
基于机器学习KNN方法的星云湖表层沉积物氮、磷元素空间分布及驱动因素研究
2024-02-27 02:05尹鹏飞贾雨欣尹继清张文翔
生物学杂志 2024年1期
熊 静, 尹鹏飞, 贾雨欣, 尹继清, 张文翔
(云南师范大学地理学部云南省高原地理过程与环境变化重点实验室, 昆明 650500)
近年来,伴随社会经济的快速发展,湖泊富营养化问题日趋突出,且研究表明氮、磷元素含量是关键影响因素[1-2]。对氮、磷元素空间分布研究常用的插值方法有普通克里金(Ordinary Kriging, OK)[3]、反距离权重(Inverse Distance Weight, IDW)[4]和核平滑(Kernel Smoothing, KS)[5]等。但由于传统插值算法大多对数据质量要求较高,需要对数据进行一定假设,若数据不符合假设条件,其预测值往往会产生较大偏差,同时还易受异常值影响而发生“牛眼”现象或“边缘效应”,所以一般不能保证插值结果的总体最优性,而出现预测误差较大的情况[6-7]。机器学习因其无需条件假设,而是凭借数据的时空依赖性,利用多元线性回归模型进行数值预测,以此获取更接近的样本数据等优势,在环境数据的模拟中得到越来越多的应用[8-9]。目前利用机器学习方法进行优化空间插值的研究已经比较成熟,包括K近邻(K-Nearest Neighbor, KNN)、随机森林(Random Forest, RF)及支持向量机(Support Vector Machines, SVM)等[10-11]。利用机器学习方法对气象干旱[12]、土壤有机质[13]、地下水盐度[14]和湖泊水体中营养物质[15]的空间插值,与传统插值方法比较,发现基于机器学习的插值算法误差显著减少[16]。但相对地理学其他领域已开展的机器学习模型研究,其在湖泊表层沉积物中的应用还有待进一步加强。云南高原湖泊水体富营养化是重要的环境问题,特别是滇中湖泊水体富营养化治理依然严峻[17]。前期通过对星云湖沉积物中有机碳、氮指数测定,并结合同位素示踪技术的相关研究发现,沉积物中有机物浓度与湖泊沿岸各种农业活动相关[18],且TN含量呈现逐年增大的趋势[19]。同时,基于熵值法对星云湖水质、富营养化、沉积物与水生生物等的研究,也得到了较一致的结果[20]。
本文通过对星云湖表层沉积物中氮、磷元素含量的研究,基于湖泊不同时期的营养盐数据及机器学习KNN算法对氮、磷元素的空间插值,分析机器学习KNN算法与传统IDW、OK及KS算法在空间插值特征与预测精度上的差异,探讨机器学习KNN算法在沉积物氮、磷元素含量预测的主要优势。研究结果将为机器学习算法在高原湖泊表层沉积物中的元素含量插值方法研究,以及低纬高原湖泊生态保护提供一定的科学依据与参考。
1 材料与方法
1.1 研究区概况
星云湖位于云南省玉溪市江川区(24°17′~24°23′N,102°45′~102°48′E)[图1(a)],为高原浅水湖泊。湖区总面积34.71 km2,平均水深约4.7 m[21]。由于受西南季风、西风和青藏高原的共同影响,形成北亚热带半湿润高原季风气候,降水主要集中在每年5—10月间[22]。流域内土地利用类型主要为林地与耕地,且磷矿开采活动聚集,开采总面积为741.73 hm2,生态环境受人类活动影响较大,水质污染较重、富营养化严重[23][图1(b)]。
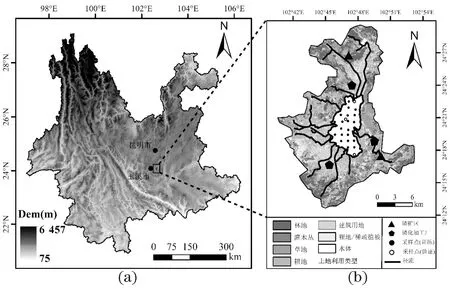
(a) 星云湖在云南省的位置; (b) 星云湖流域土地利用类型及采样点。图1 研究区采样点分布Figure 1 Distribution of sampling points in the study area
1.2 样品采集与分析
根据湖泊形态、面积等特征,以1 km2为控制单元在湖区内布设网格化采样区域,并于2020年8月,采用UWTTEC重力式柱状采样器[24],在湖区内获得沉积岩芯23个[图1(b)],取水-沉积物界面0~5 cm的沉积物装入密封袋带回实验室。
样品在云南省高原地理过程与环境变化重点实验室内经冻干过筛后,利用凯氏法在全自动凯氏定氮仪(K1100)上完成TN含量测定;TP含量则采用碱熔-钼锑抗分光光度法[25]利用分光光度计(UV-1750)测定。土地利用类型数据主要来源于欧洲航天局公布的2021年全球土地利用数据集(https://viewer.esa-worldcover.org/worldcover),其分辨率为10 m。
1.3 KNN法
KNN是一种常用的基于实例学习的机器学习监督算法,其通过构建特征向量来选取最接近的样本进行回归或分类[26]。对给定测试的样本,基于某种距离度量找出训练集中与其最接近的K个训练样本,并以K个“邻居”的信息为基准进行预测,其距离度量用Lp表示,具体公式如下:
D={(x1,y1),(x2,y2),…,(xm,ym)}
(1)
xi=(xi(1),xi(2),…,xi(n))
(2)
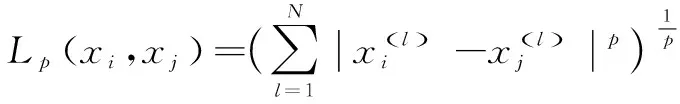
(3)
式中,D为训练数据集,m为样本数,y为不同样本对应类别,且不同样本间有n个特征,xi为样本的特征向量,p为指数,权重对距离较近的点影响大于距离较远的点,p指数越大,距离越近的点影响越大。
2 结果与分析
2.1 湖泊沉积物TN、TP空间分布特征
通过利用IDW、OK、KS和KNN模型,重建的星云湖表层沉积物TN含量的空间分布特征表明(图2),TN含量在0.56%~0.86%波动,平均值为0.71%;IDW、OK、KS和KNN模型,空间插值得到的星云湖表层沉积物TN含量空间分布总体上呈现一致的趋势,表现出氮含量由湖区西南部向东北部逐渐减少的趋势。
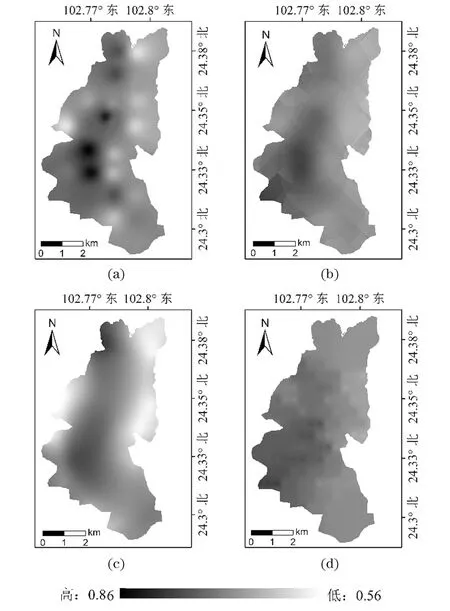
(a) IDW; (b) OK; (c) KS; (d) KNN。图2 星云湖TN空间分布特征Figure 2 Spatial distribution characteristics of TN in Xingyun Lake
同时,基于IDW、OK、KS和KNN模型获得的星云湖表层沉积物TP含量为0.57%~0.91%(图3),平均值为0.78%,磷含量的空间分布均表现出由东至西递减的趋势,其中,湖区东北部为高值区,西部为低值区。
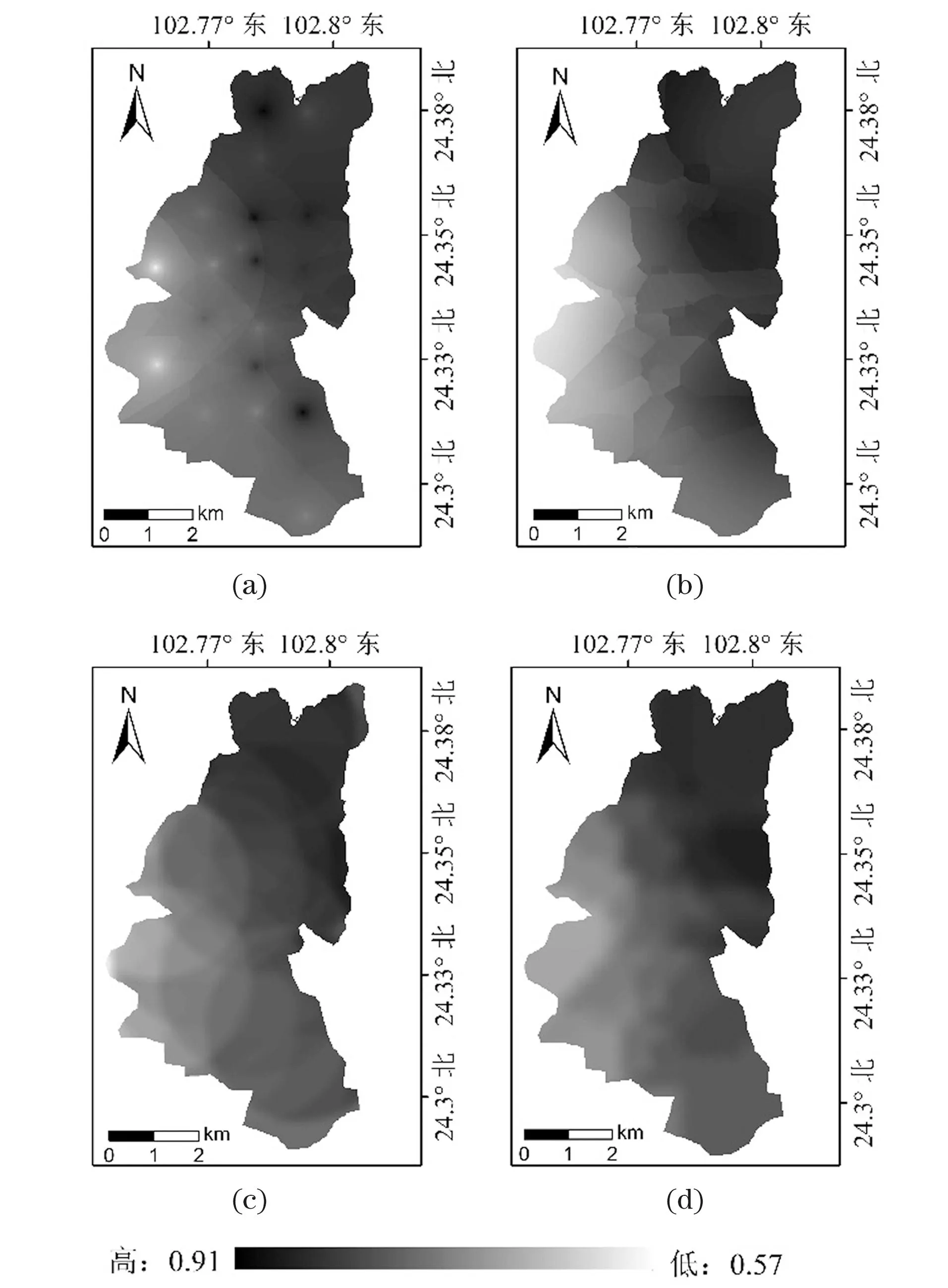
(a) IDW; (b) OK; (c) KS; (d) KNN。图3 星云湖TP空间分布特征Figure 3 Spatial distribution characteristics of TP in Xingyun Lake
2.2 湖泊沉积物营养元素插值结果对比
基于各模型空间插值得到的星云湖表层沉积物氮、磷元素的空间分布趋势整体一致,但局部存在差异:使用IDW算法进行空间插值时“牛眼”现象最为明显,KS的平滑效应突出,OK出现条带状的空间分布特征,而使用KNN算法对局部湖区分布细节有明显的改善,空间分辨率更高,能清晰呈现其变化分布趋势的同时,细节信息更突出。实测数据极值的预测中,TN极值为0.589%和0.863%,对应IDW预测值为0.54%和0.733%,OK为0.766%和0.727%,KS为0.683%和0.729%,KNN为0.706%和0.768%;TP实测极值为0.57%和0.91%,IDW为0.768%和0.77%,OK为0.72%和0.78%,KS为0.748%和0.774%,KNN为0.694%和0.803%。可明显看出,无论是对极大值或极小值的预测,KNN的预测误差是最小的、最接近实测数值,预测空间梯度最大。
基于平均绝对误差(Mean Absolute Error, MAE)、均方误差(Mean Square Error, MSE)、最大残差(Max Error)等误差评价指标分析,对KNN、KS、OK和IDW等4种不同算法模型的空间插值结果与真实值间的误差比较发现(表1),机器学习KNN算法对TN和TP的插值误差均是最小的,对应MAE、MSE及Max Error分别为0.045、0.004、0.133和0.035、0.002、0.113;而IDW的预测误差最大,分别为0.070、0.007、0.165和0.062、0.006、0.190,误差精度表现为KNN>KS>OK>IDW。其中,KNN模型插值的TP含量误差指数(MAE、MSE和Max Error)相较IDW、OK和KS分别下降了43.5%、66.7%、40.5%,37.5%、60.0%、21.5%和35.2%、50.0%、13.7%;而TN含量误差指数则分别下降了35.7%、42.9%、19.4%,33.8%、42.9%、24.9%和25.0%、33.3%、0.7%。
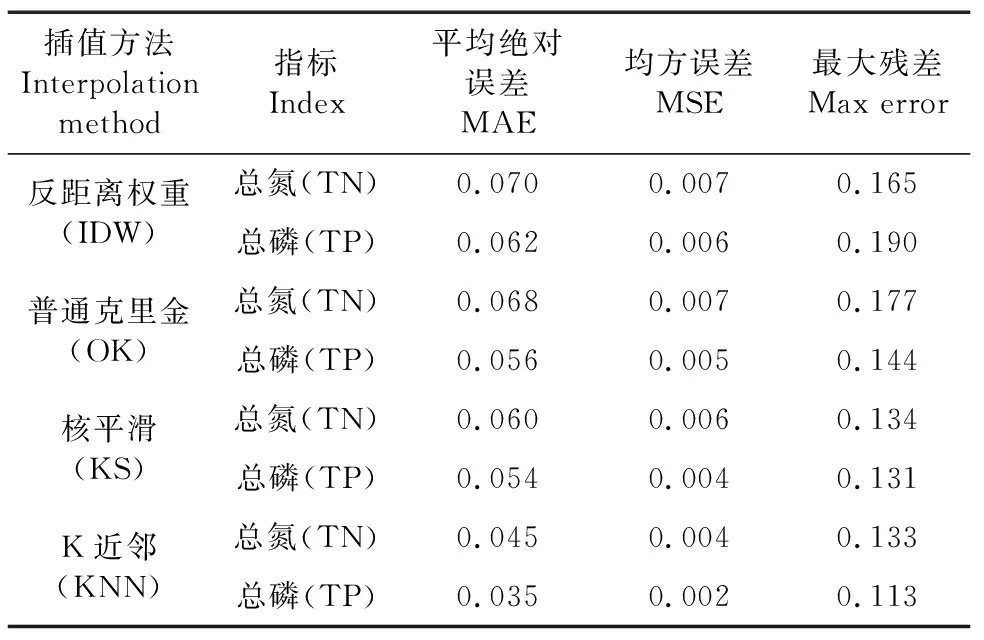
表1 不同空间插值算法预测精度Table 1 Different spatial interpolation algorithms predict accuracy
2.3 不同时期星云湖TN和TP空间差异
为进一步验证机器学习KNN算法在不同时期、不同氮和磷浓度下的插值误差,通过对已有星云湖营养盐相关研究结果[18-19],并利用上述4种插值模型对其进行空间插值(图4),且基于MAE、MSE和Max Error等指标评估各自误差。研究结果表明(表2),机器学习KNN算法依旧是4种空间插值算法模型中表现最优的,其预测误差最小、预测精度最高。IDW、OK和KS模型预测的TN及TP含量空间插值误差较大,约为KNN插值模型的2~42倍。同时,研究还表明不同时期的沉积物中氮、磷元素含量存在较大差异,呈现增大的趋势。对比不同时期氮、磷元素空间插值的预测精度,机器学习KNN算法的预测精度在4种插值算法中均是最优的,但其在低浓度范围区间内的预测误差更小,此时TN、TP对应的预测均方误差值分别为9×10-4和1×10-4。
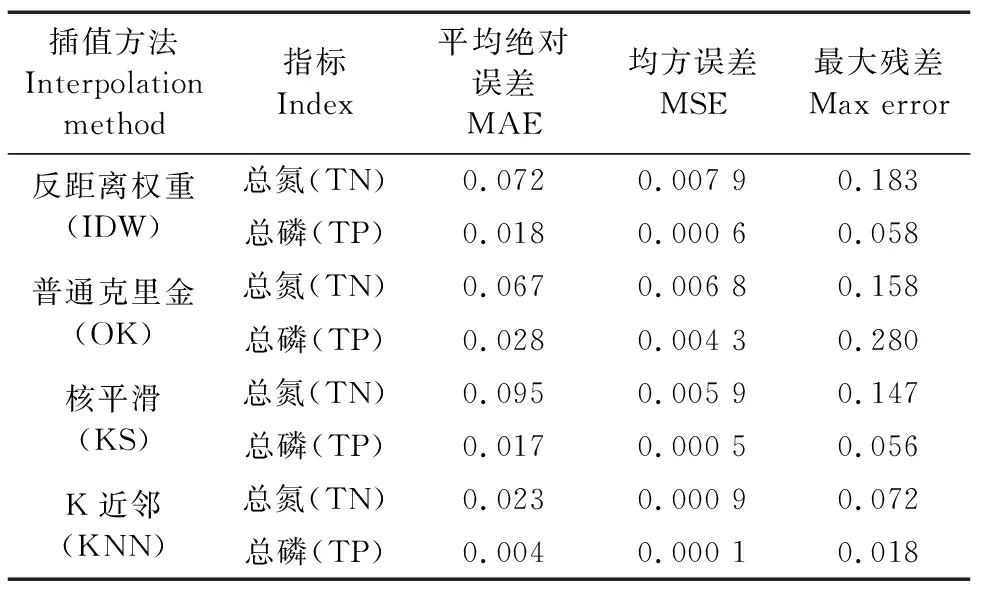
表2 不同空间插值算法预测精度Table 2 Different spatial interpolation algorithms predict accuracy
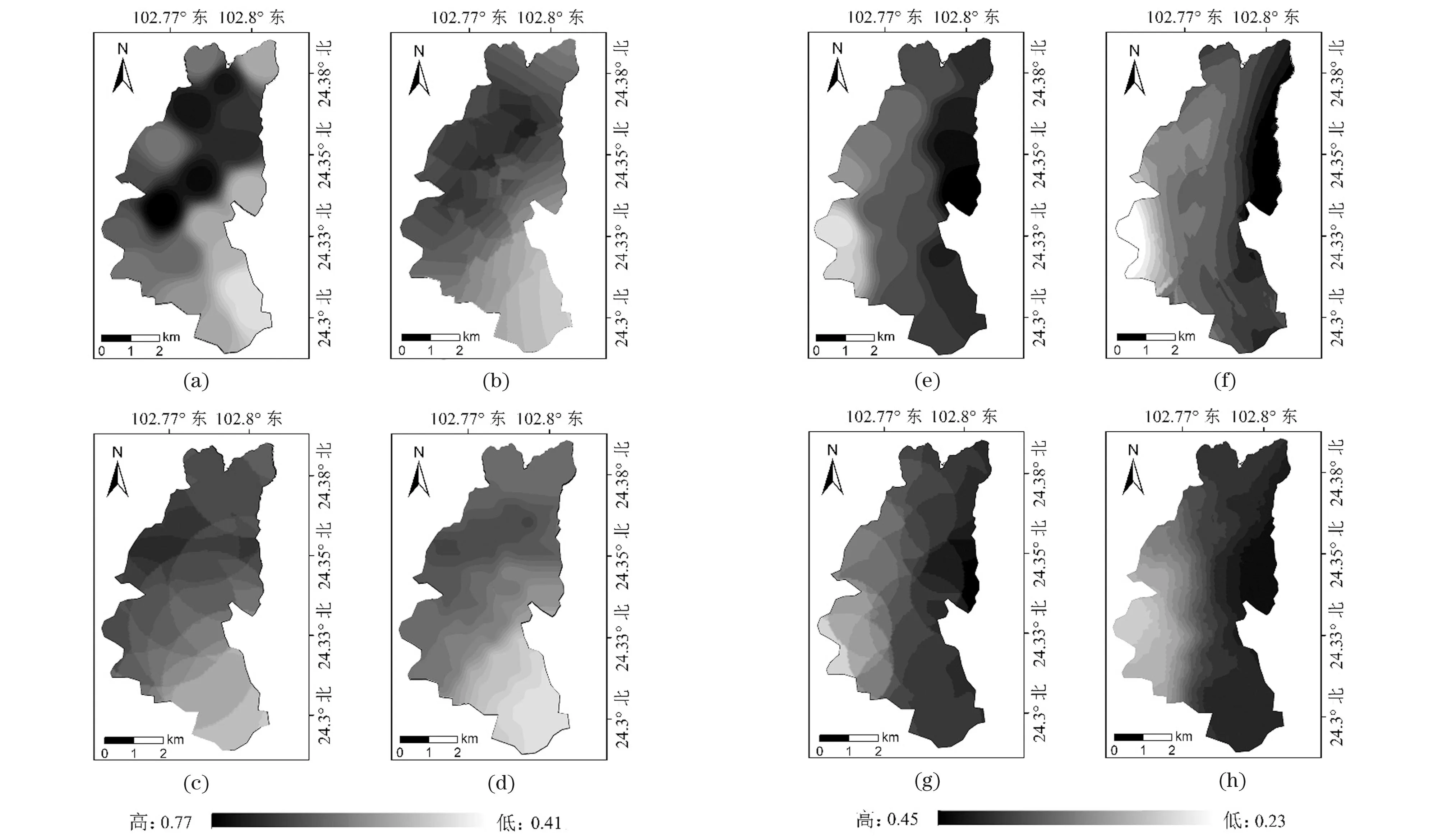
(a)TN的IDW插值; (b) TN的OK插值; (c) TN的KS插值; (d) TN的KNN插值;(e)TP的IDW插值; (f) TP的OK插值; (g) TP的KS插值; (h) TP的KNN插值。图4 2019年星云湖表层沉积物TN、TP空间分布特征(数据来源于文献[19])Figure 4 Spatial distribution characteristics of TN and TP in surface sediments of Xingyun Lake in 2019 (data source literature[19])
3 讨论
由于常规方法无法同时对空间内的所有点进行观测,只能通过获取一定数量的空间样本,并据此预测未知地理空间的特征。因此,湖泊营养盐浓度的空间内插方法,对污染物分析的研究及生态保护具有十分重要的实际意义[27-28]。通过对比机器学习KNN与KS、OK和IDW等4种不同插值算法所获得的星云湖表层沉积物氮、磷元素含量来看,基于机器学习的KNN方法较其他方法在空间插值上更接近实测值、误差更小,对应预测精度更高。同时对比不同时期星云湖表层沉积物氮、磷元素的空间插值结果可知,在氮磷元素空间浓度整体较低时利用机器学习KNN算法的预测值与实测值的误差更小。治理湖泊的重点是降低湖泊富营养化指数,在此趋势下KNN算法的优势更为突出,它可有效代替传统插值算法进行空间预测,从而保证空间预测的准确性,为湖泊富营养化治理提供重要参考。湖泊水体与沉积物中的营养元素分布常受到自然与人类活动等多种因素的共同影响,不同区域的湖泊沉积物营养元素在空间分布上可能存在显著差异,而IDW、OK等算法在插值前需要对数据进行一定的假设,这往往使预测结果与实际数值间存在显著的偏差。相反,机器学习KNN算法所建立的模型结构是根据湖泊中的氮、磷元素含量的真实数据来决定的,能有效避免条件假设对预测数据的影响,较好地减少湖泊沉积物氮、磷元素在插值过程中存在的“高值低估,低值高估”问题,以及极值凸显的“牛眼”或过度平滑引起的“边缘效应”等现象,整体表现出较好的预测空间梯度性。此外,相较我国其他区域的湖泊研究,云南高原连续、大范围的湖泊表层沉积物营养盐研究数据还较少[29],而KNN算法在运算过程中,除较为快捷高效以外,还可同步处理可能的数据缺失[30]。这也在一定程度上弥补了云南高原湖泊沉积物中氮、磷元素研究的不足,体现其广泛适用性。虽然利用机器学习KNN算法在滇中星云湖不同时期的表层沉积物氮、磷元素的空间插值中均获得了较好的结果,但如何进行自适应选择k值,使其具有最小分类误差等仍有待进一步研究分析。
同时,星云湖表层沉积物氮、磷元素含量的空间分布与流域土地利用具有较好的相关性[31],本文研究结果与前人研究结果[19]在空间总体分布趋势上整体相近,这与近年来湖区西部沿岸人口聚集、农业活动持续增强[19],且受湖流作用沉积于西部湖区水深较大处有关。而营养盐含量的不断增大,说明近年来星云湖湖泊富营养化程度仍在持续加剧[32],湖泊水质仍需科学的、有效的方法进行持续缓解与改善,而流域内的磷矿开采[33]与农业面源污染仍是当前星云湖污染治理亟待解决的问题[34]。
4 结论
通过对星云湖表层沉积物中氮、磷含量的分析,并基于KNN与IDW、OK及KS等方法的误差分析,研究了星云湖表层沉积物氮、磷元素的空间分布特征及其驱动机制,探讨了机器学习KNN算法与传统插值方法在湖泊表层沉积物氮、磷元素含量预测的优势。
(1)星云湖表层沉积物中TN平均值为0.71%,TP含量平均值为0.78%,与前人研究结果相比,含量整体呈现出增加的趋势;氮含量呈现由西南部向东北部逐渐减少的趋势,而磷含量为由东至西递减的空间分布特征,且湖泊表层沉积物中氮、磷元素的空间分布深受流域内土地利用类型、农业面源及湖泊自然要素的影响。
(2)对比不同时期的KNN和KS、OK、IDW各算法模型的空间插值结果评估发现,基于机器学习的KNN算法对星云湖表层沉积物氮、磷元素空间插值预测的平均绝对误差、均方误差、最大残差等评价指标在4种插值模型中均为最小,表现出拟合精度最高、误差最小的特性,且在氮、磷元素浓度较低时的空间预测误差更小、准确性更高。KNN无需条件假设、可同步处理数据缺失的特性,在现阶段将能够有效地弥补云南高原湖泊沉积物中氮、磷元素研究的不足,将有利于更为深入地开展低纬高原湖泊表层沉积物营养盐空间分布特征及影响要素的研究。
致谢:感谢梁秋实博士、刘圣之硕士等在野外样品采集与分析研究过程中给予的帮助与支持。
猜你喜欢
思维与智慧·下半月(2022年5期)2022-05-17
女报(2019年5期)2019-09-10
少儿美术(快乐历史地理)(2019年4期)2019-08-27
西南石油大学学报(自然科学版)(2019年1期)2019-01-28
阅读(低年级)(2018年4期)2018-05-14
小学阅读指南·低年级版(2017年2期)2017-03-23
百科探秘·航空航天(2016年12期)2017-01-15
百科探秘·航空航天(2016年9期)2016-12-01
电测与仪表(2016年10期)2016-04-12
电测与仪表(2016年14期)2016-04-11
