
基于上行MIMO-SCMA系统的异步分组检测算法
2024-02-28 13:59王雪周宁浩侯嘉
科学技术与工程 2024年3期
王雪, 周宁浩, 侯嘉,2*
(1.苏州大学电子信息学院, 苏州 215006; 2.电子科技大学长三角研究院(衢州), 衢州 324000)
稀疏码分多址(sparse code multiple access, SCMA)技术是一种基于码域的非正交多址(non-orthogonal multiple access, NOMA)接入技术,它允许多个用户共享同一个资源块,有效地利用了频谱,为5G的海量机器类型通信(massive machine type of communication,mMTC)场景下的大规模用户接入提供了可能性[1-4]。
SCMA系统将各用户的比特流映射到相应的稀疏码本[5],并采用消息传递算法(message passing algorithm, MPA) 进行信号解码检测。MPA算法是对最大后验概率算法(maximum a posteriori, MAP)的改进,它不需要像MAP一样穷举所有码字组合,利用边缘概率的传递,实现多用户叠加信号的迭代检测[6]。传统SCMA检测算法大多默认接收端能够完美同步所有信号,即用户的信号在基站处叠加,每个符号前后互不影响。
但在实际上行链路中,基站接收的信号来自于不同方向不同距离的用户,造成了信号到达接收端的时延不相同的问题,因此,基于异步传输的SCMA检测算法研究有着十分重要的意义。目前,SCMA异步检测的相关研究并不多,大部分集中在对于PD-NOMA异步系统的研究,但其中的思想与方法依旧可以借鉴。文献[7]分析了实际异步场景,异步检测主要的问题有两个:一是异步传输引起的符号间干扰问题,另一个是符号混叠造成的检测复杂度加剧的问题。文献[8-9]提出了一种基于异步非正交多址接入的循环三角串行干扰消除方案,降低了接收到的叠加信号的译码复杂度、能量消耗和误码率。文献[10]在上行NOMA异步传输模型中,将一个符号数量较大的帧划分为多个小块,采用基于近似消息传递的算法,降低了检测复杂度。文献[11]为SCMA异步传输系统提出了置信传播消息传递算法、等增益置信传播合并消息传递算法和部分相位相干算法,来弥补异步传输带来的性能损失。另外,文献[12]设计了一种基于期望传播的联合迭代解码器,能更准确地检测出活跃用户并降低误码率;文献[13]提出了一种根据导频序列进行信道估计的联合多用户检测算法,并通过高斯近似降低了复杂度;文献[14]提出在未知用户码本的情况下检测用户信号的盲检测算法;文献[15]采用深度学习的方法,在未知信道信息和系统稀疏程度情况下对信号进行检测。但现有的异步检测算法对于大规模用户或者分组用户的检测方面还没有进行深入研究。
与此同时,为了对抗大量接入引起的检测性能下降,引入多输入多输出(multiple-input multiple-output, MIMO)技术能够有效利用分集增益来提高系统吞吐量和可靠性[16]。其中,文献[17]提出了多天线SCMA系统中的基于阈值的边缘选择以及天线选择方案;文献[18]提出了基于期望传播的MIMO-MPA算法;文献[19]则引入了空分调制、空分复用来加强MIMO系统性能;文献[20]通过高斯近似检测方法,提出了部分天线激活的接收机方案。但这些方案随着MIMO天线数目的增加,检测复杂度呈指数级增加,因此对MIMO系统低复杂度检测算法的研究更值得关注。
当下,对于低复杂度SCMA检测算法的研究方向主要有:降低码本大小、降低迭代次数、降低行重因子、降低迭代点数和降低指数运算等[21-22]。例如,文献[23]提出了一种下行SCMA传输的区域限制检测算法,只选取划分的区域内的星座点,避免了穷举所有点;文献[24]采用了部分边缘化算法,将迭代过程分成两部分,后半部分只有一部分用户参与迭代;文献[25-26]研究了球形译码算法,利用高斯分布特性,选取设定半径的圆内的点参与计算;文献[27]提出了log-MPA和max-log-MPA,在微小的性能损失下,大幅降低了乘法和指数运算次数;文献[28]通过提前终止、自适应解码、初始噪声减少等方法得到更快的收敛速度。文献[29]则证明了串行消息传递能够降低迭代次数,达到更快收敛。
由以上介绍可以看出,目前的工作大部分是基于同步信号的检测,缺少对异步检测的研究,特别缺乏对于能支持大规模用户、具有低复杂度的MIMO-SCMA系统分组检测的研究。现将不同时延的用户群进行分组,提出了一种面向上行链路异步传输的连续传播的消息传递检测算法(serial propagation of message passing algorithm, SP-MPA),有效降低误码率;并针对MIMO-SCMA结构,提出了一种基于动态阈值的部分边缘化消息传递算法(dynamic threshold partial marginalization algorithm, DTPM-MPA),在降低计算复杂度的条件下,保证较好的系统性能。
1 系统模型
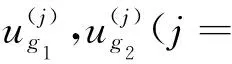
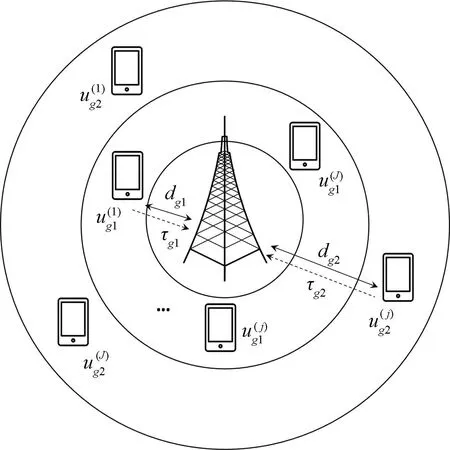
图1 多用户分组模型Fig.1 Multiuser grouping model
1.1 码本方案
首先,设计每个用户分组的母码本,将母码本划分成各个分集,分配给各资源块上共享的用户[30],各用户将比特流映射到各自的码本上,调制后发送。基站通过多天线接收到叠加信号,进而利用检测算法区分发送信号的用户信息。
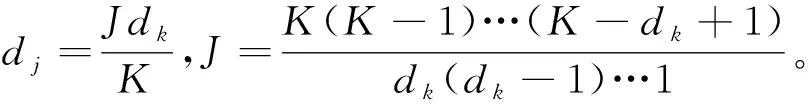
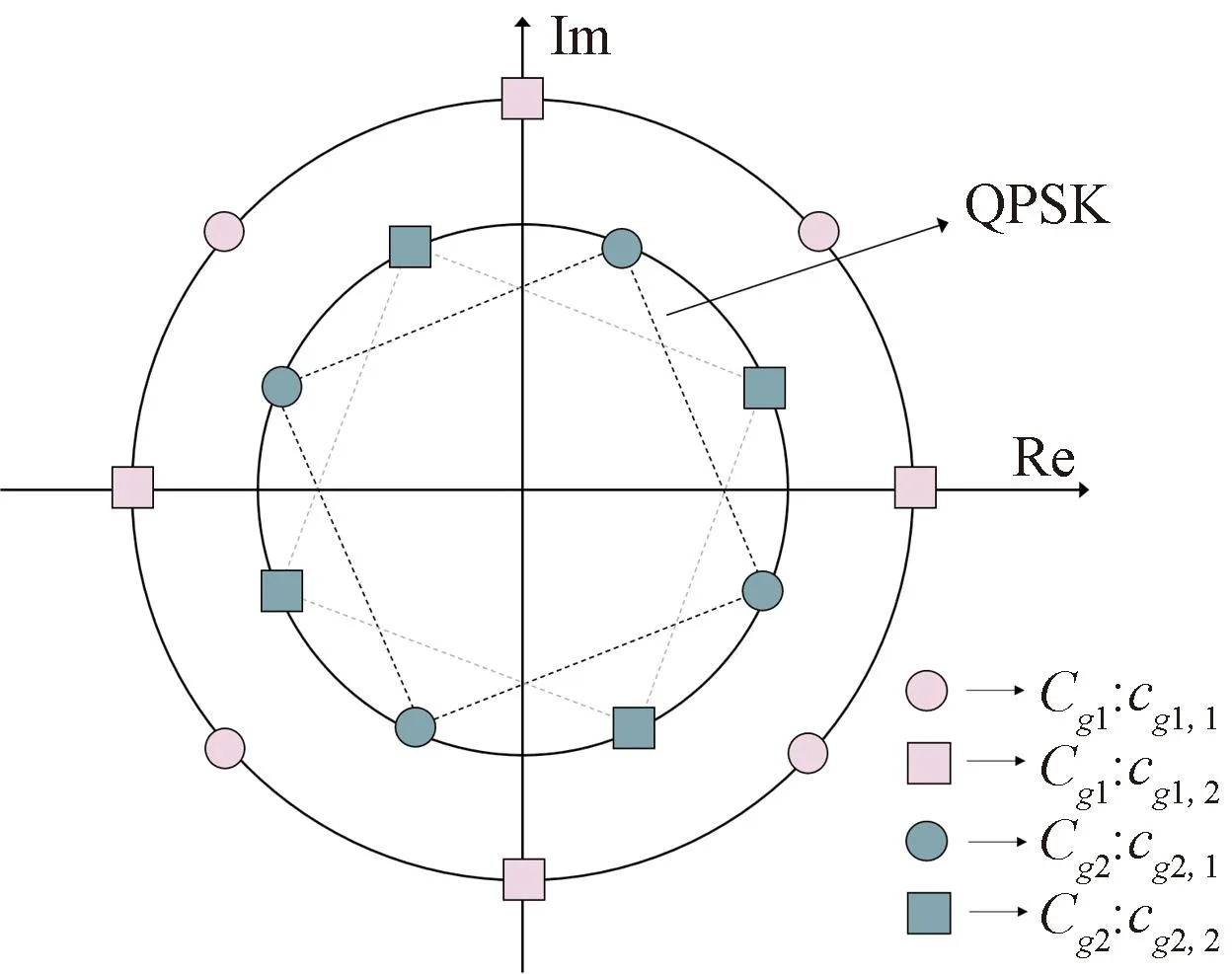
图2 第k个资源块上的用户分组码本Fig.2 Codebooks of multiuser group on the kth resource
1.2 多用户分组异步传输模型
在上行链路中,多个用户向基站传输数据,由于环境和位置的不同,信道条件不同,衰落和损耗也不尽相同[31],设每一个用户分组内的用户到达基站的时延相同,如图3所示。
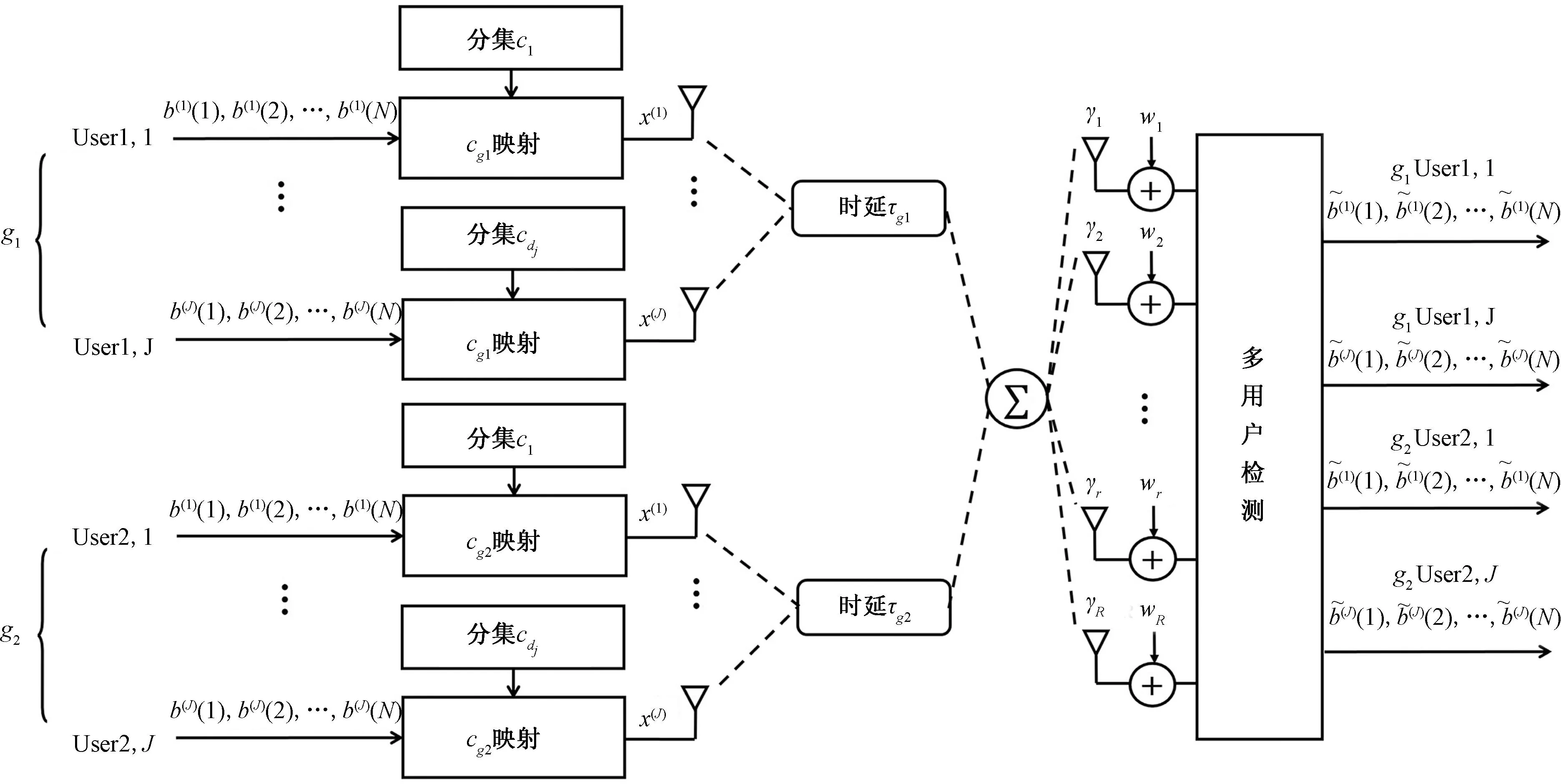
图3 上行异步MIMO-SCMA多用户分组系统Fig.3 Uplink asynchronous MIMO-SCMA multiuser group system
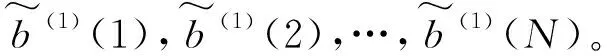
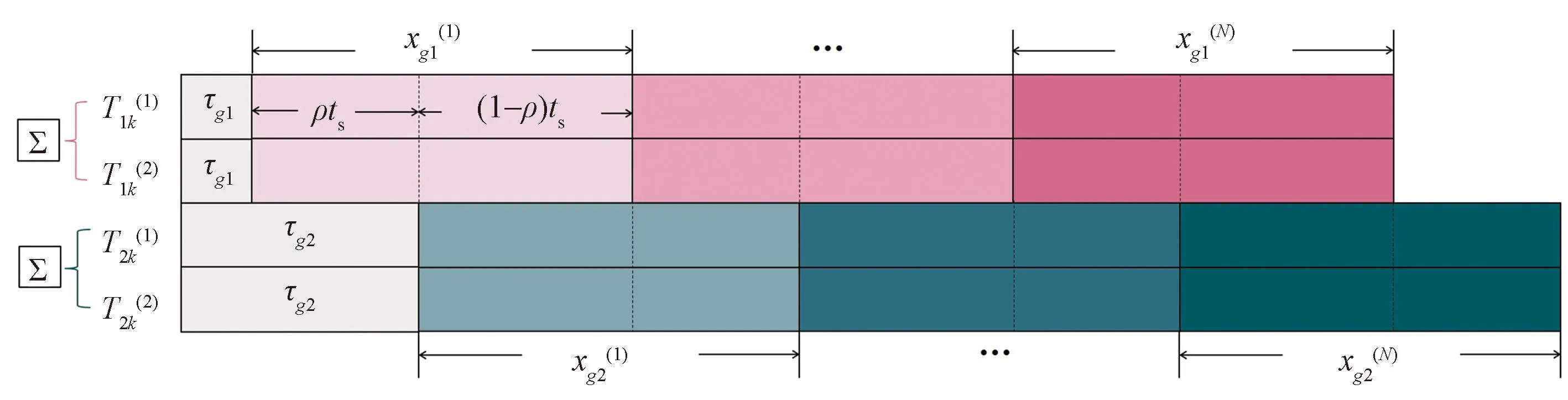
图4 两用户分组异步传输过程示意图Fig.4 Two-group asynchronous transmission process diagram
同一个资源块上的叠加信号可表示如下,Tk表示在资源块k上占用的用户集合,且T1k=T2k=Tk。ts表示每个符号持续时间,两用户分组的时延可等效为:τg1为0,即设定用户分组1是理想同步的,τg2与ts的比值为ρ。以下对ρ范围进行分类讨论。
(1)若0<ρ<1,则时延在一个符号持续时间范围内。
(2)若ρ=0,1,2,…,N-1,则时延等于符号持续时间的整数倍。
(3)若υ<ρ<μ(υ=1,2,…,N-1;μ=υ+1),则在(1)的基础上往后延迟υ个符号持续时间。此种情况下,检测思路同(1)。
本文中按照(1)的情况阐述异步检测过程。检测算法按照符号进行逐一判决,将接收信号写成与符号相关的形式,接收信号结构如图5所示。由于异步传输,每一个符号不仅影响当前符号,也影响相邻的符号,且受到的干扰也不一样[32]。接收信号表达式可写为
(1)
(2)
(3)
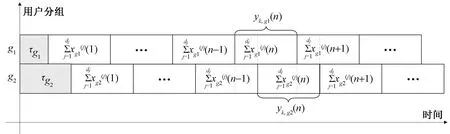
图5 接收信号结构Fig.5 Receiving signal structure
2 检测算法
2.1 log-MPA算法
MPA是一种基于因子图的近似迭代算法,通过资源节点和用户节点间进行边缘概率的计算与传播,最后得到各个用户各个码字的概率,通过对数似然比 (log-likelihood ratio, LLR)判决得到最终估计的比特流。
同步接收检测方法中,各用户经过消息传递,得到每个符号的码字概率,每个符号间的检测互相独立。传统SCMA同步模型可通过MPA算法得到较准确的判决,本文的模型也可以通过传统MPA进行解码,为了降低指数运算,这里采用log-MPA。首先初始化用户码字概率,再根据图6因子图进行消息传递迭代,用户分组1和用户分组2采用相同因子图,传递过程表达式为
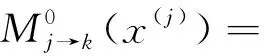
(4)
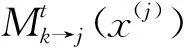
(5)
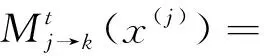
(6)
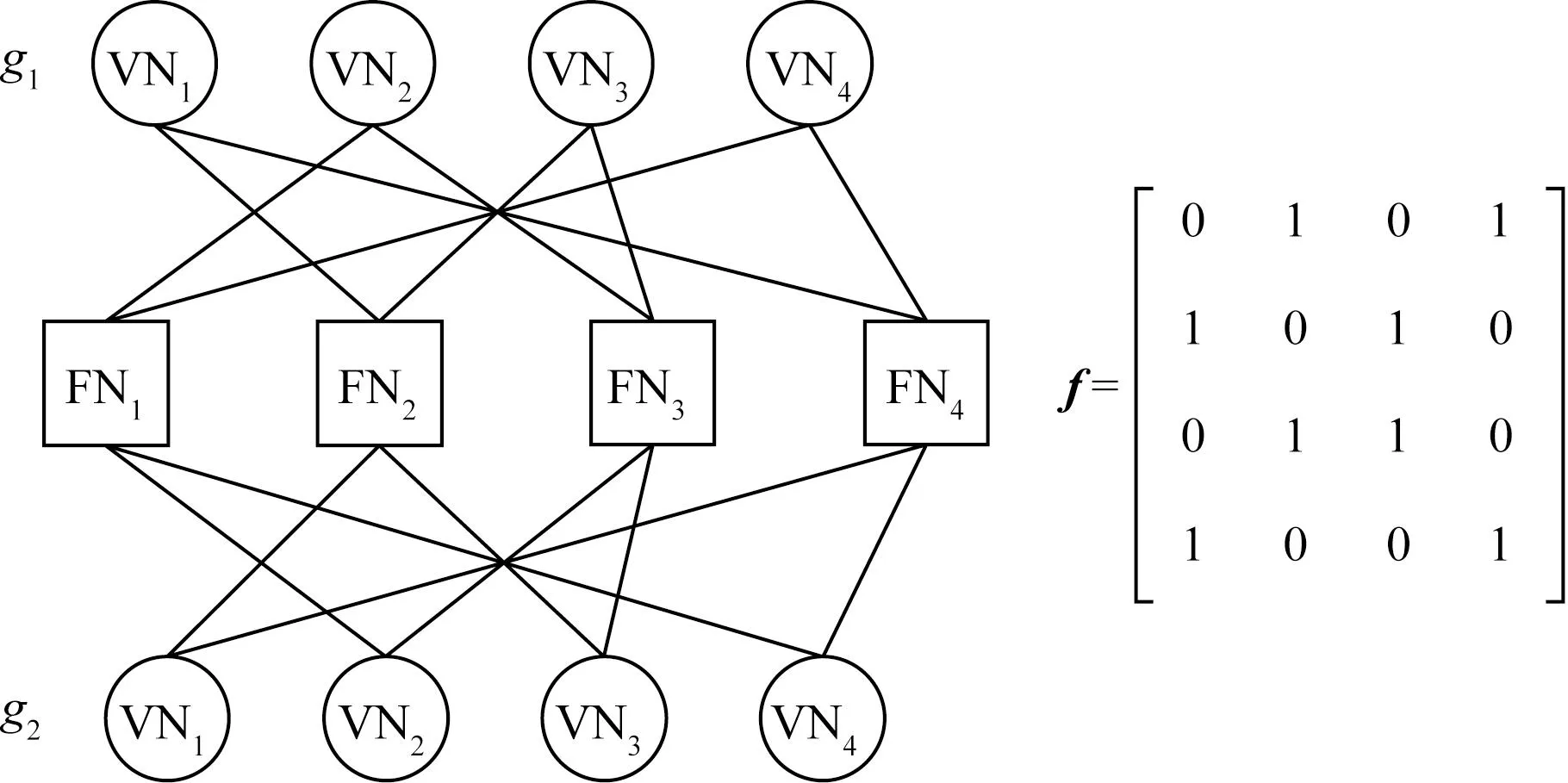
FN指的是频率资源节点;VN是用户节点图6 资源块与用户因子图Fig.6 Factor graph ofresources and users
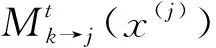
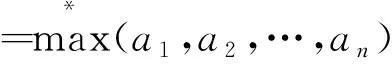
(7)
式(7)中:a为常数项。
最终对码字概率进行LLR判决,由于每个用户分组的判决过程一样,这里列出码字信息公式和LLR判决公式为
(8)
(9)
2.2 SP-MPA算法
上述传统同步检测算法在每一次进行MPA时,先验概率均从1/M开始,前面信号的概率信息并没有参与计算,即传统算法并没有很好地利用判决信息。现提出一种SP-MPA算法,充分利用先前的信息,提高系统性能。
根据前面的异步传输结构和接收信号公式,对接收信号进行检测。首先,对yk,g进行MPA迭代,同时得到用户组1和用户组2的码字信息,再将用户组2的迭代结果向后传递作为后续检测的初始概率,传递公式见式(10)。消息在各个子节点间进行传递,传播过程的节点因子图如图7所示,为了图示清楚,第k个资源块上共享的用户节点只列出一个,每个用户与资源块间的信息更新模式相同。其中,Fg表示用户组g在第k个资源块上观测到的似然概率,Q1和Q2表示用户分组1和用户分组2迭代终止时输出的各用户码字的概率。
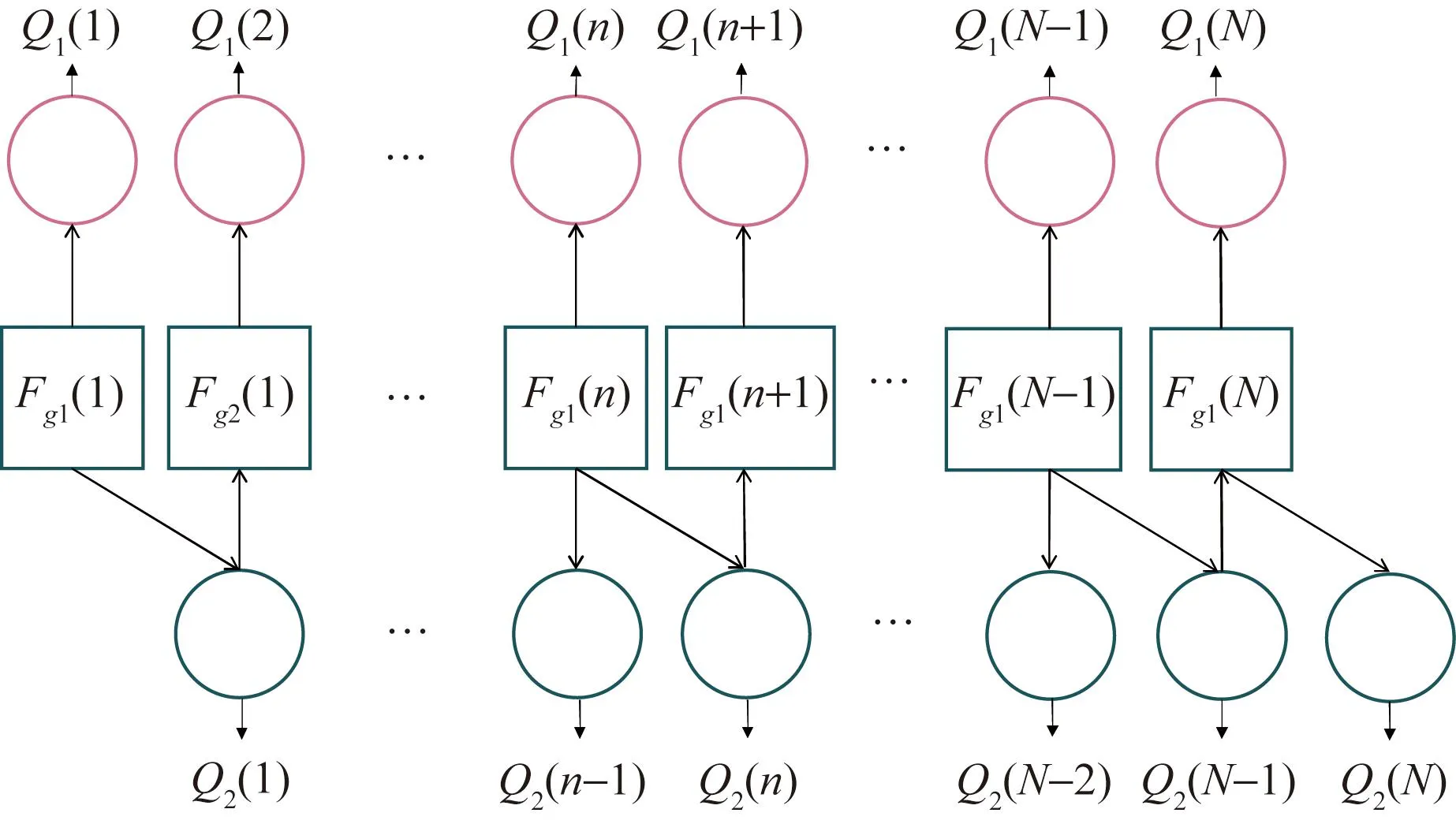
图7 SP-MPA(1)节点信息传播过程Fig.7 Message passing process at nodes in SP-MPA(1)
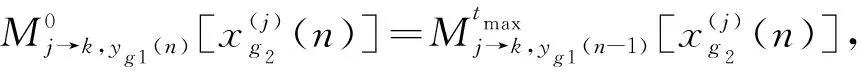
n=2,3,…,N
(10)
通过以上流程可知,只有用户组2的信息是往后传递的,但是用户组1的符号每次迭代初始概率仍为1/M,并没有充分利用所有信息。分析异步传输过程发现,yk,g1与yk,g2包含了共同信息,可通过两次检测得到更准确的信息值。首先对yk,g1(n)进行MPA迭代,再对yk,g2(n)进行MPA迭代,由于yk,g1(n)和yk,g2(n)中存在相同的符号,因此两次检测的信息可以互相利用。传播过程的节点因子图修改如图8,传播公式为
(11)
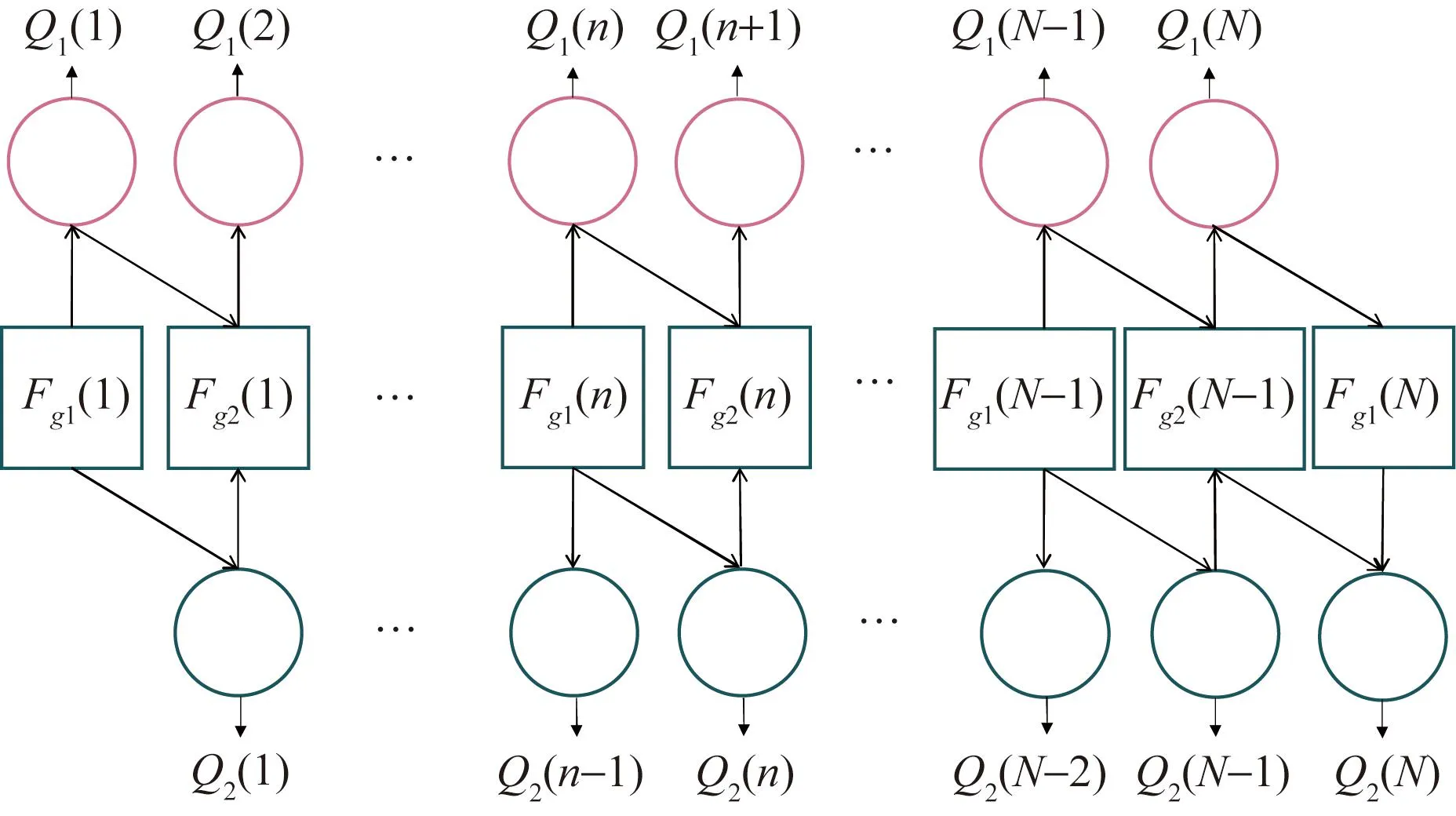
图8 SP-MPA(2)节点信息传播过程Fig.8 Message passing process at nodes in SP-MPA(2)
(12)
通过以上算法,能够将先前的信息传递下去,而传统算法设定的最大迭代次数tmax不一定准确,因此设定一个精度,若前一次迭代得到的码字概率与本次迭代的码字概率差值小于该精度,则判定迭代结束。其中,精度值越大,表明码字差值越容易满足该精度值,提前停止迭代,复杂度降低,准确度也会降低。本文将只用了一组用户信息进行迭代的算法称为SP-MPA(1), 而提出的利用两组用户信息进行迭代的算法称为SP-MPA(2), 其具体算法流程如下。
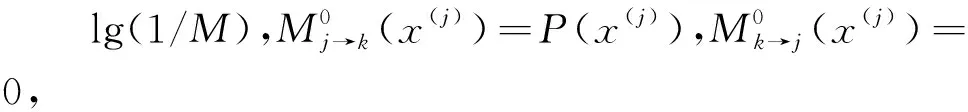
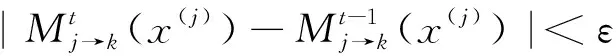
分别对用户组1和用户组2的符号进行检测,并将每次结果作为后一次检测的初始概率,传递公式见式(11)和式(12)。
最终得到各用户的码字概率Q(x(j)),再按照式(9)进行相应LLR输出所有用户的比特流b(j)(n),n=1:N。
2.3 MIMO-SCMA系统检测算法
由于多用户分组模型使得接入的用户增加了,干扰项也变多了,因此会造成系统误码率的升高,为了解决此问题,运用多天线的分集效应可以增加传输可靠性与准确度,提升系统性能。在上述单天线异步分组检测算法基础上,本节将阐述MIMO-SCMA系统中低复杂度的检测算法设计。
在多天线系统中,基站的每根天线都接收到相同的信号,即用户发来的叠加信号。将每根天线化为一个虚拟功能节点[33],每个用户分组产生R×K个虚拟功能节点。构建联合因子图如图9所示,为了更清晰的展示,图中只画出了2根接收天线、用户分组1的变量节点连接情况,用户分组2与之相同。增加天线根数相当于增加虚拟功能节点的个数,即增加了频率资源块的个数。
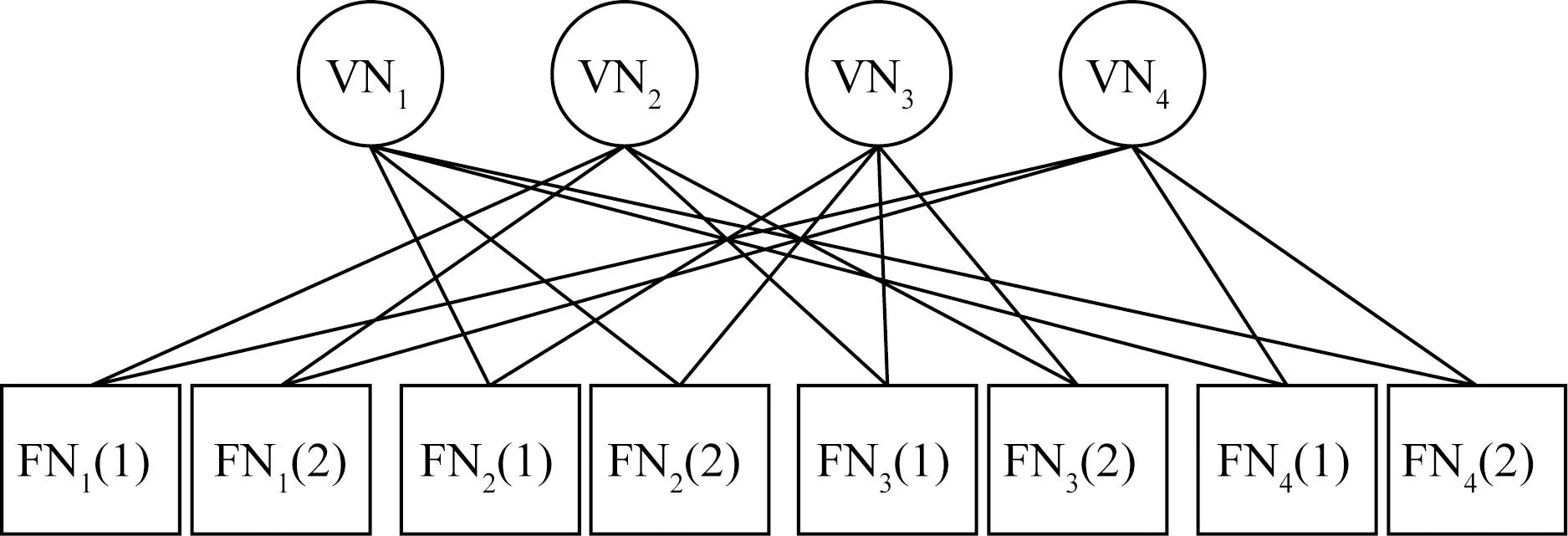
图9 MIMO-SCMA联合因子图Fig.9 MIMO-SCMA joint factor graph
从图9看来,随着天线根数的增加,因子图中信息传播的次数也在增加,虽然MIMO技术可以提高系统性能,但同时也大大增加了检测复杂度,为了减少复杂度,本节将采用一种改进后的基于部分边缘化的改进MPA算法。
基于部分边缘化的消息传递算法(PM-MPA)核心是先进行一部分的完全迭代,在剩余迭代中去掉部分用户对应的用户节点和功能节点,降低计算复杂度。传统PM-MPA中,在进行m次完整迭代后,随机选择a个用户停止迭代,在后续l-m次迭代中该a个用户消息不再参与计算,即该a个用户的消息在前m次迭代后不再变化[34]。由此看来,虽然该算法可以大大降低计算复杂度,但由于用户是随机选择的,数目也是固定的,码字概率不会全部得到充分收敛,因此误码率也会相对较高。为了在降低复杂度的同时,减少性能损失,在PM-MPA基础上提出一种基于动态阈值的部分边缘化算法(DTPM-MPA)。该算法中,前m次也是完整迭代,和PM-MPA一样,第m次迭代结束后,对各用户码字概率进行排序,如果最大的码字概率远远大于其余码字,且第m次迭代的最大码字概率与第m-1次差距小于某个精度,则可停止该用户的后续迭代。本文提出的多天线DTPM-MPA的具体算法流程如下。
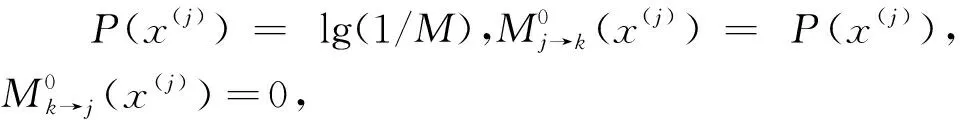
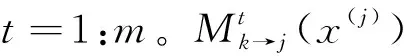
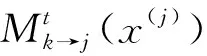
最终得到各用户的码字概率Q(x(j)),再按照式(9)进行相应LLR输出所有用户的比特流b(j)(n),n=1:N。
其中th1代表码字确定度阈值,如果某个用户的某个码字概率值大于其他码字概率值,说明该用户更容易判断出发送的是哪个码字,区别越大,判断越准确。而th2代表码字收敛性阈值,反映某个用户的码字在前后迭代的差值情况,若差值较大说明该码字并没有得到很好的收敛,还需要进一步迭代。
通过测试发现,用户码字概率值与信噪比息息相关,信噪比越大,用户最大码字概率与其他码字概率差距越大,而前后迭代差值越小。设置阈值计算公式为单调减函数,a和c决定了阈值的最大值,b和d决定了阈值间隔,由于无法预测码字概率的具体变化规律,这里采用等间隔的方式计算b和d,仿真时间隔数可取比特信噪比Eb/N0的点数l(Eb/N0)。其中,为了防止阈值为0时导致限制失效,设置了阈值最小值a′和c′。
th1=a-bEb/N0
(13)
th2=c-dEb/N0
(14)
b=(a-a′)/l(Eb/N0)
(15)
d=(c-c′)/l(Eb/N0)
(16)
2.4 算法复杂度
复杂度是衡量算法性能的一个标准,基于多天线系统,对于上述算法进行复杂度的分析,其中复杂度计算的是一个符号内算法里各种类型运算的次数,包括迭代次数和基本运算。本文假设两个用户分组的因子图相同,每个资源块上占用的用户数均为dj,每个用户占用的资源块数均为dk,各用户调制阶数均为M。
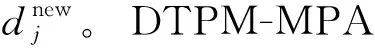
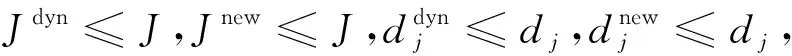

表1 复杂度分析Table 1 Complexity analysis
3 仿真结果
首先列出文章的仿真参数设置:2个用户分组,每个用户分组包含J=4个用户,共享K=4个资源块,用户分组到基站的距离分别为dg1=0.5 km和dg2=1 km,2个用户分组内的用户发射功率相同,均归一化,即Pg1=Pg2=1。两个码本间旋转角度为45°,原因是该角度能够使得两个码本中码字距离相对较远。用户采用的调制方式均为QPSK,发送数据长度相同。
图10所示为分别采用log-MPA和SP-MPA的系统性能。g1表示近用户分组,g2表示远用户分组。采用SP-MPA可以大幅降低误码率,提高系统性能,尤其是在信噪比较高的条件下,SP-MPA性能更为显著。从图10中可看到,log-MPA的下降趋势平缓,且误比特率一直处于较高水平,而SP-MPA在Eb/N0>15 dB时就开始迅速下降,误比特率到30 dB时接近10-5。其中,SP-MPA(2)由于充分利用了前面信息,误码率相较于SP-MPA(1)更低。

图10 log-MPA与SP-MPA平均误码率曲线Fig.10 Average BER curves of log-MPA and SP-MPA
分析其原因,由于log-MPA在每次进行MPA迭代时,初始码字概率均从1/M开始,而SP-MPA 则保留了前一次检测的概率作为后一次的初始概率。前一次得到的码字概率已经得到了充分计算,判断出的概率也可以反映出该符号发送情况,后一次检测不必要从头开始计算,因此可代入后续计算。而SP-MPA(2)传播的是两个用户组的信息,SP-MPA(1)仅仅传播了一个用户组的信息,因此SP-MPA(2)效果更优。
图11所示为MIMO系统中,基站配备不同数量的接收天线下系统的误码率性能,两个用户分组均包含4个用户,每个用户配有1根发射天线,选取接收天线数目为1、2、4,每个频率块共容纳4个用户。由于增加接收天线根数相当于增加了虚拟资源节点,码字概率传递路径数目增加,提高了码字概率可靠性,从而误码率下降。在信噪比为15 dB时,用户分组1与用户分组2在接收天线R=1的平均误码率分别为0.107 9和0.248 7,接收天线R=2的平均误码率为0.016 7和0.087 3,接收天线R=4的平均误码率为0.000 7和0.014 1。说明多天线的分集效应给系统带来了更低的误码率与更可靠的性能。

图11 多天线系统下SP-MPA平均误码率曲线Fig.11 Average BER curves of SP-MPA in MIMO system
图12则展示了在天线根数为2的情况下,采用低复杂度算法DTPM-MPA的效果。其中图例PM1,3表示PM-MPA的初始迭代次数为1,1次迭代后删除3个用户节点。DTPM5,25表示阈值a为5,c为25,其余图例类推。PM2,3的误码率非常接近于SP-MPA,虽然准确,但是复杂度几乎没有下降。PM1,3与SP-MPA相差较大,虽然复杂度降低了,但是码字准确度降低较多。
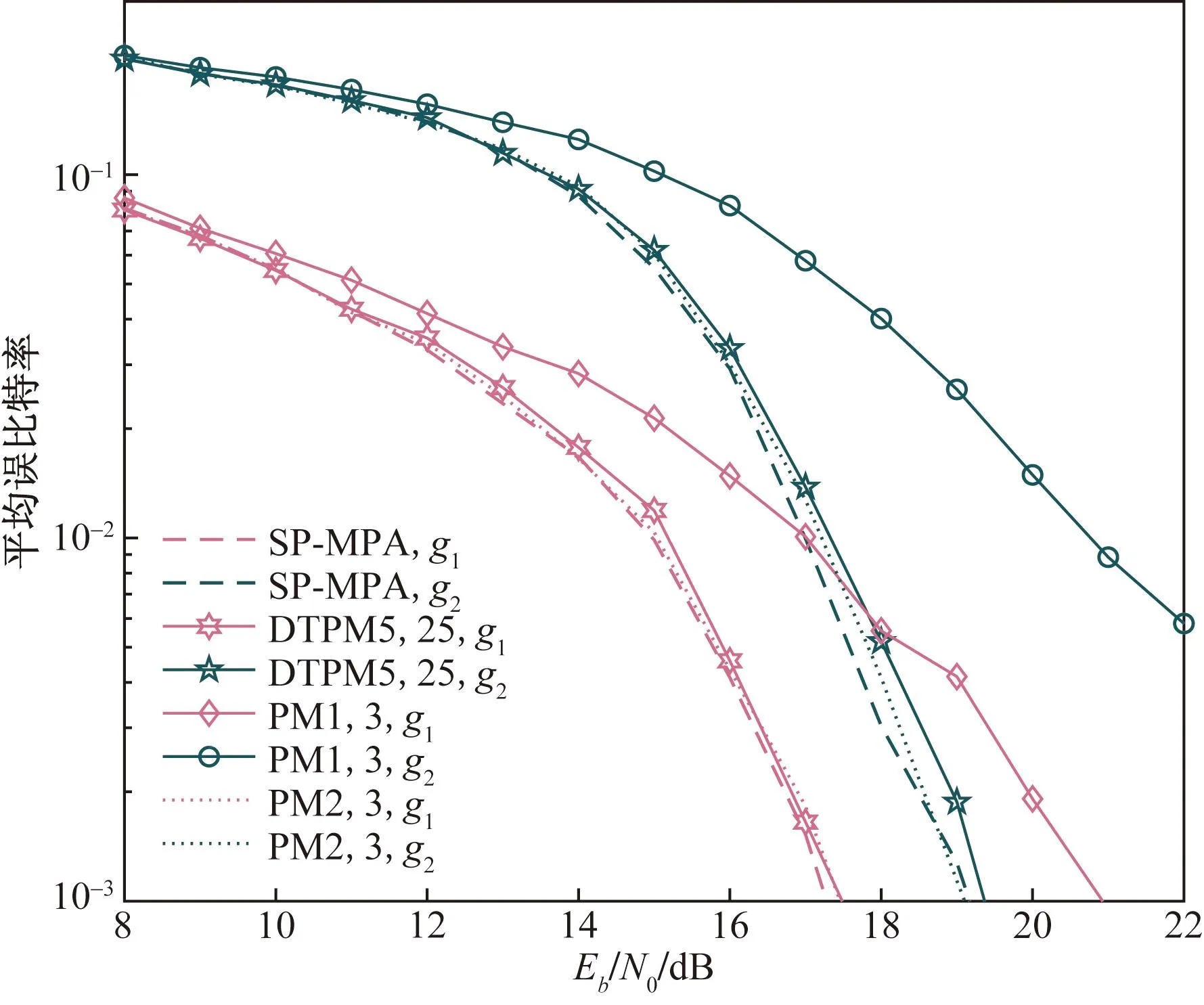
图12 各算法平均误码率曲线Fig.12 Average BER curves in different algorithms
与传统PM-MPA相比,DTPM-MPA更为灵活,通过调整阈值大小,在性能和复杂度间做一个平衡。PM-MPA只能去除特定数目的用户,有可能会删除未收敛的用户,导致性能下降,同时每次删除的用户数目相等,不利于性能调整。图13列举了10个符号判决过程中减少的用户节点。DTPM-MPA与PM-MPA相比,每一次减少的用户节点数目都不一定,是由当时的码字概率是否满足阈值来决定的。可知采用与信噪比相关的阈值,能够更准确地去除相关用户。
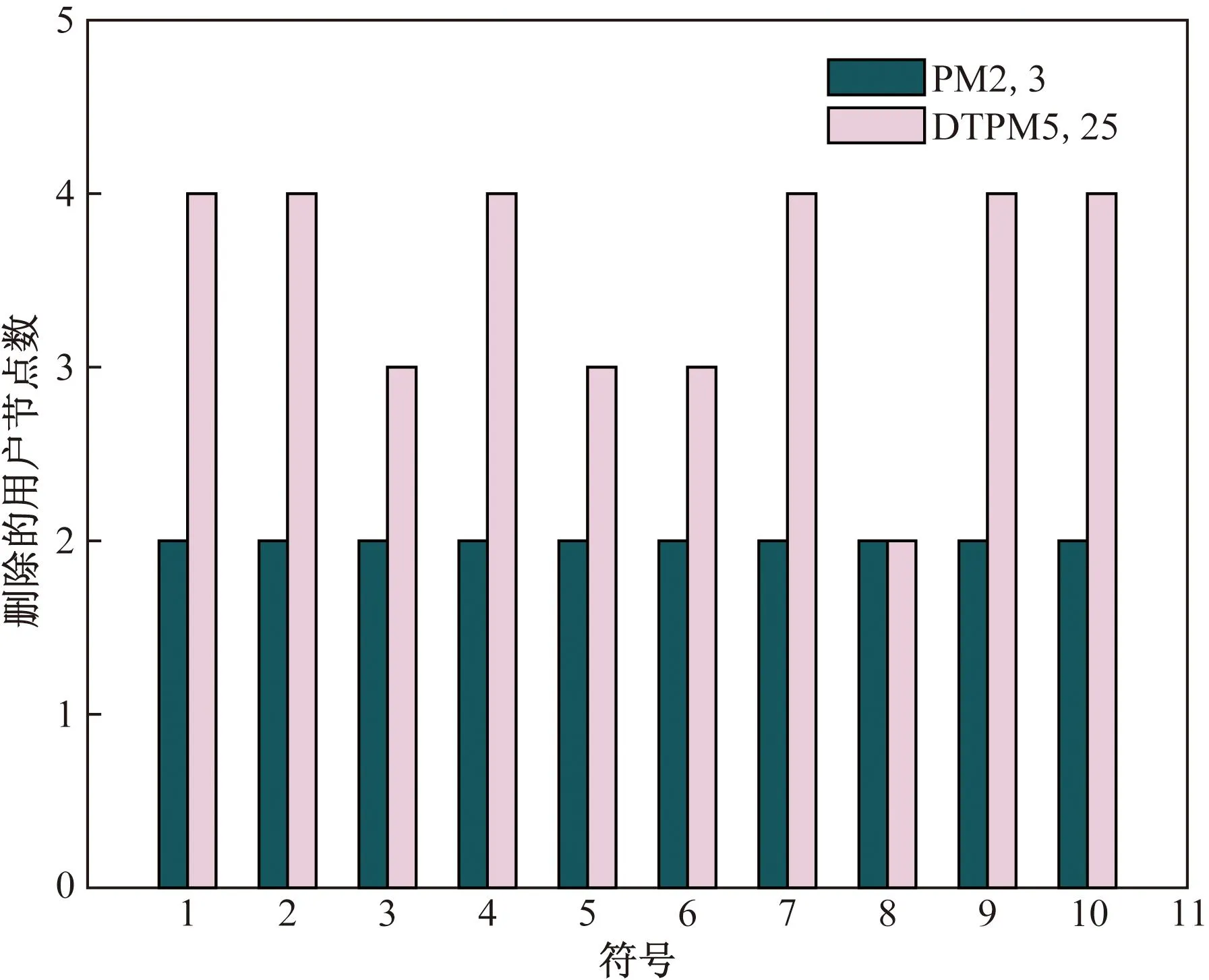
图13 减少的用户节点柱状图Fig.13 Bar chart of deleted user nodes
表2和表3的数据是采取log运算和两次迭代后的码字概率Q的计算数值,可以发现随着信噪比增加,用户各个码字间的差距越来越大,判断会更加准确。而同一用户前后迭代的码字差距越来越小,即收敛更快,因此根据信噪比设定阈值是有依据的。

表2 信噪比为10 dB时两次迭代前后码字信息Table 2 Message of codewords in consecutive iterations when Eb/N0 is 10 dB

表3 信噪比为30 dB时两次迭代前后码字信息Table 3 Message of codewords in consecutive iterations when Eb/N0 is 30 dB
本文仿真设置信噪比从0到30 dB,设置a与a′,c与c′,计算出b和d。例如,当a=5,c=25,a′=3.2,c′=7时,b=0.06,d=0.6,Eb/N0=20 dB时,时th1=3.8,th2=13。若a=2,c=20,a′=0.2,c′=2时,b=0.06,d=0.6,Eb/N0=20 dB时,th1=0.8,th2=8。表4以用户分组1为例,列出每个用户排序后的码字信息。表4数据表明,动态阈值对用户进行了筛选,th1=3.8,th2=13情况下,所有用户均满足阈值,因此全部被删除。th1=0.8,th2=8情况下,用户1满足阈值,可以被删除。

表4 信噪比为20 dB时码字信息
图14所示为删除用户个数对复杂度和误码率的影响。此处复杂度用计算时间衡量,计算时间越长表明复杂度越高,这里采用归一化时间。用户被删除的越多,误码率越高,复杂度越低,可以调整阈值,在复杂度和可靠性之间做出平衡。
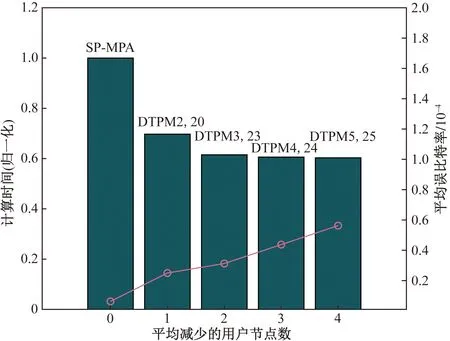
图14 动态阈值对复杂度和误码率的影响Fig.14 Dynamic threshold’s impact on complexity and BER
4 结论
针对上行异步多用户分组的单天线SCMA系统,提出了一种基于连续传播的异步检测算法。同时,针对MIMO-SCMA系统,提出了一种基于动态阈值的部分边缘化异步检测算法,在保证一定准确度的同时,降低计算次数。仿真结果表明, SP-MPA传递了前一次的计算信息,相较于传统MPA算法具有更低的误比特率。MIMO-SCMA系统下,多天线的增益使得系统的误码率更低,本文提出的DTPM-MPA更加灵活,相比于传统PM-MPA算法,可以平衡计算复杂度和误比特率,提升了系统的综合性能。
猜你喜欢
雷达与对抗(2022年1期)2022-03-31
中国惯性技术学报(2019年6期)2019-03-04
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
扬子江(2018年1期)2018-01-26
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
单片机与嵌入式系统应用(2014年7期)2014-03-24
铁路通信信号工程技术(2014年3期)2014-02-28
