
Object Helps U-Net Based Change Detectors
2024-03-01 11:02LanYanQiangLiandKenliLi
Lan Yan , Qiang Li , and Kenli Li
Dear Editor,
This letter focuses on leveraging the object information in images to improve the performance of the U-Net based change detector.Change detection is fundamental to many computer vision tasks.Although existing solutions based on deep neural networks are able to achieve impressive results.However, these methods ignore the extraction and utilization of the inherent object information within the image.To this end, we propose a simple but effective method that employs an excellent object detector to extract object information such as locations and categories.This information is combined with the original image and then fed into the U-Net based change detection network.The successful application of our method on MU-Net and the experimental results on CDnet2014 dataset show the effectiveness of the proposed method, and the correct object information is helpful in change detection.
Change detection is a crucial task in visual perception [1], [2] and video analytics [3], serving as a foundational bedrock for a diverse array of computer vision applications including but not limited to action recognition, traffic monitoring, and object tracking.It is usually employed as a pre-processing step to provide focus of attention for classification, tracking, and behavior analysis, etc.Change detection is challenging due to intricate factors such as the presence of cluttered backgrounds, perturbations introduced by camera motion during video acquisition, fluctuations in weather conditions, and variations in illumination settings.A common approach for change detection is to perform background subtractions, i.e., to consider the changing region of interest as foreground pixels and the non-changing parts as background pixels.This binary classification problem has garnered substantial attention from the research community over the years, and some effective solutions are proposed.Especially in recent years, owes to the progress of deep learning, the availability of large-scale change detection datasets [4], and the development of hardware computing capabilities and parallel processing technologies [5], the change detectors based on deep neural network have achieved impressive results.
The majority of extant change detection methods [6]-[11] based on deep neural networks predominantly leverage a single image as input, and then use elaborate network to directly segment the foreground objects.However, they neglect the mining and utilization of the target information in the video frame.Considering that change detection requires the precision segmentation of foreground objects,and the video frame inherently contains the category and location information of objects, we think that these information are helpful to improve the performance of change detector.
Currently, the change detectors based on deep neural networks mainly include three categories.The first category is multiple network models [6], [11], where FgSegNet [11] is a representative approach that trains a model for each video on the dataset and performs testing separately.The second is dual/two networks models[7], [8], which are mostly based on generative adversarial networks(GAN) to realize change detection through adversarial learning of generator and discriminator.The third is single network models [9],[10], which mainly design network structures combining advanced convolutional neural networks such as U-Net and ResNet and train one single model only on the dataset.U-Net contains a large number of long connections, so that the features can better relate to the original information of the input image, which helps to restore the information loss caused by down-sampling.At this point, we think that UNet is essentially similar to the residual connection.Therefore, in the single network model, U-Net becomes an excellent method for change detection.Besides, dual/two networks models (e.g., BSPVGAN [7]) and multiple network models (e.g., FgSegNet [11]) have shown commendable performance achievements.Particularly, our prior work BSPVGAN [7] converges the principle of Bayesian networks with generative adversarial networks, conceiving change detection as a classification problem under probability, and it is a state-of-the-art.Thus, in this letter, we mainly focus on U-Net based change detectors and discuss how to improve these models with the help of object’s information within the given image.
To this end, we propose a new change detection method, which capitalizes on object information such as the spatial location and semantic class to heighten model performance.Considering that the goal of object detection is to locate and identify the objects in an image, this is exactly consistent with the object information we need.Therefore, we leverage the object detector to extract the object information.The acquisition of these information is easy because it is automatically generated by a pre-trained object detector, without the need for dedicated training on the change detection dataset.Notably,MU-Net2 [9] also extracts additional information from video frames without supervising, but these information are pixel-level cues derived from optical flow motion and classical background reduction algorithms.In contrast, our approach focuses on the object information and employs the boundingbox-level cues.
MU-Net [9] is currently the best U-Net based change detection model, which contains two versions.Except MU-Net2 which combines spatiotemporal cues, MU-Net1 only takes images as input.Thus, MU-Net1 becomes a natural choice for incorporating object information to verify the effectiveness of our method.It is worth noting that to streamline exposition, the subsequent reference to MUNet1 will be denoted as MU-Net for conciseness.Experimental results on the CDnet2014 dataset show that our method can improve the performance of U-Net based change detection model.In particular, as shown in Fig.1, the object information can make the U-Net based change detection model pay more attention to the foreground object and reduce the negative effects of cluttered background, thus contributing to the improvement of change detection performance.
Proposed approach: Our method aims at fully mining and utilizing the object information in the given image to improve the performance of the U-Net based change detector.Fig.2 displays the comparison of our approach with the popular U-Net based change detection approach.As shown in the Fig.2, different from popular methods that only use RGB images as input, our method introduces masks with object information in addition to the original images.Benefiting from the active research on object detection in the field of computer vision, we adopt off-the-shelf object detectors to obtain the position and category information of the foreground object and generate a mask.Specifically, we first use the object detector to detect all images in a video.After the detection results are obtained, we remove the wrongly detected bounding boxes and judge the foreground objects based on the temporal cues of the video frames.According to the bounding boxes of the foreground objects, we obtain the masks required for subsequent processing.
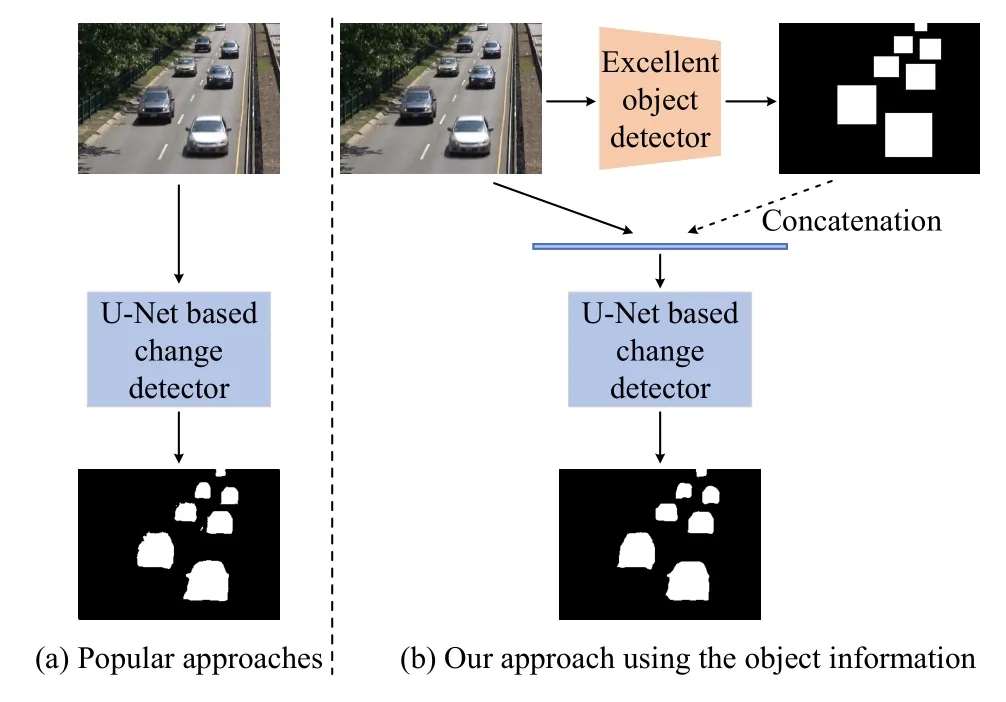
Fig.2.Comparison of our approach with the popular U-Net based change detection approaches.(a) The popular approaches takes only RGB images as input; (b) Our approach takes advantage of the object information within the given image, which is provided by an excellent object detector.
For each input image, its corresponding foreground target mask can be generated by an excellent pre-trained object detector.After that, we concatenate the RGB images and their corresponding masks,then feed the results into an U-Net based change detection network.This coupling stands as one of the most straightforward way to leverage object information.There are two main reasons why we choose this option.First, using this scheme only requires a small adjustment to the structure of the input side of the network, so that our method can be flexibly applied to a variety of U-Net based change detectors.Second, due to the existence of long connections in U-Net, the original input information can be well utilized in the network.This, in turn, obviates the need for redundant reiteration of input information within the network's intermediate layers.
Our approach leverages the object information gleaned from the object detector to make the network pay more attention to foreground objects.It is simple but effective.Nonetheless, the potency of our approach relies on the target detector’s precision in localizing and identifying objects, as well as accurately categorizing them as foreground entities.Any inaccuracies in these aspects can potentially cast an influence over the change detection performance.To obviate the deleterious impact of erroneous object information and its potential to misguide the change detector, we institute a bounding box selection strategy.In adherence to the temporal cues ingrained within video frames, we selectively eschew bounding boxes displaying tenuous correlations.This process culminates in the retention solely of bounding boxes that manifest consistent judgments across consecutive frames.This concerted effort is poised to minimize the propagation of misguided foreground object cues, thereby bolstering the performance of our change detection method.

Fig.3.The application of our method to MU-Net.Compared to the original MU-Net, this improved version introduces object information provided by the state-of-the-art object detector YOLOv8 [12].
Apply our approach to boost MU-Net: Our method is easy to deploy into existing U-Net based change detection networks.An application example of our method is provided in this section.We apply our method to the advanced MU-Net as shown in Fig.3.Considering the advantage of one-stage object detection methods (e.g.,YOLO [12]) over two-stage ones (e.g., Faster R-CNN [13]) in terms of inference speed, we adopt the state-of-the-art YOLOv8 [12] detector in the improved version of MU-Net to offer object information.The adopted object detector is pre-trained on the large-scale object detection dataset.In order to mitigate the negative impact caused by false detection,we apply the proposed bounding box selection strategy to the improved version of MU-Net.Specifically, after completing the extraction of object information for all video frames, for each image frame, we select five frames before it and five frames after it, and a total of ten frames are used as reference images.If the current frame is the first frame or the last frame, the number of reference images is five.Other cases in turn, finally for any image frame, the number of reference images will not be less than five.A bounding box in the current frame is kept if it has associated cues in no less than two reference images, otherwise it is discarded.For the existence of an associated cue in the reference frame, it mainly depends on intersection over union (IoU).Concretely, if the reference frame contains a bounding box with an IoU exceeding 0.1 when compared to the bounding box in question, it indicates the existence of an associated cue.In addition, it is necessary to determine whether the retained bounding box is the foreground or not, and retain the foreground object while discarding the background object.If a bounding box in the current frame has other bounding boxes with IoU greater than 0.95 in five or more reference frames, the bounding box belongs to the background, otherwise it belongs to the foreground.
After the judgment of adjudication of foreground object bounding boxes, we set the foreground region to pure white and the background region to pure black, thus generating a single-channel foreground mask.We concatenate it with the original RGB image to form a new four-channel input.Since the original MU-Net takes RGB images with three channels as input, the number of input channels of the first convolutional layer of the improved version network,namely Conv-1, is modified to 4, as shown in Fig.4.
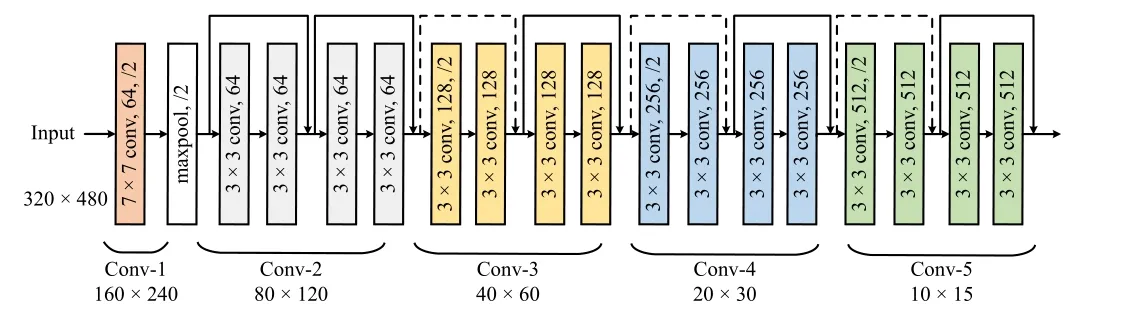
Fig.4.ResNet-18 encoder backbone adopted in MU-Net.The solid shortcuts keep dimensions constant, while the dotted shortcuts increase dimensions.In the improved version of MU-Net, the input to Conv-1 has 4 channels instead of original 3.
Experiments: To compare the performance between the improved version and the original MU-Net1https://github.com/CIVA-Lab/Motion-U-Net, we conduct experiments on the CDnet2014 dataset.As the most comprehensive change detection dataset, CDnet2014 comprises 11 categories and 53 different videosequences, where spatial resolutions of the video vary from 320 ×240 to 720 × 576.

Table 1.Evaluation Results of the Original MU-Net and the Improved Version (ours) on CDnet 2014.↑ Represents Higher is Better, While ↓ Means Lower is Better
According to the experimental setup of MU-Net, we randomly selected 200 annotated frames from each video to form a total of 10 600 frame for training and the rest for testing.During training,90% of 10 600 frame are used as training set and 10% as validation set.We adopt Adam optimizer with a learning rate of 0.0001 and the learning rate decreases by a factor of 10 every 20 epochs.Each model is trained for 40 epochs.
We choose six metrics commonly used in change detection for performance evaluation, including recall, false positive rate (FPR), false negative rate (FNR), percentage of wrong classification (PWC), precision and F-measure.The lower the FPR, FNR and PWC, the better model performance.The specific calculation formula of these indicators can be found at “changedetection.net”.
We train two models, the original MU-Net and the improved version of MU-Net, on the CDnet2014 dataset.The quantitative evaluation results are reported in Table 1, where the original MU-Net is denoted as MU-Net, and the modified version of MU-Net is represented as ours.As listed in Table 1, compared to the original MUNet, the improved version achieves better performance in the four metrics of overall recall rate, FNR, PWC and F-measure, that is,0.9639, 0.0361, 0.999 and 0.9563.The performance difference between the improved version and the original MU-Net in FPR is very small.However, in the terms of precision metric, the overall performance of the improved version which introduces additional object information is worse than that of the original MU-Net which only uses images.This is because the improved version has lower precision for change detection in four categories of video sequences,including PTZ, badWeather, lowFramerate and nightVideos.The images constituting these videos exhibit marked dissimilarity from the images typically encountered by the pre-trained object detector.Consequently, it is difficult for the object detector to provide the correct object information of these images.While our meticulously devised bounding box selection and foreground object discrimination strategies abate the prevalence of erroneous detections, we still cannot completely eliminate the false detection results that cause a negative impact on the U-Net based change detector.According to the results in Table 1 and the above analysis, it is evident that our method is effectiveness and the use of accurate target information is beneficial for boosting the U-Net based change detector.
Conclusion: In this letter, we propose to exploit object information in images to boost the performance of U-Net based change detection models.We design a simple but effective method to realize the extraction and utilization of the object information.The proposed method is applied to the advanced MU-Net to achieve performance improvement.The experimental results verify the effectiveness of our method and that the object information is helpful for the U-Net based change detector.
Acknowledgments: This work was supported in part by the National Natural Science Foundation of China (62302161, 6230 3361) and the Postdoctoral Innovation Talent Support Program(BX20230114).
 IEEE/CAA Journal of Automatica Sinica2024年2期
IEEE/CAA Journal of Automatica Sinica2024年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- A Self-Adapting and Efficient Dandelion Algorithm and Its Application to Feature Selection for Credit Card Fraud Detection
- PAPS: Progressive Attention-Based Pan-sharpening
- Optimal Cooperative Secondary Control for Islanded DC Microgrids via a Fully Actuated Approach
- Fault Estimation for a Class of Markov Jump Piecewise-Affine Systems: Current Feedback Based Iterative Learning Approach
- UAV-Assisted Dynamic Avatar Task Migration for Vehicular Metaverse Services: A Multi-Agent Deep Reinforcement Learning Approach
- Sparse Reconstructive Evidential Clustering for Multi-View Data