
基于专家反馈的广义孤立森林异常检测算法
2024-02-18 23:20:50祝诚勇黄鹏翔李理敏
计算机应用研究 2024年1期
关键词:异常检测
祝诚勇 黄鹏翔 李理敏


摘 要:针对孤立森林算法无法检测与轴平行的局部异常点以及树结构无法动态更新等问题,提出了一种基于专家反馈的广义孤立森林异常检测算法。首先,将数据映射在单位特征向量上,从映射区域内选择分割点划分数据空间,重复此操作构造出一棵广义孤立树;然后,给广义孤立森林中每棵树的叶节点引入权重,综合考虑子空间划分次数和子空间内样本数量对数据异常分数的影响;最后,计算每个数据的加权异常分数,并选择异常分数较大的数据交由专家进行批量标注,算法根据标注结果更新叶节点权重,从而实现树结构的动态调整。实验结果表明,该算法在7个数据集中专家标注真实异常的数量优于其他同类树结构算法,并在12个数据集中平均准确率比孤立森林、扩展孤立森林和广义孤立森林分别提升了38.952%、49.144%和49.144%。
关键词:异常检测; 孤立森林; 动态更新; 专家反馈
中图分类号:TP393 文献标志码:A 文章编号:1001-3695(2024)01-014-0088-06
doi:10.19734/j.issn.1001-3695.2023.05.0182
Generalized isolation forest anomaly detection algorithm based on expert feedback
Abstract:Aiming at the problem that the isolation forest algorithm cannot detect local anomalies parallel to the axes and the tree structure is unable to be dynamically updated, this paper proposed a generalized isolation forest anomaly detection algorithm based on expert feedback. Firstly, it projected the data to the sampled normal unit vector, and selected a split point from the mapping area to divide the data space, then repeated these operations until constructed a generalized isolation tree. Secondly, it introduced the weights of the leaf nodes of each tree in the generalized isolation forest, which comprehensively considered the influence of the number of subspace partitions and the sample size in the subspace on anomaly scores. Finally, it calculated the weighted anomaly scores of each data, and submitted data with high anomaly scores to expert for batch labeling, then the algorithm updated the weights of the leaf nodes according to the labeling results, so as to dynamically adjust the structure of the generalized isolation tree. The experimental results show that the numbers of real abnormal data are marked by expert in 7 datasets are better than that of the other tree-based anomaly detection algorithms, and the average precision in 12 datasets are 38.952%, 49.144% and 49.144% higher than isolation forest, extended isolation forest, generalized isolation forest, respectively.
Key words:anomaly detection; isolation forest; dynamic update; expert feedback
0 引言
異常检测(anomaly detection,AD),又被称为新奇点检测(novelty detection,ND)或离群点检测(outlier detection,OD),可以识别出与正常数据不同的数据,或与预期行为差异大的数据[1],是数据挖掘领域的一个重要研究方向,在工业[2]、金融[3]、网络[4]等诸多领域中都有广泛的应用。
目前,异常检测方法根据数据标签的使用情况可以分为监督、半监督、无监督三类[5,6]。标签数据的获取和标注需要大量的时间和精力,而且异常行为可能会随时间发生动态变化,难以获得全面且准确的带有标签的数据集[7]。因此,研究无监督异常检测方法具有非常重要的学术价值与实际意义。孤立森林(isolation forest,IF)是一种适用于连续数据的无监督异常检测方法,具有计算复杂度低、鲁棒性好、可解释性强等优点,在高维和海量数据处理中得到了广泛应用[8,9]。然而IF存在决策边界与特征轴平行的问题,在密集数据中易产生重叠效应[10],导致检测精度降低。为此,文献[11]提出了一种扩展孤立森林(extended isolation forest,EIF)异常检测算法,使用随机斜率的超平面对数据空间进行划分,解决了IF中决策边界与轴平行的问题,提升了算法检测性能,但是EIF每棵树在分支的过程中,可能会存在空分支问题。文献[12]提出了一种广义孤立森林(generalized isolation forest,GIF)异常检测算法,通过将数据映射在随机单位特征向量上,从映射区域中选取阈值划分数据空间,优化了EIF可能存在的空分支问题。然而,上述三种基于树结构的异常检测算法都是采用隔离离群点的思路进行树的构建和异常检测,存在一定概率的漏警问题[13]。文献[14]通过引入专家反馈(expert feedback,EF)策略,在每次循环过程中,将IF中最有可能是异常的数据交由专家进行标注,算法再根据标注结果进行动态更新,通过这种方式解决了IF中存在的漏警问题。但是该方法仍然存在以下问题:a)以IF为基础,存在决策边界与特征轴平行的问题;b)专家每次只标注最具异常可能性的一个数据,增加了算法迭代优化的次数;c)叶节点权重更新时,仅考虑了数据从树的根节点到叶节点的过程中经历边的个数,未涉及与数据同在一个叶节点中样本数量的影响。
基于以上分析,本文提出了一种基于专家反馈的广义孤立森林(EF-GIF)异常检测算法,其主要创新之处体现在以下几个方面:a)树的分支策略,将数据映射在单位特征向量上,从映射区域中选取阈值来划分数据空间,解决了IF中决策边界与特征轴平行的问题;b)异常数据标注,算法将异常可能性较大的多个数据提交给专家进行批量标注,有效地减少了权重迭代更新的次数;c)叶节点权重计算,综合考虑了数据从树的根节点到叶节点所经过边的个数和同在一个叶节点中样本数量的影响。实验结果表明,本文算法在专家标注真实异常数据数量方面优于IF、EIF和GIF算法,同时在检测精度方面相比同类算法也取得了不同程度的提升。
1 相关工作
1.1 孤立森林算法原理
孤立森林是集成学习算法中一类典型的无监督异常检测算法,它将异常定义为“容易被孤立的离群点”,即分布稀疏且远离高密度数据群体的点[15]。其算法思想为:随机选择一个特征超平面,不断地对数据空间划分子空间,直至每个子空间只有一个数据点或达到限定深度。在划分过程中,越是离群的数据点越早被划分开来,故其平均深度也越小。数据样本x的异常值分数计算公式如下:
其中:h(x)表示样本x的路径长度,其计算公式为
h(x)=e+c(size)(2)
其中:e表示样本x从树的根节点到叶节點所经历边的数目;size表示与x同在一个叶节点的样本数目;E[h(x)]表示样本x在所有树中h(x)的均值;c(φ)是给定φ个数据样本时,树的平均路径长度,用来对E[h(x)]作归一化处理,其计算公式如下:
其中:H(φ-1)=ln(φ-1)+0.5772。从式(1)可以看出,数据x在每棵树中的平均路径E[h(x)]越短,异常分数值score(x)越接近1,表明其越可能是异常点;反之,异常分数值score(x)越接近0,表明其越可能是正常点。
1.2 分支策略
孤立森林算法的关键在于如何划分数据空间,即树的分支策略。假设数据有d1和d2两个特征,图1给出了IF、EIF和GIF三种算法的分支策略。如图1(a)所示,IF从d1和d2两个特征中随机选取一个特征,然后在该特征的值域范围内确定左右分支的决策边界。IF在分支过程中存在轴平行问题,即在单一特征的决策过程中,决策边界与特征轴平行。这会导致在密集的数据中产生重叠效应[10],引起异常检测精度降低。EIF考虑了d1和d2两个特征之间的相关性,其随机斜率的超平面由单位特征向量β和截距点PE确定,如图1(b)所示。由于PE是从包络数据样本的超立方体中采样(粉色阴影区域,参见电子版),导致EIF在划分左右分支的过程中,可能会存在空分支问题。GIF考虑了d1和d2两个特征之间的相关性,其决策边界由单位特征向量β和截距点PG确定,如图1(c)所示。PG是数据样本在β的映射区域中选取的(绿色虚线),这有效地解决了EIF可能存在空分支的问题。
为进一步说明不同分支策略对孤立森林算法的影响,利用图2的合成数据对三种算法性能进行比较,训练集是以(0,0)为中心,服从高斯分布的数据,测试集是不同半径的圆环数据,具体测试结果如图3所示。从图3(a)可以看出,IF在密集的数据中会产生重叠效应,存在与轴平行的局部异常点无法检测的问题,导致检测效果下降。同时,对比图3(b)和(c)可以看出,GIF的异常分数比EIF更接近训练数据的真实分布情况。图4进一步给出了三种算法对不同半径测试数据的异常分数标准差。从图中可以看出,总体上GIF的异常分数标准差小于IF和EIF。
1.3 漏警问题
漏警率是评价异常检测算法的一个重要指标。孤立森林算法将数据中分布稀疏且远离高密度数据群体的点判断为异常点,但是当高密度正常数据群体呈现重尾分布时,易将落于尾部区域中的异常数据判断为正常点,即产生了漏警现象[16]。以图5(a)中分布的数据为例,分别利用IF、EIF、GIF三种算法对其进行数据异常检测,结果分别如图5(b)~(d)所示。从图中可以看出,三种孤立森林算法将靠近高密度正常数据的部分边缘异常数据误检为正常数据,导致发生了漏警问题。
2 基于专家反馈的广义孤立森林算法
2.1 专家反馈原理
在监督学习中,存在样本难以大量获取且标注成本高的问题。不同样本对于特定任务的重要程度是不同的,所以带来的模型性能提升也并不完全相同。专家反馈是一种从样本角度提高检测效率的方案,其基本思路是通过专家选择性地标注少量的高质量样本,从而训练出表现较好的模型,如图6所示[14]。
本文通过引入专家反馈过程,试图在有限的反馈标注次数中,选择最有价值的样本交给专家进行标注并将其加入到有标签数据集中继续对模型进行训练,从而实现任务模型的在线更新。原始数据根据专家标注,分成无标签数据DO、专家标注的异常数据DA和专家标注的正常数据DN。
2.2 广义孤立森林构造
2.3 专家反馈的广义孤立森林
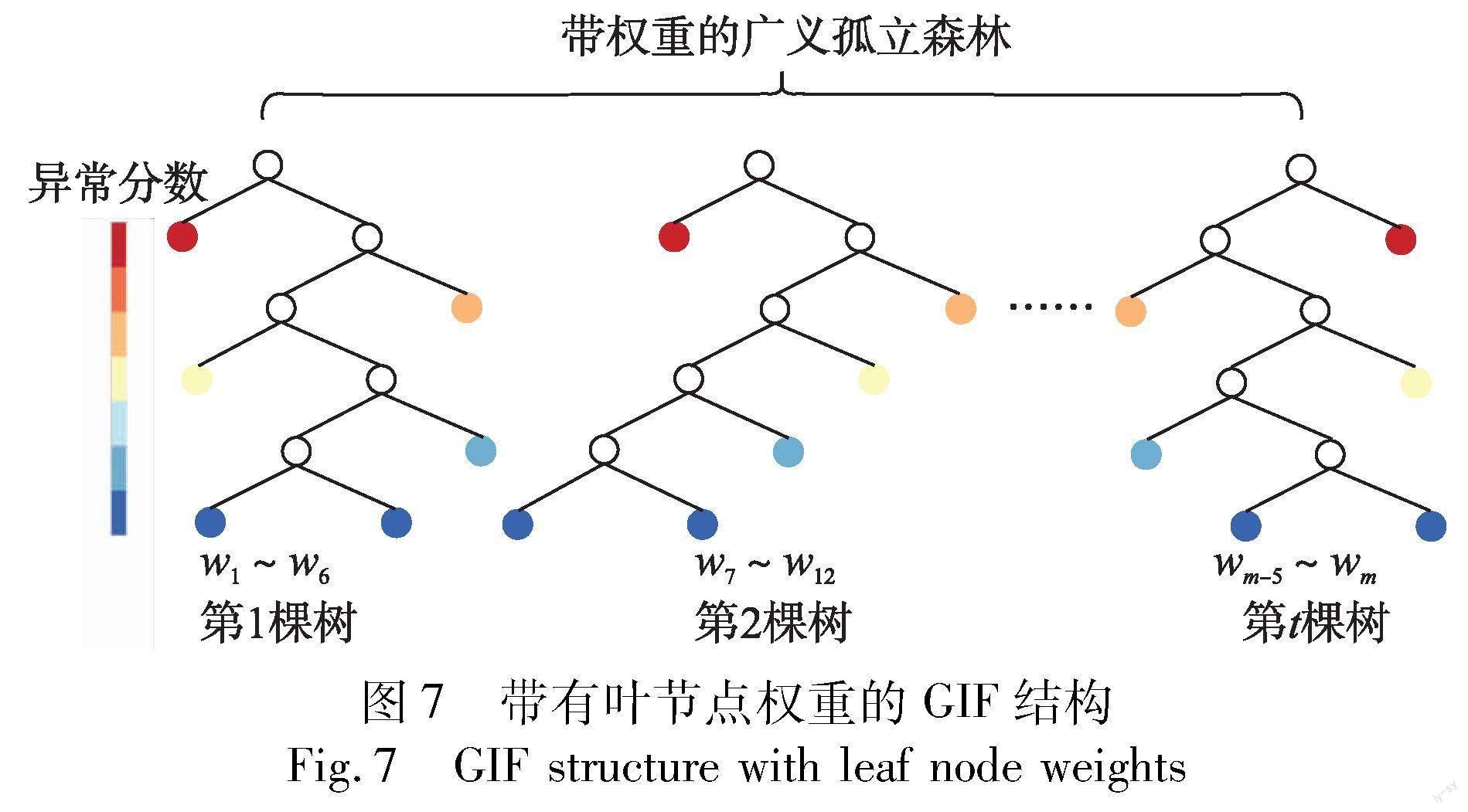
传统的孤立森林算法在模型训练完成后,在后续异常检测过程中结构保持固定不变,易出现模型无法完全适应实际动态场景的现象,还可能存在严重的误报与漏报问题[14]。为此,本文给GIF中每个叶节点添加一个权重,在异常检测过程中利用专家反馈信息自适应地调整叶节点的权重,从而实现GIF中树结构的动态更新,如图7所示。
数据x在带权重的广义孤立森林中的加权路径异常分数可以表示为
其中:h(x)是由数据x在各棵树上的路径长度组成的,当m列中只有t列非零的向量,m为广义孤立森林中叶节点总数,h(x)包含了数据从树的根节点到叶节点所经过边的个数以及同在一个叶节点中样本数量信息;w=[w1,…,wm]1×m表示广义孤立森林中叶节点对应权重组成的向量。
在初始时刻,将w的值w(0)=[1/t,…,1/t],WScore(X,w(0))将计算所有数据样本的加权路径异常分数,然后按照异常分数降序排列,假设位于异常百分位τ上的数据为x(0)τ,其加权路径异常分数为s(0)τ=WScore(x(0)τ,w(0))。传统孤立森林算法将s(0)τ作为阈值来判断数据是否异常,即若数据xi的加权异常分数WScore(xi,w(0)) 为了解决上述问题,本文在GIF中引入了专家标注反馈的过程。同时,为了减少权重迭代更新的次数,每次将异常分数值位于前q的多个数据同时交由专家进行批量标注。根据已标注数据xj的加权异常分数WScore(xj,w)、异常分数检测阈值s(b-q)τ和真实结果标签yj三者之间的关系定义如下损失函数: 其中:s(b-q)τ由w=w(b-q)时刻计算得到,以WScore(xj,w)与s(b-q)τ之间的距离作为损失:s(b-q)τ-WScore(xj,w)表示漏警导致的损失;WScore(xj,w)-s(b-q)τ表示虚警导致的损失。 通过最小化上述损失函数来更新GIF中的叶节点权重,从而降低系统误报与漏报概率。定义目标函数为 其中:|·|表示標注数据集中的数据个数;超参数CA是权衡DA中数据漏警损失和DN中数据虚警损失的系数,通常CA>>1,这使得算法更注重于优化漏警问题。同时,为了避免w(b)过拟合,在目标函数中添加了L2正则化项‖w-w(b-q)‖2,λ是权衡误报和漏报损失与正则化项的超参数。采用自适应梯度优化算法[17]对式(6)进行求解,即可得到动态更新后的w(b),使得DA中数据异常分数高于s(b-q)τ,DN中数据异常分数低于s(b-q)τ。 算法3给出了专家批量标注与叶节点权重更新的过程。 算法3 Rweight(X,B,t,q) 输入:X为输入数据,B为标注数据次数,t为树的棵数,q为批量标注数。 输出:w。 b=0 DA=DN= 权重初始化w=w(b)=[1/t,…,1/t] while b 数据集的异常分数WScore(X,w) 异常分数值位于前q的未标注数据[x1t,…,xqt] for i=1 to q do if xit is anomaly DA=DA∪xit else DN=DN∪xit end if end for b=b+q 最小化损失以更新权重w=w(b) end while return w 使用如图8(a)所示的toy2数据集[14],验证每次专家反馈后本文EF-GIF的检测效果。如图8(b)所示,随着每次专家反馈后叶节点权重的更新,EF-GIF异常检测效果明显提升。 为更加直观地说明图8(b)异常检测效果提升的过程,对toy2数据集进行可视化。图9给出了当专家标注数据次数从0~60逐渐增加时,其异常分数热力图变化的过程,图中红色区域为异常分数较高的区域,蓝色区域为异常分数较低的区域。 从图9(a)~(d)的变化可以看出,随着专家反馈标注次数的不断增加,toy2数据集异常分数热力图的分布逐渐接近图8(a)的数据真实分布。 3 实验分析 3.1 实验环境和数据集 本文的主要实验环境参数为:Intel i7-10700 2.9 GHz CPU,8 GB内存,Windows 10 64位操作系统,算法采用Python 3.6实现。 采用来源于文献[12,18]中的12个公开数据集,具体如表2所示。mammography、shuttle数据集,主要考虑多样本数对于异常检测算法的影响;cardio、PenGlobal、letter、breast cancer、annthyroid和ionosphere数据集,主要考虑高特征维度对于异常检测算法的影响;ALOI数据集,综合考虑多样本数和高特征维度对于异常检测算法的影响。 3.2 实验参数设置 本文参考文献[14]的实验参数设置,表3给出了各参数的具体描述及取值,通过100次仿真测试得到实验结果。 3.3 实验结果分析 为体现每次权重更新后异常检测算法发现异常数据的能力,图10给出了专家标注异常数据数量的实验结果。从图中可以看出,EF-GIF在breast cancer、ionosphere和yeast这3个数据集中的性能与IF、EIF、GIF相似,在PenGlobal、letter、annthyroid、abalone、cardiotocograph、mammography、ALOI这7个数据集中的性能优于其他三种未改进的算法,体现出EF-GIF在发现数据中真实异常能力方面的提升。上述结果的主要原因为:如图10所示,首先GIF的分支策略优于IF和EIF;其次EF-GIF相比GIF引入了专家反馈环节,通过式(6)中的叶节点权重更新,最小化检测过程中误报与漏报问题和正则化项构成的损失,最终提升了算法的检测效果。 表4进一步给出了四种算法在PenGlobal数据集上专家标注真实异常数据数量的均值。从表中可以看出,EF-GIF发现数据中真实异常数据的数量随反馈标注次数的增加而明显提升,尤其是在专家标注次数达到60时,EF-GIF相比IF、EIF和GIF分别有54.882%、49.136%和57.194%的提升。从表中四种算法在真实异常数据数量上的差异可知,未引入专家反馈孤立森林算法中存在漏警问题的现象较为严重。 为了更进一步说明本文算法在未知数据集上的检测效果,将数据集以7∶3的比例划分为训练集和测试集,取异常检测中常用的受试工作者特征曲线下的面积(area under curve,AUC)和平均准确率(average precision,AP)作为评价指标,实验结果如表5所示。从表5可以看出:在AUC方面,EF-GIF在12个数据集中有11个优于IF、EIF和GIF,平均分别提升了2.791%、1.925%和2.667%;在AP方面,EF-GIF在12个数据集中有11个优于IF、EIF和GIF,平均分别提升了38.952%、49.144%和49.144%。这是因为本文EF-GIF算法考虑了数据从根节点到叶节点所经过边的个数和最终落在叶节点上数据的数量信息,保证了数据异常分数的多样性,使专家在循环反馈过程中能够有效区分漏警数据。 综上所述,在发现数据中真实异常数据数量和检测准确率方面,EF-GIF相较于其他树异常检测算法有明显提升,通过专家批量标注和优化叶节点权重,使树结构和检测阈值能够根据实际场景进行自适应动态调整,提高了算法的泛化能力。 4 结束语 本文提出了一种基于专家反馈的广义孤立森林异常检测算法,其分支策略考虑到数据特征之间的相关性,将数据先映射在单位特征向量上,然后通过从映射区域中随机采样阈值分割左右分支的方式,优化了IF中决策边界与特征轴平行问题。同时,在专家反馈过程中,采用批量标注异常可能性较大的数据策略,有效减少了算法更新迭代的计算次数。另外,在叶节点权重更新方面,综合考虑了数据从根节点到叶节点所经过边的数量和最终落在叶节点上的数据数量对漏警问题的影响。实验结果表明,EF-GIF在PenGlobal、letter、annthyroid、abalone、cardiotocograph、mammography、ALOI数据集上,真实异常数据的数量优于IF、EIF和GIF算法;其次在检测准确率方面,分别有38.952%、49.144%和49.144%的提升。 后续将进一步分析不同标注策略和优化方法对异常检测性能的影响,并探究已标注数据和标签之间的关系,筛选关键特征,提升专家标注效率。 参考文献: [1]Ruff L, Kauffmann J R, Vandermeulen R A, et al. A unifying review of deep and shallow anomaly detection[J].Proc of the IEEE,2021,109(5):756-795. [2]Zhou Xiaokang, Hu Yiyong, Liang Wei, et al. Variational LSTM enhanced anomaly detection for industrial big data[J].IEEE Trans on Industrial Informatics,2020,17(5):3469-3477. [3]Li Tie, Kou Gang, Peng Yi, et al. An integrated cluster detection, optimization, and interpretation approach for financial data[J].IEEE Trans on Cybernetics,2021,52(12):13848-13861. [4]Injadat M N, Moubayed A, Nassif A B, et al. Multi-stage optimized machine learning framework for network intrusion detection[J].IEEE Trans on Network and Service Management,2020,18(2):1803-1816. [5]Pang Guansong, Shen Chunhua, Cao Longbing, et al. Deep learning for anomaly detection:a review[J].ACM Computing Surveys,2021,54(2):1-38. [6]Schmidl S, Wenig P, Papenbrock T. Anomaly detection in time series: a comprehensive evaluation[J].Proc of the VLDB Endowment,2022,15(9):1779-1797. [7]卓琳,趙厚宇,詹思延.异常检测方法及其应用综述[J].计算机应用研究,2020,37(S1):9-15.(Zhuo Lin, Zhao Houyu, Zhan Siyan. A survey of anomaly detection methods and their applications[J].Application Research of Computers,2020,37(S1):9-15.) [8]唐立,郝鹏,任沛阁,等.基于改进孤立森林算法的无人机异常行 为检测[J].航空学报,2022,43(8):584-593.(Tang Li, Hao Peng, Ren Peige, et al. UAV abnormal behavior detection based on improved iForest algorithm[J].Acta Aeronautica et Astronautica Sinica,2022,43(8):584-593.) [9]杭菲璐,郭威,陈何雄,等.基于iForest和LOF的流量异常检测[J].计算机应用研究,2022,39(10):3119-3123.(Hang Feilu, Guo Wei, Chen Hexiong, et al. Network traffic anomaly detection based on iForest and LOF[J].Application Research of Compu-ters,2022,39(10):3119-3123.) [10]楊晓晖,张圣昌.基于多粒度级联孤立森林算法的异常检测模型[J].通信学报,2019,40(8):133-142.(Yang Xiaohui, Zhang Shengchang. Anomaly detection model based on multi-grained cascade isolation forest algorithm[J].Journal on Communications,2019,40(8):133-142.) [11]Hariri S, Kind M C, Brunner R J. Extended isolation forest[J].IEEE Trans on Knowledge and Data Engineering,2019,33(4):1479-1489. [12]Lesouple J, Baudoin C, Spigai M, et al. Generalized isolation forest for anomaly detection[J].Pattern Recognition Letters,2021,149:109-119. [13]Li Changgen, Guo Liang, Gao Hongli, et al. Similarity-measured isolation forest:anomaly detection method for machine monitoring data[J].IEEE Trans on Instrumentation and Measurement,2021,70:1-12. [14]Das S, Wong W K, Fern A, et al. Incorporating feedback into tree-based anomaly detection[EB/OL].[2023-05-07].https://arxiv.org/pdf/1708.09441.pdf. [15]Liu F T, Ting K M, Zhou Zhihua.Isolation forest[C]//Proc of the 8th IEEE International Conference on Data Mining.Piscataway,NJ:IEEE Press,2008:413-422. [16]Das S, Wong W K, Dietterich T, et al. Discovering anomalies by incorporating feedback from an expert[J].ACM Trans on Knowledge Discovery from Data,2020,14(4):1-32. [17]Soydaner D. A comparison of optimization algorithms for deep learning[J].International Journal of Pattern Recognition and Artificial Intelligence,2020,34(13):2052013. [18]Lesouple J, Tourneret J Y. Incorporating user feedback into one-class support vector machines for anomaly detection[C]//Proc of the 28th European Signal Processing Conference.Piscataway,NJ:IEEE Press,2021:1608-1612.
猜你喜欢
现代电子技术(2017年19期)2017-10-12 08:15:58
电脑知识与技术(2016年30期)2017-03-06 17:06:53
教育教学论坛(2017年1期)2017-02-08 21:21:32
软件导刊(2016年11期)2016-12-22 21:59:46
科教导刊·电子版(2016年27期)2016-11-18 09:48:25
科教导刊·电子版(2016年25期)2016-11-16 22:09:46
中国科技博览(2016年26期)2016-10-24 20:28:47
计算机时代(2016年8期)2016-08-16 09:50:01
卷宗(2016年4期)2016-05-30 11:01:28
电脑知识与技术(2016年2期)2016-03-22 22:28:17
