
汽车故障知识图谱构建及应用研究
2024-02-29 06:28李先旺黄忠祥贺德强刘赛虎秦学敬
科学技术与工程 2024年4期
李先旺, 黄忠祥, 贺德强, 刘赛虎, 秦学敬
(广西大学机械工程学院, 南宁 530004)
汽车维修领域存在大量的文本数据,这些数据蕴含丰富的信息,且多数以非结构化文本的形式散落在各处,没得到统一的组织与管理,造成了知识的浪费。如何根据故障现象快速从海量文本数据中找到故障原因与解决方法,并构建一个完整的面向汽车故障诊断的知识体系是一个亟待解决的问题。
知识图谱是有效的知识集成方法之一,它能形式化地描述现实世界的事物及其相互关系[1],从而促进对其所包含信息的管理与使用。知识图谱目前已被应用在多个领域,如医疗[2]、制造[3]和公共交通[4]等领域,而针对汽车维修领域的知识图谱也有部分学者进行了研究。赵祥龙[5]基于规则进行知识抽取,在构建的车辆故障知识图谱基础上通过XGBoost分类算法实现了故障原因的推荐应用。但基于规则的方法存在召回率底、冲突性高的缺点。葛任贤[6]基于汽车故障案例,使用正则表示式进行知识抽取,构建汽车故障事理图谱。但知识抽取过于依赖人工和专家经验,自动化程度不高。徐成现[7]通过将注意力机制与BiLSTM-CRF(bidirectional long short-term memory-conditional random field)模型相结合对发动机维修案例进行知识抽取,构建发动机故障维修知识图谱,并以关键词和人工制定规则的方式进行映射实现故障知识的查询。但未能实现嵌套实体的识别,此外故障搜索依赖模板库或关键词库,后期维护困难。
命名实体识别(named entity recognition,NER)指将预定义类别的实体从非结构化文本中识别出来,为知识图谱构建、智能问答等下游任务的开展奠定基础[8]。因此提高实体识别效果十分重要。BiLSTM-CRF常作为基线模型用于中文实体识别[9],但该模型不能解决实体嵌套问题。Li等[10]提出将嵌套NER任务转化成机器阅读理解(machine reading comprehension,MRC)任务来解决,通过构建相应问题识别不同类型实体,使用单层指针网络识别实体边界,但该方法用两个模块分别识别实体的首尾,将导致训练和预测不一致。为此,Su等[11]提出全局指针(gloabal pointer, GP),该框架将实体首尾视为整体进行判别,能实现训练与预测的一致性。
首先,汽车维修文本具有领域专业性,实体结构较为复杂,存在大量实体嵌套的情况,如“发动机无法启动”是个故障现象实体,其内嵌套着“发动机”这个部件实体,因此其实体边界较难确定。其次,该领域缺乏成熟的公开数据集,只能人工标注小规模的领域数据集。预训练语言模型BERT (bidirectional encoder representation from transformers)[12]使用大规模的语料进行预训练,具有通用的语言表征能力,无需从零开始训练字符向量,只需在后续的任务中通过少量标注语料进行微调就可得到动态的字符向量,但其采用的是字级掩码机制,因此模型在处理中文时难以获得词级特征。RoBERTa-wwm(a robustly optimized BERT pre-training approach-whole word masking)[13]增加了全词掩码机制,中文语义表示能力更强。Jiang等[14]研究发现,专业领域的数据集规模较小,模型在训练中很容易发生过拟合,进而影响模型的表现。
针对汽车维修文本实体边界难确定、实体嵌套和数据集规模较小的问题,为全局指针引入中文分词,并进一步提出引入中文分词的嵌套实体识别模型AT-RWSGP (nested named entity recognition using adversarial training and RoBERTa-wwm in the word segmentation GlobalPointer frame),以提高嵌套实体识别效果。在构建汽车故障知识图谱后,实现基于知识图谱的汽车维修知识问答原型系统,展示知识图谱技术在汽车维修领域的应用前景。该系统为维修人员进行汽车故障排查提供了故障知识问答和图谱可视化功能,为辅助维修人员对汽车进行故障排查提供了理论参考和技术支撑。
1 汽车故障知识图谱构建流程及本体构建
1.1 汽车故障知识图谱构建流程
知识图谱就覆盖范围可分为通用知识图谱和领域知识图谱[15],而知识图谱的构建方式可分为自底向上构建和自顶向下构建[16]。一般而言,自底向上构建方式更合适于覆盖范围广泛的通用知识图谱,此类图谱常用于搜索、推荐以及问答等。汽车故障知识图谱是一个典型的领域知识图谱,此类图谱需要根据领域业务需求,构建出合适的本体模式,确定实体与关系的类型。所设计的汽车故障知识图谱构建流程如图1所示,包括数据层、构建层和应用层。
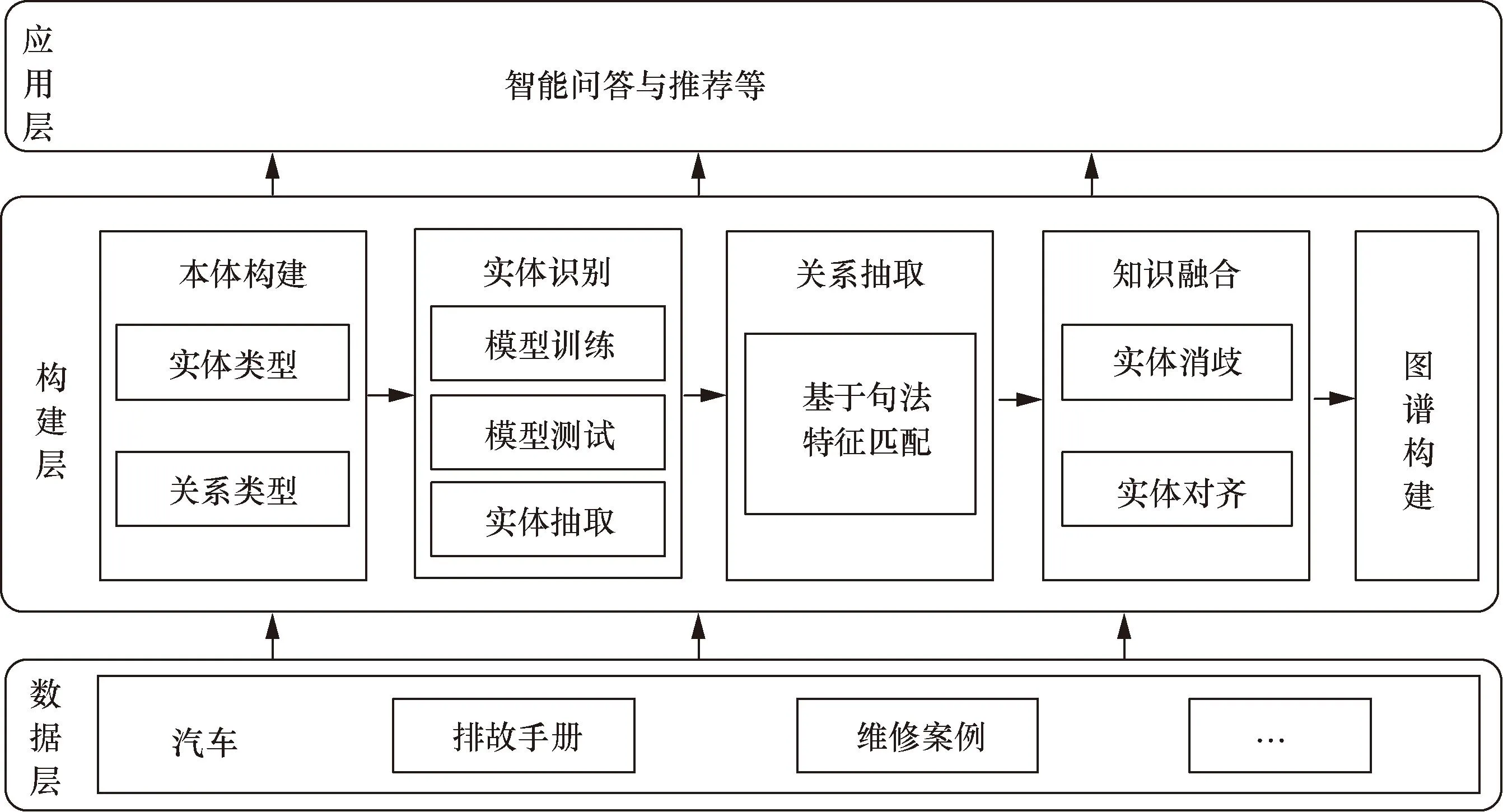
图1 汽车故障知识图谱构建框架图Fig.1 Frame chart of building automobile fault knowledge graph
图1中,数据层为汽车故障知识的数据来源,这些数据作为汽车故障实体和关系的基础语料。构建层的工作包括确定实体与关系的类型,然后将预定义好的实体和关系从多源异构的文本数据中抽取出来,并进行知识融合,最后根据构建的本体模式将知识三元组存储到知识库中。应用层则是将构建好的汽车故障知识图谱应用到汽车故障诊断业务中,包括智能问答与推荐等。
1.2 本体构建
领域知识图谱本体的构建,需要结合专家知识进行,规范好实体和关系的类型才能保证从文本中抽取出正确的知识。针对汽车故障知识图谱,其数据来源主要是维修手册和汽车维修案例等,而此类数据则主要包括品牌车型、故障现象、故障原因以及零部件等实体,具体实体和关系类型如图2所示。
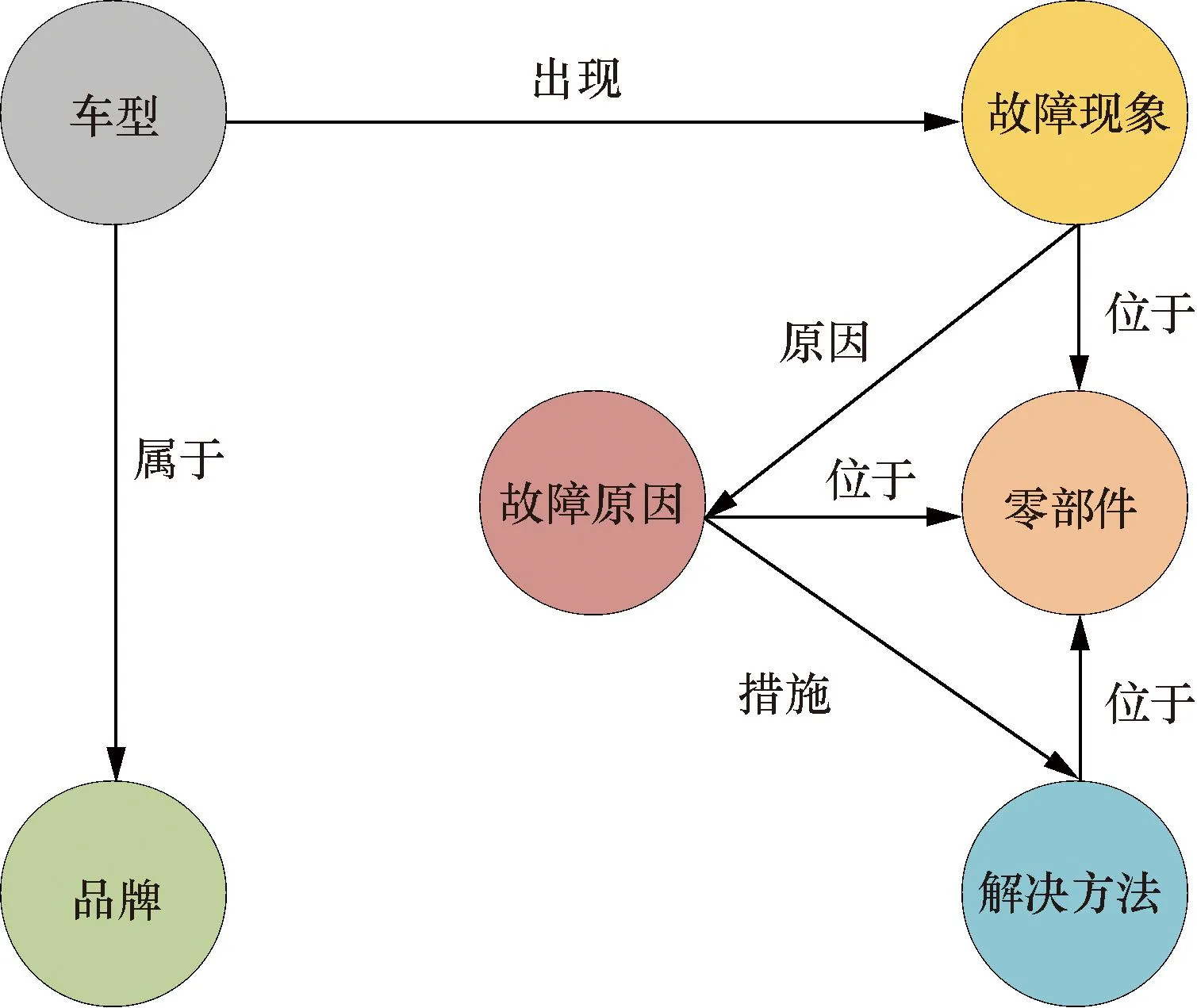
图2 汽车故障知识图谱模式层设计Fig.2 Design of pattern layer of automobile fault knowledge graph
2 AT-RWSGP模型
所提AT-RWSGP模型架构如图3所示,该模型包括三层,分别是RoBERTa-wwm嵌入层、对抗训练和WSGP(word segmentation global pointer)解码层。首先将字符序列输入到RoBERTa-wwm中获取字符编码;然后在RoBERTa-wwm后接对抗训练层,对嵌入层加入小扰动,然后一起送到WSGP中识别实体的边界并进行分类。
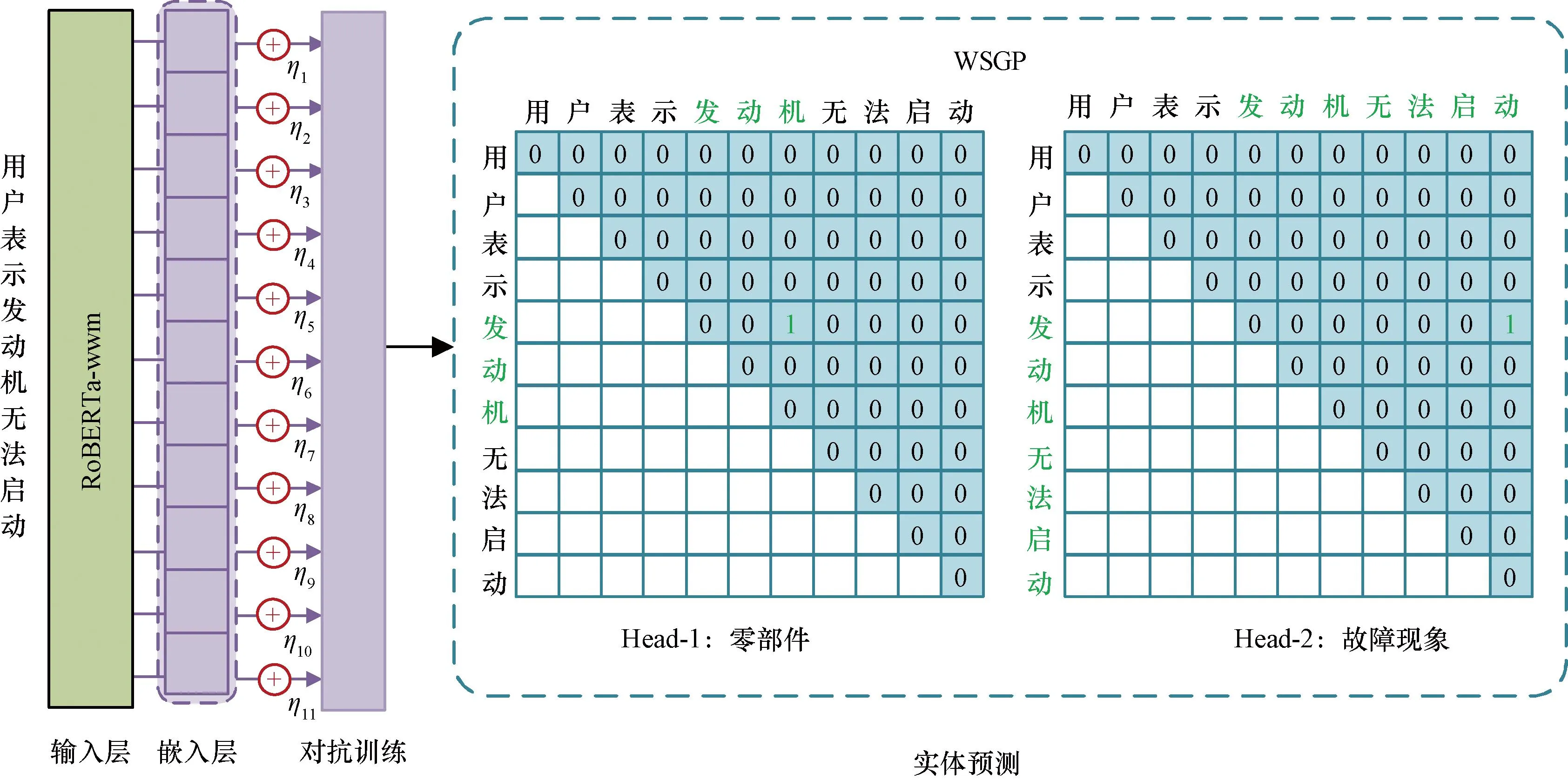
图3 AT-RWSGP模型结构图Fig.3 AT-RWSGP model structure diagram
2.1 RoBERTa-wwm嵌入层
RoBERTa-wwm预训练模型是哈工大讯飞联合实验室提出,其采用了中文全词掩码技术,如图4所示。通过全词掩码技术,RoBERTa-wwm可以在训练的时候学到词级别的语义表示,有助于提高汽车维修领域文本的实体识别效果。

图4 RoBERTa-wwm的全词掩码示例Fig.4 Example of whole word masking for RoBERta-wwm
RoBERTa-wwm结构图如图5所示,将输入的句子定义为s= {x1,x2, …,xn},其中xi为序列的第i个字,i=1,2,…,n。在句子开头加上分类符([CLS]),在句尾处添上分割符([SEP]),经由RoBERTa-wwm处理,得到句子s的向量表示E,E= [E1,E2, …,En]。
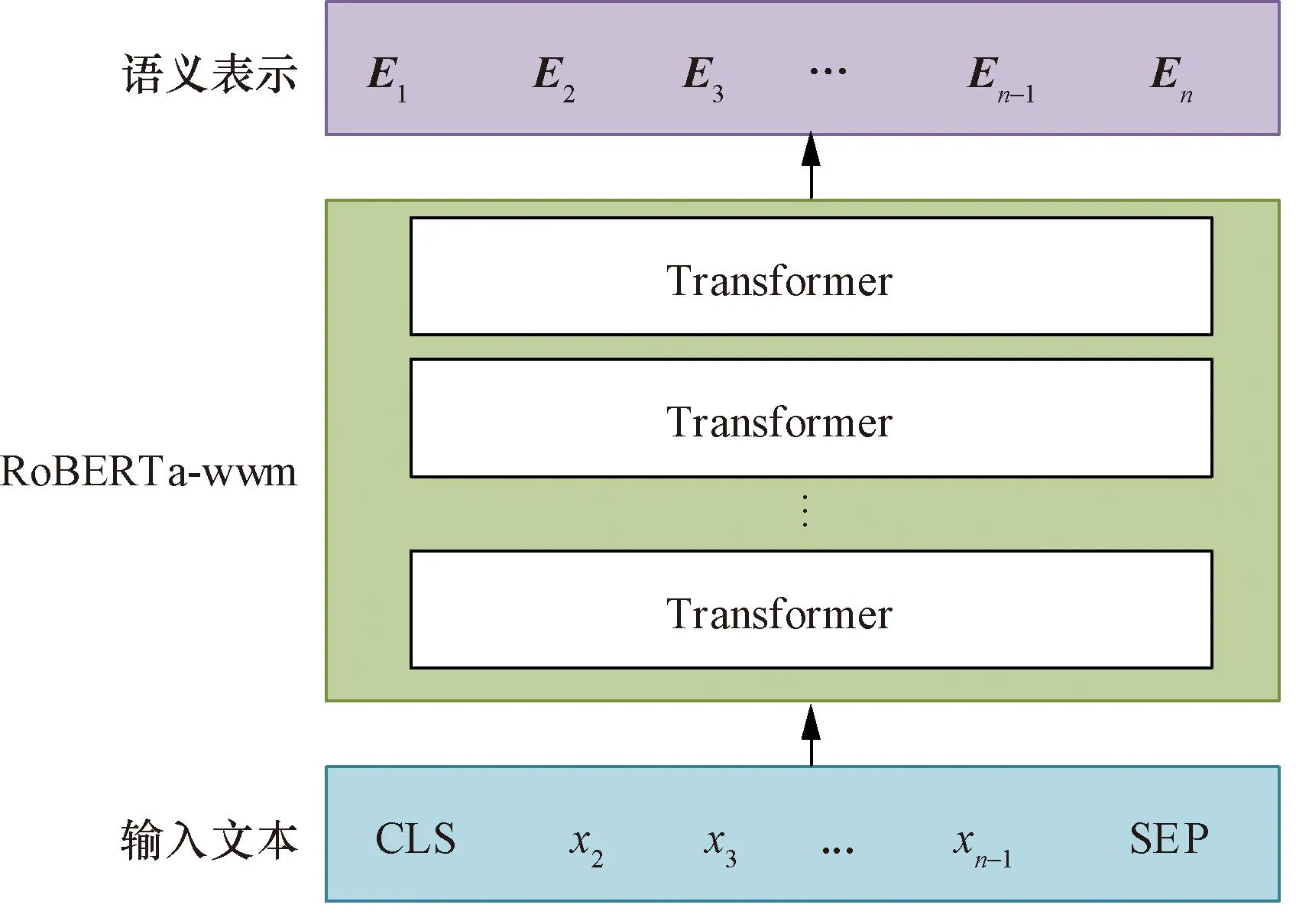
图5 RoBERTa-wwm结构图Fig.5 Structure Diagram of RoBERTa-wwm
2.2 对抗训练层
对抗训练的思想是直接在模型的向量表示层加入微小的扰动以生成对抗样本,然后再用对抗样本进行训练,借此提升模型的鲁棒性。由于FGM (fast gradient method)[17]方法兼顾了性能和效率,因此采用FGM方法来计算扰动。
FGM采用的方法是L2归一化,即将梯度的每个维度的值除以梯度的L2范数。扰动radv的计算公式为
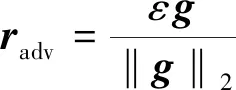
(1)
g=▽EL(E;θ)
(2)
式中:g为梯度,‖g‖2为g的L2范数;ε为超参数;L(E;θ)为损失函数;θ为模型参数。
2.3 WSGP解码层
GP通过构造一个上三角矩阵来遍历所有有效的实体边界,每一个格子对应一个实体边界,不同的矩阵表示不同类型的实体。
经过对抗训练层,添加小扰动后,得到编码向量序列[h1,h2, …,hn]。然后将每个token的编码向量放入两个线性层“start_FFN”和“end_FFN”,分别得到属于每个实体类别的开始向量和结束向量,其计算公式分别为
qi=Wqhi+bq
(3)
ki=Wkhi+bk
(4)
式中:hi为向量序列;qi、ki分别为开始和结束向量;Wq、Wk为变换矩阵;bq、bk为权重偏移指数。
为了方便推导,将省略式(3)和式(4)的偏置项。
GP将实体抽取分为两个阶段,即先判断某个token-pair是否是实体,然后再对实体进行分类。通过式(5) 计算跨度从i到j连续片段是一个类型为的实体的分数。
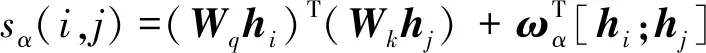
(5)
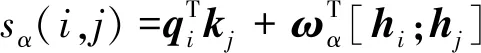
(6)
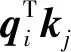
为了减少参数,可进一步将hi表示为[qi;ki],则式(6)可转化为式(7)。
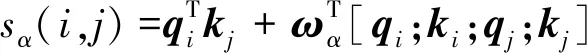
(7)
对于不同的实体类别,通过式(7)可以得到每个span[i:j]的分数sα(i,j),最后的任务就是从n(n+1)/2个候选实体中,选出k个真实的实体,该问题是个多标签分类问题。损失函数的计算公式为
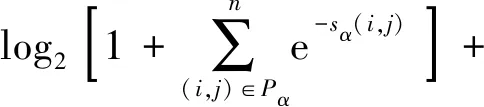
(8)
式(8)中:Pα为所有实体类型为α的span集合;Qα为非α实体类型的span集合,i≤j。
在解码阶段,只有满足sα(i,j) >0的片段才会被视为α类型的实体,并输出。log以2为底。
2.3.1 改进思路
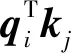
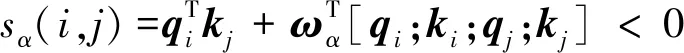
(9)
2.3.2 方法
使用开源中文分词工具jieba来获取文本的分词标签,将句子进行尽可能细粒度的分词。例如存在短句“诊断为电机控制器故障”。基于细粒度的分词会输出:[诊断][为][电机][控制器][故障],对应的词列表word_list为[(0,1), (2, 2), (3, 4), (5, 7), (8, 9)],数字代表索引位置,从0开始。然后通过递归的方式不断对相邻词进行组合从而生成:[诊断][诊断为][电机控制][控制器][电机控制器][电机控制器故障]等,递归的尽头是改句子本身,从而得到中文分词的真实标签seg_labels。seg_labels可视化如图6所示。
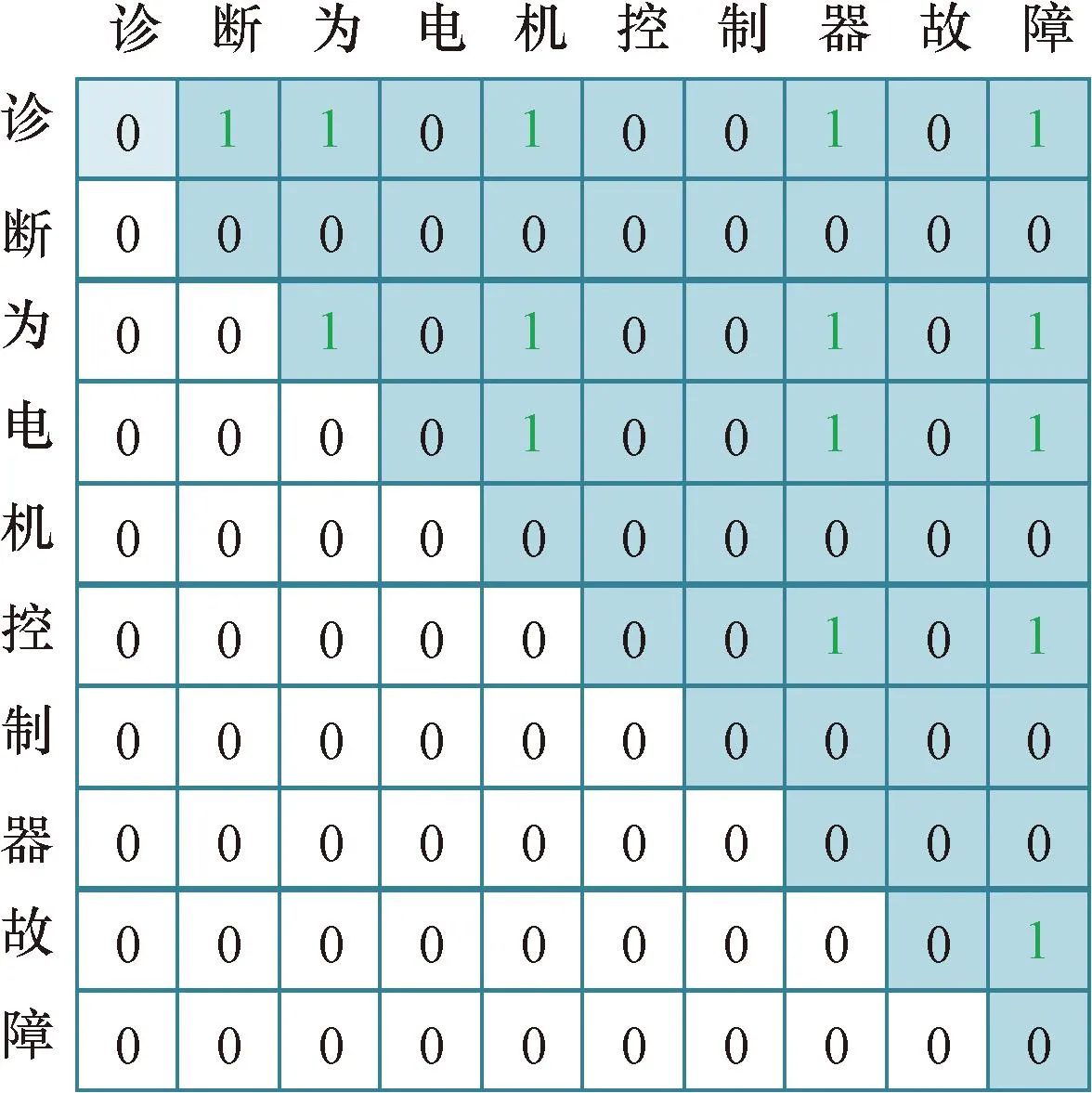
图6 seg_labels可视化Fig.6 seg_labels visualization
最后,将中文分词的真实标签引入损失函数的计算,式(10)为原版GP的损失函数计算公式,式(12)为引入分词信息后的损失函数计算公式。
loss1=loss_fc(all_logits,labels)
(10)
loss2=βloss_fc(logits,seg_labels)
(11)
loss=loss1+loss2
(12)
3 知识融合
从非结构化的汽车维修文本中抽取的故障知识极大概率存在数据语义重复、质量不一的问题,知识融合可以将冲突的知识进行融合,以实现知识表示的统一,进而构建高质量的知识图谱[18]。知识融合包括两方面内容,分别是实体消歧和实体对齐[19]。
实体消歧技术旨在解决同名不同意的实体问题,因为语料均为汽车领域文本,因此基本不存在该问题。实体对齐技术则是解决同意不同名的实体问题。例如,“发动机控制模块”和“发动机控制器”均表示“发动机控制单元”这个实体。人工撰写的故障维修报告大量存在这种用语不规范、不统一的情况,因此需要对知识进行规范化表示。
采用计算相似度的方法进行实体对齐,预先设置好阈值,将实体间相似度大于设置阈值的实体进行融合,并将二者统一存入同义词实体库,为后续实体链接做准备。采用编辑距离和余弦相似度相结合的方法来计算相似度,任一相似度大于阈值则进行融合。
(1)距离编辑相似度。编辑距离(levenshtein distance)是衡量两个字符串相似程度的常用方法,指两个字串之间,由一个转成另一个所需的最少编辑操作次数。操作方法包括插入、删除或者替换字符[20]。其中插入、删除编辑次数为1,替换编制次数为2。距离编辑相似度则根据式(13)进行计算。
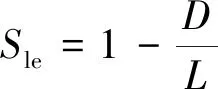
(13)
式(13)中:Sle为距离编辑相似度分数;D为编辑次数;L为两实体总长度。
(2) 余弦相似度。余弦相似度Scos是用来衡量向量空间中的两个向量是否接近、相似,其值越接近1,就表明夹角越接近0°,即两个向量越相似,其计算公式为
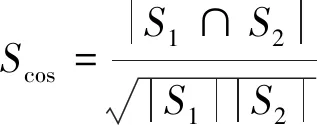
(14)
式(14)中:S1和S2为实体。
Sle、Scos值越大就表示二者相似度越高,表1列出了部分实体相似度计算实例。

表1 实体相似度计算实例Table 1 Example of entity similarity calculation
4 基于知识图谱的智能问答
问答系统的作用是通过将用户使用自然语言提出的问题进行语义解析,转化成结构化的查询语句,进而在知识图谱中找到答案,并将答案返回给用户[21]。因此,对自然问句的语义进行解析是关键的一步。采用的语义解析模块如图7所示。该模块包括3个子模块,分别是实体识别、实体链接以及关系匹配。实体识别模块的作用是识别自然问句中单个或多个关键词,实体链接模块的作用则是将识别到的关键词正确链接到知识图谱中的实体词。关系匹配则是将自然问句中蕴含的关系与知识图谱中的实体间关系进行匹配。
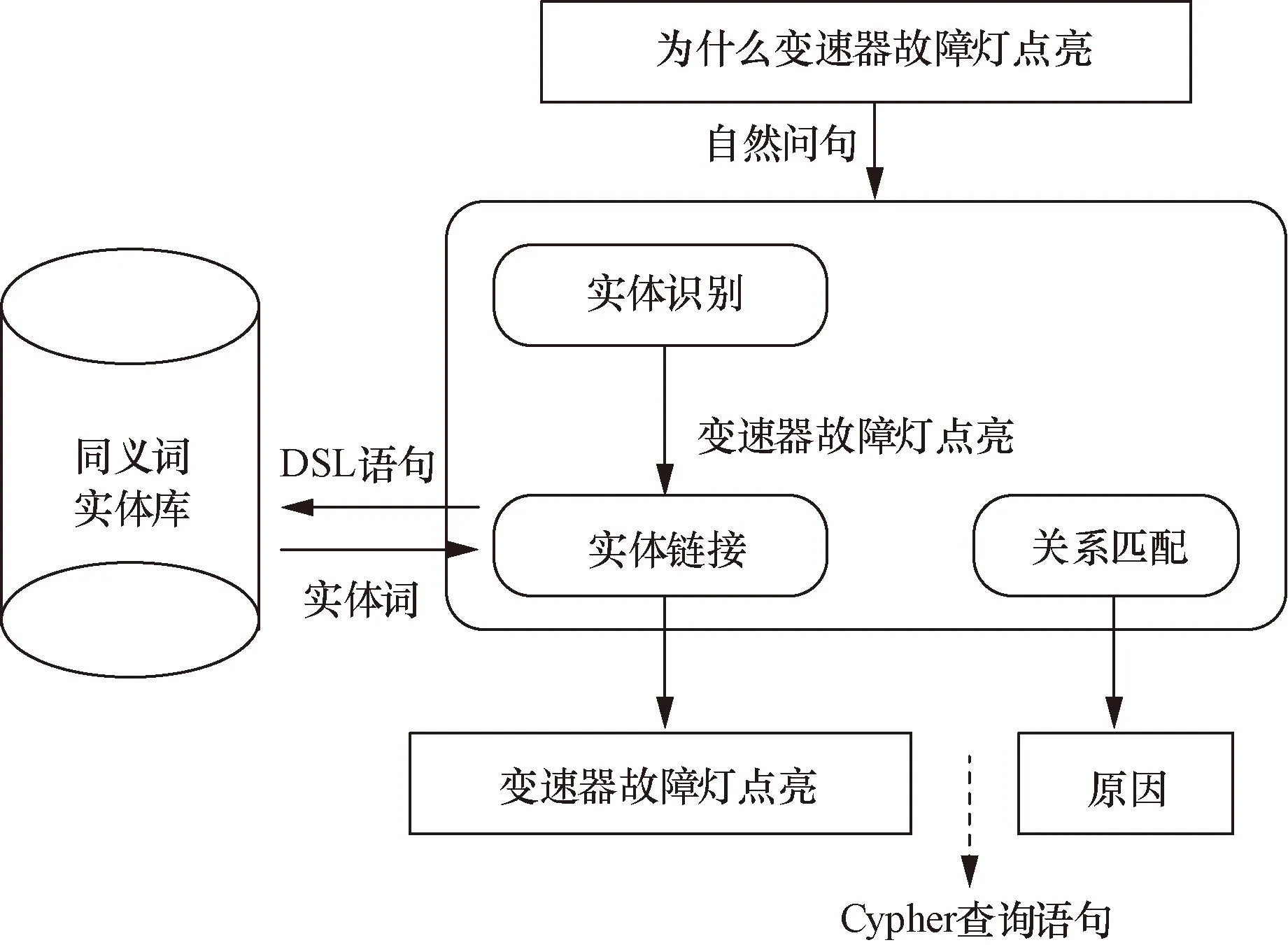
领域特定语言(domain-specific language,DSL)图7 语义解析的流程示意图Fig.7 Schematic diagram of semantic parsing process
4.1 基于Albert-WSGP的实体识别方法
Albert[22]是轻量版的BERT,其利用词嵌入参数因式分解和隐藏层间参数共享技术,在显著减少模型参数量的同时,基本没有损失模型的性能。可见Albert比BERT更适合部署在线上,因此选择Albert获取字符的上下文表示。解码层则依然使用WSGP,因为其可以无差别识别普通实体和嵌套实体,并且较CRF效率更高、速度更快。
4.2 基于字匹配的实体链接方法
在具体的业务场景下,用户表达具有多样性,为提高答案的正确率,需要通过实体链接将实体提及与知识图谱中的实体词进行关联。采用第三节中构建的同义实体库进行实体链接,并以字匹配的方式链接,为提高匹配的准确性,加权实体间相似度和实体与问句相似度,计算公式为
(15)
式(15)中:X为同义词库检索的候选实体词;Y为实体提及;S为自然问句;α、β为参数,分别取0.8和0.2;X∩Y表示X与Y的公共字符;|·|为字符数量。
计算候选实体词的分数并按照降序排序,选择得分最大的实体词。
4.3 基于Albert的关系匹配
在知识图谱中准确找到实体后,可以根据该实体匹配关系。若该实体词的关系存在与自然问句意图一致的关系,则基于实体词及关系输出对应的答案。采用Albert进行匹配,构造关系数据集对该模型进行训练,将训练好的模型部署到问答系统。该结构如图8所示,模型可简化为式(16)、式(17)。
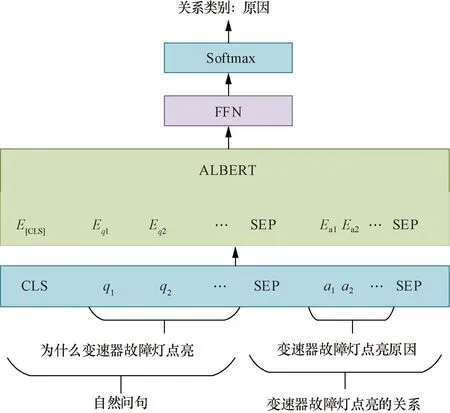
qt为自然问句的字符;at为实体词及其关系的字符;[CLS]用于输入的待匹配文本的语义表示;[SEP]为分隔符;Softmax为归一化指数函数;FNN为全连接层;E[CLS]为[CLS]的字符表示的语义编码图8 关系匹配的模型结构图Fig.8 Model structure diagram of relationship matching
E=Albert([CLS],q1,q2,…,[SEP],
a1,a2,…,[SEP])
(16)
p=Softmax(WeE[CLS]+be)
(17)
式中:qt为自然问句的字符,t=1,2,…;at为实体词及其关系的字符;[CLS]用于输入的待匹配文本的语义表示;[SEP]为分隔符;be为权重偏移指数;使用Albert模型内部的注意力机制进行交互,得到字符的向量表示E;使用Softmax进行分类;We为全连接层FFN的网络参数;E[CLS]为[CLS]的字符表示的语义编码;p为分类结果。
5 实验及知识图谱的创建与应用
5.1 汽车故障数据准备
以爬虫的方式从精通维修网获取汽车维修案例,对获取的案例进行清洗和整理,得到2 000个案例,并对数据进行人工标注,作为实验数据集,取训练集、验证集和测试集的比例为8∶1∶1。实体类别如表2所示,其中故障现象、故障原因以及解决方法实体中嵌套有零部件实体。

表2 汽车故障文本命名实体分类Table 2 Example of entity similarity calculation
5.2 实体环境及实验参数
本实验环境及配置如表3所示。

表3 环境配置Table 3 Environment configuration
5.3 模型评估
实验采用3个评价指标,分别是精确率(precision,记为P)、召回率(recall,记为R)以及P、R的调和平均数F1值(记为F1)[23],计算公式为
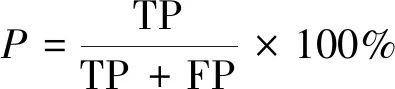
(18)
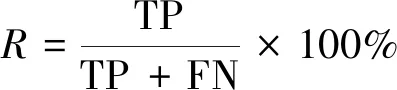
(19)
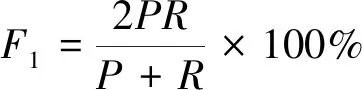
(20)
式中:TP为正确识别的个数;FP为将不正确识别为正确的个数;FN为数据集中存在但未被识别出来的个数。
5.4 实验结果及分析
本实验分析比较了AT-RWSGF模型与BERT-CRF、BERT-MRC、BERT-BinaryPointer(BERT-BP)[24]以及BERT-GP模型在汽车维修数据集上的实体识别效果,其结果如表4所示。
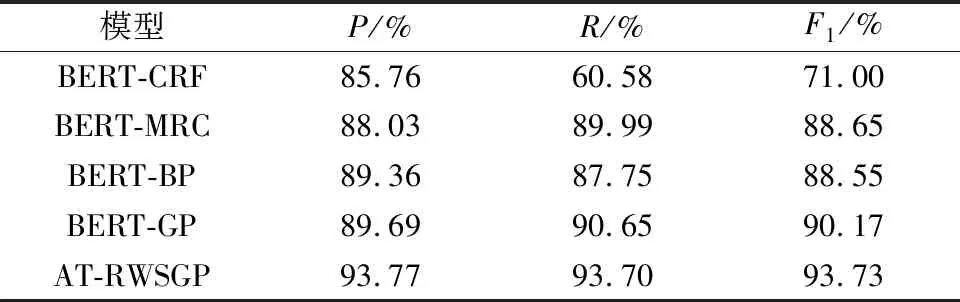
表4 各模型的评价结果Table 4 Evaluation results of each model
从表4可以看出,所提AT-RWSGP模型在汽车维修数据集上取得F1为93.73%的成绩。相对于BERT-GP而言,本文模型F1提高了3.56%。这是因为本文模型将只能字掩码的BERT替换为拥有全词掩码机制的RoBERTa-wwm,提高了模型学习词级表征的能力;其次,本文模型还增加了对抗训练,该举措有助于提高模型的鲁棒性和泛化性;最后,本文模型对GP进行改进,引入中文分词信息,可以提升模型实体识别性能。而基于序列标注的经典模型BERT-CRF表现最差,F1只有71%,说明BERT-CRF模型不适合用于嵌套命名实体识别。
为了评估RoBERTa-wwm、对抗训练模块以及WSGP的有效性,设计如下4组实验进行对比,模型分别为BERT-GP、RoBERTa-wwm-GP、BERT-AT-GP以及BERT-WSGP。各模型在汽车维修数据集上进行了对比实验,结果如表5所示。
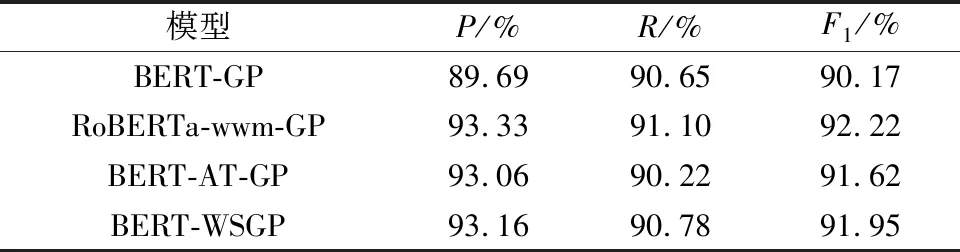
表5 不同组件对模型性能的影响Table 5 Effect of different components on model performance
从表5可以看出,将BERT-GP中的BERT换成替换为RoBERTa-wwm后,在汽车维修数据集上的F1提升了2.05%,说明RoBERTa-wwm模型增加全词掩码机制的措施可以提升汽车维修文本的嵌套命名实体识别效果。在BERT-GP基础上加上对抗训练,在汽车维修数据集上的F1提升了1.45%,这体现了通过向训练数据添加小扰动的方式能使模型的鲁棒性得到提高,进而增强模型的实体识别能力。而WSGP相比GP表现也更好,其F1提高了1.78%,可见通过引入中文分词可以提升模型的实体识别效果。
5.5 知识图谱构建与应用
抽取到实体及其关系后,需要依托相关工具将这些知识构建成知识图谱。Neo4j是一个开源图形数据库,与传统的关系型数据库相比,Neo4j可以直观地表示各节点之间的语义关系。此外,Neo4j还具有查询便捷和更新维护方便等优点。因此,选择Neo4j作为构建知识图谱的工具。如图9所示,选取部分内容进行可视化展示。
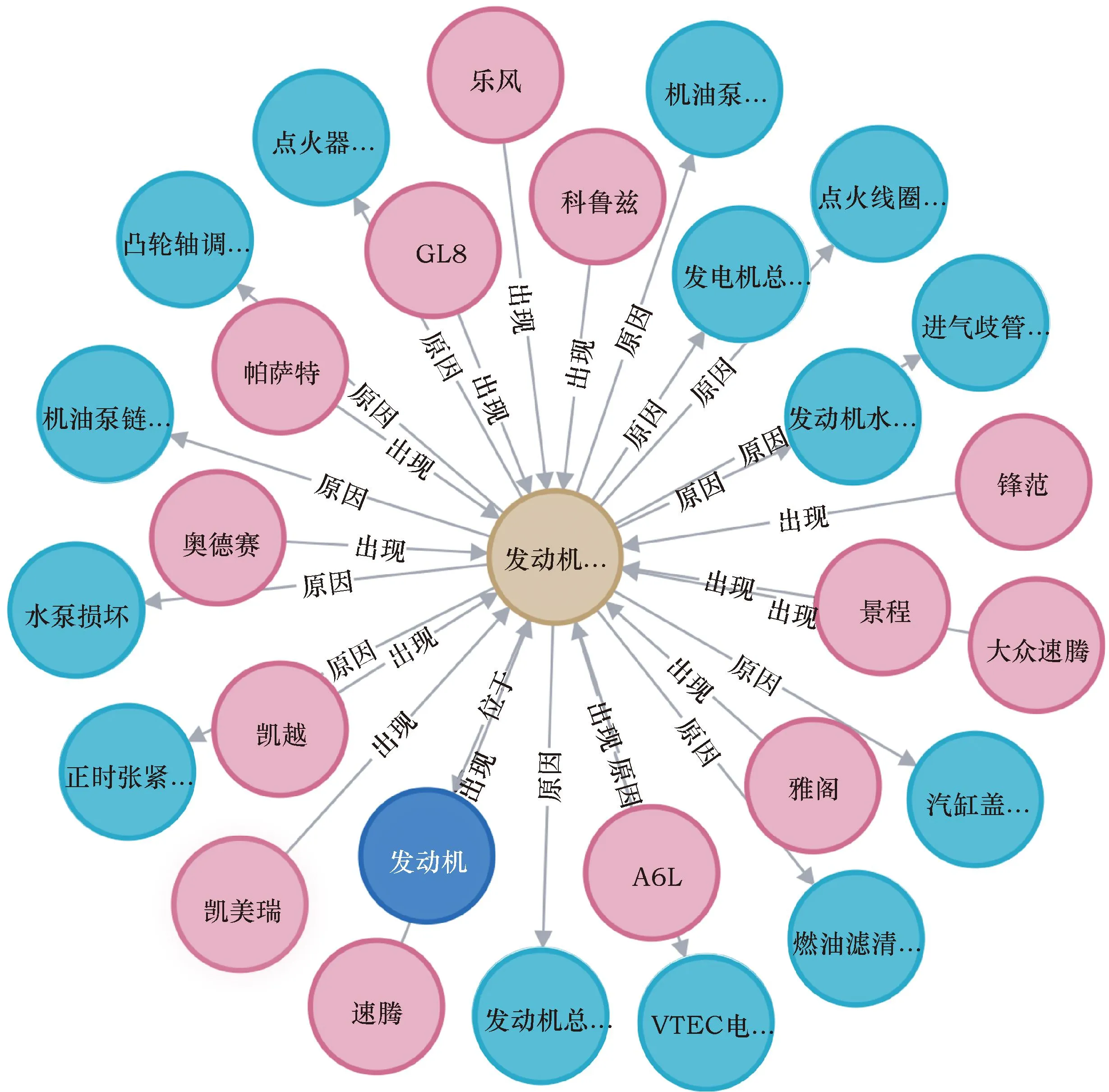
GL8为别克GL8车型;A6L为奥迪A6L车型;VTEC为本田的可变气门正时和升程电子控制系统图9 汽车故障知识图谱可视化展示Fig.9 Visual display of automobile fault knowledge graph
汽车故障知识图谱通过构建故障现象、故障原因以及解决方法等信息之间的关联关系,依托知识图谱强大的语义网络,可以进行图谱可视化,还可依靠智能问答系统,理解用户输入的自然语言问题,并返回正确的答案和相关问题推荐。
以新能源汽车中典型实例“车辆仪表EV功能受限和请检查低压系统是什么原因”进行系统演示,在系统的右上角搜索框内输入“车辆仪表EV功能受限和请检查低压系统是什么原因”的自然问句,系统首先识别实体,得到实体提及“仪表报EV功能受限”和“请检查低压系统”。接着进行实体链接,输出标准名“EV功能受限”“请检查低压系统”以及候选的关系。通过意图分类得到关系“故障原因”,然后将语义解析得到的信息转换成Cypher查询语句,在知识图谱中进行检索,并将输出答案和图谱可视化,在本例中可以看出,故障原因“PTC互锁插头松动”和“OBC内部损坏”为故障现象“请检查低压系统”和“EV功能受限”的共同原因,以可视化的方式可以通俗易懂地展示出这个信息,效果如图10所示。
6 结论
基于汽车故障文本,提出一种嵌套命名实体识别模型AT-RWSGP。该模型通过RoBERTa-wwm获得输入信息的向量表示,并引入对抗训练机制,最后使用WSGP进行解码。构建汽车故障知识图谱后,实现了基于知识图谱的汽车维修知识问答原型系统。通过实验和知识图谱应用分析后得到以下结论。
(1)所提基于AT-RWSGP的嵌套命名实体识别模型可以提高汽车维修领域嵌套命名实体识别效果。
(2)利用本文模型构建一定数据规模的汽车故障知识图谱,可以为智能问答等应用提高知识支持。
(3)知识图谱技术在汽车故障诊断领域具有良好的应用前景。
猜你喜欢
系统工程学报(2021年4期)2021-12-21
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
计算机工程(2014年6期)2014-02-28
河南科技(2014年23期)2014-02-27
