
基于域泛化的工业设备无监督异常声音检测算法
2024-02-28 13:59毕忠勤李欢峰张伟娜董真
科学技术与工程 2024年3期
毕忠勤, 李欢峰, 张伟娜*, 董真
(1.上海电力大学计算机科学与技术学院, 上海 201306; 2.国网上海市电力公司电力科学研究院, 上海 200437)
近几年,针对工业设备的状态维护和故障检测[1-5]已成为企业一项必不可少的重要内容,异常事件不仅会影响产品的质量、降低流程的连续性,还可能会危及工人的安全。因此,异常检测问题被频繁研究。而基于声音的系统因其价格低廉、安装速度快、能够覆盖摄像头盲区等优点,在机器学习领域逐渐引起广泛关注。目前已被应用在不同类型的场景中,如面向电力人员的智能调度[1],对真实电机的实时音频监控[4],或对滚动轴承的故障诊断[6]。该任务也常被称为异常声音检测(anomalous sound detection, ASD)[7]或声学机器状态监测(machine condition monitoring,MCM)[8]。
然而,在实际工业中,训练集包含的目标域数据的样本通常很少或没有,并且由于周围机器和设备在各种模式和条件下运行,声音信号往往会容易发生域转移[9]。域转移的发生往往因为运行速度、机器负载和环境噪声等因素变化造成训练数据和测试数据之间声学特性差异。因此,在这种情况下,通常考虑使用域泛化技术[11-13]。域泛化技术主要利用源域数据学习不同领域的共同特征,使模型在测试数据中既可以泛化到源域,也可以泛化到目标域。Li等[11]通过对抗训练的方式,对自动编码器进行联合优化,来学习跨域的特征表示。Gou等[10]利用多级残差连接神经网络,从频谱中提取特征,并利用局部异常因子(local outlier factor, LOF)估计特征分布以计算不同领域间各类声音片段的异常强度。域泛化技术主要适用于由以下四种差异引起的域转移场景[13]:机器物理参数差异、环境条件差异、维护差异和记录设备差异。
近年来,将深度学习模型用于工业设备无监督异常声音检测已经取得了一些成果。如Wang等[14]提出了一种利用自监督分类器模型、自编码器和任务无关异常值作为伪异常数据的二元分类模型,并集成了一种基于距离度量的模型。黄健豪等[3]提出了一种基于迁移学习(transfer learning,TL)的无监督结构优化卷积网络模型,结合快速批量核范数最大化,对不同工况的轴承故障检测效果有明显提升。Ramachandra等[15]提出了最近邻位置相关的异常检测方案,使用人工制作的距离测量方法,通过从训练数据中构建一个简洁的具有代表性的模型计算异常分数。然而音频表示通常是高维的,随着数据维度的增加,这些方法可能无法准确地表达模型。
而在异常声音检测任务中,利用域泛化技术获取更多的特征信息已经成为研究热点。如Liu等[16]提出了六个子系统的组合,包括三种自监督分类方法、两种概率分类方法和一种基于生成对抗网络(generative adversarial network, GAN)的分类方法。然而,如果测试集中的目标域数据包含太多训练集中不包含的数据类型,分类器可能无法区分域,从而会降低模型的鲁棒性。Dohi等[13]提出了两阶段的ASD系统,包括一个基于异常点曝光的特征提取器和一个基于内层建模的异常检测器,因此,该系统模型的复杂度较高,单个阶段模型无法适应异常处理任务。现阶段对此类问题的研究仍缺乏针对无法适应不同域转移场景下的有效方法。
针对上述问题,基于联合深度学习和变分高斯混合模型的新框架(joint deep learning &variable Gaussian mixture,JDL-VGM),提出一种用于机器状态监测域泛化下的无监督异常声音检测算法,学习跨域的广义潜在特征表示。通过将深度学习与无监督聚类技术相结合,能有效地从声音信号中提取特征并将其聚类到不同的类中。
1 基于域泛化的工业设备无监督异常声音检测算法
JDL-VGM模型主要可以分为三个模块:数据预处理模块、嵌入提取模块和异常评估模块。模型架构如图1所示。
1.1 数据预处理
1.1.1 音频特征提取
为了获得数据的低维表示,需要对音频进行特征提取[6,17]。同时,为了更好地捕捉来自原始波形的不同机器的声音特征,该系统利用两种不同的特征提取方式。
首先,将原始波形转换为log-Mel谱图,以初步降低其维数。更具体地说,采用128个Mel滤波器、1 024个窗口大小和512个hop size计算log-Mel谱图,得到大小为313×128维的特征。然后,所有的log-Mel谱图通过减去所有训练集文件的时间均值,并除以时间标准差,以获得最终的归一化后的特征。
第二,将原始波形转化为幅值谱图,即利用傅里叶分析方法(discrete fourier transform, DFT)将声音信号从时域变换为频域,进而得到信号的频谱结构,以更好地捕捉发出相对静止声音的工业机器的声音特征,如风扇。
1.1.2 数据增强
为了提高系统的分类性能,进一步探索将非线性方法的优点与基于线性的方法结合的可行性,并将其应用于音频处理任务,引入了“VH-Mixup”[18]混合示例数据增强方法。
首先,考虑以下形式的广义数据增强方法,即
(1)
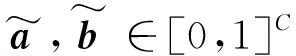
VH-Mixup是通过结合“垂直连接”“水平连接”和Mixup[19](或相当于BCL+[20]),并利用其优势,来进一步降低过拟合的风险。具体算法为:输入样本分别通过“垂直连接”和“水平连接”两两合并,再将两者结合,输出的两个结果作为中间值输入到Mixup中,每个中间值都有一个随机混合系数λ,最后可以得到混合示例,流程如图2所示。
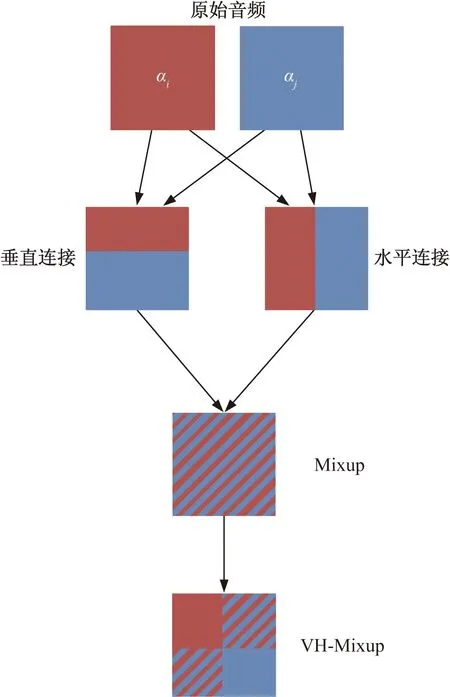
图2 VH-Mixup流程示意图Fig.2 VH-Mixup process diagram
图2中ai,aj∈RD为每个批量中的两个示例样本,左上角来自ai,右下角来自aj,左下角和右上角在两者之间混合,混合系数λ不同。总的来说,λ1、λ2、λ3服从于Beta分布,可以得到
(2)
式(2)中:F、T分别为示例的两个维度;a(r,c)为示例a的第r行、第c列的三维数组。
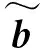
1.2 嵌入提取
为了更好地提取预处理之后得到的嵌入信息,本文设计了一种深度联合训练的神经网络。该网络由两个不同的子网络组成,分别对每个输入表示进行训练,共同区分Machine type、Section和不同的属性信息,总共产生342个分类。
首先,为了对应不同的分类任务,采用了多个不同的网络或损失函数,来捕获嵌入中存在的正常训练数据的所有信息。由于从预处理层得到的两种不同的输入表示的维度差异,因此采用了两种不同的子网络架构。对于log-Mel谱图特征表示,该子网络架构称为Mel-Resnet,是在ResNet-18模型的基础上进行了修改,其中s为步长大小,如图3所示;而对于幅值谱特征表示,采用3个一维卷积层和5个dense层组合的子网络架构,称为DFTnet。如图4所示, 通过此网络,可以更好地捕捉发出相对静止声音的工业机器的声音特征。而在整体的网络架构中,采用了子集群AdaCos损失函数[21],其主要思想是在每个类中使用多个集群,而不是单个集群,以便获得嵌入学习更复杂的分布。
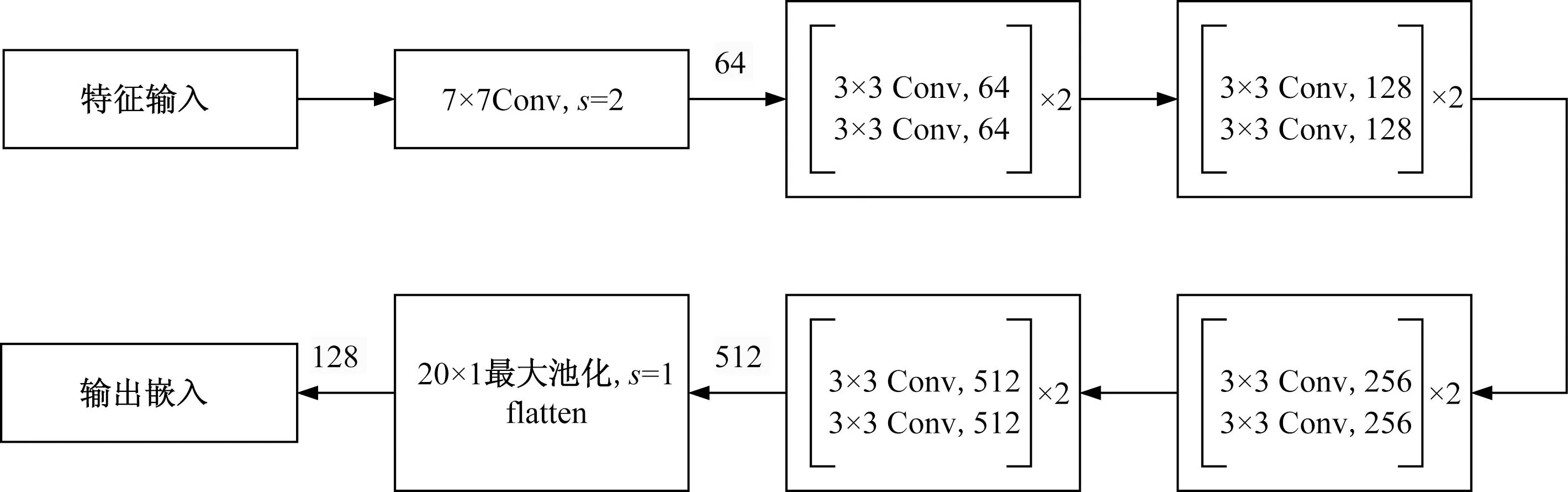
图3 Mel-Resnet子网络架构Fig.3 Mel-Resnet sub-network architecture

图4 DFTnet子网络架构Fig.4 DFTnet sub-network architecture
为了使模型能起到良好的泛化性能,如图3和图4所示,在嵌入提取模块中,对子网络架构进行了设计。
(1)具体来说,采取的策略是将批处理归一化层(batch normalization, BN)应用于块之前或flatten层之后,而不在卷积块内部,以避免学习特定簇到超球面的简单映射。
(2)随机初始化子集群AdaCos损失的簇中心。由于嵌入和簇中心都处在一个相对高维的空间,因此极可能是两两正交的,所以不必在训练期间调整它们。
(3)采用LeakyReLU的激活函数,有助于扩大 ReLU 函数的范围。其中,设定步长参数α=0.1[22]作为非线性。
然后,通过连接这两个子网络的输出(即嵌入),以获得每个文件的单个嵌入,确保两个网络都可以捕获到各自的特征表示,以区分类需要的所有信息。此时,嵌入对于异常声音会更加敏感,因为对于某些特定的异常,可能只在其中一个输入表示中表现显著,连接后的嵌入便可以利用多个特征表示来获得更多有用的信息。
1.3 异常评估
为了得到具有更少的病理特征的解,利用变分贝叶斯高斯混合模型(variable bayesian Gaussian mixture model, VBGMM)对从嵌入提取模块获取的嵌入进行异常分数的计算,将其产生的对数似然值用作异常评估,流程图如5所示。
与经典的GMM算法相比,该变分推理让模型可以自动选择合适的有效分量数量,更加稳定和需要更少的调优。VBGMM通过使用一种变分方法[23],将通过前端网络得到的嵌入进行训练,得到所有机器声音的异常分数。
首先,假设有N个独立同分布的数据:X={x1,x2,…,xN}。在贝叶斯学习中,所有参数都已经给定先验分布。这里用Z={z1,z2,…,zN}和T={t1,t2,…,tN}表示模型的潜变量和参数,并用Ω={Z,T}表示两者的集合。
对于给定的数据,边际对数似然定义为
lnp(X)=ln∬p(X,Z,T)dZdT
(3)
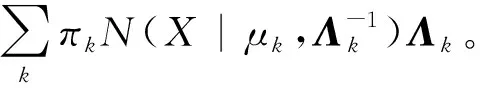
贝叶斯模型需要权衡拟合数据和模型的复杂度,具体流程如图5所示。通过一组超参数{θ}对参数分布进行建模,潜变量和参数q(Z,T|X,θ)存在后验分布。可以将边际对数似然表示为
(4)
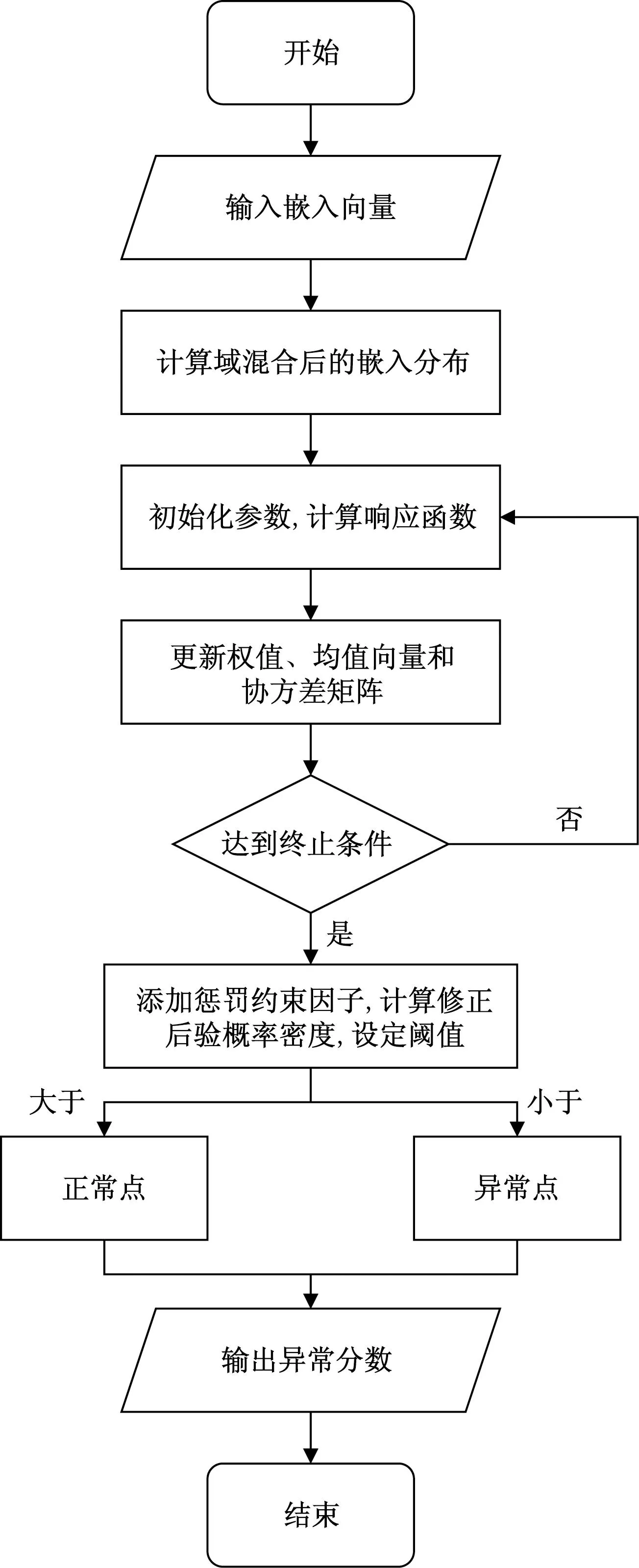
图5 VBGMM模型流程图Fig.5 Flow chart of VBGMM model
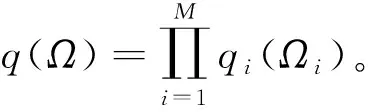
(5)
式(5)可以表示下界最大值的一组一致性条件。利用式(5)可以得到各因子的最优值q*(Z)、q*(π)、q*(μk,Λk)。由于这些数值的相互依赖性,可以用期望最大化法[23]来求解。其中,关于潜变量Z的最优值计算公式为
(6)
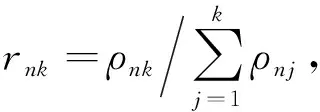
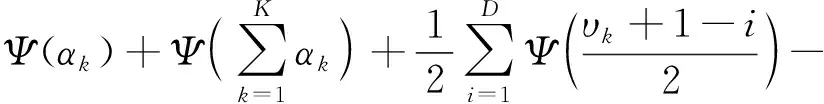
(7)
式(7)中:D为特征的维度;ψ为伽马函数。
计算出q*(Z)之后,再分别计算混合权值π、均值向量μk和协方差矩阵Λk的最优值。
q*(π)=Dir(π|α)
(8)
q*(μk,Λk)=N(μk|mk,(βkΛk)-1)W(Λk|Wk,υk)
(9)
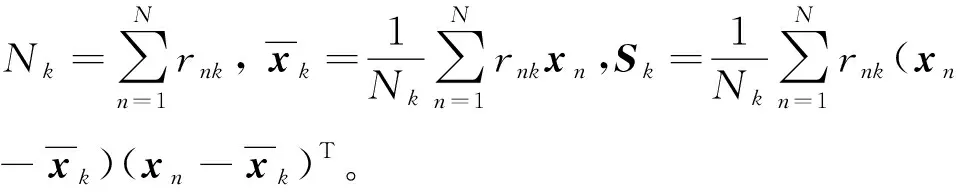
在这个过程中,对参数进行更新,更新公式为
(10)
βk=β0+Nk,υk=υ0+Nk
(11)
(12)
对给定测试数据的预测可以通过对式(3)中的参数进行积分来实现。对于VBGMM模型,后验分布混合系数的期望值为
(13)
在这个方程中,Kα0的值相对于N可以忽略不计。因此,当Nk≃0时混合系数的期望消失。通过设置先验α0的值,来最优化该模型的复杂度。
为了进一步提高GMM的域泛化能力,本文中还采用了一种称为域混合的技术。对于机器类型和section的每个组合,通过取两个嵌入的平均值,将与源域内的正常训练样本对应的每个嵌入和目标域的随机样本混合。因此,可以生成既不属于源域,也不属于目标域的附加训练样本。然后,用这些混合样本和源域的原始样本训练每个GMM,来学习到更独立于域的嵌入分布。
2 实验结果与分析
为了量化分析JDL-VGM方法中引入VBGMM模型、联合训练的网络架构、子集群AdaCos、VH-Mixup等方法对于工业设备异常声音检测性能的影响,本节针对Fan、Bearing和Valve三种不同的工业机器类型的异常声音检测问题进行了消融实验和对比实验。实验模拟的异常包括工厂噪声、阀门异常、机器噪声混合等。
2.1 数据集
本实验使用的声音数据均来源于DCASE-2022 Task2数据。这里选取其中三种工业机器类型,包括Fan、Bearing和Valve。该数据集分成训练集与评估集,每种机器类型的数据集中均包含6个不同的子集,对应不同类型的域转移,其数据构成如表1和表2所示。此外,还增加了正常训练样本的域和属性信息来定义机器的状态或不同类型的噪声。声音素材时长均为10 s且为单通道音频,采样率为16 kHz,包括真实的工厂噪声和目标机器声音。
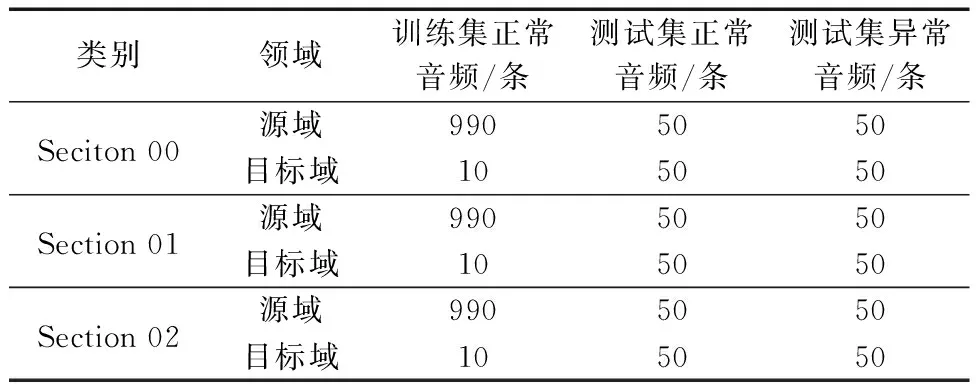
表1 训练集的统计信息Table 1 Statistics for the development datasets
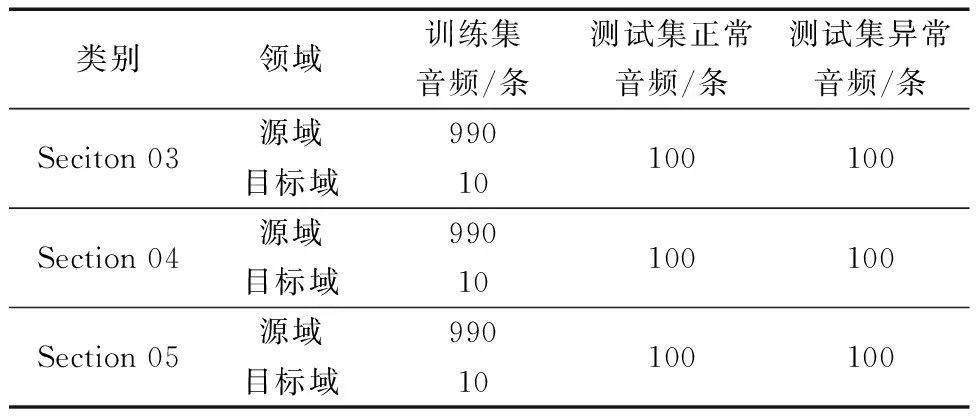
表2 附加的训练集&评估集的统计信息Table 2 Statistics for the additional development datasets &evaluation datasets
2.2 实验设置
本算法的网络采用Tensorflow2.3框架,训练的迭代次数均设置为400个epoch,训练集的batch size设置为64,测试集的batch size设置为32。并通过设置决策阈值,将在该阈值以上的属于同一种机器类型的测试样本的所有异常分数标记为异常样本,反之,标记为正常样本。其中,设置所有正常训练样本的异常分数的分位数为第90百分位。
2.3 评估方法
本实验通过AUC(ROC曲线下的面积)、F1分数和谐波平均值,三种指标对模型进行评估。AUC和F1分数均为异常检测中最为常用的指标。其中,AUC可以理解为模型将正常声音样本识别正确的概率大于将异常声音样本识别错误的可能性。因此,AUC越大,说明模型的准确率越高;反之,准确率越低。
每个域的平均AUC可以表示为
(14)
这里谐波平均值表示为hmean,具体计算公式为
hmean=h{AUCm,n,d,pAUCm,n,d|m∈M,n∈ζ(m),
d∈{source,target}}
(15)
式(15)中:h(·)为调和平均值(所有机器类型、section和领域);source为源域,target为目标域;M为机器类型集;ζ(m)为机器类型m的段集;pAUC为偏AUC。
F1分数是每个域的准确率和召回率的调和平均值。F1分数越大,说明模型的准确率越高;反之,准确率越低。具体计算公式为
(16)
式(16)中:P为准确率;R为召回率。
由于域泛化场景的识别异常的过程难以检测域转移的发生,因此,实验使用相同的指标对不同领域的不同机器类型进行评估。
2.4 消融实验
2.4.1 探究JDL-VGM的聚类性能
为了验证系统中提出的VBGMM模型的聚类性能,进行了消融实验。图6所示为采用变分方法的VBGMM模型和具有固定分量的GMM聚类效果的比较。其中,选用的机器类型设定为“Fan”,section ID为0~5,包括了11 940条数据。结果是一个多元正态分布矩阵,使用不同的颜色表示生成的簇,横纵坐标为正态分布的分位数。从图6所示实验结果可以看出,高斯混合模型为经典模型,被指定由6个簇组成;变分贝叶斯高斯混合模型被较明显分成7个簇,更符合Fisher线性判别,在聚类性能上要优于经典的GMM模型。
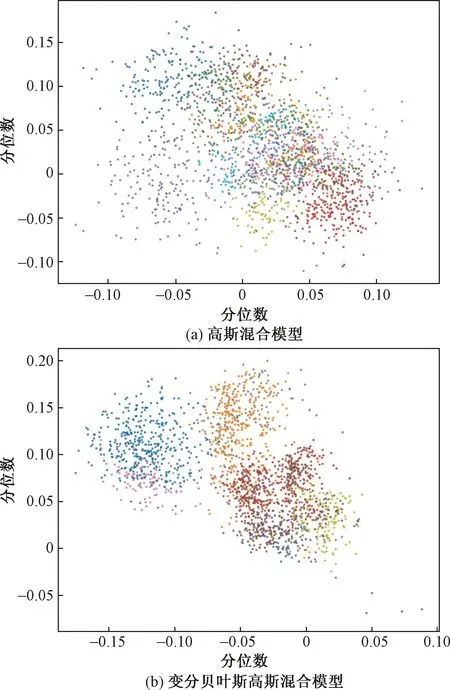
图6 聚类效果对比图Fig.6 Comparison of clustering effect
2.4.2 探究各组成模块的有效性
为验证提出的模型中不同模块对三种不同机器类型的有效性,在上述数据集上进行了消融实验,实验结果如表3所示。本实验以hmean为评价指标。

表3 探究不同模块对整个模型的影响Table 3 Explores the impact of different modules on the whole model
JDL-VGM-1:作为对照组,方便与其他实验进行结果的对比。如表3所示,与其他几组实验结果相较,VH-Mixup数据增强方法和VBGMM模块对整体模型的检测精度都有显著提升;较两种基线模型,提出的模块在三种不同的机器类型上均表现出更好的性能。
JDL-VGM-2:VBGMM对从JDL-VGM模型的神经网络中取得的嵌入进行聚类分析,为了展示VBGMM模型对JDL-VGM性能的影响,在JDL-VGM基础上将VBGMM模型替换为不含变分模块的GMM模型。如表3所示,相较JDL-VGM-3,JDL-VGM-2在机器类型fan和bearing上取得更优的h-mean值,在机器类型valve上性能较低。从整体上看,VH-Mixup数据增强方法和VBGMM模块对模型的提升效果相近。
JDL-VGM-3:即无VH-Mixup模块的JDL-VGM。由表3中的结果可知,与JDL-VGM相比,JDL-VGM在3个不同机器类型的数据集上均取得了更优的hmean,验证了JDL-VGM算法的有效性。
2.5 对比实验
本小节将提出的方法与其他算法进行比较,进一步验证提出算法的有效性。其中所采用的基线模型分别为Base-AE和Base-MobV2。前者将异常评分作为观测声音的重构误差计算,为了获得正常声音的小异常值,对自动编码器进行训练,使正常训练数据的重构误差最小化;后者使用了基于机器检测的异常评分计算器,通过训练MobileNetV2分类器[24],以确定观察到的信号是从哪个部分产生的。
表4所示为在评估集上所获得的ASD结果,并与两种基线模型进行了对比。对于所有的机器类型和领域,所提出的系统在AUC和F1分数评分方面都显著优于基线系统(其一),且在绝大部分情况下目标域的性能都接近甚至超越在源域获得的性能,并且要远高于随机猜测。然而,两个基线模型在预测某些目标域的异常声音时都表现较差,在某些情况下,AUC处在50%以下。但从结果上来看,所提出的系统的在域泛化场景下的性能都要远远优于基线。
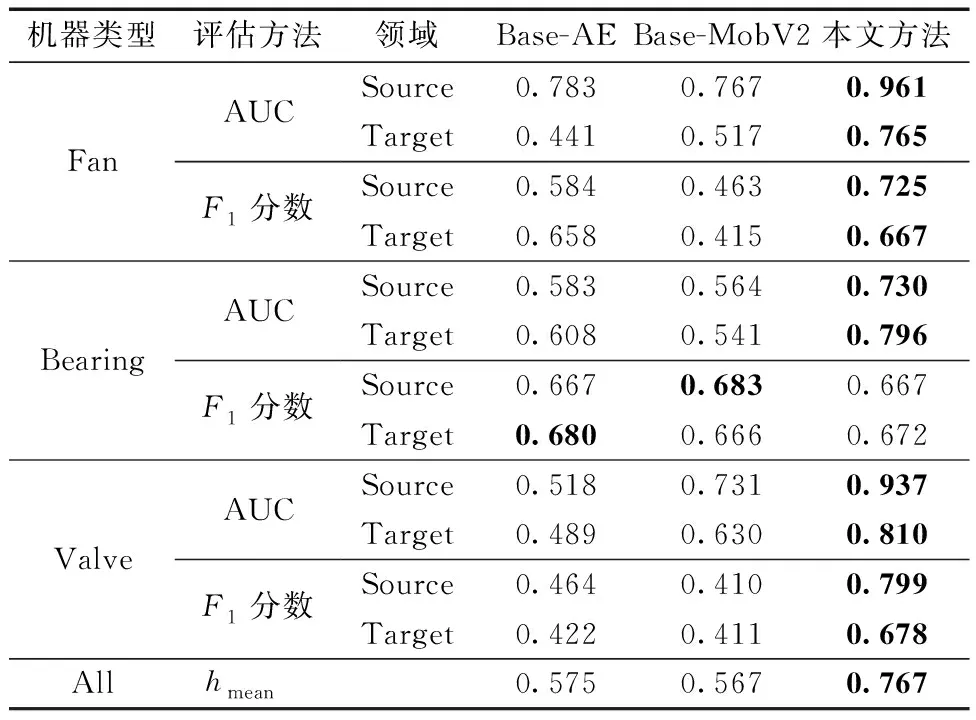
表4 评估集上不同机器类型的平均AUC&F1 scoreTable 4 Average AUC&F1 score of different machine types in the evaluation dataset
为进一步验证本文提出的算法有效性,对比测试了其他涉及域泛化场景下工业设备的异常检测算法模型[13]。本文与Gou_UESTC、Liu_BUPT、PENG_NJUPT、Li_CTRI和Cohen_Technion等几个经典的模型进行了比较。
Gou_UESTC[10]:这是一种由多级残差神经网络组成的网络,用于从片段的频谱中提取特征,并通过LOF估计特征的分布。
Liu_BUPT[25]:这是一种可以捕获分布密度的基于掩蔽自回归流的密度估计概率分布模型,利用MADE进行分布估计。
Peng_NJUPT[26]:该模型结合光谱相干性、log-Mel谱和小波包能量谱进行特征融合。
Li_CTRI[27]:该模型提出了一种集成基于CNN的特征和自动编码器的方法。
Cohen_Technion[28]:该模型基于黎曼距离,在每个聚类的中心训练一个支持向量机 (support vector machine,SVM)模型,用于检测异常。
训练结果如图7所示,列出了在评估集上不同方法在三种机器类型上的平均AUC对比。从结果上来看,所提出的系统在三种机器类型上都要优于其他算法。
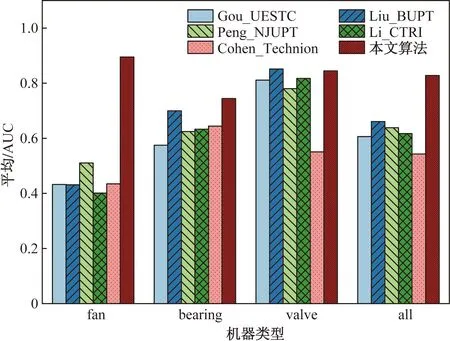
图7 评估集上在三种机器类型上的平均AUC的算法对比Fig.7 Comparison of average AUC of different methods on three machine types in the evaluation dataset
总体而言,消融实验和对比实验均验证了提出模型的各组成模块能有效提升异常声音检测的性能。
3 结论
本文提出了一种具有较强的域泛化能力的无监督异常声音检测系统。该系统基于一个经过子集群的AdaCos损失训练的神经网络来提取嵌入,由两个精心设计的子系统组成,利用log-Mel谱图和幅值谱作为特征表示,分别输入两个神经网络进行联合训练。同时提出了一种新的混合示例数据增强技术,该技术将源域和目标域的样本用多种方式相结合的替代方法生成示例,以提高模型的域泛化能力;最后,用VBGMM估计嵌入的分布以获得异常分数。实验结果表明,所提出的系统在源域和目标域上都显著优于基准系统,且高于大部分已提出的系统。在未来的工作中可以进一步借助外部信息(如属性信息)获得更有意义的合成表示,从而优化系统的整体性能。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
环球时报(2022-07-13)2022-07-13
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
环球时报(2022-03-14)2022-03-14
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
电影(2018年8期)2018-09-21
数学小灵通·3-4年级(2017年9期)2017-10-13
小猕猴智力画刊(2015年4期)2015-04-28
河南科技(2014年23期)2014-02-27
