
基于自注意力和门控循环神经网络的雷达回波外推算法研究*
2024-03-05 05:34:54薛丰昌章超钦王文硕陈笑娟
气象学报 2024年1期
薛丰昌 章超钦 王文硕 陈笑娟
1 引 言
多普勒天气雷达是短时强降水预报的主要探测设备,雷达回波的精准外推对于精确预报短时强降水、减少洪涝灾害损失具有重要意义。
循环神经网络(Recurrent Neural Network,RNN)是一种以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络(Sathasivam,et al,2008)。循环神经网络具有时间和语义的记忆能力,并且同一个循环神经网络内部参数共享,对序列数据的非线性特征学习具有很大的优势。原始的循环神经网络容易产生梯度消失问题,学者们提出了各种改进的门控循环神经网络,其中长短期记忆网络(Long Short-Term Memory networks,LSTM)是最为经典的门控循环神经网络(Hochreiter,et al,1997);在LSTM 基础上,Shi 等(2015)将长、短期记忆网络和卷积网络相结合,提出ConvLSTM 模型用于雷达回波序列的外推。Wang 等(2017,2018,2019)进一步引入双记忆状态转移机制,将时间记忆状态和时、空记忆状态结合,并通过GHU(Gradient Highway Units work)单元减缓了可能出现的梯度消失问题,先后提出了ST-LSTM(Spatiotemporal LSTM)、PredRNN++和MIM(Memory In Memory)模型,实现了时间相关和空间相关的深度特征融合。Lin 等(2020)在ConvLSTM 中加入了注意力机制,提升了此类模型的性能。Jing 等(2020)提出的HPRNN由分层堆叠的RNN 模块和细化模块组成,它采用分层预测策略和递归粗到细机制来减轻误差的积累,有助于进行长期外推。Xu 等(2019)、Ying等(2018)将LSTM 和GAN(Generative Adversarial Networks, Goodfellow, et al, 2014) 结 合, 利 用GAN 来进一步提取雷达回波特征。Sato 等(2018)通过引入跳跃连接结构及空洞卷积,提升了短时临近预报能力。Agrawal 等(2019)通过U-Net 实现了降水的临近预报,效果优于NOAA 短时临近预报模型。Song 等(2019)将残差和注意力机制融入U-Net结构,并将该模型用于北京市城市大脑的短时临近降雨预测。Trebing 等(2021)将通道注意力和空间注意力加入U-Net 结构,并用深度可分离卷积代替部分2D 卷积,得到一个轻量的短时临近外推模型。
传统利用循环神经网络进行雷达回波外推中存在误差累积,连续几个时间步的偏差会在很大程度上误导模型对未来时刻的预测,这对模型的长期预测造成了阻碍,有效挖掘雷达图像序列间长期的空间依赖关系成为了一大难题。同时,当下常见的时、空序列预测模型难以有效外推小面积的强回波区域,且对强回波区域走势的预测准确度还有待提升。针对以上问题,文中对基于ST-LSTM 结构的时、空序列预测模型加以改进,融入时、空自注意力模块用于挖掘雷达图像帧与帧的时、空依赖关系,构建一个带有自注意力结构的循环神经网络(ST-SARNN),提升对雷达强回波的预测能力。
2 研究方法
2.1 自注意力长短期记忆网络模型建立
2.1.1 时、空自注意力模块构建
注意力机制(Vaswani,et al,2017)的提出旨在令机器能够像人类一样,将关注点放在最为关心的部分,注意力机制能对不同的数据内容分配不同的注意力权重。在对雷达回波序列数据进行外推的过程中,核心的关注点就在于能否有效挖掘区域内雷达回波反射率因子的时、空生消变化。理论上,自注意力机制可以为高阶时、空特征信息分配不同的注意力权重来强化模型对时、空序列的预测能力。
针对大尺寸的雷达回波图像,目前常用的处理手段包括(1)卷积操作:经过卷积计算将原图像中长、宽维度的信息压缩至通道维度。(2)裁剪:将原图像长、宽维度的信息分割至通道维度,与卷积不同的是,裁剪不存在任何数据计算。(3)下采样:通过选择opencv 库中的重采样(resize)方式(双线性插值(Keys,1981)、最近邻插值等)将原图像缩放至较小的尺寸。由于雷达回波序列具备典型的时、空变化特性,文中联立两个自注意力基础结构,用于进一步提取时间和空间尺度的特征信息,形成一个新的时、空自注意力模块,结构如图1。因此,为有效提取较大尺寸数据的时、空特征信息,本研究采用适当下采样(128×128)+裁剪+时、空自注意力模块的处理方式。

图1 时、空自注意力模块Fig. 1 Spatiotemporal self attention module
以第l 个隐藏层为例,紫色虚线框内将该时间步的高阶特征信息进行时间特征部分的注意力计算,得到Q1h、Kh1、Vh1,将Q1h、Kh1通过转置相乘和Softmax 计算得到相似度矩阵,再将其与Vh1进行相似度计算得到Htl,将Htl作为空间特征部分的输入。黄色虚线框内对数据的空间特征做进一步卷积计算,得到Q2h、Kh2、Vh2,将Q2h、Kh2通过转置相乘和Softmax 计算得到相似度矩阵,再将其与Vh2进行相似度计算得到Mtl。最终,将Htl作为第l层第t+1 时间步的输入,将Mtl作为第l+1 层第t时间步的输入。其中,Htl表示第l层第t时间步的时间特征信息,Mtl表示第l层第t时间步的空间特征信息,Q1h、Kh1、Vh1和Q2h、Kh2、Vh2分别表示时间和空间维度的3 个隐藏状态权重矩阵, ⊗表示矩阵相乘,⊕表示矩阵相加;Wq1、Wk1、Wv1分别指通过卷积计算时间维度的“查询”向量、“被查”向量和“内容”向量时卷积核内可被训练的参数;Wq2、Wk2、Wv2分别指通过卷积计算空间维度的“查询”向量、“被查”向量和“内容”向量时卷积核内可被训练的参数;W1f指通过时间特征提取过程中最后一次卷积计算时卷积核内可被训练的参数;W2f指通过空间特征提取过程中最后一次卷积计算时卷积核内可被训练的参数。计算过程如式(1)—(4)所示
2.1.2 时、空自注意力门控单元构建
基于CNN 和RNN 搭建的记忆网络被广泛用于时、空序列预测,在这些神经网络中,往往保留了LSTM 或GRU 的门控结构。图2 为较为典型的ST-LSTM 单元结构,内部存在两个类似LSTM 的结构,分别用于提取时间维度的特征信息Htl和空间维度的特征信息Mtl。在多数情况下,此类结构搭建的PredRNN 模型的预测表现已经超越了最初的ConvLSTM 模型,但其缺陷在于空间特征信息Mtl的计算较为独立,没有充分融合时间特征信息Htl,且对空间维度信息Mtl提取不充分,这导致模型对雷达图像序列整体的时、空变化特征把握较差。

图2 ST-LSTM 单元 (左) 和ST-SARNN 单元 (右)Fig. 2 ST-LSTM block (left) and ST-SARNN block (right)
为充分提取雷达回波图像中像素间的时、空依赖关系,本研究基于ST-LSTM 单元的基本结构做进一步改进,得到图2 中的ST-SARNN 单元。两个单元的差异在于红色虚线框内的部分,ST-SARNN单元中嵌入了时、空自注意力模块(ST-SAM),用于强化模型内部记忆单元中时、空信息流的提取。Htl和Mtl的生成建立了更加密切的联系。其中,在生成Htl时进行了一次自注意力计算,并在生成Htl的基础上再进行一次自注意力计算得到Mtl。其中,⊗表示矩阵相乘, ⊕表示矩阵相加。
ST-SARNN 单元内部的计算过程如式(5)—(15)所 示。式 中,Wxg∗Htl-1表示 对 第l-1 层 第t时间步的输入进行卷积计算,Wxg、Whg等表示卷积核内的可被训练参数,bi、bf等表示偏置,σ(*)表示Sigmoid函数,Tanh 为激活函数,W1×1∗[Ctl,] 表示将Ctl和在通道维度进行连接,再进行一次1×1 卷积,并将作为时、空自注意力模块的输入。和Htl-1分别表示第l层第t-1时刻的时间维度隐藏状态矩阵和第l-1 层第t时刻的时间维度隐藏状态矩阵。表示第l层第t-1 时刻的初始记忆隐藏状态矩阵。Mtl-1表示第l-1 层第t时间步的空间维度隐藏状态矩阵。
2.1.3 时、空自注意力门控循环网络模型建立
为充分提取时、空特征信息,本研究对STSARNN 单元进行了叠加,如图3 所示。模型主要结构包括编码层(Encoding Network)和预测层(Forecasting Network)两部分,前者将输入的前一小时(10 帧)雷达回波图像编码,后者根据前者编码学习到的时、空特征对未来一小时(10 帧)进行预测。预测部分每个时间步第一层ST-SARNN 单元输入的雷达回波图为上一个时刻最高层的预测输出。
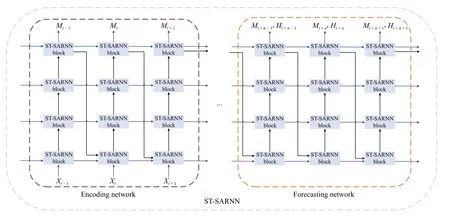
图3 时空自注意力门控循环网络Fig. 3 ST-SARNN
试验发现,在空间维度(竖直方向)上,随着堆叠层数的增加,模型的表现力会得到一定提升,但在4 层之后提升的幅度将不再明显,容易造成梯度消失,且会给GPU 造成巨大的压力。因此,本研究最终选择叠加4 层ST-SARNN 单元,且不同层STSARNN 单元的训练参数相互独立。在时间维度(水平方向)上,每个时间步接收到来自前一个时间步的输出信息和当前时间步上一层的输出信息,同一层ST-SARNN 单元的训练参数共享。其中,Xt代表t时刻雷达回波图像数据,Mt-1代表t-1 时刻最高层输出的空间特征信息,将其和t-1 时刻第一层的输出、以及Xt构成t时刻第一层的输入。其他层的ST-SARNN 单元接收来自该时间步上一层的输出Mtl-1、Htl-1以及上一个时刻同一层的输出、。预测层部分每个时刻最高层Ht+n最后经过一次1×1 卷积,生成一个与雷达回波图像维度相同的矩阵,并将其作为该时刻的预测。
2.2 试验环境及数据集
2.2.1 试验环境
本研究基于Python3.7 进行代码编写,通过Pycharm 软件进行编译,通过Pytorch 框架进行深度学习模型的开发。依托Python 第三方库,包括opencv、PIL、Numpy 等对雷达回波图像进行读取和处理。所用服务器搭载Linux 操作系统,运行内存64 G,显卡为NVIDIA TESLA V100 32 G,硬盘存储空间为10 T。
2.2.2 数据集
选用深圳市气象局与香港天文台共同建立的多普勒《标准雷达数据集2018》开展外推算法研究,该数据预先已经过质量控制等处理。数据集的覆盖时间为2010—2017 年每年3—7 月。其中每个雷达回波序列样本覆盖时长为6 h,序列中每一张雷达回波图时间间隔为6 min,共61 个时次,即每组雷达回波序列样本由61 张时间连续的雷达回波图像组成;垂直层次1 层,海平面高度3 km;雷达回波样本的水平分辨率为0.01°,约1 km;雷达图像大小为501×501。本研究利用10 万个序列样本作为训练集,3 万个序列样本作为验证集,2 万个序列样本作为测试集。选用前20 个时次的雷达回波序列作为样本,前10 个时次用于输入,后10 个时次用于预测。样本经过脱敏处理,雷达反射率因子范围为0—80 dBz,值越大代表降水的可能性越大,并以灰度图PNG 格式存储。由于原始雷达回波图像较大,需要将(501,501)维度的图像通过双线性插值法下采样成(128,128),再将其裁剪成(32,32,16),从而节省一部分显卡资源。
2.3 数据处理
图4 为数据集中不同回波强度样本占比的统计,强对流天气(超过45 dBz)的样本比例为9.9%,弱回波(低于35 dBz)样本占77.9%。
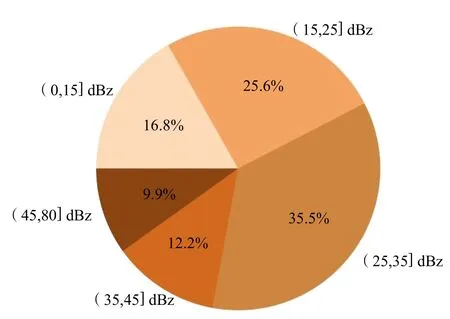
图4 数据集中不同回波强度样本占比Fig. 4 Sample proportion of different echo intensity in dataset
常规的归一化方法是将雷达回波序列直接除以80 dBz,这种简单的线性归一化方法无法改变数据分布,并不适用于样本不平衡的情况。因此,文中基于静态归一化方法进行改进,提出一种相对灵活的自适应归一化方法(ProNormalization),见式(16)。针对每个回波序列样本X(共20 帧),通过最大值函数(max(*))先求得这个序列样本中输入序列x(前10 帧)的最大回波值,若该值大于或等于60 dBz,则可认为该序列为强回波序列,直接除以80 dBz 实现归一化;否则,将回波序列样本X除以其最大值与增益(gain)的和作为归一化的结果。增益的目的在于为未来时刻可能预测到的雷达反射率因子增长提供一个增益空间,将其定义为一个常量20 dBz。若无增益空间,模型可能会面临难以预测雷达反射率因子增长的问题。
在对测试集预测时,需要记住样本的归一化分母(80 或 max(x)+gain),使模型得到输出y(后10 帧)时能够重新反乘回0—80 dBz 的范围。自适应的归一化方法使训练数据集不再呈现一种以低回波样本为主、高回波样本不足的不平衡分布状态,而是更加均匀地分布在0—1 内。
2.4 评价指标
对预测图像和实况图像进行二值化处理,将大于该阈值的像素赋值为255,小于该阈值的像素赋值为0。统计预测图像中像素点和实况图像中像素点对应位置的值相等且都为255 的格点数量,记为命中数量并用nsuc表示;统计预测图像中像素值为255,对应实况图像中像素值为0 的格点数量,记为空报数量并用navo表示;统计预测图像中像素值为0,对应实况图像中像素值为 255 的格点数量,记为误报数量并用nerr表示。
用以上3 个值组成本节的评估标准:CSI(TS)和POD,计算公式如式(17)和(18)所示。CSI 评分的取值为0—1,是评价模型外推性能的较为综合的一个指标,CSI 的值越接近1,说明模型外推的性能越出色。而命中率(POD)可以衡量实际发生的降雨且成功外推出降雨的概率,其值同样为0—1,值越大说明命中率越高,模型的预报性能越好。
3 结果与分析
3.1 自适应的归一化数据处理方法精度评估
试验选取雷达反射率因子35、40 和45 dBz 三个易导致强降水的等级作为灰度阈值,通过对外推结果进行二值化处理来进行精度评价。为验证本研究提出的自适应归一化方法对模型优化的普适性,将其用于5 种主流的时、空序列预测模型(ConvLSTM、PredRNN、MIM、SmaAt-Unet 和SEResUNet),分别命名为ConvLSTM_nor、PredRNN_nor、MIM_nor、SmaAt-UNet_nor 和SE-ResUNet_nor,将原有的5 个模型和这5 个模型进行对比分析,用于验证改进的归一化算法所带来的优化与提升。
为了直观体现外推精度的变化过程,对外推的10 个时次(1 h)的精度评分进行统计。表1 为ConvLSTM、PredRNN、MIM、SmaAt-Unet 和SEResUNet 模型在3 种级别阈值下经过自适应的归一化方法在测试集上预测10 个时次的平均精度比较。从表中可以看出,在35、40 和45 dBz 三种阈值下,自适应的归一化方法较大地提升了模型的预测表现,特别是40 和45 dBz 为阈值的情况下,3 种模型的CSI 评分提升均在10%或20%以上,这种针对数据集中强、弱样本不平衡而设计的归一化操作,甚至超越了改变模型结构本身所带来的影响;自适应的归一化方法对于45 dBz 以上回波的预测提升较大;自适应的归一化方法对于MIM 模型的提升不如ConvLSTM 和PredRNN 模型,因此,自适应的归一化方法所带来的精度提升幅度因模型而异。将自适应归一化方法(ProNormalization)与ST-SARNN 相结合,得到ST-SARNN*。

表1 三种级别阈值下各模型经过新归一化方法的平均精度Table 1 Quantitative comparison of the prediction of 10 frames on the test set by mainstream models under ProNormalization at three levels of thresholding
3.2 ST-SARNN*精度评估
将ST-SARNN 与5 个主流模型进行精度对比,从表2 中可以看出:在35 dBz 阈值条件下,STSARNN 的预测表现略有优势,而ST-SARNN*较MIM 在CSI 评分上提升了5.2%,较SE-ResUNet 提升了4.1%;在40 和45 dBz 阈值条件下,ST-SARNN和ST-SARNN*较MIM 和SE-ResUNet 在CSI 评分上均提升5.9%以上,提升较为明显。并且,STSARNN 和ST-SARNN*在3 种阈值下的POD 评分也得到了提升。由此可见,训练集的数据分布很大程度上影响着模型的收敛。并且,自注意力结构能够更好地提取强回波的特征信息;加入时、空自注意力模块后的时、空序列预测模型更加注重对强回波的预测。

表2 三种级别阈值下各模型的平均预测精度Table 2 The average prediction accuracy of each model under three level thresholds
为了直观地体现各模型的预测差异,选取一个典型的预测案例进行可视化展示,结果如图5 所示。其中,第1 行表示输入的前1 h 雷达回波图像,第2 行表示未来1 h 的实况,第3 至9 行表示各模型的预测结果。可以看出,原有的时、空预测模型已经具备了对雷达回波云团走势预测的能力,这依赖于模型中多个门控结构(遗忘门、更新门和输出门)对时间序列上的雷达回波分布特征进行选择性“遗忘”“更新”和“输出”。然而,在低回波样本主导的训练数据集中,这些模型较难对强回波的区域进行长期有效的预测,这表现为在逐时次的预测过程中,雷达回波云团呈现明显的消散趋势,尤其在40—50 dBz 区间内,原有的时、空预测模型对该强度范围的回波云团预测能力较差。然而在现实中,40 dBz 以上易发生强对流天气的区域恰恰是人们最为关心的,从ST-SARNN 和ST-SARNN*预测的结果来看,新模型和新归一化方法对强回波区域的预测能力有了一定提高。
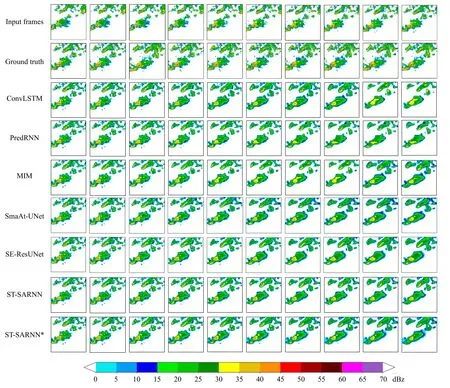
图5 各模型对某个案例的预测结果对比Fig. 5 Comparison of the predicted results of each model for a particular case
4 结论与讨论
现阶段,各种时、空序列预测模型对雷达低回波的外推表现差距不大,仅通过将CNN 与RNN 的门控结构相结合来进行雷达回波外推具有一定的局限。具体表现在:对于雷达回波反射率较强的区域较难把握;预测结果更倾向于一种消散的趋势,在持续降雨的情况下并不适用。针对这些问题,在数据处理层面,通过改进对雷达回波图像序列归一化的方式;在模型算法层面,将两个联立的自注意力结构引入ST-LSTM 结构,组成新的循环门控单元,并将这些循环门控单元进行堆叠,建立STSARNN 模型。优势表现在:
(1)当数据集中强降水样本较少时,ProNormalization 能够为模型的预测能力带来显著的提升;数据集中强对流天气样本(含有强回波的样本)的比重较大时,ProNormalization 和常规归一化方法的计算结果几乎一致,此时ProNormalization 所带来的提升并不显著。
(2)对大尺寸的雷达回波图像进行训练和预测时,单一的自注意力结构对模型预测能力的提升比较困难,而通过联立双层自注意力的结构在一定程度上能提高深度学习模型的预测能力,特别是对45 dBz以上雷达回波云团走势的预测能力.
(3)ProNormalization 和ST-SARNN 相结合得到的ST-SARNN*的预测表现出一定提升,预测结果的消散趋势得到了缓解,对强回波的运动轨迹预测更加可靠,更好地适用于持续性降雨的情况。
此外,循环神经网络相关模型预报结果偏弱的问题仍然存在,即模型能够较好地预报回波的消散,而预报回波增强的能力较弱,这使得较小尺度的强回波在经过几个时次后几乎消失。在未来,需要针对这一问题展开深入研究。基于CNN 和RNN的改进模型仍然存在预测图像分辨率低的问题,RWKV(Receptance Weighted Key Value)作为一种新颖的模型架构,有效综合了RNN 和Transformer的优点,同时规避了两者的缺点,为长时序预测提供了参考,在未来需要对其做进一步研究。
猜你喜欢
大自然探索(2023年7期)2023-08-15 00:48:21
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
小学生学习指导(低年级)(2018年12期)2018-12-29 11:13:24
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
火控雷达技术(2016年3期)2016-02-06 02:30:26
百科探秘·航空航天(2015年4期)2015-11-07 07:04:34
