
UAV-Assisted Dynamic Avatar Task Migration for Vehicular Metaverse Services: A Multi-Agent Deep Reinforcement Learning Approach
2024-03-01 10:58:54JiawenKangJunlongChenMinruiXuZehuiXiongYutaoJiaoLuchaoHanDusitNiyatoYongjuTongandShengliXie
Jiawen Kang ,,, Junlong Chen , Minrui Xu , Zehui Xiong ,,,Yutao Jiao , Luchao Han , Dusit Niyato ,,, Yongju Tong , and Shengli Xie ,,
Abstract—Avatars, as promising digital representations and service assistants of users in Metaverses, can enable drivers and passengers to immerse themselves in 3D virtual services and spaces of UAV-assisted vehicular Metaverses.However, avatar tasks include a multitude of human-to-avatar and avatar-toavatar interactive applications, e.g., augmented reality navigation,which consumes intensive computing resources.It is inefficient and impractical for vehicles to process avatar tasks locally.Fortunately, migrating avatar tasks to the nearest roadside units (RSU)or unmanned aerial vehicles (UAV) for execution is a promising solution to decrease computation overhead and reduce task processing latency, while the high mobility of vehicles brings challenges for vehicles to independently perform avatar migration decisions depending on current and future vehicle status.To address these challenges, in this paper, we propose a novel avatar task migration system based on multi-agent deep reinforcement learning (MADRL) to execute immersive vehicular avatar tasks dynamically.Specifically, we first formulate the problem of avatar task migration from vehicles to RSUs/UAVs as a partially observable Markov decision process that can be solved by MADRL algorithms.We then design the multi-agent proximal policy optimization (MAPPO) approach as the MADRL algorithm for the avatar task migration problem.To overcome slow convergence resulting from the curse of dimensionality and nonstationary issues caused by shared parameters in MAPPO, we further propose a transformer-based MAPPO approach via sequential decision-making models for the efficient representation of relationships among agents.Finally, to motivate terrestrial or non-terrestrial edge servers (e.g., RSUs or UAVs) to share computation resources and ensure traceability of the sharing records, we apply smart contracts and blockchain technologies to achieve secure sharing management.Numerical results demonstrate that the proposed approach outperforms the MAPPO approach by around 2% and effectively reduces approximately 20% of the latency of avatar task execution in UAV-assisted vehicular Metaverses.Index Terms—Avatar, blockchain, metaverses, multi-agent deep reinforcement learning, transformer, UAVs.
I.INTRODUCTION
A. Background and Motivations
METAVERSES, the future immersive 3D Internet, consists of a variety of advanced technologies, such as augmented/virtual reality (AR/VR), digital twins (DTs), and Digital Avatars, to provide users with an immersive experience[1]-[3].The Metaverse is not merely a replication of reality,but an advanced digital universe that allows seamless interaction and communication, blurring the lines between physical and virtual realms.With the rapid development of promising Metaverse technologies, mobile applications and services are continuously diversifying and evolving, becoming the nexus of next-generation applications that offer immersive and highperformance human-to-avatar and avatar-to-avatar services[4].For example, UAV-assisted vehicular Metaverses is a new paradigm that has emerged to establish a coverage-enhanced novel mode of vehicular services for drivers and passengers to perform seamless virtual-physical interaction with avatars in 3D virtual worlds.In this paradigm, both roadside units(RSUs) in downtown areas or unmanned aerial vehicles(UAVs) in remote areas or downtown hotspots act as the edge servers that allow users to efficiently and reliably immerse themselves in immersive entertainment and driving-related services, e.g., virtual travel and AR navigation [5].
Recently, avatars, as one of the essential Metaverse components, provide users with life-like and immersive digital representation via real-time interactions between humans and avatars [6].For UAV-assisted vehicular Metaverses, the promising vehicular avatars can not only offer services similar to traditional intelligent robots or assistants but also have the appearance of human beings, which can intelligently learn human demands, judge user emotions, and interact with users[7].Therefore, vehicular avatars bring a more efficient, userfriendly, intelligent, and immersive service experience, e.g.,virtual teacher avatars in education Metaverses.Using UAVassisted vehicular Metaverse services, avatars serve as vehicular assistants to manage data and services for drivers and passengers in an intelligent, personalized, and real-time manner.Emerging vehicular avatar services, e.g., 3D entertainment recommendations and AR navigation [8], require intensive computation and communicational resources to perform lowlatency, high-quality, and real-time avatar tasks.
Due to the limited resources of a single vehicle, it is inefficient and impractical for vehicles to execute avatar tasks locally [5], [9], [10].Therefore, vehicles can upload avatar tasks to edge servers (e.g., RSUs or UAVs) with sufficient resources for real-time execution [11].However, the mobility of vehicles poses a significant challenge for UAV-assisted vehicular Metaverses to ensure the continuity of avatar services, especially when the vehicles leave coverage of their host edge servers [12].To achieve uninterrupted and highquality avatar services, each avatar should migrate online with its physical vehicles to ensure real-time and immersive avatar service experiences [13], [14].
For vehicular avatar task migration, the challenges mainly focus on: 1) Avatar tasks need to be migrated not only to the nearest edge server but also pre-migrated to the next edge server to reduce total task execution latency [15].Thus, it is challenging to make appropriate migration decisions in complex UAV-assisted vehicular Metaverse environments [1];2) When all vehicles decide to migrate their avatar tasks to the same edge server, the edge server may be overloaded and thus increase the avatar task latency; 3) To ensure resource trading security and traceability during task execution, it is critical to protect the security of resource trading records between edge servers and vehicles.
B. Solutions and Contributions
To address the above challenges, we propose a dynamic avatar task migration framework to make migration decisions for avatar task execution in UAV-assisted vehicular Metaverses.However, in this framework, vehicular avatar tasks and the edge server load are time-varying.The avatar task migration problem has proven to be an NP-hard problem that cannot be efficiently solved by traditional algorithms in an acceptable time.Fortunately, the advance of multi-agent deep reinforcement learning (MADRL) [16], [17] provides a viable solution to the above problem, in which agents can learn strategies directly from interaction in high-dimensional environments and is often used in dynamic decision-making scenarios for long-term return maximization.For instance, multiagent proximal policy optimization (MAPPO), as a multiagent on-policy algorithm, is an efficient algorithm with high convergence and data sampling efficiency.However, MAPPO forces parameter sharing and may lead to non-stationary results.
Recently, several existing works have introduced the transformer [18] to solve the non-stationary issues of MADRL[19].Specifically, the multi-agent transformer is a novel RL training and inference structure based on the encoder-decoder architecture that implements a multi-agent learning process through sequence models.By leveraging the multi-agent advantage decomposition theorem [20], the multi-agent transformer can represent linear time complexity for multi-agent problems and ensure the monotonic performance enhancement guarantee.Motivated by this, we utilize transformer as a promising solution for sequential decision-making in dynamic avatar task migration [21].We propose a transformer-based MAPPO approach for dynamic avatar task migration, i.e., TFMAPPO, which converts multi-agent actions and observations into sequences that can be processed by the transformer[19], [22].The proposed approach avoids the drawbacks of MAPPO by using a self-attention mechanism to learn the relationships between the agents’ interactions and then output the policies, which achieve better results than the MAPPO approach.Therefore, this approach allows each vehicle to dynamically decide whether to perform an avatar task premigration, thereby reducing the average latency of all vehicles and improving the quality of avatar services.
Moreover, in the migration of avatar tasks, resource transaction records between edge servers (e.g., RSUs or UAVs) and vehicles should be securely managed.To this end, a blockchain as a distributed shared ledger is utilized to achieve decentralized, tamper-proof, open, anonymous, and traceable record management [23], [24].In particular, we also develop smart contracts to enable authentication as well as tamperproof execution, so that secure, irreversible, and traceable resource trading records can be securely managed [25].Therefore, in UAV-assisted vehicular Metaverses, the application of smart contracts to the resource trading records between edge servers and vehicles makes the transaction secure, reliable,and traceable.
The main contributions of this paper are summarized as follows.
1) We introduce a novel avatar task migration framework aimed at achieving continuous user-avatar interaction.Within this framework, vehicles choose appropriate edge servers(e.g., RSUs or UAVs) for the migration and pre-migration of tasks, enabling real-time avatar task execution in UAVassisted vehicular Metaverses.
2) In order to efficiently solve the service provisioning problem, we model the avatar task migration process as a Partially Observable Markov Decision Process.The proposed framework considers the avatar task migration problem as a binary integer programming and proves that this problem is NP-hard.The challenges are then tackled using MADRL algorithms.
3) We propose a transformer-based decision-making model based on MAPPO that processes in a sequential manner.To address the slow convergence and stability of conventional MADRL algorithms, this model converts multi-agent observations and actions into sequences of migration decisions for providing context information for learning agents during training and inference.The proposed model leverages the selfattentive mechanism to perceive the relationship between agents’ interactions for obtaining the optimal policy for each agent.Numerical results show that the proposed approach outperforms the existing MAPPO approach by approximately 2%and effectively reduces the latency of avatar task execution by around 20%.
4) To incentivize edge servers (e.g., RSUs or UAVs) to contribute adequate resources to vehicles, we maintain transaction records of communication, computing, and storage resources exchanged between edge servers and vehicles in the blockchain.Utilizing smart contracts ensures the security and traceability of these transactions.
The remainder of this paper is organized as follows.Section II discusses related works.Section III presents the system model.Section IV describes the avatar task migration problem as a collaborative multi-agent task, and solves the problem by using the TF-MAPPO approach.Section V describes the implementation of the blockchain and smart contracts for resource transaction records.Section VI demonstrates numerical results, and the conclusion is presented in Section VII.
II.RELATED WORK
A. UAV-Assisted Vehicular Metaverses
The concept of the Metaverses, first introduced in the science fiction novelSnow Crashas a stereoscopic virtual space parallel to the physical world, has piqued public interest and was revitalized through the successful release of the popular film,Ready Player One.Essential to these immersive experiences are real-time rendering technologies such as extended reality and spatial-sounding rendering, which serve as primary interaction interfaces but can result in substantial computational demands.
Despite the immense potential of Metaverses to revolutionize various applications and services, existing research on Metaverses is still in its infancy, primarily focusing on daily social activities, including online games, virtual touring, and virtual concerts [26], [27].For instance, the authors in [28]designed an interactive audio engine to deliver the perceptually relevant binaural cues necessary for audio/visual and virtual/real congruence in Metaverse experiences.In [26], the authors investigated the convergence between edge intelligence and Metaverses and also introduced some emerging applications, e.g., pilot testing and virtual education.Unlike the above work, the authors in [1] investigated the implementation of Metaverses in mobile edge networks and discussed the computational challenges and thus introduced cloud-edgeend computation framework-driven solutions to realize Metaverses on edge devices with limited resources.Furthermore,the authors in [5] introduced vehicular Metaverses which present a new paradigm integrating Metaverse technologies with vehicular networks to enable seamless, immersive, and interactive vehicular services (e.g., AR navigation).In addition, the authors proposed a distributed collaborative computing framework with a game-based incentive mechanism for vehicular Metaverse services.However, these works did not consider the service consistency in the coverage-enhanced UAV-assisted vehicular network topology.
B. Virtual Machine Migration
Virtual machine (VM) migration is the process that moves a virtual machine running software services from one physical hardware environment to another one, ensuring continuous services and improving the quality of services.For vehicular networks, users usually tend to offload heavy computing tasks from vehicles to RSUs or UAVs.As the distance between vehicles and RSUs increases, the service latency between the user and the RSU increases.To address this problem, the authors in [29] demonstrated that the use of VM migration techniques can effectively reduce the latency of computing services.This is regarded as an excellent way to provide continuous services with minimal latency.However, when VM migration is performed continuously, it incurs a very high overhead.Therefore, the authors in [30] proposed a dynamic scheduling-based VM migration technique, which reduces system latency by reducing unnecessary virtual machine migration.In [31], the authors proposed a distributed VM migration system based on user trajectories, which was not considered in the aforementioned works.Furthermore, in [32],the authors investigated the task migration and path planning problem in aerial edge computing scenarios.They proposed dynamic approaches for task migration to keep the system load balanced while reducing the overall system energy consumption.Unlike previous studies, we consider the pre-migration of avatars, a technique that can better reduce latency.
C. Resource Allocation Optimization
In a virtual computing environment, optimizing the allocation of resources for a virtual machine can improve energy efficiency and ensure the quality of Metaverse applications.In[33], the authors proposed a two-tier on-demand VM resource allocation mechanism.In contrast to this centralized resource allocation mechanism, the authors in [33], [34] consider distributed virtual machine decisions to balance load on servers and reduce adaptation time.The authors used a DRL algorithm to solve the VM resource allocation problem in [35].In[36], the authors propose a DQN-based approach that achieves lower latency than dynamic scheduling migration.In [37], the authors considered a scheduling optimization scenario for aerial base stations, i.e., UAVs, in mobile edge computing.Higher resource utilization with lower latency is achieved by scheduling the UAV to the appropriate hover position.In [38],the authors considered edge computing in vehicular mobile networks with UAV co-mission scenarios.They designed a collaborative task offloading framework that offloads computational tasks from vehicles to RSUs or UAVs and used a Qlearning approach to optimize task allocation.The authors employed multi-intelligent deep reinforcement learning for cloud-edge VM offloading optimization in [39], achieving better results than the baseline singleWinRAR11-agent DRL solution.In contrast to the above research, we propose a transformer-based model to solve the avatar task migration optimization problem based on MADRL algorithms.

Fig.1.The migration of avatar tasks in UAV-assisted vehicular Metaverses.
D. Blockchain-Based Avatars
Blockchains are distributed shared ledgers and databases that are decentralized, tamper-proof, open, anonymous, and traceable [40], [41].The authors proposed a lightweight workbased infrastructure for blockchain proofs in [42].In [43], the authors leveraged a reverse contract solution to solve the problem of allocating and pricing computational resources in mobile blockchains.In [44], the authors considered a mobile edge computing model consisting of RSUs, UAVs, and MEC services to run blockchain tasks.In [45], the authors used DRL for resource management in edge federated learning [46]which was supported by blockchains.In [47], the authors proposed a blockchain-based approach for resource management in edge vehicular computing.In addition, in [48], the authors proposed a dynamic gaming resource pricing and trading scheme in UAV-assisted edge computing.To secure the transactions, the authors used blockchain technology to record the entire transaction process.Unlike previous work, we use blockchain to record transaction data for communication, computation, storage, and other resources between roadside units and vehicles to ensure transaction security and traceability.
III.SYSTEM MODEL AND PROBLEM FORMULATION
A. Augmented Reality Navigation With Avatar in UAV-Assisted Vehicular Metaverses
In UAV-assisted vehicular Metaverses, AR Navigation combines the display of AR with navigation applications to generate 3D navigation guidance services that are fused and overlaid with real-world imagery.As part of the 3D navigation guidance models, the avatar is displayed on the user’s AR display devices and provides visual and voice guidance to the users, creating a more intuitive navigation experience, enhancing driving safety, and improving the driving experience (as shown in Fig.1).However, maintaining and displaying 3D objects in AR navigation services requires intensive interactive and computing resources, so it is not sufficient to rely only on the limited communication and computing resources in vehicles.Fortunately, based on the avatar task migration framework, vehicles can migrate avatar tasks to the nearest RSUs for processing.In addition, aerial edge servers (e.g.,UAVs) can provide enhanced coverage to remote areas for provisioning avatar task migration services, which ensure the continuous avatar task execution of vehicles in the proposed framework.
B. System Model
We consider a UAV-assisted vehicular Metaverse that consists of multiple vehicles, and terrestrial or non-terrestrial edge servers (e.g., RSUs and UAVs).Importantly, UAVs provide dynamic and flexible communication coverage for vehicles in remote areas or downtown hotspots.The vehicles then engage with their respective avatars in the Metaverse, which serves as a virtual extension of our physical world and enables applications such as AR navigation.As shown in Fig.1, each vehicle can migrate its avatar tasks to the edge servers for real-time execution in a single time slot [49].Alternatively, the vehicles pre-migrate a part of the avatar tasks to the next edge server for processing in advance when the vehicles move.After accomplishing the avatar tasks, the edge servers return the task results to the corresponding vehicles.In UAVassisted vehicular Metaverses, there is a setE={1,...,e,...,E}ofEedge servers (e.g., RSUs or UAVs) distributed on the road.Leterepresent the terrestrial or non-terrestrial edge server that the current vehicle is in the coverage ande′represent the next edge server the vehicle will arrive at.Finally, the maximum load capacity of the terrestrial or non-terrestrial edge servereis, and the coverage areas of all edge servers are the same.The set U={1,...,u,...,U} ofUvehicles in UAV-assisted vehicular Metaverses generate and migrate the avatar tasks to edge servers for real-time execution.The computing capability of edge servereis denoted asce.This paper considers a single episode T =1,...,t,...,TwithTtime slots.More key symbols used in the paper are given in Table I.
1)Transmission Model
We first analyzed the latency caused by migrating avatar tasks, such as AR navigation, from vehicles to edge servers via wireless communication.LetPe=(xe,ye) denote the coordinate of edge serverein RSU, and letPe=(xe,ye,he) denote the coordinate of edge serverein UAV with altitude.In addition, the dynamic coordinate of vehicleuisPu(t)=[xu(t),yu(t)] at slott.

TABLE I KEY SYMBOLS USED IN THIS PAPER
i)UAVs-vehicles links: In the system, UAVs are equipped with flying edge servers to improve the capacity, coverage,reliability, and energy efficiency of vehicular networks.The aerial edge servers in UAVs can adjust their altitude, avoid obstacles, and thus provide more reliable communication links.The distance between vehicleuand UAVeat time slottcan be calculated as
The propagation model of UAVs-vehicles links consists of the line-of-sign (LoS) and non-line-of-sight (NLoS) channel[50].Therefore, the gain of UAVs-vehicles links can be expressed as
ii)RSUs-vehicles links: The distance between vehicleuand edge serverein RSU at time slottis defined as
where |·| is the operator of the Euclidean distance.
During the migration of avatar tasks, letBupandBdowndenote the upload bandwidth and the download bandwidth,respectively.In wireless communication, the wireless communication channel between the vehicle and RSU will keep changing as the distance between the vehicle and edge server keeps changing.Considering the homogeneous wireless uplink and downlink channels, the gainhu,e(t) of the Rayleigh fading channel between the edge servereand the vehicleuat time slottcan be calculated as
whereARS Uis the channel gain coefficient of RSUs-vehicles links,fis the carrier frequency,Pu,e(t) is the distance calculated in (3).In wireless communication, the uplink rate between the vehicle and the edge server affects the time to send avatar service requests.For the uplink rate between the vehicleuand the edge servereat time slott, we use the Shannon formula [51]
wherepuis the transmit power of vehicleu, and σeis the additive Gaussian white noise at edge servere.When a user requiresavatarservice,thevehiclewill uploadthe avatarservicerequestfromtheuserofsize(t)totheedge serverof thevehicle currentlybeingserviced.For vehicleu, the uplink transmission latencyT(t)generated by migrating avatar tasks to edge serverecan be calculated as
Similar to the uplink rate, when edge servers accomplish avatar tasks of vehicles, edge servers will establish a wireless connection with the vehicle and receive the results returned from the avatar tasks.The downlink rate between vehicleuand edge servereat time slottcan be calculated as
where σuis the additive Gaussian white noise at the vehicleu,andpeis the transmit power of edge servere.
2)Transmission Latency of Avatar Tasks
Unlike uploading an avatar task request, the vehicle will potentially receive the results returned after the avatar task has been processed from a different edge server.Specifically, the vehicle can only receive the processing result from the edge server where the request is currently sent, or it can receive both the result sent from the edge server where it is currently located; The result is then returned from the edge server where the avatar task is pre-migrated.In addition, the downlink transmission latency taken by vehicleuto download the result of the avatar task is defined as

whereαis the portion of pre-migrated avatar tasks.The premigrated avatar task is executed as a portion of the avatar task that has migrated early to the next edge server of the vehicle.In physical transmission,Be,e′denotes the bandwidth between edge servers.Therefore, the migration latency(t) caused by pre-migration is defined as
After the system decides whether to pre-migrate or not, the avatar tasks that are not pre-migrated will be processed after the edge server finished processing the other avatar tasks.The processing latency(t) taken from the completion of the avatar service request received by the edge server until the edge server processed the request is defined as
whereLe(t) is the initial computation load of edge servereat time slott.
For vehicleu, the duration time in the coverage of the current edge server is defined as(t).When the avatar tasks cannot be accomplished before it leaves the coverage of the current edge servere, then the size of unfinished avatar task(t)at time slottcan be defined as
The latencyT(t) incurred by theD(t) to perform the migration, which is defined as
After pre-migration, the pre-migrated avatar tasks will be processed at the edge server where pre-migration has been completed.The avatar tasks that are not processed before the vehicle leaves the coverage of the current edge server are transmitted by wire to the next edge server, where the vehicle will arrive and wait to be processed.Therefore, the processing latency from receipt of the request to completion at edge servere′is defined as
4)Total Latency of Avatar Tasks
To sum up, when a user needs an avatar service, the vehicle will send an avatar service request to the edge server.Latency(t)is generated in the process of sending an avatar task request.Then, the system will make the decision of whether to pre-migrate or not.If pre-migration is selected, then some of the avatar tasks, such as AR navigation, will be migrated to the next upcoming server of the vehicle.If no pre-migration is selected, then all avatar tasks will wait to be processed at the current edge server.

C. Problem Formulation
The objective of this paper is to find an optimal combination of pre-migration allocation policies for avatar tasks, such as AR navigation, under the constraint of maximum load on the edge servers (e.g., RSUs or UAVs) to satisfy the optimization objective of minimizing the average latency of avatar tasks for all vehicles, as defined in the equation as
The first and second constraints on the load capacity of edge servers indicate that, for each edge server, the load should be less than the maximum load it can store.The third constraint indicates that for each vehicle’s avatar task, the vehicle may choose to pre-migrate a part of the tasks within that task.The fourth constraint on the portion of pre-migration goes from zero, indicating no pre-migration, to one, indicating full premigration.Finally, the optimization problem is a long-term optimization withTtime slots.
Theorem 1: The Avatar Pre-migration Problem is NP-hard.
Proof: In the optimization (19), the choice of whether to pre-migrate or not has a corresponding time cost and the objective of the function is to maximize the negative of the total cost.The problem is a two-dimensional cost knapsack problem that proved to be NP-hard [6].Thus the two-dimensional cost knapsack problem can be reduced to the primal problem, i.e., the primal problem is NP-hard.■
IV.THE MULTI-AGENT DEEP REINFORCEMENT LEARNING ALGORITHM
In this section, we propose a family of MADRL algorithms to solve the above avatar task migration problem, as the problem is NP-hard to be solved via conventional approaches.First, we transform the problem of avatar task migration into a POMDP, where multiple learning agents can be trained via interaction with the avatar task migration environment.The learning agents can observe the states of the environment and receive rewards for output actions from the environment.More details about how MADRL methods handle NP-hard optimization problems can be found in [52], [53].Then, we propose the MAPPO and the TF-MAPPO algorithms to improve the strategy of agents to minimize long-term avatar task migration latency.
A. POMDP for Avatar Task Pre-Migration
In the following, we present the multi-agent decision-making process consisting of observation space, action space, and reward function for vehicles.
1)Observation Space: In UAV-assisted vehicular Metaverses, the state space of the avatar task migration environment includes the real-time information of edge servers (in RSUs or UAVs) and vehicles.During the interaction with the environment, vehicles can observe the information of surrounding edge servers for proper avatar task migration and pre-migration.Let o represents the set of observed states for all vehicles, i.e., o={o1,...,ou,...,oU}.For vehicleu, its observation at time slottis defined asou(t)=[Pu(t),Le(t),Le′(t),Ttotal(t)], wherePu(t) represents its current location,Le(t)represents the computing load of the near edge server currently migrating theavatar task to,Le′(t)represents the loadof thenextedge serverforpre-migration,andTtotal(t)represents the latency generated by the avatar service at time slott.
2)Action Space: For each vehicle, there are only two actions that can be performed: pre-migratingkcopies of the task or not pre-migrating; and the action it performs at time slottis defined asatu, and the joint action of vehicles isa.
3)Reward Function: Through each agent’s own observationou(t) , the rewardru(t) is obtained from the environment feedback after interacting with the environment using the migration policyau(t).To achieve latency minimization, we set the reward function as the negative value of the total avatar task execution latency at time slott, defined as
B. MAPPO Algorithm Design
To address the problem that the MAPPO’s forced parameter sharing imposing constraints on the policy space may lead to worse results, we apply the transformer on MAPPO.Specifically, we solve this problem by replacing the fully connected layer in MAPPO with the encoder-decoder structure of the transformer.In the following, we describe the definition of the TF-MAPPO model and its training approaches.
1)PPO
To introduce the MAPPO algorithm, we first describe the policy-improving process of a single PPO learning agent.The vanilla policy gradient approach uses stochastic gradient ascent for vehicleuto solve for the estimated objective functiongˆ(θu), which is usually defined as
where E ˆ(t){·} denotes the expected value over a batch of samples, π[au(t)|ou(t);θu] represents the current policy,ou(t) andau(t) are the state and action in the sample, andAˆu(t) is the estimated advantage value.
Based on the traditional strategy gradient algorithm, the PPO algorithm leverages the clipped surrogate objective function to avoid a large difference between the new policy and the old one, which is defined as
where θuandare hyperparameters in the policy that can be updated.The clipping functionfclip[βθu(t),ϵ] is defined as
where ϵ ∈[0,1] is the clipping parameter, and βθu(t) is the ratio of the new policy to the old policy, which is defined as
As a consequence, the differences between the old and new policies are limited.
Theorem 2(Multi-Subject Dominance Decomposition): In the multi-subject dominance decomposition theorem, the following equation always holds:
The proof of this theorem can be found in [54].This theorem provides an intuitive guide for incrementally improving the agent’s actions.Specifically, when agentu1makes an action with a positive advantage, all other agents after it in the sequence can obtain the joint action of the agents before it.In this way, it can choose an action to ensure that the advantage is positive.Since the previous agents have already made their actions, the agent only needs to search its individual action space at each step.That is, the complexity of the search is additive, not multiplicative, which will reduce the complexity of the action space search.
2)MAPPO
Based on the traditional PPO algorithm, the multi-agent proximal policy optimization (MAPPO) approach uses a framework of centralized training and decentralized execution.It equips all agents with a set of shared parameters and uses the aggregated trajectories of the agents to update the shared policies.The MAPPO approach enables all learning agents to share a global policy through parameter sharing,allowing improved collaboration between agents.However,forced parameter sharing imposes a constraint θu=θu′on the joint strategy space, which can lead to algorithms that may not end up with optimal results.
3)The Transformer Model
Based on the encoder-decoder structure, the transformer architecture introduces an attention mechanism to resolve the problem of forced parameter sharing.The attention mechanism gives the neural network the ability to “pay attention” to specific features of the data when encoding it, which helps to solve the problem of gradient disappearance and gradient explosion in neural networks.One of the most important components of the transformer is the scaled dot product attention,which captures the interrelationships between input interrelationships between sequences.Specifically, the attention mechanism captures sequence-to-sequence relationships by dotting product relationships between input sequences.Letdkdenote the dimension of K.The attention function is defined as
where Q ,K,V represent vectors of queries, keywords, and values, respectively.Self-attention is the case where Q,K and V share the same set of parameters.Modeling a sequence of actions and observations of a set of training agents makes it feasible for us to solve the MARL problem with the transformer.Next, we will discuss how the transformer model can be applied in MAPPO for giving avatar task migration decisions.
4)TF-MAPPO

Fig.2.Architecture of TF-MAPPO-based migration for avatar tasks.
To implement the sequence modeling paradigm for MARL,we leverage the approach in [19].Similar to the modeling approach applied to the transformer for the machine translation task, we modeled sequences for the MARL task.As shown in Fig.2, we embedded the observations of all agents as a sequence {ou1,...,oun}, which was used as input to the encoder.The encoder will learn the representation of the joint observations and encode the observations.The decoder obtains the encoded observations and outputs the actions of each agent in turn by means of an autoregression.
The encoder consists of a self-attentive mechanism and a multi-layer perceptron (MLP) that encodes the input observation sequence {ou1,...,oun} into {oˆu1,...,oˆun}.It encodes not only information about the individual agents but also the hidden high-level relationship between the agents interacting with each other.To learn how to express this relationship, we make the encoder approximate the value function to minimize the Bellman empirical error [55] via
whereφand φ¯ are the parameter of the encoder and the target network respectively.They will be updated every number of epochs.

decoder, our goal is to minimize the clipping of the PPO objective [56] as follows:
and

whereθis the parameter of the decoder, andAˆ(t) is an estimate of the joint advantage function.We used generalized advantage estimation (GAE) with as a robustness estimate for the value function.The output of the movement is divided into two phases, the reasoning phase,and the training phase.In the inference phase, each action is generated sequentially and reinserted into the decoder after interacting with the environment to provide support for the generation of the next action.In the training phase, the decoder takes a batch of action samples from the buffer and performs parallel computation.
The attention mechanism is an important part of the transformer.The matrix of weights used to encode observations and actions is calculated by multiplying embedded queries(qu1,...,qun)andkeys(ku1,...,kun),whereeachweightcanbe representedasw(qui,kud)=〈qui,kud〉.By multiplying the embedded values (vu1,...,vun) with the matrix of weights, we are able to obtain the output representation.An unmasked attention mechanism is used in the encoder to extract a representation of the relationship between agents.In the decoder,the attention mechanism with masking is used to capture the interrelationships between actions.
Algorithm 1 contains the pseudo-code for the TF-MAPPO algorithm.First, we initialize the environment of vehicular Metaverses, the replay buffer BF , and the parameters φ0,θ0of the encoder and decoder.As shown in Fig.2, the TFMAPPO algorithm makes decisions for the agents sequentially based on the agents’ observations.When an agent completes an action, the environment changes and becomes the observation environment for the following user.Within each episode, each agent collects its observations, actions, and rewards.Then they are inserted into the replay buffer B F.

Algorithm 1 TF-MAPPO-Based Training Algorithm for Avatar Task Migration 1: Initialize: Number of agents n, max step in an episode ,number of episodes , Replay buffer , batch size b, parameter of Encoder and Decoder.k=0,1,...,EPS-1 Tmax EPS BF φ0,θ0 2: for do t=0,1,...,Tmax-1 3: for do 4: Collect agent’s observations from the environment and embedding them into sequences.{ou1(t),...,oun(t)}5: Feed the sequence of observations into the encoder and obtain representation sequence.{ˆou1(t),...,ˆoun(t)}{ˆou1(t),...,ˆoun(t)}6: Put the representation sequence into decoder.m=0,1,...,n-1 7: for do{au0(t),...,aum(t)}8: Input into decoder and get output.aum+1(t) {au0(t),...,aum(t)}9: Execute action and insert it into.10: end for r[o(t),a(t)]11: collect the reward.{o(t),a(t),r[o(t),a(t)]} BF 12: Insert into.13: end for 14: Get a random mini-batch of data with size b from.{ou1(t),...,oun(t)} {Vφ(ˆou1),...,Vφ(ˆoun)}BF 15: Feed to the encoder and obtain.LEn-co(φ)16: Calculate with (27).ˆA 17: Compute the joint advantage function based on with.{ˆou1,...,ˆoun} {au0,...,aun-1} {πu1θ ,...,πun θ }{Vφ(ˆou1),...,Vφ(ˆoun)} GAE 18: Input and , obtain policy from the decoder.LDe-co(θ)19: Calculate with (28).20: Update the encoder and decoder by minimising with gradient descent.21: end for LEn-co(φ)+LDe-co(θ)
During the training process of agents, each agent randomly samples a mini-batch of data from the replay buffer BF for training.We embed the collected observations as sequences{o1(t),...,ou(t)}through an embedding layer and feed them to the encoder.The encoder transforms the observation sequences into a representation sequence {oˆ1(t),...,oˆu(t)} that can represent the interrelationships between observations through a self-attentive mechanism and generates value functions through MLP.The encoder’s Bellman empirical error will be calculated by (27).Then, the generated observation representation sequences and action sequences are fed to the decoder for decoding and generating policies.The Bellman empirical error of the decoder is calculated by (28).Finally, the parameters of the encoder and decoder are updated by gradient descent to minimize the Bellman empirical error.
The computation complexity of the encoder is denoted asO(n), while the computation complexity of obtaining all the actions from the decoder isO(n2) [57].Consequently, the overall complexity is primarily influenced by the execution of actions.Therefore, the total computation complexity of the TF-MAPPO algorithm can be calculated asO[EPS Tmaxn2],whereEPSrepresents the number of training episodes,Tmaxsignifies the maximum step in an episode, andnrefers to the number of agents.
V.SMART CONTRACTS FOR RECORDING RESOURCE TRANSACTION INFORMATION
While users enjoy avatar services, they also have to pay for various resources (including communication, storage, and computing resources) that the avatar takes up on the edge servers.The users choose different amounts of resources according to the different resource requirements of their avatar services.As shown in Fig.3, when a user wants to use avatar services, the vehicle will send the resource requirements needed for avatar services to the resource providers (i.e., edge servers).Once the resource provider receives the resource requirements from the user, it sets appropriate resource prices based on the resource demands and resource costs.Here, the optimal resource prices could be obtained by using optimization theory, e.g., game theory [9], [16].The resource provider then sends the price information to the user.Once the user has paid, the resource provider will allocate the appropriate resources on the edge server for the avatar.After that, the smart contracts deployed in a consortium blockchain consisting of edge devices are targeted to perform the consensus mechanism (e.g., PBFT) to verify and record the resource transactions.During this process, the smart contract records the user address with the resource provider, resource demands,the resource prices of different resources, the money paid for each resource, and so on.More details about the smart contracts can be found in Algorithm 2.
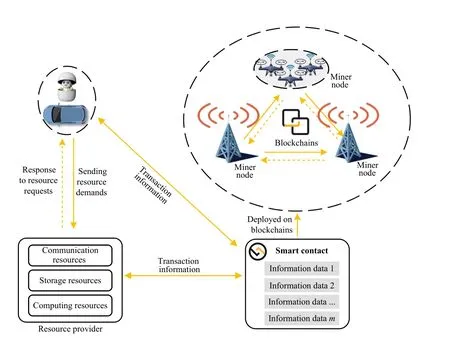
Fig.3.The execution process of the resource transaction information recording smart contract.

Algorithm 2 The Pseudo-Code of Smart Contracts for Recording Transaction Information 1: //SendRequestAddress: SRAddr;2: //SendTradeAddress: STAddr;3: //Resource_Provide_Address: RES_Provide_Addr;4: //Resource_Request_Address: RES_Request_Addr;5: Contract main is SendRequest, SendTrade{6: Function InitialStates(address STAddr,7: address payable _RES_Provide_Addr,8: address payable _RES_Request_Addr) public{9: SendTrade _sendtrade = SendTrade(STAddr);10: _sendtrade.inputRESaddr(_RES_Provide_Addr ,_RES_Reqhuest_Addr);}11: Function ToAddUserRequire(address SRAddr, uint _bandwith, uint _storage, uint _computing) public{12: SendRequest _SendRequest = SendRequest(SRAddr);13: _SendRequest.addUserRequire(_bandwith, _storage, _copmuting);}14: Function ToSendMoney(address STAddr, address SRAddr)public{15: SendRequest _SendRequest = SendRequest(SRAddr);16: _SendRequest.GetTotalMoney();17: SendTrade _sendtrade = SendTrade(STAddr);18: _sendtrade.SendMoney();19: Require totalMoney < Balance[RES_Request_Addr]20: or “Error! Your account has not enough money.”}21: }
VI.NUMERICAL RESULTS
In this section, we validate the performance of the proposed avatar pre-migration framework through simulation and verify how we record information on resource transactions between vehicles and edge servers (e.g., RSUs or UAVs)through smart contracts.
A. Avatar Task Pre-Migration
We simulated a scenario with three edge servers acting as a mobile base station on the main city road.Each edge server is equipped with computing capabilities in the environment and the edge servers are connected to each other via a wired network.All of the edge servers are evenly distributed on one side of the road, and all of the vehicles are within the coverage area of at least one edge server.For the sake of simplicity,we considered all vehicles moving at the same speed.The key parameters of the experiment are given in Table II [19].
B. Convergence Analysis
To demonstrate the effectiveness of our approach, we use several baselines for comparison with the proposed algorithms, including always pre-migrated, always not premigrated, random pre-migrated, and the MAPPO.As shown in Fig.4, the average episode reward of the proposed TFMAPPO approach is higher than those of the other baselines during the convergence process.Specifically, Fig.4 shows that TF-MAPPO outperforms Migration, Random, Pre-migration, and MAPPO by 35%, 22%, 13%, and 2%, respectively.In addition, both the TF-MAPPO approach and the baseline MAPPO achieved better performance than the other baselines,demonstrating the effectiveness of the utilization of MADRL to solve the avatar task migration problem in UAV-assisted vehicular Metaverses.Moreover, the trend of the learning curves in Fig.4 shows that as the number of iterations increases, the proposed TF-MAPPO algorithm can converge faster than the MAPPO algorithm and achieve better performance.For the TF-MAPPO approach, TF-MAPPO with UAVs can achieve higher rewards than TF-MAPPO without UAVs.The reason is that TF-MAPPO with UAVs can bring enhanced coverage to build real-time connections for vehicles and their avatars.It is worth noting that the stability of our proposed TF-MAPPO after convergence is significantly better than that of the baseline MAPPO.These results illustrate that our proposed approach can overcome the drawback of MAPPO.

TABLE II THE KEY PARAMETERS

Fig.4.Average episode reward of different algorithms.
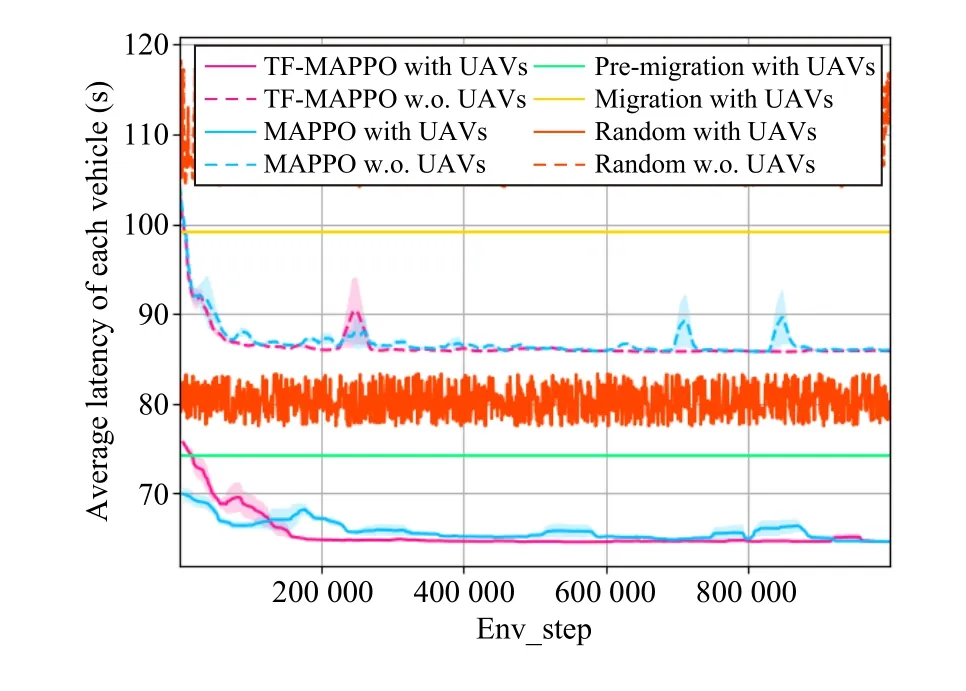
Fig.5.Average latency of each vehicle.

Fig.6.Average system latency v.s.different task sizes.
As shown in Fig.5, the average vehicle latency for the proposed algorithms decreases as the number of training steps increases, demonstrating the effectiveness of the proposed algorithm in reducing the average latency of avatar tasks as the number of training sessions increases compared to the other baselines.Specifically, our TF-MAPPO can reduce latency up to 35% of latency compared to other baselines.For the TF-MAPPO approach, TF-MAPPO with UAVs can effectively reduce the average latency of each vehicle compared to TF-MAPPO without UAVs, which benefits from the reliability brought by edge servers in UAVs.The reason is that TFMAPPO with UAVs can bring enhanced coverage that could build real-time connections for vehicles and their avatars.In addition, we can observe that the three baselines have poor performance and close latency.This is due to the fact that the vehicle decisions affect the load in different environments,and not pre-migrating results in a higher computational load on the edge servers.When the computational load on edge servers is high, the waiting time for the avatar tasks to be processed increases accordingly, resulting in increased latency.In addition, when the downlink bandwidth of the vehicle receiving avatar task results is affected by the distance between the vehicle and the edge server, it is unwise to choose the premigration decision when the vehicle is close to the current edge server, regardless of the computational load of edge servers.Similarly, choosing not to pre-migrate when the vehicle is far from the current edge server increases the latency of transmitted data.
C. Performance Evaluation Under Different System Parameters
To demonstrate the robustness of our approach under different system parameters, we vary the environmental parameters for validating the proposed learning-based algorithms.
Fig.6 shows the comparison of system latency between the TF-MAPPO algorithm and baselines under different sizes of avatar tasks.The comparison is performed for five levels of data sizes between 100 MB and 500 MB.As we can see from Fig.6, as the size of avatar tasks increases, the latency increases accordingly.In detail, the TF-MAPPO approach reduces system latency by an average of 3%, 17%, 23%, and 34% over MAPPO, Pre-migration, Random, and Migration,respectively, for different task sizes.We can observe that the approaches with UAVs have lower latency than the approaches without UAVs since UAVs can assist RSUs in processing avatar tasks, reducing the latency of avatar tasks waiting to be processed.The reason is that edge servers in UAVs can improve the established likelihood of UAV-vehicle links.Compared to the existing baselines, the TF-MAPPO algorithm still has the lowest latency for all task sizes, giving it a clear advantage when the environment becomes more complex due to the larger task size.
Fig.7 shows the comparison of the average system latency between the MAPPO-based algorithm and the baseline for different bandwidths assigned to the vehicles.We chose the system latency of the avatar task at different multipliers of the wireless bandwidth with a size of 300 MB.The TF-MAPPO approach reduces system latency by an average of 2%, 12%,20%, and 36% over MAPPO, Pre-migration, Random, and Migration, respectively, for different wireless bandwidth settings.It can be observed that approaches with UAVs have lower latency than the approaches without UAVs due to the fact that UAVs improve the coverage of wireless transmission.The trend of the curves in the graph shows that the TFMAPPO algorithm still has the lowest system latency and effectively reduces the system latency in different scenarios.

Fig.7.Average system latency v.s.different wireless bandwidth.

Fig.8.Average system latency v.s.different edge server computing capabilities.
Fig.8 shows how the TF-MAPPO approach compares to the other baselines for different edge server computational capacities.In detail, the TF-MAPPO approach reduces system latency by an average of 2%, 14%, 20%, and 35% over MAPPO, Pre-migration, Random, and Migration, respectively, for different edge server computing capability settings.As shown in Fig.8, the approaches with UAVs have lower latency than the approaches without UAVs, since the incorporation of UAVs increases the computational resources of the system and speeds up the processing of avatar tasks.As we increase the computational capability from 100 to 300, we can see a rapid decrease in the system’s latency.This illustrates that as the computational capability increases, the edge server takes less time to process the avatar task.
Fig.9 shows the impact of task migration bandwidth of the virtualization body on different approaches.The data in Fig.9 shows that the TF-MAPPO approach reduces system latency by an average of 2%, 12%, 21%, and 34% over MAPPO, Premigration, Random, and Migration, respectively, for different task migration bandwidth settings.We can observe that approaches with UAVs can bring lower latency than approaches without UAVs since UAVs can help in avatar task migration.As the bandwidth increases, the system latency continues to decrease.This is due to the fact that higher migration bandwidth reduces the time required to migrate avatar tasks.

Fig.9.Average system latency v.s.different task migration bandwidth.

Fig.10.Average system latency v.s.different number of vehicles.
We simulate the scenario with a different number of vehicles in Fig.10.The data in Fig.10 demonstrates that the TFMAPPO approach reduces system latency by an average of 5%, 14%, 19%, and 36% over MAPPO, Pre-migration, Random, and Migration, respectively, in environments with varying numbers of vehicles.We can observe that the approaches with UAVs can bring lower latency than those without UAVs because UAVs can help RSUs handle avatar tasks and reduce the load on RSUs with a different number of vehicles.As we can observe, as the number of vehicles increases, so does the latency of the system: more vehicles increase the load on the edge server and thus the time spent processing the avatar tasks.The results in Fig.10 show that our proposed approach TF-MAPPO allows the system to reduce the latency in different scenarios.From the trend of the curves, it is easy to see that our proposed TF-MAPPO algorithm can reduce the system latency more than the baseline MAPPO as the number of vehicles increases.The reason is that the transformer architecture has the advantage of processing long sequences and thus can achieve better results in an environment with multiple vehicles.
D. Smart Contract for Resource Transaction Recording
In the simulation, we consider a single blockchain scenario with five consensus nodes.In the simulation, we build a blockchain using the open-source platform WeBASE and deploy smart contracts to record resource transactions through this platform.The blockchain is built using the practical byzantine fault tolerance (PBFT) algorithm for consensus and the elliptic curve digital signature algorithm (ECDSA) to secure transactions.The WeBASE platform was deployed on a virtual machine with an Intel Core i5 running CPU, clocked at 2.4 GHz and 4GB DDR4 RAM.
Fig.11 shows the administration interface of the WeBASE platform.The upper left area of the image shows the number of nodes on the blockchain, the deployed smart contracts, the current number of blocks, and the number of blocks.The top right area of the image shows the number of transactions in the last seven days.The middle of the image shows the node ID and the current status, while the bottom part of the image shows the block information and the transaction information,respectively.
To demonstrate the consensus time taken to deploy the resource transaction recording smart contract under different consensus nodes, we recorded the consensus time for the cases with 3, 5, 7, 9, and 11 nodes, respectively.The trend from Fig.12 shows that as the number of nodes increases, the consensus time increases accordingly.

Fig.11.Smart contract implementation for resource transaction records on the WeBASE platform.

Fig.12.Consensus time v.s.different number of miners.
VII.CONCLUSION
In this paper, we have studied the avatar pre-migration problem in vehicle Metaverses.To provision continuous avatar services, we have proposed a novel avatar service migration framework, where vehicles can choose to premigrate their avatar tasks to the next near edge server for execution.This guarantees continuous immersion for users.In this framework, we modeled the vehicles’ avatar task migration decision as a POMDP and solved it with advanced MADRL algorithms, i.e., MAPPO and TF-MAPPO.In addition, compared with the MAPPO baseline, the proposed TFMAPPO algorithm overcomes the sub-optimal problem caused by the mandatory parameter sharing in the MAPPO algorithm.In addition, we recorded the transaction data of communication, computation, and storage resources between roadside units and vehicles in the blockchain to ensure the security and traceability of transactions.The simulation results illustrated that the proposed approach outperformed the MAPPO approach by around 2% and effectively reduced the latency of avatar task execution in different scenarios by around 20% in UAV-assisted vehicular Metaverses.In the future, we plan to combine the pre-trained models with a transformer model to increase the sample efficiency [58] and utilize model compression [59] to reduce the size of the transformer model in our algorithm.
 IEEE/CAA Journal of Automatica Sinica2024年2期
IEEE/CAA Journal of Automatica Sinica2024年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Reinforcement Learning in Process Industries:Review and Perspective
- Communication Resource-Efficient Vehicle Platooning Control With Various Spacing Policies
- Virtual Power Plants for Grid Resilience: A Concise Overview of Research and Applications
- Equilibrium Strategy of the Pursuit-Evasion Game in Three-Dimensional Space
- Robust Distributed Model Predictive Control for Formation Tracking of Nonholonomic Vehicles
- Stabilization With Prescribed Instant via Lyapunov Method