
基于PCA-PSO-ELM模型预测地震死亡人数研究
2024-02-14 09:00陈韶金刘子维翟笃林
大地测量与地球动力学 2024年1期
陈韶金 刘子维, 周 浩 江 颖, 翟笃林
1 防灾科技学院信息工程学院,河北省三河市学院街465号,065201 2 中国地震局地震研究所,武汉市洪山侧路40号,430071 3 武汉引力与固体潮国家野外观测研究站,武汉市洪山侧路40号,430071
我国是一个地质灾害频发的国家,破坏性的地震往往会造成巨大的人员伤亡和经济损失。预测震后死亡人数对救援工作和物资分配都起着十分关键的作用,而预测地震死亡人数的影响因素错综复杂,传统的方法难以解释地震死亡人数的关键影响因素。张莹等[1]利用层次分析方法构建以地震震级、人口密度、地震烈度、建筑物抗震性能以及发震时刻等主要影响指标形成的指标体系,为后续的震后死亡人数预测提供了重要的参考。
随着机器学习的盛行,许多学者将其应用到地震死亡人数预测中。Tang等[2]采用经验回归法快速估计中国地震伤亡人数;杨帆等[3]和吴昊昱等[4]建立BP神经网络对震后伤亡人数进行快速预测;周德红等[5]将传统的BP神经网络和遗传算法优化的BP神经网络对地震伤亡人数预测模型效果进行对比,结果表明后者精度更高;Li等[6]提出支持向量回归(SVR)的分区伤亡预测方法;王晨晖等[7]和刘立申等[8]分别建立PCA-GSM-SVM和PCA-PSO-SVM模型对地震死亡人数进行预测,并取得良好的效果;Cui等[9]建立集成学习方法分别对地震受伤和死亡人数进行预测。上述研究主要是利用机器学习的不同方法对地震死亡人数进行建模,虽然均有良好的非线性拟合效果,但训练速度慢,网络易陷入局部最优。针对该问题,Huang等[10]提出一种新型的单层前馈神经网络(single-hidden layer feedforward neural network, SLFN),该算法被称为极限学习机(extreme learning machine, ELM)。相比于传统的神经网络,ELM具有学习速度快、精度高、参数设置简单等优势。景国勋等[11]加入预报水平作为影响指标,构建PCA-ELM的地震死亡人数评估模型,并对比ELM和传统的BP神经网络模型,结果表明PCA-ELM模型准确率更高。
基于此,本文对PCA-ELM模型进行改进,引入粒子群优化算法对ELM进行参数优化,构建PCA-PSO-ELM地震死亡人数预测模型。首先对影响指标进行主成分分析降维;然后通过粒子群智能算法对ELM网络权重进行训练优化,避免网络陷入局部最优,得到网络最佳参数;最后对比ELM、PCA-ELM、PCA-PSO-ELM三个模型的预测精度。
1 基本原理和算法流程
1.1 主成分分析(PCA)原理
主成分分析本质上是通过线性变换方式将高维数据变换成一组各维度线性无关的数据,其具体计算过程参考文献[12]。主成分分析算法步骤如下:
1)对数据进行标准化,消除不同量纲和量级的影响。
2)计算相关系数矩阵。
3)计算特征值和与之对应的特征向量。通过求解特征方程,计算特征根,按从大到小依次排序,同时得到对应的特征向量。
4)计算贡献率和累积贡献率。
5)综合分析。当累积贡献率达到85%~95%时,取前n个主成分作为新的综合指标变量替代原来的高维特征变量。
1.2 粒子群优化算法(PSO)原理
在粒子群优化算法模型中,粒子通过群体信息的共享和更新不断优化目标。粒子速度、位置计算公式以及更新公式参考文献[13-14]。
由于惯性权重的大小对算法的搜索能力具有显著影响,其值较大时,有利于全局搜索;其值较小时,有利于局部搜索。因此,为有效平衡全局搜索与局部搜索能力,使用线性递减权重公式[15]:
(1)
式中,ωmax和ωmin分别为惯性权重系数的最大值和最小值,Tmax为粒子群优化算法的最大迭代次数。
1.3 极限学习机(ELM)原理
ELM本质上是一种单隐含层的前馈神经网络,其输入权重和偏置项权重均采用随机生成的方法进行赋值,且其训练方式不采用传统的梯度下降方式,而是在最小二乘法架构下,通过解算对应的广义逆矩阵计算最优输出权值。因此,ELM具有收敛速度快且不易陷入局部最优等优点。ELM网络具体计算过程可参考文献[10],其网络拓扑结构见图1。
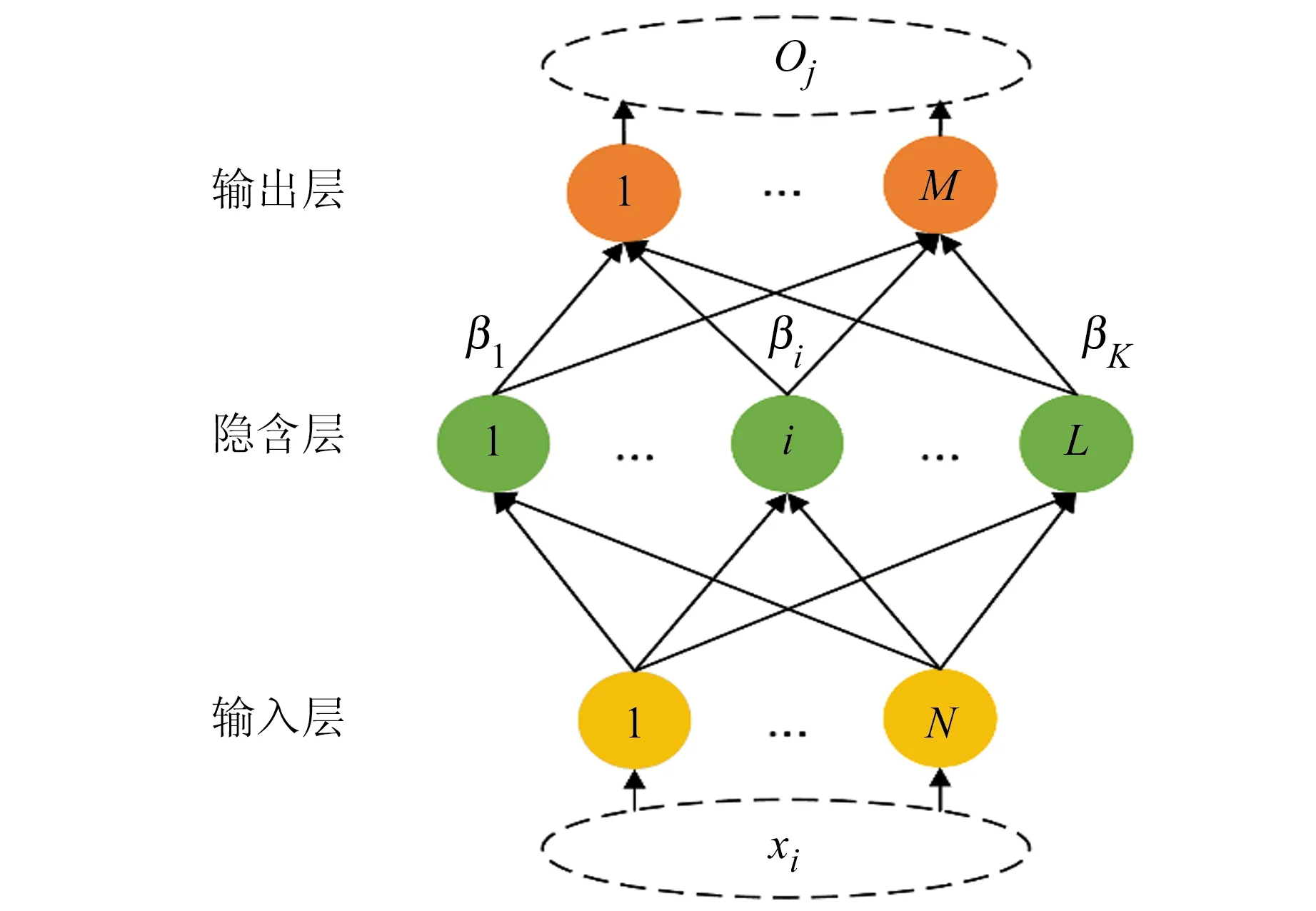
图1 极限学习机网络拓扑结构Fig.1 Topological structure of extreme learning machine network
1.4 算法流程
本文提出的PCA-PSO-ELM 预测模型流程分为3个阶段:1)PCA处理阶段。通过 PCA对影响地震死亡人数的7个影响因子进行降维处理,消除各个影响因子之间的相关性、冗余性。2)粒子群算法寻优阶段。将 PCA 计算的主成分得分作为 PSO-ELM 预测模型的输入,设置PSO优化算法的粒子速度、位置等参数和模型终止条件,并进行模型训练。3)ELM网络训练阶段。将PSO优化好的初始权重代入ELM模型进行测试并分析其结果。模型处理流程见图2。
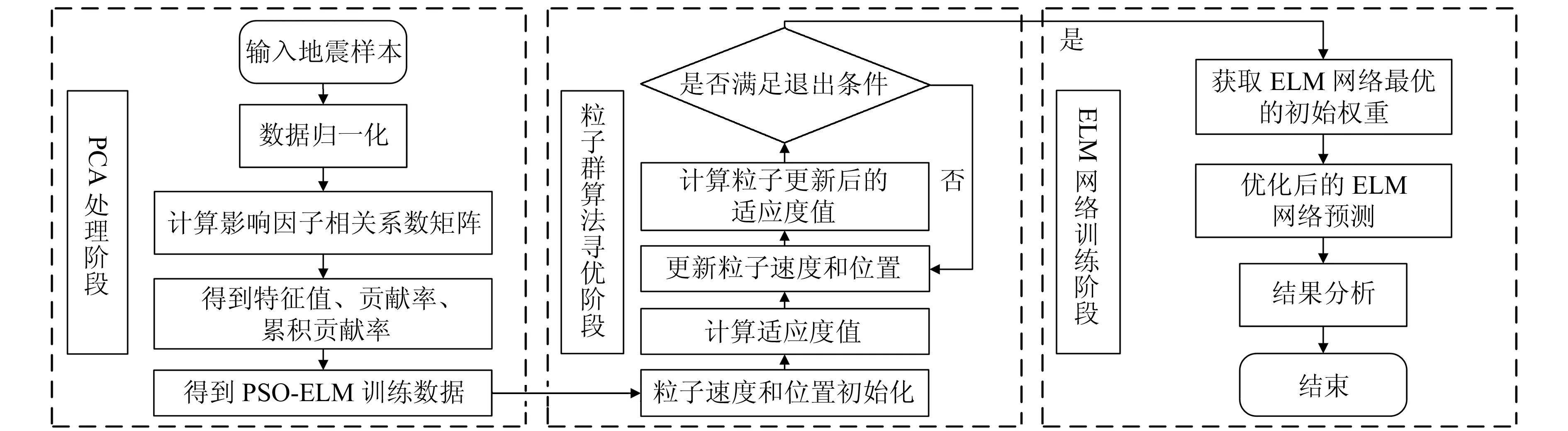
图2 PCA-PSO-ELM模型流程Fig.2 The flow chart of PCA-PSO-ELM model
2 影响指标选取和主成分分析
2.1 影响地震死亡人数的指标选取
影响地震死亡人数的指标错综复杂,本文从数据获取难易程度和重要性角度综合考虑,选取地震震级、震源深度、震中烈度、抗震设防烈度、震中烈度与抗震设防烈度之差(ΔL)、人口密度以及发震时刻等7个影响因素作为模型输入。
地震震级是表示地震强弱的度量,地震震级越大,其对建筑物的破坏力越强,造成的死亡人数也越多。震源深度表示震源在地面上的垂直投影距离,一般来说,震源越靠近地面,对地表的破坏力越强。震中烈度是指地面受到地震震动作用的强烈程度,在同等震级大小条件下,震源深度越浅,震中烈度也越大。抗震设防烈度是在工程建设时对建筑物进行抗震设计的地震烈度,通常情况下,抗震设防水平越高的地区,同等地震条件下造成的人员死亡越少。震中烈度和抗震设防烈度之差(ΔL)可体现建筑物抵御地震破坏的能力,如果ΔL>0且两者差值越大,则说明建筑物抗震能力越弱,地震造成的死亡人数也越多;如果ΔL<0且两者差值的绝对值越小,说明建筑物破坏程度越严重,地震造成的死亡人数也越多。此外,人口密度和发震时间也是直接影响地震死亡人数的重要指标。若地震发生在人口密度大的地区,所造成的人员死亡数远大于人烟稀少地区;若发震时间为夜晚,由于缺少反应时间,死亡人数也会增加。
2.2 数据来源
本文从相关文献[5,7,11]中筛选42个历史地震震例数据(表1),选取地震震级、震源深度、震中烈度、抗震设防烈度、震中烈度与抗震设防烈度之差(ΔL)、人口密度以及发震时刻7个影响因子作为网络模型的输入数据,实际死亡人数作为模型的输出数据。

表1 地震震例信息
由于抗震设防烈度[16]与发震区域有关,本文选取的是发震地区抗震设防烈度的最大值。发震时刻分为2个时间段:发震时刻“1”表示白天(07:00~19:00),“0”表示夜晚(19:00~次日07:00)。
2.3 主成分分析
对原始数据的7个影响因子进行PCA降维处理。表2为影响因子的特征值、贡献率和累积贡献率,由表可知,前4个主成分累积贡献率达88.607%,说明其包含原始数据的绝大多数信息,满足替代条件。主成分得分是由因子载荷矩阵与原始数据线性组合,计算公式如下:

表2 特征值、贡献率和累积贡献率
(2)
式中,S1为地震震级,S2为震源深度,S3为震中烈度,S4为抗震设防烈度,S5为震中烈度与抗震设防烈度之差(ΔL),S6为人口密度,S7为发震时刻。将降维后的4个主成分替代原始数据的7个影响因子,并对主成分得分进行归一化处理,公式如下:
(3)
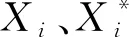
3 地震死亡人数预测模型
3.1 模型建立
选取经过PCA处理后的37个震例数据作为训练样本,其余5个数据(样本2、9、15、29、38)作为测试样本。由于地震死亡人数数值离散且跨度较大,为了更直观地对比预测值与真实值,本文采用自然对数对地震死亡人数进行处理。
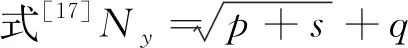
建立好网络模型后,将37个震例数据分别输入到ELM、PCA-ELM和PCA-PSO-ELM模型中进行训练,经过多次实验,得到粒子群优化算法的最佳参数设置和3个模型的训练集预测值与实际值对比结果,具体见表4和图3。

表4 PSO-ELM网络参数
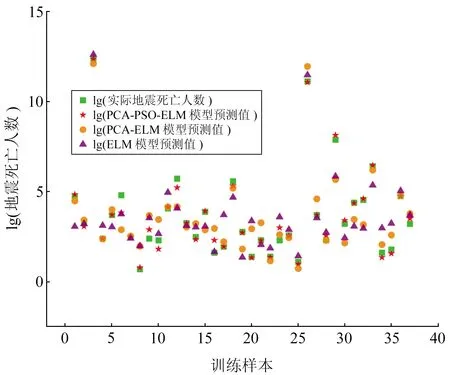
图3 不同模型训练集预测值与实际值对比Fig.3 Comparison between predicted values and actual values of different models
由图3可知,除个别样本数据是ELM或PCA-ELM预测值更接近实际值,从整体上看,PCA-PSO-ELM模型的拟合效果最好,其预测值和实际值非常接近,该模型可用于测试样本数据进行预测。
3.2 实验结果及分析
选取样本2、9、15、28、36作为测试样本数据检验模型的准确度。将5个测试数据分别代入到ELM、PCA-ELM和PCA-PSO-ELM模型中进行实验,可得到3个模型的预测值和平均误差率结果(表5)。

表5 不同模型结果对比
由表5可知,未经PCA处理的ELM模型平均误差率为29.25%,而经过PCA处理的ELM模型平均误差率相较前者减少8.70个百分点,说明采用PCA对数据进行预处理十分必要,可以去除原始数据的冗余性。本文提出的PCA-PSO-ELM模型的平均误差率为10.87%,比PCA-ELM模型提高9.68个百分点,说明经过优化的模型可避免网络陷入局部最优,并找到最优的模型参数,进而提高模型的预测精度。因此,该组合模型可为地震死亡人数预测提供新方法。
4 结 语
本文利用主成分分析对原始数据特征进行降维,再通过粒子群优化极限学习机网络对数据进行仿真实验,对比3个模型的实验结果,得到以下结论:
1)在众多影响地震死亡人数的因素中,构建以地震震级、震源深度、震中烈度、抗震设防烈度、震中烈度与抗震设防烈度之差(ΔL)、人口密度以及发震时刻为主的影响指标体系。
2)经过PCA降维处理,能够极大地去除原始数据之间的相关性和冗余性,可强化模型的泛化性,提升模型的预测精度。
3)对比ELM模型和PCA-ELM模型,本文提出的PCA-PSO-ELM模型不仅能避免网络陷入局部最优,而且模型的预测值与实际值的平均误差率最低,可为地震死亡人数预测提供一种新的评估方法。
然而,由于收集的历史震例数据还不够丰富,构建影响地震死亡人数的评估体系还不够完善,此外模型精度和稳定性仍有进一步提高的空间,这将是未来研究的重点。
猜你喜欢
——以盈江地区为例
地球物理学报(2022年11期)2022-10-31
建材发展导向(2021年15期)2021-11-05
建材发展导向(2021年14期)2021-08-23
地震研究(2021年1期)2021-04-13
少儿美术(快乐历史地理)(2019年4期)2019-08-27
城市道桥与防洪(2019年5期)2019-06-26
上海建材(2018年6期)2018-03-21
中国学术期刊文摘(2016年1期)2016-02-13
中国火炬(2015年5期)2015-07-31
灾害学(2014年1期)2014-03-01
