
Dendritic Learning-Incorporated Vision Transformer for Image Recognition
2024-03-01 10:59:06ZhimingZhangZhenyuLeiMasaakiOmuraHideyukiHasegawaandShangceGaoSenior
Zhiming Zhang , Zhenyu Lei , Masaaki Omura ,Hideyuki Hasegawa ,,, and Shangce Gao , Senior,
Dear Editor,
This letter proposes to integrate dendritic learnable network architecture with Vision Transformer to improve the accuracy of image recognition.In this study, based on the theory of dendritic neurons in neuroscience, we design a network that is more practical for engineering to classify visual features.Based on this, we propose a dendritic learning-incorporated vision Transformer (DVT), which outperforms other state-of-the-art methods on three image recognition benchmarks.
Introduction: Image recognition, as an upstream task of many computer vision problems, has very important research value.Many studies focus on optimizing the architecture of the feature extraction network to make it extract richer and more representative image features.In the early stages of deep learning, the convolutions are simply stacked to build feature extraction networks.While effective, this method had some limitations such as the need for large amounts of data, long training times, and limited interpretability [1].To address these issues, researchers have introduced more effective and biologically interpretable structures.The use of residual connections [2],densely connected blocks [3], and attention mechanisms [4] have all been explored to improve the performance of image recognition models.These structures have proven to be successful in improving accuracy, reducing training time, and enhancing interpretability.More recently, the introduction of vision Transformer (ViT) has further improved the network used to extract image features [4].ViT decomposes images into multiple patches and processes them through multiple Transformer layers, allowing the network to capture global context and long-term dependencies of images.Furthermore, a self-attention mechanism allows the model to focus on the most important regions of images, further improving its efficiency and accuracy.
However, another important aspect of the image recognition task is seldom mentioned, i.e., how to effectively classify the extracted features.Most of the aforementioned studies have focused on using multi-layer perceptron (MLP) structures for feature classification.Despite their simplicity and effectiveness, MLPs still have limitations, such as excessive parameter requirements and susceptibility to overfitting [5].They are also less suitable for handling high-dimensional feature vectors in large-scale image recognition tasks.Inspired by the evolution of visual feature extraction networks, developing more efficient and biologically interpretable classification networks has the potential to significantly improve image recognition accuracy.Thus, opening up new possibilities for computer vision applications.
Artificial neurons, inspired by their biological counterparts, play a crucial role in shaping neural networks.The initial McCulloch Pitt’s model used a simple linear threshold function for computation [6].MLP architectures later addressed the issue of linear inseparability[7], and spiking neural networks introduced discrete pulse signals to improve computational efficiency [8].However, there still exists a considerable accuracy gap between current artificial neurons and biological neurons.Recently, dendritic neurons, drawing inspiration from neuroscience, have emerged as promising alternatives.With their architecture incorporating synapse, dendrite, and soma layers,dendritic networks enhance biological interpretability and exhibit superior performance in challenging tasks [5].
In this study, we propose a novel neural network architecture that combines two biologically interpretable networks for neuroscientifically aligned image recognition.To ensure practicality, we carefully design the synapse, dendrite, and soma layers of the dendritic neuron as an artificial neuron model.By integrating the Vision Transformer with our proposed dendritic network, we create DVT, a highly interpretable network.Extensive experiments on multiple benchmarks demonstrate the significant performance improvements achieved by DVT compared to state-of-the-art methods in image recognition.The accuracy results in Fig.1 depict the performance of peer models on the CIFAR dataset, without pre-training weights.These findings indicate the potential of DVT to advance computer vision and deepen our understanding of visual perception mechanisms.Related work:
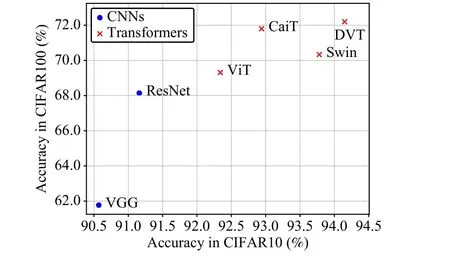
Fig.1.The accuracy comparison in CIFAR.
1) Vision Transformer: It, a novel class of image feature extraction networks, overcomes the limitations of traditional convolutional operators by using long-term dependency-based self-attention to extract spatial features [4].However, despite their effectiveness in capturing global features, they still face issues such as computational complexity [9], sensitivity to hyper-parameters [10], and data dependency [11].Besides, enhancing their expressiveness, particularly on lower-resolution datasets, remains a significant challenge.
2) Dendritic network: Inspired by the structure and function of retinal ganglion cells [12], the dendritic network has been proposed as a more biologically plausible artificial neuron [5].It has shown remarkable results in various kinds of problems [13], [14].However,its sophisticated architecture requires efficient learning algorithms to improve its performance [5], which presents an obstacle to its further development.In light of this, we aim to optimize the architecture of the dendritic network to enhance its practical performance.Specifically, we reinvent its synapse, dendrite, and soma layer to improve its learning stability and performance.It makes the dendritic network more practical for image recognition.
Methodology: In this study, we propose DVT, a dendritic learning-incorporated vision Transformer, aimed at enhancing the performance and interpretability of image recognition tasks.DVT combines two essential components: a vision Transformer featuring embedded attention mechanisms and a dendritic network mirroring real neuronal architecture.The vision Transformer extracts more comprehensive and representative image features, while the dendritic network ensures accurate feature classification.The overall framework of DVT is depicted in Fig.2.Initially, the input image is sliced into smaller patches, and linear projection and position encoding are applied to each patch to preserve spatial information and optimize computational efficiency.These processed feature maps are then fed into multiple stacked Transformer blocks, wherein the selfattention mechanism enables the network to selectively focus on pertinent information and suppress irrelevant noise.Through continuous fusion and amplification of receptive fields, DVT efficiently extracts highly representative features from the entire image.The dendritic network, comprising three biomimetic layers (synapse, dendrite, and soma), takes charge of the final feature classification.To enhance its convergence·, we introduce a feature normalization operation that reduces feature discrepancies and overall improves network performance.
1) Self-attention mechanism: It plays a crucial role in visual feature extraction by incorporating local and global information to obtain more representative features [4].By employing multi-head self-attention and stacking multiple Transformer blocks, the robustness of feature extraction is enhanced.However, the computational cost of training a vision Transformer from scratch remains a challenge, particularly when dealing with small-sized datasets.To mitigate this issue, we propose integrating locality self-attention into DVT, drawing inspiration from [15].This modification effectively captures locally-focusedattentioncontextualinformationthrougha self-maskingmatrixm∈Rh×n×nand alearnableparameterγ.This adaptation improves the efficiency of DVT without compromising its ability to capture relevant local information.Its formula is following:
whereq,k, andv∈Rh×n×dare different feature vectors that obtained by linear projection of input datax.Self-attentionA(·) integrates them via scaled dot-product.mis a all-ones matrix with negative infinity eigenvalues.It is added toAto further deepen the ability of the network to capture global features.
2) Dendritic network: Extensive neuroscience research has unequivocally demonstrated the irreplaceable nature of the theoretical model of dendritic nerves.Moreover, numerous experiments conducted in the field of information science have consistently showcased the remarkable capability of dendritic networks in effectively addressing nonlinear problems.Building upon this knowledge, in our proposed DVT, we integrate a feature normalization operation η(·)into the dendritic network, thus aligning it more closely with the practical requirements of real-world engineering applications, i.e.,
wherexis the input feature ofddimension andykis the predicted probability of thetth classification target by the network.cis the number of classes.First, normalized inputs are mapped tomdendritic branches throughmsets of learnable parameterswandb, a process called synaptic connection.Then, feature normalization and softmax activation function δ(·) are performed on each branch.Finally, soma layer conception in neuroscience is applied in the network to integrate all dendrites into the result.Notably, eachyis associated with one dendritic neuron following (3), and the synapses on each branch are independent for each neuron.Such mutually exclusive connections are considered to be ubiquitous in neuroscience[16], and they have also been proved to be the basis of efficient network inference [17].In proposed feature normalization η(·),θandλare learnable parameters,ϵis constant to prevent the denominator from being 0,x¯ and σ (x) are mean and variance ofx, respectively.
Experiment:
1) Dendrite and learning rate analysis: The number of dendrite branches directly influences the network’s ability to approximate the objective function accurately.Similarly, the learning rate significantly impacts the network’s adaptability and learning capacity.In this study, we comprehensively analyze these hyper-parameters to determine the optimal DVT configuration.We establish a fair baseline by comparing our findings to the original ViT.To ensure a consistent evaluation, all methods are trained for 100 epochs using the AdamW optimizer.CIFAR10 is chosen as the dataset for this experiment due to its universality in image recognition and the diversity of images it contains.Fig.3 presents the results, where the number of dendritic branches is denoted as 0, representing the original ViT.Remarkably, incorporating the dendritic network significantly improves the performance of DVT across various learning rates.Through extensive experimentation with different numbers of dendritic branches (ranging from 2 to 64), we observe that increasing the number of branches leads to better results.For optimal prediction outcomes across different problem domains, we recommend setting the number of branches within the range of 8 to 32.Additionally, we find that a learning rate of 0.003 yields favorable outcomes for DVT.
2) Performance comparison: We evaluate the performance of DVT against state-of-the-art methods using four widely recognized and challenging datasets: SVHN, CIFAR10, CIFAR100, and Tiny-ImageNet.The compared methods include VGG19 [18], ResNet50 [2],ViT [4], Swin [9], and CaiT [11], covering the classic CNN architecture and the latest Transformer-based neural network.Notably, the biological interpretability of these methods has shown a gradual increase, transitioning from CNN to Transformer models.The results presented in Table 1 demonstrate the clear superiority of DVT over its peers.Notably, the advantages of DVT become more pronounced as the classification difficulty of the datasets increases, reinforcing our conclusion that DVT excels at approximating complex target functions.Furthermore, the accuracy of each model increases as its interpretability improves, highlighting the advantage of employing biologically interpretable models for image recognition problems.

Fig.3.The analysis of dendrite and learning rate in CIFAR10.

Table 1.Accuracy Comparison on Four Datasets
3) Ablation study: We delve deeper into the spatial and temporal complexity of DVT.It exhibits an increased number of learnable parameters and higher FLOPs compared to the original ViT.More specifically, we introduce a linear layer between the extracted features and the classification outcomes.As presented in Table 2, the sizes of the added linear layers are 160 and 576, respectively.The parameters of the ViT-160 and the FLOP of the ViT-576 are almost similar to those in the DVT.This allows us to perform comparisons to highlight the performance advantages of DVT.The backbone networks of all model architectures are the same.Therefore, only learnable parameters and FLOPs of their classification networks are counted.Notably, a simple stacking of linear layers and increasing their size not only fails to enhance accuracy but also leads to degraded network performance due to heightened learning difficulty.In contrast, DVT relies on a sophisticated architecture to perform efficient calculations with fewer parameters, thereby enhancing network performance.
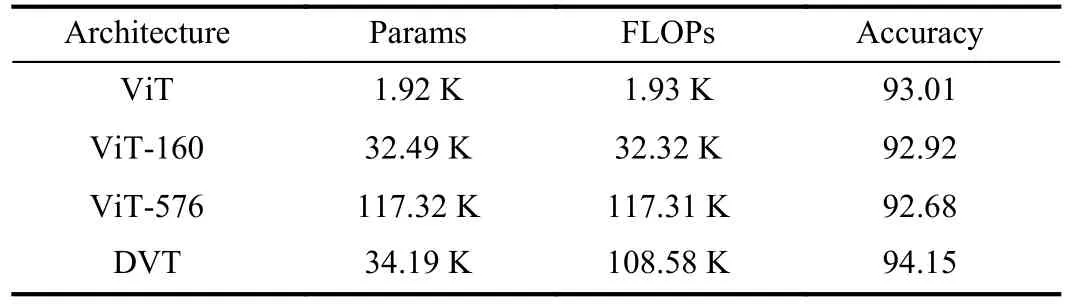
Table 2.Ablation Study On IFAR10
Conclusion: In this study, we introduce DVT, a dendritic learningincorporated vision Transformer, specifically designed for universal image recognition tasks inspired by dendritic neurons in neuroscience.The incorporation of a highly biologically interpretable dendritic architecture enables DVT to excel in handling complex nonlinear classification problems.Our experimental results highlight the substantial improvement achieved by DVT compared to the current state-of-the-art methods on four general datasets.Moreover, these findings affirm our hypothesis that networks with high biological interpretability in architecture also exhibit superior performance in image recognition tasks.
Acknowledgments: This work was partially supported by the Japan Society for the Promotion of Science (JSPS) KAKENHI(JP22H03643), Japan Science and Technology Agency (JST) Support for Pioneering Research Initiated by the Next Generation(SPRING) (JPMJSP2145), and JST through the Establishment of University Fellowships towards the Creation of Science Technology Innovation (JPMJFS2115).
 IEEE/CAA Journal of Automatica Sinica2024年2期
IEEE/CAA Journal of Automatica Sinica2024年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Reinforcement Learning in Process Industries:Review and Perspective
- Communication Resource-Efficient Vehicle Platooning Control With Various Spacing Policies
- Virtual Power Plants for Grid Resilience: A Concise Overview of Research and Applications
- Equilibrium Strategy of the Pursuit-Evasion Game in Three-Dimensional Space
- Robust Distributed Model Predictive Control for Formation Tracking of Nonholonomic Vehicles
- Stabilization With Prescribed Instant via Lyapunov Method