
注意力机制的TS-PVAN双流动作识别
2024-02-27 09:02郭佳乐胡天生史士杰陈恩庆
小型微型计算机系统 2024年2期
郭佳乐,胡天生,史士杰,陈恩庆
(郑州大学 电气与信息工程学院,郑州 450001)
0 引 言
近年来,基于深度神经网络的视频级人体动作识别作为计算机视觉领域的研究热点,已经取得了巨大进展.不同场景下与视频动作识别相关的应用也越来越广泛[1],例如视频监控、自动驾驶、智慧医疗等.
目前,基于卷积神经网络的动作识别主要通过两种方法实现,一种是使用双流网络,分别将RGB帧与光流数据作为两流的输入以提取动作的时空信息.另一种是使用3D卷积[2]或时间卷积[3]从RGB帧学习运动特征,然而这种方式通常会带来较高的计算成本.
双流网络是动作识别领域中识别效果较好的一种方法.Simonyan[4]等人首先提出了具有时空结构的双流网络,以RGB帧作为空间流的输入,以堆叠的连续几帧光流作为时间流的输入,分别提取动作发生过程中的空间信息和时间信息,空间信息包括外观特征、位置等,时间信息则包括通过光流表示的相邻帧之间的运动特征.然而,双流网络无法利用视频长期时间信息,Wang[5]等人提出一种时间分割网络(TSN)以对视频长时间结构建模,但该网络仅在最后阶段进行了时间融合,同样未能捕获更精细的时间结构,TSN网络模型结构如图1所示,将视频分为3段,分别经过空间流与时间流网络,最后进行双流融合.此外,传统的双流方法通常采用相同的卷积网络对RGB与光流数据进行处理,忽略了不同卷积网络对不同模态数据的处理能力不同,Bai[6]等人提出了一种时空异构双流网络模型,为双流设计不同的卷积网络.

图1 TSN网络结构Fig.1 TSN Network Structure
3D卷积的方法也通常用于视频动作识别任务中,三维卷积主要是对二维卷积在时间维度上进行扩展,能够同时从视频中获取视频动作的空间和时间特征.C3D是一种经典3D卷积网络,该网络中所有3D卷积核的大小均为3×3×3,并通过实验证明将卷积核设置为三维的情况下提取特征的能力更强.由于ResNet网络的发展,提出一种三维残差网络3DResNet,将三维卷积神经网络结合残差网络ResNet而构成,将ResNet中的残差模块引入到三维卷积网络中,并通过实验验证了模型的有效性.
在深度学习领域中,模型通常需要接收和处理大量的数据,然而在特定的某个时刻,往往只有少部分的某些数据是重要的,这种情况就非常适合使用注意力机制来解决问题,能够关注有用的信息而忽略无效内容.近年来,注意力机制也被广泛应用在动作识别领域中,根据注意力施加的维度大致可以划分为通道注意力和空间注意力两种,典型的通道注意力网络如SENet[7]、GCNet[8]等,通过对各个特征通道的重要程度建模,针对不同的任务增强或抑制不同的通道,CBAM[9]双重注意力机制将通道注意和空间注意相结合,能够显著提升模型的性能.此外,目前基于双流网络的研究工作有,Liu[10]等人提出一种残差时空注意网络(R-STAN),使网络更加关注区分性的时间和空间特征.Huang[11]等人提出一种压缩视频识别的压缩域双流网络(IP TSN),大大提高效率和精度.Du[12]等人基于主成分分析方法,提出一个交互感知自我注意模型(ISTPAN),能够有效学习注意图.Shou[13]等人针对光流提供的运动表示,提出一种能实现更具辨别力运动线索的生成器网络.
由于双流网络与注意力机制的发展,本文发现两个不足之处:1)TSN双流网络中简单地使用卷积网络提取特征,仅关注于动作的局部特征,忽略了视频动作中空间长距离依赖关系的重要性,比如在打篮球的动作中,需要关注手部和脚步的同步变化,如果缺乏长距离动作变化关系,则可能被误判为打招呼或跑步,而注意力机制的引入有利于获取动作的长距离依赖关系;2)卷积网络处理RGB帧时空间维度的降低通常会带来特征损失,视频背景噪声也会对动作识别的准确性造成影响,而噪声信息也可以通过注意力的方式弱化其不良影响.因此,如何利用注意力机制,设计更加高效的网络以提取丰富的动作空间特征对于视频动作识别任务具有重要意义.
本文针对以上两个问题,提出一种注意力机制的TS-PVAN双流动作识别模型.在TSN双流框架的基础上,为空间流设计P-VAN网络作为空间主干网络,主要由视觉注意网络[14](Visual Attention Network,VAN)与极化自注意力模块[15](Polarized Self-Attention,PSA)构成,结合异构的思想,时间主干网络仍选取卷积网络BN-Inception[16]处理光流数据.该模型能够捕获空间上的长距离依赖关系,有利于动作特征的提取,同时减少空间维度降低造成的特征损失,降低视频背景噪声对识别效果的影响,最终提升动作识别模型的准确率.此外,在两个数据集HMDB51[17]和UCF101[18]上的实验结果验证了本文所提模型的有效性.下面首先介绍VAN网络,其次介绍极化自注意力模块PSA,然后介绍基于注意力机制的TS-PVAN双流动作识别模型,最后给出实验结果和分析.
1 注意力机制的TS-PVAN双流动作识别
本文提出一种注意力机制的TS-PVAN双流动作识别模型,其网络结构如图2所示.其中,处理RGB帧的空间流主干网络P-VAN由视觉注意网络[14](VAN)与极化自注意力模块[15](PSA)构成,结合异构的思想,时间流仍选用BN-Inception[16]卷积网络处理光流数据.本文将给定的动作视频均匀分成k段(设置k=5),再抽取其视频帧作为网络的输入,然后提取动作特征并分类,最后融合双流网络的时空特征,得到动作的最终识别准确率.本节首先介绍视觉注意网络VAN的优点及基本结构,再介绍极化自注意力模块PSA的构成,最后介绍P-VAN网络以及注意力机制的TS-PVAN双流动作识别模型.
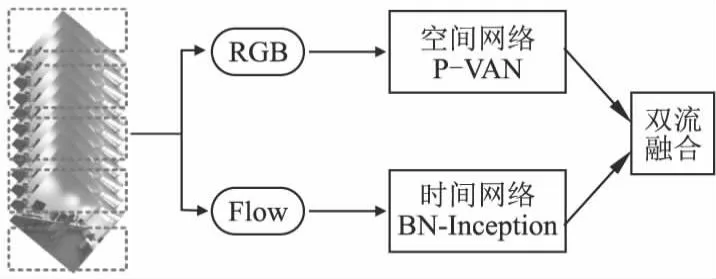
图2 注意力机制的TS-PVAN双流动作识别模型Fig.2 TS-PVAN two-stream action recognition model based on attention mechanism
1.1 视觉注意网络(VAN)
近年来,由于卷积神经网络具有强大的特征提取能力,成为计算机视觉领域的主干网络之一,应用于各种视觉任务中能显著提升模型性能,包括目标检测[19]、图像分类[20]、姿态估计和语义分割等领域.最近的研究表明,注意力机制可以看作是一种自适应选择输入特征的过程.文献[21]最早提出将注意力机制应用于视觉领域中,进行图像分类任务.文献[22]将注意力机制应用在自然语言处理领域,通过构建注意力模型来进行机器翻译,并且取得了效果的提升.此外,自注意力模型[23](Transformer)的提出完全舍弃了RNN和CNN这样的卷积网络结构,只使用注意力机制进行机器翻译,达到的效果也不错.自注意力机制的关键问题是生成注意图,以表示不同点的重要性,得益于其强大的建模能力,基于Transformer[23]的视觉主干网络迅速应用到各类计算机视觉领域中,并取得了不错的效果,比如在ViT[24]方法进行图像分类任务时,当训练数据集足够大时,分类准确率能够超过resnet网络的最好结果,在VAN网络做图像分类任务时,准确率相比resnet提升了6.3%,验证了自注意力机制相比卷积网络的有效性.
针对第一个问题,如何能够避免由忽略长距离动作特征关系而引起的误判问题,研究发现卷积神经网络与自注意力模型中的不足之处,卷积方法主要提取局部特征,缺乏适应性和长程依赖性,而自注意力方法虽然能够捕获长程依赖关系并具有空间维度的适应性,但是忽略了局部特征及通道适应性,结合两者的优点能够有效地解决所提问题.Guo[14]等人提出一种视觉注意网络(Visual Attention Network,VAN),主要由大核注意模块(Large Kernel Attention,LKA)构成,通过分解一个大核卷积运算以捕获长程关系,该模块结合了卷积网络与自注意力的特点,同时具有局部感受野、长程依赖性、空间适应性及通道适应性等优点,能够在视觉任务中达到更好的性能.
因此,本文考虑使用视觉注意网络VAN替换原来采用的卷积网络模型,以解决卷积网络仅关注动作的局部特征,忽略长距离特征信息而带来的相似性动作误判问题.值得注意的是,本文改进的部分仅针对用于提取动作特征的空间主干网络.VAN网络主要具有4个阶段的层次结构,其中一个阶段的基本结构如图3所示.
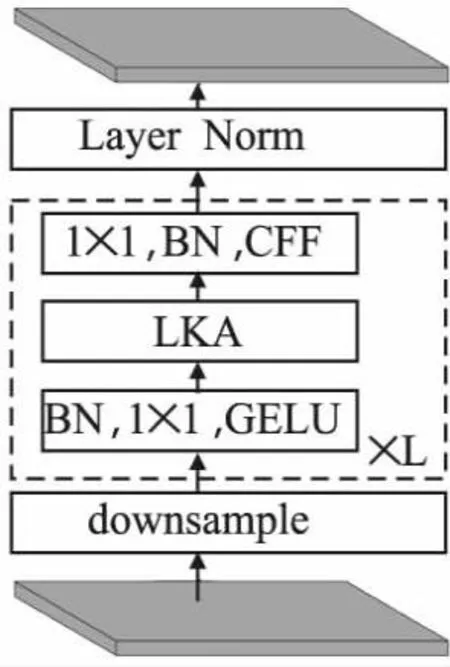
图3 VAN网络结构Fig.3 Network structure of VAN
由图3网络结构可知,该网络结构由底部输入数据,依次向上传输,其中L表示一个阶段中虚线框中所选部分模型结构的叠加次数.在VAN的每级结构中,首先对输入数据进行下采样操作,并使该阶段中的其他层均保持相同的输出大小,即空间分辨率和通道的数量总和不变,当输入数据的形状尺寸为H×W×C时,每级网络的输出空间分辨率分别降低为H×W的1/4,1/8,1/16和1/32倍,同时输出通道数量随着分辨率的降低而增加,其中,H和W分别表示输入图像的高度和宽度.然后,再将输出部分经过BN(Batch Normalization)层、GELU激活函数、大核注意模块LKA和卷积前馈网络CFF(Convolutional Feed-Forward)按L组顺序叠加的结构以提取特征.最后,在每个阶段的末端应用Layer Norm层.
VAN网络中最关键的部分是LKA模块,其结构如图4所示.其中DW-Conv(Depth-Wise Convolution)深度卷积即空间局部,可以利用图像局部上下文信息,用于提取视频动作的局部特征,DW-D-Conv(Depth-Wise Dilation Convolution)深度扩展卷积即空间长程卷积,提供了深度方向的扩张卷积,有利于捕获动作中长距离的依赖关系,Attention注意力机制和1×1 Conv的结合实现了网络的空间适应性及通道适应性.LKA模块可以表示为:

图4 LKA网络结构Fig.4 Network structure of LKA
Attention=Conv1×1(DW-D-Conv(DW-Conv(F)))
(1)
Output=Attention⊗F
(2)
其中F∈RC×H×W是输入特征,Attention∈RC×H×W表示注意力图,图中的值代表每个特征的重要性,⊗代表元素乘积.
如上所述,LKA模块结合了卷积与自注意力模型的优点,能够获取空间动作的长距离关系,利于解决本文所提出的卷积网络忽略动作长距离依赖关系进而导致误判的问题.
1.2 极化自注意力模块(PSA)
针对第2个问题,本文发现在卷积操作提取RGB帧信息的过程中,通常会降低空间维度以提高通道维度,然而空间维度的降低不可避免地会造成空间特征损失,同时视频背景噪声也可能会对动作识别的准确性造成消极影响,因此本文考虑在将动作视频输入视觉注意网络VAN进行特征提取之前,首要处理好特征损失的问题以及减少背景噪声带来的负面影响.
研究发现像素级任务中能够对高分辨率输入或输出特征的远距离依赖关系进行建模,并且能估计其高度非线性的像素语义,是计算机视觉领域的一项重要任务[25].其中,像素回归问题中相同语义的像素外观和图片形状是高度非线性的,目标是将具有相同语义的每个图像像素映射到相同的分数,例如将背景像素分别映射到0,将所有前景像素分别映射到它们的类索引.受此启发,本文认为像素级任务中更关注于图像的细节内容,回归任务可以有效增强或抑制部分特征,因此本文考虑利用像素级任务中的方法解决视频动作识别中的问题.
Liu[15]等人提出一种极化注意力模块(Polarized Self-Attention,PSA),用于突出或抑制部分特征信息,这与光学透镜过滤光的作用相似,由于摄影中横向总会有随机光的产生影响图像质量,而极化滤波仅能通过与横向正交的光,这样便可以提高照片的对比度.极化注意力模块PSA中主要有两个重要设计部分,第1点是极化滤波,使得图像在一个方向上的特征能够完全折叠,同时在其正交方向上保持高分辨率,其主要作用是在通道和空间两个分支中,分别保持较高的分辨率,降低由空间维度降低带来的特征损失.第2点是增强部分,采用Softmax进行归一化,再使用Sigmoid函数增加注意力的动态范围,能够更加真实的拟合输出分布.本文使用并联形式的PSA模块,主要有两部分组成,左边为通道分支,右边为空间分支,分别以C×H×W作为输入特征,其结构如图5所示.

图5 PSA模块结构Fig.5 Module structure of PSA
由图5可知,PSA模块主要有通道和空间两个分支.在通道分支中,先将输入特征X经过1×1的卷积后转换为Q和V,Q的通道被全部压缩,而V的通道保持C/2.经过Softmax函数后对Q的信息进行增强,并增加注意力的范围,然后将Q和V做矩阵乘法运算,再经过1×1卷积、LN层将通道数量升为C,最后使用Sigmoid函数进行动态映射,使所有参数保持在0~1之间.在空间分支中,不同的是将Q特征的空间维度压缩为1×1的大小,而V特征的空间维度保持为H×W,同样采用Softmax增强Q的信息,以及Sigmoid使得参数在0~1之间.
如上所述,极化自注意力PSA模块能够降低由空间维度降低造成的特征损失,同时可以实现减小图像的背景噪声,对于有效解决本文所提视频动作识别任务中的问题起着重要作用.
1.3 注意力机制的TS-PVAN双流动作识别
由于传统的卷积神经网络主要提取动作的局部特征信息,缺乏通道、空间的适应性及长程依赖性,虽然在卷积网络中加入通道和空间注意力可以实现通道及空间适应性,但同样缺乏长程依赖性.有关研究表明自注意力模型能够对长程依赖关系进行建模,这在视觉任务中非常重要.同时本文注意到2.1节介绍的VAN网络结合了卷积网络与自注意力模型的优点,不仅能够提取动作的局部特征、实现通道及空间的适应性,还能捕获空间长距离依赖关系,适用于各类计算机视觉任务,并有利于解决处理视频动作识别时只关注局部特征,忽略动作长距离关系而导致的误判问题.
受此启发,本文基于TSN双流模型的框架,首先设计了一种时空特征融合的TS-VAN模型.模型采用VAN网络替换简单的卷积网络作为空间流的主干网络,目的是处理RGB帧从而提取视频动作中更丰富的空间特征.结合异构的思想,模型时间流部分仍采用BN-Inception卷积网络处理光流数据提取时间信息.最后融合双流网络的时空特征.模型可以通过提高对RGB帧中空间特征信息的利用,更好地融合时空特征,从而提高动作识别准确率.其中,VAN网络的四级结构信息设置如表1所示,C为该级的通道数,L为部分结构的叠加次数.

表1 VAN结构设置Table 1 Structural settings of VAN
此外,本文注意到使用VAN网络处理RGB视频帧时,通常需要降低空间维度、提高通道维度,这种方式可能会造成特征信息的丢失.其次,空间网络主要提取的是RGB帧的外观、位置及形状特征,而这些信息对图像背景噪声比较敏感.
针对以上问题,本文引入极化自注意力机制,从而提出一种注意力机制的TS-PVAN双流动作识别模型.本文将2.2节介绍的极化自注意力PSA模块插入VAN网络的前端,构成P-VAN作为空间流的主干网络.由于PSA模块包括通道分支和空间分支两个部分,并采用自注意机制获取注意力权重,因此可以视为是对VAN网络的增强注意.TS-PVAN动作识别模型在捕获长距离动作特征信息的同时,可以在空间网络中提取高空间分辨率下的动作特征,减少由空间维度降低造成的特征损失,同时减小视频背景噪声对识别结果的影响,实现在空间流中提取更丰富的视频动作空间特征,以达到增强时空特征融合的效果,最终提高动作识别准确率.
TS-PVAN模型结构如图2所示.本文采用与TSN相同的时间分割策略,并利用异构的方式,在空间网络中,经过实验验证后将给定的视频v按其时间长度平均分为k段(本文设置k=5),再从每段截取的视频中随机抽取1帧,组成短片段{s1,…,sk}.时间网络的抽帧方式与其相同,只是每段抽取的是连续5帧光流作为输入.然后将短片段中的si分别作为双流网络的输入,得到其动作类别得分,再将s1~sk的类别得分进行均值融合.最后使用Softmax函数,计算整个视频分别对应于每个类别的概率.计算过程可以表示为:
(3)
其中,S表示为Softmax函数,M表示均值融合函数,F(si;W)表示以W为参数的网络模型函数,计算得到si的初始分类得分.融合结果的损失函数定义如下:
(4)
其中,n表示动作类别总数,yi∈{0,1}表示第i类动作的真实标签,mi为该类动作的初始得分.反向传递误差时,可得损失函数L相对网络参数W计算的梯度可表示为:
(5)
在模型训练时,将视频数据输入到网络模型中,然后使用k个片段的融合结果通过反向传递误差以更新网络的参数,最终训练得到视频级动作识别网络参数值,以相同的方式对训练后得到的模型进行测试,得到该动作识别模型的准确率.
2 实验分析
本节首先介绍实验所用数据集,其次详述实验的训练与测试过程,最后与现有双流动作识别方法的结果进行比较,验证了所提模型的有效性.本文所有实验均在一台Linux服务器上进行,其操作系统为Ubuntu 16.04,搭载4块RTX2080Ti GPU,所用软件包括python开发环境和pytorch框架等.
2.1 数据集
本文在HMDB51和UCF101两个大型动作识别数据集上验证所提模型的有效性,这两个数据集常用于双流网络的动作识别任务中,包含RGB及光流两种模态的数据,本文所对比的双流方法也均给出这两个数据集的实验结果.Kinetics数据集多用于单流网络的方法,只对RGB数据进行处理的情况,对本文而言缺乏可对比性.因此,本文选用HMDB51和UCF101数据集进行实验,便于对比分析模型性能.
其中,UCF101数据集包含101个动作类别,共有13320个视频,视频来自YouTube中注释的视频片段,每个视频时长约在10秒内.HMDB51数据集包含51个动作类别,共有6766个视频,主要来自YouTube、Google视频等,可分为5个大类:1)常见面部动作:如微笑、交谈;2)复杂面部动作:如吃、喝;3)常见肢体动作:如爬、倒立;4)复杂肢体动作:如骑马、射弓;5)多人交互动作:如拥抱、握手等,其部分动作示意图如图6所示.本节实验按照文献[5]中的标准评估协议将数据集划分为训练集与测试集.

图6 HMDB51数据集部分动作示意图Fig.6 Schematic diagram of actions of the HMDB51 dataset
2.2 实验设置
预训练策略:近年来,大量研究证实,使用预训练模型的权重初始化训练网络的参数能够有效提高网络的识别准确率,因此,本文使用在ImageNet[26]数据集上经过预训练得到的VAN模型及BN-Inception模型的参数对双流网络的权重进行初始化,对于RGB数据,VAN网络的预训练模型输入的卷积层的卷积核尺寸为三通道的,所以可以直接初始化网络权重,而光流数据的通道数为10,不能直接初始化,光流数据有两个方向即水平和垂直,采用的是连续5帧光流数据作为网络的输入,因此,首先将卷积核的三通道经过复制改为通道数为10的卷积核,再使用修改后的模型参数对网络模型进行初始化.
训练:本文将数据集划分为3个部分,分别进行训练,最后取得3部分的平均值作为最终准确率.本文所有实验均采用小批量随机梯度下降法训练网络参数,其中空间网络的batch_size设置为16,时间网络的batch_size设置为32,视频分段数均设置为k=5.在空间网络中,设置初始学习率为0.001,共80个epoch,当epoch分别为30和60时将学习率衰减为原来的1/10,dropout设置为0.8以防止过拟合.在时间网络中,设置初始学习率也为0.001,共340个epoch,当epoch分别为190和300时将学习率衰减为原来的1/10,dropout设置为0.7.每个epoch结束后保存一次训练模型参数,并在训练过程中更新最优模型的参数.此外,为避免数据集样本量过小可能导致过拟合的问题,实验中还采用了数据增强方法,保证模型的性能.
测试:本文按照文献[5]中的测试方案对训练得到的模型进行测试.首先以等间隔的划分方式分别对RGB及光流数据采样25帧,其次对抽取的视频帧以裁剪4个角及1个中心的方式处理,再进行水平翻转后输入训练得到的模型中.在对分段的数据进行特征融合时,采用平均融合的方法,将所分的25段图像帧的分类结果取平均值作为最终的分类结果.然后采用加权融合的方式并通过遍历搜索权重值来对空间网络与时间网络的分类得分进行融合,遍历搜索权重值的方法能够有效获取模型的最优性能,最后得到本文所提模型的最终识别率.
2.3 实验比较分析
下面首先分析由VAN网络构成空间主干网络的TS-VAN模型的动作识别准确率,再对由P-VAN作为空间主干网络的TS-PVAN模型的实验结果进行分析,最后将本文所提模型与目前的一些主流方法进行对比,验证所提模型的有效性.TSN网络中将视频数据分为3段,为提高模型识别精度,本文经过实验分别将视频段数分为3、5、7,发现当视频分为5段时识别准确率最高,考虑到段数越高数据冗余越明显,为了便于做对比分析,本文所有实验都将视频分段数设置为5.
2.3.1 TS-VAN模型实验结果
为了捕捉空间长距离依赖关系,提取视频动作更丰富的动作特征,本文将VAN视觉注意网络引入到处理RGB帧的空间主干网络中,光流数据仍采用BN-Inception卷积网络处理,构成TS-VAN模型.本文在HMDB51与UCF101两个数据集上进行实验以体现模型的泛化能力,实验结果如表2、表3所示,表中分别给出了基线TSN与TS-VAN两种方法处理RGB单流数据的识别准确率以及双流融合后的准确率的对比结果.

表2 HMDB51在TS-VAN模型的识别准确率(%)Table 2 Performance comparison of HMDB51 in TS-VAN model(%)

表3 UCF101在TS-VAN模型的识别准确率(%)Table 3 Performance comparison of UCF101 in TS-VAN model(%)
由上述实验结果对比可知,空间主干网络采用VAN网络与TSN中使用卷积网络相比,在两个数据集上提取空间特征的能力分别提高6.0%和2.6%,双流融合后的结果分别提高了4.8%和1.1%,证明了视觉注意网络VAN相比原有卷积网络能够捕获空间范围上更丰富的动作特征,验证了本文设计的TS-VAN模型的有效性.
2.3.2 TS-PVAN模型实验结果
由于VAN网络处理空间网络中视频RGB帧时降低空间维度可能会带来特征损失,且视频动作的背景噪声也会对识别结果造成影响,本文又在TS-VAN结构的基础上,将极化自注意力PSA模块插入VAN网络的前端以构成P-VAN网络作为TS-PVAN模型的空间网络,以增强空间流网络提取动作空间特征的能力,时间流网络同样选取BN-Inception卷积网络.最后,通过对比HMDB51与UCF101两个数据集分别在TSN及TS-PVAN模型上的实验结果及对比如表4、表5所示.

表4 HMDB51在TS-PVAN模型的识别准确率(%)Table 4 Performance comparison of HMDB51 in TS-PVAN model(%)

表5 UCF101在TS-PVAN模型的识别准确率(%)Table 5 Performance comparison of UCF101 in TS-PVAN model(%)
由表中结果可知,TS-PVAN方法相比TSN在空间网络提取特征的性能在HMDB51数据集上达到58.8%,提高了7.6%,在UCF101数据集上达到89.0%,提高了3.8%,双流融合后的准确率分别提高5.7%和1.7%.此外,TS-PVAN与TS-VAN相比,在两个数据集上提取空间特征的能力分别提升了1.6%和1.2%.可见,本文设计的两种空间网络能够提高对RGB帧的处理能力,有利于改善时空特征融合的性能,验证了本文所提模型的有效性.
为了清晰地观察模型训练过程中性能的变化,本文分别给出本文所提TS-PVAN模型对HMDB51与UCF101两个数据集,在空间网络中训练RGB单流数据提取动作特征的过程中,识别准确率的变化趋势如图7、图8所示,横坐标表示为epoch的数目,总计80,纵坐标为该轮次对应的识别准确率.
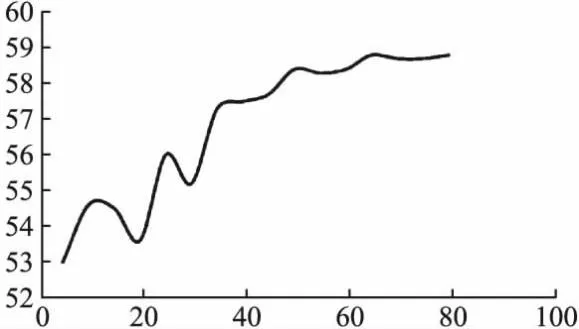
图7 HMDB51上RGB单流准确率变化图(%)Fig.7 RGB single-stream accuracy change chart on HMDB51

图8 UCF101上RGB单流准确率变化图(%)Fig.8 RGB single-stream accuracy change chart on UCF101
2.3.3 同主流方法的性能对比
本节将所提双流动作识别TS-PVAN模型的性能与目前几种比较先进的双流网络方法进行比较,并分别给出在两种HMDB51与UCF101数据集上的识别准确率对比结果如表6所示.

表6 两种数据集上本文方法同现有方法对比Table 6 Comparison of the method proposed in this paper and existing methods on the HMDB51 and UCF101 dataset
由表中数据可知,对于HMDB51数据集,所提方法与TSN双流方法相比提升了5.7%,与基于时空特征乘法交互的Mul-ResNet[27]方法和时空金字塔模型ST-pyramid[28]相比提升5.3%,与残差时空注意模型R-STAN[10]相比提升5.5%,与IP TSN[11]模型和ISTPAN[12]模型相比分别提升5.1%和4.6%,相比DMC-Net[13]网络提升了2.4%.此外,对于UCF101数据集,与这几种双流网络相比,识别准确率大约提升0.6%~3.1%.实验表明本文所提TS-PVAN模型的有效性及泛化性,同时说明该模型在相对较小的数据集上能达到更好的识别效果.
3 结 论
本文提出一种注意力机制的TS-PVAN双流动作识别模型.首先给出模型整体架构,介绍了视觉注意网络VAN和极化自注意力模块PSA的特点及网络结构.其次将VAN网络引入动作识别双流模型中,作为空间主干网络处理RGB数据以捕获视频动作在空间上的长距离依赖性,充分利用丰富的空间特征.最后将PSA模块插入VAN网络的前端,构成P-VAN作为空间主干网络,减少了空间维度降低造成的特征损失且降低视频背景噪声对特征提取的影响.在HMDB51和UCF101两个数据集上进行实验,实验结果验证了本文所提模型的有效性,同时具有一定的泛化能力.此外,在本文已完成工作的基础上,未来将进一步考虑对时间网络的改进,如何高效地建模长范围时间结构,提取丰富的长期时间信息,是下一步将要重点展开研究的工作内容.
猜你喜欢
中小学校长(2022年7期)2022-08-19
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
冶金设备(2020年2期)2020-12-28
高原山地气象研究(2020年3期)2020-07-16
中小学校长(2019年10期)2019-11-07
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
