
基于信息融合和多粒度级联森林模型的挖掘机作业阶段智能识别
2024-03-09 02:30苏德赢王少杰卜祥建饶红艳
工程设计学报 2024年1期
苏德赢, 王少杰, 卜祥建, 饶红艳, 侯 亮
(厦门大学 萨本栋微米纳米科学技术研究院, 福建 厦门 361102)
挖掘机的发动机通常被设定为轻载、经济和重载3种工作模式,并在不同工作模式下设定不同的工作挡位。在挖沟、平地等不同作业工况下,挖掘机操作者根据经验调整发动机的工作模式和工作挡位,以实现挖掘机的节能控制[1]。这种节能方式较为粗放,存在盲目性,节能效果较差。若能根据挖掘机的实际作业阶段来调节发动机的工作点,使得工作系统实现“所需即所得”,将会带来较好的节能效果。准确、快速地识别挖掘机的作业阶段是实现这种节能控制方式的前提。目前,针对挖掘机工作状态智能识别的研究主要借助机器视觉和运行数据分析。Bao等[2]采用决策树方法分析挖掘机的空间运动学特征,成功实现了挖掘机工作状态的识别,准确率达到88.91%;Kim 等[3]基于机器视觉技术,分析了挖掘机与自卸卡车的交互操作,然而机器视觉检测效果易受到物体遮挡、视角和尺度偏差等影响[4],在挖掘机复杂、恶劣的作业环境下,机器视觉检测可靠性较低;柳齐[5]利用挖掘机先导压力和主泵出口压力对挖掘机挖掘和平整2个工况进行了识别,但是未进行作业阶段的识别;Ahn等[6]通过收集挖掘机在不同模式下的三轴加速度信号,识别了挖掘机的运行模式。这些研究侧重于挖掘机的运行工况和工作模式,尚未涉及作业阶段的智能识别。基于主泵压力与作业阶段的关系,冯培恩等[7]、黄杰等[8]和Shi 等[9]分别采用DAGSVM(directed acyclic graph support vector machine,有向无环图支持向量机)、PCA-SVM(support vector machine based on principal component analysis,基于主成分分析的支持向量机)、LⅠBSVM(library for support vector machines,支持向量机库)、BPNN(back propagation neural network,反向传播神经网络)和LR(logistic regression,逻辑回归)等机器学习方法对挖掘机作业阶段进行了识别,识别准确率分别达到95.00%、89.36%、94.64%、89.64%和81.79%。Shi等[10]将先导压力信号与LSTM (long short-term memory,长短期记忆)模型结合,实现了挖掘机作业阶段的识别,识别准确率达到93.21%。在上述研究中,部分识别方法的识别准确率已经超过了90%,主要采用有限的运行数据会导致数据信息不充分。主泵数据的识别方法存在时间延迟。基于先导信号的识别方法存在难以识别、操作手误等问题。这些不足都会降低作业阶段智能识别方法的可靠性。
综上所述,基于机器视觉和运行数据的识别方法有其局限性,而且为了提高识别可靠性,需要增加数据信息。但过多的数据会造成信息冗余、识别成本提高以及识别效率降低等问题[11],因此需要选择合适的方法进行数据信息的融合。信息融合包括数据级融合、特征级融合和决策级融合[12]。深度森林模型又称多粒度级联森林模型,在处理高维数据时效率高、识别效果好,在识别问题研究中被广泛使用[13]。通过结合数据融合技术和多粒度级联森林模型,可以从数据特征和识别模型2个方面有效避免挖掘机作业阶段识别研究中数据冗余的问题,提高挖掘机作业阶段识别的可靠性。
本文提出了一种基于信息融合和多粒度级联森林模型(information fusion and multi-granularity cascade forest model,ⅠFMCFM)的挖掘机作业阶段智能识别方法。首先,根据挖掘机作业的特点,设计了挖掘机运行数据采集试验,以获取智能识别研究所需的数据;其次,介绍了信息融合技术和多粒度级联森林模型的原理;最后,基于运行数据开展了挖掘机作业阶段的智能识别研究,并与其他识别方法进行了对比分析。
1 挖掘机运行数据采集与数据特征筛选
挖掘机运行数据采集须符合GB/T 7586—2018《土方机械 液压挖掘机 试验方法》的要求,试验场地为某挖掘机生产企业的标准试验场。样机采用21吨级履带式挖掘机,作业方式为90°甩方,作业对象为原生土。试验时分别由2名操作手在20 min内操作50次,共采集100次循环作业数据。挖掘机运行数据采集现场如图1所示。试验中主要采集压力、流量、角度和转速等运行数据,涉及主泵、液压油缸、回转马达和发动机等工作元件,共有25个采集通道。需采集的挖掘机运行数据如表1所示。
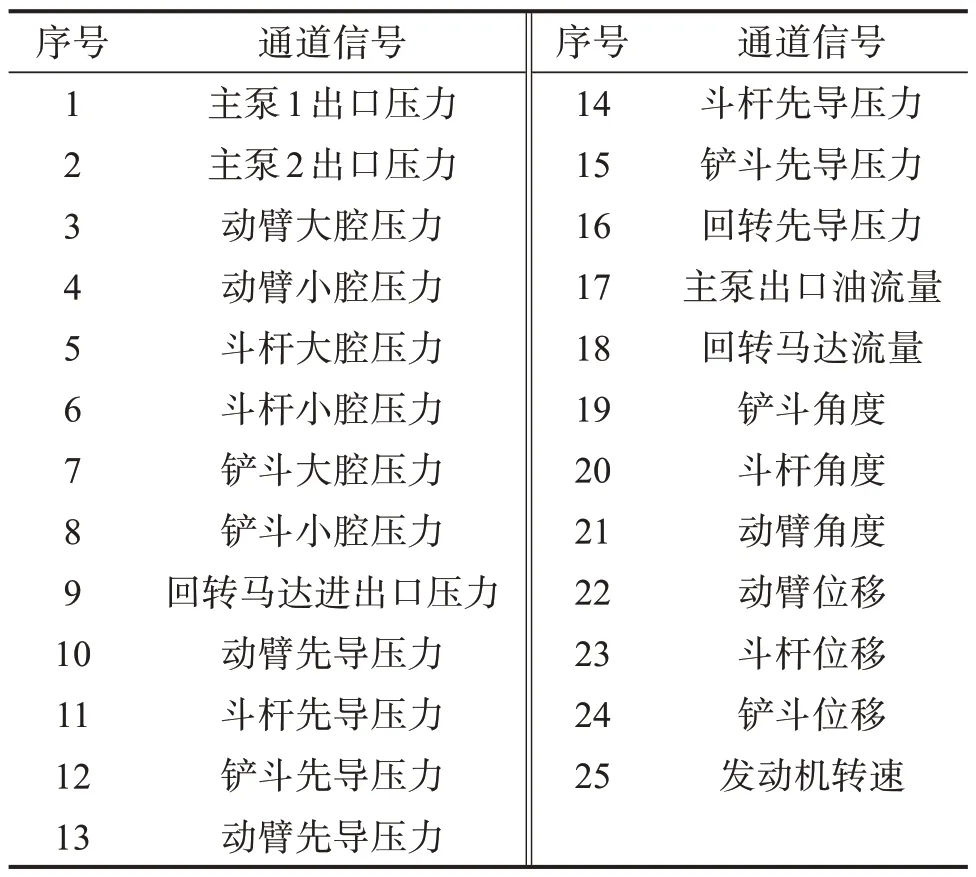
表1 挖掘机的运行数据信息Table 1 Operation data information of excavators

图1 挖掘机运行数据采集现场Fig.1 Experiment on data collection of excavator operation
在运行数据采集过程中,由于试验环境的影响,试验数据可能会出现尖峰和杂波。对数据进行加权均值滤波处理,以消除数据杂波的干扰。数据滤波前后主泵1 出口压力和动臂大腔压力如图2所示。
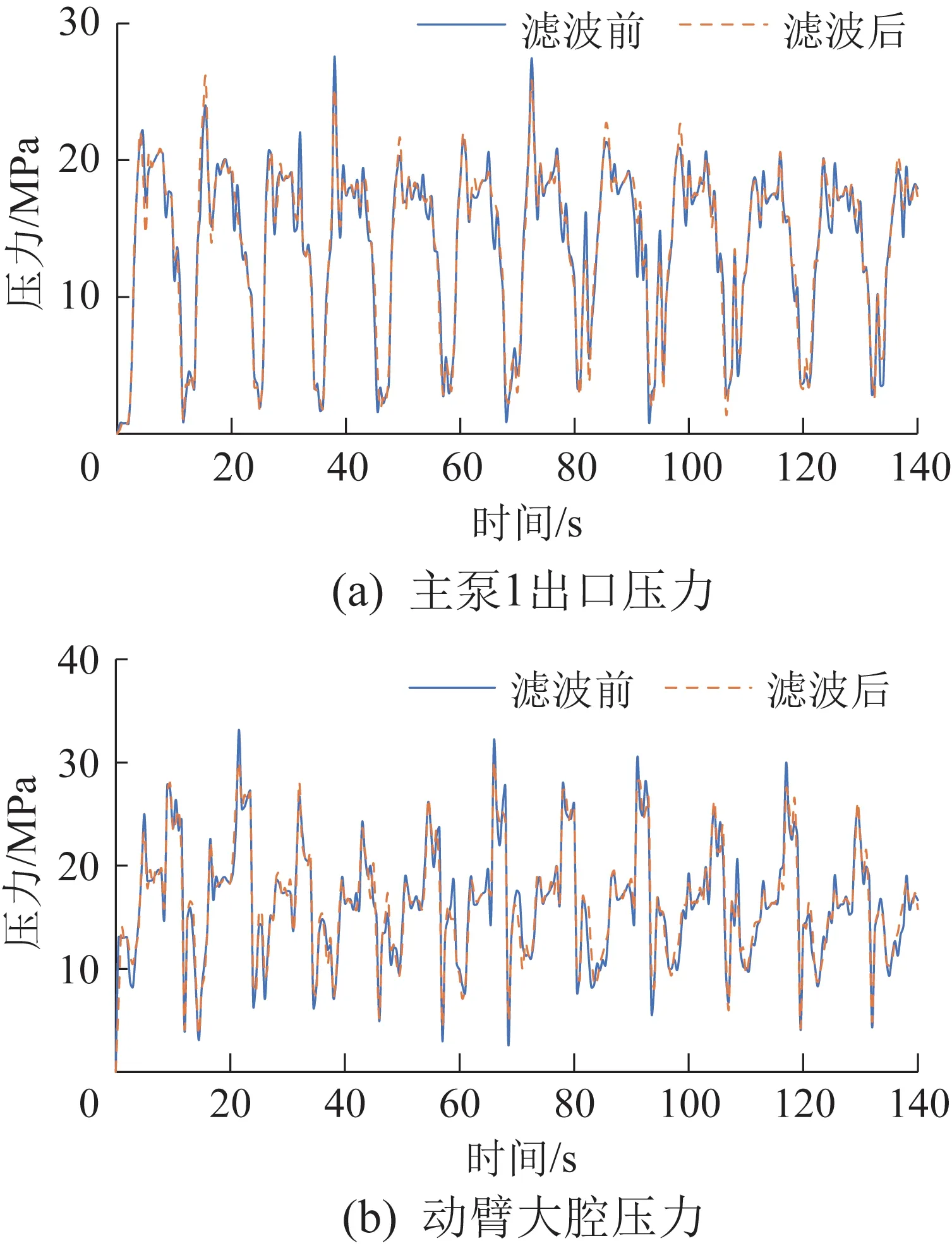
图2 数据滤波前后主泵1出口压力和动臂大腔压力Fig.2 Main pump outlet pressure and boom chamber pressure before and after data filtering
挖掘机作业划分为挖掘、提升回转、卸料、空斗返回和挖掘准备等5个阶段。各阶段存在明显的特点,例如挖掘、卸料阶段和铲斗相关,提升回转和空斗返回阶段仅有回转马达工作。根据这些特点对运行数据进行作业阶段划分,制作样本标签。以主泵压力和铲斗油缸压力为例,其在1个作业循环内的划分如图3所示。
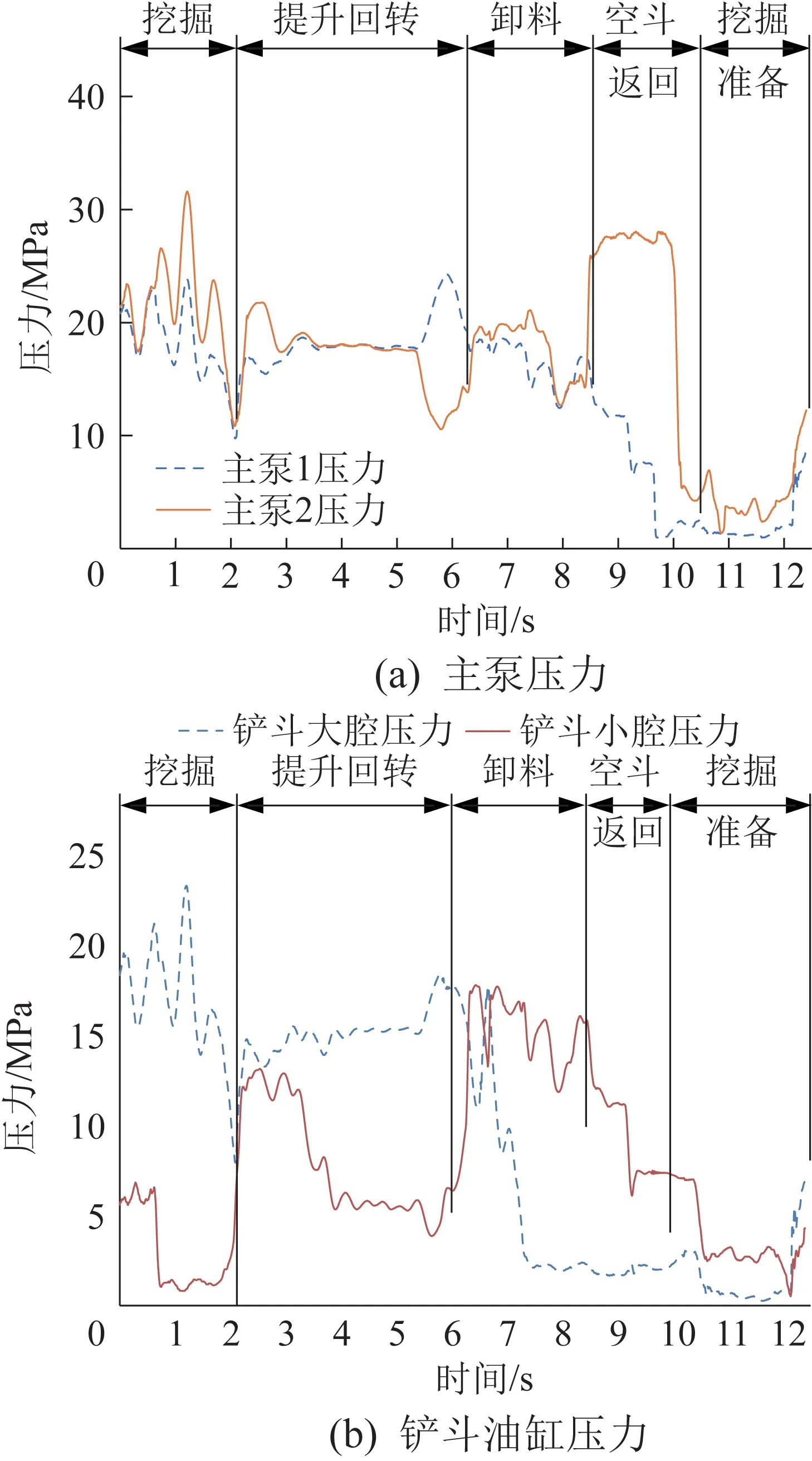
图3 主泵压力和铲斗油缸压力的划分结果Fig.3 Division results of main pump 1 pressure and bucket cylinder pressure
完成运行数据的划分后,需要对每个作业阶段的数据进行时域特征提取。这些时域特征包括均值、峰值、峰-峰值、整流平均值、均方根值和标准差等。对每个通道的数据都计算6个特征值,初步特征集总计6×25=150维。本文采用随机森林模型对初步特征进行重要度评估,并选择前9个重要特征进行组合,构建新的特征集。重要特征筛选结果如表2所示。在这9个特征中,动臂先导压力、斗杆小腔压力、斗杆先导压力和铲斗先导压力的相关特征占比较高,而其他特征与马达流量和动臂角度有关。这9个特征包含了更多的作业阶段信息,使模型识别结果具有较强的可靠性。

表2 挖掘机运行数据特征的筛选结果Table 2 Screening results of excavator operation data characteristics
2 挖掘机作业阶段识别方法
2.1 信息融合技术
在多次加工和抽象的过程中,技术是基于多个信息源的信息融合是获取更高层次信息的处理技术。它能够整合不同类型的信息,实现对信息的深入挖掘和使用。其处理流程是多级的,每一级的处理都是对上一级信息进行加工和转化。在数据级融合、特征级融合和决策级融合的过程中,初始数据、数据特征和决策结果分别是整合对象。数据级融合是信息融合技术中最基本的融合方式,它将不同来源、同一类型的数据进行简单融合,不对其进行任何处理。数据级融合的优点是可以获取较为全面的信息,融合后的信息量较大;缺点是未经处理的原始数据可能含有噪声或冗余信息,对融合结果会产生不良影响,且在合并大量数据时耗时较长。特征级融合属于第2层次的融合,即对初始数据进行特征提取,提取出的特征直接或经过筛选后构成新的特征向量。特征级融合突破了数据级融合的信息必须为同一类型数据的限制,并实现了信号压缩,从而方便传输和处理。决策级融合则对每个初始数据进行特征提取、识别和决策,将不同的决策结果进行融合并形成最终的决策向量。相比于数据级融合和特征级融合,决策级融合的抗干扰能力更强,分类效果更加精确。
本文通过信息融合技术来实现挖掘机运行数据的融合。通过融合分类器的决策结果和筛选后的数据特征来形成新的特征向量。其融合过程如图4所示。

图4 挖掘机运行数据融合过程Fig.4 Process of data fusion for excavator operation
在挖掘机运行数据融合中,分类器分别采用随机森林、多层感知器、SVM和K近邻算法。各分类器的工作原理如下。
1)随机森林。
随机森林是一种集成学习方法,通过多个决策树投票或平均的方式来进行预测。随机选择数据集的一部分和特征的子集,并根据这个数据集和子集构建一棵决策树;之后,通过投票的结果来进行分类预测。
2)多层感知器。
多层感知器是一种人工神经网络,由多个神经元层组成,每个神经元层都与前一层的神经元相连接。它包括输入层、隐藏层和输出层,信息从输入层传递到隐藏层,然后再传递到输出层。在每个神经元层中,输入被加权并传递给激活函数,以产生输出。通过反向传播算法,多层感知器调整权重,以最小化预测误差。
3)SVM。
SVM是一种监督学习算法,用于分类和回归任务。其目标是找到一个最优的超平面,以最大化2个不同类别数据点之间的间隔。SVM通过将数据映射到高维空间来实现非线性分类,然后在该空间中找到最佳的分割超平面。支持向量是距离分割超平面最近的数据点,它们决定了超平面的位置。
4)K近邻算法。
K近邻算法是一种基于实例的学习方法,根据样本的相似性进行分类或回归。它基于一个简单的思想,即将与新样本最相似的K个训练样本的标签用于预测新样本的标签。对于分类,K近邻模型计算新样本与训练数据中所有样本的距离,然后选择与新样本距离最近的K个样本,最终的分类结果是这K个样本中最常见的类别;对于回归,取K个最近样本的平均值作为预测结果。
以挖掘机运行数据特征作为输入,分别对上述4种分类器进行训练,获得4个模型的决策结果,即挖掘机5个作业阶段的类别概率向量,总计4×5=20个。将类别概率向量与通过随机森林模型筛选得到的9个挖掘机运行数据特征进行拼接,得到29维的预测特征向量,将它作为多粒度级联森林模型的输入。
2.2 多粒度级联森林模型原理
多粒度级联森林模型由多粒度扫描结构和级联森林结构组成,是一种不同于深度神经网络的深度模型,具有参数量较少、训练难度低、数据需求量小等优点。多粒度级联森林模型原理如图5 所示。多粒度扫描结构采用类似卷积神经网络的若干个滑动窗口进行滑动采样[14],可以获得多个相互联系又具有差异性的子样本;采用随机森林和完全随机森林分类器对子样本进行训练,得到类别概率向量,类别概率向量与运行数据特征拼接,形成最终的转换特征。例如:对t维的原始数据特征向量用宽度为w维、步长为s的滑动窗口进行特征子样本的划分和获取;通过随机森林和完全随机森林分类器对每个特征子样本进行训练,每个分类器训练后得到一个c维的类别概率向量,共获得个类别概率向量;将类别概率向量拼接,即可以获得维的拼接特征向量。

图5 多粒度级联森林模型原理Fig.5 Principle of multi-granularity cascade forest model
多粒度级联森林模型采用与深度神经网络(deep neural networks,DNNs)类似的层级结构,即级联森林结构,其中每级的输入都包含了上一级随机森林模型的输出。级联森林结构的初始输入特征为经多粒度扫描得到的拼接特征,拼接特征将与每一级随机森林模型的输出进行二次拼接,二次拼接后的特征将作为下一级随机森林模型的输入,逐级传递,最终获得预测结果。级联森林结构的每一级包含若干个随机森林和完全随机森林分类器[15],每级2种不同的森林分类器增强了模型集成的多样性,可以充分利用特征的差异来更好地表征特征信息。
3 实 验
3.1 模型训练结果
挖掘机9个重要运行数据特征对应的原始数据如图6 所示。共包括6 个通道的数据,相比于原有的25 个通道有很大的降低。如前所述,将特征信息筛选和融合后获得的29 维拼接特征向量输入多粒度级联森林模型,开展挖掘机作业阶段的智能识别。

图6 挖掘机9个重要运行数据特征对应的原始数据Fig.6 Original data corresponding to 9 important operational data features of excavators
多粒度级联森林模型的训练过程如下:将29维预测特征向量输入多粒度扫描结构,拼接形成一个维新特征向量,并将它输入级联森林结构,与每一级森林模型输出的类别概率向量进行拼接;以此类推,上一级的输出与该特征拼接后作为下一级的输入,将最后一层输出的最大值作为最终的预测结果。为了减弱过拟合现象,每个随机森林模型都采用五折交叉验证。当验证集的准确率不再提升时,模型停止训练。多粒度级联森林模型的参数设置如表3所示。不同的滑动窗口和步长可以从输入数据中提取多尺度的特征信息。步长越小,样本集的多样性越高,模型的泛化能力也就越强。

表3 多粒度级联森林模型的参数Table 3 Parameters of multi-granularity cascade forest model
共采用140个数据集样本,将训练集的比例分别设定为80%,60%,40%,20%和10%,进行挖掘机作业阶段智能识别。不同训练集比例下的识别结果如表4所示。由表可知:随着训练集比例的提高,模型的识别效果越来越好;当训练集的比例为80%时,准确率、召回率和F1值(精确度和召回率的调和平均数)分别为95.00%,95.17%和95.02%,模型识别效果最好。
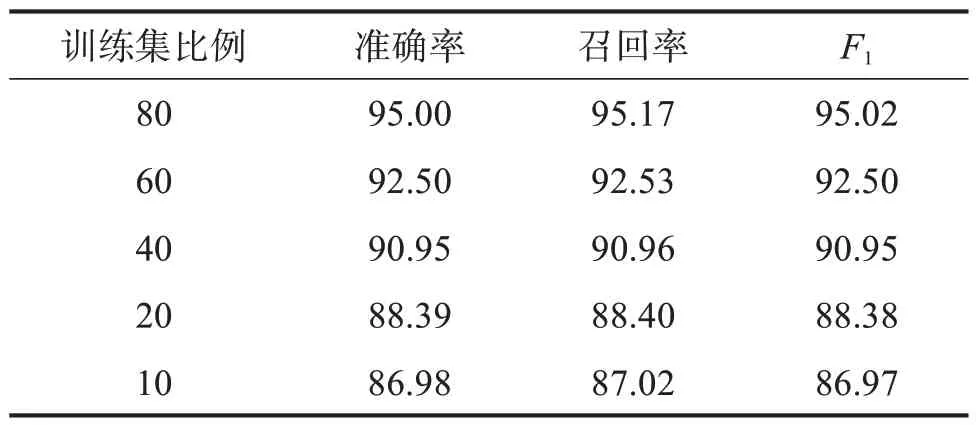
表4 不同训练集比例下挖掘机作业阶段的识别结果Table 4 Recognition results of excavator operation stages under different training set proportions%
基于前述分析,选取80%的样本作为训练集,20%的样本作为测试集,对模型的性能进行评估。模型对挖掘机不同作业阶段的识别结果如表5所示。由表可知:模型对挖掘准备阶段的识别效果最佳,其准确率达到了100%,F1值也较高,识别结果更为可靠;在提升回转阶段,准确率仅为90%,识别效果最差。
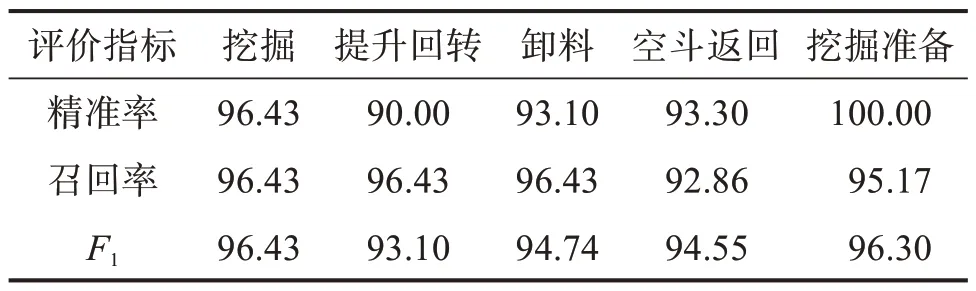
表5 IFMCFM模型的识别结果Table 5 Ⅰdentification results of ⅠFMCFM model%
3.2 不同方法对比
在相同的数据样本下,将ⅠFMCFM模型对挖掘机不同作业阶段的识别结果与DAGSVM[7]、PCASVM[8]、LⅠBSVM[9]、LSTM[10]模型进行对比,结果如表6 所示。由表可知:相较于其他识别模型,ⅠFMCFM 模型表现出更加稳定的识别结果,5 个作业阶段的评价指标值较接近,其整体性能最佳;LⅠBSVM在挖掘、提升回转和挖掘准备阶段表现优秀,各项评价指标值较高;DAGSVM 的识别效果仅次于ⅠFMCFM模型;PCA-SVM的识别效果较差,各项评价指标均明显低于其他模型。
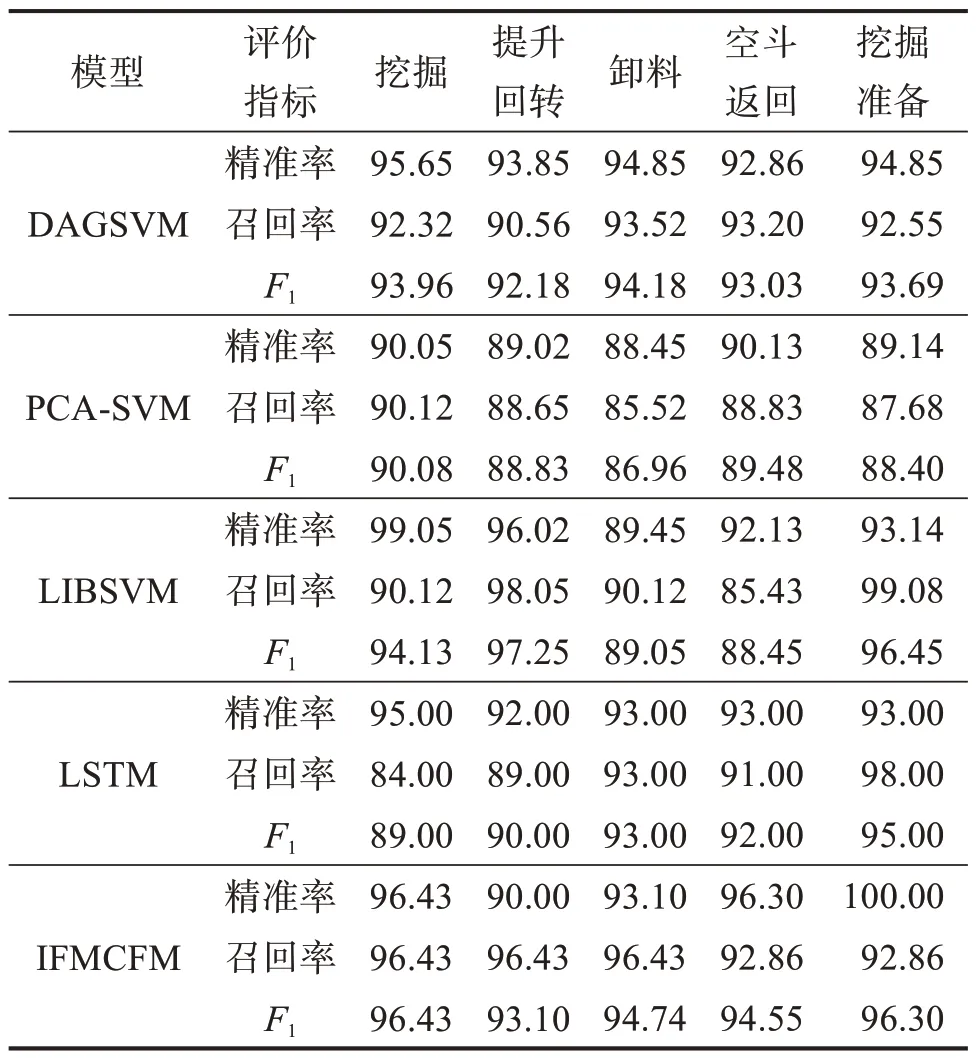
表6 各模型的识别结果Table 6 Ⅰdentification results of each model%
4 结 论
本文基于信息融合技术和多粒度级联森林模型开展挖掘机作业阶段的智能识别研究,以解决现有识别方法可靠性低的问题。获得以下研究结论:
1)基于信息融合技术,通过多种分类器获得挖掘机作业阶段智能识别的类别概率向量和高重要度特征,并将两者拼接,形成新的识别特征,有效避免了数据冗余的问题。
2)对ⅠFMCFM 进行训练和测试,当训练集比例为80%时,模型识别的准确率、召回率和F1指标分别为95.00%,95.17%和95.02%,识别效果较优。
3)相比于其他识别模型,ⅠFMCFM 的识别准确性和可靠性最高。
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28
南京大学学报(自然科学版)(2021年1期)2021-01-30
装备制造技术(2020年4期)2020-12-25
电子制作(2016年15期)2017-01-15
系统工程与电子技术(2016年12期)2016-12-24
系统工程与电子技术(2016年2期)2016-04-16
有色金属设计(2015年2期)2015-02-28
电测与仪表(2014年1期)2014-04-04
电测与仪表(2014年1期)2014-04-04
筑路机械与施工机械化(2014年10期)2014-03-01
