
融合时间序列特征的群组推荐模型
2024-02-20 11:52:18朱欣娟熊依伦
西安工程大学学报 2024年1期
朱欣娟,熊依伦
(西安工程大学 计算机科学学院/陕西省服装设计智能化重点实验室,陕西 西安 710048)
0 引 言
随着人与人之间的联系越来越紧密,群体活动的发展逐渐多样化。在日常生活中,朋友外出就餐、微信读书等群体活动需要有一个满意的结果来权衡群组内用户的差异性。考虑到群体成员的偏好是复杂和相互冲突的,群组推荐系统通过群组内用户与项目的交互作用[1]向单个群组推荐项目来最大程度地满足群体的喜好。如何权衡群组间用户的差异性并为群组推荐一个满意的项目,逐渐成为一个具有挑战性的研究课题[2]。
群组推荐首要步骤是群组识别。依据群组内相似度可分为随机群组和相似群组。随机群组中成员随机聚集在一起,例如餐厅的顾客。随机分配群组的方式,无法汇聚兴趣相似的用户,无法提升推荐质量。相较于随机群组,许多学者尝试使用聚类算法来构建相似群组进行推荐[3]。例如采用K-means聚类[4]、密度峰值聚类[5]或者马尔可夫聚类[6]完成群组划分。众多研究表明,群组内相似度越高,推荐准确率也就越高。
推荐方法是群组推荐系统的重要组成部分,目前应用比较广泛的就是将个性化推荐算法应用到群组领域,主要思想是将单个群组视为一个用户并使用传统协同过滤算法为该群组生成推荐。协同过滤又分为基于内存的协同过滤与基于模型的协同过滤。基于模型的协同过滤的推荐效果要优于基于内存的协同过滤[3],因此受到广泛关注。基于主题的推荐方法是基于模型的协同过滤的一种,通过群组主题来学习群组成员的个人影响,例如PIT模型[7]。考虑到群体动态的内在复杂性,群体偏好不能直接建模。因此准确表征用户偏好是获得群体偏好的重要步骤,对群体成员之间的交互进行建模至关重要[8]。融合策略作为获得群组偏好的关键部分,分为静态融合策略与动态融合策略。静态融合策略提前指定用户所占比重,忽略群组成员动态性或者经验的重叠[9],例如专家策略[10]等。动态融合策略使得群组推荐效果更好,例如纳什均衡策略、注意力机制等。纳什均衡策略将博弈论的思想融入群组偏好融合中,使得推荐效果相较于静态策略得到提升。李琳等将群组满意度的问题转化为求解纳什均衡的问题,有效缓解群组用户之间偏好不一致的问题[11]。目前,越来越多的学者将深度学习的技术应用到群组推荐领域,来获得更好的推荐性能[12]。例如CAO等提出AGREE(attentive group recommendation)模型来学习群组中每个用户的影响力权重,以此融合策略汇聚群组偏好,提高群组推荐准确率,但忽略了用户间交互对群组偏好的影响[13]。SIG(Social-Enhanced Attentive Group Recommendation)模型则利用用户的社会关注者信息增强个体用户表征,有助于捕获用户个人偏好,较好地解决用户间交互对群组偏好的影响[14]。GUO等则提出一种社会自我注意网络来模拟群体成员的投票方案,综合考虑了群体间的社会影响和动态权重调整,模拟群体的复杂决策过程[15]。JIA等设计了一个成员级超图卷积网络来学习群组成员的个人偏好,捕获用户与物品之间的跨群体协作关系,以此提高群组推荐准确率[16]。这些深度学习的技术使得群组中用户影响力权重动态化,充分考虑了群组动态性对于群组决策的影响。
随着时间的推进,用户不断与外界产生交互行为,用户兴趣也随着时间演化[17]。对于一些时尚化产品或动态性对象,用户对某一产品的偏好一定程度上反映了群组对某产品的偏好。若用户偏好无法正确表示,也会影响群组偏好表示,最终导致群组推荐准确率不高。例如某用户在以往的购物历史中,更加倾向购买棕色衣服,而在最新的时间段内,此用户热衷购买天蓝色衣服,随着时间变化,用户的兴趣逐渐从棕色衣服转换为天蓝色衣服。单个用户兴趣迁移如何影响群组决策是值得研究的问题。目前的群组推荐领域中,此类问题尚未得到较好的解决。有学者尝试将时间因素[18]融入推荐模型中,例如孙明阳等将群组内用户偏好与兴趣点空间和时间特性等因素进行融合,实现动态兴趣点群组推荐,该方法将时间特征局限于某个特定时间段,对各时间段内兴趣点进行加权求和[19]。陶永才等利用成员兴趣地点随时间变化这一特征,对成员签到地点对应时间轨迹进行聚类,形成群组数据集,其主要应用场景为用户某一天内不同时间点的不同兴趣点进行推荐[20]。上述2种方法聚焦于将某天划分为多个时间段进行考虑,而对于大型数据序列中依存关系无法有效捕获。因此,群组推荐中如何更好地模拟用户随时间演化的偏好迁移,以及如何获得更加全面的用户偏好表示[21]及其对群组决策产生的影响是一个重大挑战。
综上所述,现有群组推荐系统面临的问题如下:1)采用预定义策略融合群组成员的个人偏好,群组内成员权重没有依据实际情况发生变化,无法反映群组决策过程的动态性[22];2)群组推荐系统中并未过多考虑单个用户随时间演化兴趣偏好迁移过程,无法准确表征用户偏好。针对上述问题,本文提出一种融合时间序列和注意力机制的群组推荐算法TAGR。模型中使用循环神经网络GRU(gate recurrent unit)建模用户兴趣随时间的演化,从时间序列中捕捉用户兴趣迁移过程,通过聚合的方式准确表征用户的兴趣偏好[23]。同时,利用注意力机制融合群组偏好,以动态加权的方式强化组内具有代表性的用户,利用项目和群组之间的交互信息对群组偏好进行建模。
1 模型概述
1.1 群组形成
群组识别作为群组推荐的首要步骤,分为实际群组和虚拟群组。在很多情况下,需要构建虚拟群组进行推荐。为了获得高相似度群组,本文采取层次聚类进行虚拟群组的构建。层次聚类算法基于簇间的相似度在不同层次上分析数据,从而形成树形的聚类结构。其主要思想是将每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度。再寻找各个类之间最近的两个类,归为一类。之后重新计算新生成的这个类与各个旧类之间的相似度,并不断重复上述步骤,直到所有样本点归为一类。可设立一个阈值,当最近两个类的距离大于这个阈值,迭代终止。相似度(D)计算公式为
式中:n为单个群组内用户的数量;pk和qk分别为数据对象p和q的第k个维度。
1.2 融合时间序列和注意力机制的群组推荐模型
群组偏好来源于群组内用户的偏好融合。许多融合策略采用预定义策略来聚合成员评分,例如最大值等。预定义策略忽视用户与项目之间的交互性,没有充分考虑群体决策的影响因素。在某个群组中,可能某个用户对商品的影响力较大,该用户对商品的话语权也就更高,按照预定义策略,无法体现出该用户的影响力。结合注意力机制的群组推荐很好地解决了上述问题,但在成员偏好中忽略了用户兴趣迁移过程。为解决上述问题,构建了融合时间序列的群组推荐模型TAGR,如图1所示。

图 1 TAGR方法结构图Fig.1 Structure diagram of TAGR method
为了捕捉用户兴趣偏移过程,更好地表征用户偏好,在输入层提取每个用户各时刻的行为,经过嵌入层获得用户各时刻行为向量,输入GRU中。利用GRU获取每个时刻用户行为的兴趣偏好,并聚合各时刻兴趣偏好作为用户偏好。其次利用注意力机制学习群组内用户偏好权重,结合用户偏好得到群组偏好向量。将单个群组看成单个用户进行个性化推荐,获取推荐结果。
图1中,G={U1,U2,…,Un}为群组用户;et为某个用户t时刻的行为。为了更好地体现用户兴趣偏好迁移的过程,采用GRU训练用户偏好迁移过程,GRU结构如图2所示。

图 2 GRU结构图Fig.2 GRU structure diagram
将用户浏览过的项目按照浏览时间做排序,把原始的id类行为序列特征转换成嵌入行为时间序列。将行为时间序列输入GRU中,并提取每个时刻下,此用户行为背后潜藏的兴趣状态。从连续的用户行为中提取一系列的兴趣状态。其公式为:
zt=σ(etWxz+ht-1Whz+cz)
rt=σ(etWxr+ht-1Whr+cz)
式中:et为GRU的输入,表示用户第t时刻行为向量;rt表示第t时刻输入信息与之前记忆的结合程度;zt表示前一时刻的状态信息被带入到当前状态中的程度;ht为第t时刻隐藏状态;Wxz、Whz、Wxr、Whr、Wxh、Whh分别为权重矩阵;cz、cr、ch分别为偏置矢量。隐藏状态ht捕捉行为之间的依赖关系,表示t时刻对于上一时刻有效偏好信息的获取,无效信息进行遗忘,以此表示t时刻用户兴趣偏好。将每个GRU单元的ht累加作为此用户偏好xn,即
xn=∑t=0ht
结合注意力机制,获得此用户在本项目所占权重,将此权重作为用户偏好权重,融合用户偏好作为群组偏好,即
o(j,n)=hTReLU(svij+suxn+b)
式中:sv、su分别为项目嵌入和用户嵌入转换到隐藏层的注意力网络的权重矩阵;b为隐藏层的偏置矢量;ij为当前第i用户与第j项目的交互编码,使用ReLU作为激活函数,然后投影到具有权重矢量h的注意力得分o(j,n);n′为群组内用户下标,最后使用softmax函数对得分进行归一化。
式中:a(j,n)为群组内所有用户的注意力权重;tk为第k群组与项目j的交互编码,以此表示单个群组普遍偏好。gk(j)作为第k群组偏好输入至推荐模型中。
1.3 基于神经协同过滤的推荐模型
本文选择神经协同过滤(neural collaborative filtering,NCF)框架对嵌入(项目、组)和交互函数进行端到端学习。NCF是一个用于项目推荐的多层神经网络框架[24],将用户嵌入与项目嵌入输入特定神经网络中,利用用户与项目的交互数据训练模型。
将上文所获取的群组偏好矢量gi点乘项目j的嵌入矢量,并将其与用户i和项目j的嵌入矢量进行拼接,即
所得f0将作为隐藏层输入,使用ReLU函数作为非线性激活函数,即
式中:Wh为隐藏层第h层的权重矩阵;bh为第h层偏置矢量;fh为第h层输出神经元。最后将最后一层神经元作为预测函数的输入,即
ylj=WTfh
所得ylj为最终的群组-项目的预测,WT为最后一层权重矩阵。通过上述公式,得到最终预测结果。
1.4 算法复杂度
利用GRU与注意力机制来获得群组偏好表示。在GRU中,获取单个用户偏好表示,其时间复杂度为a(d×v),其中d为单个用户某时刻项目嵌入维度,v为用户与项目的交互次数。之后利用注意力机制获取群组偏好,其时间复杂度为a(d×v×n×t),n代表群组内人员数量,t代表项目数量。
2 实验结果与分析
2.1 数据集
Goodbook数据集来源于goodreads网站,包含10 000本最受欢迎图书的6百万评分数据,从中截取了3 434个用户的22 279条用户交互记录,其中用户交互记录按时间顺序排列。MovieLens 数据集是由GroupLens项目组制作的公开数据集,包含6 000名用户对4 000部电影的100万条评分数据,从中截取了3 380个用户的42 105条用户交互记录,用户交互记录按照时间顺序排序。数据如表1所示。
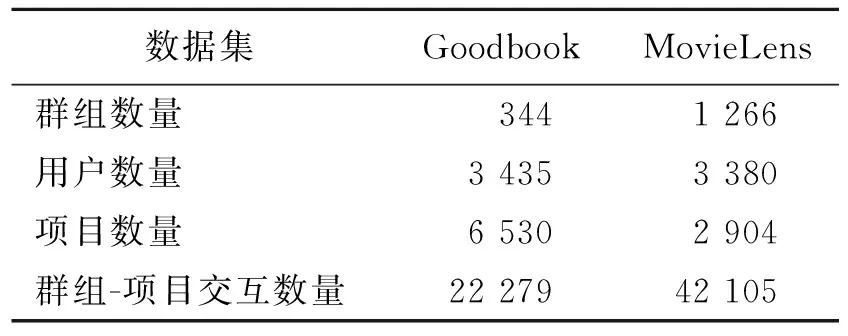
表 1 数据集统计信息表
2.2 实验环境
实验在Ubuntu18.04操作系统下运行,Pytorch1.9.1 GPU基础镜像,GPU计算型GN7/8核/32 GiB/5 Mbps。本文对Goodbook和MovieLens数据集采用层次聚类的方法来进行群组划分,通过实验选取相似度阈值为0.3,将单个群组用户数量为1的群组剔除。并将数据集按照2∶8的比例随机划分为测试集与训练集,每个模型计算5次后取其平均值作为最终实验结果,模型epochs设置为35。实验参数[14]如表2所示。

表 2 模型参数设置
2.3 评价指标
本文所使用的评价指标分别是命中率HR(hit ratio,记为HR) 和 归 一 化 折 扣 累 积 增 益NDCG (normalized discounted cumulative gain,记为NOCG)。公式中HR用来衡量推荐项目的命中率,测量了推荐的准确性,指标数值越大说明效果越好;NoH表示点积数量;TN表示测试项目集合;N为Top-N,表示推荐项目的个数。计算公式为
NDCG用来衡量列表的排序质量,越接近1说明推荐越准确;DCG为折损累计增益,对每一次收益添加一个折损值;IDCG为理想状态下最大的DCG值。计算公式为
2.4 对比算法(基线模型)
为了评估本算法的性能,将本文算法与NCF[24]、Popularity[25]、AGREE[13]、FastGR[26]等多种方法进行比对,以此验证算法的有效性。
1) NCF:基于神经网络的协同过滤,将组视为用户,作为网络输入,从组项历史数据中学习交互功能。
2) Popularity:根据项目的受欢迎程度向用户和群组推荐。由于受本数据集的影响,项目的受欢迎程度依据其在训练集中的交互次数来衡量。
3) AGREE:该模型首次将注意力机制引入群组推荐中,主要依据用户与项目的历史交互数据为每个成员动态分配权重。
4) GREE:GREE删除了AGREE模型中注意力网络,采用统一权重。
5) NCF+avg:NCF与平均值的结合,将个体的偏好得分平均为组偏好得分。这种方法的假设是每个成员对最终群体决策的贡献相等。
6) FastGR:一种基于神经协同过滤的群组推荐算法,利用卷积神经网络提取用户特征。
实验效果如表3,在Goodbook数据集上,将本模型TAGR和其他多个模型进行对比实验。可以看出,当K=5时,TAGR模型相较于Popularity、GREE、AGREE、NCF、NCF+AVG、FastGR,在指标HR上分别提升了16.97%、8.48%、4.70%、8.97%、6.93%、4.04%,在指标NDCG上分别提升了12.47%、7.48%、5.01%、7.16%、5.66%、3.10%。当K=10时,TAGR模型相较于Popularity、GREE、AGREE、NCF、NCF+AVG在指标HR上分别提升了17.33%、5.53%、3.30%、5.89%、4.80%、1.76%,在指标NDCG上分别提升了11.47%、4.36%、3.69%、4.68%、3.92%、2.48%。
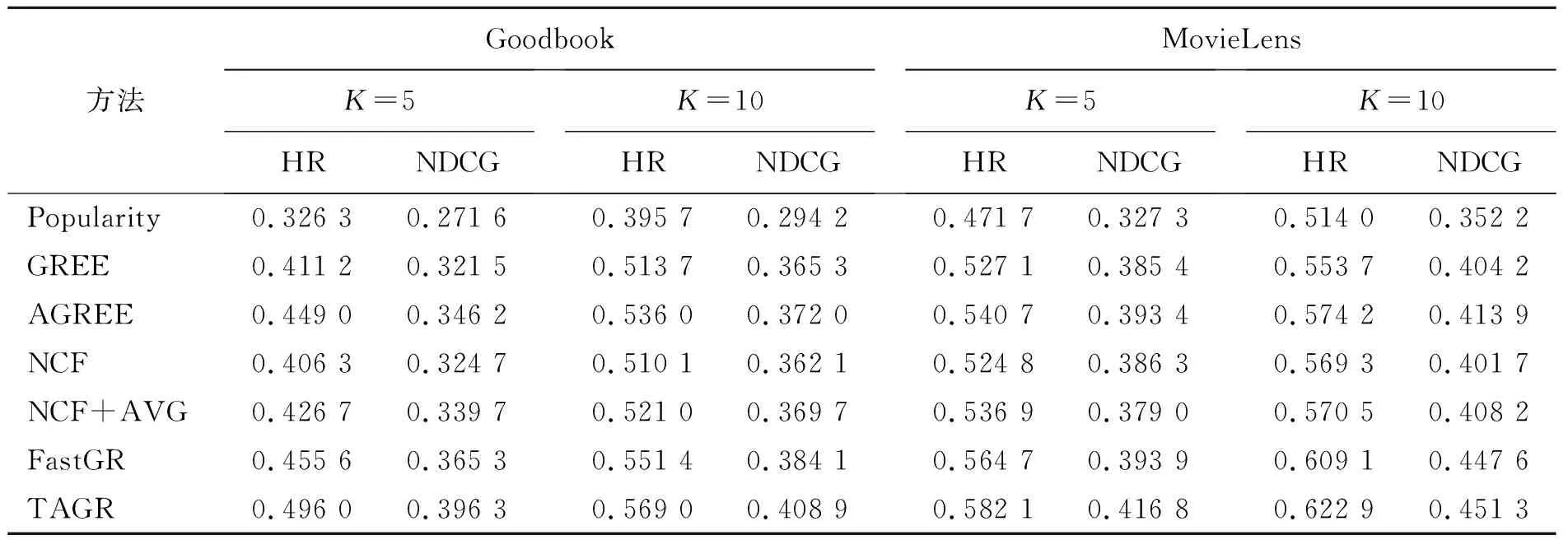
表 3 实验结果表
在MovieLens数据集上,将本模型TAGR和其他多个模型进行对比实验。当K=5时,TAGR模型相较于Popularity、GREE、AGREE、NCF、NCF+AVG、FastGR在指标HR上分别提升了11.04%、5.50%、4.14%、5.73%、4.52%、1.74%,在指标NDCG上分别提升了8.95%、3.14%、2.34%、3.05%、3.78%、2.29%。当K=10时,TAGR模型相较于Popularity、GREE、AGREE、NCF、NCF+AVG在指标HR上分别提升了10.89%、6.92%、4.87%、5.36%、5.24%、1.38%,在指标NDCG上分别提升了9.91%、4.71%、3.74%、4.96%、4.31%、0.37%。
综上可知,本文所提出的TAGR模型在HR与NDCG指标上均高于选取的基线算法,提升了群组推荐的准确率。实验中NCF与NCF+AVG的实验数据较低,主要原因在于采用静态策略融合群组成员偏好,忽略了群组用户对项目的影响力。而AGREE模型采用注意力机制进行成员偏好融合,提升推荐性能,但是忽略了用户偏好迁移过程,无法准确表征用户偏好。FastGR模型采取卷积神经网络优化了模型,提取了用户特征,但同样也忽略了用户偏好迁移过程。本模型TAGR通过时间序列捕捉用户兴趣偏移过程,准确表征用户偏好,并利用注意力机制对群组成员进行偏好融合,以此获得准确性更高的群组推荐结果。为了进一步研究模型的有效性,将本文模型TAGR与AGREE模型在Goodbook数据集上进行比较。图3、4显示了在最佳参数设置下,TAGR与AGREE在每次训练迭代中HR与NDCG的变化趋势。

(a) K=5
图3(a)、4(a)中可以看出,当K=5时,经过25次迭代后,TAGR模型的HR与NDCG逐渐趋于稳定。图3(b)、4(b)中可以看出,当K=10时,经过27次迭代后,TAGR模型的HR与NDCG逐渐趋于稳定。说明在Goodbook数据集上,TAGR模型效果比AGREE模型效果更优。证明本模型可以有效捕捉用户兴趣迁移过程,得到更为准确的群组偏好表示,提高了推荐的准确率。
为了验证时间序列对模型是否有促进作用,本文采取相关消融实验进行验证,结果如表4所示。

表 4 消融实验结果
TAGR-A表示TAGR模型去除注意力机制的方法,此模型在群组内得到每个用户偏好后,不再使用注意力机制模拟用户与项目之间的交互。TAGR-T表示在TAGR模型去除时间序列的方法。TAGR-T的实验数据略优于TAGR-A,主要原因在于TAGR-A中去除注意力机制,群组的偏好融合采用静态策略,群组的偏好准确性的丢失相较于TAGR-T模型中单个用户偏好准确性的丢失影响更大。表4数据表明,TAGR模型优于TAGR-A和TAGR-T,验证了捕获用户兴趣偏移过程可以更为准确地表征用户偏好,也证明了注意力机制对于单个群组内用户的偏好权重起到促进作用。
3 结 语
本文针对传统的预定义策略过于单一,忽视用户与项目之间的交互性,同时无法捕捉时间推移所造成的用户偏好迁移,采用GRU捕捉用户兴趣偏移过程,融合用户交互记录作为用户偏好,更为准确地表征用户偏好,并结合注意力机制来获取群组内各用户对于此项目的偏好占比权重。在此基础上,采用神经协同过滤算法学习群组与项目交互。实验验证本文所提出的模型优于基线模型,提升了群组推荐准确率。但此模型对于用户社交关系对群组偏好融合的影响尚未考虑。在未来的研究中,会将用户社交关系融入推荐算法中,进一步提升群组推荐准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
当代陕西(2020年17期)2020-10-28 08:18:18
电子测试(2018年14期)2018-09-26 06:04:10
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:42
河南科技(2014年15期)2014-02-27 14:12:51
计算机工程与设计(2011年7期)2011-09-07 10:16:54
