
基于动态Transformer的轻量化目标检测算法
2024-02-26 07:59:48方思凯孙广玲陆小锋刘学锋
电光与控制 2024年2期
方思凯, 孙广玲, 陆小锋, 刘学锋
(上海大学,上海 200000)
0 引言
目标检测[1]旨在从一幅图像中同时分类和定位出多个感兴趣的物体,近年来因其快速的技术突破和广阔的应用场景而受到关注。传统的目标检测方法[2-3]通常使用卷积神经网络(CNN)[4]作为骨干来提取视觉特征,其通过堆叠卷积层逐渐增大模型的感受野以检测整幅图像。同时,具有不同感受野的特征图可以实现对不同尺度物体的检测。然而,LUO等[5]研究发现CNN中特征图的实际感受野只占其理论值的一部分,这表明模型的最终感知区域难以覆盖整幅图像,也严格限制了其检测性能。
随着深度学习的发展,诞生于自然语言处理领域[6]中的Transformer网络框架[7]为人们带来了新的思路。如文献[8]提出了结合Transformer和卷积神经网络的检测模型;文献[9]引入了位置编码和编码器-解码器框架范式;更进一步地,文献[10]彻底移除了卷积结构,提出了一种称为Vision Transformer的纯Transformer网络框架,该框架将图像分割为均匀的小块,使用自注意力机制在各块之间建立相关性,以充分利用图像的视觉特征。然而,Transformer视觉模型在目标检测任务中仍然存在问题。首先,全局自注意力机制擅长远程依赖性建模,适用于分类任务(其实例往往占据整幅图像)以及目标检测中的大尺度物体检测。但对于小尺度和中尺度物体的检测精度往往比CNN模型低几个百分点,这表明完全排除局部机制是不合理的。此外,全局自注意力机制的计算复杂度随着图像块的数量增加呈二次指数增长,尤其在目标检测等高分辨率输入的任务中,对设备的计算能力要求较高,难以在实际应用中大规模拓展。
针对Transformer在目标检测任务中检出效率低、多尺度泛化能力弱的问题,本文在Vision Transformer的框架基础上,提出了一种轻量化的动态Transformer目标检测算法。改进算法在降低计算复杂度的同时,增强了对中小尺度目标的检测性能,保证了模型的实时性和准确性。
1 改进的Transformer目标检测算法
改进的算法即动态Transformer目标检测算法的网络整体框架如图1所示。

图1 改进后网络的整体框架结构Fig.1 Overall framework structure of the improved network
首先通过4×4的卷积层将输入图像映射成空间尺度为原图的1/4、通道数为96的特征图,然后依次经过4个网络阶段进行特征提取,每个阶段由3个编码层组成,同时,在网络中插入由2×2的最大池化层和1×1的卷积层组成的下采样模块,将特征图的空间尺度和通道数分别减小至原来的1/2和扩展2倍,最后使用Faster R-CNN[11]目标检测头得到最终的检测结果。编码层主要由改进的动态稀疏自注意力(DS-Attention)模块和全连接层组成,对于前者,本文算法使用由卷积组成的动态门从全局范围内为每个查询向量Q选择一定比例(由动态因子μ决定)的键向量K和值向量V做自注意力计算。同时,在网络的浅层阶段使用较小的比例阈值,关注图像的局部区域,随着网络的阶段加深逐渐增大该比例阈值,以最终实现全局关注的自注意力模式。为了进一步加快模型的计算效率,本文算法还将动态门机制应用于网络的结构层面,通过在每个编码层前面插入动态跳层门(DLG),模型可根据不同的输入自适应地选择不同的编码层参与计算,以跳过重要性较弱的编码层,从而减少模型的冗余。此外,层归一化(LayerNorm)和批归一化(BatchNorm)被插入网络以优化训练梯度。
1.1 动态稀疏自注意力机制
传统自注意力机制的关键组件有查询向量Q、键向量K和值向量V,由输入特征x线性变换而来。随后进行线性映射转换为多头状态,即
(1)

在所提出的动态稀疏自注意力机制中,如图1右下角所示,对于第l个编码层,通过动态门Ql生成一组概率向量Gl,并假设生成的Gl中元素的值越大,选择对应的K和V的概率就越高,其算式为
(2)
式中:C(·)为4×4的卷积;B和δ分别为批归一化和GeLU激活函数;同时,将当前和前一编码层生成的概率向量相加,以记忆先前层的选择结果,并定义了一个记忆因子α,通常被设为0.2。最后,生成的概率向量Gl∈Rh×N转换为掩码,即
(3)
式中:j的区间为(1,N),N为图像块的数量;μ为动态因子;阈值t为Gl中第μ大的值。Gl中小于阈值t的元素被设置为0,其余的被保留,相当于过滤器。然后,将掩码MMask扩展到与K∈Rh×N×dk相同的维度,并使用哈达玛积将MMask与K和V进行逐元素乘积,以对键向量和值向量进行掩码,算式为
(4)
最终的自注意力函数为
(5)
式中,D(Kmasked)和D(Vmasked)都属于Rh×μ×dk,由最大池化函数D(·)生成,以显式地减少掩码后键向量和值向量的特征维度。
由式(5)可知,提出的动态稀疏自注意力机制的计算复杂度降低到与N呈线性关系,且可以在全局水平上动态选择重要性较高的键向量和值向量参与自注意力计算。同时,由于自注意力的多头特性,可以在每个头中为查询向量生成不同的概率向量,使得模型即使在μ很小的情况下也有能力关注到图像的各个区域,而残差连接能够将当前层未被选择的信息向后传递。由于其输出维度与原始自注意力机制相同,且以上操作都是可微的,所以可以直接代替原始自注意力机制进行端到端训练。
1.2 从局部到全局的自注意力模式
本文进一步将动态稀疏自注意力机制中的动态因子归一化表示为自注意力选择的百分比,并为每个网络阶段分配了一个固定的μ值。因此设计了几种特定的自注意力模式:局部到全局型、全局到局部型、中等型和局部型。随着网络阶段的加深,其μ值分别为(0.2,0.4,0.6,0.8),(0.8,0.6,0.4,0.2),(0.5,0.5,0.5,0.5)和(0.2,0.2,0.2,0.2)。通过Grad-Cam[12]将上述4种模式以及传统(全局)模式对小、中和大尺度物体的关注效果进行可视化展示,如图2所示。
由图2可以观察到,局部型和中等型的自注意力模式能够识别出小尺度和中尺度物体,但其受限的感受野不足以识别大尺度物体。传统(全局)自注意力模式虽然可以识别出小尺度物体的语义信息,但很难在全局范围里准确定位出它们的位置,导致小目标的检测性能较差。
对于局部到全局型,当网络初始阶段的动态因子较小时,这种较小的感受野有利于模型在早期阶段识别和定位出小目标。随着网络阶段的加深,增大的动态因子允许模型关注更大的特征区域,特征也逐渐转化为高层次的语义信息,使模型能够识别出中型和大型目标。此外,对于全局到局部型的注意力模式,较浅的网络阶段缺乏高级语义信息而较深的阶段缺乏足够的感受野,使其始终无法识别出大目标。综上所述,与自然语言处理领域相比,在图像处理领域,尤其是目标检测任务,在网络的早期阶段不需要对图像中的太大区域进行关注,否则会导致模型丢弃低层次的细粒度特征,同时还会增加计算复杂度。类似于卷积神经网络的逐级提取特征的方法更有利于模型取得更好的性能。因此,本文最终选择了从局部到全局的自注意力模式。
1.3 动态跳层网络结构
根据常识,对于一幅简单图像,人眼只需较短时间就能分辨清楚;而对于一幅复杂图像,通常需要较长时间且仔细的判断才能辨认。因此,本文从人眼的视觉机制出发,尝试将动态决策方法进一步扩展到模型的结构层面上(如图1左下角所示)。
首先,对于第l个编码层,在其前面插入动态条件门来生成重要性权重因子Hl∈R1,其算式为
Hl=max(0,tanh(C1(δ(B(C2(Xl))))))
(6)
式中:Xl为当前编码层的输入特征;C1(·)和C2(·)为3×3的卷积;tanh(·)为双曲正切函数。因此,Hl的结果区间为[0,1],表示当前层的重要性。
在网络训练时,不论Hl是否为0,每个编码层的所有结构都参与计算,防止网络中某些参数没有被训练。在推理时,若Hl为0,则直接跳过当前层。训练和推理时编码层的输入输出分别有以下关系
(7)
(8)


(9)
重要性权重Hl的值越小,网络在当前层的期望计算量就越少,反之亦然。则新的损失函数为

(10)
式中:Laccuracy为精度项损失函数;Lefficiency为效率项损失函数;λ为精度和效率之间的权衡因子,λ越大,网络越轻量,反之网络精度越高;θ为衰减系数,控制网络提升效率的上限,通常设为0.2。
最后,为了使网络更好地训练,本文算法在训练的早期阶段只采用精度项损失函数,称为预加热阶段,之后才加入效率项损失函数。通过动态跳层机制,网络在训练时能够利用损失函数,学习在不同的输入情况下动态地选择编码层,以更好地平衡网络精度和效率。
2 实验结果与分析
2.1 实验数据集与评价指标
本文使用MS COCO-2017数据集[13]作为训练和测试时使用的数据集,共包括80个目标类别,其中训练集和测试集分别拥有11万张图片和5000张图片。采用浮点运算次数(FLOPS)和检测帧率(FPS)分别验证模型的计算量和计算速度。同时,使用平均精度均值(mAP)、小尺度目标精度(APS)、中尺度目标精度(APM)和大尺度目标精度(APL)等作为验证模型检测性能的主要指标。其中
(11)

(12)
(13)
式中:P为查准率;R为召回率;PT为真正例;PF为假正例;NF为假反例;PAP为平均精度;P(R)为P-R曲线;C为目标类别数。APS,APM和APL分别为像素面积小于322、像素面积在322与962之间以及像素面积大于962的目标框的AP值。AP50和AP75分别表示交并比为0.5和0.75时的AP值。
2.2 实验细节与运行环境
本文在训练时采用的操作系统为Windows 10,GPU为NVIDIA-RTX3090(24 GiB)。为了测试模型的实际检测能力,使用“大疆妙算”(机载计算机)作为测试设备。机载计算机的操作系统为Ubuntu-16.04,GPU为NVIDIA-Jetson TX2(8 GiB)。其中,模型的初始学习率为8E-5,AdamW优化器和分段式学习率衰减策略被用于训练模型。网络训练的前20个轮次被设定为预加热阶段,此时只有精度项损失函数生效,在预加热阶段结束后效率项损失函数才开始生效。对于输入的图像,其短边被调整为512像素,而长边保持在800像素以下。模型的具体参数以及当输入为H×W×3时模型各部分的输出特征大小如表1所示,其中,k和s分别代表核大小和步长。
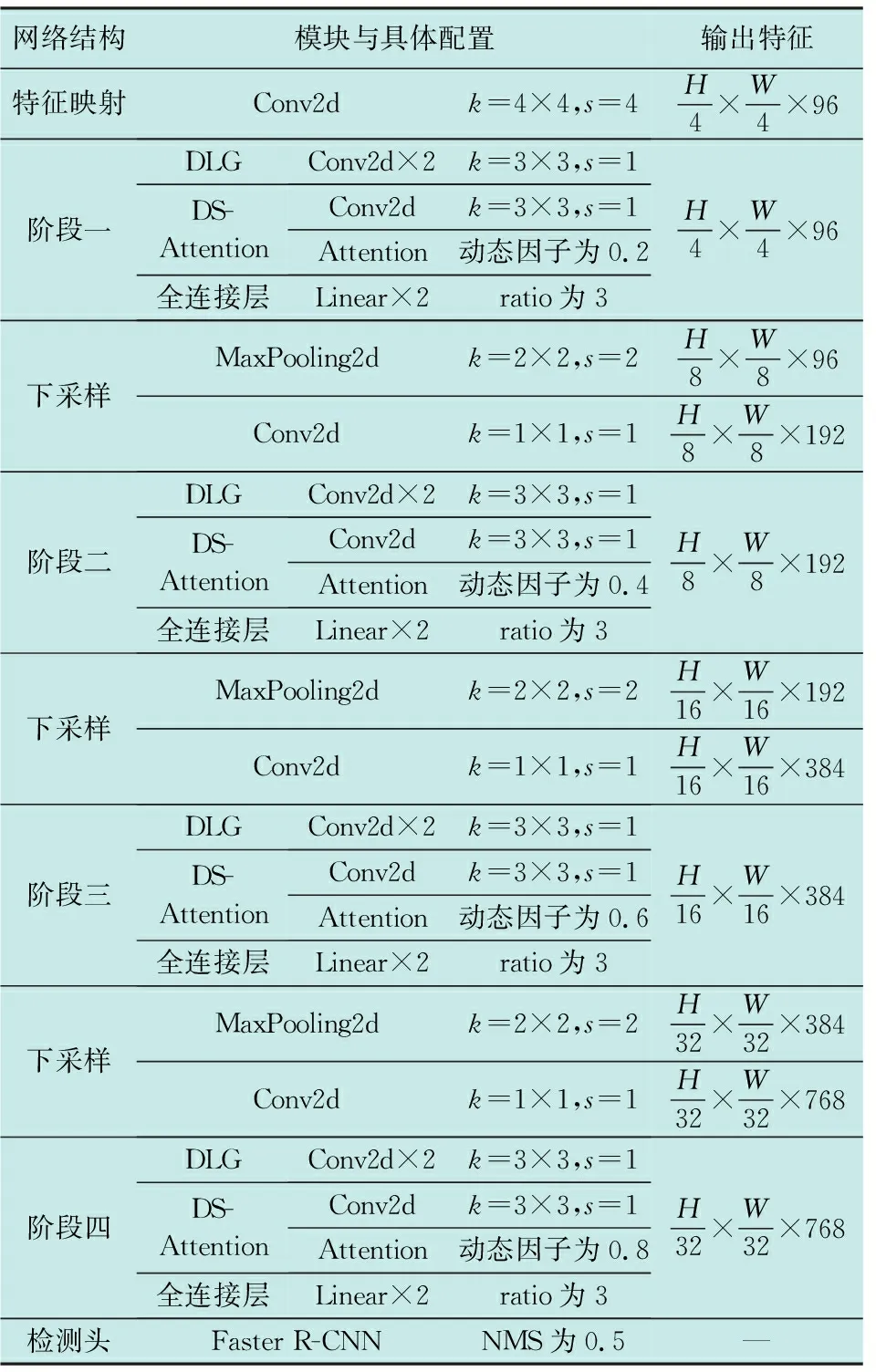
表1 改进模型的具体参数Table 1 Detailed parameters of the improved model
2.3 对比与消融实验
图3展示了本文算法在MS COCO-2017数据集上的部分检测结果,模型展现了对各种尺度目标以及复杂图像的检测能力。同时,图4还展示了在不同输入条件下模型的编码结果。由图4可知,模型能够根据输入动态选择部分编码层参与计算以达到检测效果,体现了算法的自适应能力。

图3 本文算法在MS COCO-2017数据集上的部分检测效果实例Fig.3 Some examples from MS COCO-2017 test dataset detected by the proposed algorithm
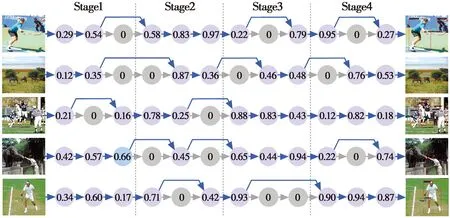
图4 部分编码结果展示Fig.4 Display of partial encoding results
为了对模型进行更详细的性能测试,本文对比了改进算法模型与其他几种基于Transformer的目标检测基准模型的性能,如表2所示。

表2 模型性能对比Table 2 Comparison of model performance
与其他算法相比,本文算法在检测精度与效率方面都取得了更好的性能。其中,模型的平均精度均值达到了43.8%,尤其是对小、中尺度目标的检测性能分别为27.6%和47.4%,相比其他模型有较大的提升。此外,模型的计算量相对较小,其检测速度达到了37帧/s,实时性大幅提升。本文在图5中进一步说明了改进算法模型的收敛性,由图5可知,模型在300个训练轮次就可取得较为理想的结果。

图5 模型训练损失变化Fig.5 Variation of model training loss
为了研究本文算法中的不同组件对模型的影响,将所提出的改进模块逐一添加到原Vision Transformer框架中,其结果如表3所示。动态稀疏自注意力在提升小尺度和中尺度目标检测性能的同时减轻了网络的一部分计算量,动态跳层机制在略微损失精度的同时大幅降低了模型的计算复杂度,对于提升效率的贡献度较大,通过它们的组合实现了更高效的Transformer检测模型。

表3 不同组件对模型的影响Table 3 Impact of different modules on the model
为了验证不同的自注意力模式对模型性能的影响,本文将传统(全局)模式与本文提出的4种模式的性能进行了测试对比,如表4所示。相比传统的全局型模式,所提出的几种模式在小型和中型物体上都取得了明显的性能提升,得益于受限的关注区域。本文建议的局部到全局型的自注意力模式能够关注所有尺度的物体,取得了最好的性能。该实验结果与图2中观察到的现象一致。

表4 不同自注意力模式的性能对比Table 4 Comparison of performance of different self-attention patterns
为了验证动态跳层机制在模型训练时的工作模式,图6显示了在前50个训练轮次中,损失函数中的不同权衡因子对网络训练的影响。在前20个训练预加热轮次中,算法为了提高精度增加了模型的计算量。在20个轮次后,效率项损失函数开始生效,模型的计算量逐渐下降,同时,模型精度在略微衰减后继续上升。可以看出,权衡因子越大,模型越轻量,对精度的影响也越大。

图6 权衡因子对训练的影响Fig.6 Impact of the trade-off factor on training
3 结束语
为了提高Transformer检测框架的实时性和准确性,本文提出了基于动态Transformer的轻量化目标检测算法。实验表明,本文算法改善了原Transformer框架对于小尺度和中尺度物体检测性能不足的问题,同时模型的计算量有效减少,实时性得到有效提升,在机载计算机上的检测速度达了37帧/s,模型的实际应用空间获得大幅增加。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
金桥(2018年4期)2018-09-26 02:24:54
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
