
基于改进深度学习的电力营销数据异常识别研究
2024-03-05 06:53李佳凝
电气技术与经济 2024年2期
李佳凝
(国网山东省电力公司青岛市黄岛区供电公司)
0 引言
电能是我国最重要的基础能源之一,与国计民生、经济发展有着密切关联,采用深度学习模式,将其用于实体经济的分析,能够进一步推动电力行业的经济运转。在我国经济发展水平日益向好、国民生活质量日益改善的背景下,我国电力用户的数量也在持续增加,与此同时用电量也出现明显提升,在电力系统中电力业务所具有的重要意义和作用也逐渐突出,因此针对电力营销管理工作中所涉及到的电量管理工作的要求也愈发严格[1]。对电量管理工作而言,电费以及电价的统计分析工作极为关键,在进行电量管理工作时经常会遇到电量异常等问题,借助优化后的改进深度学习方法,对于电力营销工作中所涉及到的异常数据加以识别判断,可改善电力营销数据的准确性和可靠度。
1 深度学习简介
深度学习模式的原理,即找到学习资料数据中的表层含义与深层含义之间的关联规律,学习环节中获取的全部文字、音频及图像信息内容,具有深层次的应用价值。深度学习模式算法的主要目的,是和AI具有人类一样的领悟分析能力,能够精准识别文字、音频及图像信息,并且能够找到各类信息之间的必要关联,再加以处理。
简而言之,深度学习模式是一种相对繁杂的信息化学习算法,对于数据识别方面具有较为广阔的应用前景,远超数据挖掘、机器翻译等其他类型的信息处理技术[2]。
深度学习在异常检测方面展现出良好的性能,递归神经网络(RecurrentNeuralNetwork,RNN)常用于分析序列信息, 长短期记忆 (LongShort-TermMemory,LSTM)作为RNN 的分支网络,能够深度处理语音信息,并做好信息分类。
1.1 深度学习主要网络模型
卷积神经网络(ConvolutionalNeuralNetwork,CNN)为当前应用较多的深度学习理论中的研究模型之一,主要架构涵盖:信息输出模块、信息连接模块、信息输入模块及信息交换模块、池化模块等。为进一步优化电力事业发展,提升电网运行可靠性与安全性,相关研究人员已经开始采用深度学习模式用于电力行业中[3]。
自动编码器(AutoEncoder,AE)在创建之初实际上是用于压缩数据,主要具有下述特点:(1)与数据间具有密切联系,即代表自动编码器,仅能够对和训练数据较为类似的数据进行压缩处理;(2)通过该方法对数据进行压缩处理以后,会在一定程度上对数据产生损伤,这主要是由于在进行降维处理时必然会丢失部分信息。
通过自动编码器能够对输入原始数据所具有的一些隐蔽性特征进行学习,也就是编码(Coding)。在对新特征进行学习后,即可重新获得原始输入信息,这一过程也被称之为解码(Decoding)[4]。对自动编码器的工作情况进行分析,其实际上和主成分分析(PrincipalComponentAnalysis,PCA)具有相似之处,但是性能却得到显著优化,这主要是由于神经网络能够自动的对一些新的数据和能力进行学习,因此能够使得企业数据处理效率和质量均得到显著提高。在对自动编码器的工作原理和整体情况进行深入分析后,能够发现其实际上属于无监督式的深度学习模型,通过其能够获得多种多样的训练样本的新数据信息,所以从这一层面而言,其实际上也可以被划分到生成算法模型的范畴中[5]。
对于RNN结构进行分析,该算法能够对此前所输入的各项信息加以记忆,并在现有输出信息中进行应用,所以对于数据序列类型的数据信息进行计算时极为适用,而且将CNN 算法和RNN 算法联合应用可以很好地解决数据间的相关性问题。
1.2 基于改进深度学习的电力营销数据识别设计
采用改进深度学习模式的电力营销异常信息量的识别技术,主要涵盖Caffe网络架构、电力营销信息流清洗、异常识别标签注解这三个步骤,详细方法如下[6]。
1.2.1 Caffe网络学习框架
Caffe网络学习架构的主要功能,是作为电力系统中硬件设备运行的基础,主要包括网络学习中心、检测主机、深度学习节点、异常信息流采集等模块。
网络学习中心能够为电力系统的正常运行提供需要的电量数据,同时,可用信息传输通道将电子量数据传递至下级模块中。检测主机的作用是连接上级与下级的模块,能够在电量信息传输的过程中,把识别出来的异常信息均分到每个深度学习节点,这样可以让电信息捕获更为精准。异常信息流采集模块在Caffe网络学习架构的最底层,主要功能是梳理每个深度学习节点内的异常信息流,把信息流资料转化成固定格式的系统日志,并存储。Caffe网络学习架构参考图1。
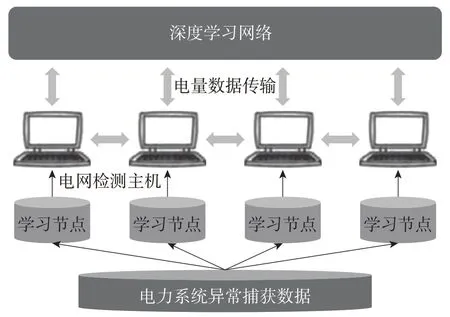
图1 Caffe网络学习架构
1.2.2 电力营销信息流清洗
信息流的清洗,即为处理电力营销数据中的异常信息,同时可辅助异常信息识别工作,将遗漏的异常信息再次捕捉并处理,将其所涉及到的不足之处进行解决应对的过程,通过传统的人工数据处理方法仅能够对少量的数据信息进行处理,而且还存在费时费力、效率较低等问题,同时对专业水平要求高,本身还会出错,不能满足海量调度管理类及实时类数据清洗要求[7]。基于此,开发出一种便捷高效快速的数据清理转换方法,并且借助一定的设备或者仪器实现自动化或者半自动化的数据清洗工作具有重要意义,对于控制数据质量也具有显著积极影响。
通常状况下,Caffe网络学习架构内,电力营销信息流清洗与流程化识别指标X密切关联,如果不考虑其余因素对于捕捉结果的影响,流程化识别指标X的参数越大,信息流清洗的效果就会越强,信息流清洗流程如图2所示。
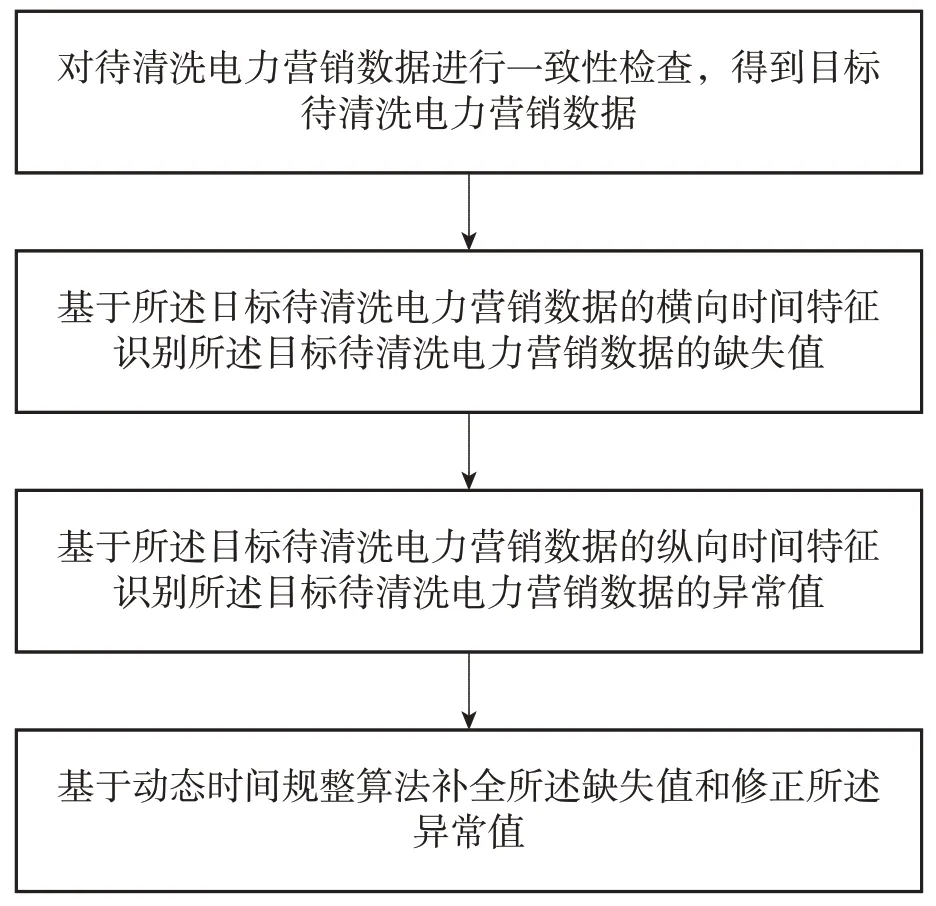
图2 信息流清洗流程
1.2.3 异常识别标签注解
异常检测主要分为以下两类。
(1)数据有标签。对于这样的数据,期望训练一个分类器,这个分类器除了要能告知正常数据的类别外,还要对于异常数据输出其属于“unknown”类,这个任务叫做Open-setRecognition[8]。
(2)数据无标签。这类数据分为两种,一种是数据是干净的(clean),也就是说数据集中不包含异常数据;另一种是数据是受污染的(polluted),数据集中包含少量的异常数据。其中,受污染的数据是更常见的情况。
一般状况下,营销异常信息内都会包含很多有着固定类别与特点的信息量,因此,能够自动对这种信息量的特点进行标注。然而还是会有个别识别节点,需要执行上级系统的判定指令,这也就是异常识别标签注解的目的。异常识别标签注解可以采集的系统信息量一定是有固定规律的,同时,信息量的输出必须是不间断的状态[9]。
2 异常识别研究
采用自动化协议,能够解决电力营销异常数据的智能化识别、提取。系统应用模块、数据传输模块、网络架构模块以及各链路布设于电力系统以太网络的外层,可以辅助Caffe网络学习架构系统的运行,为其提供更好的信息捕捉条件。
不但可以防止异常信息流对电力系统的攻击、恶意干扰,还能够把异常信息流梳理整合为一整体,进一步简化了Caffe网络学习架构系统的信息储存。异常信息流的复制会消耗大量的系统储存空间,在自动化协议多层模块的协助处理下,能够大幅度缩短异常信息流的识别获取时间,减轻50%的储存空间。异常信息流的传输速度普遍为l0Mb/s,识别标签注解功能可以将原有识别获取的速度提升数倍。
一般情况下,电力系统的内部访问权限不会对对深度学习模式开放,同时,在系统运行过程中,也会被信息捕捉节点的布置所干扰。所以,需要将电力营销异常信息的初始捕捉节点当做捕获映射网的搭建条件,对智能化捕获节点的范围加以限定。这样能够为电力系统应用深度学习模式捕捉异常信息提供更加有利的搭建环境。
3 改进深度学习的电力营销数据异常识别研究难点
异常信息流的审核环节中,核算人员需要根据电力系统内,电量营销、电费数据等条件,筛选异常用户,对其进行审核。审核条件是电量、电费审核过程中的重要参考,条件的制定与执行,对于审核工作来说十分关键。改进深度学习模型需要进行实际的训练,通过大量数据来提高它的准确性和智能性。深度学习实际上就是借助建立涉及到多个隐藏层的机器学习模型,通过大量的训练数据进行反复的学习,从中提取到数据的有用特征,进而使得预测或者分类工作准确性得到有效提升的一种方法。深度模型实际上是一种方式、一种手段,而特征学习才是其目的。在深度学习算法中,对于模型结构的深度极为重视,同时对于特征学习所具有的重要意义进行了着重表现,借助逐层的特征变化使得样本在原本空间中所具有的特征进行处理,以一个新的空间特征加以表示,进而降低预测或者分类工作的难度[10]。相较于人工规则构造特征算法而言,借助大数据进行课程学习,可以对数据所蕴含的大量内在信息进行更加准确可靠的体现。
在仅能够提供有限的数据的情况下,深度学习算法无法实现对数据中所包含规律的无偏差估计,所以为显著提高算法的精度,必须给予充足的数据支持。因为深度学习中图模型的复杂化,所以使得算法的时间和复杂程度大大提高,想要切实保证算法的实时性,还需要进一步优化改善硬件设备和编程技能。
4 结束语
基于改进深度学习模式下,电力系统营销的异常信息智能识别方法可采用Caffe网络学习架构,在清洗电力信息流的同时,能够对异常识别标签进行注解处理,并且因为自动化协议多模块架构系统的协助,待复制的异常信息可以与最终信息识别结果建立一一对应的捕获映射网,不但可以使电网运行环境更加稳定,还能够实现对异常传输信息流的精准处理,具备较强的应用可行性。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
军事运筹与系统工程(2020年1期)2020-09-11
铁道通信信号(2018年12期)2019-01-31
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
军事运筹与系统工程(2018年1期)2018-11-10
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
电信科学(2017年6期)2017-07-01
