
基于综合模糊证据推理的路线方案比选研究*
2024-03-07 03:01左博睿
公路与汽运 2024年1期
左博睿
(中铁四院集团 西南勘察设计有限公司, 云南 昆明 650220)
路线走向是道路设计阶段重点考虑的关键环节,须综合考虑工程因素、社会经济因素、环境因素等[1-3],存在关键节点间多路线方案比选问题。路线比选是多属性决策问题[4-6]。一般通过建立评价指标体系对方案进行决策,如刁万名、赵庆伟、谢长洲等采用不同指标对路线方案优劣进行对比,确定了最终路线方案[7-9]。该方法虽然考虑了多指标问题,但方案的实际比较过程仍然是主观、模糊的,方案优劣主要基于定性分析。为解决这一问题,万冬华等通过专家打分获取各指标数值,采用投影法,通过对比分析备选方案各指标在理想方案上的投影值得到方案优劣排序,确定最佳方案[1];张霖波等构建公路路线方案多层次指标体系,采用模糊综合评价方法得到了定量分析结果[10];程轩等针对评价指标权重问题,采用IAHP-EWM得到指标相对权重,结合模糊综合评价法计算得到了路线方案的最终排序结果[11]。引入模糊方法可在一定程度上解决定性、定量指标共存的问题,但现有研究基于层次结构,难以结合工程实际构建有针对性的评价指标体系,多项目采用同一评价指标体系易导致评估失效。此外,指标间未能考虑同一尺度描述的问题,忽略了部分方案的部分指标可能由于各类客观因素未能在对应深度有效评估,只能以未知形式呈现的客观现实。如何构建合理的指标体系,并考虑定性、定量、未知信息共存的制约,在统一描述框架下有效聚合方案评估指数,进而得到方案优劣排序有待研究。
模糊证据推理技术是一种基于证据理论的多属性决策方法,其最大特点是在描述不确定性信息时以区间估计代替点估计,在处理路线比选中多类型数据收集、不确定性信息融合问题方面具有较好的准确性[12-15]。G1赋权法是在层次分析法的基础上提出的主观赋权方法,具有简易、适用性广泛等优势,可有效评估指标相对重要程度进而得到指标权重[16]。本文结合德尔菲法、G1赋权法、模糊证据推理技术,提出一种路线方案比选评估模型,针对公路项目的特点建立指标体系,并经过模糊信度结构建立、不确定性信息融合得到有量化数值的方案优劣排序,为路线方案比选提供决策依据。
1 综合模糊证据推理方法
1.1 方案比选指标体系的建立
目前通常采取固定的指标无差异评估各项目路线方案。然而路线方案的形成往往具有自身特点,如是否穿越敏感地区(水源地、基本农田等限建地区)和已规划的地块等、路线与重要构筑物(管网、电网等)的协调程度等,这些影响因素并非方案被否定的强制性因素,却是须重点考虑的关键因素,难以以一套无区别的指标体系来评价。
德尔菲法可有效考虑项目特征,得到较为合理的评估指标体系。因此,基于德尔菲法针对项目特点建立差异化的指标体系。流程如下:1) 在综合现有研究成果的基础上,针对项目特点,由专家群提出重要指标,并组合为基础指标库。2) 通过问卷调查向专家征询意见,对既有指标进行增减。3) 重复步骤2,直到形成一致性较高的专家意见,结束问卷调查,形成n项评价指标体系[17]。
令最终得到的指标体系为R={r1,r2,…,rn},其中含有定量指标和定性指标。基于G1赋权法完成对各因素重要性的权重设置,主要过程如下:


Wk-1/Wk=pk(k=n,n-1,…,3,2)
(1)
(3) 计算评估条件权重系数。按式(2)、式(3)计算评估条件的权重,按式(4)计算最终权重。
(2)
Wk-1=pkWk(k=n,n-1,…,3,2)
(3)
W={wi,i=1,2,…,n}
(4)
式中:wi为指标体系R中第i项指标的权重。
1.2 模糊信度结构建立
为在统一的描述框架中描述各指标属性,建立模糊信度结构(Fuzzy Theory and Belief Structure Model Combined Approach,FBS)。将模糊信度结构定义为反映属性值强弱的统一描述框架,框架中假设指标有N级强弱等级,并确定其相关隶属度函数。模糊指数水平LFIL={LFIL1,LFIL2,…,LFILn,…,LFILN},每个等级LFILn以三角或梯形模糊数描述。当相邻等级信息重叠时,各LFIL之间存在交互作用,假设只有相邻LFIL相交,则可用LFILn,n+1表示LFILn与LFILn+1的交,μ(i)表示隶属度函数的分布。模糊因素评估等级见图1。参考文献[15],模糊信度结构可描述为:
FBS(R)={(LFILn,LCLn) (n=1,2,…,N)}
(5)
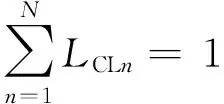

图1 模糊指标评估等级
FBS模型可有效描述评估过程中信息客观存在的不确定性。
1.3 数据预处理

(6)
N=NR时,δn1,n2=1,可得:
(7)
数据为定量数据时,须将数据进行无量纲化处理并映射到模糊信度结构中。考虑到传统归一化方法可能由于数据结构不合理拉伸评估区间,针对选线过程中指标值往往存在阈值(某方案指标值超过一定程度即认为方案存在不合理性而拒绝该方案)的特点,提出一种改进的指标数据映射转换方法,其中成本型指标按式(8)进行归一化,效益型指标按式(9)进行归一化。
(8)
(9)


(10)
(11)
1.4 信息融合
通过数据预处理得到选线评估数据的模糊信度结构模型后,按下式计算各指标的mass数(基本可信度):
(12)

(13)
(14)
(15)


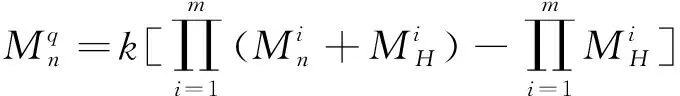
(16)
(17)
(18)
(19)
(20)
(21)

(22)
(23)
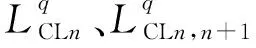
1.5 模糊交集分配
在获取各等级信度值后,将LCLn,n+1合理分配到模糊影响等级(LFILn,LFILn+1) 上。运用文献[14]中的分配方法,将LCLn,n+1分配为(LCF′n,LCF′n+1),并分别匹配到(LFILn,LFILn+1) 上。公式如下:
(24)
(25)
(26)
(27)
式中:S、d分别为交集区域的面积与长度(见图2)。

图2 模糊交集信息分配示意图
Fi的综合评价置信度为:

1.6 方案量化评估


(28)

(29)
(30)
(31)

(l=1,2,…,q-1,q+1,…,Q)
(32)
(33)
建立模糊判断矩阵V,并通过数据转换聚合得到方案的量化评估值,公式如下:
V=(vql)L×L
(34)
(35)
(36)
ηl=
(37)
式中:L为方案数量;ηl为方案l的最终评估指数。
2 算例分析
结合云南省某道路关键节点间路线方案设计,采用上述模型进行方案比选,并与实际比选结果进行对比,验证模型的科学性及有效性。路线起于某立交,终于某隧道,全长约6 km。涉及的关键制约因素为滇池二级禁(限)建区、林地、耕地、已规划地块等,建设条件复杂,须考虑的因素众多。共设计6种路线方案,分别编号A1、A2、A3、A4、A5、A6。
(1) 选取路线、桥隧等相关领域的专家4人,采用德尔菲法进行分析,形成方案评价指标体系S={滇池二级禁建区侵占面积S1、生态红线侵占面积S2、桥隧占比S3、线形条件S4、隧道建设条件S5、工程总投资S6、对关键构筑物的影响S7}。考虑到6种路线方案普遍占用滇池限建区,不考虑滇池限建区侵占问题,滇池限建区侵占不纳入指标体系;路线对规划地块及路旁变电站、燃气站的影响均视为对关键构筑物的影响。通过G1赋权法确定指标权重W={0.112 3,0.295 6,0.157 9,0.119 6,0.050 3,0.173 8,0.090 5}。
(2) 建立统一的描述框架,参考文献[14],将FBS分为5个评估等级,分别为优异、良好、中等、较差、很差,其模糊分布见图3。
(3) 数据预处理。将量化信息进行归一化处理,并映射至FBS描述框架中。该项目的量化指标均为成本型(见表1),按式(8)进行处理,结果见表2。

图3 评估等级的模糊分布

表1 路线方案评价指标的评估值
对于定性语言描述的信息,根据专家知识和经验给出定性转化矩阵A,如方案A1的线形条件评估为“良好”,λ=[0,0,1],按式(6)计算,得:
[0.0,0.0,0.1,0.9,0.0]
(4) 按式(10)~(23)计算综合评价基本可信度,以方案A1为例,计算得其综合评价基本可信度为{0.000 0,0.000 0,0.006 4,0.000 5,0.133 2,0.049 4,0.492 4,0.075 2,0.242 6}。然后按式(24)~(27)计算方案的综合评价置信度,以方案A1为例,计算得其综合评价置信度为{0.000 0,0.006 7,0.158 3,0.554 8,0.280 3}。
(5) 聚合计算量化评估值。按式(28)~(37)计算各方案实际评估值并进行排序,同时列出专家评估的排序,结果见表2。
由表2可知:运用上述评价模型得出方案A1、方案A6、方案A3的评估结果处于“优异”和“良好”的信度明显高于其他方案,方案排序为A1>A6>A3>A2>A4>A5,A1为最优方案。最优方案为A1,与专家评估结论一致,一定程度上体现了模型的有效性。但次优方案两者存在差异,分析其原因,一是由于方案A6的线形条件不佳、标准低,在专家评选之初即未被重点考虑;二是方案A6与其他方案的差别较大,可行性研究阶段该方案涉及的地形等信息未能有效覆盖,评估因素存在模糊性甚至部分因素只能以未知状态参与评估,模型分析中由于现有条件的模糊性未能产生有效评估结论。根据模型评估结论,有必要对方案6进行进一步分析,以更全面地确定最优方案。

表2 路线方案比选评价结果
3 结语
本文采用模糊证据推理技术结合G1赋权法等方法构建选线方案比选评价模型,通过合理筛选指标,并基于统一描述框架,可有效解决实际比选过程中存在的指标定性、定量及未知共存的情况,得到聚合的量化评估值,为路线方案选取提供参考。在方案众多、评估因素繁杂的大型项目方案比选中,采用该方法有助于辅助专家明确评估体系并找到可能忽略的优选方案。另外,考虑到选线中的客观因素制约,建立有针对性的评估模型能使路线比选评估更科学、客观。
但指标权重筛选环节仍有较大改进空间,模型在权重赋予时仅考虑了指标相对重要程度,忽略了各指标所携带的信息量差异,如何结合相对重要程度、信息量确定指标权重是未来须考虑的问题。专家群具有不同的专业背景、偏好甚至不同的利益属性,加上评价体系中各指标存在较大关联性,如何在群体条件下得到更合理的权重分配是今后的重要研究方向。由于不同设计阶段得到的数据深度不同,专家评估中存在犹豫,如何将专家经验作为区间数,结合犹豫模糊熵等方法进一步改进模型,提高评价结果的准确性也是下一阶段的研究方向。
猜你喜欢
世界科学技术-中医药现代化(2021年7期)2021-11-04
科学技术创新(2021年16期)2021-06-26
数学小灵通·3-4年级(2020年11期)2020-12-14
数学小灵通·3-4年级(2020年3期)2020-06-24
小学生导刊(2017年31期)2017-08-15
小学生导刊(低年级)(2016年8期)2016-09-24
管理现代化(2016年6期)2016-01-23
听力学及言语疾病杂志(2015年5期)2015-12-24
中国康复理论与实践(2015年7期)2015-05-09
佛山陶瓷(2015年9期)2015-03-19
