
高熵合金生成相的机器学习预测
2024-03-06 10:34马妞妞刘翠霞坚增运
西安工业大学学报 2024年1期
马妞妞,刘翠霞,坚增运
(西安工业大学 材料与化工学院,西安710021)
高熵合金(High-Entropy Alloys,HEAs)其独特的微观结构和优异的性能,包括强抗氧化性、优异的机械性能、良好的热稳定性和理想磁性等引起了各个领域的极大关注。根据合金成分-微观结构-性能之间的关系表明HEAs的优异性能取决于生成相的组成,故深入了解相阶段对于进一步开发具有所需性能的HEAs至关重要。而作为多主元素合金,HEAs各元素之间接近等原子比或接近等原子组成,使其拥有巨大的搜索空间,使得从可用元素调色板中制造出大量不同系统,设计开发具有前途的新型HEAs十分困难。机器学习(Machine Learning,ML)应运而生,作为一种数据驱动方法,经济高效的特点使得其很快在材料领域得到发展和应用。材料信息学将其用于相阶段预测,它可以帮助确定一个包含所需性能候选合金的较小子空间,减少大量实验过程中人和物品的损耗。
文献[1]关于多主元素合金的初次报告就引起了工业研究领域的关注,其研究了等原子多组分合金成分FeCoNiMnCr,表现出了单一FCC固溶体。文献[2]研究了多种元素的不同组合,例如Co、V、Al、Mo、Ti、Zr和Nb,其表现出比传统合金更好的机械性能。传统的试错实验需要花费大量的时间和金钱,同时对实验条件要求苛刻、不能短时间内进行大量时间。随着研究的进行,人们对HEAs的研究越来越深入。HEAs优异的性能被认为取决于第二相的类型和分数,文献[3]进行了计算辅助参数方法,对双相HEAs中的定量相预测。文献[4]对多组分合金进行了从头相稳定性和机械性能的研究,提供了迄今为止使用离散傅里叶变换研究的多主要元素合金和各种材料特性的广泛汇编。同时,大量计算智能模拟方法应用在HEAs相预测,例如,第一性原理计算[5]、参数方法[6]、CALPHAD[7]等。文献[8]使用 CALPHAD 方法开发了一个组合数据库,该数据库集成了一系列过渡金属的热力学描述、迁移率和摩尔体积,其展示了该数据库在预测 Co-Cr-Fe-Mn-Ni 体系中的相关系方面的成功应用。这些常规的方法研究HEAs比较准确但其成本高昂、同时存在的其他多种影响因素,使得其设计难度较大。为此,寻找一种更有效的途径来加快其成分空间的探索已成为当前迫切需要解决的问题。其作为最有前途的结构和功能材料具有广泛潜在应用。ML作为一种数据驱动方法,能够自主学习,可用于从预定的先验实验观测数据进行推断和分类[9]。可以迭代地提高每个新数据样本的性能,并从复杂、异构和高维数据中发现隐藏的见解,而无需显式编程。经济高效的特点使得ML很快在材料领域得到发展和应用。文献[10]采用三种不同的 ML 算法:K-最近邻(K-Nearest Neighbors,KNN)、支持向量机(Support Vector Machine,SVM)和人工神经网络(Artificial Neural Network,ANN)对HEAs进行生成相预测,测试精度值分别达到 68.6%、64.3% 和 74.3%。文献[11]采用四种ML算法,即决策树(Decision Tree,DT)、KNN、SVM和ANN,研究了两个不同数据集的相位选择规则,一个由1761个不含AM或IM相位的固体溶液(SS)HEAs组成,另一个由2436个HEAs组成,同时进行交叉验证以优化ML模型,考虑了生成相对HEAs模型的预测精度。文献[12]对采用主成分分析与否对ML算法的影响,实验数据比较证实了应用 KPCA 后DT 和随机森林(RF)的准确性有所提高。使用ML对HEAs进行相阶段预测仍存在许多需要解决的问题,例如:缺乏统一的相形成规则、完备的实验数据库以及用于预测的机器模型算法仍需提高其精度等,这使得之前的研究都不够全面完备。
文中拟从数据收集开始,通过综合考虑选择适合于HEAs设计的小数据集,由实际问题和数据集出发,进行HEAs生成相的预测,了解合金成分-微观结构-性能之间的联系,对于进一步辅助设计开发新型合金奠定基础;文中从多分类和多标签两方面进行建模,选择主流算法实现生成相的预测;同时进行特征重要性分析,通过控制去除特征参数的数量,达到探究特征参数对模型的准确率的影响的目的。
1 数据处理和建模
1.1 数据集选择
文中所使用的HEAs实验数据集从相关文献[13-19]中收集,并进行筛选和处理,最终得到306组样本数据。HEAs的特征属性,包括合金元素组成、温度、制备工艺、屈服强度、构型熵以及价电子浓度等均对HEAs相生成有关键影响。由以往研究成果和实际情况等综合考量,最终选择9种常用于ML特征参数作为输入数据,分别为原子尺寸参数(δ)、混合焓(ΔHmix)、电负性(Δχ)、无量纲参数(Ω)、二元相互作用的混合自由能的二阶导数参数(μ)、价电子浓度(VEC)、流动电子浓度(e/a)、原子间距错配度(Sm)、体积模量错配度(Km)。
HEAs生成相的种类有面心立方晶体结构(FCC)、体心立方晶体结构(BCC)、块状金属玻璃(BMG)、金属间化合物(IM)、σ相、B2 相和 Laves(L)相[20-22]。根据数据样本大小和实际需求,由于σ相、B2相和Laves(L)相数据所占比例较小故,将其和其他未检测到的相统称为多相(MultiPhase)。经过数据处理后最终采用FCC、BCC、BMG、IM和MultiPhase五种相结构进行预测。
在将HEAs数据集用于训练模型之前,首先对HEAs数据集进行如下操作:首先设置两组数据集,数据集1作为多分类模型的总实验数据集,采用9种特征参数作为输入数据,同时将5种生成相作为输出数据,为了探究特征参数数量对模型的影响,分别组成含有Δχ,VEC,δ,3个特征参数的数据子集1,含有Δχ,VEC,δ,Ω,Sm,5个特征参数的数据子集2,含有Δ,VEC,δ,Ω,Sm,Km,μ,7个特征参数的数据子集3;数据集2采用与数据集1相同的特征参数,但输出数据选择7种生成相(FCC,BCC,BMG,σ,IM,B2和L)作为参照标准,同时每一组样本可以属于多种类别。
图1为三种特征参数(δ,VEC,Δχ)相关的306组HEAs生成相的分布情况,HEAs数据集来自数据集1。由图可以看出,五类相在空间分布重合部分较少,ML模型可有效识别生成相,提高其预测精度。
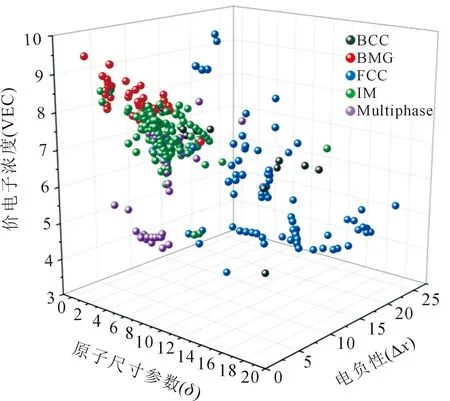
图1 HEAs数据集的生成相分布可视化图
1.2 特征选择
在预测HEAs生成相的实验过程中,其合金特征参数的选择是保证实验成功的关键,它不仅决定了训练ML预测生成相模型效果的上限,同时还实现对5种生成相的合理分类。由于无关的特征对HEAs中的相位分类是冗余的,在实验中增加预测特征的数量可能会引发维数灾难的问题,故选取与HEAs相最相关的9种特征参数。为了保证选取到最适宜的特征参数,优化HEAs生成相模型的泛化能力,同时尽可能减少实验过程中过多合金特征带来的维度灾难,减少训练时间、减少过拟合、增强对HEAs特征值的理解,对数据集进行简单的特征子集分类。最后,为实现最佳分类精度,对数据集进行预处理,保留与相位分布相关的特征,对实验结果进行对比分析。
文中使用一些被广泛接受的经验参数作为HEAs生成相的特征参数。通过冗余检查,并通过相关系数选择最佳的9种经验参数作为文中特征参数。图2所示为皮尔逊相关系数热图以检查特征参数之间的正相关和负相关。
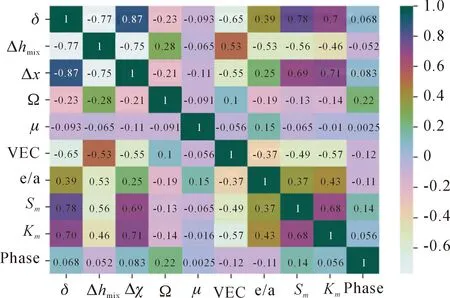
图2 HEAs特征参数皮尔逊相关系数热图
从图2中可以看出这9个经验参数之间的相关性,如,和相关系数达到了0.87,具有很强的相关性,在特征选择时优先考虑。在HEAs生成相预测实验中作为依据,选择相关性高的特征以表征合金属性。表1展示了文中实验数据所采用的9个特征参数的相关定义。
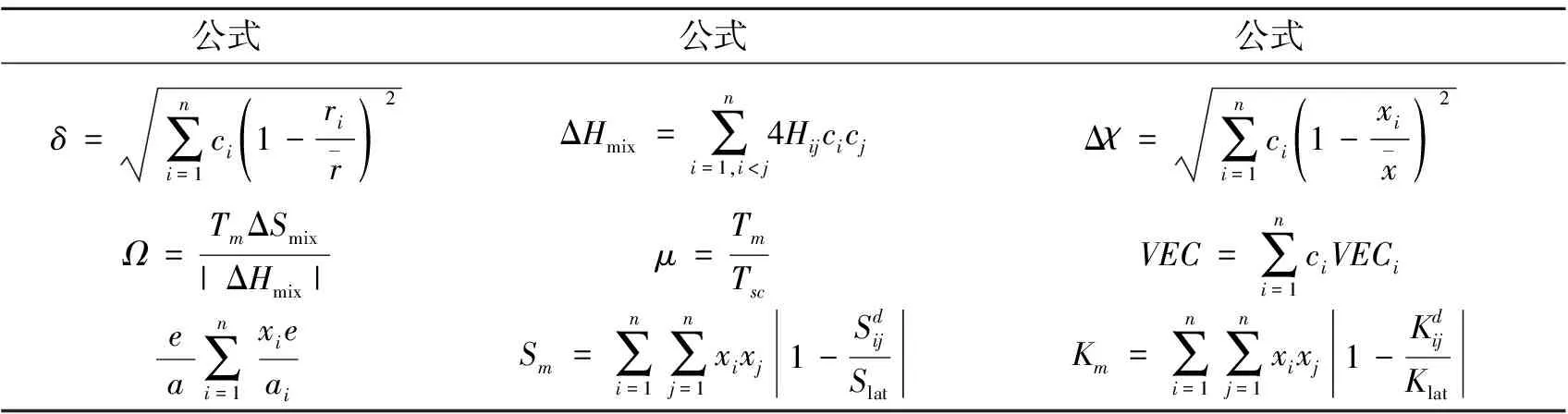
表1 HEAs生成相相关特征参公式[23]
1.3 HEAs相结构筛选框架
文中基于PyCharm编译平台,使用Python作为编程语言,同时使用Scikit-Learn作为开源库。利用ANN、SVM、特征选择等[23]技术对HEAs的相结构进行预测,预期发现HEAs类和生成相的相互关系。如图3阶段预测分类的ML建模框架所示,首先从已有论文和实验资料中收集大量的HEAs数据,经过筛选和清洗数据得到最终用于文中的HEAs相预测实验数据集。对于HEAs相预测的实验,选择了多分类和多标签分类两种模型进行实验,同时选择目前ML的主流算法分别对收集到的HEAs数据集进行相预测测试。为了尽量保证实验的准确度和减小误差,通过对不同模型的实验参数进行调整达到优化模型的目的。在实验最后通过不断测试以及模型调整,详细记录了不同模型和算法的最终相预测相关数据。

图3 HEAs阶段分类的ML建模框架
使用归一化对对HEAs数据集进行标准化处理,数据归一化会使得求得最优解的过程变得更加平滑,减少时间,从而可以更好的得到最优解。HEAs数据集特征参数归一化处理前后的对比如图4所示,为9个特征参数归一化前后的分布。
图4 HEAs特征参数归一化处理前后的对比
1.4 分类器
文中对HEAs生成相的预测过程中采用了有监督学习算法。对于HEAs生成相预测使用的多分类算法学习模型包括:KNN,DT,RF,SVM,ANN,梯度提升树(Gradient Boosting Decision Tree,GBDT)、自适应增强(Adaptive Boosting,AdaBoost)和XGBoost(eXtreme Gradient Boosting)。用多标签学习模型进行HEAs相预测,选择了KNN,DT,RF和GBDT算法。对于不同问题的提出与数据结构的不同,学习算法的选择依赖于收集到的HEAs数据结构以及对实验问题的提出和达到的目的。文中通过对ML用于材料研究方面的主流学习算法进行分析,以寻求和识别最适用于解决本次HEAs相预测的最佳策略。
两个HEAs数据集都被随机分为两个子集,训练集占80%的样本数据,其被用来训练和选择生成相预测模型的最佳参数,测试集占用20%的样本数据,被用来评估模型的精度和泛化能力。同时为进一步从有限的高熵数据样本中获取有效信息以及在一定程度上减小过拟合问题,实验过程中采用交叉验证方法,对模型进行实施培训和测试。
1.5 分类器评价标准
评价分类器性能的指标一般是分类准确率(Acc),但对于二分类问题,其评价指标为精确率(Precision)与召回率(Recall),除此之外还有F1值(F1Score)、PR曲线、ROC曲线、AUC等帮助理解的评估标准。对于分类算法只使用准确率的评价标准是不够的,且对于一些情况是存在问题的,需要使用混淆矩阵进行进一步分析。
使用的混淆矩阵评价指标正确率和Kappa指数由式(1)(2)给出,同时表2给出了术语的解释。评价指标定义为
(1)

表2 评估指标相关描述
(2)
2 结果和分析
针对收集到的306组样本进行实验,其包含9种特征参数。选择了基于DT、RF、GBDT和XGBoost对特征重要性进行简单的选择以及特征重组,从而提高其可用性以及识别提供最佳分类性能的特征子集。图5为DT、RF、GBDT和XGBoost四种算法对HEAs相关的9个特征的重要性曲线。其计算了研究所选HEAs特征参数在预测生成相过程中的有用程度,可以加深对HEAs规律以及模型更深入的了解,提高HEAs预测模型的效率。

图5 DT、RF、GBDT和XGBoost特征重要性曲线
图5给出了进行二分类和多分类的特征重要性曲线,流动电子浓度(e/a)对各合金相的形成规则可忽略。同时在合金相形成阶段可将电负性、价电子浓度和原子尺寸差作为主要预测特征参数。
由图5可以看出,特征重要性曲线遵循相位形成规则,各主元的晶格类型对形成简单固溶体的影响较大,晶体结构相同时,有利于各组元的固溶,形成无限固溶体。当各主元的晶格类型不同时,主元间原子固溶受到抑制,只能形成有限固溶体,同时,原子在发生扩散固溶的同时,会造成晶格的变形,当溶质原子半径大于溶剂原子半径时,晶格会发生膨胀,反之,则会收缩。晶格的变形程度取决于各主元原子半径之差,在一定条件下,原子尺寸差异较小时易形成固溶体、当混合焓相同时,混合熵越大,则吉布斯自由能越小,体系倾向于生成简单固溶体。熵作用判据认为,混合焓和混合熵在体系凝固过程中处于相互竞争的关系,可以把混合熵和混合焓看作是形成固溶体的驱动力和阻力。当熵作用判据大于1时,表明混合熵提供的驱动力大于混合焓产生的阻力,有助于体系形成简单固溶体;反之,驱动力小于阻力,体系易形成金属间化合物,并会导致成分偏析。
通过表1所展现的不同算法在合金相位预测的重要设计参数,分别选取前3个、前5个、前7个和所有9个特征进行不同分类器的精度、Kappa指数以及ROC-AUC曲线的分类性能统计测量。统计分类结果见图6,表3和表4。

表3 不同特征组合的不同ML算法的分类精度

表4 不同模型关于所选特征数量的Kappa系数Tab.4 Kappa coefficients for different models regarding the number of selected features

图6 ROC-AUC曲线
由图5以及表3、表4可以发现在ML算法中,选择合适的特征参数可以很好的避免数据的冗余,有效提高了预测分类精度,且经过排序的特征子集提供了更稳健的性能预测。对于残余排序的特征参数来说,其排名顺序为Δχ,VEC,δ,Ω,Sm,Km,μ,Hmix和e/a。其中,e/a作为特征参数,在预测性能评估表现不佳。也可以看出,不同的特征参数对于不同分类器的重要性大体上是没有巨大的区别,但也有些特征参数对于某一个分类器影响很大,其中KNN和DT对于参数数量的变化不敏感,但参数数量变化对ANN算法的分类精度影响较大,在只有前3个特征参数时,ANN预测模型达到最高0.818 2,但在参数数量为7时达到最低为0.688 3。
表3和表4总结了不同特征分类子集对不同算法模型的总体性能统计测量。可以直观地看出,不同分类器对同样的数据集表现不同,总体来说RF、SVM和KNN分类器比较适用于小数据集的预测,故其在文中性能优于其他算法模型。准确率和Kappa系数作为衡量多分类性能的常用评估标准,在特征参数为3的数据集,ANN分类器得到了最好的分类准确率0.818 2和Kappa系数0.708 4。在特征参数为9的数据集中,RF和SVM达到最好分类精度和Kappa系数,分别为0.831 2,0.748 1和0.857 1,0.787 2。这说明在不同的特征参数数量的选择对于学习模型的质量是十分重要的。
混淆矩阵在二分类模型的应用中十分实用。其通过将预测结果与真实结果相对比,给出了四种评价模型的定义。在HEAs相多分类场景中,这样会导致真否定数的增加,导致特异性膨胀(TN/(TN+FP)),由于把生成相分为五种类别,故简单绘制数据集的ROC曲线不具有实际意义。而多类分类的软分类器用于评估提供分数而不是预测的输出,故使用截止来评估多类分类器的性能或曲线下面积(AUC),通过对不同算法对每个类别绘制ROC-AUC曲线,可以更加直观的看到不同分类器对于HEAs特征参数及生成相预测的影响。图6绘制了不同算法的ROC-AUC曲线。由图可知,每个ROC曲线针对不同类别进行了绘制,每条曲线绘制时,将此类别设置为正,其他类别设置为负,其去线下面积(AUC)越大,其基尼指数越小,其随机变量的不确定度越小,表明模型质量越好,具有更好的泛化性。
现实情况下,HEAs由于其温度、制备工艺以及其他各种问题,其不会产生单一的相。同时不同合金相的区别很大,除研究所搜集的FCC、BCC、BMG、σ、IM、B2和L其中相以外,还包括金属间化合物(IM)、固溶体相(SS)、非晶相(AM)以及混合相等。单一的按照多分类算法无法满足实际中的需求,而ML中的多标签算法则能解决因此带来的问题。但相生成数量无法确定以及类标签之间相互依赖,导致多标签的训练集比较难以获取,这时多标签分类算法的难题。文中简单实现对HEAs生成相的多标签预测,以获取HEAs相包含的更多有效信息。
目前有很多关于多标签的学习算法,依据解决问题的角度,这些算法可以分为两大类:一是基于问题转化的方法,二是基于算法适用的方法。
文中采用Scikit-Learn自带的多标签分类器,使用多标签DT、多标签RF、多标签KNN和多标签FNN实现对HEAs的分类,如表5所示。由图可以看到,文中的多标签算法对于生成相的预测准确率很高,但由于其适应性受限,对于现有的多分类算法封装较少,同时在深度神经网络中,需要自行修改最后一层的输出,对于没有专业编程知识的材料从业者不够友好,同时其黑盒性质,不能有效解释其模型,输出结果不能足够引起研究者的信任。

表5 多标签分类算法准确率
由于HEAs的数据标签大多数依赖每位研究者的标准,故会造成噪音标签的问题。同时HEAs不仅要考虑特征参数之间的关系,还需要研究者使用相应模型对标签之间的相关性关系进行提取、学习以及借助其他工具寻找其对应关系。多标签算法与图模型以及其他技术相结合,可以有效识别HEAs相图的微观结构,发现其隐藏规律,对HEAs的进一步发展意义重大。
HEAs作为当前研究的热点,其与ML的结合辅助从力学性能和变形机制等方面进行探索以及集合相图计算等计算材料学方法,可以在已有的HEAs中添加新的元素,通过模拟和实验和现有的材料比较,提高HEAs的性能。
HEAs由于其独特的多组元成分结构,其相阶段相较于其他材料比较复杂,同时相阶段对于合金设计至关重要。而通常材料的成分和组织决定了材料最终的性能,故如何通过理论计算相形成规律,从而准确地预测出给定成分HEAs的相组成成为一个难题和热点。
3 结 论
文中采用Scikit-Learn库的分类器,通过对两个HEAs数据集进行多分类和多标签分类模型,其中,在多分类算法中,SVM和ANN算法优于其他算法分别达到了0.8571和0.8182的准确率,在多标签分类模型中,集成学习算法的RF表现最佳,准确率达到了0.9400。
在运用不同的算法进行HEAs生成相的预测的同时,考虑了特征选择对模型的影响,特征参数进行了HEAs相类选择的强材料描述符(Δχ,VEC,δ等),同时说明独立识别和量化HEAs设计中常用因素的重要性,可以更好的捕捉HEAs相形成中存在的热力学非线性信息。在以后的研究中应将制备工艺、元素组成成分、HEAs经验参数以及实验中观察得到的微观结构相结合,作为ML模型的特征标签,能更好的表征和识别HEAs生成相。
比较了各个算法模型之间的对HEAs生成相的影响以及改进,综合来说SVM、RF和ANN在HEAs生成相方面的表现优于其他算法模型。同时多标签分类模型的高准确度以及其余图像模型结合在识别生成相方面可对HEAs在相设计和微观性能调控方面有巨大潜力。
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
粉末冶金技术(2021年3期)2021-07-28
电子测试(2018年1期)2018-04-18
中国有色金属学报(2018年2期)2018-03-26
制造技术与机床(2017年11期)2017-12-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
焊接(2016年8期)2016-02-27
电测与仪表(2015年7期)2015-04-09
