、T1c 和3D -动脉自旋标记)中提取放射组学特征,并使用SVM 分类器进行分级预测,多模态MRI 模型的AUC 和准确率分别为0.987和96.8%。本研究最优模型在训练组和验证组中的性能类似,在验证集上,AUC 达到0.996,准确率为97.6%,均能较好预测脑胶质瘤分级,具有良好的鲁棒性,优于Tian等[15]的模型。
通过DL 方法提取的DLR 特征很难解释,不可解释性会阻碍其在胶质瘤临床实践中的应用。SHAP 值用于评估预测模型中每个特征的贡献,这是解释ML 模型的最先进方法。这种方法源于博弈论的Shapley 值,它量化了每个参与者对结果的贡献[22]。因此本研究采用SHAP法对模型的特征进行解释,可以发现,贡献较大的特征来自Flair 序列最多,其次为T2及T1c序列,这与上述T2+T1c+Flair序列融合为最优模型的结果相符。
本研究构建的最优模型在准确性和临床实用性上都有一定优势,但仍有一些局限。首先,本研究使用的数据均为小样本公共数据集,缺少对应的外部数据集进行验证,所以模型的泛化能力无法验证。未来应继续扩大样本量,进一步收集多个医疗机构的高质量数据,整理形成多中心的大样本数据集进行研究。其次,本研究仅用了4 种常规MRI 序列对脑胶质瘤的高、低级别进行分类预测,应用范围相对局限,后续还应结合更多序列进行研究。其他组学内容也应纳入研究,如病理组学、基因组学等,分类也应更加深入。最后,基因突变和生存周期预测的研究未来仍需进一步探索。
综上所述,基于MRI 的DLR 模型可有效预测脑胶质瘤肿瘤分级,其中T2+T1c+Flair序列组合,且基于SVM-RFE 的特征筛选方法和SVM分类器的模型获得最好效果,可为脑胶质瘤患者术前预测分级,制定个体化的诊疗方案提供有力支持。
猜你喜欢
国际口腔医学杂志(2019年3期)2019-05-31
天然产物研究与开发(2018年2期)2018-04-04
中国医疗保险(2017年6期)2017-07-18
中国卫生(2016年5期)2016-11-12
磁共振成像(2015年8期)2015-12-23
吉林大学学报(医学版)(2015年5期)2015-12-16
中国卫生(2015年10期)2015-11-10
中国卫生(2015年6期)2015-11-08
医学研究杂志(2015年11期)2015-06-10
中国当代医药(2015年9期)2015-03-01
