
基于进化集成学习的用户购买意向预测
2024-03-05 05:31张一凡于千城张丽丝
计算机应用研究 2024年2期
关键词:特征选择
张一凡 于千城 张丽丝

收稿日期:2023-07-11;修回日期:2023-08-17 基金项目:宁夏重点研发计划(引才专项)项目(2022YCZX0013);宁夏重点研发计划(重点)项目(2023BDE02001);银川市校企联合创新项目(2022XQZD009);北方民族大学2022年校级科研平台《数字化农业赋能宁夏乡村振兴创新团队》项目(2022PT_S10);“图像与智能信息处理创新团队”国家民委创新团队资助项目
作者简介:张一凡(1998—),女,安徽宿州人,硕士,主要研究方向为机器学习、数据挖掘;于千城(1976—),男(通信作者),宁夏银川人,副教授,硕导,博士,主要研究方向为社会感知计算、社交网络分析、机器学习(1999019@nmu.edu.cn);张丽丝(1999—),女,云南曲靖人,硕士,主要研究方向为机器学习.
摘 要:在电子商务时代背景下,精准预测用户的购买意向已经成为提高销售效率和优化客户体验的关键因素。针对传统集成策略在模型设计阶段往往受人为因素限制的问题,构建了一种自适应进化集成学习模型用于预测用户的购买意向。该模型能够自适应地选择最优基学习器和元学习器,并融合基學习器的预测信息和特征间的差异性扩展特征维度,从而提高预测的准确性。此外,为进一步优化模型的预测效果,设计了一种二元自适应差分进化算法进行特征选择,旨在筛选出对预测结果有显著影响的特征。研究结果表明,与传统优化算法相比,二元自适应差分进化算法在全局搜索和特征选择方面表现优异。相较于六种常见的集成模型和DeepForest模型,所构建的进化集成模型在AUC值上分别提高了2.76%和2.72%,并且能够缓解数据不平衡所带来的影响。
关键词:购买预测;差分进化算法;进化集成;特征选择;模型选择
中图分类号:TP39 文献标志码:A
文章编号:1001-3695(2024)02-007-0368-07
doi:10.19734/j.issn.1001-3695.2023.07.0272
User purchase intention prediction based on evolutionary ensemble learning
Zhang Yifana,Yu Qianchenga,b,Zhang Lisia
(a.School of Computer Science & Engineering,b.The Key Laboratory of Images & Graphics Intelligent Processing of State Ethnic Affairs Commission,North Minzu University,Yinchuan 750030,China)
Abstract:In the era of e-commerce,accurately predicting user purchase intentions has become a crucial factor for enhancing sales efficiency and optimizing the customer experience.Addressing the limitations of traditional ensemble strategies,which often suffer from subjective biases during the model design phase,this paper introduced an adaptive evolutionary ensemble lear-ning model to predict user purchase intentions.This model adaptively selected the optimal base learners and meta-learners,incorporating both the predictive information from the base learners and the differential information between features to expand the feature dimensions,enhancing prediction accuracy.Moreover,to further refine the predictive capabilities of the model,this paper designed a binary adaptive differential evolution algorithm for feature selection,aiming to identify features that significantly influence the prediction outcome.Research results show that the binary adaptive differential evolution algorithm outperforms traditional optimization algorithms in global searches and feature selection.Compared to six common ensemble models and the DeepForest model,the proposed evolutionary ensemble model achieves a 2.76% and 2.72% increase in AUC value,respectively,and effectively mitigates the impacts of data imbalance.
Key words:purchase prediction;differential evolution algorithm;evolutionary ensemble;feature selection;model selection
0 引言
在互联网时代,电子商务因其便捷性和高效性得到了广泛的应用[1]。通过机器学习技术[2]对海量的电商数据进行分析和预测,有助于电商企业深入挖掘用户的购买意向和需求,从而提供更加精准化、个性化的服务和产品,进一步提高客户的满意度和企业竞争力。然而,随着互联网用户数据的爆炸性增长以及用户行为模式的多样化,准确预测用户的购买意向变得越来越具挑战性。现有预测模型大多基于集成学习技术[3],尽管这种技术在提高预测精度上有一定优势[4],但在处理日益复杂且高维度的电商数据时,由于模型设计和特征选择往往依赖于人工设定,缺乏足够的自适应性,所以预测的准确性和稳定性仍然有待提高。近年来,进化算法的快速发展为解决这一难题提供了可能。其在解决优化问题上具有独特的优势,特别是在处理高维、非线性、多模态等复杂问题上,展现出了优异的性能[5]。综上所述,本文结合进化算法和集成学习的优点,提出一种自适应进化集成模型。该模型包含模型选择层和模型融合层两层。选择层采用进化算法自适应地調整集成学习器的权重,找到在给定数据集上使投票分类器性能达到最优的权重组合,并将相应的学习器传递给融合层;融合层通过融合最优学习器组合的预测结果和重要特征的标准差扩展特征维度,并在元学习器上做最终的购买意向预测。为进一步优化模型的预测精度,本文还设计了一种二元自适应差分进化算法,该算法模拟生物进化的过程,通过自适应地调整交叉和变异率,有效地控制搜索过程中的扰动幅度,从而挑选出对预测准确性有显著影响的特征。本文的主要贡献如下:
a)设计的二元自适应差分进化算法可以自适应地调整交叉率和变异率,不断优化目标函数,有效选择出对购买意向预测有显著影响的特征,进而提高预测的准确性。
b)自适应进化集成模型解决了传统集成策略没有进行基学习器组合策略调优以及如何选择元学习器的问题。
c)融合最优基学习器组合的预测信息和特征差异扩展特征维度,使模型能够更深入地把握购买意向的预判信息,降低元学习器的欠拟合风险,并提高了对购买意向的判断精度。
d)采用常见的集成学习模型作为基学习器,实现了基于集成的再次集成,从而增强了模型的鲁棒性和泛化能力。
1 相关工作
在电子商务领域,运用机器学习技术预测用户的购买意向是一个重要的研究方向。传统的机器学习算法,如逻辑回归(logistic regression,LR)[6],往往存在泛化能力差和精度低等弊端。因此,随着数据量和复杂度的不断增加,这些传统机器学习算法的准确性和泛化能力受到了挑战。为了解决这个问题,学者们开始采用混合模型来提升机器学习的表现。混合模型是将模型或算法结合起来,以得到一个综合的预测结果。其中,Tang等人[7]将支持向量机(support vector machine,SVM)和萤火虫算法[8]相结合,Hu等人[9]使用SVM和LR相结合,有效解决了单一传统模型拟合能力不足的问题。但这种混合模型的组合过程较为简单,缺乏灵活性,很难进行深入优化。
近年来,集成学习被广泛应用于购买预测任务,主要模型有以bagging[10]方式集成的随机森林(random forest,RF)[11]和以boosting[12]方式集成的XGBoost(extreme gradient boosting,XGB)[13]、LightGBM(light gradient boosting machine)[14]、AdaBoost(adaptive boosting,AdaB)[15]、CatBoost(CatB)[16]和GBDT(gradient boosting decision tree)[17]等。这些模型通过整合多种不同的机器学习算法,有效克服了单一算法的局限性,且具有预测精度高、训练速度快、占用内存少等优点,成为解决数据挖掘任务的主流方案[18]。为了进一步提升模型的泛化表现,研究者们开始对集成模型进行融合。例如:李伊林等人[19]对多种预测算法的特性进行了比较和融合,最终构建了一个基于XGBoost的融合预测模型,该模型在预测精度和泛化能力方面的表现均优于单一预测模型;Nguyen等人[20]在预测帕金森病患者的抑郁症方面提出了一种堆叠集成模型,该模型不仅比单一模型具有更高的准确性,而且通过具体实例解释预测结果,使得医学专业人员能够以他们熟悉的方式理解人工智能对抑郁症的判断过程,从而更好地服务于临床实践。
融合模型在预测方面的优势已经得到了充分的证明,但其在结构设计上仍然依赖于人工设定,往往需要大量的实验或专业知识来获取最优的模型结构和参数配置,这在一定程度上限制了其在处理复杂和大规模问题上的应用。为了突破这些局限,进化集成学习应运而生。例如,Li等人[21]通过构建学习器盒并将其嵌入到遗传算法(genetic algorithm,GA)[22]中,通过对学习器进行二进制编码并设定合适的适应度函数,使得学习器盒能够自我调整并挑选出最优学习器组合。该框架在预测传染病的扩散趋势时表现出了较高的准确性,但是,模型在权衡学习器的权重以及突出关键特征方面尚有待完善。
针对电商平台提供的数据,需要进一步提取和衍生有意义的特征,以便更好地挖掘数据中潜在的用户行为信息和隐藏的规律。然而,并不是所有提取的特征都对模型的预测有贡献,因此特征选择成为提高模型准确性和可解释性的关键步骤。传统的特征选择方法[23]在处理大规模数据的效率以及特征集自适应调整的能力上存在不足。因此,许多研究者转向使用搜索能力更强的元启发式算法来处理特征选择问题[24,25]。其中,差分进化算法(differential evolution algorithm,DE)[26]因其具有全局搜索能力强、可适应性强和易于实现等优点,被应用于特征工程中。为了进一步提升特征选择的效果,研究者对种群组合、搜索空间、交叉和变异操作等方面进行了深入的优化,提出了MDEFS[27]、ACCFS[28]、MVDE[29]和SaWDE[30]等算法。虽然改进的DE算法在其他领域得到了广泛应用[31,32],但在购买意向预测方面仍然鲜有研究,有待进一步探索。本文综合考虑了特征属性和集成过程中的学习器选择,实现了特征选择与模型结构的自适应优化。同时,通过融合学习器组合的预测信息和特征差异扩展特征维度,使模型能够更深入地把握用户购买意向的预判信息,显著提升购买预测模型的准确性。
2 二元自适应差分进化算法的特征选择
特征选择本质上是一个二元离散型问题。本文设计了一个二进制版本的自适应差分进化算法(BADE),以获得最优特征子集。具体操作如下:
a)初始化种群。在BADE中,种群是多个二元参数向量组成的集合。若目标任务的数据集包含N个特征,则初始化一个1×N个特征的参数向量,其中每个元素的值都是0或1。编码如图1所示。
根据特征的维度,设置合适的种群大小NP,重复上述编码NP次,即可得到有NP个个体的初代种群,并记为
Xi(0)=(Xi,1(0),Xi,2(0),…,Xi,N(0)) i=1,2,3,…,NP(1)
b)适应度函数设置。选用以决策树(decision tree)分类器对输入数据进行五折交叉验证后得到的精确度(accuracy)和曲线下面积(AUC)的均值作为适应度值,其定义如下:
fitness=accuracy5-fold(X)+AUC5-fold(X)2(2)
其中:X是指用二进制向量标识的特征子集;accuracy5-fold(X)和AUC5-fold(X)代表了分类器在训练数据上进行五折交叉验证得到的accuracy和AUC值。
c)进化操作。进化操作是模拟生物进化的众多操作,包括变异、交叉和选择三个步骤。
(a)变异操作。本文采用一种基于“锦标赛选择”的复合变异策略[33],具体来说,从当前种群中随机选择三个不同的个体,记为Xr1(g)、Xr2(g)和Xr3(g)(满足r1≠r2≠r3)。然后,根据适应度值由低到高的顺序分别标记为Xbr(g)、Xer(g)和Xhr(g)。选取Xbr(g)作为变异基向量,Xer(g)-Xhr(g)为差分向量。该变异策略如式(3)所示。
Vi(g)=Xbr(g)+F·(Xer(g)-Xhr(g))(3)
其中:F为变异缩放因子,用来控制变异操作的幅度。
在执行完变异操作后,使用式(4)对变异向量进行修正,以确保每个元素都处于0和1之间,这样可以确保变异后的个体的每个元素都是二进制位,保证算法的正确执行。
Vi(g)=1Vi(g)>1
0Vi(g)<0(4)
(b)交叉操作。交叉操作需要借助目标向量Xi,j(g)和变异向量Vi,j(g)重组产生新的实验向量Ui,j(g),这样既保留了原个体的信息,又引入了变异个体的信息,如式(5)所示。
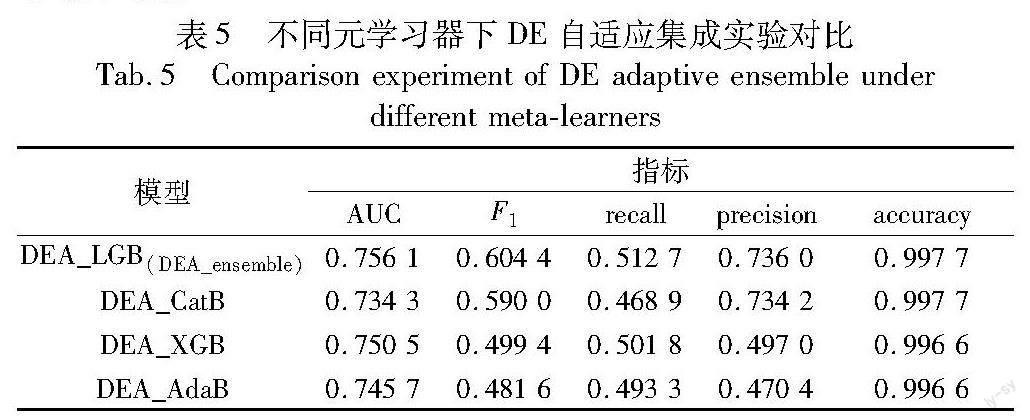
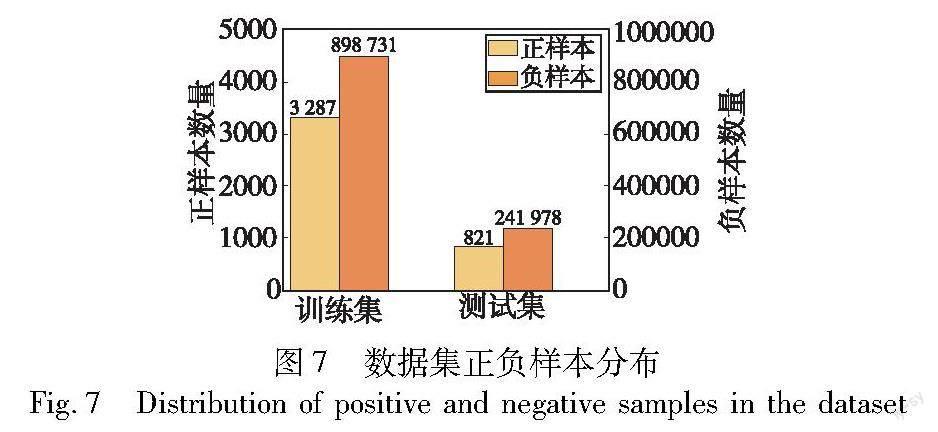
Ui,j(x)=Vi,j(g)if rand(j) Xi,j(g)otherwise(5) (c)选择操作。选择操作是根据评估实验向量和原始个体的适应度大小来选择下一代的策略,其目的是选择出种群中的最优个体,使种群逐渐收敛至全局最优解。具体选择方式如下: Xi(g+1)=Ui(g)if f(Ui(g))>f(Xi(g)) Xi(g)else(6) 其中:f为适应度函数。在Ui,j(g)和Xi,j(g)之间采用贪婪选择策略,较优个体作为新的个体。通过特定的策略,动态地调整变异因子和交叉因子。当算法找到一个更优的解(即f_new>best_fitness)时,交叉率和变异率会增加,这有助于提高种群中不同个体间的多样性,促使算法在搜索空间中尝试新的区域,以寻找可能存在的更优解。调整策略如式(7)所示。 F=min(1,F+μ) CR=min(1,CR+μ)(7) 其中:μ表示每次调整时增加或減少的数值。若在连续的T次迭代中未能找到更优的解决方案,算法将减小交叉率和变异率,以便让算法更加专注于在当前已知优良解的邻近区域进行搜索,期望在这些区域发现更优的解。调整策略如式(8)所示。 F=max(0.1,F-μ) CR=max(0.1,CR-μ) (8) 算法1描述了使用BADE算法进行特征选择的具体流程。 算法1 二元自适应差分进化算法特征选择流程 输入:种群数量NP;变异缩放因子F;交叉因子CR;最大迭代次数Gmax;连续未发生变化的迭代次数T;调整值μ。 输出:最优特征子集。 对特征进行编码并初始化种群 for g=1 to Gmax do 根据式(2)计算当前种群中每个个体的适应度fitness for i=1 to NP do 使用锦标赛策略在当前种群中随机选取三个互不相同的个体,将适应度最大的个体作为基向量。同时,根据式(3)执行变异操作,并利用式(4)生成修正向量 根据式(5)进行交叉操作 依据式(6)进行选择操作,以生成新一代种群 根据式(7)(8)调整变异缩放因子和交叉因子的值 end for g=g+1 end for 3 DE自适应进化集成模型 为了探究用户的购买意向,本文设计了一种DE自适应进化集成模型(DEA_ensemble),如图2所示。模型由两层组成: a)模型选择层。模型选择和权重学习被集成到一起,通过差分进化算法自适应地调整学习器的权重,得到最优学习器组合和元学习器。 b)模型融合层。通过融合基学习器的预测结果和重要特征的标准差扩展特征维度,进而在元学习器上做最终的购买意向预测。 3.1 模型选择层 为了更高效地找到最优基学习器组合和元学习器,在选择层设计了一个基于差分进化算法的多模型集成优化方法。首先,选取传统集成模型作为学习器放入模型池中,记为{model1,model2,…,modelM},并使用训练集依次对它们进行训练。其次,采用差分进化算法将这些学习器初始化为一个包含NP个个体的种群,其中每个个体都是一个长度为M的权重向量。使用投票分类器按照学习器的权重进行组合,并将其应用于交叉验证数据集进行评估,计算AUC得分作为适应度值,如式(9)所示。差分进化算法能够自适应地调整学习器的权重,找到能使投票分类器性能在给定数据集上最大化的权重组合。最后,根据设定的权重阈值,得到基学习器的最佳组合方式,记为{modelx,…,modeln}。在这组学习器中,权重值最大的学习器被选为元学习器,并反馈给融合层。 AUC=1k[∑i∈positiveClassranki-T(1+T)2T×N](9) 其中:k表示k折交叉验证;∑i∈positiveClass表示只把正样本序号加起来;ranki表示第i条样本的序号;T和N分别是正样本和负样本的个数。 3.2 模型融合层 为了优化模型的整体预测能力,设计了一种融合模型和数据的策略。首先,将训练集分成两部分:一部分用于基学习器的训练,记为{train_data};另一部分用于生成元学习器的训练集,记为{validation_data}。然后,使用{train_data}分别对{modelx,…,modeln}进行训练,在{validation_data}上进行预测,并计算每个基学习器中前五个重要特征的标准差。预测数据记为{V_Px,…,V_Pn},重要特征的标准差记为{V_Fx,…,V_Fn}。同时,在测试集{test_data}上使用{modelx,…,modeln}进行预测,并计算每个基学习器中前五个重要特征的标准差。预测的数据记为{T_Px,…,T_Pn},重要特征的标准差记为{T_Fx,…,T_Fn}。之后,需要重组新的特征构建新的数据集。将{V_Px,…,V_Pn}、{V_Fx,…,V_Fn}与{validation_data}合并,作为元学习器的训练集,记为{metamodel_traindata};{T_Px,…,T_Pn}、{T_Fx,…,T_Fn}和{test_data}合并,作为元学习器的测试集,记为{metamodel_testdata}。最后,使用{metamodel_traindata}训练元学习器,{metamodel_testdata}进行预测,得到模型最终的预测结果。 由于传统集成模型本身可以作为特征评估器,而标准差可以呈现top-k特征上的实例差异[34],所以,该模型可以更加充分地利用特征数据和预测信息提升模型的整体预测能力。此外,通过改变训练数据和测试数据的特征维度还可以有效地降低元学习器欠拟合的风险。 4 实验准备 4.1 数据介绍 本文的实验数据采用的是京东商城真实在线交易数据,包含四类共计六个数据集。详细信息如表1所示。 JData_Action_201604.csv13 199 9344月行为记录 京东商城提供了2016年2月1日至4月15日期间的数据,包括105 321位用户的行为数据,共50 601 736条;24 187件商品的558 552条评论数据。 4.2 数据预处理 本文使用的是平台真实的交易数据,收集过程中可能会出现误差,导致数据重复和缺失等问题。这些问题会对后续的特征构建和模型训练的有效性产生一定影响,因此,本文将从以下几个方面对数据进行预处理。 a)噪声数据处理。检查用户信息表和用户行为表中的用户是否一致;检查是否存在注册时间在4月15日之后的用户;删除没有任何购买记录的爬虫用户。 b)缺失字段处理。在分析用户信息和行为数据时,发现有三位用户的性别、年龄和注册时间数据缺失,但这三位用户均存在行为记录。因此,采用其前一位用户的信息对这些缺失值进行填补。 c)數据类型处理。对用户属性中的性别字段定量化处理;把唯一标识用户和商品的ID属性转换为整数类型;规范购买时间的格式,以方便后续计算。 4.3 特征提取 由于用户的历史行为数据对未来购买意向预测具有重要影响,所以在进行特征提取时,本文采用了滑动窗口的方法。具体来说,通过设置五个滑动窗口,分别对应购买意向预测日期前的1天、2天、3天、一周和半个月,每五天滑动一次。 图3展示了使用滑动窗口抽取特征的示意图,其中,滑窗左侧的数字代表了一个滑窗下的数据集大小。除基础特征外,本文还抽取出用户行为特征、用户-商品行为特征、用户-品类行为特征和用户-品牌行为特征共343维。 4.4 评价指标 本文实验采用准确率(accuracy)、精确率(precision)、召回率(recall)、F1值(F1-score)和AUC值(area under curve)作为模型的性能评价指标。计算公式如式(10)~(13)所示。 accuracy=TP+TNTP+TN+FP+FN(10) F1=2×precision×recallprecision+recall(11) precision=TPTP+FP(12) recall=TPTP+FN(13) 4.5 实验环境 表2列出了实验的软硬件环境、算法框架、模型方法等。 5 实验结果及分析 5.1 特征选择实验分析 图4展示了应用BADE算法进行特征选择的结果。解码处理后,共得到151个特征。其中,3个特征属于用户基础特征,包含性别和注册日期等;3个特征属于商品基础特征,包含商品属性。此外,有27个用户-商品行为特征,29个用户-品类行为特征,36个用户-品牌行为特征,51个用户行为特征,还有两个评论特征。所选定的特征均在预测目标变量时发挥重要的作用。为了验证所提二元自适应差分进化算法的优化效果,本文对BADE、DE、GA和模拟退火算法(SA)四种优化算法进行对比分析,适应度值变化曲线如图5所示。可以观察到,在处理用户购买意向数据的过程中,随着迭代次数的增加,各个算法在适应度值优化上呈现出不同的趋势。其中,BADE算法的适应度值明显高于其他算法。这表明,BADE通过自适应地调整交叉率和变异率,能够有效控制搜索过程中的扰动幅度,使其在搜索空间的探索方面具备显著优势,展现出卓越的全局搜索能力。 表3展示了XGBoost、LightGBM、CatBoost和AdaBoost四种集成学习模型在原始特征数据和经过GA、SA、DE以及BADE选择的特征数据上的预测表现。实验结果表明,相比于未经特征选择的原始数据,进行特征选择后的数据在模型上的预测性能有不小的提升。这表明原始数据中存在大量的冗余信息,这些信息对模型的性能和拟合效果产生了负面影响。深入分析发现,使用BADE算法选择的特征在多数模型上的预测性能超过了使用GA、SA和DE算法选择的特征。尽管在XGBoost模型上,BADE算法的表现稍逊于GA算法,但这个差距极其微小。因此,可以推断,本文BADE算法在特征选择方面具有一定的优势。 5.2 DE自适应进化集成模型实验分析 本文选用经过BADE算法特征选择后的数据,将RandomForest、XGBoost、CatBoost、LightGBM、AdaBoost和GBDT共六种传统集成模型放入模型池中进行选择。图6展示了选择层中各模型对应的权重值。通过设定权重阈值为0.6,得出最优基学习器组合为{LightGBM、XGBoost,CatBoost,AdaBoost},元学习器设为拥有最高权重的LightGBM模型。 表4详细比较了DEA_ensemble模型、深度神经网络(DNN)、深度森林(DeepForest)以及六种传统的单一集成模型在五个评估指标上的表现。实验结果显示,相较于六种单一集成学习模型,DEA_ensemble在AUC值上提高了2.76%,而DNN并未显现出优势。这可能是因为购买意向预测数据集存在严重的类别不平衡问题,而神经网络在处理这类数据时,对少数类别的识别率通常较低[35]。相比之下,作为集成学习和深度学习相结合的模型,DeepForest的性能表现有所提升。 本文还与文献[19~21]进行了对比分析。结果显示,文献[20]所探寻的学习器组合在购买预测任务中的表现并不理想,而文献[19]在此基础上对训练元学习器数据的特征维度进行了扩展,因此预测效果得到了一定提升。文献[21]在选取较优学习器组合的基础上,进一步利用了学习器的预测信息来增强特征维度,使得模型在整体分类性能上超过了前两种模型。而DEA_ensemble作为一种基于多层集成的融合模型,不仅整合了最佳基学习器的预测结果,还加入了特征的标准差进行数据增强,为元学习器提供了充足的训练数据,成功地减少了欠拟合的风险。显然,该模型在各项评价指标上,除了precision之外,均有明显提升。特别是AUC上,其得分达到了75.61%。这充分证明,在分类任务中,该模型相对于其他比较模型,具备显著的性能优势。 为了验证DE自适应调整基学习器组合、选择元学习器以及扩展元学习器特征维度方法的有效性,本文将选出的最优学习器分别作为元学习器进行对比实验。如表5所示,DEA_LGB、DEA_XGB、DEA_CatB、DEA_AdaB分别表示在选择层中选中的四个最优学习器,将它们依次作为元学习器。实验结果表明,DEA_ensemble模型与性能最低的元学习器在AUC指标上的差异仅为0.021 8且均优于传统的单一模型,证明了DEA_ensemble模型在处理购买预测任务时具有较高的稳定性和健壮性。 5.3 不平衡数据集的影响分析 如图7所示,用户购买意向预测数据集的正负样本比例呈现出显著的不平衡。在训练集中,正样本有3 287个,而负样本高达898 731个,负样本和正样本的比例为237:1。同样地,测试集中的样本比例为294:1。这种不平衡的情况会导致模型过度关注数量众多的负样本,在预测较少的正样本时产生误判。 图8则展示了各模型在训练集与测试集上的分类性能,呈现出明显的差异。GBDT与其他模型的表现不同,其经过训练后,在测试集上表现出色。CatBoost在训练集和测试集上的AUC值差距最大,达到了0.038。相比之下,DEA_ensemble模型在这两者之间的差距仅为0.013 4,说明其在不同数据集上的性能更为稳定。考虑到模型性能的差异,本文引入了对抗验证(adversarial validation)策略来评估训练和测试数据分布的一致性。这一过程涉及合并训练数据和测试数据并创建一个新的二元目标变量,训练集的样本被标记为1,测试集的样本标记为0,使用LightGBM模型来预测新的目标变量,以评估两个数据集的分布差异。通过计算模型的AUC值进行评估,若AUC值明显高于0.5,则该模型能有效地区分来自训练集和测试集的数据,也说明训练集和测试集的分布存在显著的差异。 图9为对抗验证的结果,AUC达到了0.89。这一数值揭示了模型具有有效识别来自训练集和测试集样本的能力,进一步证明训练集与测试集的分布存在显著不一致性,这也是导致训练集和测试集在AUC上性能差异的主要原因。值得注意的是,尽管数据分布存在不一致性,而DEA_ensemble在提高分类性能的同时也显现出了缓解数据不平衡所带来负面影响的潜力。 如图10所示,混淆矩阵可详细检验模型的预测结果。矩阵显示,在241 978个负样本中,模型准确地预测了241 827个,这表明模型在识别非购买用户方面表现优异。然而,在预测负样本时产生了151个假阳性误报,这可能会导致资源的不必要浪费,因为这部分用户实际上并没有购买意向,而模型却错误地将他们预测为潜在的购买者。在处理正样本方面,模型在821个样本中成功预测出了421个,即使面临数据不平衡的问题,仍能成功地识别出超过一半(51.3%)的购买用户。因此,鉴于类别不平衡的挑战,模型表现出较为可观的鲁棒性。 6 结束语 为了更加精准地预测用户的购买意向并在特征选择和模型结构上实现自适应优化,本文首先设計了一个二元自适应差分进化算法。该算法通过自适应地调整交叉率和变异率,不断优化目标函数,筛选出对购买意向预测结果有重要影响的特征。其次,构建了DE自适应进化集成模型用于预测用户的购买意向。与传统集成策略相比,该模型可以自适应地调整基学习器的组合并选择合适的元学习器,降低了模型设计阶段因人为选择而可能引入的误差。此外,模型融合了最优基学习器的预测信息和特征间的差异性扩展特征维度,使其更全面地捕捉购买预判信息,进而提高预测精度。 實验结果显示,本文算法在特征选择上优于传统优化算法。同时,所构建的模型不仅在分类性能上超越了传统集成学习模型和深度森林模型,而且有效地缓解了数据不平衡所带来的负面影响。然而,对于正样本的预测准确率,仍存在进一步优化的空间。因此,在未来的工作中,将着重探索处理类别不平衡的策略,以更精确地预测用户的购买意向。 参考文献: [1]刘馨蔚.基于大数据时代下电子商务个性化推荐的研究与应用[J].现代商业,2022(15):23-25.(Liu Xinwei,Research and application of personalized recommendation in e-commerce in the era of big data[J].The Business Circulate,2022(15):23-25.) [2]Roscher R,Bohn B,Duarte M F,et al.Explainable machine learning for scientific insights and discoveries[J].IEEE Access,2020,8:42200-42216. [3]Dong Xibin,Yu Zhiwen,Cao Wenming,et al.A survey on ensemble learning[J].Frontiers of Computer Science,2019,14(2):241-258. [4]彭岩,马铃,张文静,等.基于集成学习的风险预测模型研究与应用[J].计算机工程与设计,2022,43(4):956-961.(Peng Yan,Ma Ling,Zhang Wenjing,et al.Research and application of risk forecast model based on ensemble learning[J].Computer Engineering and Design,2022,43(4):956-961.) [5]吕帅,龚晓宇,张正昊,等.结合进化算法的深度强化学习方法研究综述[J].计算机学报,2022,45(7):1478-1499.(Lyu Shuai,Gong Xiaoyu,Zhang Zhenghao,et al.Survey of deep reinfocement learning methods with evolutionary algorithms[J].Chinese Journal of Computers,2022,45(7):1478-1499.) [6]Cruz A G,Cadena R S,Faria J A F,et al.Consumer acceptability and purchase intent of probiotic yoghurt with added glucose oxidase using sensometrics,artificial neural networks and logistic regression[J].International Journal of Dairy Technology,2011,64(4):549-556. [7]Tang Ling,Wang Anying,Xu Zhenjing,et al.Online-purchasing behavior forecasting with a firefly algorithm-based SVM model conside-ring shopping cart use[J].Eurasia Journal of Mathematics,Science and Technology Education,2017,13(12):7967-7983. [8]Li Jun,Wei Xiaoyu,Li Bo,et al.A survey on firefly algorithms[J].Neurocomputing,2022,500:662-678. [9]Hu Xin,Yang Yanfei,Zhu Siru,et al.Research on a hybrid prediction model for purchase behavior based on logistic regression and support vector machine[C]//Proc of the 3rd International Conference on Artificial Intelligence and Big Data.Piscataway,NJ:IEEE Press,2020:200-204. [10]Bbeiman L,Quinlan R.Bagging predictors[J].Machine Learning,1996,24(2):123-140. [11]Ghosh S,Banerjee C.A predictive analysis model of customer purchase behavior using modified random forest algorithm in cloud environment[C]//Proc of the 1st International Conference for Convergence in Engineering.Piscataway,NJ:IEEE Press,2020:239-244. [12]Grabner H,Bischof H.On-line boosting and vision[C]//Proc of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2006:260-267. [13]Wang Wenle,Xiong Wentao,Wang Jing,et al.A user purchase beha-vior prediction method based on XGBoost[J].Electronics,2023,12(9):2047. [14]Lu C J,Lee T S,Lian C M.Sales forecasting for computer wholesalers:a comparison of multivariate adaptive regression splines and artificial neural networks[J].Decision Support Systems,2012,54(1):584-596. [15]Algawiaz D,Dobbie G,Alam S.Predicting a users purchase intention using AdaBoost[C]//Proc of the 14th International Conference on Intelligent Systems and Knowledge Engineering.Piscataway,NJ:IEEE Press,2019:324-328. [16]Cao Wenchao,Wang Ke,Gan Hongcheng,et al.User online purchase behavior prediction based on fusion model of CatBoost and Logit[J].Journal of Physics:Conference Series,2021,2003:012011. [17]Zhao Erfeng,Li Yi,Zhang Jingmei,et al.Interval prediction model of deformation behavior for dam safety during long-term operation using Bootstrap-GBDT[J].Structural Control and Health Monitoring,2023,2023:article ID 6929861. [18]叶志宇,冯爱民,高航.基于深度LightGBM集成学习模型的谷歌商店顾客购买力预测[J].计算机应用,2019,39(12):3434-3439.(Ye Zhiyu,Feng Aimin,Gao Hang.Customer purchasing power prediction of Google store based on deep LightGBM ensemble learning model[J].Journal of Computer Applications,2019,39(12):3434-3439.) [19]李伊林,段海龙,林振荣.数据平衡与模型融合的用户购买行为预测[J].计算机应用与软件,2022,39(9):50-55,86.(Li Yilin,Duan Hailong,Lin Zhenrong.Prediction of use purchase behavior based on data balance and model fusion[J].Computer Applications and Software,2022,39(9):50-55,86.) [20]Nguyen H V,Byeon H.Prediction of Parkinsons disease depression using lime-based stacking ensemble model[J].Mathematics,2023,11(3):708. [21]Li Xiaoning,Yu Qiancheng,Yang Yufan,et al.An evolutionary ensemble model based on GA for epidemic transmission prediction[J].Journal of Intelligent & Fuzzy Systems,2023,44(5):7469-7481. [22]Holland J H.Genetic algorithms[J].Scientific American,1992,267(1):66-73. [23]李郅琴,杜建強,聂斌,等.特征选择方法综述[J].计算机工程与应用,2019,55(24):10-19.(Li Zhiqin,Du Jianqiang,Nie Bin,et al.Summary of feature selection methods[J].Computer Enginee-ring and Applications,2019,55(24):10-19.) [24]Li Xiaoning,Yu Qiancheng,Tang Chen,et al.Application of feature selection based on multilayer GA in stock prediction[J].Symmetry,2022,14(7):1415. [25]Nurhayati,Agustian F,Lubis M D I.Particle swarm optimization feature selection for breast cancer prediction[C]//Proc of the 8th International Conference on Cyber and IT Service Management.Piscata-way,NJ:IEEE Press,2020:1-6. [26]Storn R,Price K.Differential evolution—a simple and efficient heuristic for global optimization over continuous spaces[J].Journal of Global Optimization,1997,11(4):341-359. [27]Ot A,Ttn B,Sm C.A novel wrapper-based feature subset selection method using modified binary differential evolution algorithm[J].Information Sciences,2021,565:278-305. [28]Firouznia M,Ruiu P,Trunfio G A.Adaptive cooperative coevolutionary differential evolution for parallel feature selection in high-dimensional datasets[J].The Journal of Supercomputing,2023,79:15215-15244. [29]Hassan S,Hemeida A M,Alkhalaf S,et al.Multi-variant differential evolution algorithm for feature selection[J].Scientific Reports,2020,10(1):17261. [30]Wang Xubin,Wang Yunhe,Wong K C,et al.A self-adaptive weighted differential evolution approach for large-scale feature selection[J].Knowledge-Based Systems,2022,235,10:107633. [31]Chakraborty S,Saha A K,Ezugwu A E,et al.Differential evolution and its applications in image processing problems:a comprehensive review[J].Archives of Computational Methods in Engineering,2023,30(2):985-1040. [32]畢超超,范勤勤,王维莉.基于策略自适应的多目标差分进化算法及其应用[J].计算机应用研究,2020,37(7):2016-2021.(Bi Chaochao,Fan Qinqin,Wang Weili.Multi-objective differential evolution algorithm based on self-adaptive strategy and its application[J].Application Research of Computers,2020,37(7):2016-2021.) [33]傅嗣鹏,乔俊飞,韩红桂.基于锦标赛选择变异策略的改进差分进化算法及函数优化[J].计算机科学,2013,40(S1):15-18,36.(Fu Sipeng,Qiao Junfei,Han Honggui.Improved differential evolution algorithm based on mutation strategy of tournament selection for function optimization[J].Computer Science,2013,40(S1):15-18,36.) [34]Guo Yang,Liu Shuhui,Li Zhanhuai,et al.BCDForest:a boosting cascade deep forest model towards the classification of cancer subtypes based on gene expression data[J].BMC Bioinformatics,2018,19:article No.118. [35]董勋,郭亮,高宏力,等.代价敏感卷积神经网络:一种机械故障数据不平衡分类方法[J].仪器仪表学报,2019,40(12):205-213.(Dong Xun,Guo Liang,Gao Hongli,et al.Cost sensitive convolutional neural network:a classification method for imbalanced data of mecha-nical fault[J].Chinese Journal of Scientific Instrument,2019,40(12):205-213.)
猜你喜欢
福州大学学报(自然科学版)(2022年1期)2022-01-21
河南科学(2021年3期)2021-05-06
电信科学(2017年6期)2017-07-01
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
电测与仪表(2016年23期)2016-04-12
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
电测与仪表(2015年24期)2015-04-09
振动工程学报(2014年4期)2014-03-01
