
基于机器视觉的煤矸石分选方法研究
2024-02-20 08:51石亦琨李润田党长营曾志强
中国矿业 2024年1期
石亦琨,李 峥,李润田,党长营,曾志强
(1.北京星途探索科技有限公司,北京 100176;2.中北大学机械工程学院,山西 太原 030051;3.先进制造技术山西省重点实验室,山西 太原 030051)
0 引 言
在煤炭开采中,原煤中混杂的煤矸石占15%~20%。煤矸石是一种含碳、硅、铝的混合物,密度较大、发热量小,因此一般需要通过“选煤”工艺将煤矸石与煤块分离出来[1]。近几十年,我国因经济发展需要大规模开采煤炭,聚集了大量矸石山,不仅占用大量土地,还对大气和水体造成了不可估量的污染。同时,煤矸石山中会夹杂一定比例的煤块,使得矸石山存在自燃的风险,由此将对环境造成更加难以估量的污染[2-3]。因此,研究如何高效地将煤块中夹杂的矸石分离出来具有重要意义。
目前,我国应用较多的煤矸石与煤块分选方法是人工选矸、射线选矸、重介质选矸等[4]。人工选矸是依靠人工进行,有赖于操作工人的主观意识,故分选结果存在大量的误选、漏选等情况,且分选效率以及精度很难得到保障[5]。射线选矸主要是以X 射线和γ 射线穿过煤和矸石过程中产生的不同能量衰减为依据来识别矸石和煤块,但是该方法后期维护成本高,且产生的辐射严重危害工人健康[6]。重介质选矸在分选过程中则会浪费大量的水资源,且占用面积过大[7],缺点较为明显。近年来,随着深度学习迅速发展,一些学者将深度学习技术应用于煤矸石分拣领域,郑爽等[8]提出了一种基于AlexNet-SN 网络的煤矸石检测方法,首先对网络进行改进,其次引入风格迁移技术增强数据集的多样性,实验证明该方法检测精度为85%,较原网络提高了1.8%。李亚坤等[9]通过在VGG-16 网络中加入Dropout 和正则化等操作,在参数量大幅降低的同时,训练集与验证集的精度分别为99.73%与97.58%。郑道能[10]针对传统机器视觉的煤矸石识别方法检测速度与精度无法平衡的问题,提出了基于改进的tiny YOLOv3 的煤矸石检测方法,在满足检测精度的前提下,单张图片检测速度仅为12.5 ms。
因此,本文在深度学习的基础上提出一种基于机器视觉与YOLOv5 算法结合的煤矸石分选方法,并对YOLOv5s 网络模型进行优化,使其能准确识别煤矸石与煤块。
1 煤矸石自动分选系统原理
煤矸石自动分选系统工作原理如图1 所示。由图1 可知,物料经过上料机构预筛后落到传送带上,经过排队机构排序后依次有序前进,防止物料堆积。当经过图像采集装置下方时,相机对物料进行图像采集,送入目标检测网络进行识别。当识别到目标物料为矸石时,计算机发出指令控制高压气阀喷气,将矸石吹入矸石料斗;当识别到目标物料为煤块时,气阀不动作,煤块落入煤块料斗,从而实现煤矸石与煤块的分离。

图1 煤矸石自动分选系统工作原理示意图Fig.1 Schematic diagram of the working principle of coal gangue automatic sorting system
2 基于机器视觉的煤矸石自动分选方法
2.1 YOLOv5 网络原理
YOLO 系列算法有速度快、检测精度高等优点,在计算机视觉领域得到了广泛应用[11]。本文采用的YOLOv5 算法包含四个模型,分别为YOLOv5s 模型、YOLOv5l 模型、YOLOv5m 模型和YOLOv5x 模型,网络大小依次增大,检测时间也依次增加,考虑到时间成本等因素,本文选用YOLOv5s 模型。
YOLOv5s 模型主要结构可以分为输入网络(Input)、主干网络(Backbone)、颈部网络(Neck)以及预测网络(Head)四个部分,图2 为其网络结构图。输入网络(Input)采用Mosaic 数据增强的方法,从训练集随机选取四张图像进行缩放与裁剪,拼接成一张图像,这种方法能够有效增加数据集的样本数量和多样性,提高目标检测模型的鲁棒性与精度。主干网络(Backbone)的作用是提供一个特征提取器,可以识别图像中的特征,并将这些特征转换成高维特征向量,用于后续的分类、定位和检测任务,主要分为Conv 模 块、CSPDarkNet53 模 块 和SPPF 等 模 块。在颈部网络(Neck)中,YOLOv5s 模型采用了FPN+PAN 特征图像金字塔结构,将不同尺度的特征图进行融合,并且将多个尺度的特征图进行上采样与下采样等操作,使其具有相同的尺度和分辨率,然后进行拼接,得到一个更加全局的特征图来提高检测精度。在预测网络(Head)中,使用CIoU_Loss 函数作为损失函数,分别对大、中、小三种尺寸的目标对象进行检测。
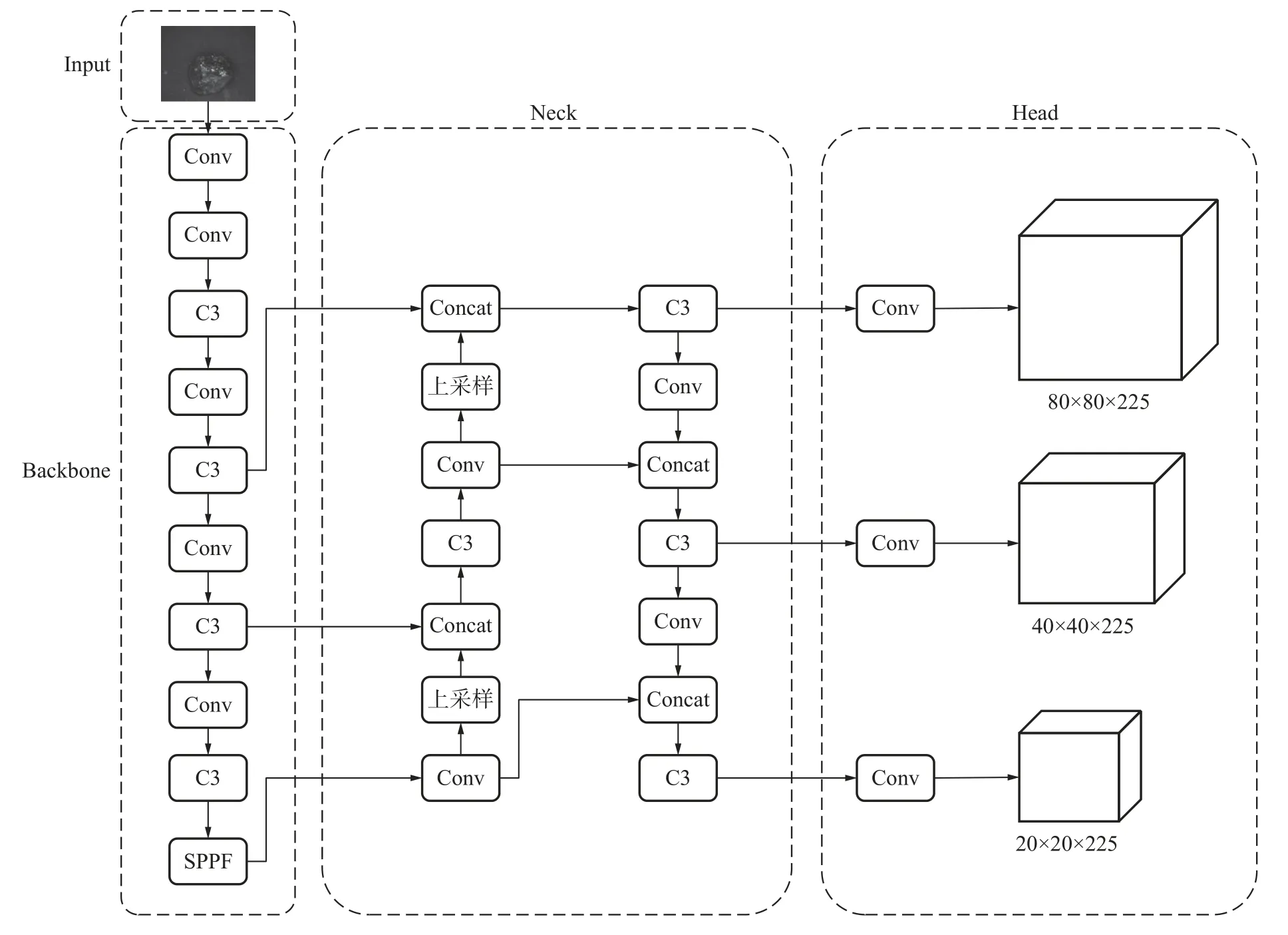
图2 YOLOv5s 模型网络结构Fig.2 Network structure of YOLOv5s model
2.2 网络优化改进
为了提高模型检测精度、增强对小目标的检测能力,针对YOLOV5s 原网络进行如下改进。
1)在主干网络(Backbone)中引入CBAM 模块注意力机制,提高网络的特征提取能力与泛化能力。
2)在颈部网络(Neck)使用BiFPN 加权双向特征金字塔网络替换PANet 结构,加快网络多尺度特征融合,提高对小目标的检测能力。
3)在预测网络(Head)中,使用EIoU_Loss 函数替代CIoU_Loss 函数作为网络的损失函数,进一步提高网络识别准确率,加快网络收敛。
2.2.1 CBAM 注意力模块
YOLOv5s 模型针对不同的目标检测场景,设计了四种不同大小的模型,但针对一些小目标的检测效果会变差。此外,由于本文选用的YOLOv5s 模型的深度以及宽度最低,会造成网络对小目标物体特征提取信息的丢失,特别是在煤矸石与煤块的检测中,会夹杂较多的小目标物体,影响其检测精度。针对这一不足,在YOLOv5s 模型主干网络(Backbone)中加入CBAM 模块注意力机制来提高检测精度,其结构图如图3 所示。

图3 CBAM 模块结构原理图Fig.3 Structure schematic diagram of CBAM module
CBAM 模块是一种基于注意力机制的卷积神经网络模块,可以有效地提高模型的表现力和泛化能力。CBAM 模块主要包含两个部分:通道注意力和空间注意力。其中,通道注意力机制可以自适应地学习每个通道的重要性,从而增强有用的特征通道,抑制无用的特征通道;空间注意力机制可以自适应地学习每个空间位置的重要性,从而增强有用的空间位置,抑制无用的空间位置。CBAM 模块将通道注意力和空间注意力相结合,可以自适应地学习每个通道和空间位置的重要性,从而提高模型检测精度。
2.2.2 加权双向特征金字塔结构
在YOLOv5s 模型中,颈部网络(Neck)部分主要使用PANet 结构对来自不同特征层的信息进行融合,PANet 结构[12]相较于原始的FPN 结构增加了一条自下而上的特征通道,能够实现自上而下与自下而上特征融合,提高了检测精度,但是计算量较大,增加了模型的训练时间与推理时间,因此,本文引入BiFPN 结构对颈部网络(Neck)部分进行改进。BiFPN 结构是加权双向特征金字塔结构,其主要思想包括高效的双向跨尺度连接和加权特征图融合[13],相比于PANet 结构,首先BiFPN 结构删除了只有一个输入端的节点,减少了计算量;其次BiFPN 结构将自上而下和自下而上的路径视为一个网络,并且允许多次重复叠加,能够融合更多特征,提高对小目标的检测能力。此外,BiFPN 在特征融合的过程中为每个输入添加了一个权重,可以通过调整权重的大小来学习更多的特征。图4 为两种不同的特征金字塔结构。
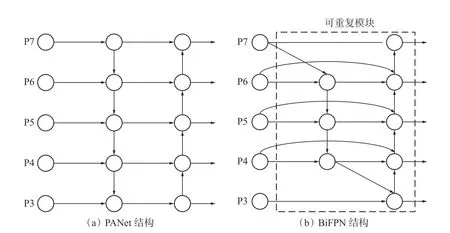
图4 两种不同特征金字塔结构Fig.4 Two pyramid structures with different features
2.2.3 EIoU 损失函数
在YOLOv5s 模型中使用CIoU_Loss 函数作为其损失函数,具体表达式见式(1)。
式中:IoU为预测框与实际框的交并比;b、bgt为预测框与实际框的中心点;ρ为预测框与实际框的两个中心点的欧几里得距离;c为包含预测框与实际框最小矩形的对角线长度;α为权重系数;v为预测框与实际框的宽高比特性。
CIoU_Loss 函数通过计算各个框的欧几里得距离,解决了预测框与实际框互相包含的问题[14],但是其结果比较固定,不能很好地适应高IoU 损失、低IoU 损失和梯度加权的问题。为了提高网络识别精度和加快收敛,本文采用EIoU_Loss 函数[15]替换CIoU_Loss 函数,具体表达式见式(2)。
式中:cw、ch为最小封闭矩形的宽和高;w、h为预测框的宽和高;wgt、hgt为实际框的宽和高。
EIoU_Loss 函数继承了CIoU_Loss 函数的优点,又引入了宽高损失,能使真实框与预测框的宽和高之差达到最小,使得网络收敛速度加快。经过上述改进以后的YOLOv5s 模型网络结构如图5 所示。
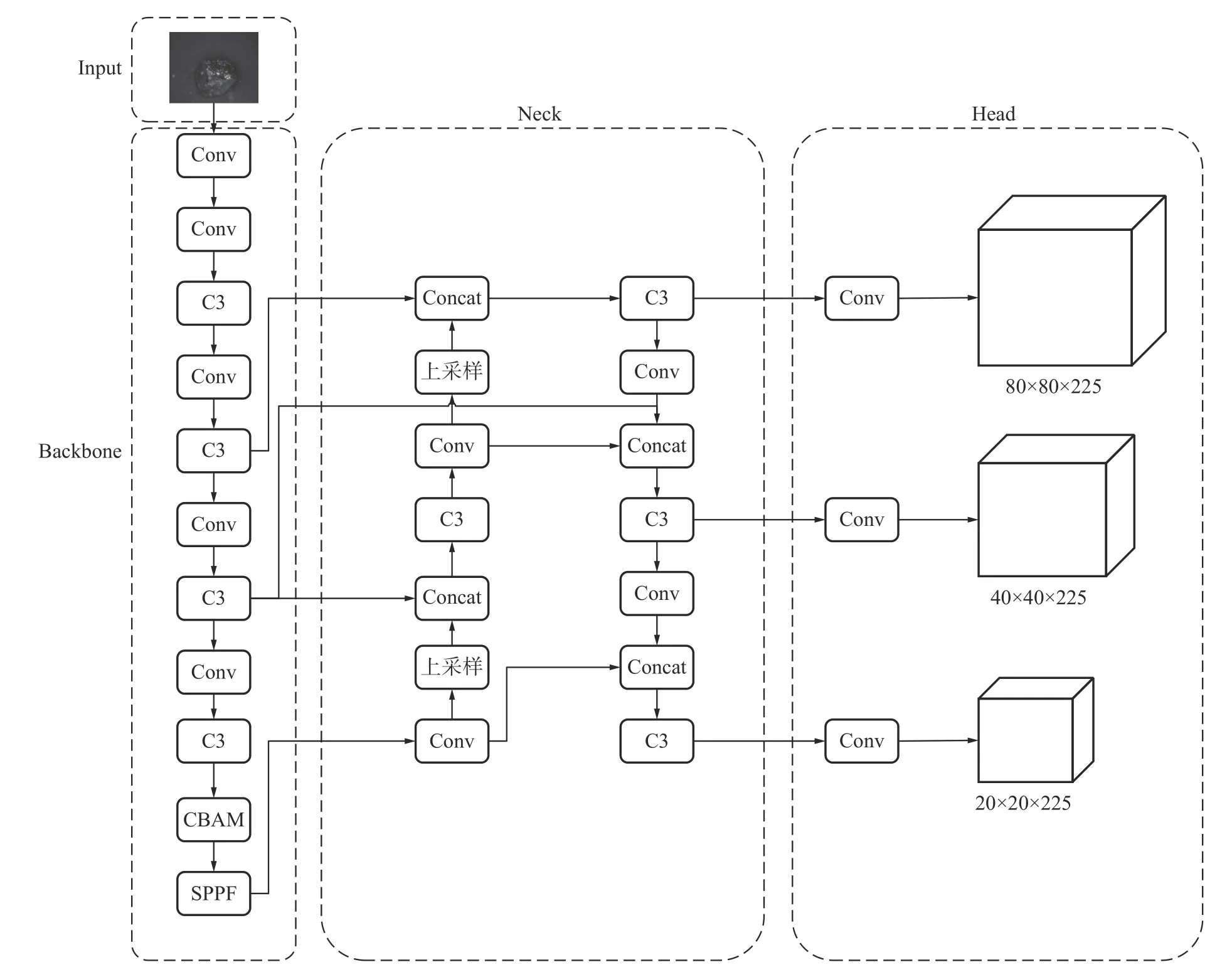
图5 改进后YOLOv5s 模型网络结构Fig.5 Network structure of improved YOLOv5s model
2.2.4 数据增强
在深度学习中,过少的数据集往往会导致模型出现过拟合现象,从而导致模型的泛化能力较差,无法满足实际需求,因此在网络训练前应准备足够的数据集[16]。由于实验室样本数量有限,本文采用旋转、平移、随机亮度设置等图像增强的方法对现有数据集进行扩充。图6 和图7 为部分增强后的数据集。

图6 图像平移Fig.6 Pan for image

图7 图像随机亮度设置Fig.7 Random brightness settings for images
经过图像增强以后,样本数量由原来的1 000 张扩充到2 000 张,其中,煤块图像为900 张,矸石图像为800 张,煤块与矸石图像为300 张,按照8∶1∶1的比例划分训练集、验证集与测试集,其中,训练集包含图像1 600 张,验证集和测试集各包含图像200 张。
3 实验过程及分析
3.1 实验环境与评价指标
本文算法软硬件配置如下所述:操作系统为Windows10,CPU 为i5-12600kf,内存容量为16 G,显卡为NIVIDIA GeForce RTX3080,显存为12 G,编程语言为python3.8,采用PyTorch 深度学习框架。为了保证对比实验的客观性与真实性,对改进前后网络进行测试时,选用相同的超参数,见表1。

表1 超参数设置Table 1 Setting of hyperparameters
本文实验选用平均精度均值mAP(mean Average Precision)和损失函数作为模型的评价指标,其中,mAP 表示模型对所有类别预测平均精度的平均值,mAP 值越高代表检测效果越好,常用的有mAP@0.5(预测框与实际框的交并比阈值为0.5)和mAP@0.5∶0.95(交并比阈值从0.5 到0.95,步长0.05)。本文选用mAP@0.5 作为改进前后模型的评估指标,mAP 可通过以精确度P为纵轴、召回率R为横轴的P-R曲线求得,计算公式见式(3)~式(6)。
式中:TP为将真目标预测为真目标的数量;FP为将假目标预测为真目标的数量;FN为将真目标预测为假目标的数量;AP为模型计算单类别平均精度;k为类别总数。
3.2 实验结果分析
为了验证改进后YOLOv5s 模型识别煤矸石与煤块的准确性与有效性,本文设置对比实验,实验分别用改进前后的算法在相同的配置环境下进行训练,训练结果如图8 所示。
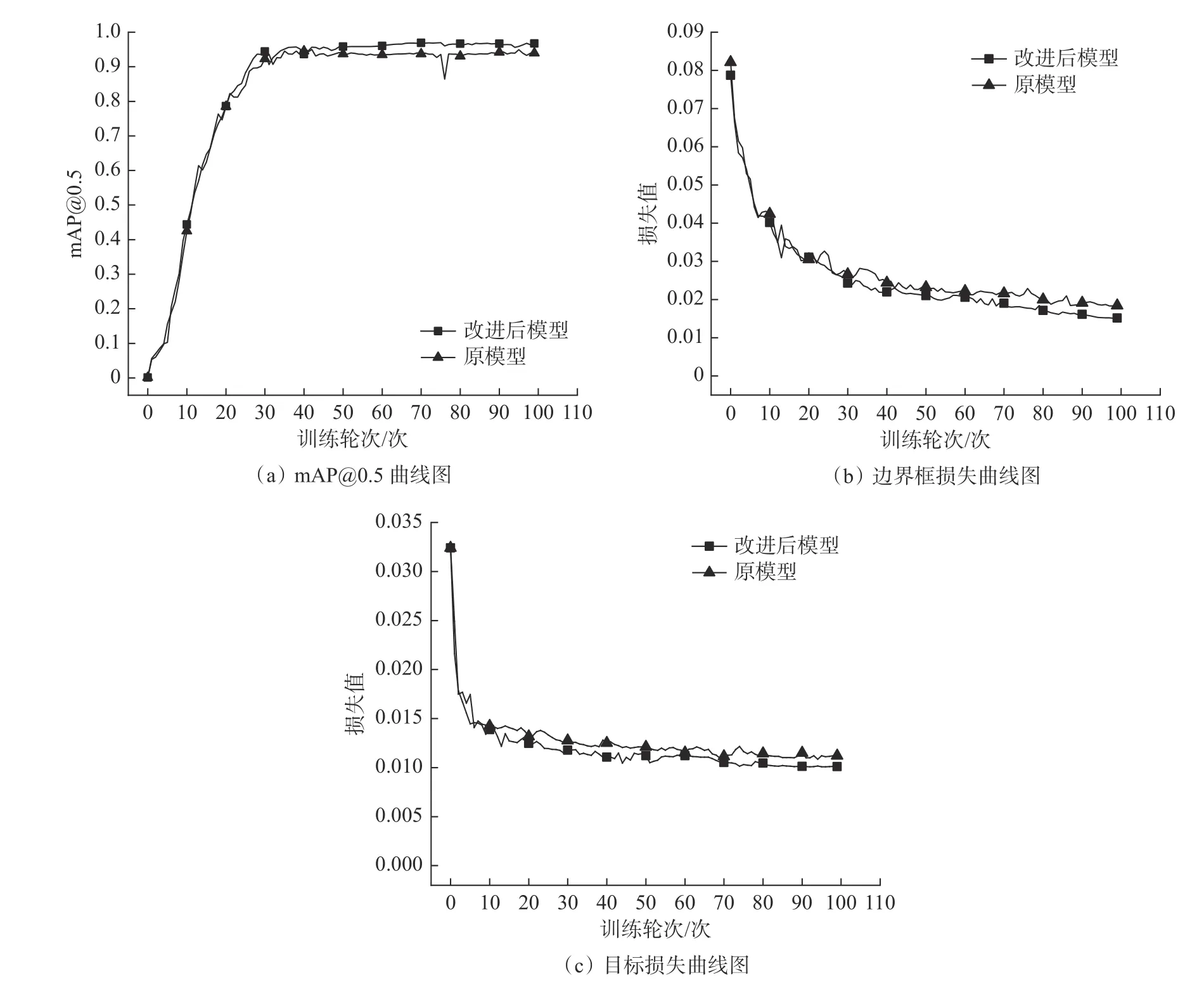
图8 模型改进前后实验结果曲线图Fig.8 Experimental results curves before and after model improvement
由图8(b)和图8(c)可知,改进后模型的损失函数相较于原模型更加平滑,且损失值更小,在边界框损失中较原模型下降了约0.003 2,在目标损失中下降了约0.001 3,说明改进后网络检测效果更好,鲁棒性更强。由图8(a)可知,当训练30 轮以后两个模型mAP 值相差不大,均在0.91 左右,在后面训练当中,原模型上升速度开始减慢,最终稳定在0.93 左右,而改进后模型上升速度较快,且更加平稳,最终稳定在0.95 附近,说明改进后模型的检测精度更高。为了更清楚地展现改进后模型的效果,选取两组测试结果进行对比,如图9 所示。

图9 改进前后模型识别结果图Fig.9 Model recognition results before and after improvement
4 结 论
1)针对当前煤矸石分选效率低、自动化程度不高等问题,提出了一种基于机器视觉与YOLOv5s 模型相结合的新分选方法,并经过实验验证了该方法的可行性。
2)改进后模型的平均识别精度达到了95.3%,较原网络提高了2.1%,能够很好地完成煤矸石分选,为后续基于机器视觉的自动化分选系统设计提供相应的理论基础。
猜你喜欢
建材发展导向(2022年18期)2022-09-22
山西冶金(2022年3期)2022-08-03
陕西煤炭(2021年6期)2021-11-22
煤炭与化工(2021年5期)2021-07-04
环球时报(2020-12-25)2020-12-25
文萃报·周五版(2020年10期)2020-03-23
环球时报(2020-03-05)2020-03-05
山东冶金(2019年5期)2019-11-16
上海建材(2018年2期)2018-06-26
济宁医学院学报(2014年4期)2014-08-16
