
基于Python的某直聘大数据岗位招聘数据爬取与可视化分析
2024-02-09 00:00:00张三群
电脑知识与技术 2024年36期
关键词:数据可视化



关键词:Python;Selenium;数据爬取;数据可视化;招聘数据;大数据岗位;某直聘
中图分类号:TP311.5 文献标识码:A
文章编号:1009-3044(2024)36-0063-04"开放科学(资源服务) 标识码(OSID) :
0 引言
随着人工智能和大数据技术的快速发展,从海量数据中提取有用信息的需求日益增长,网络爬虫和数据可视化技术成为重要的工具。现有研究已应用这些技术对招聘数据进行分析,例如,裴丽丽[1]利用Sele⁃ nium和Matplotlib分析了爬虫工程师岗位的地区平均薪资;蔡文乐等[2]使用Scrapy和Echarts对C语言工程师岗位进行了可视化分析;郭瑾[3]利用Requests和Mat⁃ plotlib分析了北京地区大数据运维岗位数据;付腾达等[4]使用Requests和Echarts分析了南昌市IT岗位信息。然而,这些研究存在数据量不足、分析维度单一、区域局限性等问题。本文基于Python,利用Selenium、Pandas和Matplotlib,对某直聘网站12个一线城市的“大数据”岗位招聘信息进行爬取、清洗和可视化分析,旨在更全面地揭示大数据岗位的市场需求特征,为求职者、高校和用人单位提供更具参考价值的信息。
1 技术概述
1.1 技术原理
网络爬虫是指按照一定的规则,自动地抓取万维网信息的程序或者脚本[5]。本文通过编写网络爬虫程序,利用爬虫程序获取某直聘网站“大数据”岗位页面,然后从页面中提取岗位信息,并保存数据。数据清洗是指对数据进行重新审查和校验的过程,包括检查重复、缺失或错误的数据以及处理一些特殊的数据。本文通过编写数据清洗程序,对爬取的原始数据进行删除重复值、补充缺失值、清理不需要的字符、替换字符串、删除含有特定字符串的行等操作,完成对数据的清洗处理,从而保证“大数据”岗位数据的准确性和完整性。数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,将它们加以汇总、理解和消化。数据可视化则是指将数据以图表的形式呈现,以便更好地理解和分析数据,帮助用户发现数据中的模式、趋势和关联,更直观地发现数据的规律,并从中获取有价值的信息和见解。本文通过编写数据可视化分析程序,将清洗后的数据,通过筛选、分词、分组、求和、求平均值、排序等统计方法,得出有参考价值的数据并生成各种图表,最后根据图表进行分析,得出“大数据”岗位需求结论。
1.2 功能模块
主要包括数据采集模块、数据清洗模块、数据可视化分析模块。一是数据采集模块,主要利用Sele⁃ nium库获取岗位简介页面和岗位详情页面的源代码,然后进行页面解析,将解析提取的岗位数据保存至本地文件中。二是数据清洗模块,主要利用Pandas库对文件中的岗位数据进行清洗和处理,包括删除重复数据、填充缺失值、清理不需要的字符、将字符串转换为小写或大写、删除含有某个特定字符串的行等。三是数据可视化分析模块,先利用Pandas模块对清洗之后的岗位数据进行筛选、分组、统计、排序等操作,然后使用Matplotlib模块实现数据可视化,常见的可视化图表包括柱形图、条形图、饼图、词云图等。
相关流程步骤表现为:第一步确定目标网址URL,利用Selenium库,获取指定的cookie信息;第二步注入cookie信息,发送页面请求,获取响应回来的源代码;第三步解析源代码,提取所需的岗位数据;如果所有页面都请求完毕,则保存采集到的所有数据到文件中。否则,继续请求下一个页面,流程回到第二步。当数据保存完毕后,接下来对数据进行清洗处理,然后对清洗后的数据进行可视化分析。
2 数据爬取关键技术实现
2.1 获取页面源代码
网站为了保护网站安全和减轻服务器压力会设置反爬机制。常见的反爬机制有:IP封禁,同一IP地址在短时间内发送大量请求,很可能会导致该IP被封禁;User-Agent 检测,通过检测HTTP 请求头中的User-Agent字段来判断是否为爬虫访问;验证码,通过要求用户输入验证码来验证访问者的真实性,防止机器自动访问;追踪用户登录状态,通过Session 和Cookies来追踪用户的登录状态,爬虫如果没有正确管理Session或模拟登录状态,可能会被限制或封禁。
针对IP封禁可以采取的应对策略:1) 使用代理池,通过切换IP地址来规避限制,可以使用代理服务商提供的高匿名代理或自己搭建代理池。2) 控制请求频率,通过随机延时来避免过于频繁的请求,模拟正常用户行为。针对User-Agent检测可以采取的应对策略:更换请求头User-Agent来模拟来自不同用户的请求。针对验证码可以采取的应对策略:1) 使用验证码识别服务,利用第三方验证码识别服务(如TTOCR、 2Captcha、百度OCR等) 可以帮助自动识别验证码并返回结果。2) 人工干预,如果爬虫需要频繁处理验证码,可以采取人工介入的方式解决。在脚本中加入人工干预的步骤,比如暂停脚本执行,让用户输入验证码。针对用户登录状态可以采取的应对策略:1) 模拟登录,获取必要的认证信息(如Cookies) 后,携带这些信息发起后续请求。2) 自动处理Session,使用浏览器自动化工具来模拟真实用户的登录行为,获取动态生成的认证信息,再次发送请求,Cookies信息会被自动携带。
在爬取某直聘网站数据时遇到的反爬问题主要包括追踪用户登录状态、图形验证码、IP封禁。本文采取的应对策略:利用Selenium库,模拟真实浏览器,发送请求,并模拟用户登录,保持登录状态以便访问被限制的岗位信息;由于该网站需要频繁处理验证码,所以采取人工干预的方式解决验证码问题;轮换使用代理IP(如random.choice(proxy_list)),从而避免IP被封,确保爬虫能够持续运行。
首先使用webdriver.Chrome()打开浏览器,接着使用driver.get()发送页面请求,然后使用driver.get_cook⁃ ies()获取所有Cookies信息,并保存为.json文件。
2.3 保存数据
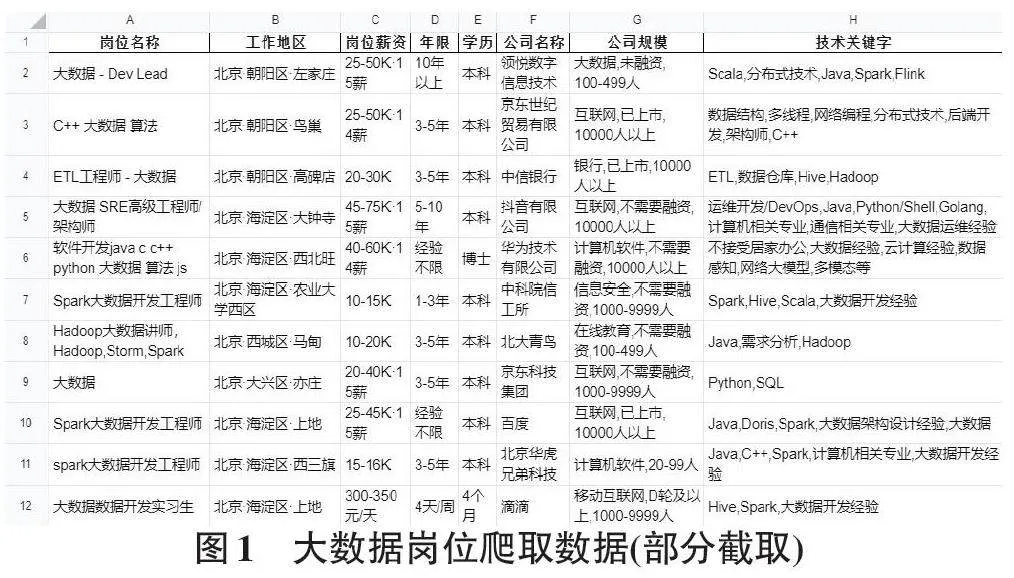
爬取到的数据可以保存到MySQL数据库中,也可以保存到Excel文件中,本文选择后者,这样方便后续对数据进行清洗处理。具体做法是使用pd.DataFrame ()函数,将爬取到的信息构建成一个数据框架df,使用df.to_excel('大数据岗位.xlsx',index=False)函数写入到Excel文件,总共3 598行,17个字段,文件部分截取内容如图1所示。
3 数据清洗关键技术实现
接下来利用Pandas库对Excel文件中的原始数据进行清洗处理,步骤和方法如下:
第一步,读出原始数据。使用pd.read_excel('大数据岗位.xlsx')函数读出Excel中的所有数据。
4.3 使用年限、学历等数据生成饼图
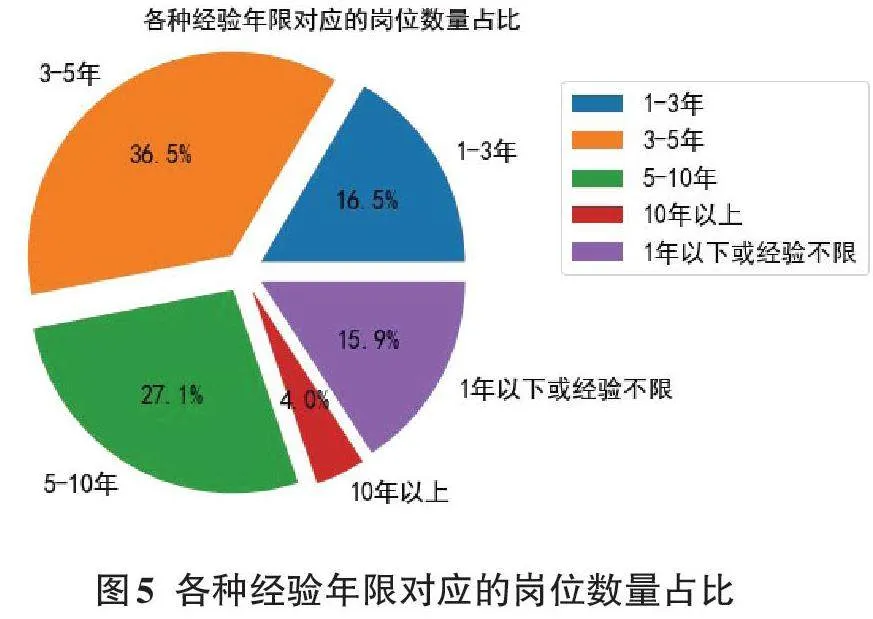
获取“年限”“学历”字段的所有数据,使用(df['年限']==\"1-3年\").sum()统计各个年限级别、各个学历级别的岗位数量,然后使用plt.pie()分别绘制饼图。如图5所示,该图表明3~5年经验年限的岗位最多,占比为36.5%,其次是5~10年的,然后是1~3年的,接着是1年以下或经验不限,占比15.9%,这说明适合应届毕业生的岗位还是比较多的。另一个饼图,本科学历对应的岗位最多,占比为75%,其次是大专,占比11.1%,这说明适合高职毕业生的就业岗位也比较多。
4.4 其他可视化分析
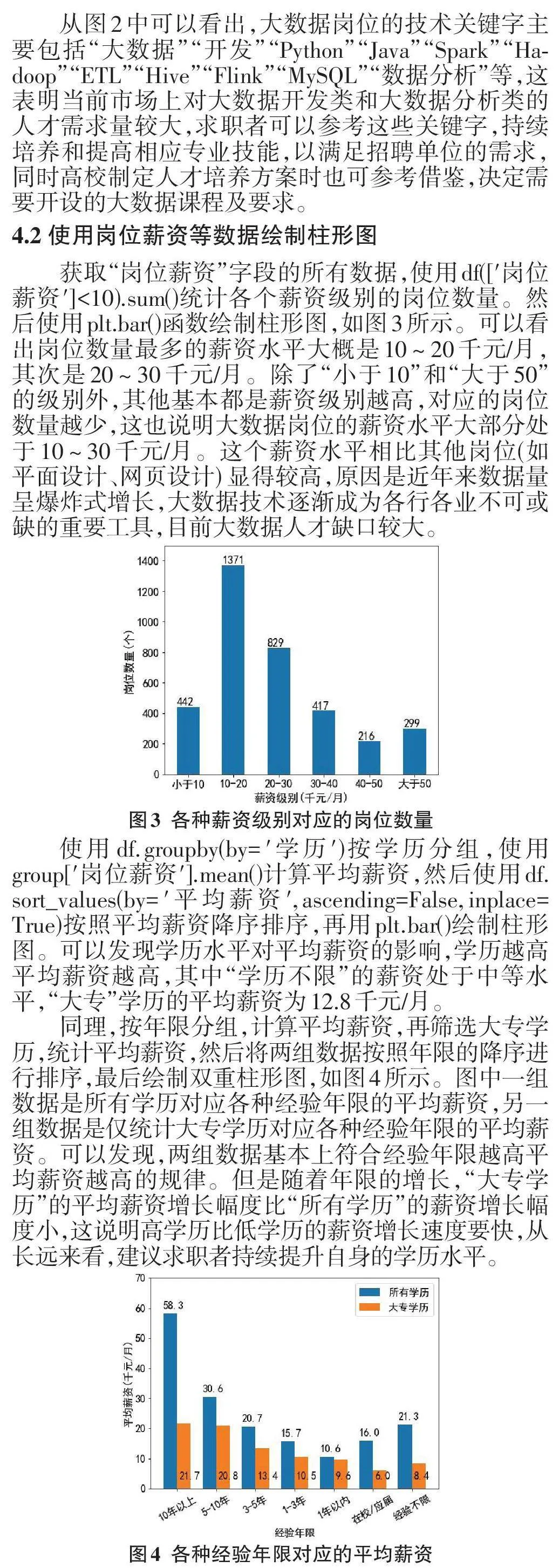
一是按照工作地区统计平均薪资。获取“工作地区”“岗位薪资”字段的所有数据,从“工作地区”字段提取出城市名,然后按城市名分组统计出每个城市的平均薪资,绘制“各个城市对应的平均薪资”条形图。统计得出杭州的平均薪资最高32.7,其次是深圳28.3、上海28.1、北京28.0,而广州平均薪资相对较低,只有20.5,单位都是千元/月。杭州平均薪资高的原因是大部分企业都是按超出12个月的薪资来计算的,如15、16或17月薪。杭州的互联网产业非常发达,这带动了整个城市的数字经济发展。其以电子商务、互联网、金融服务等为支柱的产业体系,带动了大量的就业机会,同时也提高了高新技术的工资水平。二是按照岗位涉及的行业统计岗位占比。从“公司规模”字段提取到涉及行业数据,然后按照“行业”分组统计出每个行业的岗位数量,绘制“各个行业的岗位数量占比”环形图。可以得出,计算机软件行业的大数据岗位最多,占34.4%,其次是互联网、大数据行业、通信/ 网络设备、计算机服务、电子商务等。三是按照公司规模人数统计岗位占比。从“公司规模”字段提取到企业规模数据,然后按照“企业规模”分组统计出每种规模级别的岗位数量,绘制“各种规模级别的岗位数量占比”环形图。可以得出,岗位数量占比最大的企业规模是100~499人,占24.8%,其次是20~99人的规模,说明中小企业提供的大数据岗位较多。
5 结束语
本文基于Python爬虫技术,对某直聘网站的大数据岗位招聘信息进行了爬取和可视化分析,揭示了大数据岗位的市场需求特征,包括技能要求、薪资水平、学历与经验要求、地区分布、行业分布和公司规模分布等。研究结果可为求职者提供就业指导,为高校制定人才培养方案提供参考,也为用人单位的招聘决策和人力资源管理提供依据。未来研究可以进一步探索其他数据源,例如拉勾网、智联招聘等,并结合更先进的数据分析方法,例如机器学习等,对招聘数据进行更深入的挖掘和分析。
猜你喜欢
软件导刊(2016年12期)2017-01-21 16:36:18
教书育人·高教论坛(2016年12期)2017-01-17 17:28:11
艺术与设计·理论(2016年4期)2017-01-16 02:04:52
科技传播(2016年19期)2016-12-27 14:53:29
中国管理信息化(2016年21期)2016-12-27 12:12:29
今传媒(2016年3期)2016-03-28 00:30:43
