
类不平衡的公共和标签特定特征多标签分类
2024-02-21 04:33:26张海翔李培培胡学钢
计算机技术与发展 2024年2期
张海翔,李培培,胡学钢
(1.蚌埠医学院附属合肥市第二人民医院 讯息处,安徽 合肥 230012;2.合肥工业大学 大数据知识工程教育部重点实验室,安徽 合肥 230601)
0 引 言
多标签分类[1-2]指利用一组已标记数据训练出模型对未标记的样本进行分类。现实中对事物的描述通常用多个标签进行描述,如视频注解、文本分类和生物信息学。常见处理方法分为:问题转化和算法适应。前者将多标签任务转换为一个或多个单标签分类任务,后者则将传统机器学习算法直接处理多标签数据。同样深度学习近年来在多标签医疗领域应用广泛,如:深度CNN[3]对26种心脏异常进行多标签分类,X光图像分类有ConvNeXt网络[4]与BioBert编码的语义向量相结合,EfficientNetB4架构[5]与转移学习方法进行结合用以提高胸部X光图像分类准确性,以及判别核卷积网络(DKCNet)[6]用于眼科疾病智能识别。
大多数多标签分类模型都面临类不平衡问题[7],尤其当负类实例的数量远大于正类实例的数量,导致分类器偏向于负类实例,分类性能降低。不平衡问题可分为:标签内部的不平衡、标签间的不平衡和标签集之间的不平衡。在标签内部不平衡中每个标签通常包含极高数量的负样本和极少量的正样本[8]。标签间不平衡考虑数据集中单个标签的频率,其中一个标签(正类)的数量可能高于另一个标签的正类数量[9]。标签集[10]的稀疏频率,如果考虑到完整标签集每个类别的正样本与负样本比例可能与常见标签集相关联,由于标签稀疏性,通常存在较多的频繁标签集和唯一标签集。这也意味着一些标签集被认为是大多数,而其余标签集同时被认为是少数情况。
现实数据同样面临数据维度爆炸问题,对模型训练将消耗过多资源。研究人员使用特征降维的技术从原始数据集筛选出对全部标签具有代表意义的特征子集,称为公共特征,如方法SCMFS[11]使用耦合矩阵分解技术找出特征与标签矩阵间公共部分。而实际中每个标签在特征空间都有对其最相关的特征称为标签特定特征,如方法IMLSF[12]。该方法分为两种:特征转换和l1范数,如LIFT[13]通过特征转换将标签正负实例转换为单标签特定特征,但这种方法无法识别出哪些特征是某标签的特定特征。以上方法只考虑公共特征或标签特定特征的优势,未将两种优势同时考虑。CLML[14]综合两种方法的优势,提出基于公共特征与标签特定特征方法,通过l1,l2,1范数限定系数矩阵选出每个标签的特定特征与公共特征,但该方法未能适应类不平衡数据环境。
因而,该文提出类不平衡的公共和标签特定特征多标签分类方法,采用启发式重采样技术解决类不平衡问题,然后综合标签公共特征和标签特定特征的优势进行数据筛选,不仅找出对所有标签都有意义的公共特征集合,还为每一个标签找出最具代表意义的特定特征。最后采用标签相关性实现关联标签的相似模型输出,实例相关性保证关联特征共享对应标签分布信息,提高了多标签分类精准度。
主要贡献如下:
(1)所提方法考虑少数标签列表,使用这些标签作为种子出现的实例来生成新实例,解决类不平衡问题。
(2)为降低训练过程带来的资源消耗,利用l1,l2,1范数限定模型系数矩阵,结合每一个标签自身特点找出其对应的特定特征和多个标签的公共特征。
(3)为提高分类精准度,假设相似标签之间具有相似输出,相关实例可共享对应标签分布,来约束模型的系数。
1 相关工作
类不平衡是多标签分类过程面临的难题之一,样本与对应标签并非分布在同一数据空间中。多标签分类只采用问题转换或算法适应策略不能很好地解决该问题。针对不平衡问题,已有方法可分为四类:重采样、分类器自适应、集成方法和代价敏感方法。重采样方法[15]对数据集的预处理产生新的平衡多标签数据,独立于分类器组。基于LP变换[16]的重采样方法(LP-RUS)将多标签数据集转换为一个多类数据集,每个不同的标签组合(标签集)作为一个类处理。但基于LP的重采样在解决不平衡问题时受到数据集中标签稀疏性的限制。分类器自适应通过改进现有机器学习方法适应。Luo等[17]提出基于非对称分阶段损失函数,动态调整正样本和负样本的损失代价方法解决不平衡问题。集成方法将几个基本模型结合起来产生最佳预测模型,如BR-IRUS[18]。代价敏感方法使用不同成本度量来描述任何特定错误分类样本的成本,旨在使总成本最小化。如SOSHF[19]通过代价敏感聚类将多标签学习任务转换为不平衡的单标签分类类型。
在多标签分类过程中学习公共特征和标签的特定特征能有效提高计算效率和分类性能。公共特征方法指通过某种方法从原始特征空间中提取对分类过程有意义的特征子集。Zhu等[20]面对缺失标签空间引入流形正则化将特征相似样本在补全标签空间中也接近一致,构建模型时补全标签矩阵,结合实例相关性约束模型系数。MIFS[21]为降低缺失标签在标签相关性中的不利因素,将原标签空间分解至低维,在低维空间进行公共特征筛选。以上方法在模型构建过程中只选择了被所有标签共享的公共特征,而现实中每一个标签都应该在特征空间中有与之对应的特定特征。
其中特征转化的标签特定特征方法有LIFT,LIFTAce[22]和LSDM[23],LIFTAce利用聚类技术结合标签相关性假设满足相关关系的标签共享聚类结果。LSDM通过调整比例参数,针对单个标签的正负实例聚类重建特定特征空间。IMLSF使用加速近端梯度方法,以迭代的方式快速有效地求解目标函数,找出每个标签对应的具体特征。基于l1范数的特定特征方法如LLSF[24]假设标签与特征子集关联,运用线性回归模型区分出对标签具有代表意义的特征。LSFCI[25]通过概率邻域图模型计算实例相关性,在学习标签特定特征时同时考虑实例、标签相关性。
2 类不平衡的公共和标签特定特征多标签分类
本节给出多标签分类问题定义:U是实例集,L是标签集,X为d维的输入空间集,Y是有l个标签的决策属性集。输入数据矩阵X=[x1,x2,…,xn]T∈Rn×d,xi=[xi1,xi2,…,xid],Y=[y1,y2,…,yn]T∈Rn×l,yi=[yi1,yi2,…,yil]。多标签分类是从训练集中学习一种映射f(·):X→Y,然后对测试数据预测标签。
2.1 类不平衡多标签分类方法
为解决类不平衡问题,该文利用重采样策略MLSMOTE单独处理每个少数标签出现的实例集,每个少样本都将是新的合成样本,新实例由特征子集与合成标签集构成,合成标签集指在参考样本及其邻居出现的标签都在合成实例中。该过程主要分为三步:第一步选择一个少数实例作为参考点。在标签空间中计算类不平衡比率得到当前标签的不平衡程度。IRLbl表示单个标签不平衡的程度,MeanIR表示所有标签的IRLbl的均值,见式1和式2:
(1)
(2)
其中,li为L的第i个标签,1≤i≤|L|,yj为xi对应的标签集。若IRLbl(i)≥MeanIR表示该标签比其他标签在标签空间中更加稀疏,将其放入少数类中得到少数类实例包,反之放入多数类。第二步少数实例筛选完成后选择一个与其最近邻居的集合。集合大小由参数K确定,并从邻居集合中随机选择一个实例refNeigh作为参考。第三步特征集和标签集的产生,对每一个样本和其参考实例refNeigh合成实例特征值将沿着连接这两个样本的线进行插值。新实例的标签集,从邻域相关性计算参考样本及其邻居中每个标签的出现次数,包括在合成标签集中出现一半或更多实例中的标签。合成的新实例样本最终被添加到数据集中,对每一个少数类实例包样本和剩余标签做以上步骤处理。为达到更好的平衡效果,每个标签的IRLbl在新标签开始时需重新评估其平衡率,如果一个少数标签在处理过程中达到了MeanIR值,将被排除在合成样本生成过程中。
2.2 公共特征和标签特定特征学习
该文选择线性回归模型分类器,通过投影矩阵W关联特征与标签空间,为提取标签特定特征,采用l1范数方法把投影矩阵中元素稀疏性和参数缩小,同时引入l2,1范数提取公共特征。以上过程可表示为式3:
(3)
其中,W=[w1,w2,…,wl]∈Rd×l为回归模型系数矩阵,且W中第j个标签系数向量为wi=[w1j,w2j,…,wdj]T,wij表示第i个特征对第j个标签辨别程度,wij≠0表示特征与标签存在辨别程度,该特征是第j个标签的特定特征。β和λ2分别控制系统矩阵稀疏性和公共特征、标签特定特征数量。此外学习过程中经常引入标签相关性提高分类性能。但如果简单认为标签间存在相关,某一标签的特定特征对另一相关标签而言也是特定特征,相应的系数向量也相似,此假设不成立[14]。因而,该文假设标签相关对应输出模型XW也相似,且相关性越高,相似度越接近,使用正则项表示为式4:
(4)
其中,Sij表示标签i与标签j的相关性,L1是标签相关性矩阵的拉普拉斯矩阵,因而式3可转化为式5:
β‖W‖1+λ2‖W‖2,1
(5)
借鉴方法LSFCI引入实例相关性增强标签特定特征选择的结果,两实例之间存在强相关性,对应标签空间也存在相关性。该文也引入此技术并在K个实例邻居之间计算相似度C,使用正则项表示为式6:
(6)
其中,Cij表示实例i与实例j的相关性矩阵,L2是实例相关性矩阵的拉普拉斯矩阵。最终目标函数表示为:
λ2‖W‖2,1
(7)
其中,α,β,λ1,λ2为常数参数。
2.3 分类模型处理与优化
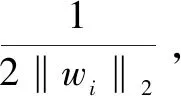
(8)

由近端梯度算法F(W)近似优化表示为:

(9)


(10)

当给定系数矩阵W1,W2,ΔW=W1-W2,有:
αXTXΔWL1+λ1XTL2XΔW+
(12)
利普希茨常数Lf为:

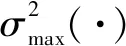
3 实验及其结果分析
3.1 数据集与对比算法
为验证对比所提方法是否取得明显优势,在多个数据集上进行实验。表1给出了实验数据集信息,包含数据量、特征数、标签数、MaxIR和MeanIR,其中MaxIR和MeanIR分别代表最大和平均类别不平衡比。

表1 数据集
将所提方法与常见多标签分类方法进行比较,包括:LLSF,LLSF-DL,LIFT,MLCIB,LSFCI,LSFMLL,JLCLS,CLML。其中LLSF假设任意强相关的两个类标签可以对应特征,利用线性回归方法学习每个类标签的标签特定特征。LLSF-DL[26]在LLSF基础上引入高阶的标签相关性。LIFT通过聚类分析手段在正负实例中学习标签特定特征,参数γ设置为0.1。MLCIB[27]通过学习标签正则化,把原始标签空间映射到新空间中处理缺失标签和类不平衡问题,参数α,β,γ在[0,1]调整,步长为0.1。LSFCI借助标签、实例的相关性学习标签特定特征,参数α,γ值在[2-10,210]范围变化,步长为2,参数η值在[2-12,212]范围变化且步长为2,阈值τ设置为0.5。LSFMLL[28]在模型训练过程中结合标签特定特征和相关性内容。JLCLS[29]利用标签关系型补全缺失标签矩阵,扩展原始标签矩阵内容。所有对比算法相应的参数均按照文献中的建议进行设置,所有的参数值均为其在各个数据集上的最优解。
3.2 评价指标与实验结果分析

(14)
其中,Ri(yj)是样本xi的类标签yj预测等级。
Ranking Loss描述样本的标签对被反向排序的平均比例:
(15)
Micro F1将标签向量的每个条目视为单独实例,不考虑标签的区别:
(16)
Macro F1为各标签的精度和召回率的综合:
(17)
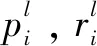
F1为每个样本的精度和召回率的综合:
(18)

Hamming Loss评估样本对应标签分类结果错误的频率,包括标签预测错误或漏预测:
(19)
Δ表示两组之间的对称差。
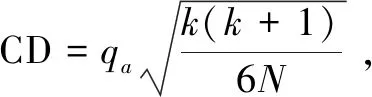

图1 所提方法与对比算法的Nemenyi检验比较结果
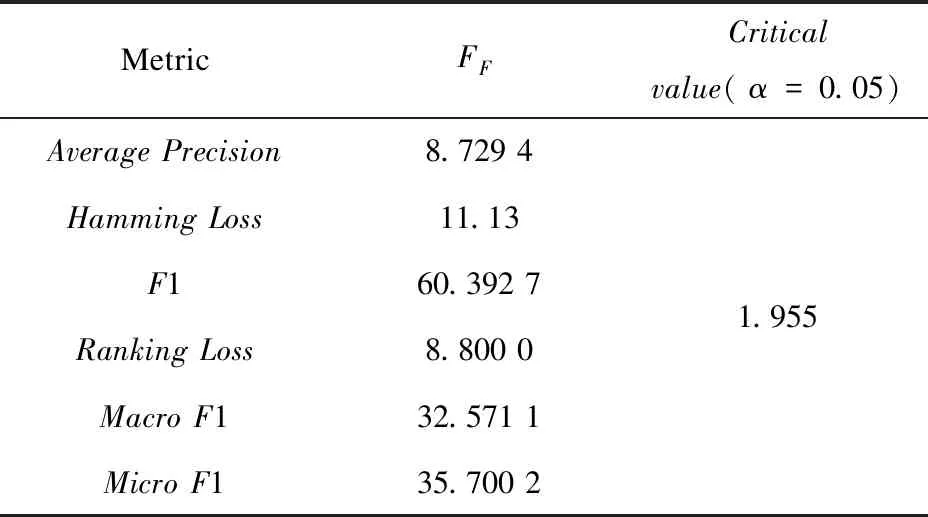
表2 在0.05显著性水平条件下FF每种评估方法的临界值
根据图1可知,在实验指标下所提方法优于对比算法。Hamming Loss指标与标签相关性无明显关系,除LIFT是一阶以外,其余对比算法均为二阶或高阶,实验结果也显示此指标下LIFT算法相对最优,所提方法非最优但在Hamming Loss指标对比其他算法无显著差异。在其余实验指标下所提方法在实验精度上明显高于LLSF,LSFCI,CLML,体现了类不平衡处理和公共特征与标签特定特征的有效性。因为在构建模型过程中根据标签信息学习标签特定特征,类不平衡问题将影响标签特定特征的比重,预测过程倾向大类信息。而使用重采样策略单独处理每个少数标签出现的实例集,每个少数样本视为新的合成样本,可以有效平衡标签特定特征的比重。
此外,在其他单指标上(如Micro F1和Macro F1),所提方法显著优于LIFT,LLSF,LSFMLL。原因在于类不平衡情况下对标签特定特征的选择非最优,且这些方法忽略公共特征带来的优势。CLML指标排名均靠前,原因在于其他方法的假设条件并非总是成立,该文假设相似标签之间具有相似输出,相关实例可共享对应标签分布。通过约束模型的系数可有效解决此类问题,且CLML和所提方法均考虑标签特定特征和公共特征,引入实例相关性和标签相关性,取得了较好的实验结果。
在类不平衡的特殊环境下,不平衡的标签空间给特征筛选过程带来误导,降低了分类精度。例如在MeanIR平均不平衡度较高的Corel5k,Medical和Education数据集上,可以看出所提方法均优于CLML,在低MeanIR值如:数据集Cal500、Genbase类不平衡手段未取得明显优势。虽然在Nemenyi排名上所提方法相比CLML没有取得显著优势,但所有排名均靠前。
为了验证类不平衡处理第二步少数实例筛选完成后选择一个与其最近邻居的集合,集合大小由参数K对实验结果的影响,该文在4个代表数据集Medical,Enron,Science,Education上设置不同参数K,大小在区间[3,4,…,10],步长为1上调整。图2为4个数据上6个评价指标下的实验结果折线图,由图可知实验结果随K的变化而变化,其中K值取3,4,9,10时效果最差,此时筛选出来的集合大小结果要么信息缺失要么信息冗余,取值为5时在Education,Medical,Science数据集上各实验指标结果最优,取8时实验结果在Enron数据集上最优,且在其他数据集上实验结果为次优。实验结果与文献[30]给定建议参数K取值为5吻合。

图2 在4个代表数据集上调整K所得到的实验结果
4 结束语
该文提出类不平衡的公共和标签特定特征多标签分类方法,在类不平衡环境中考虑实例间的相关性及公共特征问题。利用重采样策略,通过找到种子实例的最近邻居结合插值技术得到合成实例的特征。然后综合标签公共特征和标签特定特征的优势进行数据筛选,不仅找出对所有标签都有意义的公共特征集合,还为每一个标签找出最具代表意义的特定特征。最后采用标签相关性实现关联标签的相似模型输出,实例相关性保证关联特征共享对应标签分布信息,提高分类精准度。实验结果表明,通过算法对比,所提方法在精准度上取得明显优势。未来将针对缺失特征与缺失标签的不平衡多标签数据展开研究。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
车迷(2018年11期)2018-08-30 03:20:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
海峡姐妹(2018年3期)2018-05-09 08:21:02
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
