
基于DistilHuBERT模型微调在乐器演奏技术检测应用
2024-02-09 00:00:00邓颖岸
电脑知识与技术 2024年36期
关键词:DistilHuBERT模型;深度学习;乐器演奏技术(IPT) 检测;模型微调;快速动态时间规整
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)36-0099-04 开放科学(资源服务) 标识码(OSID) :
0 引言
乐器演奏技术(IPT) 检测的准确率直接影响音乐转录[1]的效果,同时IPT检测还可用于乐器音准检测,例如检查各音符的准确性,确保乐器调音正确、判断乐器的磨损情况等,为乐器修复提供凭证。乐器演奏技术(IPT) 检测通过记录演奏过程中的音频,对这些音频进行转换和特征提取,再进行特征计算以获得检测结果,在某种程度上与语音识别[2]的过程类似。
早期的IPT检测工作多采用机器学习方法,并结合手工创建的特征;随着卷积神经网络的发展,Su等提出使用卷积神经网络(CNN) [3] 取代支持向量机(SVM) [4],显著提升了IPT检测的效果。近年来,深度学习预训练大模型的泛化能力得到显著提升,Di⁃ chucheng Li等人提出使用预训练模型针对具体的乐器演奏数据集进行模型微调[5],进一步提高了IPT检测的准确率。
然而,在中国传统乐器演奏技法检测方面,一方面由于缺少高质量、有标签的数据集;另一方面,由于使用其他数据集训练的模型受到泛化能力的限制,直接应用于IPT检测任务时效果并不理想。针对这些问题,不少学者提出了解决方案。例如,李荣锋等希望能找到每种中国乐器各自独有的声音特征,并通过卷积神经网络结合对数Mel声谱图作为输入特征,在所构建的两个子数据集中实现了超过97%的分类准确率,表明所构建的模型能够较好地学习到每种乐器的特征[6]。李子晋等针对中国民族复音音乐的乐器活动检测问题,提出了一种基于卷积循环神经网络(CRNN) 的复音乐器活动检测方法,发现相较于CNN,CRNN能够更好地识别具有旋律信息的多乐器复音音频中的乐器[7]。Zehao Wang等针对二胡演奏技法提出了基于全连接网络(FCN) 的可变长度音频检测算法,并在二胡演奏技法的不同分类数据集上进行训练,平均准确率分别为87.31%(4 分类) 、67.94%(7 分类) 、48.26%(11分类) [8]。此外,Dichucheng Li等建议应用一种在大规模无标记音乐数据上预先训练的自监督学习模型,并在IPT检测任务中对其进行微调,在一些数据集上取得了良好的效果[5]。
总体而言,由于中国传统乐器的发声具有各自的特点,模型需要针对IPT相关的下游任务进行专门训练才能取得良好的效果。针对中国传统乐器演奏技法检测,相关研究中很少使用卷积与Transformer组合的预训练模型。本文提出了一种基于DistilHuBERT 预训练模型微调的方法,以期在少量数据集上训练后获得较好的准确率。
1 DistilHuBERT模型
DistilHuBERT保持了HuBERT的基本结构,将HuBERT作为教师模型,采用知识蒸馏完成Distil-HuBERT的训练。DistilHuBERT参数量为23.49M,包含7层卷积层,可有效压缩并提取长时间序列的有效信息,2层Transformer用于特征融合,并采用GELU激活函数。总体来说,DistilHuBERT模型浅而宽,适合提取长序列音频的特征。此外,DistilHuBERT在多个数据集上取得了良好的效果,非常适合用于下游任务的微调。模型的具体结构和各层输出形状如表1所示。
2 二胡演奏技法数据集简介
二胡演奏技法数据集最初来源于用于MIR多功能音乐数据库(CCMusic) [13],数据由专业音乐演奏人员录制。录制者具有较高的音乐素养,录制环境和设备专业,录音质量较高。本研究使用的数据集是经过整理后的版本[14],数据集共分为11个类标签,共有1253个样本,总时长约为1552.44秒。训练集、验证集和测试集的样本数分别为748、251和254,每个样本的平均时长约为1.24 秒。数据集中各类别的占比统计见表2。
本数据集由专业人员录制和标注,数据质量较高。然而,数据集存在样本数量分布不平衡的问题。如果每个分类的数量平均分布,那么每个分类的数量占比应为9%。但分类Trill 的数量最多,占比接近20%,远高于9%;分类Harmonic的数量最少,占比仅为2.39%,远低于9%。此外,分类Trill的数量是分类Harmonic数量的8倍多。数量占比低于9%的分类包括Vibrato、Ricochet、Percussive、Harmonic、Diangong和Detache,这些分类的总占比约为39%。数据集的样本数量偏向于Trill、Tremolo、Staccato 和Legato_Slide_ Glissando这几个分类。
深度学习模型高度依赖于数据的质量和分布。样本数量分布不平衡[15]会对模型的微调带来不良影响。在模型训练过程中,可能导致模型偏向于数量较多的分类,而数量占比较少的分类可能因训练不充分而出现类别偏差。这种情况会导致最终训练的模型存在偏差,从而影响模型的推理结果。
3 实验过程与结果
模型主要参数:卷积层为7层,采用GELU激活函数,隐藏层大小为768,注意力机制中的多头注意力头数为12,损失函数使用交叉熵损失函数。
模型的实现基于PyTorch框架(版本:2.01) [16]。微调训练[17]使用Adam优化器[18],为防止学习率过大对预训练模型[19]参数造成破坏,学习率设置较小,为5e-5,并采用Warmup策略。初始学习率设置为5e-5,批量训练的大小为8,随机种子设为42。训练过程中,每5 个Step记录一次训练日志,每个Epoch后计算验证集的性能,共完成10个Epoch。
模型配置的主要参数与训练过程的主要参数如表3所示。
首先从音频原始文件读取数据。由于DistilHu⁃ BERT模型要求输入音频的频率为16 kHz,因此需将源音频重采样为16 kHz,并对音频数据进行标准化处理。随后,将处理后的数据送入DistilHuBERT模型进行训练。训练完成后,加载微调后的模型,对测试集数据进行推理,并记录推理结果。
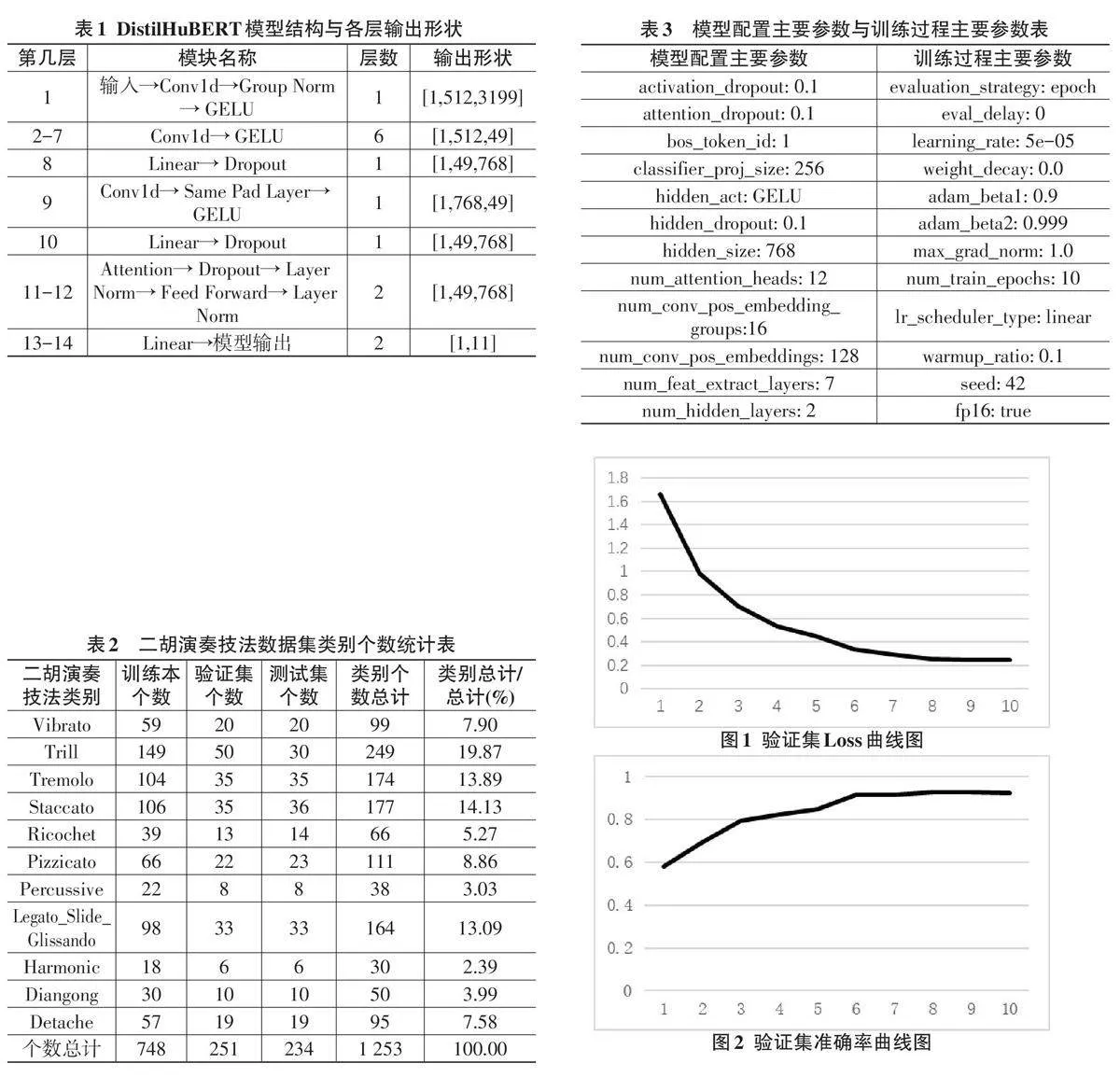
模型训练过程中,验证集的Loss曲线和准确率曲线分别如图1、图2所示。从图1可以看出,验证集的Loss初始值大于1.6,随后稳定下降,最终约为0.24,表明选择了合适的模型参数和训练参数。从图2可以看出,验证集的准确率逐步上升,第一个Epoch结束时低于60%,训练结束后最终达到约92%。从图3可以看出,DistilHuBERT模型最后分类头的权重参数稳定在一定范围内,各分类的输出未出现较大的偏差。总体而言,这些结果表明模型的微调训练符合预期。
使用微调后的DistilHuBERT模型对测试集进行推理,得到的总体准确率为88%,具体各项指标如表4 所示。
由于使用同一个数据集(二胡演奏技法数据集) 作为训练数据的研究较少,本文将文献[8]作为对比参考。该论文使用全连接卷积网络(FCN) [20]模型,在11分类任务上的平均准确率为48.26%。本研究的模型与该论文的模型对比结果见表5。
表5中,FCN模型的发表时间为2019年,当时预训练模型尚未普及,Transformer技术也未完全发展成熟。而本研究使用的预训练模型DistilHuBERT经过大量数据集的训练,具有较强的泛化能力,并能够在多个任务中取得良好效果。在本研究中,DistilHu⁃ BERT经过微调后,在完成第一个Epoch时验证集准确率已达到58%,随后准确率逐步提升,最终达到92%。
通过对比分析可以看出,微调后的DistilHuBERT 模型在二胡演奏技法检测任务上表现出色,显著优于传统的FCN模型。
本研究的创新点在于使用DistilHuBERT模型,加载预训练的权重参数后,在少量的二胡演奏技法数据集上进行微调,克服了模型训练需要大量数据的难点。微调后的模型学习到了二胡演奏技法数据集的特征,准确率达到88%,具有较好的泛化能力。本研究表明,深度学习模型可以用于IPT检测,并且效果显著。然而,直接使用未经过微调训练的深度学习模型,准确率会很低。例如,DistilHuBERT模型在加载预训练权重参数后,第一个Epoch的准确率低于60%。这说明需要先进行微调训练,再使用微调后的模型进行推理,准确率才能达到满意的效果。本研究使用的模型参数和训练参数,为进一步利用少量数据集优化DistilHuBERT 模型在IPT 检测中的应用提供了参考依据。
4 模型推理错误分析
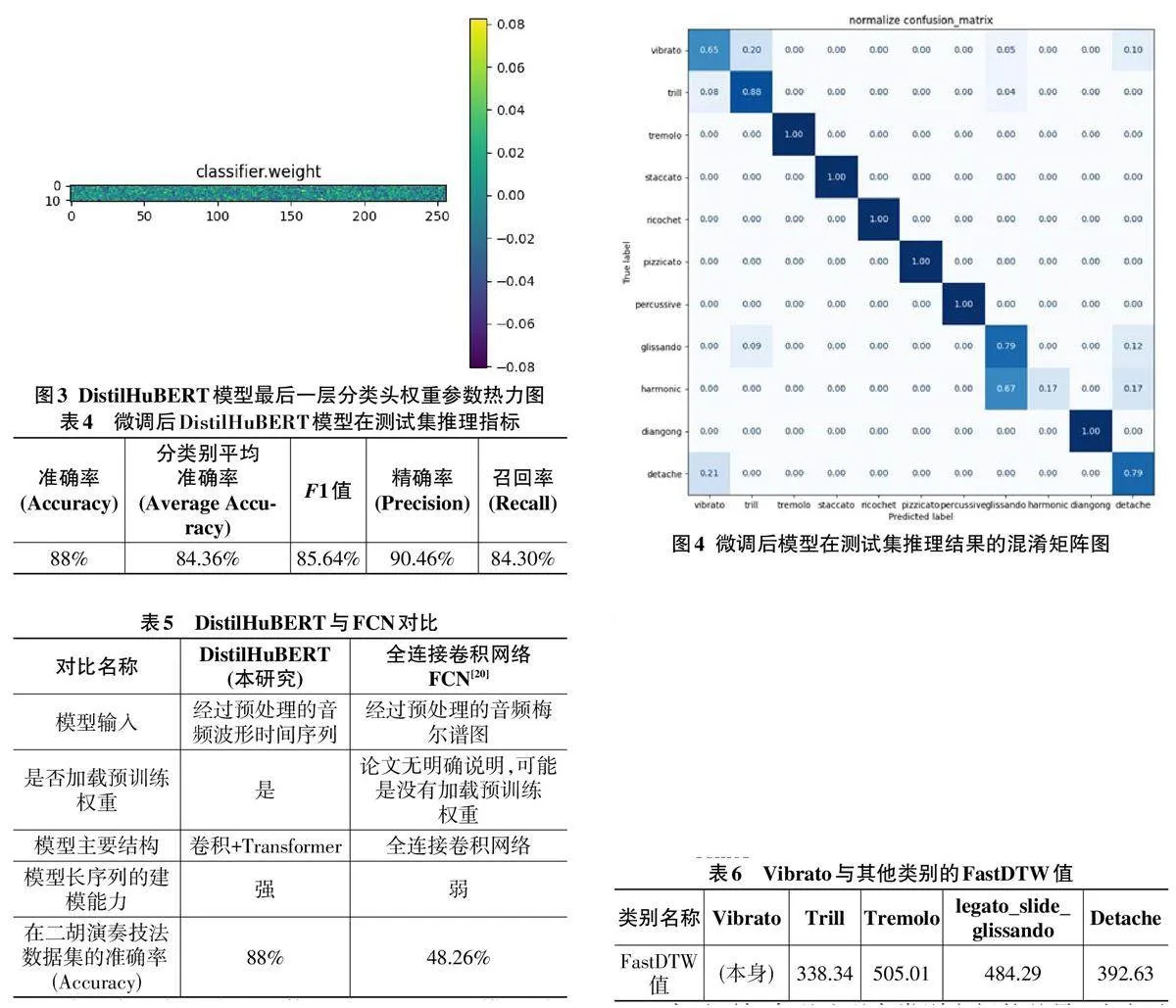
加载训练后的模型,在测试集上进行推理,并将结果绘制成混淆矩阵(如图4所示) 。从图4可以看出,大部分推理结果是正确的,但错误主要集中在Vi⁃ brato和Harmonic 这两个类别。其中,Vibrato 有20% 被错分类为Trill,10%被错分类为Detache。接下来将使用动态时间规整(Dynamic Time Warping, DTW) 和波形图对其进行分析。
动态时间规整(Dynamic Time Warping, DTW) 是一种用于比较两个时间序列相似性的算法[20],音频序列可以看作是时间序列的一种。本研究的音频序列每秒采样16 kHz,如果按照标准的DTW算法计算,时间复杂度为O(N²) ,直接计算两个音频序列的DTW值会耗时较长。为了缩短计算时间并简化计算过程,本研究采用了快速DTW(FastDTW) 方法。具体实现中,使用了Python第三方库FastDTW[21]的快速计算方法,估算出大致结果。
由于数据集中单个样本的时间长度不统一,为了方便计算,仅选取超过1.56秒的音频样本,并截取这些音频样本的前1.56秒作为计算输入。因此,Fast⁃ DTW的计算并未包含所有样本,但能够得到合理的估算结果。结果如表5所示。FastDTW的数值越小,说明两个时间序列的相似性越高,模型正确分类的难度也越大。从表6可以看出,Vibrato类别相似度从高到低依次为:Trill、Detache、Detache、Legato_Slide_Glis⁃ sando、Tremolo。
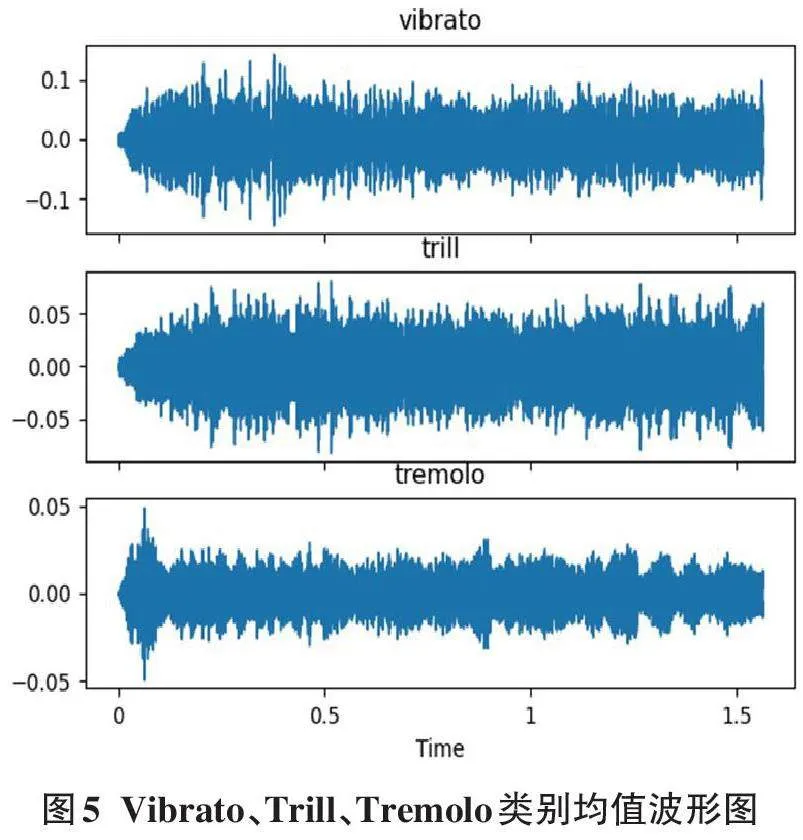
为了更加直观地观察类别之间的差异,选取了Vibrato、Trill、Tremolo这三个分类,绘制了类别均值波形图进行比较。具体方法是:仅选取超过1.56秒的音频样本,截取这些样本的前1.56秒作为计算输入,计算总和(保留维度) ,然后除以某一类参与计算的样本数量,得到类别均值,最终绘制均值波形图(如图5所示) 。从图5可以看出,Vibrato与Trill的波形图相似性非常高,两者的FastDTW值为338.34;而Vibrato与Tremolo的波形图相似性较低,两者的FastDTW值为505.01。
5 结论和下一步工作
IPT研究面临着缺乏大量高质量数据集的难题。直接使用初始化参数的模型进行训练时,如果模型参数过少,可能无法很好地拟合数据集;如果模型参数过多,由于数据集规模较小,可能导致模型过拟合[17]。本研究提出的基于DistilHuBERT预训练模型的微调方法,在数据集较小的情况下,实现了对二胡演奏技法的高准确率检测,有效缓解了数据匮乏的问题,充分发挥了预训练模型的优势。同时,本研究表明,由于个别分类样本具有较高的相似度,导致模型推理出现错误。在专业领域中,可以先选取部分样本,计算不同类别的FastDTW值,根据FastDTW值的结果,专门针对相似度较高的类别增加数据收集和标注,再进行微调训练,从而提高模型的效果。总体而言,微调后的DistilHuBERT模型能够较好地学习二胡演奏技法数据集的特征,并具有较好的泛化能力。
下一步研究方向有两个:
1) Harmonic类别有67%的样本被错误分类为Le-gato_Slide_Clissando。在训练集中,Harmonic类别共有18个样本,而Legato_Slide_Glissando类别共有98个样本。经过初步分析,可能是南丁数据集不平衡导致的。在数据量较少的情况下,由于学习率较小且训练Epoch次数不足,模型权重参数的更新幅度较小,Har-monic分类受到原有预训练模型参数的影响较大。后续研究将增加训练Epoch次数和学习率参数,观察训练后的效果。同时,可以收集容易被错误分类的演奏技法音频,例如Harmonic和Legato_Slicle_Glissando,专门对模型进行再次微调。
2) 在保留现有模型权重参数的基础上,在模型第12层后(模型结构见表1) 新增Transformer层,以增强特征融合的效果,然后对新模型进行再次微调训练。
致谢:
感谢星海音乐学院提供计算资源,感谢中国传统乐器音响数据库(CTIS) [22]与多功能音乐数据库(CCMu⁃sic) 提供数据集支持[22]。
猜你喜欢
今日农业(2022年16期)2022-09-22 05:39:06
小太阳画报(2019年5期)2019-06-25 10:56:04
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
电线电缆(2018年2期)2018-05-19 02:03:44
家庭影院技术(2017年10期)2017-11-23 03:35:51
电子制作(2017年9期)2017-04-17 03:00:46
人间(2015年8期)2016-01-09 13:12:42
教育科学论坛(2014年8期)2014-03-01 04:01:54
中国工程咨询(2011年12期)2011-02-13 02:43:58
