
基于自动编码器和支持向量机的飞机机动智能识别方法
2024-03-04 13:19岳龙飞杨任农杨文达左家亮刘会亮许凌凯
兵器装备工程学报 2024年2期
岳龙飞,杨任农,杨文达,左家亮,刘会亮,许凌凯
(1.海军工程大学 电磁能技术全国重点实验室, 武汉 430033; 2.空军工程大学 空管领航学院, 西安 710051; 3.西安卫星测控中心, 西安 710043; 4.中国人民解放军95882部队)
0 引言
机动动作识别是空战智能决策中的关键问题,准确快速识别敌方飞机机动动作类型有利于我方在空战中快速决策机动,夺取有利态势。随着人工智能技术的飞速发展,战争节奏越来越快,战场信息量越来越大,空战也变得越来越智能[1-3]。面对空战中复杂多变的态势和海量高维的飞行数据,采用新型人工智能方法进行机动动作识别显得尤为重要。
目前主要有2种机动动作识别方法,一种是知识驱动的方法,另一种是数据驱动的方法。
知识驱动的方法主要是依靠领域专家人工识别机动动作的先验知识,通过观察飞机机动时航向角、滚转角、高度等参数的变化规律,来推理出其最有可能采取的机动动作。孟光磊等[4]通过分析飞机的各飞行参数信息,利用动态贝叶斯网络模型自动识别机动动作,实时性较高;钟友武等[5]参考人的思维过程,利用模糊推理方法识别基本机动动作;倪世宏等[6]根据领域专家先验知识和飞行参数变化规律,构建飞行动作识别知识库,并采用正向精确推理识别各种机动动作。这种方法从飞行参数据变化规律出发,对领域专家知识要求较高,识别准确率较高,对大规模数据的特征提取能力不足。
数据驱动的方法主要是通过对机动动作样本库历史数据的学习,训练出一个分类器数据模型,进而对新输入的机动动作进行识别分类。杨俊等[7]利用模糊支持向量机优良的分类能力,对6种飞行动作进行识别,识别准确率较高;杨俊等[8]也建立了基于模糊最小二乘支持向量机的飞行动作识别模型,提高了多分类的识别准确率;张振兴等[9]把机动识别问题看成方向状态和动作状态的时间序列数据的识别问题,采用隐马尔科夫模型识别9种基本飞行动作。这种方法分类器比较简单,易于实现,存在特征提取能力不足的问题。
近年来以深度学习[10-12]为代表的人工智能技术取得了巨大进步,自动编码器作为其中一种十分重要的无监督学习方法,能够对大量无标签数据进行降维,并自动学习、抽象、提取出蕴含在数据中的重要特征,因此已成功应用于模式识别、数据分类、异常检测等问题中[13]。面对大量的、时序的、高维的飞行机动动作数据,如果能从中提取出重要特征,然后结合支持向量机(support vector machines,SVM)良好的分类性能,对不同的机动动作进行分类识别,将大大提高机动动作识别的准确率。
因此,提出一种基于正则化自动编码器-支持向量机(regularized auto-encoder-support vector machines,RAE-SVM)的飞机机动动作识别新方法。首先依靠飞机机动动作数据的变化特征和领域专家人工识别机动动作的先验知识,建立飞机机动动作识别样本库;然后构建基于RAE-SVM的机动动作识别模型,通过构建的样本库对模型进行训练,确定了RAE网络拓扑结构和SVM最优参数;最后与其他几种典型机动识别模型进行准确性和实时性对比,并采用真实机动数据进行实例评估。仿真结果表明,该方法能够快速准确地识别飞机机动动作。
1 问题描述
由于飞机在做机动的过程中,常常伴随着大量飞行参数数据的变化,如航向角、滚转角、高度、俯仰角、速度等,因此飞机机动动作识别问题可以看成一个时间序列数据的识别问题。
飞机机动动作一般分为战术机动动作和基本飞行动作2种。其中,战术机动动作如左爬升、高速摇一摇等相对复杂,基本飞行动作如转弯、爬升等相对简单。考虑到各类复杂的战术机动动作都可以由简单的飞行动作组合而成,因此本文中只考虑简单飞行动作,将飞机机动动作分为左转弯、右转弯、爬升和俯冲4种,如图1所示。当飞机没有做以上4种机动动作时认为其保持平飞状态。下面以4种典型机动动作为例进行分析。
图1(a)为飞机进行左转弯机动,飞机先保持平飞状态,滚转角基本保持在0°,航向角缓慢变化,其他参数基本保持稳定;当开始进行左转弯机动时,滚转角立即增加到一个比较大的数(一般为60°左右),航向角也开始剧烈变化,这个点称为左转弯起始点;之后滚转角稳定在一个数值附近,航向角保持匀速变化,飞机保持左转弯状态,持续一段时间;当结束左转弯机动时,滚转角快速回到0°附近,航向角缓慢变化,其他参数又回到基本稳定状态,这个点称为左转弯结束点。左转弯起始点和结束点之间飞机进行左转弯机动。图1(b)为飞机进行右转弯机动,类似地,定义右转弯起始点、结束点,两点之间飞机进行右转弯机动。

图1 4种典型机动动作
图1(c)为飞机进行爬升机动,飞机先保持平飞状态,高度基本保持稳定,俯仰角保持在一个比较小的数值附近;当开始进行爬升机动时,高度迅速增加,速度减小,俯仰角保持在一个数值附近,这个点称为爬升起始点;之后高度保持匀速增加,俯仰角基本保持稳定,飞机保持爬升状态,持续一段时间;当结束爬升机动时,俯仰角快速回到一个小的数值附近,高度和速度保持稳定,这个点称为爬升结束点。两点之间飞机进行爬升机动。图1(d)为飞机进行俯冲机动,类似地,定义俯冲起始点、结束点,两点之间飞机进行俯冲机动。
因此,只要识别出飞机机动起始点和结束点,也就识别出了机动动作。考虑到飞机机动是一个持续的过程,一个机动动作往往需要数秒甚至几十秒来完成,因此本文中将机动识别问题看作基于时间段数据特征[14]的时间序列数据识别问题。
2 机动动作样本库
2.1 构建机动动作特征数据
基于上文对飞机机动时飞行参数数据变化规律的描述,以空战训练测量仪(air combat maneuvering instrument,ACMI)记录的单机机动数据为研究对象,构建机动动作特征数据。其中,ACMI是一种空战数据记录设备[15],以0.25 s的间隔实时采集、传输并保存飞机的时间、位置、姿态、过载数据。具体构建步骤为:
步骤1根据上文分析,并借鉴杨俊等[8]研究成果选择机动动作数据特征,包括航向角、航向角变化量、俯仰角、俯仰角变化量、滚转角、滚转角变化量、高度、高度变化量、速度和速度变化量共10类参数,见表1所示。
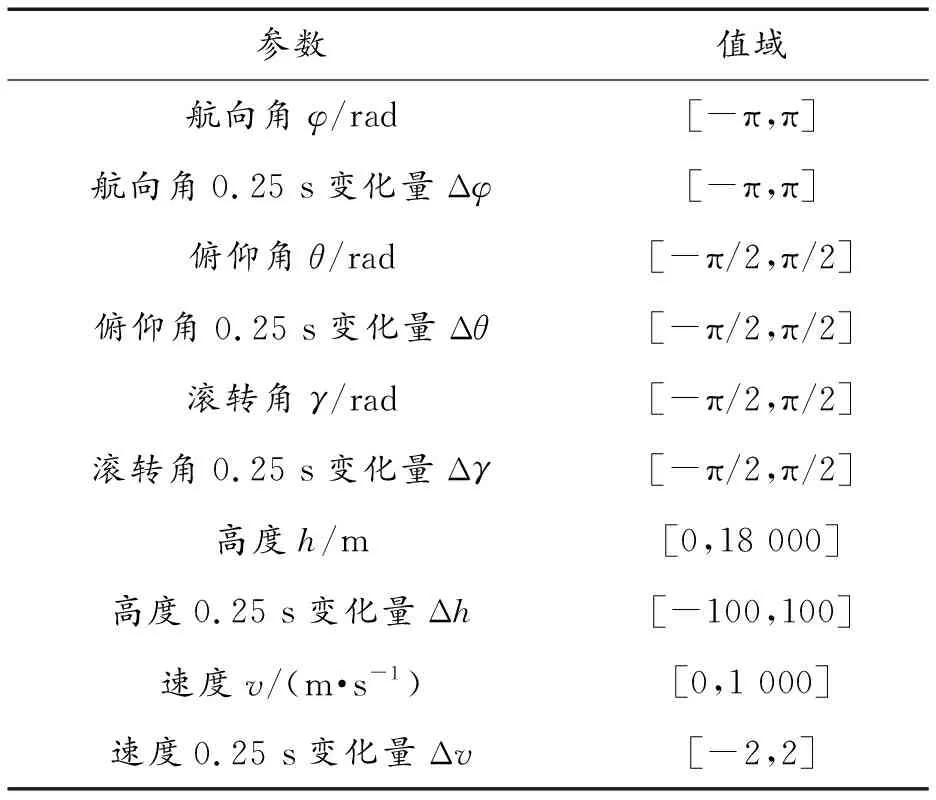
表1 机动动作数据特征
步骤2从飞行第1个点开始,向前取9 s共36个点的数据,每个点包括10维参数,按照时间顺序连续排列,形成维度为(1,360)的机动动作特征数据,见图2所示。

图2 一组机动动作特征数据
步骤3以9 s作为一组机动特征数据的时间窗口向后滚动,直至遍历整个飞行时间。
2.2 构建机动动作样本库
基于机动动作数据变化规律,由3位领域专家依靠经验知识构建样本库,步骤如下
步骤1专家根据ACMI三维态势显示,初步确定机动起始点、结束点所在的时间段。
步骤2专家结合ACMI数据中机动动作参数变化规律,确定左转弯、右转弯、爬升和俯冲机动起始点、结束点。
步骤3从专家确定的机动起始点、结束点对应时刻向前取9 s为一组,构造各类机动动作特征数据。
步骤4各类机动起始点、结束点之外的数据也是9 s为一组,组成非机动点特征数据。
经过3位领域专家判断,得到机动动作样本库见表2所示。

表2 机动动作样本库
3 基于RAE-SVM的飞机机动动作识别模型结构
3.1 RAE神经网络
自动编码器是一种无监督神经网络模型,由编码器(Encoder)和解码器(Decoder)两部分组成,目标函数是最小化输入与输出之间的重构误差[16],其网络结构见图3所示。其中,编码器和解码器可以由任意的神经网络架构组成,编码时对原始数据逐层进行压缩降维,解码时再将压缩后的隐空间表示逐层解压升到原始维度,通过最小化原始数据和解压数据之间的误差,编码器就可以得到原始数据的“精华”,自动提取到原始数据中的重要特征[17-20]。

图3 自动编码器网络结构
按照图3结构,传统自动编码器的编码和解码过程可以描述为[19]
h1=σ1(W1x+b1)
(1)
h2=σ2(W2h1+b2)
(2)
h3=σ3(W3h2+b3)
(3)
y=σ4(W4h3+b4)
(4)
其中:x代表输入值;y代表输出值;h1、h2、h3分别代表第1、2、3隐含层输出值;W1、b1、σ1、W2、b2、σ2、W3、b3、σ3分别代表第1、2、3隐含层的权重、偏差与激活函数,激活函数一般为sigmoid、tanh、ReLU等。
输入与输出之间的重构误差一般有2种形式,一种是均方误差函数,多用于回归问题,如式(5)所示。另一种是交叉熵函数,多用于独热(one_hot)编码的分类问题,如式(6)所示。

(5)
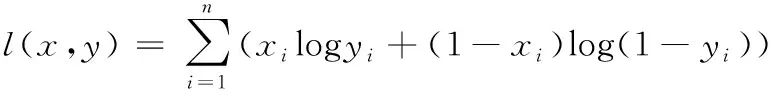
(6)
为了避免传统自动编码器在训练中容易发生过拟合的问题,通过在损失函数上增加一个权重衰减项来控制权重的减小程度,得到了RAE。其损失函数为正则化均方误差,公式为

(7)
当权重比较大时,损失函数也相应地大一点,权重就要减小快一点;当权重比较小时,损失函数也相应地较小,权重就可以减小慢一点,这样,有利于加快收敛速度,提高网络泛化性能。
3.2 SVM算法
SVM是一种理论基础坚实、数学模型简单的机器学习方法,在小样本、非线性和模式识别问题中表现出优异性能[21]。SVM的目的是寻找一个最优分类超平面,使得两类的间隔最大。
以二分类为例,给定训练集(xi,yi),i=1,2,…,n,x∈Rn,y∈{±1},超平面记为wx+b=0,SVM要求所有样本分类正确且分类间隔最大,即求解下面约束优化问题

(8)
SVM本身只能实现二分类,但可以通过组合多个SVM来实现多分类。常见的组合方法有2种,一种是一对多法,另一种是一对一法。一对多法是训练时将某个类别的样本分为一类,将剩余类别样本归为另一类,对于k分类任务就要构造k个分类器;一对一法是在任意两类样本中构造一个分类器,对于k分类任务就要构造k(k-1)/2个分类器,从而实现多分类。
3.3 基于RAE-SVM的机动动作识别模型
考虑到自动编码器强大的特征提取能力和SVM优异的分类性能,提出先降维后分类的RAE-SVM方法,其结构如图4所示。

图4 RAE-SVM分类原理
RAE-SVM是一种将无监督学习和有监督学习相结合的方法。先由自动编码器以无监督的方式对原始高维数据进行学习,从而提取高维数据中的重要特征;然后利用提取到的特征数据对SVM进行训练,确定SVM最优参数;最后通过训练好的SVM进行分类。识别算法流程如图5所示。

图5 识别算法流程
因此,建立基于RAE-SVM的机动动作识别模型,模型输入为基于时间段的10类机动动作数据特征参数构成的向量,模型输出为9类机动点类型,见图6所示。

图6 基于RAE-SVM的机动动作识别模型
4 仿真实验与分析
仿真环境为:Intel i7-7700HQ 2.8 GHz处理器,4 GB内存,Win10 64位操作系统,运行平台为PyCharm。为了使实验结果更具说服力,取10次运行的平均值为最终仿真结果。
4.1 数据处理
从上文构建的机动动作样本库中按照7∶3的比例,随机抽取样本得到1 400组训练集和600组测试集。
由于机动动作特征数据中不同特征的量纲不统一,数据范围差异大,因此对样本数据进行归一化处理,将各类特征数据统一压缩到[0,1],这样有利于加快模型训练速度,改善分类效果。最终将归一化后的数据作为模型输入。公式为

(9)
式(9)中:x代表某变量的实际值;xmax代表最大值;xmin代表最小值;x′代表归一化后的值。
4.2 模型设置
模型训练前,需要先对模型学习算法、网络结构和相关参数进行配置。
1) RAE学习算法
学习算法采用Adam优化算法[22]。Adam优化算法是深度学习中性能最好的优化算法之一,通过自适应调整学习率和动量,使得模型收敛速度更快,需要资源更少,学习性能更好,其权值更新公式为
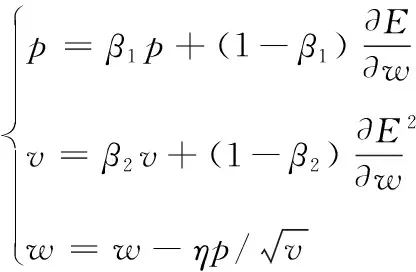
(10)
式(10)中:p为动量项;v为速度项;E为每次训练后得到的误差和;β1、β2为超参数,设置β1为0.9,β2为0.999,学习率η为0.001。其他参数设置见表3所示。
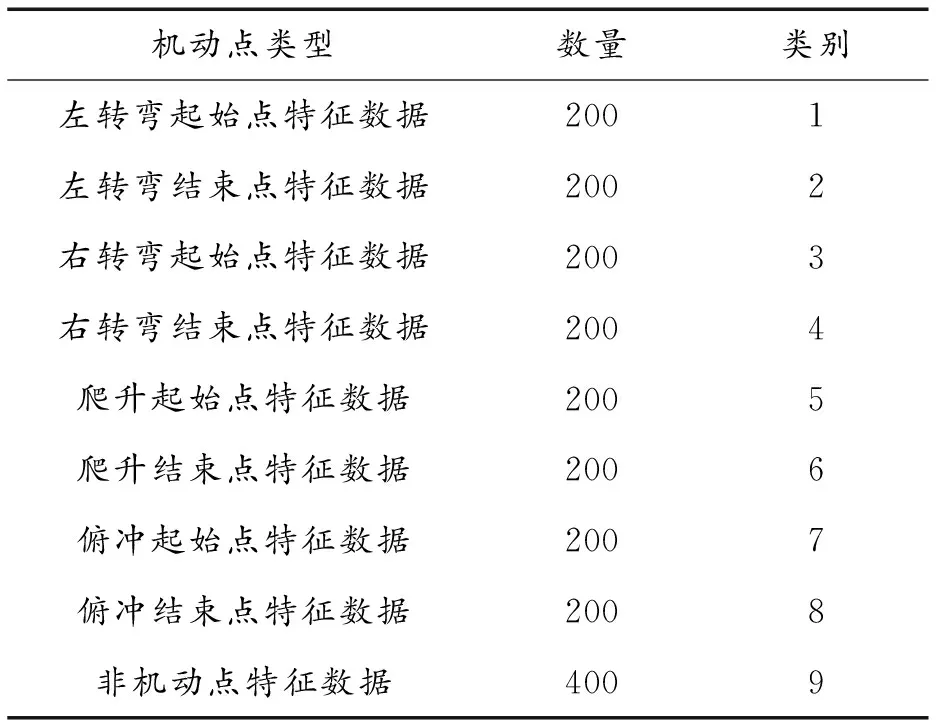
表3 参数设置
2) 权重与偏差初始化
权重初始化采用截断随机正态分布,将初始化的值控制在2倍的标准差之内,有助于提高计算稳定性;偏差采用均值为0、标准差为1的随机正态分布。
3) RAE网络拓扑结构确定
神经网络的隐含层数和隐含层节点数的确定一直没有确定性的方法,需要一定经验和尝试。因此通过对比不同隐含层数和隐含层节点数时的重构误差大小来确定。
由图7可知,重构误差随隐含层数的增加呈现先减小后增大的特点。当隐含层数为3时,重构误差最小。故确定隐含层数为3。
然后确定隐含层节点数。考虑到隐含层主要负责降维抽象和特征提取表示,因此设置第1隐含层节点数为200,第2隐含层节点数为100。由于第3隐含层节点数对特征提取效果和分类性能尤为重要,因此第3隐含层节点数取值设在(10,50)区间,步长为5,根据重构误差大小确定,见图8所示。横坐标代表第3隐含层节点数,纵坐标代表其对应的重构误差。

图7 不同深度RAE的重构误差

图8 不同第三隐含层节点数时的重构误差
由图8可知,当第3隐含层节点数为35时,重构误差最小,因此最优第3隐含层节点数为35。最终确定的RAE网络拓扑结构为360-200-100-35-100-200-360,最终提取到重要机动数据特征维度为35维。
4) SVM参数设置
SVM核函数选择径向基核函数RBF,惩罚因子C默认1,输入数据维度为35,分类函数选择SVM多分类中的一对多分类函数(OVR),该函数在解决类别较多的多分类问题时,生成分类器数较少,分类速度快。核函数系数γ通过直接使用样本训练集数据通过10折交叉验证确定,如图9所示。图中横坐标代表不同γ值,纵坐标代表其对应的10次实验的分类准确度平均值。
由图9可知,γ值为0.03时准确率最高,因此最优γ值为0.03。
4.3 正则化对模型性能的影响
为了分析正则化对模型性能的影响,将训练集和测试集分别输入到有正则化的模型和无正则化的模型进行对比。结果如图10和表4所示。

图9 γ值10折交叉验证
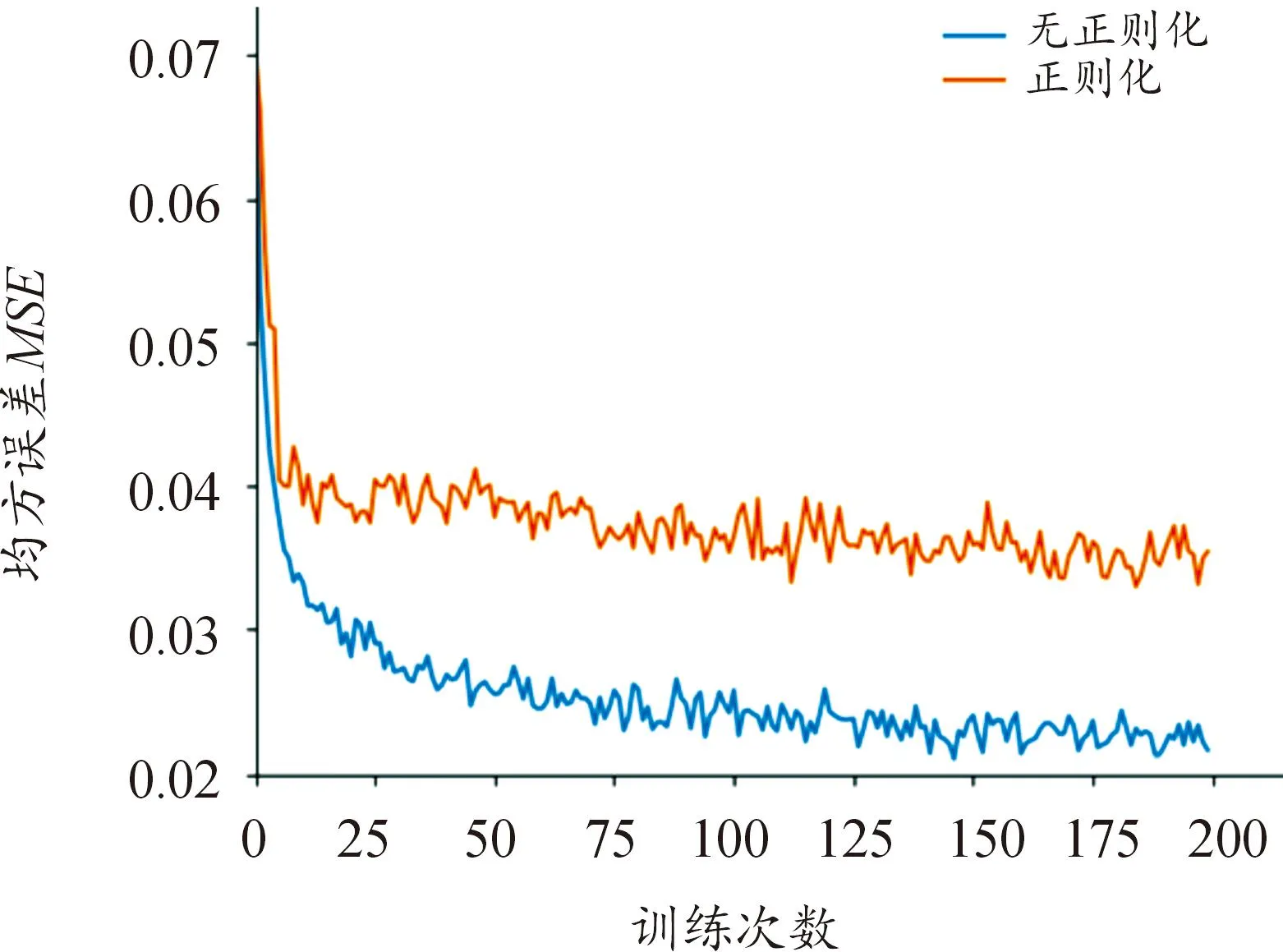
图10 正则化对模型性能的影响
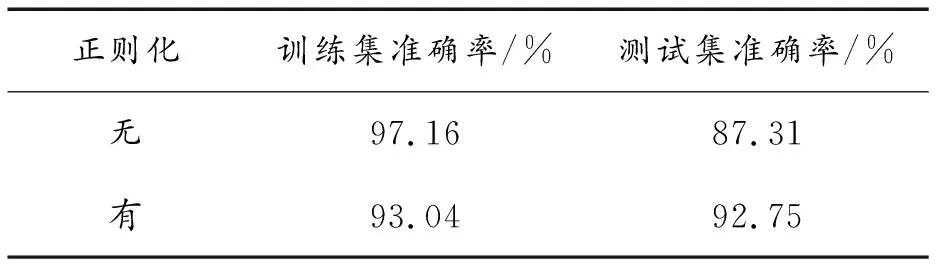
表4 有无正则化模型分类准确率
由图10可知,没有正则化的模型比加入正则化的模型均方误差更小,但加入正则化的模型由于在损失函数上增加了权重衰减项使得收敛速度更快。由表4可知,加入正则化的模型分类准确率更高,这是因为正则化避免了模型对训练集的过度学习,即“过拟合”,牺牲了训练时的均方误差,提高了模型的泛化性能,故分类准确率反而提高。
4.4 模型性能对比
为进一步对比模型的分类准确率与实时性,将模型与粒子群算法(PSO)优化的SVM(RBF核函数,γ取0.03,C取1)和经典分类器随机森林(RF)(最大弱学习器个数Ne取50,最大深度Dmax取30)进行对比,经过不同数量的训练集训练后,模型在测试集上的效果如图11所示。
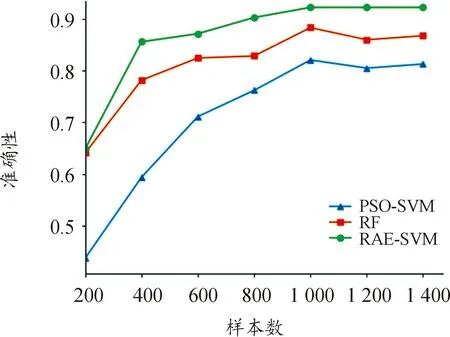
图11 模型效果对比
由图11可知,在样本数量很少时,RAE-SVM模型分类准确率和RF模型接近,这是因为RF通过集成学习,本身对高维数据就有较好的学习能力,而RAE-SVM模型需要通过较多样本进行学习,才能提取出重要特征,进而提高分类准确率。总体上看,RAE-SVM模型较RF和PSO-SVM模型具有更好的识别准确率。详细性能对比见表5所示。

表5 不同模型性能对比
由表5可知,RAE-SVM模型在测试集上性能较PSO-SVM模型和RF模型更好。RAE-SVM模型准确率达到92.75%,单组数据分类运行时间为2 ms,满足数据实时传输要求,内存占用率峰值为1.96%,对硬件要求较低,具有实用性。
4.5 实例分析测试
本文中选取某次空战训练中ACMI记录的飞机做典型机动时的数据共330个点,进行机动点类型识别,从而得到机动类型,用来评估模型的准确性。经3名专家判定,得到评估样本的机动类型分布见图12所示。

图12 机动类型分布
结合ACMI三维态势观察和图12可知,飞机依次进行了平飞、左转弯、平飞、左转弯、平飞、爬升、右转弯、俯冲机动。然后使用训练好的模型对评估样本进行识别,识别结果如图13所示。
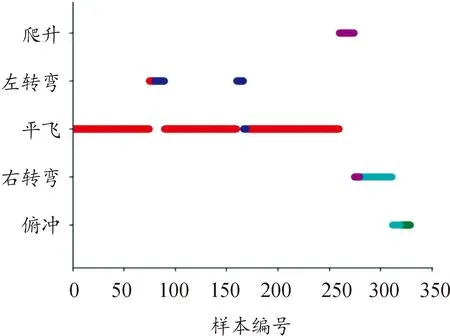
图13 机动识别结果
由图13可以看出,模型总体上可以识别出飞机的机动起始点和结束点,进而得到机动动作,准确性较高。但在识别机动结束点和复杂机动时容易出现误判。如对左转弯结束点识别不准确,导致将左转弯识别为平飞;飞机在进行爬升、转弯再俯冲的复杂机动时,识别效果稍差。因此,模型可以较为准确地进行飞机机动动作识别。
5 结论
本文中构造了基于时间段数据特征的机动动作样本库,并提出了基于RAE-SVM的机动动作识别模型,先对高维的机动动作特征数据进行降维,再利用SVM优良的分类性能进行分类识别。主要得出以下结论:
1) 结合机动数据规律和专家知识,构建了飞机机动动作样本库,解决了飞机机动动作样本库缺失的问题。
2) RAE具有强大的特征提取能力,通过对原始数据降维,可以抽象提取出原始数据中的重要特征。通过引入正则化,提高了自动编码器的泛化性能。
3) 基于RAE-SVM的机动动作识别模型识别准确率较高,实时性较好,实用性强。
下一步研究将丰富飞机机动动作,构建更加贴近实战的机动动作样本库,提出更好更优的机动动作识别模型。
猜你喜欢
装备制造技术(2020年3期)2020-12-25
当代陕西(2019年12期)2019-07-12
汉语世界(The World of Chinese)(2019年1期)2019-03-18
数学年刊A辑(中文版)(2019年1期)2019-01-31
数学杂志(2018年5期)2018-09-19
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
电子器件(2015年5期)2015-12-29
数学年刊A辑(中文版)(2014年5期)2014-11-01
电测与仪表(2014年13期)2014-04-04
