
一种融合改进TF-IDF与词典模型的情感分类算法
2024-03-07 02:32王康静钱江海
上海电力大学学报 2024年1期
王康静, 钱江海,2
(1.上海电力大学 数理学院, 上海 200090;2.华东师范大学 软硬件协同设计技术与应用教育部工程研究中心, 上海 200062)
随着网络与社交媒体的不断发展,网络用户可以自由且随时发表自己对某一实体的主观意见,各大媒体便需要分析人们对于某一特定实体的反应,并依据其表达的情感采取有针对性的措施[1],因此情感分析对于政策措施的制定与经营策略的实施具有重大研究意义。目前常用的情感文本分析模型主要包含无监督词典模型[2]和有监督分类模型[3-4]。无监督词典模型通过预定义情感词典中的特定词汇来计算文本的情感得分,并结合其他因素决定最终情感分数。文献[5]利用情感词典优化特征词权重,并与文本语义特征相融合,有效提高了情感特征词的强度和情感分类精度。文献[6]通过分析WordNet词典的相似性,评估同类别的情感词汇具备同质相似性特征,为情感文本分析提供基础。文献[7]利用词性标注、情绪词典和通用情感词典作为情感分类流程中特征提取的外部资源,显著改善了情感分类效果。虽然词典模型在无标签数据下可作为一种优选的情感分类方法,但由于其理论基础依赖于特定领域词典和专家知识,所以词典模型的鲁棒性和适用性有限。有监督分类模型的首要工作是非结构化文本数据的结构化,包含应用最为广泛的词频-逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)模型[8]和词嵌入模型。词嵌入模型主要包含Word2Vec模型[9]和GloVe模型[10]两类。文献[11]通过实义词语抽取分析,并利用支持向量机(Support Vector Machine,SVM)分类算法对藏文微博进行积极、客观与消极分类。文献[12]提出通过卡方统计提取训练文本特征词,并由TF-IWF赋予其特征权重,有效扩大了特征词权重值的范围。文献[13]通过改进TF-IDF加权,对类别区分能力不同的词语赋予不同的权重。虽然有监督分类模型相比无监督词典模型具有更好的分类表现,但是其前提条件必须是针对标签数据,且对于训练文本的数据质量要求较高。TF-IDF模型是一种经典文本特征表示方法,其主要思想是通过计算词项的频率和逆文档频率来衡量其重要性。TF-IDF模型能够准确反映文本中各个词项的重要性,可以将其应用于多语言文本的特征表示、图像文本的联合表示及知识图谱的构建等。
通过综合分析无监督词典模型和基于TF-IDF特征提取的有监督分类模型在情感分类方面的优缺点和适用性可知,这两种方法本质上具有互补性,适当结合可满足不同领域情感分类的适用性。
1 模型概述
1.1 TF-IDF模型
TF-IDF模型主要用于识别不常出现的词汇,是构建结构化文本最为成熟的模型之一。它是基于两个度量指标的组合:词频和逆文本频率。词频表示一个特征词在对应文本中的出现次数,逆文本频率表示包含某特征词的文本数与总文本数的比率。词频与逆文本频率的计算公式为
(1)
(2)
式中:Tf(w,D)——文本D中词w的频率;
fwD——文本D中词w的出现次数;
ND——文本D总词数;
Idf(w,D)——文本D中词w的逆文本频率;
N——文本集合总篇数;
df(w)——存在词w的文本数。
在实际模型中,为了避免因误差为零导致计算量出现无穷大情况,需要对每个词项增加1的文档频率,即将Idf计算结果加1。
通过将文本的词频向量和词的逆文本频率相乘,并进行L2规范化,可以得到最终特征向量Tfidf为
(3)
式中:‖·‖——欧几里得L2范数。
1.2 无监督词典模型
无监督词典模型是出现较早的情感分类模型,适用于互联网中大量未经标注的情感文本数据分类。该模型的附加资源是情绪词典。情绪词典中包含正面情感和负面情感、极性(正面或负面分数的大小)、词性标签等相关联的单词列表,可以用来计算情感文本中的情绪得分,并结合其他参数,修正情绪得分。无监督词典模型的算法逻辑描述如下。
第1步:加载情感文本数据,以特定标识符进行分句预处理。
第2步:加载第三方情绪词典资源,可将多个情绪词典进行融合。
第3步:依据情绪词典匹配各情感文本分句所包含的情感词,并记录其极性与位置。
第4步:依据分句情感词定位向前搜索程度副词,并依据程度副词的权重对情感极性进行加权。
第5步:依据分句情感词定位向前查找否定词。若否定词数量为奇数,则情感极性取反;若否定词数量为偶数,则情感极性不变。
第6步:搜寻分句结尾感叹词。若分句结尾存在感叹号,则分句相应情感词极性加2;若分句结尾存在问号,则分句相应情感词极性加负2。
第7步:计算各分句情感词极性之和,即正极性与负极性之和。
第8步:计算各分句情感词正极性和负极性均值,并计算正极性均值和负极性均值与该分句极性之和的距离。距离较近的极性,则为该分句的情感倾向。
2 基于词汇深层极性的改进TF-IDF
传统的TF-IDF模型通过逆文本频率计算每个特征词的权重与文本语料的特征向量。首先,通过中文分词或英文词根还原;然后,经过去停用词预处理;最后,使用TF-IDF模型,得到文本语料的特征向量表示。虽然此种方式可以适用大多数文本特征向量构建场景,但在情感文本领域却有很大的局限性,因为情感文本所含的某些特征词具有不同程度的情感极性。这些具有更大权重的特征词,需要在原始TF-IDF模型构成的特征词向量基础上融合特征词的情感极性。
当前情感词汇的极性研究主要包含情感词汇的极性偏好和极性程度。前者用于评价特征词的正面情感和负面情感倾向,后者用于评价特征词的正面情感和负面情感程度。情感词汇的极性偏好和极性程度共同构成了该特征词的情感区分度。在计算特征词的情感区分度时,可以采用该特征词在不同情感语料中的分布频率表示。如果一个词汇在正面情感文本中出现的频率较高,则有理由相信该词汇具有正极性的可能性更高;反之亦然。因此,通过计算一个词汇在正面情感文本的频率和在负面情感文本的频率并进行比较,可以得出该词汇的情感区分度。词汇的情感区分度计算公式为
(4)
式中:ηw——特征词w的情感区分度;
Nwp——特征词w在正面情感文本中的出现次数;
Np——正面情感文本总篇数;
Nn——负面情感文本总篇数;
Nwn——特征词w在负面情感文本中的出现次数。
为了避免词汇在正面情感文本或负面情感文本中出现零次而不满足对数运算,故分别加1。词汇的情感区分度模型如图1所示。

图1 词汇的情感区分度模型
当特征词w在正面情感文本或负面情感文本出现次数相等时,ηw=0,表示该特征词无任何情感区分度;当特征词w在正面情感文本的出现次数大于在负面情感文本的出现次数时,ηw>0,表示该特征词的情感倾向为正,且情感程度等于η;当特征词w在正面情感文本的出现次数小于在负面情感文本的出现次数时,ηw<0,表示该特征词的情感倾向为负,且情感程度等于η。
式(4)虽然可以通过度量每个特征词在不同情感类型文本中的分布频率计算其情感区分度,但由于其仅统计每个特征词在情感文本中是否出现,并没有考虑该特征词在各文本中的出现次数,因此可能会导致由于恶意差评和虚假好评而引发的词汇情感区分度失真,即词汇情感区分度稳定性较差。
现假设存在10组情感文本数据D,其中5组为正面情感文本,5组为负面情感文本。某一特征词w在正面情感文本中出现2次,在负面情感文本中出现3次,依据式(4)可以计算得出ηw=-0.29,那么可以判定w的情感倾向为负面,且倾向程度等于|ηw|。但若w在2篇正面情感文本出现的次数分别为(2,5),在3篇负面情感文本出现的次数分别为(1,1,9),此时若仅依据ηw判断w的情感区分度便会失真,因为虽然w在负面情感文本中多出现了1次,但在某一负面情感文本中出现了9次,相比同为负面情感文本的其他情况差异极大,因此可能属于恶意差评。如果该条文本不纳入w的负面情感文本统计范围,那么w的情感区分度ηw=0,且根据其在正面情感文本其中的出现次数,可以判断w更有可能偏向正面。
因此,除了通过度量每个特征词在不同情感类型文本中的分布频率计算其情感区分度之外,还需要更为深入的度量每个特征词在同一情感类型文本中的出现次数。为此,本文引入离散系数这一统计指标来评估特征词在正面情感文本或负面情感文本中的分布情况,以判定其情感偏好的稳定性,避免恶意差评或虚假好评情况的发生。离散系数可以用以衡量不同水平高低的数据组别的离散情况,有效避免正面情感文本组别与负面情感文本组别的数据水平差异。其计算公式为
(5)
式中:λ——特征词w在正面情感文本或负面情感文本中的离散系数;
n——特征词w在正面情感文本或负面情感文本中的出现次数;
xi——特征词w在第i篇正面情感文本或负面情感文本中的出现次数;

在情感文本数据D中,w在2篇正面情感文本出现的次数分别为(2,5),则其正面离散系数为λp=0.43;在3篇负面情感文本出现的次数分别为(1,1,9),则其负面离散系数为λn=1.03。若λ越大,表示特征词w在正面情感文本或负面情感文本的不稳定性越高,则需要对特征词w的正面情感或负面情感倾向加以惩罚。惩罚计算公式为
(6)

λp——特征词w的正面离散系数;
λn——特征词w的负面离散系数。
在对特征词的情感极性偏好和程度做出完备评估后,便可以将其作为特征词的情感表征权重融入到TF-IDF模型中。现假设某情感文本的原始TF-IDF为矩阵V,由n篇情感文本的m个特征词构成,特征词集合为{w1,w2,w3,…,wm},第i篇情感文本的第j个特征词的Tfidf值为vi·j,V表示为
(7)
式中:Tfidffinal——改进后的TF-IDF模型;
NTUSD——情绪词典集合;
k——情绪词典中的特征词w应赋予的权值,一般取2。
3 融合改进TF-IDF与无监督词典模型的情感分类算法
通过无监督词典模型可以在情感文本无标签的情况下,对情感文本做出初步的情感评分,且通过某些有监督的机器学习算法。基于改进的TF-IDF模型也可以通过其决策函数评估情感文本具体属于某一类别的得分,并将此得分视为情感评分。为综合考量两种情感文本评分模式,参考分类指标查准率和查全率的融合得到F1综合评价指标的思想,对两类评分模式进行调和平均。计算公式为
(8)
式中:sf——情感文本综合情感得分;
stfidf——基于改进TF-IDF模型的有监督分类模型决策得分;
sdict——基于词典模型的情感得分。
融合改进TF-IDF与无监督词典模型的情感分类算法计算流程如图2所示。
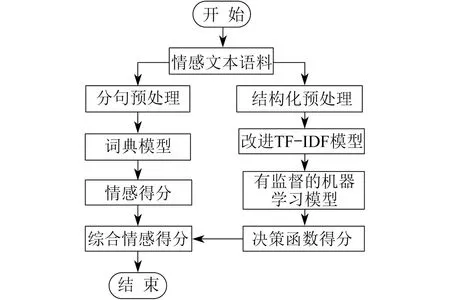
图2 情感分类算法计算流程
由图2可知:首先,对情感文本语料分别进行结构化预处理,将通过分句预处理的文本语料输入词典模型进行评估,便可以得到各分句的情感得分;其次,将结构化预处理后的文本数据通过改进TF-IDF模型进行文本特征向量化,并将其特征矩阵输入有监督的机器学习模型,评估其决策函数的得分,作为情感得分;最后,对两类情感得分进行调和平均,得到情感文本的综合情感得分。计算完成情感文本的综合得分后,便可以根据决定决策边界对综合得分进行分类。
4 实验验证与结果分析
4.1 实验数据集
本文实验采用一个中文旅馆评论数据集和一个英文电影评论数据集。中文旅馆评论数据集来自文献[14],共选取5 000条记录,包含正面评论2 500条,负面评论2 500条,且在正面评论和负面评论中分别含有与旅馆居住环境不符的虚假好评200条和恶意差评300条,用以测验本文模型在二者之间的鉴别力。英文电影评论数据集来自文献[15],共选取50 000条记录,包含正面评论25 000条,负面评论25 000条。此外,英文情绪词典采用AFINN词典和VADER词典,AFINN词典包括3 300个单词及其情感极性分数;VADER词典包含7 500个带有正确验证分数的词汇特征。中文情绪词典采用台湾大学情绪词典,包含8 276个负面词汇和2 810个正面词汇。实验过程中,均取整体数据集的80%作为训练集,20%作为测试集。对于无监督词典模型仅使用20%的测试集。
4.2 实验评价指标
情感分类的整体效能可采用分类准确率衡量,即正确分类的情感文本占所有情感文本的比例。准确率越高,分类模型效能越好。分类准确率计算公式为
(9)
式中:TP——实际类标签等于预测类标签的正类实例总数;
TN——实际类标签等于预测类标签的负类实例总数;
FP——模型错误地将负类预测为正类的实例总数;
FN——模型错误地将正类预测为负类的实例总数。
准确率一般用于数据类别较为平衡的情况。如果数据类别分布偏差较大,将使用精度Precision、召回率Recall和F1分数这3个指标衡量模型分类效能。精度表示正类中正确预测的数量占所有预测正类数量的比例,召回率表示正类中正确预测的数量占正确预测和错误预测数量的比例,而F1分数则是精度和召回率的谐波平均值,用以平衡二者的度量值及评估模型的整体分类效能。3个指标计算公式为
(10)
(11)
(12)
4.3 实验结果分析
为验证本文所提模型在情感分类方面的提升效果,将采用上述两种不同的数据集分别针对原始TF-IDF模型、词典模型、结合情绪词典的TF-IDF模型、卷积神经网络(Convolutional Neural Network,CNN)模型和本文模型进行分析对比。情绪词典模型采用AFINN,该模型可以预测情感文本的正负情感得分;有监督分类模型采用梯度提升机,该模型是一种常用的集成学习模型,相比传统的单一机器学习分类模型,具有更好的分类精度和稳定性,且该模型通过其决策函数可以评估某一样本属于某一类别的得分。
中文旅馆评论数据集测试过程中,有监督分类模型采用5层交叉验证方式,无监督词典模型采用5次测试均值。实验结果如表1所示。

表1 旅馆评论数据集对比分析
由表1可知,在中文情感文本语料测试条件下,本文模型显著优于其他模型分类表现。由于无监督词典模型属于无监督情感分类模型,仅依靠情感文本与情绪词典的匹配关系计算情感得分,所以其分类表现最差,综合分类精度为0.726。TF-IDF模型考虑了特征词汇的统计特性,并利用有监督分类模型进行训练,所以分类精度较无监督词典模型有明显提升。融入情感词典的TF-IDF模型,不仅考虑了特征词汇的统计特性,还对这些特征词是否在情感词典出现或根据其情感词典中的极性,赋予不同的权重,所以相比TF-IDF模型,综合分类精度略有提升,但由于情感特征词的数量限制和具体分布信息欠缺,所以提升效果不太显著。CNN模型在两项指标均表现良好,但对于文本语料的数量和质量要求较高,且训练时间较长。本文所提模型综合分类精度及准确率都表现优异。
英文电影评论数据集测试过程中,有监督分类模型采用5层交叉验证的方式,无监督词典模型采用5次测试均值。实验结果如表2所示。
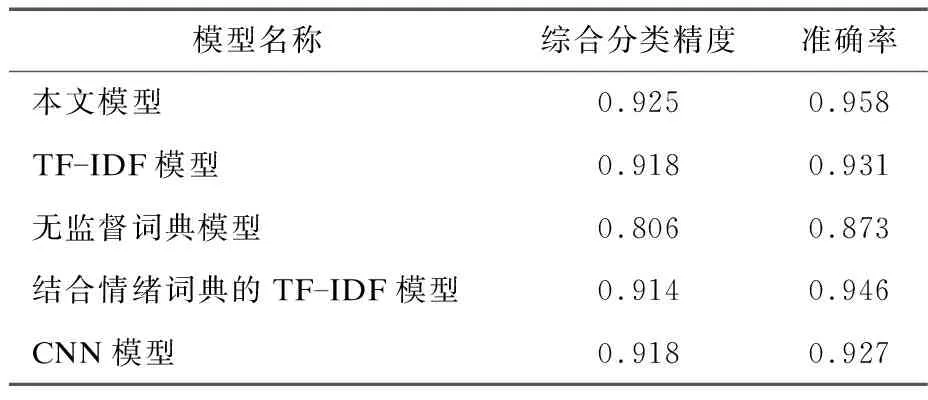
表2 电影评论数据集对比分析
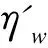

表3 旅馆评论数据集词汇分析
5 结 语
针对基于TF-IDF模型的传统情感文本分类算法存在情感词汇极性偏好区分度和稳定性较低的问题,本文提出改进TF-IDF模型加权的方式,并融合有监督分类模型与无监督词典模型的综合评分。通过对比实验可知,本文模型可以提高情感分类的精确度。
猜你喜欢
时代英语·高一(2019年5期)2019-09-03
中国校外教育(2019年12期)2019-04-15
江淮论坛(2018年4期)2018-08-24
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
福建中学数学(2016年5期)2016-11-29
电测与仪表(2016年11期)2016-04-11
心理学探新(2015年3期)2015-12-27
电源技术(2015年5期)2015-08-22
中文信息学报(2015年4期)2015-04-21
