
基于信息识别的园林植物地理信息查询系统
2024-02-22 06:50李勋
地理空间信息 2024年1期
李 勋
(1.西安职业技术学院 教务处,陕西 西安 710077)
我国是一个植物种类极为丰富的国家,园林更是人们生产生活中不可或缺的景观资源之一。随着互联网技术的发展,人们对信息与资源的获取更便捷,万维网成为地理空间信息资源获取的主要方式与载体,但相关信息数量也在急速增加,“信息爆炸”给信息的精准搜寻带来了巨大挑战。如今,人工观察、记录并采用被动输入的信息查询方式已很难满足难度日益增加的信息检索需求。在大数据背景下,为深度挖掘并最大化开发利用园林植物资源,智能信息技术已俨然成为园林植物地理信息管理中亟待引进的技术之一。园林植物景观信息可反映现实世界中植物的存在方式及其生长状态,信息识别是指接受者从既定位置出发,根据本身具有的知识和经验对信息进行相关识别。不考虑其他干扰条件,将园林植物信息识别技术与服务目标相结合,可在分析植物信息有用性的同时,合理构建宏观园林信息环境,这是实现信息价值唯一的实践前提[1-2]。
目前以WebGIS 技术为主的园林植物地理信息查询系统,需要限定各类摆放景观的实际位置,以被动化信息输入为基础数据,在个体化区域环境中,实现对植物地理信息的合理查询;而实际应用中,这种被动输入信息的模式缺少主动识别过程,智能化程度较低,且易导致植物地理景观所受保护能力不断下降。为解决该问题,本文引入信息识别技术,在组件式GIS 开发平台的支持下,设计了一种新型园林植物地理信息查询系统,在完善现有数据库服务器架构的同时,对地理信息参量进行空间化建模处理,并通过构建决策树训练集合的主动信息识别方式促进植物属性特征查询与空间地理特征查询能力的不断增强。
1 系统软件设计
本文按照空间化建模、基于决策树训练的信息查询、数据库服务器架构链接的流程搭建系统的软件执行环境。
1.1 园林植物地理信息识别方法设计
空间化建模是园林植物地理信息管理系统在信息处理过程中最重要的景观特征处理工具,也是地理信息查询与决策成果展示的必要操作技术。人仅凭肉眼很难在一堆待选数据中分辨出某一固定区域内的园林植物地理信息,且由于数据信息自身的可感知、可操控等特性,与属性特征查询模块和地理特征查询模块所匹配的提取操作应是一项极复杂的流程[3-4]。对于园林植物地理信息查询系统来说,待识别信息的空间化建模涉及非空间数据等多项操作,其建模处理的关键是识别园林区域环境中的地理信息参量与非空间专题信息参量,在既定识别技术的支持下,将二者完全转化为数字化表达形式,并借助组件式GIS 开发平台进行有机整合,从而实现对园林地理空间的空间化环境重构[5]。通过空间化建模识别园林植物地理信息,即
式中,i0、in分别为园林空间环境中的最小、最大地理信息查询条件;n为待识别地理信息的迭代执行系数;q̇为园林植物地理信息的分辨识别参量;yˉ为园林景观数据的迭代均值;k̂为特定园林植物景观的地理信息特征值。
根据识别的园林植物地理信息,以决策树训练的方式提取空间地理信息特征。决策树训练是指收集园林植物地理信息训练样本,提取空间地理特征,并利用这些信息样本与特征生成具有分类能力树状决策机构的过程。对提取的空间地理信息特征进行加窗处理,构建园林植物地理信息查询控制函数,完成信息查询。通常经过训练的决策树组织可直接应用于地理信息管理系统的特征信息识别,其质量水平将直接影响信息识别技术的应用准确率和系统的实际运行效率。决策树训练遵循自上而下的原则,除原有叶节点外,每个节点处均能生成两个或两个以上的信息事件,经过多次累计,生成一棵二叉树或多叉树结构体[6-8]。决策树训练处理深度和广度完全取决于园林植物地理信息特征集的大小和特征区分度条件,信息特征集区分度不高或特征值过大均会导致决策树分类效率的持续降低。因此,在选取训练特征时应注意不要一次性挑选过多的信息参量,这也是园林植物地理信息始终具备降维处理能力的主要原因。系统决策树训练的空间地理信息特征提取结果可表示为:
式中,dn为第n个园林植物景观的地理信息特征值;β、χ分别为两个不同的地理信息数据识别条件。
对提取的空间地理信息特征进行加窗处理,窗函数形式为:
式中,x̂为特征提取的决策变量;N(t)为空间地理数据的关联语义特征分辨率。
根据处理结果,构建园林植物地理信息查询控制函数,即
式中,vt为园林植物地理信息查询的速度;c1为园林植物地理信息查询聚类的空间规划系数;α1、α2为[0,1]之间的随机数。
1.2 数据库服务器
数据库服务器架构由服务器设置、数据库架构与备份要求两部分组成,服务器设置是指系统所设立的中心数据服务器、Web 服务器和GIS 服务器;数据库架构与备份要求描述了园林植物地理信息与数据服务器之间的对应服务关系。在既定识别环境下,GIS 服务器与Web服务器能够借助数据库主机建立共用链接模式,数据库服务器同时面对GIS 客户端与C/S 客户端提供识别信息所需的存储数据与访问管理指令,但前者的执行能力与特殊的C/S 客户端类似,可在面向Web服务主机的同时,为其他园林植物地理信息提供所需的应用型任务。Web 服务器既能面向B/S 客户端响应系统客户提出的请求,又能将这些信息指令直接上传至GIS 服务器。与此同时,GIS 服务器会将园林植物地理信息的处理结果反馈至B/S 客户端主机中,具体见图1。
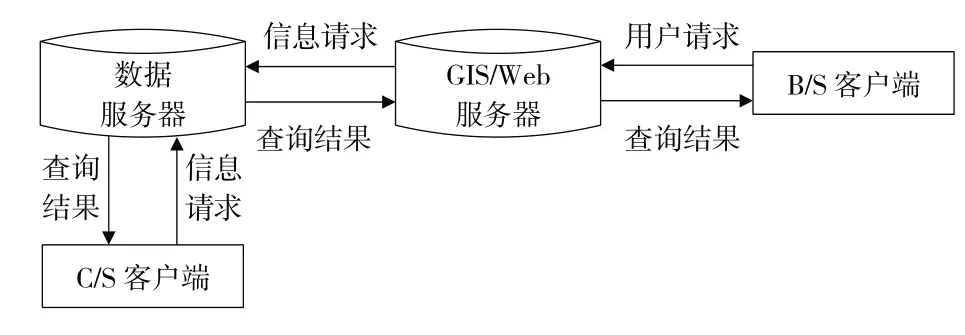
图1 数据库服务器架构形式
园林植物地理信息查询系统数据库的构建需根据其设计背景与设计目的,合理规划总体结构,充分实现其存储、查询和基础知识库的功能。数据库将信息分为两类进行存储:①园林空间地理信息库,包括基础信息、数据信息、图文信息;②园林植物属性信息库,包括花、叶、果形态以及植株整体形态、生态习性等。按照植物名称及其相关属性等查询各种植被信息以及根据地理名称、特征、方位查询相关空间地理信息时,首先提取数据库中满足条件的信息表表名,然后在该信息表内查询满足目标信息的数据,这样可迅速缩小查询范围,在一定程度上减少查询时间,提高查询效率。在上述信息识别技术的支持下,本文设计了新型园林植物地理信息查询系统,能高效准确地查询相关信息。
2 系统硬件设计
在系统软件执行环境搭建的基础上,设计园林植物地理信息查询系统的硬件。系统硬件执行环境由组件式GIS 开发平台、植物属性特征查询模块、空间地理特征查询模块3 部分组成,两相结合,实现基于信息识别的园林植物地理信息查询系统。
2.1 组件式GIS开发平台
组件式GIS 开发平台是系统搭建的硬件基础执行框架,由执行连接层(图2 中“1”)和附属连接层(图2 中“2”)组成,执行连接层能够感知网关设备元件的现有应用状态,并可在信息化网络的作用下,对系统防火墙设备进行直接控制,通常执行连接层中的设备元件能对园林环境中植物景观摆放位置进行干扰,并可在确保系统信息查询能力的基础上,规划相关应用主机的实际连接位置[9-10];附属连接层负载数据库服务器、GIS 服务器的实际连接需求,能按照信息识别技术的作用权限,调动个别园林植物景观所处的地理位置,并将上述数据文件整合为信息流的传输形式,反馈至相关系统执行主机。
2.2 植物属性特征查询模块
植物属性特征查询模块可独立完成园林地理信息管理工作,查看景观环境的相关属性信息,在图像中显示植物景观所属位置,浏览园林景观的图片资料,最终使植物的地图信息与地理属性数据形成一一对应关系。植物属性特征查询主要根据园林景观地理信息进行[11-12],系统用户可通过园林植物的属性特征检索该地理景观的地图坐标位置和其他属性特征数据,标记于定位地图中;还可自主选择与园林植物景观匹配的地理数据,由于园林植物景观的属性要素种类较多,系统的特征查询行为必须借助SQL数据库才能实现[13]。通常,实际查询结果能在植物属性表中反映出来,用户通过数据信息处理的方式找到最初确定的园林植物地理景观位置,并将其定位到属性地图的固定位置。
2.3 空间地理特征查询模块
系统用户可对属性地图进行操作,包括拖动、缩小、放大等。首先将鼠标定位于地图上的某一固定区域,主机管理界面能显示该区域内所有园林植物地理景观的名称;然后在地图中点击任意景观所在位置的图标文件,查询该类型植物属性特征信息;再对植物权属、冠幅、高度、宽度、种类等信息进行编号,使系统主控界面中显示的文件不断细化,最终生成完整的空间地理特征查询文件[14-15]。在整个模块单元(图3)中,待输入的识别信息始终作为中间过渡结构,一方面为园林植物地理特征提供链接的查询依据,另一方面可借助输入信道,建立系统核心控制主机特征开发平台软件之间的应用链接,直至最终生成的地图与属性数据能够完全满足特征查询模块的实际执行需求。
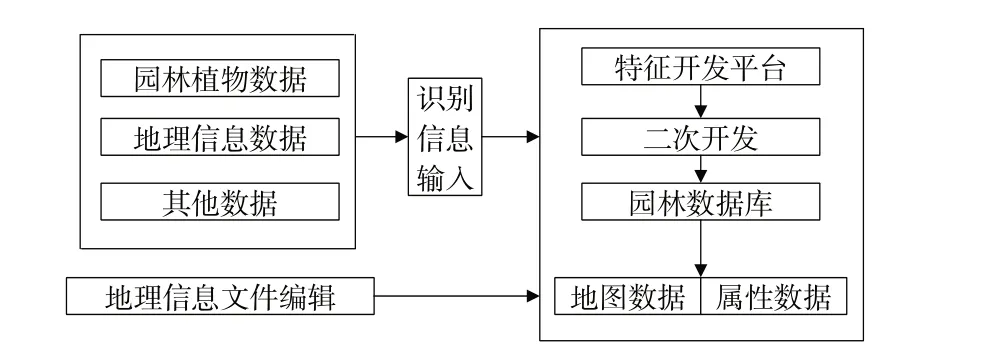
图3 空间地理特征查询模块结构图
3 实验结果分析
本文通过对比实验验证基于信息识别的园林植物地理信息查询系统的实际应用价值。将实验组控制主机、对照组控制主机分别与电脑端设备相连,实验组主机搭载基于信息识别的园林植物地理信息查询系统,对照组主机搭载多维语义型管理系统,在相同的实验条件下,分析相关实验指标的具体变化趋势,并测试园林植物地理信息的查询精度。实验采用Python语言编程设计,将园林植物地理信息查询划分为12 个网格,每个分块区域的数据片大小为24 kB,数据库的数据分布大小为1 024,数据特征采样的时间延迟为5 ms,将数据集划分为训练数据和测试数据,根据上述参数设定进行园林植物地理信息查询,得到测试集样本数据分布见图4。
图4 测试集样本数据分布
以测试集样本为测试对象,对实验组与对照组进行实验测试,并分析实验指标的具体变化趋势。已知TII、LII指标均能反映系统主机对植物景观在地理环境中实际摆放位置的限制影响强度,通常TII与LII指标越大,系统主机的限制影响能力越强,反之则越弱。实验组与对照组TII指标的实际变化情况见表1,可以看出,35 min 之前,对照组TII 一直呈上升趋势,35~45 min出现小幅波动,45~50 min达到最大值73.56%;实验组TII先大幅增加,在40 min时达到最大值84.72%,之后呈小幅下降;与实验组相比,对照组的最大值下降了11.16%,说明应用该方法后,TII得到了明显的促进影响,可在一定程度上加强系统主机对于植物景观在地理环境中实际摆放位置的限制影响能力。
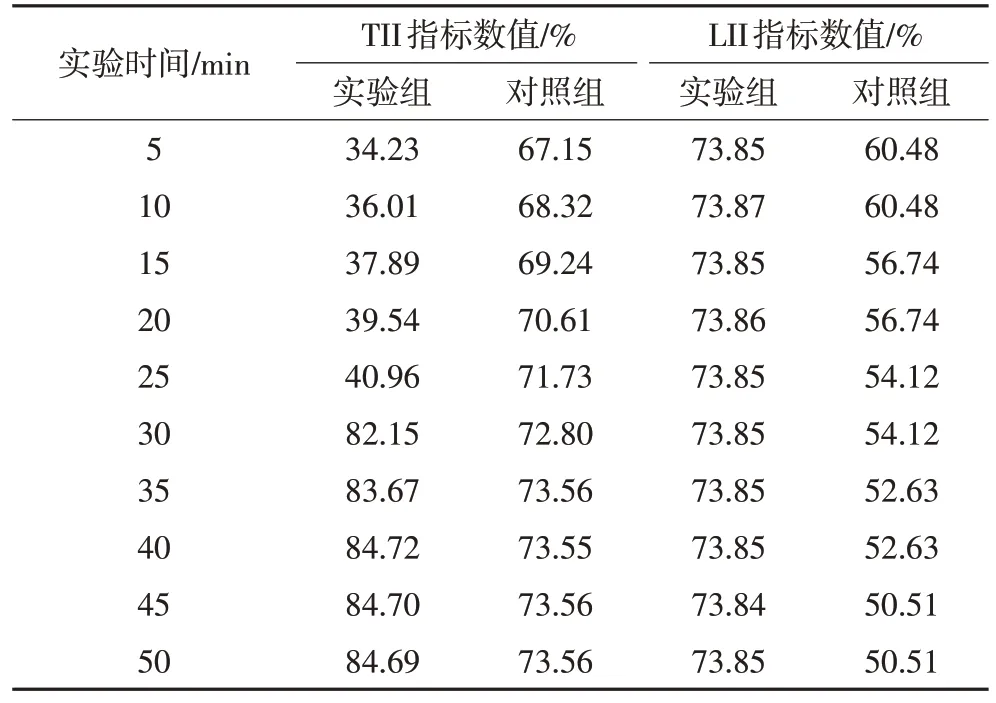
表1 TII、LII指标对比表
随着实验时间的增加,实验组LII 一直呈现小幅波动,在10 min 达到了最大值73.87%;对照组LII 一直呈下降趋势,由60.48%降至50.51%;与实验组相比,对照组最大值下降了13.39%,说明应用该方法后,LII 呈现不断增大的变化趋势,满足促进系统主机对于植物景观在地理环境中实际摆放位置的限制影响能力的实际应用需求。
为了进一步验证本文系统的有效性,以园林植物地理信息查询精度为验证指标,采用实验组和对照组测试园林植物地理信息的查询精度,结果见图5,可以看出,实验组进行园林植物地理信息查询的精度最高可达98%,而对照组的精度最高只有80%,实验组的信息查询精度较高、效果较好。
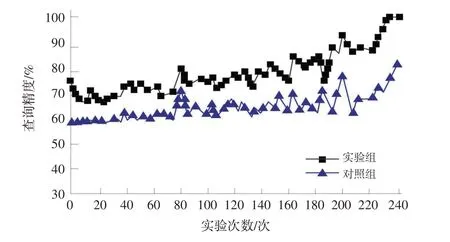
图5 园林植物地理信息查询精度对比
4 结 语
本文通过系统硬件和软件两部分设计了基于信息识别的园林植物地理信息查询系统,从实用的观点来看,TII与LII指标的增大,能促进系统主机对于植物景观在地理环境中实际摆放位置的限制影响能力的不断增强。在组件式GIS 开发平台、植物属性特征查询模块与空间地理特征查询模块的作用下,该系统能在实现园林植物地理信息空间化建模的同时,建立必要的决策树训练组织,使园林景区中的植物地理景观得到有效保护,提高园林植物地理信息查询精度。
猜你喜欢
现代装饰(2021年6期)2021-12-31
建材发展导向(2021年14期)2021-08-23
小学科学(学生版)(2020年12期)2021-01-08
小学科学(学生版)(2020年7期)2020-07-28
少年漫画(艺术创想)(2020年12期)2020-06-09
铁道通信信号(2019年9期)2019-11-25
现代园艺(2018年2期)2018-03-15
现代园艺(2018年3期)2018-02-10
现代园艺(2017年13期)2018-01-19
网络安全和信息化(2017年10期)2017-03-08
