
深度学习法检测大坝安全监测异常数据
2024-03-11 09:38:52杨关平李登华
水利水运工程学报 2024年1期
杨关平,李登华,丁 勇
(1.南京理工大学 理学院,江苏 南京 210094; 2.南京水利科学研究院,江苏 南京 210029; 3.水利部水库大坝安全重点实验室,江苏 南京 210029)
在大坝安全监测中充分利用监测资料及时评估掌握大坝运行状态,分析处理异常情况是确保大坝正常运行的基础。由于人为误差、外界干扰及设备异常等因素[1],原始监测数据中往往存在异常数据,这会严重影响大坝安全监测分析的准确性。异常数据检测方法主要有:(1)过程线法[2],通过绘制时程曲线,判断有无明显的突变点,此类方法主要用于人工检测。(2)基于统计学的方法(如拉依达、格拉布斯、肖维勒等方法[3]),此类方法简单明了但识别效果一般。(3)基于密度或距离的方法[4](如K-最近邻算法),此类方法从数据距离出发,适合处理简单直观的数据。(4)基于聚类原理的方法(如K-means 算法),通过识别聚类,检测离群点,但此类方法需基于大量的数值计算结果,且受限于局部密度[5]。(5)借助图像技术检测的方法,如Zheng 等[6]通过高斯模糊和二值化处理,提取数据主趋势线识别出监测数据中的异常数据并进行剔除,但此类方法的适用性未得到实际工程的验证。王军等[7]基于卷积神经网络(convolution neural network,简称CNN),利用异常特征片段图像,将图像分为正常形态和异常形态识别异常。此方法需要大量训练数据集,且适用性不高。苏荣等[8]根据异常数据的分布特征,基于边缘检测与方差变点识别异常数据,但此方法仅适用于风功率数据。
针对现有异常数据检测算法的不足,本文参考人工识别异常模式,将数据、图像和深度学习算法相结合,提出基于深度学习的异常检测算法,模拟人工识别异常数据的过程。
1 基于深度学习的异常检测算法
基于深度学习的异常检测算法分为两个阶段,第一阶段进行异常分类,即判断数据中是否存在异常数据;第二阶段进行异常定位,即确认异常数据的具体位置。本文算法的基础是将数据转化为图像形式,通过制作标签数据集,基于深度学习技术对图像进行分析研判,找出图像中的异常,再还原定位原数据中的异常点。其中标签数据集采用自动制作模式,具备反馈机制,可根据分析处理效果进行结果反馈,调整标签数据集,从而优化算法处理结果,实现精细化识别。
1.1 自动生成标签算法
异常数据检测算法的核心为基于深度学习的图像分类和目标识别,而深度学习离不开标签数据集的制作。传统标签制作方式采用Labellmg 方法,需要人工手动标注,存在人为误差、耗时耗力、效率低下等缺点。故本算法采用固化分类和定位两阶段的标签自动制作形式,在标签制作时,从已有数据库提取监测点数据,利用程序快速生成大量的两阶段标签数据集。数据库来源于真实大坝监测资料,为了消除指标间量纲的影响,需先进行数据归一化处理,对任一测点数据,从第1 个数据开始,每100 个数据生成1 张图片,最后不足100 个的单独成图。考虑到分类和定位两阶段的联系,将图像大小统一设为640 像素×480 像素。
分类和定位两阶段的标签数据集不同。一阶段分类中,标签数据集分为有异常图像和无异常图像两类,其中无异常数据图像采用实测并经人工清洗过的监测数据作图,标签含关键字‘N’,有异常数据图像是在无异常数据基础上,根据可能的异常类型人为添加异常作图,标签含关键字‘Y’。该阶段标签数据集样例如图1 所示。

图1 分类标签数据集示意Fig.1 Diagram illustrating the structure of a categorical label dataset
二阶段识别定位中,标签数据集分为图像集和标签位置参数集。以标签形式标记异常数据位置,标签框根据添加的异常数据位置自动定位并选中异常位置的数据,同步生成对应的标签参数文件。根据添加的异常数据横坐标x、 纵坐标y,按式(1)和式(2)转变为图坐标x¯ 及y¯。
标签位置参数包含目标类别和按图像大小归一化后每个标签框中心坐标、标签框所取的高h和宽w。标签标记示意图如图2 所示。
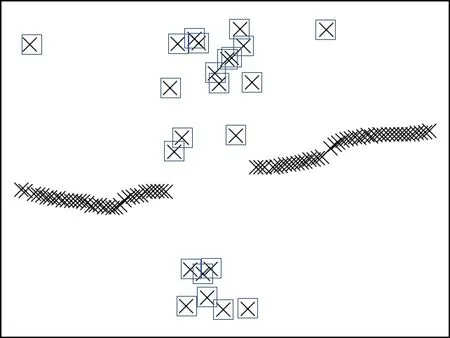
图2 定位标签示意Fig.2 Schematic diagrams of the positioning tag
1.2 异常分类算法
对测点数据生成的数据图像进行分类,无异常数据的图像无需进行异常定位检测,可有效减轻后续异常定位的工作量。本文提出的异常分类算法基于二分类图像算法,其网络结构如图3 所示。该算法在分类器的标签取值上只有2 种,只需预测1 个标签[9]。本文每个样本类别的可能性只有2 种,即“有异常”和“无异常”。

图3 卷积神经网络结构示意Fig.3 Schematic representation of the structure of a convolutional neural network
使用二分类图像算法对自动生成的标签数据集进行训练,获取权重,生成分类模型。训练过程如图4 所示,损失值在1 000 个迭代周期后趋于稳定,且呈现高准确率。同样将待检验数据转化为图像,具体方法同自动标签环节,但不赋予类别。分类模型对图像进行特征提取,经由全连接层,得到维度为1 的值,设为k,按式(3)计算样本是正类的概率hθ(k) , 对hθ(k)以0.5 为界,得到类别0 或1,从而实现对异常数据的分类。
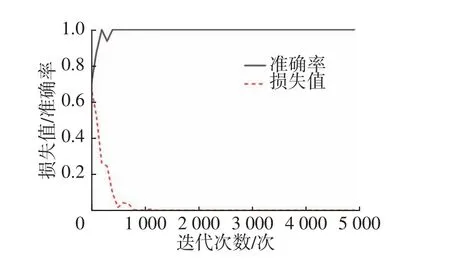
图4 卷积网络训练过程Fig.4 Training process of a convolutional neural network
经分类阶段筛选,如果存在异常则进行二阶段异常定位,实现对异常值的位置定位;如果无异常,则等待最终数据汇总。
1.3 异常定位算法
异常定位阶段采用YOLOv5 算法,此算法是一种单阶段目标检测算法[10],网络结构如图5 所示。本文算法中,网络输入为存在异常数据的图像,通过输出层给出异常数据的坐标位置。
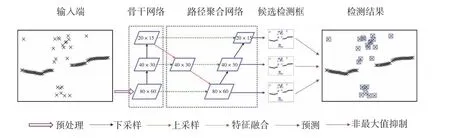
图5 YOLOv5 网络结构图Fig.5 Diagram depicting the network structure of YOLOv5
使用YOLOv5 算法对自动生成的标签数据集进行训练,生成定位模型。训练过程如图6 所示,精准度及召回率波动小且均接近1,可认为模型达到稳定收敛,训练效果较好。使用定位模型识别有异常数据的图像,定位图像中异常数据的位置,再还原找到该异常数据,最后对所有检测结果进行汇总,从而找到此测点数据中所有的异常数据。
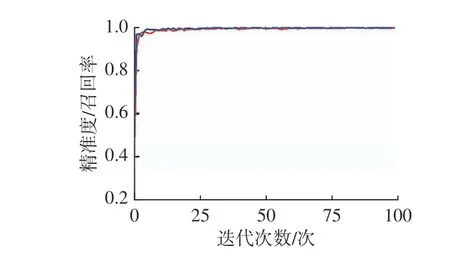
图6 YOLOv5 网络训练过程Fig.6 Training procedure for the YOLOv5 neural network
异常数据识别定位效果如图7 所示。图7(a)为待检测的数据图,经模型定位,得到图7(b)所示的定位图,包含定位给出的标签类别、对应概率及框住目标的标签框。

图7 识别定位示意Fig.7 Illustration representing the schematic diagram of identification and positioning
1.4 反馈机制算法
深度学习的检测效果在很大程度上取决于标签数据集的制作。基于标签数据集制作的多样性,可根据检测效果不断调整重新制作标签数据集,再训练模型,以实现不同检测效果。最典型的可对异常数据与正常数据的偏离大小进行人为干预,对于偏离程度在可接受范围内的,可认为是正常数据,在标签制作时调整此类数据类别,实现对异常数据识别权重的更新。
大坝不同测点数据具有变化趋势、规律不一致等特征。对不同类型数据的检测结果进行综合分析评价,可采取不同尺度的标签形式,可调整制图数据的数量,同时在识别定位标签中将堆积数据以段的形式作为标签。即通过增加标签数据集的多样性,可明显改善算法对不同类型数据的检测效果,使得算法具备优秀的反馈机制。
2 算法验证试验
2.1 试验设计
本文数据来源于新疆某面板堆石坝近10 年的实测资料,包括库水位、渗压、应力应变等。该大坝布置各类测点约800 个,包含测缝计、土压力计、渗压计、水平位移计等近20 类不同监测仪器,采取人工监测和自动化监测相结合的方式,获取丰富的大坝安全监测数据。结合实际大坝监测数据特征,将试验数据分为趋势性数据、周期性(包含季节性)数据及不规则数据。其中趋势性数据采用固定式测斜仪数据,周期性数据采用大坝单向测缝计数据,不规则数据采用大坝渗压数据。
试验数据采用真实数据,时间序列长度均取5 年。数据均经专业人员检查处理,数据集中无明显异常数据。考虑大坝实际所受环境、受力特征的复杂性和不确定性,为更好探究本文算法对各类型异常值的检测效果,在大坝真实测点数据的基础上,随机加入多种模式异常值。大坝异常数据出现的方式主要为孤立和连续两类,因此将添加位置分为孤立、连续及混合3 种。考虑大坝数据的基本异常率及更好检验算法效果的目的,将添加数量设为2%、5%及10%。最后参照拉依达准则阈值区间确定规则,通过以不同标准差倍数确定添加数值的大小:通过计算原数据标准差,小数值添加为在原数据基础上加上1 倍标准差得到异常添加序列。中等数值添加、大数值添加及混合数值添加分别对应1~2 倍标准差、2~3 倍标准差及1~6 倍标准差。
通过添加位置、添加数量及添加数值大小的不同组合,生成多种形式异常数据,符合大坝安全监测异常数据出现的不确定性,可更全面检验本文算法。
2.2 试验结果分析
为直观评价算法异常检测效果,借鉴图像分类处理评价指标,将查准率(P),查全率(R)及准确率(A)作为本文算法评价指标。具体公式如下:
式中:TP为检测到的正样本;FP为未检测的正样本;FN为未检测的负样本;TN为检测到的负样本。考虑本文方法场景,将随机添加的异常数据视为正样本,序列中的剩余样本视为负样本。
为简便起见,本文后续将趋势性数据称为A 类、将周期性数据称为B 类及不规则数据称为C 类。小数值添加以‘小’表示,中等数值添加以‘中’表示,大数值添加以‘大’表示,混合数值添加以‘混’表示。异常出现位置统一采用混合添加,添加数量统一采用大量添加,添加数值分小、中、大、混4 类。因此可组合出12 种添加模式。考虑充分检验算法适用性及稳定性,每种添加模式下,均多次生成异常并检验,记录每次的P、R、A指标。本文每种模式采取100 次试验。A 类数据的小、中、大及混添加模式,简记为A1、A2、A3 及A4,B、C 类数据同理简记。
将本文算法与业界常用的绝对中位差算法和四分位算法进行比较,各种模式下的查准率、查全率及准确率见图8~10。
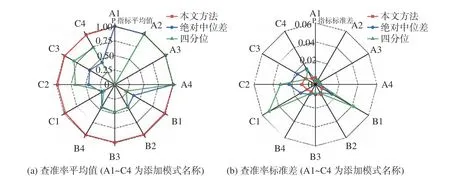
图8 各类试验的查准率Fig.8 Evaluation rates across diverse tests
由图8 可知,本文算法较传统算法,在A 类数据上,查准率区别不大,基本都为1。在B、C 两类数据上,本文算法的查准率平均值均达到0.97 以上,而两种传统算法查准率平均值大部分小于0.5,因此本文算法效果提升明显。而在B、C 两类数据上查准率标准差中,本文算法取值均位于千分位,而两种传统算法查准率标准差取值出现过多百分位的情况,因此本文算法具有更好的稳定性。
由图9 可知,本文算法对于A、B、C 三类数据,查全率平均值均达到0.97 以上,而两种传统算法对各类数据的查准率平均值大部分低于0.90。对比本文算法与两种传统算法的查全率标准差可知,本文算法稳定性更好。尤其在小异常数据处理时,优势很大。

图9 各类试验的查全率Fig.9 Examine the rates for each test category
由图10 可知,本文算法对于A、B、C 三类数据,准确率平均值均达到0.99 以上,而两种传统算法对各类数据的准确率平均值大多低于0.90,故本文方法检测效果更佳且稳定。
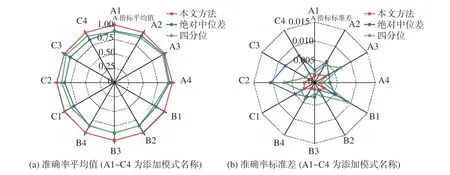
图10 各类试验的准确率Fig.10 Accuracy metrics for individual test categories
通过对试验数据查准率、查全率及准确率的综合分析,说明本文算法较传统的绝对中位差算法和四分位算法,具有更好的检测效果。本文算法可有效识别小数值添加异常数据,而传统方法难以识别此类异常数据。本文算法在对趋势性及周期性数据进行异常数据识别时,可有效找出数据主体趋势,准确区分出正常数据与异常数据。在处理不规则数据时,也可找出异常数据。
3 结 语
将数据检测、图像识别及深度学习相结合,提出了基于深度学习的大坝安全监测异常数据检测算法。本算法通过将数据转化为图像,并通过异常分类和异常定位两阶段进行异常数据检测。 在标签数据集制作环节,提出了自动标签生成算法,具备更高标签制作效率的同时,又确保了定位准确性。基于深度学习算法,保证了本文算法具备良好的反馈机制,可根据处理效果评价反馈,调整模型权重,从而调整检测效果。也可根据使用场景,按实际需求出发,个性化设计,具有较高的实用性,优于传统方法的简单数值处理。
猜你喜欢
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
百科知识(2018年6期)2018-04-03 15:43:54
现代电子技术(2017年23期)2017-12-20 13:23:31
计算机应用(2016年10期)2017-05-12 11:02:20
少儿科学周刊·儿童版(2016年4期)2017-02-08 13:49:11
少儿科学周刊·儿童版(2016年4期)2017-02-08 13:48:12
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
中国三峡(2013年11期)2013-11-21 10:39:18
