
A Novel Tensor Decomposition-Based Efficient Detector for Low-Altitude Aerial Objects With Knowledge Distillation Scheme
2024-03-01 11:02:50NianyinZengXinyuLiPeishuWuHanLiandXinLuo
Nianyin Zeng , Xinyu Li , Peishu Wu , Han Li , and Xin Luo ,,
Abstract—Unmanned aerial vehicles (UAVs) have gained significant attention in practical applications, especially the low-altitude aerial (LAA) object detection imposes stringent requirements on recognition accuracy and computational resources.In this paper, the LAA images-oriented tensor decomposition and knowledge distillation-based network (TDKD-Net) is proposed,where the TT-format TD (tensor decomposition) and equalweighted response-based KD (knowledge distillation) methods are designed to minimize redundant parameters while ensuring comparable performance.Moreover, some robust network structures are developed, including the small object detection head and the dual-domain attention mechanism, which enable the model to leverage the learned knowledge from small-scale targets and selectively focus on salient features.Considering the imbalance of bounding box regression samples and the inaccuracy of regression geometric factors, the focal and efficient IoU (intersection of union) loss with optimal transport assignment (F-EIoU-OTA)mechanism is proposed to improve the detection accuracy.The proposed TDKD-Net is comprehensively evaluated through extensive experiments, and the results have demonstrated the effectiveness and superiority of the developed methods in comparison to other advanced detection algorithms, which also present high generalization and strong robustness.As a resourceefficient precise network, the complex detection of small and occluded LAA objects is also well addressed by TDKD-Net, which provides useful insights on handling imbalanced issues and realizing domain adaptation.
I.INTRODUCTION
UNDER the impetus of computer vision, especially for object detection, unmanned aerial vehicles (UAVs) have been endowed with the ability to perceive, analyze, and make decisions, which enable efficient and flexible collection of images as well as accurate and rapid target recognition and localization [1], [2].In particular, object detection from the perspective of UAVs holds great potential in various domains such as intelligent transportation systems, smart city construction, and major disaster relief [3]-[5].For instance, in the event of natural disasters such as earthquakes or floods, UAVs can fly freely in the air without being constrained by ground transportation, quickly arriving at the disaster site to collect wide-angle images and conducting intelligent analysis based on deep learning algorithms, so as to provide effective support for emergency rescue and management.
Images captured by UAVs are typically low-altitude aerial(LAA) images.In LAA images, due to the jitter and rotation of UAVs, variations in target illumination and scale are conspicuous, coupled with uneven spatial distribution, prevalence of small-sized objects and dense clustering, and the blurriness of obtained samples.Simultaneously, the hardware resources of UAVs are significantly constrained, rendering them inadequate for accommodating the computational capabilities of large-scale models.Hence, despite the remarkable advancements in general machine vision technologies, the specific object detection methodologies targeting LAA images have not yet been adequately explored in-depth, and there are many performance bottlenecks such as poor recognition accuracy, low positioning precision, and high latency.
For example, the two-stage algorithm Faster R-CNN (regian convolutional neural network) [6] effectively incorporates contextual knowledge to enhance feature representation, but its large parameter size results in low recognition speed, making faster R-CNN fail to meet the lightweight deployment requirements in LAA image detection tasks.The well-known YOLO (you only look once) series algorithms [7]-[9] based on one-stage framework leverage a single neural network for object classification and bounding box regression simultaneously to enhance the detection efficiency, which sacrifices the localization accuracy and may present unsatisfactory recognition performance for small-sized targets in UAV-based tasks.Furthermore, RefineDet [10] inherits the advantages of both one-stage and two-stage detectors by designing an anchor refinement module to filter negative anchors and coarsely adjust their position and size, followed by using the refined anchors for a second regression and multi-class classification based on the object detection module.However, RefineDet exhibits unsatisfactory results for small and dense objects in LAA images due to the unreasonable receptive field settings.
In recent years, some efforts have been carried out to improve the recognition accuracy and computational efficiency of models for UAV-based target detection.However,existing LAA image detection methods exhibit certain limitations.Some approaches focus on enhancing prediction accuracy without considering the deployment practicality for UAVs, while others utilize fewer parameters but fail to demonstrate effective performance for LAA-based targets.In particular, inadequate attention is given to addressing the performance trade-off and sample imbalance problems in complex scenes.For instance, EdgeYOLO [11] incorporates data augmentation technique and hybrid random loss function to address the over-fitting issues, while the EdgeYOLO might not adequately address the issue of imbalanced scenes in LAA images, potentially resulting in biased detection and overlooking certain classes of objects.Similarly, parallel residual bifusion network (PRBNet) [12] combines top-down and bottom-up paths for bi-directional feature fusion, thereby retaining high-quality features and enhancing LAA image target localization accuracy, but its large computational complexity presents challenges in practical deployment.Furthermore,there are some innovative studies focusing on UAV-based model trustworthy and intelligent systems, such as scenarios engineering and synthesize methods [13]-[15], which provide robust and dependable solutions for enhancing situational awareness, optimizing resource allocation, and increasing the overall performance.
To tackle the aforementioned challenges, this study addresses the dual objective of attaining both accuracy and computational efficiency in LAA-based detection models.Therefore, we propose a novel framework, termed TDKDNet, which leverages tensor decomposition (TD) and knowledge distillation (KD) techniques.TDKD-Net (TD and KDbased network) is built upon the widely adopted YOLOv7 network [16], aiming to optimize both accuracy and lightweight characteristics in LAA image object detection tasks.On one hand, in terms of improving detection precision, firstly, the performance bottleneck of tiny-sized targets is alleviated by designing a small object detection head (SODH), which leverages higher resolution feature maps and a smaller receptive field to extract fine-grained details from targets.Secondly, to handle the issues arising from uneven spatial distribution and blurred targets, a dual-domain attention (DA) mechanism is introduced, which is integrated into the efficient layer aggregation network (ELAN) to propose the DA-ELAN.To be specific, in the spatial domain, an adaptive convolution kernel is employed to generate feature responses from diverse positions, which enables the ELAN to effectively address the issue of uneven spatial distribution of targets in both sparse and dense areas; in the channel domain, a self-attention mechanism is adopted to learn the inter-channel correlations, facilitating the extraction of more comprehensive and resilient feature representations, which significantly boosts the complementarity between features and contributes to the overall robustness of the model.Furthermore, in order to tackle the difficulties posed by inaccurate bounding box regression(BBR) and imbalanced positive and negative samples, the improved focal and efficient IoU (intersection of union) loss with optimal transport assignment (F-EIoU-OTA) is developed.The F-EIoU-OTA mechanism explicitly measures the differences of three geometric factors in BBR: overlap area,center point, and bounding box length.
On the other hand, a thorough analysis of the redundancy in the ELAN structure is conducted, which redundantly extract similar or identical features at multiple stacked layers.To effectively handle the conflict between high-resolution property of LAA images and the limited computational resources of embedded devices, the ideas of tensor decomposition (TD)and knowledge distillation (KD) are adopted to compress the model at both the parameter and structure levels, which facilitate reducing the model redundancy and improving detection efficiency.The TD-ELAN reduces the complexity of the model while preserving important information, which is particularly beneficial for UAVs-based resource-constrained environments and real-time applications.Moreover, by leveraging the knowledge learned from a larger and more complex model, the designed TDKD-Net gains insights into challenging patterns and generalizes better on unseen data, leading to enhanced performance in various scenarios.Furthermore,ELAN, combined with TD and KD, promotes the extraction of more robust feature representations.The fusion of knowledge from a larger model enriches feature learning, enhancing the model’s capability to recognize complex patterns and improve object detection accuracy.
The major contributions of this paper are outlined as follows:
1) A novel LAA target detection framework TDKD-Net is proposed, which can effectively balance the detection accuracy and model size.
2) Based on the ELAN, dual-domain attention and tensor decomposition are developed.Through the channel and spatial attention mechanism, the TDKD-Net can extract robust feature representations with a slight parameter increase cost.
3) An equal-weighted response knowledge distillation method is introduced, which uses the output response of the large model to improve the generalization ability of TDKDNet, and compensate for the performance degradation caused by TD.Furthermore, the F-EIoU-OTA method is proposed to solve the performance bottleneck of the model caused by the imbalance of bounding box regression samples and the inaccurate regression geometry factors, and improve the detection accuracy.
4) An equal-weighted response knowledge distillation method is proposed, which uses the output response of the large model to improve the generalization ability of the small model and compensate for the loss of accuracy caused by tensor decomposition.
The remainder of this paper is organized as follows.In Section II, related representative work is reviewed, and the proposed TDKD-Net is introduced in Section III.Experimental results and discussions are presented in Section IV, and finally, conclusions are drawn in Section V.
II.RELATED WORK
In this section, relevant LAA object detection algorithms are reviewed.Due to the performance bottleneck caused by the unique nature of images captured from UAVs, methods for improving detection accuracy and compressing model size have been briefly introduced as well.
A. Low-Altitude Aerial Object Detection Algorithms
In the field of computer vision (CV), object detection methods based on deep learning have achieved great success in natural scenes.The success of CV techniques can be drawn upon and referenced for UAV-based detection tasks, for which many detection algorithms specifically designed for LAA images have been proposed.For example, in [17], a UAV object detection method ComNet based on thermal images is proposed for pedestrian and vehicle targets under different lighting conditions in both daytime and nighttime.ComNet employs a boundary-aware salient object detection network to extract maps of thermal images, and enhances thermal images using corresponding saliency maps through channel replacement and pixel-wise weighted fusion, which achieves a tradeoff between average precision and inference time.In [18], a feature fusion module has been proposed to enhance the expression capability of small objects by facilitating the interaction and fusion of features across multiple levels.Additionally, to address the problem of discontinuous information in occluded objects, an efficient convolutional transformer block with multi-head self-attention mechanism has been introduced.To address the problems that scale of objects changes dramatically and the high-speed motion brings object blur,[19] adds a prediction head to detect targets at different scales and replaces the original one with a transformer structure,which explores the detection potential for complex environments with self-attention mechanism.Inspired by trident networks, [20] presents an improved ResNet module that utilizes dilated convolutions to effectively capture contextual information, particularly for small-sized objects.By incorporating this module, the ResNet-based model becomes robust to scale variations in LAA objects.Moreover, in [21], small object detection accuracy is enhanced by incorporating feature maps from a shallow layer that contains fine-grained information for precise location prediction.This improvement is achieved by fusing local and global features from both shallow and deep feature maps within the pyramid network, resulting in an enhanced ability to extract more representative features, and the proposed methods have shown impressive performance and interpretability for LAA images.
In this work, YOLOv7 is used as the baseline detection framework of proposed TDKD-Net, which incorporates strategies such as ELAN [22], coarse-to-fine guided label assignment and planned re-parameterized [23] convolutions.It is worth noting that, in addition to designing effective feature integration methods and accurate detection strategies for the network architecture, YOLOv7 also places great emphasis on optimizing the model training process.Specifically, it discusses some optimization modules that can improve accuracy without increasing the inference cost.Therefore, the improvement of YOLOv7 in model size and detection accuracy is significant.
B. Methods for Performance Improvement and Model Compression
Generic target detection algorithms are unable to overcome the performance bottleneck caused by remote shots, background occlusion, and tiny size in the UAV view, because the feature extraction and information abstraction structures are designed for natural scene images.Meanwhile, most deep models are computationally and memory-intensive, which makes it difficult to be deployed in embedded systems.Therefore, in response to performance improvement and model compression issues, recently there have been many improved approaches for LAA-based tasks.
On one hand, the improvement of target detection performance from the perspective of drones mainly includes multiscale feature fusion, regional focusing strategy and loss function optimization.For example, in view of the insufficient visual information for small objects, a novel enhanced multiscale feature fusion method is proposed in [24], where rich receptive field information combined with contextual features is fully exploited.In addition, considering the issue of imbalanced positive and negative samples, [25] adopts VariFocal loss to address the detection of targets that require heightened attention, which selectively reduces the loss contribution of negative samples without uniformly decreasing the weight of positive ones in the same manner.
On the other hand, in order to adapt to the deployment requirements of embedded or edge devices and achieve realtime applications, some lightweight methods are applied to LAA image analysis.For instance, to enable the inference on resource-constrained edge devices, [26] leverages the lightweight MobileNet V3 as a replacement for the original YOLOv4 backbone, resulting in a significant reduction in parameters.Meanwhile, [27] introduces network sparsity by incorporating L1 regularization on the convolutional layer and implements channel or layer pruning techniques to eliminate redundant structures.Furthermore, facing the real-time detection of embedded systems using UAVs, [28] develops an improved CNN model by employing the KD scheme on the pruned models.
In this work, for the purpose of achieving a compromise between recognition precision and computational resources in the context of network structure optimization, the ELAN combined with DA mechanism, and a new object detection head for small-sized targets are constructed.At the same time, an FEIou-OTA mechanism is proposed to solve the performance bottleneck of the model caused by the imbalance of bounding box regression samples and the inaccurate regression geometry factors.Moreover, TD and KD techniques are applied for reducing network structure redundancy and compressing model size.Specifically, CNNs can predict results with only a small number of parameters, which indicates that there is a large amount of redundant information in the convolutional kernels.The idea of TD is to decompose the original CNN tensors into several low rank ones, which is beneficial for reducing the number of convolution operations and accelerating the operation process, and the mainstream TD approaches include CANDECOMP/PARAFAC (CP), Block-Term Tucker(BTT), Tucker-2, Tensor Train (TT), Tensor Ring (TR)[29]-[32] and typical non-negative matrix factorization methods [33]-[35].Furthermore, KD is a parameter optimization and model compression method based on transfer learning[36], which accomplishes the model compression and acceleration by transferring the relevant domain knowledge of teacher network to student network and guides the training of the latter.Generally, teacher networks are often of complex structures with strong generalization abilities, while student networks are small-sized models, and performance of student networks can be significantly improved under controlled parameter quantities through KD scheme.The mainstream KD methods can be divided into three types: response-based, feature-based and relation-based KD frameworks [37]-[39].
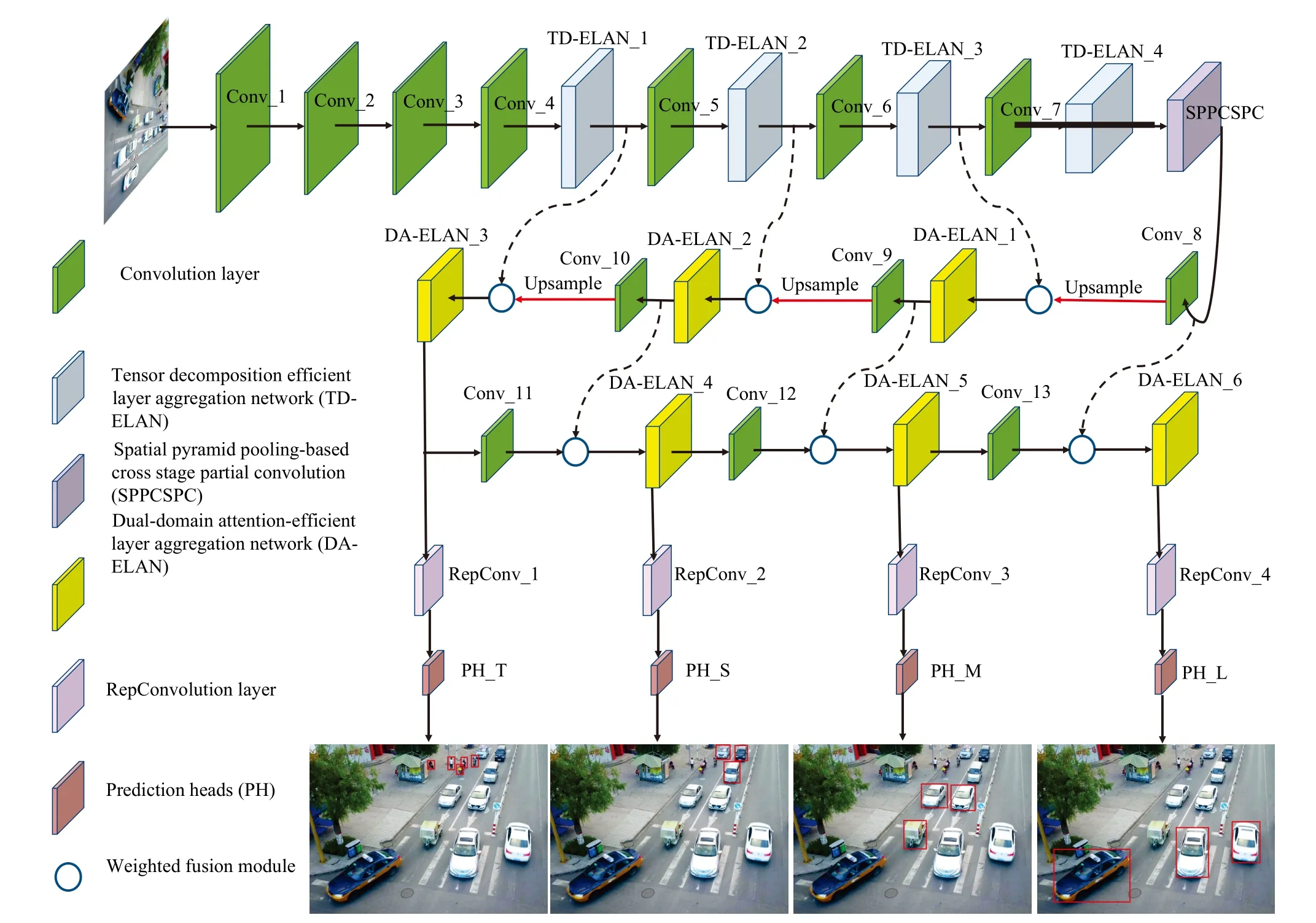
Fig.1.Framework of the proposed tensor decomposition and knowledge distillation-based network (TDKD-Net).
III.PROPOSED METHOD
In this section, the proposed TDKD-Net is elaborated with implementation details, including the designing principles of DA-ELAN and TD-ELAN, as well as the developed equalweighted response-based KD scheme and F-EIoU-OTA mechanism.
A. Overall Framework of TDKD-Net
To begin with, the overall framework of TDKD-Net is illustrated in Fig.1.Firstly, the resolution of all LAA images is adjusted to 640 × 640 with data augmentation operations like geometric transformation, color adjustment, noise addition and morphological operations, and then input images are down-sampled by 4 times through Conv_1 to Conv_4 operations, where each operation consists of a 3 × 3 convolution with batch normalization and SiLU activation.Afterwards,four designed TD-ELAN modules are interspersed in the down-sampling operations of Conv_5 to Conv_7, which is responsible for obtaining rich gradient flow information and continuously enhancing contextual learning capabilities.It is worth noting that the convolution operation combined with tensor decomposition is embedded in TD-ELAN, which can effectively reduce redundant computational parameters.Furthermore, the spatial pyramid pooling-based cross stage partial convolution (SPPCSPC) module avoids the dilemma of data distortion caused by cutting and scaling the image region,and further solves the problem of repeated feature extraction with less computational cost.
Next, the multi-scale feature maps are fused and in the followed Conv_8 to Conv_11 operations, successive six DAELAN modules are performed on different scales maps, where the dual-domain attention mechanism is applied for modeling the target locations and category characteristics.At last, four prediction heads are designed to recognize and locate objects at multi-scale level, which covers from tiny to large targets.Noticeably, reparameterized convolution (RepConv) is employed prior to the prediction head for channel adjustment, while simultaneously expediting the inference process through equivalent structure fusion.RepConv [23], as an efficient convolutional module, reinforces feature maps by replicating input or output within the channel dimension, without introducing additional parameters or computations.Substituting traditional convolutional layers with RepConv significantly enhances the performance of detection for LAA-based objects.

Fig.2.The structure of DA-ELAN (left) and mechanism of dual-domain attention (right).
B. Dual-Domain Attention-Efficient Layer Aggregation Network
In order to improve the target focusing ability in the multiscale fusion process, a dual-domain attention mechanism based on spatial and channel domain is embedded in ELAN to develop DA-ELAN.In the proposed DA mechanism, the spatial attention focuses on selectively attending to specific spatial locations, which assigns higher weights to certain regions that are deemed more important for the detection task at hand,and further effectively concentrates computational resources on informative regions.Moreover, the channel attention aims to highlight critic feature maps by distributing distinct weights to each channel, where the informative channels are amplified and unimportant ones are suppressed, and further the model can enhance the discriminative power of feature representations.As shown on the left of Fig.2, the dual-domain attention mechanism is introduced into the ELAN structure.By combining the two types of attention mechanisms, the proposed DA-ELAN could exploit both spatial and channel dependencies in LAA images, so that context-aware focused information can be efficiently utilized.
As shown in Fig.2, the DA mechanism inspired by [40] is further developed with the ELAN structure.In the DA module, the input featureFis firstly executed channel attention operations, where the max and average poolings are used to aggregate and refine target features.Subsequently, it is imperative to highlight that substituting the multilayer perceptron with a duo of 1 × 1 convolution operations engenders several noteworthy advantages.This entails a marked reduction in both parameter quantity and computational workload, while simultaneously preserving the spatial structure and local correlation of the feature map.Consequently, this leads to an augmented spatial information capacity, thereby elevating the network’s efficiency and generalization ability.Moreover, the Add operation and Sigmoid activation synergistically facilitate the generation of channel domain attention.Next, the channel weight distribution of different pixel regions is realized by element-wise multiplication, and spatial attention operations are further carried out.Compression is performed using max and average poolings over each channel, and 1 × 1 convolution is applied for parameter learning.Similarly, after the Sigmoid activation, the spatial domain weight assignment of different pixel regions is finally achieved by element-wise multiplication and obtain the refined featureF′.The working principle of the DA module is expressed as follows:
whereαandσdenote the R eLU and S igmoid function, respectively;APandMPrepresent Average Pooling and Max Pooling,respectively.C1,C2andC3refer totheconvolutionoperations.Fis the originalfeature map oftheinput,F′cdenotes the feature map after the channel attention, and combined with spatial attention, the final outputis obtained.
C. Tensor Decomposition-Efficient Layer Aggregation Network
The original ELAN [22] considers the shortest and longest gradient paths of each layer and the longest gradient path of the whole network, where the transition layer is appropriately removed to alleviate performance degradation caused by model scaling.Through observation, it is evident that the ELAN architecture employs an extensive array of 1 × 1 convolution for channel transformation or dimension reduction.Moreover, it integrates numerous parallel convolutional branches to bolster the expressive capacity of features.While these convolutional branches contribute to heightened feature diversity and detailed information, they also incur an escalation in parameters and computations, potentially introducing redundant and noisy information.

Fig.3.The structure of TD-ELAN (left) and TT-format TD principles for convolutions (right).
Therefore, in order to minimize the redundancy of convolutional operations, the TD is introduced into the ELAN structure.In the TD principles, Tucker and CP decompositions are the most well-known TD methods, and in comparison to these two conventional ways, the TT decomposition possesses more inherent low-rank properties and provides more accurate information representation, so the TT-ELAN structure is proposed, as illustrated in Fig.3.
Due to its balanced unfolding matrices, the TT decomposition can make more effective use of the information contained in the original tensors, which decomposes anN-th order tensor into a contraction form ofN-1 second-order or thirdorder tensors.The TT decomposition scheme [41] is performed by the following formula to represent the operation mode of the convolution kernel:
whereFandF′refer to the original feature map and the refined one by convolutionW, respectively, andBis the bias.
For ease of expression, we rewrite (2) as follows:

To simplify the notation, the formula of the TT decomposition for the convolutional kernel can be expressed as
As shown in the blue box content of Fig.3, the specific convolutional layer in the original ELAN structure can be represented in the following form:
D. Equal-Weighted Response-Based Knowledge Distillation
Although TT decomposition reduces the redundant parameters of convolutional operations through low-rank approximation, it unavoidably traps in the bottleneck of precision degradation.As a result, the equal-weighted response-based KD method is further applied for the proposed TDKD-Net, in which the knowledge transfer process from a teacher model to a student model is based on equal weights assigned to the responses generated by both models.The aim of KD is to encourage student model to learn knowledge from the teacher while maintaining a balanced consideration of its own predictions, leading to improved performance and generalization capabilities.The distillation scheme is illustrated in Fig.4.In the designed KD scheme, the enhanced TDKD-Net that increases the input resolution or the number of layer channels is used as the teacher network for pre-training.Subsequently,a distillation process is initiated, computing the distillation loss between the teacher network and the student model,which facilitates the optimization of training parameters for the student model.
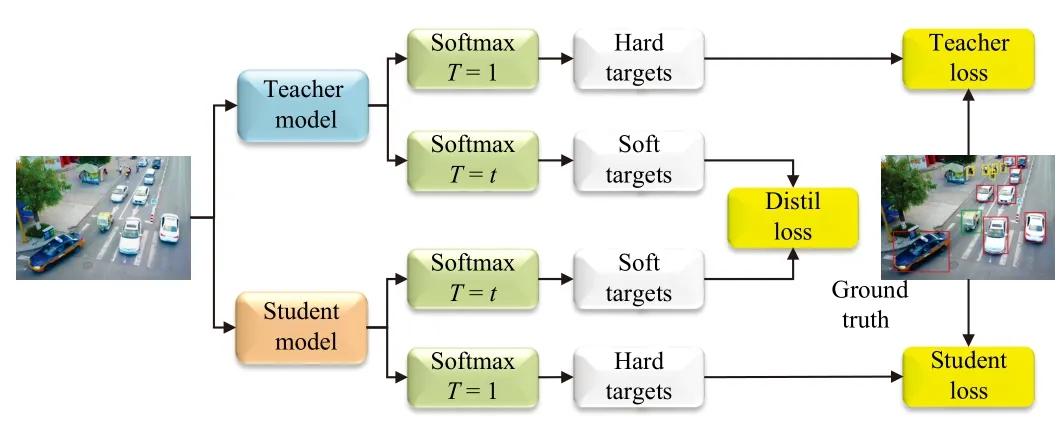
Fig.4.Equal-weighted response-based distillation framework.
Subsequently, the principles of equal-weighted responsebased KD is analyzed through the training loss functions.For the loss functionLossstuof student model TDKD-Net, the weighted sum of the classification loss, confidence loss and bounding box loss are included, which can be expressed as follows:
Furthermore, we observe that the original OTA (optimal transport assignment) mechanism [42] employs the relative proportion of width and height within the CIoU loss function,rather than their absolute values.Consequently, when the prediction box’s width and height meet specific conditions, the additional penalty term related to the relative proportion becomes ineffective.This situation hinders simultaneous increment or decrement of both width and height, thereby hampering synchronized optimization.To enhance the precision of object identification and localization, the EIoU loss[43] is adopted for accurate bounding box regression.The EIoU loss explicitly quantifies discrepancies in three geometric factors of BBR, namely the overlap area, center point, and side length, which are defined as follows:
whereLEIOUmainlycontainsthe IoU lossLIOU,thedistance lossLdisandthe aspectlossLasp,whereWcandhcarethe width and height of the smallest enclosing box covering the two boxes, respectively.ρ2(b,bgt) represents center distance,and ρ2(W,Wgt), ρ2(h,hgt) denote the width and height differences, respectively.
It is noticeable that the problem of imbalanced training examples always exists in BBR, that is, due to the sparsity of the target object in the image, the number of high-quality examples (anchors) with small regression error is much less than that of low-quality examples (outliers).Outliers produce gradients that are too large and harmful to the training process.Therefore, it is crucial to make high-quality examples contribute more gradients to the network training process, and the focal mechanism [43] is introduced to enhance the contribution of high-quality anchors with IoU in BBR model optimization, while suppressing irrelevant anchors.Focal Loss introduces a focusing parameter to re-weight the contribution of each sample during training, thereby amplifying the importance of hard-to-classify samples and enhancing the model’s performance on minority classes.As part of the bounding box loss in (8), the F-EIoU loss is defined as follows:
whereIoU=|A∩B|/|A∪B| andγis a parameter to control the degree of inhibition of outliers.
In order to avoid the student model mislearning the background prediction of the teacher model, the objectness scaling strategy [44] is further applied in above distillation process, in which the student model TDKD-Net employs the distillation mechanism only when encountering high-confidence outputs from the teacher model.Inspired by the notion of mutual learning, we believe that teacher knowledge is equally important as student information, therefore the same value weights are utilized to optimize the student model.In addition, the temperature coefficientTis introduced to control comparable gradient contributions from soft and hard targets [37], and the distillation loss from the classification, confidence and bounding box aspects, can be expressed as follows:
IV.RESULTS AND DISCUSSIONS
In this section, the proposed TDKD-Net is comprehensively evaluated on VisDrone [45], SeaDronesSee [46],UAVOD10 [47] and COCO2017 [48] datasets.Furthermore,substantial comparison experiments and ablation studies have been carried out to validate the effectiveness and superiority of the developed methods.At first, experimental datasets and environment are briefly introduced.

TABLE I COMPARISON RESULTS BETWEEN YOLOV7 AND TDKD-NET IN VISDRONE, SEADRONESSEE, COCO2017 AND UAVOD10 VALIDATION SETS
A. Dataset and Experimental Settings
In order to facilitate an equitable comparison of the suggested enhancements, we conducted all experiments utilizing PyTorch with Python 3.8-based deep learning framework, and executed training from the ground up on a single NVIDIA 3090Ti GPU.Throughout all experimental configurations, we maintained uniformity in the input image size, data augmentation approach, learning rate, and batch size.
The evaluation encompasses four datasets: VisDrone-2023,SeaDronesSee-v2, UAVOD10 and COCO2017.Specifically,VisDrone-2023 serves as the principal dataset and constitutes a large-scale UAV aerial image benchmark.It encompasses 6471 training images (1.44 GB) and 548 validation images(0.07 GB) with 2.6 million annotations across 10 object categories, including pedestrians, bicycles, and cars.The majority of objects are notably small, with 74.7% measuring below 32 × 32 pixels.On average, each image contains 61 objects,with certain images containing over 900 objects, thereby presenting significant complexity and computational challenges for detection algorithms.The prevalent object categories are pedestrians (29.4%), people (10.2%), and cars (23.5%), which hold paramount importance in UAV detection scenarios.Although other categories are relatively infrequent, they remain representative within the dataset.
The remaining datasets serve as supplementary resources for performance validation.SeaDronesSee-v2 is tailored for UAV-based search and rescue operations in oceanic scenarios,encompassing five categories: swimmer, boat, jet-ski, life-saving appliances, and buoy.We employ a compressed version of a subset of SeaDronesSee-v2, comprising 1082 training images and 464 validation images, randomly sampled from the original dataset.UAVOD10, comprising 10 UAV target detection categories, including building, pool, vehicle and so on, is divided randomly into 590 training images and 254 testing images.Lastly, COCO2017, a large-scale and one of the most popular object detection dataset, comprises 80 categories, with 118 000 training images and 5000 testing images.
Furthermore, preprocessing is performed on above datasets before training the model, where the size of input images is resized to 640 × 640 at first, and other data augmentation operations are only performed on the training samples, including HSV augmentation, translation, scale, flip, mosaic, mixup and copy-paste operations for LAA images.Online data augmentation is adopted, which allows the diversity of data fed into network training to be enriched without actually increasing the local training images.Regarding the VisDrone, SeaDronesSee, UAVOD10, and COCO2017 datasets, we have established batch sizes of 8, 12, 8, and 8 for training the models, respectively.The number of training epochs is set to 500 800, 1000, and 120, correspondingly.For TDKD-Net, the initial learning rate is configured to 0.01, employing the OneCycleLR policy with a maximum value of 0.1, while stochastic gradient descent is utilized as the optimizer.Meanwhile, the temperature factorTfor equal-weighted responsebased KD is set to 20.The learning rates for other models remain unchanged from their original settings.
B. Performance Evaluation
To completely evaluate performance of the proposed TDKD-Net, three groups of experiments are carried out,which aim at verifying the generalization ability, superiority against other typical CNN models and competitiveness in comparison to state-of-the-art UAV-based object detection algorithms, respectively.MetricsPrecision,Recall, mAP50,mAP50:95,Params,GFLOPs,FPSandTraining-timeare adopted for performance evaluation, whereAPis the abbreviation of average precision.Specifically,Precisiongauges the model’s accuracy in identifying true positive instances among all positive predictions, whileRecallindicates its ability to capture all relevant positive samples within the dataset.mAP50representsAPover IoU at 0.5, and mAP50:95representsAPover IoU at [0.5:0.95:0.05] (from 0.5 to 0.95 with an interval of 0.05).The remaining metrics are as follows:Paramsdenotes the number of model parameters,GFLOPsrepresents the computational complexity of the model,FPSsignifies the frame rate of the model detection, andTrainingtimeindicates the time required for the model to complete a certain number of epochs.
In the following, the precision and recall indicators in all experimental data are shown as percentage form.

Fig.5.Visualization results of baseline models and TDKD-Net for VisDrone and SeaDronesSee validation sets.
1)Comparison With the Baseline Models: Initially, we validate the performance and effectiveness of the proposed TDKD-Net alongside the baseline model YOLOv7 using the VisDrone, SeaDronesSee, UAVOD10, and COCO2017 datasets.The comparison results are presented in Table I and visualization predictions as shown in Fig.5.The results reveal superior performance of TDKD-Net compared to the baseline model across all four datasets.Notably, TDKD-Net achieves remarkable improvements in mAP50:95of 3.0%, 2.6%, and 2.8% for the first three LAA image datasets, attributed to its small object detection head and attention mechanism, which significantly enhancePrecisionandRecall.Particularly on UAVOD10, theRecallis boosted by 8.5%.Moreover, the FEIOU mechanism contributes to more accurate bounding box regression and higher precision.The performance superiority of our model over the baseline extends to all metrics on the COCO2017.While maintaining stable values of precision and recall, TDKD-Net reduces the parameters count by 2.097 M compared to YOLOv7, making it more suitable for lightweight deployment needs for UAV-based LAA images.For an intuitive view, experimental results of the proposed TDKD-Net framework and baseline models are visualized in Fig.5, where the first three rows are predictions obtained by VisDrone dataset and the last row is from SeaDronesSee.The comparison results with gradient-weighted class activation mapping (Grad-CAM) have shown that the introduction of small object detection head (SODH) and DA mechanism can make the model accurately locate the target region and suppress useless information.In particular, under the complex scenes like severe light changes, tiny-sized and blurred objects, the developed TDKD-Net demonstrates strong robustness.It should be highlighted that, for the first line of LAA image, our TDKD-Net can recognize the tiny-scale crowds at long distances, which are missed detection by the baseline model.For the maritime vessel instances in the fourth line, the baseline model outputs a redundant prediction bounding box,whereas TDKD-Net dose not.By using the proposed TDKDNet, the better overall performance is achieved in terms of both localization and recognition ability of small-sized and densely distributed LAA objects.
2)Comparison With Typical CNN-based Methods: In order to further validate the competitiveness of the proposed TDKD-Net, other 13 representative CNN-based algorithms are adopted for comparison in this experiment setting, including RetinaNet [49], fully convolutional one-stage object detection (FCOS) [50], CenterNet [51], TridentNet [52], adaptive training sample selection (ATSS) [53], feature selective anchor-free (FSAF) method [54], faster-RCNN [6], VariFocal network (VFNet) [55], disentangle dense object detector(DDOD) [56], YOLOX [57], Cascade-RCNN [58], taskaligned one-stage object detector (TOOD) [59] and the improved YOLOv3 [9].For fairness, all models share the same datasets, and the comparative results on validation dataset are reported in Table II.

TABLE II COMPARISON WITH TYPICAL CNN-BASED MODELS ON VISDRONE AND SEADRONESSEE VALIDATION SETS
As can be seen from Table II, the developed TDKD-Net achieves the best results on all metrics, which further demonstrates the superiority of TDKD-Net for UAVs-based object detection tasks.In particular, the TDKD-Net outperforms the suboptimal results on mAP50and mAP50:95of 10.2% and 6.3% respectively for the VisDrone dataset, while for the SeaDronesSee dataset, the proposed TDKD-Net also achieves satisfactory results of 87.8% and 57.2% on mAP50and mAP50:95, respectively.
Through this group of experiment, it is demonstrated that the proposed TDKD-Net has overwhelming precision advantages against other advanced CNN-based models, which may owe to the meticulously designed SODH for tiny targets, DA mechanism for focusing on key information, improved loss functions for stable training and KD scheme for robust knowledge acquisition.
3)Comparison With State-of-Art UAV-Based Detection Algorithms: This section presents a comprehensive comparison between the proposed TDKD-Net and other state-of-theart UAV-based detection algorithms, including Transformer prediction head (TPH)-YOLOv5 [19], parallel residual bi-Fusion network (PRBNet) [12], YOLOv8 [60], EdgeYOLO[11], and the PaddlePaddle evolved version of YOLO (PPYOLOE) along with its improved variants: PP-YOLOE with learnable parameterαfor the second output layer of the backbone (PP-YOLOE-P2-Alpha) and with scale optimization and detection head (SODH) (PP-YOLOE-SOD) [61].It is important to note that all experimental results are conducted under a fair comparison, utilizing the same local experimental setup.However, it may differ from the reported results of the advanced models.For instance, the best results of TPHYOLOv5 in their paper are based on high-resolution input,which increases the model’s memory consumption, neglecting the deployment factor.Therefore, we maintain consistency by employing 640 × 640 size images for training in all experiments.
Tables III and IV demonstrate the superiority of the proposed TDKD-Net over well-known LAA image detection algorithms in terms of recognition accuracy, reduced parameter count, and controlled computational complexity.TheParamsandGFLOPsvalues of TDKD-Net, measuring spatial and computational complexity, are 34.433 M and 105.6,respectively.For the challenging VisDrone task, TDKD-Net exhibits significant performance advantages, achieving a remarkable 9.8% and 6.1% increase in mAP50and mAP50:95metrics compared to TPH-YOLOv5, respectively.In the SeaDronesSee task, which focuses on UAV detection of maritime targets, TDKD-Net demonstrates exceptional robustness and generalization, achieving commendable mAP50and mAP50:95metrics of 87.8% and 57.2%, respectively.As shown in Table IV, TDKD-Net achieves a highFPSindex of 68.03, ranking second, satisfying real-time detection requirements, but a limitation lies in the TD and KD schemes, which has a negative impact on theTraining-timeefficiency.The YOLOv7-sea [62] demonstrates remarkable performance in maritime UAVs-based target detection using the SeaDrones-See dataset, whose effective and inspiring strategy yields impressive results.In short, TDKD-Net achieves an efficient balance between recognition accuracy and computational complexity, making it suitable for practical UAV LAA image detection tasks, while a longer training phase for reduced computing resource dependency during deployment.
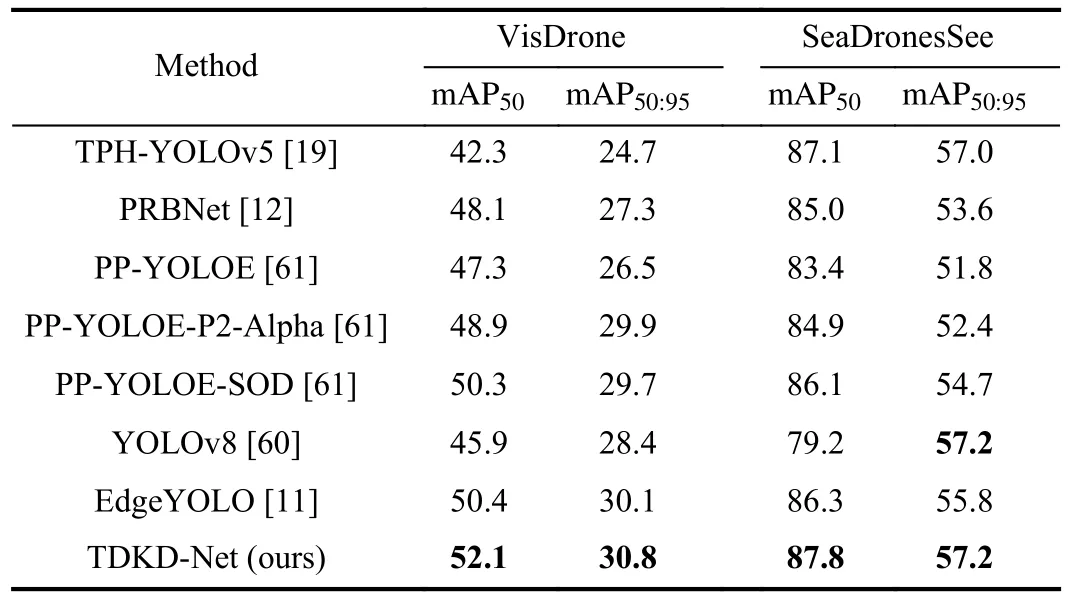
TABLE III COMPARISON WITH STATE-OF-THE-ART UAV-BASED DETECTION ALGORITHMS ON VISDRONE AND SEADRONESSEE VALIDATION SETS
C. Ablation Study
To validate the effectiveness of core components in the proposed TDKD-Net, substantial ablation studies have been conducted, where the VisDrone dataset is adopted for verification.The results are reported in Fig.6 and Table V.It can be seen in Table V, in comparison to baseline model YOLOv7, the mAP50, mAP50:95andRecallhave been improved to a certainextent after introducing the SODH and DA, while leading to a noticeable increase burden in bothParamsandGFLOPs.After the TD method in TT-format is implemented, model size and computational cost of the model have been significantly reduced, resulting in enhanced detection performance compared to the original YOLOv7, while maintaining similar computational complexity.Ulteriorly, the utilization of FEIoU loss function, coupled with KD methods, demonstrates a remarkable capability of higher precision and recall values,which alleviates the performance degradation caused by lowrank approximation of TD, resulting in a 3.2% and 3.7%improvement of mAP50and Recall respectively compared to the baseline model.Furthermore, although the stacking of core components leads to a slight decrease inFPS, the resulting value of 68.03 still meets the real-time detection requirement.This notable enhancements of TDKD-Net highlight the efficacy of employing the methodologies and strategies to capture fine-grained tiny object details and handle challenging UAV-based scenarios, and further excellent performance is gained in terms of recognition and localization with strong robustness.

TABLE IV COMPARISON WITH STATE-OF-THE-ART UAV-BASED DETECTION ALGORITHMS ON VISDRONE VALIDATION SET

Fig.6.Precision-Recall (P-R) curves on VisDrone validation set for developed models.
Moreover, the precision-recall (P-R) curves of six models listed in Table V are further presented in Fig.6, which offers insights into the ability to accurately identify positive instances while capturing all relevant samples.Fig.6 demonstrates that TDKD-Net with the combination of SODH, DA,TD, F-EIoU and KD is able to keep the high value of precision with growing recall, which reflects that our model consistently achieves accurate and comprehensive detection of UAV-based objects across a range of thresholds.
D. Parameter Selection Study
Additionally, in order to select the most suitable parameters for developed TT decomposition and equal-weighted response-based KD scheme of TDKD-Net, two sets of experiments are carried out to further analyze the impact of hyperparameters in TD and KD, and aid in the selection of the optimal parameter combinations.
1)Rank Selection for TT Decomposition: Firstly, the optimal combination of ranks in TT decomposition is explored,where the range of initializing TT-rank includes [2, 2, 2], [4,4, 4] and [6, 6, 6].From the results of Table VI and Fig.7,when using the setting of [6, 6, 6] for TT-rank, the compression rate of 86.15 times is achieved in the selected layers, and the overallParamsis decreased by 2.697 M at the cost of only 0.3% loss for mAP50and mAP50:95.While the TT-rank is set to [2, 2, 2] and [4, 4, 4], inconspicuous parameter reduction is brought to TDKD-Net, but the information transmission is blocked at the expense of an unacceptable decrease in precision.Considering that the rank combination of [6, 6, 6]exhibits a substantial reduction in model parameter count with minimal compromise in accuracy, while lower ranks prove less advantageous, the rank of [6, 6, 6] has been adopted by TDKD-Net.
It can be concluded that a lower rank corresponds to the decreased parameters and worse precision, and this is because the rank determines the number of latent factors or components used to represent the tensor data.Conversely, by employing a higher rank in TT decomposition, the complex relationships and structures of tensors can be captured with more accurate representation, while potentially resulting in increased memory requirements.Therefore, the selection of TD rank is crucial, which involves a trade-off between model performance and parameter efficiency.
2)Parameter Configurations for KD Methods: For the implementation of equal-weighted response-based KD mechanism, where the larger input size and width channel used for the teacher model are studied, and further applied for KD process.As shown in Table VII and Fig.8, the term “Student”refers to the student framework obtained by removing KD scheme from TDKD-Net, “T-1.25Input size” denotes the teacher network obtained by increasing the resolution of the student’s input images by 1.25 times, and meanwhile “TS-1.25Input size” represents the new model obtained by KD training on the student framework with the guidance of the teacher network.Similarly, “TS-1.5Width channel” is the new model through KD, where the teacher network is generated by enlarging the number of channels in convolution operations(model width) by 1.5 times.
From the results of Table VII and Fig.8, it can be observed that utilizing a larger LAA image resolution in the teacher network facilitates the transfer of richer prior knowledge to the student model, but the corresponding performance improvement is marginal.By increasing the model width to obtain theteacher network and further conducting KD training, the resulting new model exhibits an improvement of 0.2% in mAP50:95and 1.0% inRecall, while reducing the parameter counts by 42.848 M compared to the teacher network.These findings demonstrate the effectiveness and robustness of employing the teacher network obtained through channel expansion for the KD process.Furthermore, the proposed KD achieves considerable recognition performance without increasing the parameters, showcasing the capacity to enhance robustness and generalization for LAA-based detection tasks.
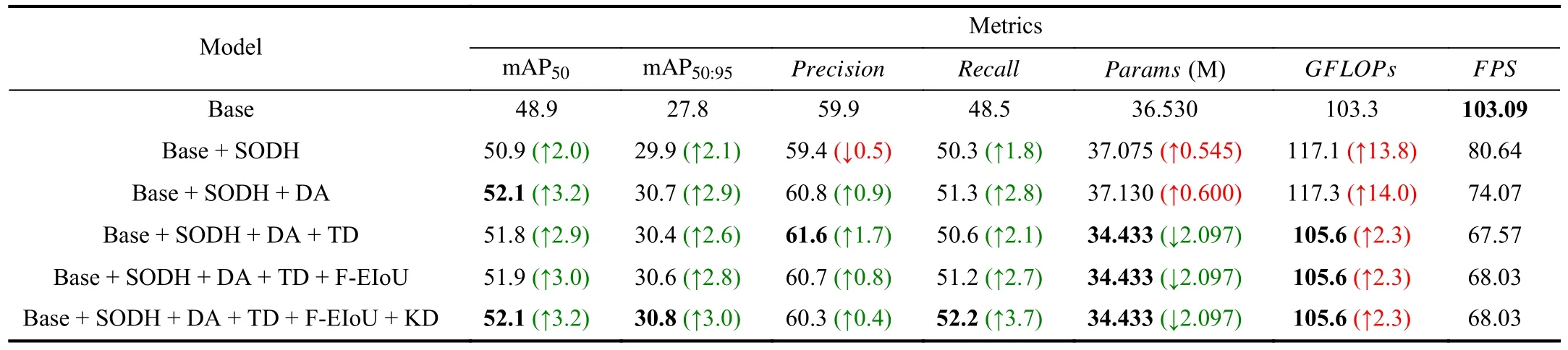
TABLE V ABLATION STUDIES OF TDKD-NET ON VISDRONE VALIDATION SET

TABLE VI TENSOR DECOMPOSITION IN DIFFERENT CONFIGURATIONS OF TDKD-NET ON VISDRONE VALIDATION SET

TABLE VII PERFORMANCE OF TDKD-NET WITH DIFFERENT KD CONFIGURATIONS ON VISDRONE VALIDATION SET
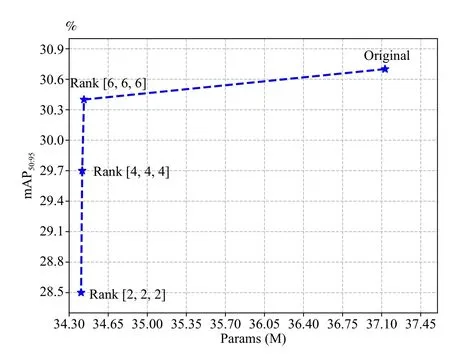
Fig.7.Different TT-rank combinations of TDKD-Net on VisDrone validation set.
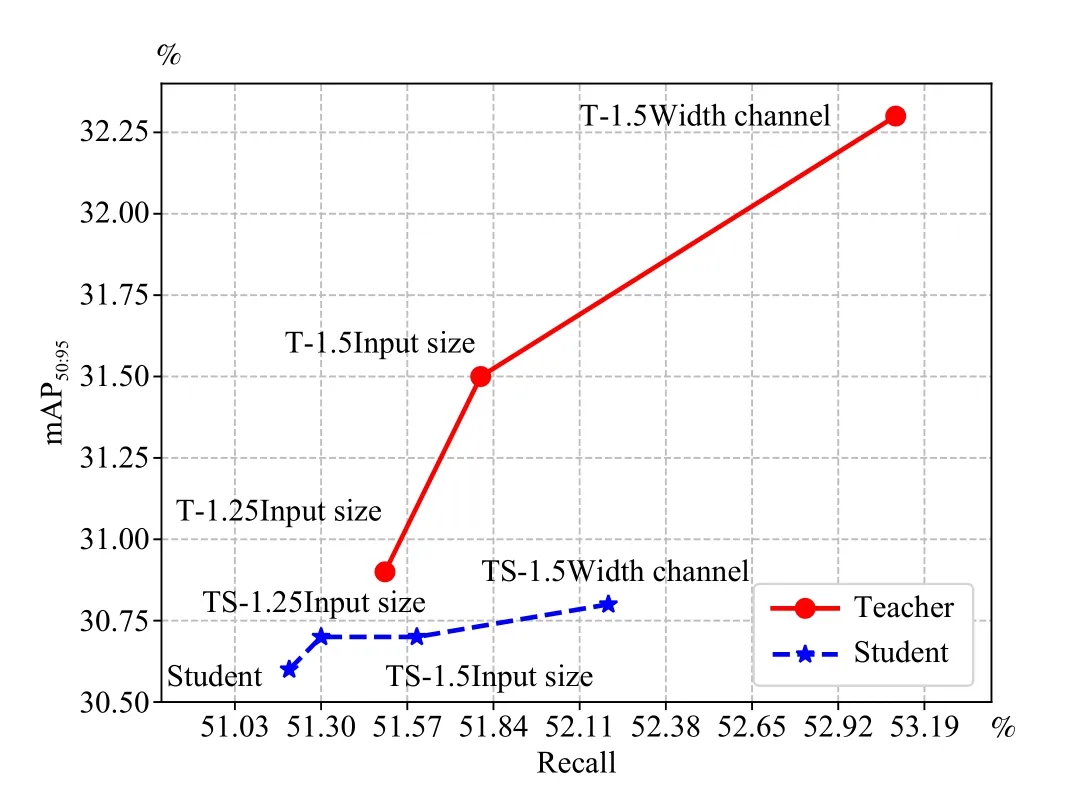
Fig.8.The P-R curves of TDKD-Net in different KD configurations on VisDrone validation set.
V.CONCLUSION
In this article, a novel TDKD-Net has been put forward for the detection of LAA objects, which aims to achieve an efficient trade-off between recognition accuracy and model size,catering to the practical deployment requirements of UAVs.In the proposed TDKD-Net, a TT-format tensor decomposition has been designed to extract the compact yet informative representations from high-dimensional input data; the equalweighted response-based KD scheme has been developed to distill the knowledge from sophisticated teacher model to a compact student model with comparable performance.Meanwhile, based on the YOLOv7 framework, the aforementioned principles are incorporated, and further enhancements are developed, including SODH, DA mechanism and F-EIoUOTA.These modifications make TDKD-Net selectively focus on salient regions and crucial information of small-sized targets, thereby improving the recognition and localization precision for LAA objects, which makes TDKD-Net selectively focus on salient regions and crucial information of small-sized targets, thereby improving the recognition and localization precision for LAA objects.
The proposed TDKD-Net has been evaluated on four challenging datasets, and the obtained results show the effectiveness and superiority of our method, which also exhibits the potential of TDKD-Net for the real-world UAVs-based applications.In future, it is promising to 1) study the more efficient lightweight algorithms based on TD, KD and pruning with less model size and training time; 2) investigate the impact of virtual image generation on the performance of TDKD-Net; 3) explore neural network architecture search and the particle swarm optimization (PSO)-based automatic hyperparameter tuning methods [63], [64].
 IEEE/CAA Journal of Automatica Sinica2024年2期
IEEE/CAA Journal of Automatica Sinica2024年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Reinforcement Learning in Process Industries:Review and Perspective
- Communication Resource-Efficient Vehicle Platooning Control With Various Spacing Policies
- Virtual Power Plants for Grid Resilience: A Concise Overview of Research and Applications
- Equilibrium Strategy of the Pursuit-Evasion Game in Three-Dimensional Space
- Robust Distributed Model Predictive Control for Formation Tracking of Nonholonomic Vehicles
- Stabilization With Prescribed Instant via Lyapunov Method