
基于GIS与递归算法的水库移民安置自适应选址方法
2024-02-29 00:55肖超
水利技术监督 2024年2期
肖 超
(贵州省水利投资(集团)有限责任公司,贵州 贵阳 550001)
0 引言
自改革开放以来,我国水利水电事业取得迅猛发展,以长江三峡、南水北调等工程为代表的水利水电项目,不仅改善了我国区域结构性缺水的现象,而且有利于推动我国社会经济的高速增长。但是,由于水利水电工程涉及范围较广,在工程发挥巨大的社会效益的同时,无法避免为附近居民带来严重影响,水库不仅淹没了附近耕地,甚至会损坏居民房屋,所以在我国水利水电工程建设中,水库移民安置至关重要,水库移民安置区的选址直接关系到水利水电工程效益的发挥程度。在选址问题上,国内外众多学者在工业布局、设备设施选址等不同行业与领域纷纷展开了相关研究,费香泽等人[1]在抽水蓄能电站上下水库选址中引入了卫星遥感地形数据,提升了选址工作的效率;韩文军[2]等人将排序学习技术应用于城市设施选址中,提升了选址的质量;马国普等人[3]利用分支定界算法设计一种突发事件应急救援点和安置点协同考虑的选址方法,对人员疏散具有重要作用。一般来说,水库移民安置选址是一项融合社会、环境等众多因素的复杂工程,本文旨在推动我国水利水电事业的健康发展,设计一种水库移民安置自适应选址方法。
1 基于GIS获取水库移民安置区信息
一般来说,在进行水库移民安置选址时,必须掌握移民安置区的土地利用情况、地形地貌等基础信息[4],所以本文引入了GIS技术[5],该技术具有强大的空间分析与数据管理能力,可以为水库移民安置选址提供所需的空间与非空间数据等。首先通过GIS软件采集水库移民安置区的交通道路网络、街道等空间数据,以AutoCAD的dwg文件格式进行存储,并采集人口分布、人口密度等非空间数据,通过数据表的形式和空间数据一一对应。然后对水库移民安置区信息的空间数据进行预处理,主要包括格式转化和提炼操作,其中格式转化就是将原始采集水库移民安置区空间数据由地图形式转化为数字形式。关于数据提炼,就是从众多水库移民安置区信息中提取后续选址所需的影响因素数据[6],结合水库移民安置选址的实际情况,本文将选址影响因素大致分为生产生活、自然环境、基础设施以及社会条件这几类关键因素,在进行影响因素数据的提取时,需要通过排序倒数法获取各个因素的权值,也就是先利用影响因素的重要性系数对各因素进行排序,表达式如下所示:
ε=∑100(ph)/5
(1)
式中,ε—水库移民安置区选址影响因素的重要性系数;p—影响因素的评分;h—影响因素的序号。根据式(1)分别求出上述影响因素的重要性系数,再按照从大到小的顺序进行排序,完成排序后,即可获取各影响因素的权值,计算公式如下所示:
(2)
式中,Zi—水库移民安置区选址影响因素归一化处理后的权重值;hi—第i个影响因素的序号;N—影响因素的数量。根据式(2)所求权值,对GIS软件中采集的原始安置区信息数据进行属性赋值,并将与选址无关的数据剔除,从而提取到有用的水库移民安置区信息数据,作为选址基础数据。
2 构建水库移民安置区选址模型
通过分析文中上述内容所获取的水库移民安置区选址影响因素,本文决定将各影响因素转化为能够定量计算的优化目标,以此构建多目标的水库移民安置区选址模型[7]。首先考虑水库移民安置工程的成本、经济效益等因素,需要在符合相关规范的前提下,最大限制控制安置区数量并提升1个安置区容纳的人数,所以本文构建的第1个目标函数就是安置区数量最小化目标,表达式如下所示:
(3)
式中,minf1—水库移民安置区数量最小化目标;μi—第i个安置区的重要程度;xi—变量,如果在i点设置安置区,该变量为1,否则为0;I—水库移民安置区的数量。然后,本文构建的第2个目标函数就是容纳人数最大化目标,表达式如下所示:
(4)
式中,maxf2—水库移民安置区容纳人数最大化目标;γi—第i个安置区的占地面积;yij—变量,如果居民原住址j被安置区i所覆盖,则变量为1,否则为0;φij—安置区的覆盖度系数;J—居民原住址地区数量。最后,考虑到安置区周边的生活环境、经济发展等因素,安置区所在位置不应该离居民本身的居住地太远,所以本文构建了下式所示的距离最短化目标函数:
(5)
式中,minf3—水库移民安置区选址距离最短化目标;dij—居民原住址j与安置区i之间的距离。综上,本文构建的多目标水库移民安置自适应选址模型[8]表达式为:
f=minf1+maxf2+minf3
(6)
式中,f—多目标水库移民安置自适应选址模型。如上述内容所示,本文通过线性加权的方法,构建了多目标的水库移民安置自适应选址模型,将水库移民安置选址问题转化为优化求解问题,促使实际安置区的选址更加科学合理。
3 递归算法确定水库移民安置区位置
在实际的水库移民安置选址模型求解过程中,由于选址影响因素较多,模型求解较为困难,传统寻优算法很容易陷入局部最优,所以本文引入了递归算法对文中上述内容构建的多目标水库移民安置区选址模型进行求解,从而获得最佳选址方案[9]。递归算法就是将原始复杂的求解问题转换为同类简单的子问题进行求解,简单来说就是“自己调用自己”,所以在进行水库移民安置选址时,引入递归算法不仅可以提升模型求解速率,而且可以保障最优解的自适应性,具体流程如图1所示。
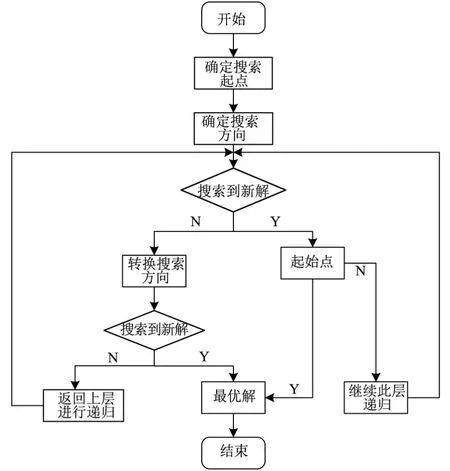
图1 递归算法求解水库移民安置选址模型流程
在利用递归算法求解多目标的水库移民安置选址模型时[10],主要分为递推与回归2个步骤:①递推就是在确定模型解空间的搜索起点与搜索方向时,依次调用函数对模型各个节点进行搜索求解,在此过程可以清楚呈现模型解的搜索顺序;②回归就是当递推搜索结果不满足要求时,可以返回上1层调用函数,对模型解空间进行重新搜索,直至跳出函数停止算法搜索过程中,将此时求得结果输出,得到水库移民安置自适应选址方案[11]。因此,本文求解目标水库移民安置选址模型时,将原始较为复杂的大型问题转化为规模较小的问题依次进行求解,这样输出的模型最优解为全局最优解,且具有较高的自适应性,最后根据输出方案即可确定水库移民安置区的位置[12]。
4 实例分析
4.1 研究区概况
本章以某水利枢纽工程为研究对象,从定量角度对设计水库移民安置自适应选址方法进行实例分析。该水利枢纽工程是某城市建设的重点水利工程之一,距下游村庄约80km,主要以防洪、发电为主要功能。工程包含了重力坝、泄水闸、船闸等建筑物,最大坝高达24.2m,坝顶全长1296m,受坝区淹没影响的有周边3个县区的12个乡镇,所以本次水库移民安置计划涉及拆迁房屋面积约86.5万m2、村民约1万余人。本文结合该水利工程的实际情况,通过文中设计方法进行水库移民安置区的选址,最终得到安置区选址结果见表1。
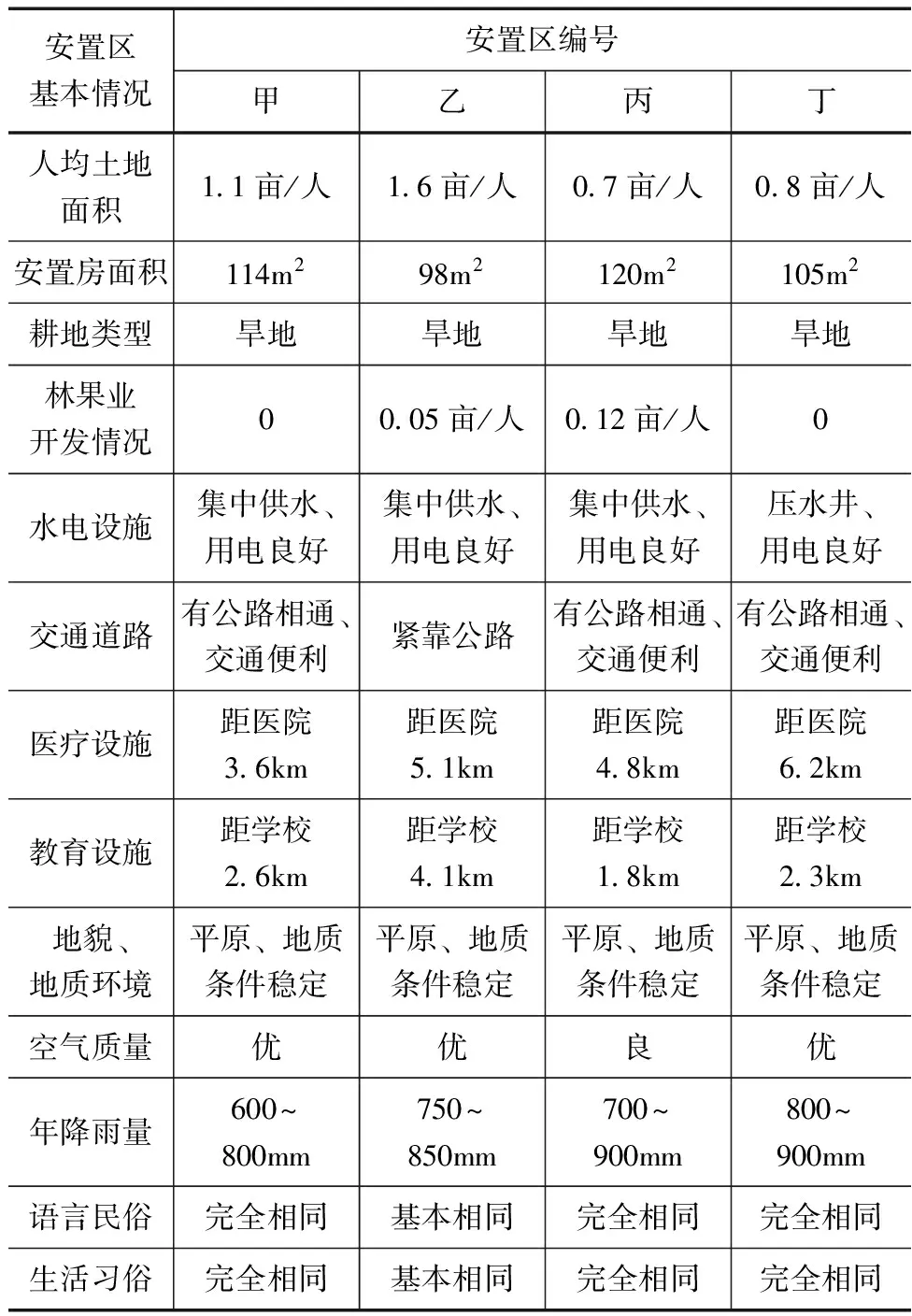
表1 水库移民安置区选址结果
在本文设计方法下,该水库移民安置区最终选择了上表所示的甲、乙、丙、丁这4个安置点,根据实地调查得到的各安置点基本资料显示,这4个安置点可以满足居民的生产与生活需求。
4.2 结果分析
为定量分析实例水库移民安置区的选址结果,本章对上述安置点进行适宜性评价,首先选取适宜性评价指标与权重见表2。
在上表所示数据的基础上,借助ArcGIS软件即可求出各安置区的适宜性综合分值,计算公式如下所示:
(7)
式中,Pi—水库移民安置区第i个一级指标的综合分值;Fij—第i个一级指标中的第j个二级指标的量化分值;ωj—第j个二级指标的权值;n—二级指标的数量。与此同时,本文利用ArcGIS软件中的自然断点法对安置区适宜性进行分级,由高至低依次分为Ⅰ级(适宜)、Ⅱ级(比较适宜)、Ⅲ级(基本适宜)、Ⅳ级(不适宜)。针对研究区的实际数据,所得具体评价结果见表3。
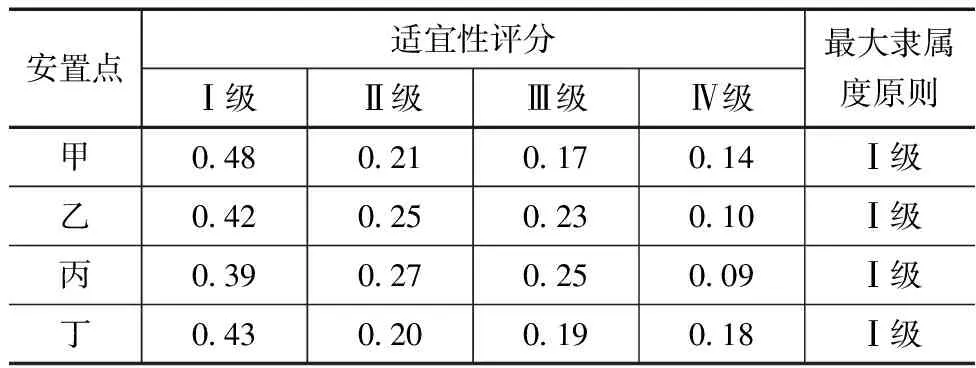
表3 水库移民安置区适宜性评价结果
从上表中数据可以看出,各水库移民安置区的适宜性均处于Ⅰ级,说明本文设计选址方法在理论与实践上都是可行的,可以解决水库移民安置选址问题,且所得选址结果良好。
5 结语
综上所述,本文依据水库移民安置是一项涉及重大民生的复杂性工程,所面临问题众多,尤其是选址问题较为突出,选址结果直接关系到整个水库移民安置工程的效益。基于此,本文提出一种基于GIS与递归算法的水库移民安置自适应选址方法,通过GIS技术获取了水库移民安置区的相关信息,在此基础上构建了多目标优化的选址模型,然后再利用递归算法求解模型即可获得最佳的选址方案。同时,本文依托实际项目,对设计方法下所得选址结果的适宜性进行了定量评价,根据评价结果证明了设计方法的有效性与正确性,解决水库移民安置选址问题,选址结果良好,可为我国水利水电工程提供相关技术参考。
猜你喜欢
三峡大学学报(自然科学版)(2023年3期)2023-05-08
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
侨园(2016年8期)2017-01-15
水利科技与经济(2016年2期)2016-04-21
测绘科学与工程(2016年4期)2016-04-17
留学(2015年12期)2015-12-19
湖南水利水电(2014年1期)2014-02-27
测绘科学与工程(2014年2期)2014-02-27
