
一种基于异质信息网络的多维度语义融合推荐算法研究
2024-03-04 13:02王华武
江西科学 2024年1期
甘 宏,王华武
(1.广州南方学院商学院, 510970,广州;2.江西新余国科科技股份有限公司,338034,江西,新余)
1 问题提出
在算法推荐中,数据集可能包含了许多异质信息,而异质信息又隐含丰富的语义关系。如何有效建模多源异质信息及如何有效利用其中丰富的语义关系是现有的推荐算法急需解决的2个问题。
异质信息网络是由多种类型的节点和边组成的复杂网络,是一种通用的融合多源异质数据的方法[1]。而异质信息网络[2]的推荐模型为上述问题提供了有效的解决途径。采用异质信息网络对推荐系统内的交互进行建模,可保留推荐系统中的实体和关系,又可以高效地整合各种属性和辅助信息。基于异质信息网络的推荐模型在提取语义结构、融合语义信息等方面具有显著优势[3]。现有的许多方法都使用元路径结构对异质信息网络内的多元关系进行显式约束,但在元路径设计、元路径聚合模式及损失函数设计上仍有很大的改进空间。
图神经网络使用图结构来表示输入的神经网络,并通过相邻节点之间的消息传递来捕捉图中的交互关系,核心目标是学习图中各节点的特征表示。与此同时,深度学习领域的图神经网络(GNN)受到了研究者的广泛关注。图神经网络的结构与异质图的思想十分适应,在提取和聚合语义信息上具有显著的优势,于是逐渐成为实践中的热门选择。总体而言,异质图神经网络在推荐任务上表现出优越的性能。然而,目前基于图神经网络的推荐模型普遍存在邻域信息聚合过程中发生信息损失的问题,在异质图模型中,由于多源异质信息存在属性维度上的差异,会导致更大程度的信息损失[4]。
本文提出了一种基于异质信息网络的多尺度语义融合系统推荐模型。首先,使用异质图和元路径来建模推荐中的复杂语义结构。然后,将元路径引导下的邻域划分为多个邻居组,利用邻居组之间的多层交互获取多尺度语义信息。最后,使用两阶段的关系注意力来指导多尺度语义融合。
2 相关技术
2.1 基于异质信息网络的推荐模型
基于异构网络节点(HERec)[5]采用随机游走的策略,利用元路径结构生成对象序列以学习对象的嵌入表示,最后,将其与矩阵分解框架相结合以进行商品推荐;异构信息网络(LGRec)[6]使用共同的注意力机制对用户和物品之间的直接交互信息进行建模,并利用元路径提取的间接交互信息预测交互概率,最终实现了对排序推荐任务的改进;NeuACF[7]使用深度神经网络计算不同元路径下的相似性矩阵,其中每个相似性矩阵代表用户在某个方面的偏好,全面地考虑了用户在各个方面的兴趣,然后使用多层感知机学习用户和商品方面的特征,并使用注意力机制来融合这些特征以得到最终的表示。元路径(HueRec)[8]假设在不同元路径约束下用户或商品具有共同的语义特征,因此,可以使用全部的元路径来学习用户和商品的统一表示。GNewsRec模型[9]针对新闻推荐任务利用不同的关系矩阵对不同的交互类型进行建模,通过完整的用户行为历史捕获用户的长期兴趣,并设计融合注意力的 LSTM 模型以建模用户的短期兴趣,最终融合长短期兴趣辅助推荐。Comb-K模型[10]是一种利用异质图卷积网络和异质图池化网络的组合优化模型用于促销推荐任务,该模型考虑了所有用户群体的偏好并进行用户聚类,同时在商品的选品和展示方案上寻求最佳组合;HGSRec模型[11]通过三方异构图神经网络来表示用户和物品的多重特征,然后利用注意机制捕获潜在的三方交互关系并对特征进行动态融合,最后模型通过三元组结构刻画了分享行为的非对称影响,成功将异质图应用于分享推荐任务。现有方法都使用元路径结构对异质信息网络内的多元关系进行显式约束,但目前在元路径设计、元路径聚合模式及损失函数设计上仍有很大的改进空间。
2.2 语义信息的提取和融合
MCRec算法[12]是从每条元路径中基于优先级采样策略提取高质量的实例作为背景信息,随后使用共同注意力机制进行有机的交互融合,最终有效地利用基于元路径的丰富背景信息提升了 top-N 推荐任务的推荐效果。HAN(Heterogeneous Graph Attention Network)模型[13]首次将注意力机制引入到异质图领域,提出基于层次注意力的异质图神经网络模型,对推荐系统中不同类型的节点和关系进行差异化的考虑,为不同节点及关系学习影响力权重,进而有所偏重地融合更重要的信息。HetGNN模型[14]是将不同类型的邻居节点分别进行聚类处理,为不同种类的异质信息专门设计编码方式以尽可能地保留其中的异质信息,然后再进行特征融合。SIAN(Social Influence Attentive Neural Network)模型[15]提出了一种关注社交影响的神经网络,使用注意力特征聚合器来学习不同层面上朋友和商品的节点表征,并提出了一个社会影响耦合器以一种专注的方式捕获朋友推荐圈的影响力,最终成功应用于社交分享增强的推荐任务;NIRec模型[16]率先将数据损失现象正式总结为“过早总结”问题并进行针对性研究,并在双层聚合层之前额外引入一个交互式信息提取层以捕获潜在的交互信息;SDCN(Structural Deep Clustering Network)[17]聚焦于深度聚类问题,利用自编码器和图卷积网络双通道学习样本表示,并设计对偶自监督机制实现样本信息和结构信息的有机融合,有效缓解了图卷积过程中的过平滑问题。现有方法大多是利用注意力机制,尽可能在聚合时提升重要信息的占比,降低信息损失,在语义信息的提取、聚合模式及聚合前的交互增强方面还有很大的研究空间。
3 模型的研究与实现
本节提出了基于异质信息网络的多尺度语义融合推荐模型。首先针对推荐场景构建异质图,通过设计合理的元路径获取异质图在特定关系下的语义结构以针对性提取特定语义信息。然后,将元路径引导下的邻域划分为多个邻居组,利用邻居组之间的多层交互获取多尺度语义信息。最后,使用两阶段的关系注意力来指导多尺度语义融合。
3.1 模型的数学建模
为了能有效地解决建模多源异质数据并充分提取利用其中的丰富语义信息这个难点问题,本节首先针对Movielens数据集下的电影推荐场景和Amazon数据集下的商品推荐场景构建异质图G= {V,E,φ,φ},其中V代表推荐场景中不同类型的实体集合,在图中以节点的形式表示;E代表不同类型的交互关系集合,在图中以链接节点的边表示;函数φ:V→A维护了节点v∈V到实体类型集合A的映射关系,保证了每一个节点都能被归属为某个实体类型;函数φ:E→R维护了边e∈E到关系类型集合R的映射关系,保证了每一条边都能被归属为某个关系类型。
构建具体的异质图模型,如图1所示,本节针对电影推荐场景中关键实体和交互关系进行建模,抽取出了观影者(User)、电影(Movie)、主题类别(Topic)和职业(Occupation)4种主要实体类型,以及观看关系(User-Movie)、主题归属关系(Movie-Topic)、相关关系(Movie-Movie)和职业归属关系(User-Occupation)4种主要交互类型。

图1 异质图模型的构建
而类似的,本节针对商品推荐场景也进行了实体和关系的抽取与建模,抽取出了消费者(User)、商品(Item)、品牌(Brand)、目录类别(Category)和评价(view)5种主要实体类型,以及购买关系(User-Item)、品牌归属关系(Item-Brand)、目录类别归属关系(Item-Category)和评论关系(Item-View)4种主要交互类型。

具体而言,如图2所示,本节利用在电影推荐场景下的先验知识进行元路径结构的精心设计,通过组合基本交互定义了共同观影(UMUM)、相关电影(UMMM)、共同主题(UMTM)、职业共同观影兴趣(UOUM)4条元路径以刻画4种对提升推荐结果最有帮助的关键语义结构。类似的,本节针对商品推荐场景也进行了合理的元路径结构设计,定义了共同购买(UIUI)、共同目录类别(UICI)、共同品牌(UIBI)、共同评价(UIVI)4条元路径,有效建模了4种关键的高阶语义信息。
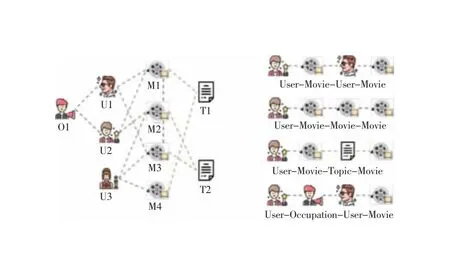
图2 元路径结构设计
在对于每条给定的元路径设计中,目标节点都存在一组基于元路径引导的邻居节点,在元路径结构约束下进行邻域信息的聚合,有效地揭示了异质信息网络中不同的语义结构信息。本节设计的元路径结构不仅贴合相应推荐场景需求,精准提取了关键交互信息,并以元路径的显示结构有效保留了高阶语义知识。
至此本节实现了复杂推荐场景下对多源异质数据的类型约束,对异质信息进行了有效建模,实现了以结构化的形式探索异质信息中的语义结构和复杂交互关系。
3.2 模型的整体框架
模型的整体框架由2个主要模块组成,如图3所示。多尺度语义提取模块首先根据游走距离将邻居节点划分为不同的邻居组,然后将节点之间的交互关系扩展为节点邻居组之间的交互关系,通过不同层级邻居组之间的交互结构提取了多尺度的语义信息。多尺度语义聚合模块通过细粒度的邻域层次注意力关注邻域节点层面和多层邻居组层面的影响力差异,有效引导邻域交互信息聚合,进而实现了多尺度语义的融合。最终,模型给出推荐任务的预测结果。整体框架通过多层邻域交互的方式提取多尺度语义信息,在形成最终表示前充分利用邻域信息增强了节点之间的交互,一定程度上缓解了聚合过程中的信息损失,改进了推荐结果。

图3 模型的整体框架
3.3 多尺度语义提取模块
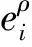
(1)
随后本模块基于划分的邻居组进行多尺度语义信息提取,通过划分多层次的邻居组实现了将邻域交互的范围扩展到节点邻域之间,通过不同层级邻居组之间的交互可以提取到不同尺度的语义信息。具体如公式(2)所示,通过不同层级邻居组之间的交互 [H[Nρ(i),Nρ(j)]l来抽取不同尺度的语义信息,其中⊙代表卷积操作。
[H[Nρ(i),Nρ(j)]l=H[Nρ(i)]l⊙H[Nρ(j)]l
(2)
3.4 多尺度语义聚合模块

(3)
(4)
(5)
(6)


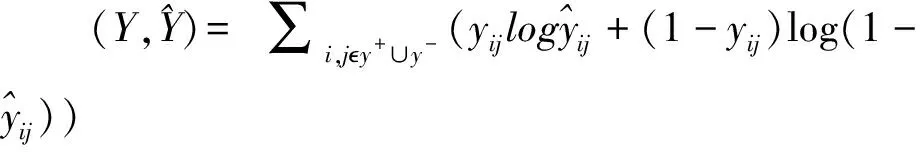
(7)
4 实验结果与分析
4.1 实验设置
4.1.1 数据集 实验选择了2个推荐场景下的相关数据集,分别为Movielens电影数据集[18]和Amazon电子商务数据集。Movielens数据集来源于网站(https://grouplens.org/datasets/movielens/),是一个电影推荐任务中常用的电影评分数据集,有多种大小的分类数据集可以使用。数据集中包含电影标签、 电影题目和电影类型等电影属性信息,也包括观影者职业、年龄等用户信息,还包括观影者 对电影的评分、评论时间等交互信息。
Amazon 数据集来源于网站(http://jmcauley.ucsd.edu/data/amazon/),是一个商品推荐任务的经典数据集,根据商品分类可分为图书、电子、影视等子数据集,每个子数据集内包含商品名称、价格、品牌等商品属性信息和用户评分记录数据。
4.1.2 评估指标 实验在点击率预测(CTR)任务上采用ACC和AUC评价模型。ACC描述了推荐结果的准确率,是广泛应用于二分类任务的评价指标。ACC表示了预测正确的样本占所有样本的比例,其中预测正确的可能有正样本也可能有负样本。AUC被定义为ROC曲线下的面积,是衡量模型优劣的一种指标。ROC曲线全称受试者工作特征曲线,曲线的横坐标是假正类率 FPR,纵坐标是真正类率 TPR,能够综合地检验模型准确性。但ROC曲线的表示不够直观,因此,提出AUC来对ROC曲线的表示进行总结。作为一个数值,AUC越大说明分类效果越好,表示预测的正例排在负例前面的概率。
4.1.3 实施细节 节点的嵌入维度设置为128,多尺度语义提取的上限设置为在5跳范围内的邻居组交互,每个节点基于每条元路径的邻居采样数设置为16。数据集的划分方法为训练集:验证集:测试集=6:2:2。
4.2 与基线方法的对比实验
实验在数据集 Movielens 和 Amazon 上与多个最先进的模型进行比较,以评估所提出模型的有效性。对比模型的选择如下所示:
1) NeuMF[19]是一种基于深度神经网络的推荐算法,结合了传统矩阵分解技术和多层感知机制,可以同时提取低阶和高阶的语义特征。
2) HetGNN[14]是一种基于图结构的异质图模型,将不同类型的邻居节点分别进行聚类处理,为不同种类的异质信息专门设计编码方式以尽可能地保留其中的异质信息,然后再进行特征融合。
3) HAN[13]是一种基于元路径的异质图模型,提出基于层次注意力的异质图神经网络模型,对推荐系统中不同类型的节点和关系进行差异化的评估,有所偏重地融合更重要的信息。
4) MCRec[12]是一种基于元路径的异质图模型,从每条元路径中基于优先级采样策略提取高质量的实例作为背景信息,随后使用共同注意力机制进行有机的交互融合,最终有效地利用基于元路径的丰富背景信息实现低阶和高阶特征的交互融合。
5) IPE(评估系统)[19]是一种基于元路径的异质图模型,提出了一种新颖的交互式路径来捕获元路径之间丰富的交互信息,以模拟查询对象与目标对象之间的多个路径之间的相互依赖性。
6) TANHIN[20]是一种基于元路径的异质图模型,设计了一个结合源域和目标域的跨域模型学习对象和物品的表示。
结果如表1所示,与之前所有工作相比,本文所提出的模型在2个数据集的所有评估指标上都取得了更好的性能,说明本文提出的模型能够充分利用邻居组多层交互提取多尺度语义信息,同时实现了多尺度语义信息的高效融合,进而丰富了节点信息表示的强度,有效缓解了聚合过程中的信息损失,提升了推荐效果。
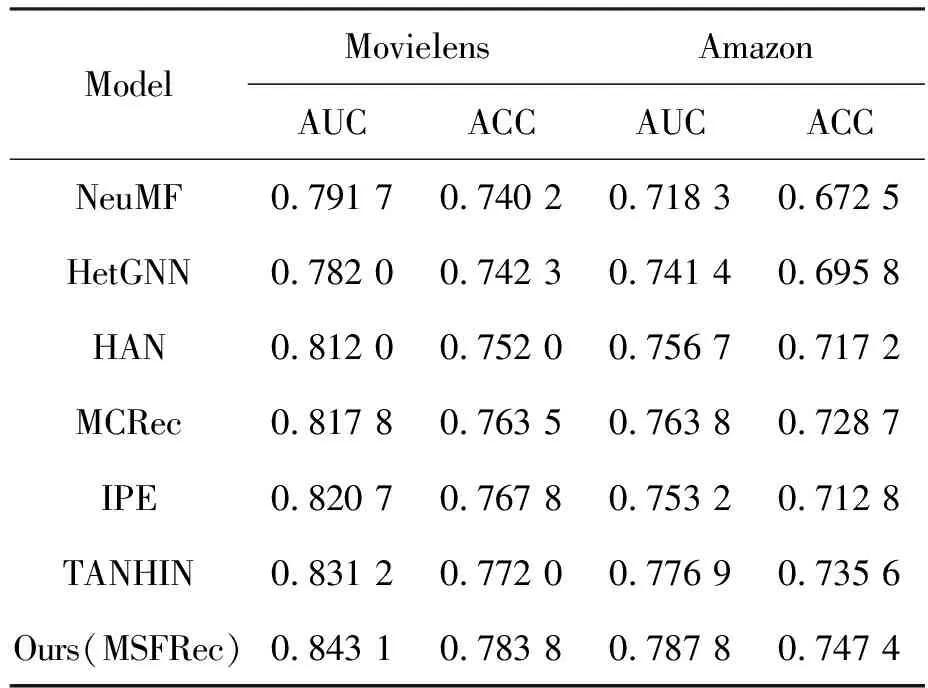
表1 2个数据集上有效性评估的对比实验
4.3 消融实验
首先,实验在数据集上对3种模型变体进行比较,验证本文模型中各个模块的有效性。在原有模型MSFRec的基础上,MSFRec-Extract将基于邻域交互的多尺度语义提取模块替换为基于相同元路径结构的公共邻域提取方法;MSFRec-Fusionn将多尺度语义聚合模块中的节点级注意力去除,为各节点赋予相同的注意力权重;MSFRec-Fusions将多尺度语义聚合模块中的元路径类型级注意力去除,为各元路径赋予相同的注意力权重。实验结果如表2 所示,本章提出的各模块均为提升模型性能提供了有效贡献。其中,多尺度语义提取模块有效地提取了异质信息网络中的多尺度语义信息,丰富了节点表示。多尺度语义聚合模块通过两阶段的细粒度注意力机制同时关注了节点级别和元路径级别下语义信息影响力的细微差异。

表2 验证模块有效性的消融实验
然后,实验通过在2个数据集上逐步增加多尺度语义提取模块中的元路径种类来评估本文设计的元路径结构的有效性,评估指标为AUC。实验结果如表3和表4所示,可以看出,本文设计的元路径结构精准建模了多源异质信息间丰富多样的交互关系,针对性地提取、聚合了特定的语义信息,有效地捕获了关键信息辅助推荐。进一步分析可以看出,元路径之间的贡献度存在明显差异,在Movielens数据集中UMTM路径显著提升了推荐结果,说明在电影推荐任务中共同主题所代表的语义关系最为重要;在Amazon数据集中UIVI路径显著提升了推荐结果,说明在商品推荐任务中共同评价关系是最为重要的交互关系。

表3 验证 Movielens与Amazon数据集上元路径有效性的消融实验

表4 验证 Amazon 数据集上元路径结构有效性的消融实验
最后,实验在数据集上进行消融实验测试不同的多尺度语义提取上限对模型产生的影响,评估标准为AUC值,对比模型的设置如下所示。
N-hop Neighbors:通过控制邻居组划分中最远邻居的距离调整邻域多层交互所涉及的范围,进而限制多尺度语义提取的尺度上限,N-hop代表邻居组划分的最远跳数为N。
实验结果如表5所示,可以看出,随着多尺度语义上限的提升,模型的整体性能先上升后下降。进一步分析原因可能是随着语义尺度上限提升,邻域交互范围得到扩大,可以更全面地学习到多层交互信息。当邻域范围扩展在一定限度内时,这些信息对最终性能提升有所助益。然而,随着多语义尺度上限不断提升,这种扩展逐渐达到了效益边界,扩展超过一定限度则可能会包含更多噪声,对最终预测反而不利。

表5 验证提升多尺度语义上限影响的消融实验
5 结论
当前,推荐算法大多对多源异质信息的利用不足,在元路径的结构设计和语义信息的高效聚合上存在许多改进空间。同时在邻域信息聚合过程中发生信息损失的问题,而在异质图模型使用过程中,由于多源异质信息存在属性维度上的差异,信息损失问题造成的影响被进一步放大。因此,提出了一种基于异质信息网络的多尺度语义融合推荐模型,首先,针对推荐场景构建异质图,通过设计合理的元路径获取异质图在特定关系下的语义结构以针对性提取特定语义信息。然后,基于元路径搜索节点的邻居节点,根据到节点的距离将邻居节点划分为不同的邻居组,进而成功地将节点之间的交互扩展为了邻居组之间的交互。通过利用邻居组之间的多层交互关系提取出了多尺度的语义信息。最后,使用两阶段、细粒度的关系注意力关注了多尺度语义之间的细微差别,进而指导了多尺度语义信息高效融合。实验结果证明,文中提出的推荐模型能够在形成最终表示前充分利用邻域信息增强节点之间的交互,在一定程度上抵抗了邻域信息聚合过程中的信息损失,改进了推荐结果。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
吉林大学学报(理学版)(2020年3期)2020-05-29
自动化学报(2018年7期)2018-08-20
周口师范学院学报(2016年5期)2016-10-17
太空探索(2016年5期)2016-07-12
云南师范大学学报(自然科学版)(2015年5期)2015-12-26
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
物理实验(2015年10期)2015-02-28
时代英语·高三(2014年5期)2014-08-26
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
