
AIGC 技术创建三维数字内容的研究进展及应用浅析
2024-03-13 08:12龚雨楠薄一航
现代电影技术 2024年2期
龚雨楠 薄一航
北京电影学院美术学院,北京 100088
1 引言
电影和技术的发展息息相关,从黑白电影到彩色电影,无声电影到有声电影,再到现如今的数字电影时代,不断提升的视听技术使电影拥有更多的细节,更具沉浸性,为观众提供极佳的视听体验。视效技术将创作者的想象力进行视觉化呈现,为观众带来了丰富的视觉体验,其中三维数字技术在电影制作中起到了越来越重要的作用。三维技术可以拓展电影呈现的场景空间,展现生动的计算机图形学(CG)角色,其应用不仅仅局限于后期提升最终成片的视觉效果,还可以应用在前期筹备过程和拍摄过程中的预览,使创作人员能够更加准确地把握创作效果。
与图像内容相比,三维数字内容的创作流程更长,创作难度和成本相对更高。在人工智能生成内容(Artificial Intelligence Generated Content,AIGC)技术迅猛发展的背景下,如何利用相关技术辅助三维数字内容创作,是一个值得探讨的问题。AIGC 技术并不特指某种技术,而是综合多种不同人工智能生成技术,涉及不同的计算机研究领域和其他学科的交叉融合,包括但不限于自然语言处理(NLP)、计算机视觉(CV)、计算机图形学(CG)等。近两年陆续有面向公众的AIGC 类型产品发布,如文本生成大模型ChatGPT、文生图类型应用Midjourney 和Stable Diffusion 等,这些产品不仅可以实现对图像或文本等信息的理解与判别,还可以根据要求生成新的内容,甚至可以根据给定要求完成一系列任务,可以让大众真正通过使用人工智能技术提高工作效能。
本文将围绕影视中的三维数字内容创作,阐述影视制作流程中对三维数字内容的需求,探讨在AIGC 技术飞速发展的背景下,由文本生成3D 技术在三维创作中的实际落地应用,如何降低繁琐的重复性工作以及提升影视制作效率,释放创作者的想象力。
2 电影对三维数字内容的需求
在数字电影制作流程中,尤其在需要三维技术辅助的电影中,需要利用多种CG 模型、角色来实现最终的成片效果,其中三维数字内容包含了模型资产、材质资产、动画资产等。三维数字内容通常由创作人员在计算机上利用三维建模软件进行建模而得到,传统创建流程包括设计、建模、展UV、UV 贴图绘制,最终导入渲染引擎进行渲染和导出,对于人物角色等需要动画的模型,还需要进行骨骼绑定、蒙皮权重调整等操作。除传统建模方法外,还可以通过激光扫描进行三维重建,通常应用于微缩模型的数字化或者对已有现实大场景的还原。相较于游戏行业中对三维模型高精度、优性能的要求,电影中所需的三维模型在不同应用场景中对应了不同需求,并非在任意场景都要求满足这两个要求,因此在创建方法的选择上更灵活,可以尝试选用多种技术结合的方式,提高创作效率,提升创作质量。
电影对三维数字内容的需求可以从两个不同的应用场景进行分析:前期视觉预演与后期视效制作。以下将通过对不同应用场景的分析,提出电影摄制流程对三维数字内容的需求。
2.1 前期视觉预演
在影片的前期筹备工作中,分镜脚本设计是一个重要环节,对现场拍摄和后期制作都具有指导意义。影片的分镜通常将故事情节内容以镜头为单位来划分,能够体现出场景与人物的关系、人物调度、镜头景别、摄影机运动方式等,实现了从剧本到画面的初步转化,加深拍摄团队对剧本的理解和对拍摄内容的把握,降低不同部门间的沟通成本,为现场拍摄工作减轻压力。在特效影片中,拍摄团队需要通过故事板预先确定特效制作方案,避免返工,减少不必要的成本。
随着CG 技术的快速发展,分镜不再局限于早期手绘故事板,出现了动态故事板,即如今的动态视觉预演。创作者可以在仿真虚拟场景中,通过设定虚拟摄影机位置制定拍摄方案,直接以短片的方式呈现预览结果。虚拟三维空间能够更好地模拟现实场景,提升前期筹备的工作效率,三维视觉化呈现以及虚拟场景中的各项数据可以对现实进行仿真,如场景的大小、各类道具的位置以及虚拟摄影机的各项参数。这些数据在虚拟仿真空间内进行尝试与调整后,能够更好地为现场拍摄工作提供参考。图1为影片《流浪地球2》在前期为多个视效镜头制作的动态预览镜头。

图1 《流浪地球2》预览与实拍画面对比[1]
在动态预演过程中,电影制作团队往往需要丰富的三维数字内容以快速得到相应场景,如特定场景、角色、动画,在耗费人力成本较小的前提下,短时间内得到尽可能接近预期的结果,为之后的拍摄及后期流程做充分准备。这一环节的三维数字内容并不需要特别精细,但是应该不仅能够准确反映最后的拍摄效果,如角度、景别、演员与摄影机的调度等,还可以指导后期精细化的道具模型、角色模型创建,是贯穿整个摄制流程的重要参考;且因处于前期环节,实现高效快速的建模与动画流程占有更高的优先级。
2.2 后期视效制作
在电影后期视效制作流程中,三维数字化技术进一步拓展了电影内容的创作空间,有助于创作者进行艺术表达,无论是对历史场景的再现,或者是对架空背景奇幻世界的展示,都需要三维数字内容进行辅助。在后期视效中需要运用到的三维数字内容可以简要划分为三维角色、三维道具和三维场景。科幻类型电影展现着创作者天马行空的想象力,以《阿凡达:水之道》为例(图2),不仅呈现了潘多拉星球独特且震撼的生态系统,还设计了纳美族角色形象。生动的角色表演和精妙的场景设计,往往能够与电影的叙事相结合,创建出一个更具信服力和沉浸感的世界。

图2 电影《阿凡达·水之道》截图[2]
针对后期视效制作所需的三维模型内容,三维数字艺术家应该从电影整体的美术风格出发,在设计阶段制定模型的需求和规范,根据实际应用范围确定该模型的精细程度以及是否需要动画,并就此对模型的创建进行规划。如果在影片中有关键道具的特写镜头,则需要呈现更加丰富的细节。此外,最终性能也应在设计阶段便纳入考虑范围,虽然电影相较于游戏而言对性能的要求并没有那么高,但是当前为了实现实时预演,提升后期渲染效率,仍然需要准备低面数模型,并在不影响最终视觉效果的情况下,减少模型面数和顶点数量。
针对电影中的CG 人物角色,后期需要利用面部捕捉和动作捕捉实现生动的CG 角色表演。为保证面部动画的流畅性,需要对模型的布线进行调整,以符合面部肌肉运动方向;为实现自然的角色动作动画,需要对人物角色模型进行骨骼绑定,并进行蒙皮权重处理,使得骨骼动画发生变化时,角色模型表面的网格顶点可以根据骨骼进行合理的移动和变形。总而言之,后期视效制作所需的三维模型不仅需要更高的精细度和细节,还要考虑动画的可实现性。
3 文本生成三维技术原理及发展现状
随着文本生成图像研究不断发展进步,文本生成三维(Text-to-3D)成为一个值得关注的课题。与图像生成方法相比,针对生成三维形状的深度学习(Deep Learning)更为困难,三维模型相较于二维图像而言,包含的信息数据量更多且更复杂,对神经网络(Neural Network)的训练难度更大。
首先,难度来源于三维模型数据的复杂性。以像素为单位整齐排布的二维图像为欧几里得结构数据,节点与邻居节点之间具有统计上的相关性,更容易被处理与学习;而三维模型数据较为复杂,因此首先需选取合适的表示方式。目前较为主流的三维模型数据表示方式可以划分为显式表示和隐式表示,前者包含点云(Point Cloud)、体素网格(Voxels)、多边形网格(Polygon Mesh),后者则包含符号距离场(Signed Distance Field,SDF)、多视图表示(Mult-view Data)等。其中基于多视图表示与体素网格的三维模型数据属于三维欧几里得数据,能够将二维深度学习范式拓展到三维数据;三维非欧几里得数据的深度学习技术难度更大,需要使用几何深度学习方法。
其次,三维生成的训练还面临数据集不足的难题。Text-to-Image 的模型训练可以从互联网获得海量数据,但是三维内容的训练数据集规模是远远不够的。随着针对三维数字内容的研究发展,已有研究团队创建了相关数据集。ShapeNet 是根据Word-Net 层次组织的三维形状数据集,但由于其为仿真数据集,外观与真实世界中的数据分布差距较大,因此得到的训练结果仍然有差距;数据集Objaverse 包含了通过扫描得到80 万余标注的三维物体,研究团队在此基础上进行了扩展,创建了Objaverse-XL[3],包含一千余万的三维物体;OmniObject3D 为物体提供了四种模态的信息,包含带纹理的高精度模型、点云、多视图渲染图像以及实景拍摄的环绕视频。尽管整体数量看上去十分可观,但是与图像亿级的数量相比,训练数据集规模仍然非常有限。
目前,随着对三维生成研究的开展与深入,部分技术方法可以直接由文本生成种类丰富的三维模型。下文将根据发展的时间及不同的技术要点,对已有的Text-to-3D 技术方法进行分类,划分为初期、中期、中后期。初期阶段不直接生成三维形状,但是可以用文本指导三维模型进行组合,形成一个更复杂的模型或组合成为一个场景;中期阶段研究发展探索对不同三维表示的学习,通过编码器学习文本和三维模型的对应关系,实现跨模态映射,可以利用生成网络针对部分特定类目生成形状;中后期,即现阶段,则在文生图技术发展的基础上,基于CLIP、神经辐射场(Neural Rediance Fileds, NeRF)和Text-to-Image 相关方法实现的Text-to-3D 技术方法。
3.1 根据文本检索三维模型
在初期阶段,文本和三维内容的相关研究包括文本与三维模型间的匹配;三维模型的位置定位,以及在文本与三维生成的文本引导三维模型的组合等。根据给定文本从资产库中检索出对应模型,并且组合成一个完整的三维场景,如WordsEye[4]利用解析器对文本进行解析,转换为依赖结构,再对依赖关系结构进行语义解释,并转换为表示三维对象、姿态、空间关系、颜色属性等的描述器,之后根据描述器重构场景。此类研究中的重点主要在于通过对文本进行解析,准确学习空间中的物体关系,使系统能够根据给定文本确定所需物体,从资产库中选择三维模型,确定不同模型的位置与空间关系,合成一个三维场景。其中三维模型仍然需要人工创建,只是可以使由输入文本控制三维场景合成及搭建场景的效率得到提高。
Chang 等人[5]提出了可以从三维场景中学习的空间知识表示,通过统计在不同场景中出现的物体及其相对空间位置,实现了从简洁文本到真实可信场景的生成。Ma 等人[6]针对室内场景陈设,实现了子场景中的文本驱动场景建模,且增强了生成的三维场景的复杂性和现实性(图3),该生成框架利用语义场景图表示对几何与语义信息进行编码并学习物体间更复杂的关系,用多个文本提示逐步生成需要的场景。

图3 自然语言驱动合成系统的结构概览[6]
3.2 针对特定类目的3D 物品生成
随着生成模型如生成式对抗网络(GAN)、扩散模型(Diffusion Model)等进一步发展,在利用文本生成具体三维模型的研究中,部分研究方法根据三维数据集,通过对三维模型的点云、体素网格、三角形网格或隐式函数的表示进行学习,将文本特征映射到自动编码器的特征空间,然后利用隐式解码器生成三维形状(图4)[7][8][9]。

图4 隐式解码器结构[9]
Chen 等人[10]提出了文本描述和三维形状联合表示的问题,通过学习文本描述和彩色三维形状的联合嵌入,利用生成式对抗网络预测彩色的体素网格,能够生成三维形状,但是文本与形状语义仍然存在差距,生成形状不够准确,且在最终的分辨率和纹理上表现不尽如人意。Jahan 等人[11]基于参数化建模的想法将关键词映射到三维形状的子空间,让用户可以通过对子空间的关键词控制形状生成,该研究通过结合学习以标签为条件的潜在向量分布的标签回归网络,以及将采样的潜在向量转换为三维形状生成网络来实现,只能通过关键词生成对应形状。Liu 等人[12]基于隐式场的三维生成方法,对模型的形状和颜色特征进行编码学习,并对输入文本进行编码,根据与形状和颜色特征的对应关系,再通过空间感知解码器对提取到的特征解码,生成具有不同形状和颜色的三维形状,训练数据是针对桌子和椅子的类目,可以生成有一定变化的桌椅模型(图5)。
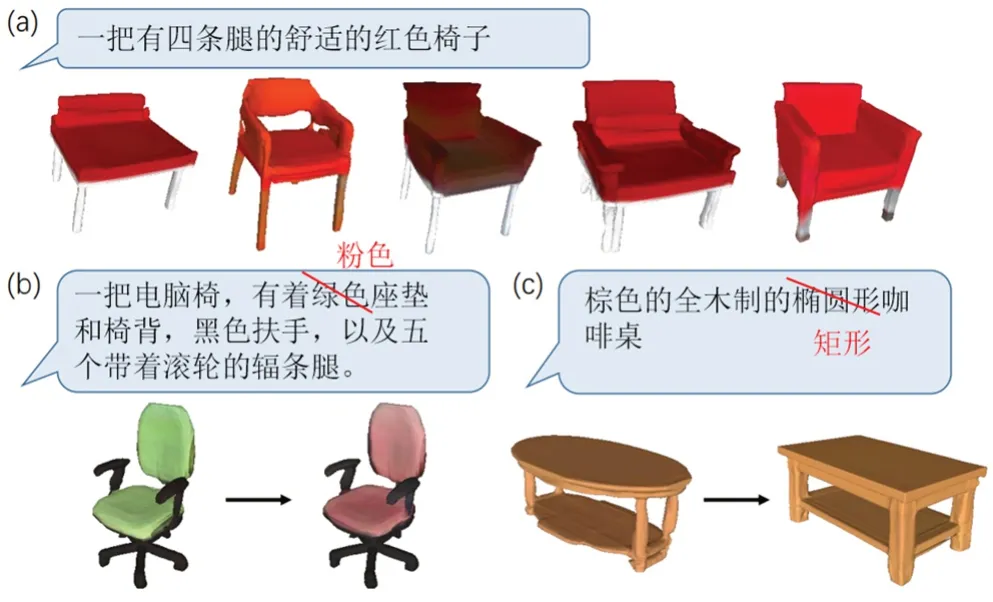
图5 文本生成桌椅类目结果[12]
在这一阶段的研究中,实现了由文本生成三维形状。但由于只能生成较少类别的物体,很难实现多样性的生成结果,难以满足实际应用中对不同三维模型种类的需求,且由于训练数据带来的限制,纹理及贴图的生成仍然需要进一步完善。
3.3 基于NeRF 和CLIP 的Text-to-3D 的方法
近年来,有几项技术为现阶段的Text-to-3D 方法研究拓展了新的方向。
NeRF[13]利用神经网络从稀疏的多视角二维视图中学习连续的三维场景表示,生成任意新视角的渲染视图。其基本原理为将三维场景表示为连续5D 函数,并可以使用多层感知器(Multi-layer Perceptrons, MLPs)表现此映射,从空间位置和观看方向得到该位置的体积密度和发射辐射量,之后进行体渲染(Volume Rendering),最终对得到的值进行合成,得到新视角的图像。NeRF 成为了三维重建和生成的新范式,在三维重建领域有着巨大影响。
Text-to-Image 方法已经有了较为成熟的解决方案,可以结合对比文本-图像预训练模型(Contrastive Language-Image Pre-training, CLIP)对齐多模态的语义信息,基于自回归模型或扩散模型生成多样化的符合文本语义的图像。由文本生成图像的研究有了非常优秀的结果,研究团队开始关注利用Text-to-Image 的相关技术辅助文本生成三维物体。基于CLIP和Text-to-Image 方法的研究减少了训练集不足带来的限制,且在语义关系对齐上有了更好的效果。作为输入条件,文本会让生成物体的形状、颜色、风格更具创造性和多样性。
由于匹配三维模型的文本数量较少,Jain 等人[14]提出了利用CLIP 来生成三维物体且不需要三维数据监督(图6),利用NeRF,根据给定的文字描述与在正则化器指导下对物体的颜色和几何体形状进行学习,通过CLIP 对随机角度渲染得到的物体图像进行评分,来对齐三维模型与文字语义的关系。

图6 Dream Fields 的结构[14]
DreamFusion[15]在Dream Fields 的基础上进行了改进,采用从文本到图像的模型,对不同角度渲染出的图像进行扩散渲染,并用条件图像模型进行重建渲染,预测注入的噪声,使得生成结果更加具有保真性。Magic3D[16]由一个从粗到细的策略租场,利用低分辨率和高分辨率的扩散先验来学习目标内容的三维表示。相比DreamFusion 而言,Magic3D 能够生成更高分辨率的三维模型,在生成效率上也优于DreamFusion。Magic3D 可以给定一个使用文本提示生成的粗糙模型,再通过修改提示中的部分文本,从而基于原本输入微调生成的三维模型。之后使用高分辨率潜在扩散模型(LDM),不断抽样和渲染第一阶段的粗略模型,生成具有细节纹理的高质量三维网格(图7)。

图7 由文本生成的三维模型[16]
Make-It-3D[17]结合Text-to-Image 模型,从单个图像实现三维模型创建,采用两阶段优化管道:第一阶段通过结合参考图像正面视图的约束和新视图的扩散先验来优化NeRF;第二阶段将粗模型转换为纹理点云,并在利用参考图像高质量纹理的同时,结合扩散先验进一步提高真实感。Make-It-3D 提升了纹理的生成质量,在前景视图的呈现上拥有更好的效果,但是在生成背面不可见内容时仍然缺少细节。
4 Text-to-3D 在三维数字内容创建流程中的应用
为了提升三维数字内容的创作效率,已有使用人工智能技术的各类产品及研究融入创建流程中,减少繁琐的重复性工作,为创作者们提供更加自由的创作空间。以传统建模流程为例,自动拓扑、自动展UV、纹理程序化生成已经成为较为成熟的应用,三维艺术家可以利用这些工具辅助建模流程,提升工作效率。ZBrush 在软件中提供了自动布线的工具ZRemesher,用于识别模型的硬表面边缘,并且根据边缘对模型表面的网格进行自动拓扑,生成更少且具有更高精度的多边形,让模型表面的网格分布更加均匀、合理,以此满足高精度模型转低精度模型或动画的需求;针对角色动画制作,也出现了更加便利的方法以取代传统流程。Mosella-Montoro 等人[18]提出了一种新的神经网络架构,该架构通过联合学习网格和骨架之间的最佳关系,自动提取最佳特征来预测蒙皮权重并自动生成更加准确的蒙皮权重。Chen 等人[19]利用深度学习对光学动作捕捉数据进行清洗,可以得到更加准确的动作,从而大大减小清洗数据的工作量。
随着跨模态技术及Text-to-3D 技术的发展,在实际三维内容的创建流程中,文本引导生成也出现了相应应用。本节将从纹理贴图、虚拟角色、三维场景三个方向阐述现有应用情况。
4.1 文本生成纹理贴图
在Text-to-Image 相关技术发展的背景下,作为三维模型的要素之一,纹理贴图也可以通过文本引导生成。如果将纹理贴图仅视作图像信息,则可以利用Text-to-Image 的流程进行生成,生成过程可以划分为两个环节,一是通过Text-to-Image 模型生成无缝颜色贴图,二是根据单张颜色图分析生成对应的法线贴图(Normal Map)、环境光遮蔽贴图(Ambient Occlusion Map)、高度图(Height Map)等。Midjourney 与Stable Diffusion 都可以支持颜色贴图的生成,但仍有可能无法得到无缝效果,且不含其他基于物理渲染(Physically Based Rendering, PBR)的贴图,因此,还需要利用其他软件来进行相应计算。软件Materialize 支持根据导入的图像,调整不同参数,使材质更加接近预期效果。
同时,更加便利的方法是将上述两步直接结合,直接通过文本生成一系列纹理贴图。Poly 支持根据输入的文本在库中搜索符合描述的纹理贴图,如果没有合适的贴图,可以输入文本进行相应纹理的生成,此外,网站提供了有机自然、哑光、有光泽的、织物类等不同材质选择,以便生成更准确的PBR 贴图,使材质更加真实,接近想要的质感。经过测试,在官网输入文本“broken blue tiles”后得到的纹理效果如图8所示。

图8 根据文本生成的纹理贴图[20]
作为实现针对网格模型生成高质量纹理的新方法,Text2Tex[21]利用深度感知扩散模型逐步更新纹理图案,逐步生成多视点的局部纹理,再反向投影至纹理空间。为了消除旋转视点时的拉伸和不连续伪影,该研究提出了一个可以计算可见纹理的法向量以及与当前视图方向间相似性映射的视图划分技术,允许在不同的区域应用不同的扩散强度。实验最终得到了较好的效果(图9)。

图9 根据网格生成纹理[21]
4.2 文本生成数字角色
数字角色是三维数字内容的一个重要分类,无论影视行业还是游戏行业,都对虚拟角色内容有着大量需求。在虚拟角色内容创建流程中,利用文本引导虚拟角色生成,可以更快速地获得虚拟角色,且不需要额外的建模技巧。虚幻引擎(Unreal Engine,UE)发布的MetaHuman 工具为创作者提供创建数字人类角色的完整框架,支持用多种面部混合模式制作需要的面部形状,同时结合肤色和纹理细节,可以实现自动的多层次细节,降低了创建数字人类角色的难度。
AvatarCLIP[22]结合大规模预训练模型,提出了一个可以由文本引导生成虚拟角色的框架,包含形状、纹理和动作生成。AvatarCLIP 生成静态模型的管线分为两个环节:第一环节是由形状变分自编码器(Variational Autoencoder, VAE)构成的码本,用于CLIP 引导的查询,生成粗颗粒度形状模型;第二环节则通过网格模型的多视角图像对NeuS[23]进行优化、形状雕刻和纹理生成。
DreamFace[24]是由文本生成数字角色面部的解决方案,主要包括三个模块:几何体生成、基于物理的材质扩散和动画能力生成。基于此研究,该团队发布了专门针对数字人的生成工具ChatAvatar。该工具生成的三维模型能够将PBR 材质下载至本地,并支持导入到引擎中,其拓扑规整度和绑定能够满足CG 流程要求。使用者可以通过官网和聊天机器人对话得到生成的提示词(Prompt),通过不断的对话式引导丰富提示词,再进行生成,降低了对输入Prompt 能力的要求;系统会根据文字Prompt 快速生成几个备选的几何体模型,用户选择更符合期待的模型后,系统将进一步生成PBR 材质贴图(图10)。目前ChatAvatar 仅支持对人脸的生成,暂时不支持添加发型,但是这已经为Text-to-3D 类型的创作产品提供了一个更加明确的方向。

图10 ChatAvatar 生成样例[25]
DreamAvatar[26]可以从文本提示和形状先验生成高质量的、具有可控姿势的三维数字人类角色,利用一个预训练的Text-to-Image 模型提供二维自我监督,用可训练的NeRF 预测三维点的密度和颜色特征,可以得到更加具有细节和生动的数字角色,经过评估生成结果优于现有方法,生成效果如图11所示。

图11 根据文本引导生成的数字角色[26]
4.3 文本生成三维场景
三维场景的生成可以在电影筹备环节提高动态预览效率,呈现更加准确的空间关系,进而获得更接近成片的视觉效果。三维场景包含的三维数字内容往往非常丰富,相较于独立的三维物体而言,还需要确保各个物体具有合理的空间关系。文本生成三维场景既应该提高创建效率,又应该具备一定的可控性与可编辑性。
正如第三节所述,目前众多有关文本到三维场景的研究是基于已有的模型库,根据对输入文本进行语义分析和特征提取,从模型库提取对应模型,将模型按照符合语义且合理的空间关系组合成三维场景。SceneSeer[27]提出的交互生成系统,允许用户使用简单文本命令添加、删除、替换和操作模型对象,不断迭代细化所创建的场景。
Text2NeRF[28]能够仅从自然语言描述生成多样化和连续的三维场景。首先通过一个文本到图像的扩散模型来生成初始视图,根据此视图,利用基于深度图的渲染方法为NeRF 重建提供不同视角的支持集。在对这个初始化的NeRF 模型进行训练后,引入了一个图像补全的更新策略以扩展新的场景视图,补全缺失部分,之后再更新NeRF。该方法可以生成具有复杂几何结构和精细纹理的三维场景,但其生成的三维场景仍然局限在一定角度内,且没有生成单独三维对象。
Set-the-Scene[29]提出了全局—局部的训练框架,即利用代理对象确定物体生成场景中的空间位置,并可以选择定义为粗模型。每一个对象表示为独立的NeRF,在进行优化时,交叉进行单对象优化与场景优化,创建合理的场景。该系统还提供了修改与编辑方式,可实现编辑代理对象的几何形状,对生成场景进行微调。生成场景合成结果如图12 所示,由代理对象生成更为合理、具备整体性的场景。

图12 场景合成结果[29]
5 总结与展望
AIGC 技术发展是当前的热门话题,尤其是跨模态生成方法能够使用户使用工具时更加轻松,但是在进入实际应用时,仍然存在一些实际问题。近几年出现的Text-to-3D 应用研究,如DreamFusion、Dream Fields 等,为三维生成提出了一个富有前景的应用落地空间,Text-to-Image 模型应用的大范围落地让人们对三维模型的自动生成有了更多期待。
Text-to-3D 在三维数字内容创建过程中已有针对不同使用场景、不同创作环节的技术方案出现,部分纹理生成工具、数字人脸生成产品能够生成较好的结果;场景和数字角色的高效生成可以满足动态预演的基本需求。但目前大部分生成结果的精细程度及过程可控性,还难以达到工业级标准。如今相关研究的技术管线仍然无法很好地融入到电影传统制作管线中,无论是在最终成果还是可用性上,距离实际落地仍然存在一定差距。正如Midjourney 和ChatGPT 是经过了一段较长时间的多种算法积累与发展后,才实现了质的飞跃,成为了能够与实际工作流相结合的工具。相信Text-to-3D 技术也在不断迭代发展中逐渐助力实际创作流程,释放创作者的想象力,提升前期预览效果和后期视效工作效率,使创作者对电影整体制作流程有更好的把握。❖
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
新世纪智能(英语备考)(2018年11期)2018-12-29
创新作文(5-6年级)(2018年11期)2018-04-23
Coco薇(2017年8期)2017-08-03
小学生学习指导(低年级)(2016年10期)2016-12-01
南风窗(2016年19期)2016-09-21
Coco薇(2015年5期)2016-03-29
小天使·六年级语数英综合(2014年3期)2014-03-15
